CSIT205 - Generative AI
1/449
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
450 Terms
What are the practical applications of generative AI?
Generating faces and videos
Lung cancer detection and prediction
Summarising texts
Assisted coding
Image generation
Generating faces and videos and lung cancer prediciton
Image classification
Lung cancer detection
Text summarisation
Summarising texts
Text generation
AI-assisted coding (writing code)
Text evaluation
AI-assisted coding (critiquing)
Artificial Intelligence
Refers to systems designed to perform tasks that normally require human intelligence.
They can be rule-based or learning-based
Rule-based ones follows predefined instructions rather than learning patterns from data
Doesn’t necessarily learn from data
Machine Learning (subset of AI)
Focuses on pattern learning from data
Identifies feature-based patterns to make predictions or decisions
Does learn from data (where learning begins in AI)
Deep Learning (subset of ML)
Uses layer-based models
Multiple layers allow the system to learn increasingly complex patterns
Learn from data
Essentially ML using layered structures
Generative AI/GenAI (subset of DL)
Based on transformer models or diffusion models
Generates new outputs rather than only analysing data
Most specialised
AI Hierarchy
AI —> ML —> DL —> GenAI
What are the general areas generative AI is applied to?
Deep reasoning & general knowledge
Coding & software development
Multimodal (text + image + video)
Large-context
Supervised Learning
ML method where a model is trained using labelled data.
Each data example has a correct label (e.g. dog image —> Dog and cat image —> Cat)
Model learns the pattern between the data and its label
Goal: train a model to classify data
After learning from labelled examples (e.g. dogs and cats), the model can use learnt patterns to connect new data to the correct label
Unsupervised Learning
ML method where the model is trained using data with no labels
Model learns to distinguish groups in the data based on patterns
Groups similar data together into clusters without predefined labels
When a new input is given, the model places it into the most similar group
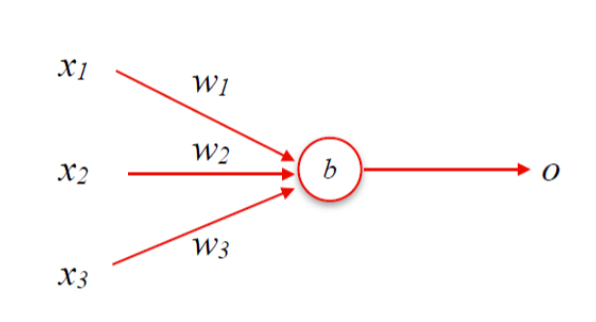
What is Perceptron?
Model that uses a linear function to produce binary outcomes i.e. Yes/No, True/False and 0/1
Used for binary classification
Learns by updating its weights and bias during training
Trained using supervised learning
What components make up a Perceptron model?
Inputs x — several input values
Weights w — importance assigned to each input
Bias b — an additional adjustment term
Output o — the final prediction
What is the activation function that Perceptron uses?
Step function
Performs binary classification [0, 1]
Output 0 if the linear combination is below the threshold
Output 1 if its above the threshold
![<ul><li><p>Step function </p></li><li><p>Performs binary classification [0, 1]</p><ul><li><p>Output 0 if the linear combination is below the threshold</p></li><li><p>Output 1 if its above the threshold</p></li></ul></li></ul><p></p>](https://assets.knowt.com/user-attachments/0618bedc-31d3-4fa7-9d9d-ec5d38052095.png)
How does a Perceptron learn?
Weights are updated using the learning rule

What are the limitations of Perceptron?
Performs only binary classification (0 or 1)
Uses a single layer — too simple to represent complex problems
Limited learning capability
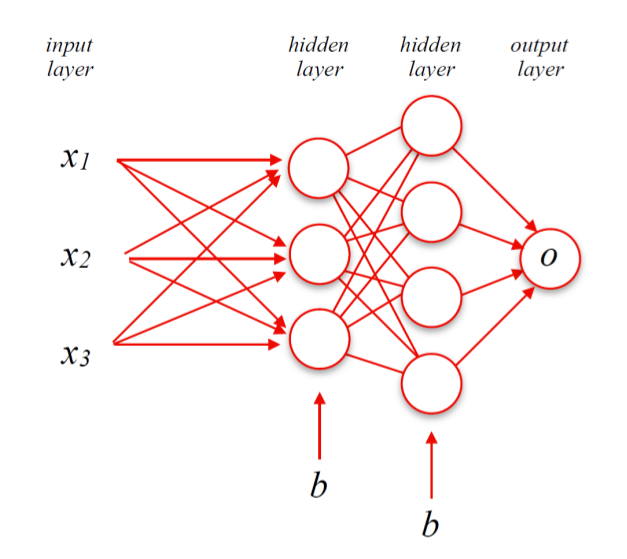
What is a Neural Network?
Multi-layer perceptron that learns weights between neurons
Uses stochastic gradient desccent to learn
Used for tasks such as object character recognition (OCR)
What is the structure of a neural network?
Same components as Perceptron
x = input values
w = importance assigned to each input
b = additional adjustment term
o = final prediction
1 input layer
Multiple hidden layers
1 output layer
Connections between layers have weights and biases, which are updated during learning
Information moves from left to right through the network (feed-forward)
What is the activation function that Neutral Networks use?
ReLU Function (Rectified Linear Unit)
Allows more gradual changes in the network
Output 0 if z <= 0
Output z if z > 0
where z = xw+b
How do neural networks learn?
Learning is based on minimising prediction error
Neural Networks Learning Rule: Loss Function
C(w) e.g. RSME
Measures the error between predictions and actual values
Neural Networks Learning Rule: Back-propogation
Calculates the gradient (how the cost changes when weights change)
Neural Networks Learning Rule: Stochastic Gradient Descent (SGD)
Updates the weights by moving down the gradient to minimise the cost
What are the limitations of neural networks?
Vanishing/exploding gradient — weights can become extremely small or large during backpropogation
Cannot handle sequence data (e.g. sentences like “The quick brown fox jumps over the lazy dog“).
Why do some neural networks tasks require memory?
Some problems involve sequences of information, where earlier inputs affect later outputs
What are Recurrent Neural Networks (RNNs)?
Contain loops within their layers, allowing information to persist
Keeps a running memory called the hidden state
Allows the model to process sequential data i.e. sentences, speech, time series, video etc
What types of input-output structures can RNNs handle?
One-to-one
One-to-many
Many-to-one
Many-to-many
Network is unfolded across time to show information flows step by step
What are the limitations of RNNs?
Vanishing gradient problem
Long-term dependency problem
Long sequences are difficult because the model must retain information from earlier inputs
Recurrent Neural Networks: Long Short-Term Memory (LSTM)
Special Type of RNN designed to remember information for a long time
Created to fix the memory loss problem in RNNs
Applications include language understanding e.g. Google Bert and time-series forecasting
How does LSTM improve on RNNs?
Instead of a single hidden state, LSTM uses:
Memory block that stores long-term information
Gates that control the flow of information
These help address:
Vanishing gradients
Long-term dependency problems (not completely)
What are Convulutional Neural Networks (CNNs) used for?
Designed to analyse grid-like data i.e. images
What is the basic architecture of a CNN?
Convolutional layers that apply kernels/filters to detect features in the data
Pooling layers that reduce dimensionality (downsampling)
Why are GPUs important for training CNNs?
They enable faster computation so its originally designed for computer graphics but can now be used for general processing
It makes the training faster
What architecture did many language generation systems use before transformers?
Encoder-decoder architecture
Also called sequence-to-sequence learning because it converts one input sequence into another output sequence
e.g. an English sentence translated into another language
What does the encoder do in the encoder-decoder architecure?
Reads the input sentence
Compresses the information into a fix-sized representation called a context vector e.g. 128 dimensions
What does the decoder do in the endcoder-decoder architecture?
Takes the context vector
Generates the output sequence word-by-word
Why do sequence-to-sequence models need to handle different input and output lengths?
Input and output sequences can have different lengths e.g. input english sentence is shorter than the output french translated sentence so models must handle variable-length sequence
Needs to understand a full input sentence before generating an output sentence word by word.
Solution
Encodes the entire input into a context vector
Lets the decoder generate the output sentence
What is the limitation of encoder-decoder models that use only LSTMs?
Suffers from long-term dependency problem which happens when the input sequence becomes very long
All the input information must be compressed into a single fixed-sized context vector.
So some important details may be lost
The model may struggle to understand long inputs
Why do LSTM encoder-decoder models struggle with relevance of words?
LSTMs consider the entire input sequence, but not all input words are equally important when generating each output and a standard LSTM autoencoder does not know which input parts are most relevant
So some irrelvant words may influence the output
Model cannot easily focus on the most important parts of the input
What is attention in machine learning models?
Allows a model to focus on specific parts of the input data instead of treating all parts equally
Model can look at the most relevant words or features when producing an output
Improves model’s performance
How does attention help when processing sequences of words?
Allows a model to attend to different parts of the input sequence at the same time
Model doesn’t treat all previous words as equally important
Model gives more weight to the words that matter most for the current prediction
Assigns different importance values (weights) to different words in the sequence
Word embedding
Way of representing the meaning of words using numbers
Each word is converted into a vector (a list of numbers), i.e. fox = [0.01, 0.43…, 0.3]
Vectors are learned from large amounts of text which allow the model to capture relationships between words
How is similarity between words measured in word embeddings?
Words are represented as vectors in an n-dimensional space
The angle or dot product between vectors (measured using cosine similarity) shows how similar the words are
If 2 vectors point in similar directions, words are considered more similar in meaning.
What does self-attention do in the encoder?
Allows the model to compute attention weights for each word (token) in the input sequence
Adjust the meaning of a word depending on the surrounding words in the sentence
Weights show how important each word is relative to other words in the same input sentence
Model then uses these weights to combine information from different words when creating the representation of each word (vector)
What does self-attention do in the decoder?
Computes attention weights for each token in the input sequence
These weights show which input words are most important when generating the next word in the output sequence
Uses these values to decide which parts of the input sentence to focus on for predicting the next word.
How does self-attention compute a token’s representation?
Applies the attention weights to the input words
Calculates a weighted sum of the input word vectors (features.
This means each word’s representation (vector) can include information from other relevant words in the sentence
e.g. the representation of fox may include context from “quick“ and “brown“
What does the self-attention output represent?
Produces a set of values called attention weights
Each value represents how important a specific input word (token) is when interpreting another token
These values help the model determine which words in the input sequence are most relevant
How does the decoder use attention during translation?
It starts with a start token (<EOS>) and asks: “Which input words are most important for generating the next word?“
Calculates attention scores for each input word, then forms a context vector as a weighted sum of the encoder outputs
Context helps the model predict the next word, and the process repeats for the following words.
What are the limitations of single-head attention?
Computation time increases as the input sequence becomes longer because attention weights must be calculated for more words (tokens)
Limited ability to capture complex relationships between words, since a single attention head can only focus on one type of relationship at a time.
Why do LSTMs struggle with long input sequences?
They consider the entire input sequence but not all words are equally important for producing each output word
Model may treat irrelavant words as important, making it harder to focus on the most relevant parts of the input
What architecture does a transformer typically use?
Encoder: processes the input and maps it into a context representation
Decoder: uses the encoder’s representation to generate the output sequence
Both uses a multi-layer architecture for the encoder and decoder
What is multi-head attention in transformers?
Allows the model to use multiple attention heads at the same time
Each head can focus on different relationships between words in the text
Captures more detailed and nuanced relationships in language
Why do transformers allow better parallelisation?
Uses multi-head attention, allowing the model to compute multiple attention weight calculations in parallel
Helps the model capture different relation types between words at the same time
What components are included in the transformer encoder and decoder layers?
Multi-head attention
Feed-forward neural networks
Add & norm layers for stability
Positional encoding to help the model understand word order
What are advantages of transformers?
Improved performance compared to traditional recurrent architectures
Can handle sequential data with variable-length inputs
Can be parallelised easily (e.g. using multiple GPUs and attention heads).
What are the main types of transformer models?
Encoder-only models e.g. BERT
Encoder-decoder models e.g. T5, BART
Decoder-only models e.g. GPT
What is an encoder-only (transformer) model?
Simpler architecture
Use fixed input length
Used for sentiment analysis
e.g. BERT
What is an encoder-decoder (transformer) model?
Can handle longer sequences and context
Used for translation
What is a decoder-only (transformer) model?
Simpler architecture
Used for text generation and translation
What is a Variational Autoencoder (VAE)?
A neural network designed to encode data and reconstruct it as accurately as possible
Encoder converts the input e.g. an image into a compressed numerical representation called an embedding vector (Z)
This vector captures important features of the input i.e. shapes or textures
The decoder then uses this representation to reconstruct the original image.
Goal: output image to be as close as possible to the original input
How are autoencoders trained?
Split the dataset into training and test sets
Build the encoder and decoder parts of the autoencoder
Train the model using the training data, where the input and output are the same data
During training:
Model tries to reconstruct the same image it receives as input
Calculates the difference between the original and reconstructed image (reconstruction loss)
Model updates its paramters using backpropogation to reduce this error
How can the decoder in VAE generate new outputs after training?
After training:
A vector (embedding) is defined e.g. x = [2.2, 2.5]
The decoder predicts an output using this vector: decoder.predict(x)
The decoder then generates an image based on the vector representation
Different points in the embedding space correspond to different image features
What is a limitation of standard autoencoders?
When an image is encoded into a vector in the embedding space, the model does not guarantee that nearby vectors represent similar images
This means that even if 2 vectors are close in the embedding space, the generated images may still be very different
This happens because
Standard autoencoders are trained only to reconstruct each individual input
They do not learn relationships between different embedding vectors
How do Variational Autoencoders address its limitation?
Instead of representing an image as a single point (vector), they model it as a normal /probabability (Gaussian) distribution
The encoder outputs
A mean vectoro (center of the distribution)
A variance vector (how spread out the distribution is)
The model then samples a point from this distribution.
This helps create a more structured embedding space for generating outputs
What is a Generative Adversarial Network (GAN)?
Consists of 2 neural networks: generator and discriminator
They compete which helps the generator produce more realistic outputs
Goal: generate new data samples that look similar to real data
Often used in unsupervised learning tasks
What is noise?
A vector of random numbers with no meaninga vector of random numbers with no meaning
What is the generator’s role in a GAN?
Responsible for creating new data samples that look like real data
How it works:
Starts with random noise as input
Generator transforms this noise into synthetic da
Training objective:
Improves by minimising its loss function
Goal: fool the discriminator into thinking the generated data is real
What is the discriminator’s role in a GAN?
Determines whether a sample is real data from a training dataset or fake data produced by the generator
It receives both real and generated samples and outputs a probability showing how likely the input is real
Training objective
Improves by maximising the loss function
Tries to correctly detect fake images produced by the generator
How is a GAN trained?
Alternates between updating the generator and the discriminator
Generator tries to make a generated sample look real by maximising the function toward 0
The discriminator tries to correctly classify generated samples as fake by pushing the function toward 0
Function = D(G(z))
z = latent vector used to generate new data
What are some application of GANs?
Image generation (e.g. faces/objects)
Data augmentation (for tasks like image classification)
Anomaly detection (finding unusual data points)
Style transfer and colourisation
Text-to-image synthesis
What are some limitation of GANs?
Mode collapse: generator produces limited variations of the same output
Vanishing gradients: generator’s weights become too small during training, making learning difficult
Unstable training: discriminator may become too powerful, causing the generator to converge to a poor solution
What is a diffusion model and what can it learn?
An unsupervised learning framework
Learns to reconstruct images using diffusion and reverse diffusion
Models complex distributions, even with noise and uncertainty
Main components: encoder, decoder, skip connections
What does the Diffusion model actually learn during training (reverse diffusion)?
It learns to predict the noise at each step
Then subtracts that noise gradually
This repeated refinement produces high-quality and diverse images
What is the role of U-net in Diffusion Models?
The main architecture used
Does not generate images directly
Predicts the noise in a noisy image so the model can remove it
What are the main parts of U-Net (network)?
Noise-level embedding
Encoder
Decoder
Skip connections
What inputs does the U-Net receive?
Noise variance (timestep t): tells how much noise is added
Noisy image: image at step t
Noise embedding spreads this timestep info across all pixels
What does the U-Net encoder do?
Downsampling Path
Takes combined features (images + noise info)
Gradually transforms: x0 —> x1 —> … —> xt
Reduces spatial size but increases features
Captures high-level semantic inormation
What does the U-Net decoder do?
Reverse the process: xt —> xt-1 … —> x0
Predicts noise and removes it step-by-step
Cannot jump directly from noisy to clean image
What are skip connections in U-Net and why are they important?
Direct links between encoder and decoder layers
Restore lost details like edges, textures, boundaries
Help decoder recover spatial information
Reduce issues like vanishing gradients
What are the three key components of a Diffusion model?
Noise schedule: controls how much noise is added at each step
Diffusion process: gradually adds noise to the image over many steps
Reverse diffusion: predits and removes noise step-by-step to recover or generate images
What does the Noise schedule do in the Diffusion model?
Controls how quickly noise is added
Small noise is added gradually over many steps
Determines how fast the image becomes corrupted
What happens during the Diffusion process?
Noise is iteratively added to the image
Image transforms: x0 —> x1 —> x2 —> … —> xt
After many steps, the image becomes almost random noise
What happens during Reverse Diffusion?
Model learns how noise was added
Then predicts and removes noise step-by-step
Gradually reconstructs a clean image from noise
What are the main steps in Diffusion model training?
Add noise to images (using noise rate and signal rate)
Train model to predict noise and signal
Remove noise from the image (recover clean version)
Calculate loss (compare prediction vs true values)
Update weights (where learning happens)
What is Nose rate in the Diffusion model?
How much noise is added
What is Signal rate in the Diffusion model?
How much of the original image remains
What does the Diffusion model learn during training?
It estimates how much noise is present
Predicts noise and signal components
Uses this to recover the clean image
What are the main advantage of Diffusion models?
High-fidelity generation: very realistic and detailed images
Mode coverage: captures a wide variety of patterns
Robustness: handles noise well and resists disturbances
Where are diffusion models used?
Text-to-image generation
Image editing & inpainting
Creative design and digital art
What are the main challenges of manual coding?
Time-consuming and labour-intensive: takes many hours to write, test and debug
Error-prone: human mistakes can cause bugs, unexpected behaviour, or security issues
Limited scalability & maintainability: code becomes harder to manage as projects grow
What is code analysis?
AI examines the structure and quality of a program
Identifies issues and possible improvements
What aspects of code can be analysed?
Functions in the program
Directory/project structure
How modules interact
Whether the code follows good programming practices
What is the output of code analysis?
Suggestions for improvement
Helps create cleaner and more maintainable code
Can be integrated into editors for real-time feedback
What is code completion?
AI predicts what the developer will write next
Suggests or automatically generates code based on existing code
How does AI translate natural language to code?
Developers describe tasks in plain English
AI generates the corresponding code
How does AI help with testing?
Automatically generates unit tests for functions
Helps verify correctness and improves software reliability
What is code refactoring?
Improves internal code structure
Does NOT change functionality