2.1.3 Protein synthesis
2.1.3 Nucleotides and nucleic acids (f-g)
Protein synthesis - Notes
2.1.3f: the nature of the genetic code
Outline how the sequence of bases in DNA can code for the primary structure of a polypeptide chain. (F)
Define the terms “codon” and “gene”.
Define the terms “triplet code”, “non-overlapping”, “degenerate”, and “universal” in relation to the genetic code. (F)
Explain why the genetic code is a triplet code, the value of it being non-overlapping and the reason for it being degenerate.
Describe what is meant by a “start codon” and a “stop codon”.
Outline how mutations can alter the structure of a protein.
2.1.3g: transcription and translation of genes resulting in the synthesis of polypeptides
Define the terms “transcription” and “translation”.
State the three types of RNA. [see ‘Nucleotide and nucleic acid structure” pack]
Draw a table to compare the structure and function of mRNA, tRNA, and DNA. (F)
Draw and annotate a diagram to outline the process of protein synthesis.
Draw and annotate a diagram to show the sequence of events in transcription.
Describe the process of transcription in a series of bullet points. (F)
Define the terms “sense strand”, “antisense strand”, and “template strand”.
Describe the structure of a ribosome and explain the role of rRNA.
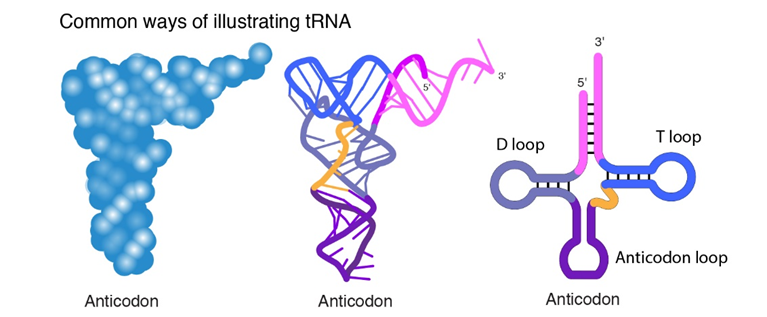
Draw and label a diagram of tRNA.
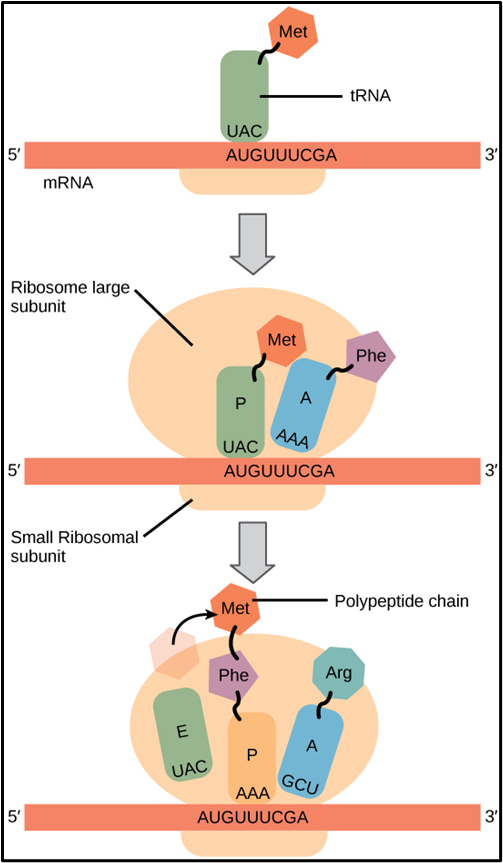
Draw and annotate a series of diagrams to show the sequence of events in translation.
Describe the process of translation in a series of bullet points. (F)
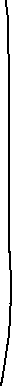
Genes and alleles
A gene is the sequence of nucleotide bases of DNA coding for the production of a specific polypeptide by determining the sequence of amino acids (its primary structure).
Genes are sections of chromosomes. Each chromosome is a single molecule of DNA wrapped around protein molecules (called histones).
Genes can exist in different forms called alleles which code for different versions of the same characteristic. For example we all have two copies of the gene for eye colour, but there are different alleles of this gene that produce the range eye colours seen in the human population (actually there are several genes involved in determining eye colour so it’s even more complicated than that).

Different alleles of a gene have different sequences of nucleotides which result in different proteins being produced and therefore result in different characteristics.
Alleles of a particular gene are found in the same relative position (locus) on homologous (pairs of) chromosomes. Homologous chromosomes carry the same genes at the same loci but not necessarily the same alleles.
The genetic code
DNA carries the genetic information that determines the sequence of amino acids in proteins. The genetic code is the sequence of nucleotide bases.
The genetic code is a triplet code. This means that a sequence of three nucleotides in DNA codes for one amino acid.
A sequence of three nucleotide bases in DNA is called a base triplet.
There are 4 different nucleotides in DNA so this means there are 64 (43) possible base triplets.
These triplets code for 20 amino acids.
The base triplets on mRNA are called codons.
There are 64 different codons but only 20 different amino acids so some amino acids are coded for by more than one codon. This mean the genetic code is degenerate.
Some codons are used for ‘punctuation’ for example at the start or end of a gene (start or stop codons).
The genetic code is non-overlapping. This means that each triplet is read in sequence separate from the triplet before and the triplet after. I.e., each nucleotide only contributes to one triplet. Being non-overlapping allows any triplet to follow any other triplet and so doesn’t restrict the possible sequences of amino acids in proteins.
The genetic code is (almost) universal. This means that each base triplet codes for the same amino acid in (almost) all life.

Mutations
Mutations are changes in the sequence of nucleotides in DNA. Mutations that affect a single nucleotide are called point mutations. They can be substitutions (where one nucleotide is replaced by a different one), deletions (where one nucleotide is removed), or insertions (where one nucleotide is added).
Substitution mutations can have no effect on the final protein produced (if the same amino acid is still coded for after the change), can affect one amino acid in a protein, or can end translation and so result in a shortened protein (if the change results in a stop codon).
Deletions and insertions of single nucleotides have a large impact on the protein as the amino acid coded for by that triplet and all subsequent amino acids, will be different due to a frame shift in the translation of the code.
Mutations affect the jobs cells can do due to this sequence of logical steps:
A mutation changes the sequence of nucleotides in DNA
A protein with a different sequence of amino acids is produced
Bonds that hold the tertiary structure of the polypeptide chain together occur in different places
The protein folds into a different shape
The altered shape affects the job the protein should be doing
Overview of protein synthesis
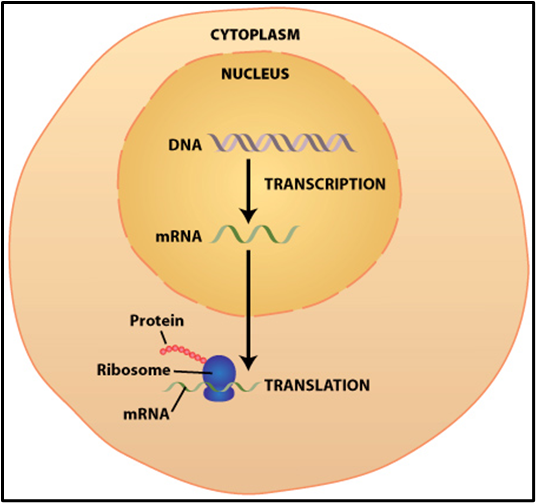 In eukaryotic cells the DNA, carrying the code to build proteins, remains in the nucleus. However, the ribosomes that make the proteins are in the cytoplasm. In diploid cells there are only two copies of each gene. It is important to keep the DNA safe in the nucleus, so it doesn’t get damaged by the reactive molecules in the cytoplasm. Instead of DNA travelling to the ribosomes, a copy of the genetic code is made in a process called transcription. The molecule produced is called messenger RNA (mRNA), it leaves the nucleus and travels to a ribosome where the code can be used to make a polypeptide chain in a process called translation.
In eukaryotic cells the DNA, carrying the code to build proteins, remains in the nucleus. However, the ribosomes that make the proteins are in the cytoplasm. In diploid cells there are only two copies of each gene. It is important to keep the DNA safe in the nucleus, so it doesn’t get damaged by the reactive molecules in the cytoplasm. Instead of DNA travelling to the ribosomes, a copy of the genetic code is made in a process called transcription. The molecule produced is called messenger RNA (mRNA), it leaves the nucleus and travels to a ribosome where the code can be used to make a polypeptide chain in a process called translation.
Transcription
The DNA is in the nucleus so this process occurs in the nucleus
RNA polymerase binds to the DNA (at a promotor region)
DNA unwinds and unzips (by the action of DNA helicase), beginning just after a promotor region
Hydrogen bonds between the two DNA strands are broken by DNA helicase as the DNA molecule unzips.
The template (or antisense) strand is used as a template to construct the mRNA (RNA polymerase moves along the template strand in the 3’ to 5’ direction and so mRNA is made in the 5’ to 3’ direction)
Complementary free RNA nucleotides link with the exposed DNA nucleotides by hydrogen bonds (A on DNA with U, T on DNA with A, C on DNA with G, G on DNA With C) (2 hydrogen bonds between A and U, and T and A. 3 hydrogen bonds between C and G)
The enzyme RNA polymerase joins the RNA nucleotides together by phosphodiester bonds to form mRNA (in condensation reactions)
Hydrogen bonds attaching the mRNA to the template strand of DNA are broken
mRNA is released from the DNA
The process continues until RNA polymerase reaches a terminator region
The relatively short mRNA molecule coding for a single gene leaves the nucleus via a nuclear pore (and enters the cytoplasm)
Complementary bases of the DNA re-join once the mRNA has detached
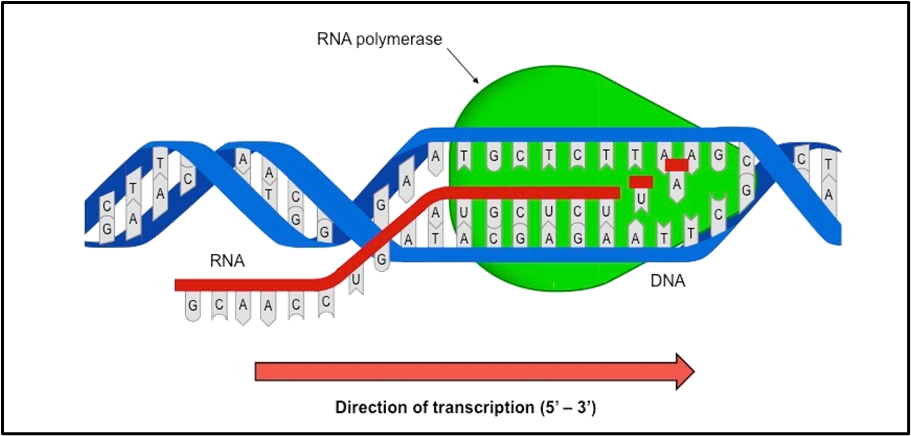
The sense and the antisense strand
The strand of DNA used as a template in transcription is called the antisense (or template) strand. The other strand is called the sense (or coding) strand.
It seems a bit weird to call the strand that is not being used the ‘sense’ strand. However, because the sense strand and the mRNA are both complementary sequences of nucleotides to the template strand, they have the same sequence of nucleotides (except that where there is a T in the DNA there is a U in the mRNA).
The mRNA is a copy of the code on the sense strand (not a copy of the code on the template strand).
Transfer RNA (tRNA)
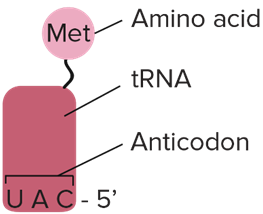
Ribosomes catalyse the construction of a new polypeptide chain but a molecule called transfer RNA (tRNA) is really the one that translates the code on mRNA into a sequence of amino acids. It does this by having one end that can bind to particular codons on mRNA whilst at the other end there is the particular amino acid that that codon codes for.
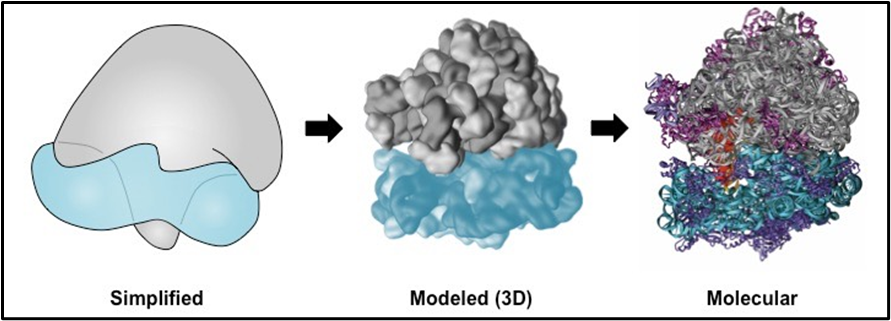
Ribosomes
Ribosomes are made up of two sections a large subunit and a small subunit. Each subunit is made of both protein and ribosomal RNA.
The shape of the ribosome allows all the molecules involved in translation to interact with each other in the correct way. One section of the large subunit made of RNA called peptidyl transferase catalyses the transfer of the amino acid from one tRNA onto the end of the growing polypeptide chain.
Translation
In the cytoplasm the mRNA attaches to a ribosome (the start codon (AUG) of mRNA attaches to the small subunit of the ribosome and then the large subunit attaches)
In other words the first codon (start codon) of the mRNA enters the ribosome
A tRNA molecule with the complementary anticodon (the first one is UAC) brings the appropriate amino acid (the first amino acid is always methionine)
The anticodon of the tRNA binds to the codon of the mRNA using hydrogen bonds
The ribosome moves along one codon and the next appropriate tRNA (with its specific amino acid) binds to the next codon
The two amino acids join by a peptide bond (in a condensation reaction) catalysed by the enzyme peptidyl transferase (an rRNA component of a ribosome)
The first amino acid detaches from its tRNA
The ribosome moves along one more codon and the process is repeated
tRNAs that have detached from their amino acid detach from the mRNA (Hydrogen bonds break) and are reused by attaching to another specific amino acid (the one that is appropriate for the tRNA’s anticodon)
The process is repeated again and again and the chain of amino acids gets longer, folding up as it grows
Eventually a stop codon is reached and the process stops. There are no tRNA molecules with a complementary anticodon to the stop codon on mRNA. Instead a release factor binds. The ribosome detaches from the mRNA and the polypeptide chain detaches from the ribosome and the last tRNA. The process of protein synthesis is now complete