Chapter 5: The Structure and Function of Large Biological Molecules
The Molecules of Life
- all living things are made up of four classes of large biological molecules: carbohydrates, lipids, proteins and nucleic acids
- ==macromolecules==: large and complex molecules
- the architecture of a large biological molecule plays an essential role in its function
- FORM = FUNCTION
- large biological molecules have unique properties that arise from the orderly arrangement of their atoms
Concept 5.1: Macromolecules are polymers, built from monomers
- ==polymer==: long molecule consisting of many similar building blocks
- ==monomer==: the repeating unit that serves as a building block of polymers
- carbohydrates, proteins, and nucleic acids are polymer -- NOT LIPIDS
^^The Synthesis and Breakdown of Polymers^^
- although each class of polymer is made up of a different type of monomer, the chemical mechanisms by which cells make and break down polymers are basically the same in all cases
- ==enzymes==: specialized macromolecules (proteins) that speed up chemical reactions such as those that make or break down polymers
- ==dehydration reaction==: occurs when two monomers covalently bond together through the loss of a water molecule to form parts of a polymer
- each monomer contributes to a part of the water molecule that is formed through this reaction
- this process is also called ==polymerization==
- ==hydrolysis==: process that disassembles polymers → reverse of dehydration synthesis
- uses pressure to break the bond and adding a water molecule to the free bonds
- without water, those empty bonds can virtually bond with anything and become poison
- however, hydrolysis does not only occur in polymer - material doesn’t have to be a polymer
^^The Diversity of Life^^
- variety in molecules is due to the fact that many different polymers can be created from similar or same monomers → variation occurs when the arrangement is modified
- small molecules common to all organisms act as building blocks that are ordered into unique macromolecules
- least variation is seen within the same organism, while the greatest variety is seen across different species
Concept 5.2: Carbohydrates serve as fuel and building material
- ==carbohydrates==: sugars and the polymers of sugars
- almost everything in the body can be broken down into carbohydrates because they are needed for energy
- even protein can be broken down into carbs
- ==monosaccharides==: simple sugars → simplest carbohydrates
- have multiples of the molecule formula CH2O
- classified by the location of the carbonyl group (==aldose or ketose==) and the number of carbons in the carbon skeleton (ex. triose, pentose, hexose)
- another source of diversity, is in the way their parts are arranged spatially around an asymmetric carbon - where the different groups are attached to a central carbon atom
- most common is glucose (C6H12O6) → alpha and beta glucose only exist randomly when in water due to how the bonds bend when in water
- different glucose molecules of glucose only differ by where their double bonded oxygen is located, making it either an aldose or ketose sugar
- most five or six carbon monosaccharides form rings in water as a hydration shell bends the linear structure into a more stable structure
- monosaccharides serve as a major fuel for cells and as raw material for building molecules
- ==disaccharide (oligosaccharide)==: two monosaccharides joined by a glycosidic linkage
- ==glycosidic linkage==: covalent bond between two monosaccharides by a dehydration reaction
- %%maltose%%: alpha glucose + alpha glucose
- %%sucrose%%: alpha glucose + fructose
- %%lactose%%: alpha glucose + galactose
- Know how to draw and recognize the molecules
- ==polysaccharides==: polymers composed of many sugar monomers (carbohydrate macromolecules)
- have storage and structural roles
- contain a large number of monosaccharide units bonded to each other by a series of glycosidic bonds
- ^^storage^^:
- %%starch%% (storage polysaccharide for plants) consists of glucose monomers → plant version of glycogen in animals
- plants store surplus starch as granules within chloroplasts and other plastids
- simplest form of starch is amylose
- %%glycogen%% (storage polysaccharide in animals) → stored in liver and muscle cells (for energy)
- hydrolysis of glycogen in these cells releases glucose when the demand for sugar increases
- easiest to break down in our bodies
- if you have fat around your liver, it means that your body turned starch into fat and formed a lining, which is not good for you
- ^^structure^^:
- %%cellulose%%: major component in the tough walls of plant cells
- polymer of glucose, like starch, but has different glycosidic bonds (has beta bonds)
- the difference is based on two ring forms for glucose: alpha and beta
- %%chitin%%: structural polysaccharide found in the exoskeleton of arthropods
- also provides structural support for the cell walls of many fungi
- ^^differences^^:
- structural polysaccharides are made up of beta glycosidic linkages, while storage polysaccharides are made up of alpha glycosidic linkages
- Starch is helical due to alpha configuration
- Cellulose is straight and unbranched due to beta configuration
- Certain hydroxyl groups on cellulose monomers can hydrogen-bond with hydrogen on parallel cellulose monomers
- enzymes that digest starch by hydrolyzing alpha linkages can’t hydrolyze beta linkages in cellulose → different arrangements, won’t fit in enzyme
- the cellulose in human food passes through the digestive tract as “insoluble fiber”
- some microbes use enzymes to digest enzymes → without this enzyme cellulose physically can’t be brown down in any body
- many herbivores have symbiotic relationships with these microbes, which is why they can process cellulose much better than people can
- individual glucose molecules (mini carbs) are macromolecules, but not polysaccharides
Concept 5.3: Lipids are a diverse group of hydrophobic molecules
- ==lipids==: the one class of large biological molecules that does not include true polymers, and are generally not big enough to be considered macromolecules
- the unifying feature of lipids is that they mix poorly, if at all, with water
- due to its molecular structure → consists mostly of hydrocarbon regions, which are nonpolar, and thus does not mix well with water
^^Fats^^
- although fats are not polymers, they are large molecules assembled from dehydration reactions
- ==fats== are constructed from two types of smaller molecules: glycerol and fatty acids
- ==glycerol== is a three-carbon alcohol with a hydroxyl group (OH) attached to each carbon
- ==fatty acids== consist of a carboxyl group attached to a long carbon skeleton
- formed through dehydration synthesis
- in a fat, three fatty acid chains are joined to glycerol by an ester linkage (==esterification==), creating a ==triacylglycerol or triglyceride==
- fatty acids in a fat can be all the same or of two or three different kinds
- this is why fats are not polymers because they do not always have the same monomer and are made up of two or more different molecules put together
- ==saturated fatty acids==: have the maximum number of hydrogen atoms possible and no double bonds
- form fats that are unhealthy for the body in large quantities → must control consumption
- usually solid at room temperature
- most animal fats are saturated
- ==unsaturated fatty acids==: have one or more double bond
- there are unbonded hydrogens in its structure, which means that it can bond to anything on these H
- ==polyunsaturated lipids==: have more than one double bond (very healthy for you)
- usually liquid or oil at room temperature due to “kinks” in fatty acid chains (due to cis structure) that cause the fat molecules to not be able to pack close together
- plant fats and fish fats are usually unsaturated
- ==hydrogenation==: the process of converting unsaturated fats to saturated fat by adding hydrogen
- hydrogenating vegetable oils also creates unsaturated fats with trans double bonds (very unhealthy and extremely hard to get rid of)
- to become a trans fat, a hydrogen or OH on a carbon will switch sides under pressure or heat and become a trans fat
- trans fats start as a cis fat, then the H or OH switches under high pressure or heat
- to be a trans fat, the fat must be unsaturated for the double bond to be there
- these trans fats may contribute more than saturated fats to cardiovascular disease
- the major function of fats is energy storage
- humans and other mammals store their long-term food reserves in adipose cells
- adipose tissue also cushions vital organs and insulates the body
- plants store starches in seeds → compact method, good for immobile beings
- a diet rich in saturated fats may contribute to cardiovascular disease through plaque deposits
- not guaranteed diseases because factors such as genetics and environment, etc, also contribute
- fats are also good because they are needed by your body -- ex. insulation and neurons
- if fat coat on neurons disintegrates, the neurons can’t communicate with body probably
- this is what happens in Parkinson’s disease → neurons can’t communicate with muscles
^^Phospholipids^^
- phospholipids are essential for cells because they are major constituents of cell membranes
- ==phospholipids== have two fatty acid chains and a phosphate group attached to a glycerol
- they two fatty acid tails are hydrophobic, but the phosphate groups and its attachments form a hydrophilic head
- they have one bent tail and one straight tail to allow the cell membrane to remain semi-permeable
- if both were straight, the lipids would be too close together, not allowing anything to pass in or out of cell membranes, and if they were both bent, they would be too far apart, causing a lack of control
- bent tail is an unsaturated fatty acid (due to kink of cis bond), and straight tail is saturated
- the head of the phospholipid is charged, which allows it to form bonds with other molecules
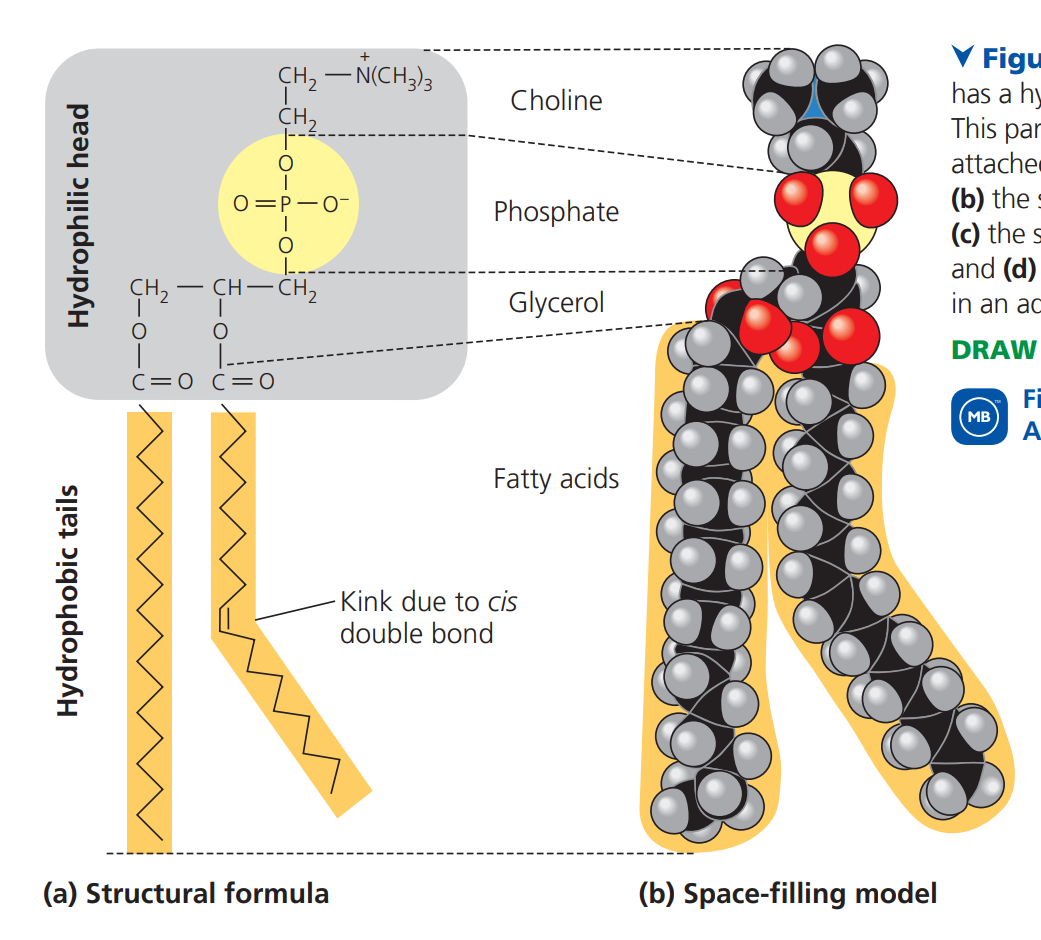
- when phospholipids are added to water, they self-assemble into double-layered sheets called ==bilayers==
- at the surface of a cell, phospholipids are also arranged in a bilayer, with the hydrophobic tails pointing towards the interior
- this forms a boundary between the cell and its external environment
^^Steroids^^
- ==steroids==: lipids characterized by a carbon skeleton consisting of four fused rings
- steroid backbone: 3 cyclohexanes (one with a double bond), 1 pentane
- ==cholesterol==: type of steroid that is a component in animal cell membranes and a precursor from which other steroids are synthesized
- high levels of cholesterol in the blood may contribute to cardiovascular disease
Concept 5.4: Proteins include a diversity of structures, resulting in a wide range of functions
- proteins account for more than 50% of the dry mass of most cells
- some proteins speed up chemical reactions → enzymes
- enzymes reduce the amount of initial energy for the reaction to happen so that it SEEMS to be occurring faster
- enzymatic proteins regulate metabolism by acting as catalysts
- ALL ENZYMES ARE PROTEINS BUT NOT ALL PROTEINS ARE ENZYMES
- enzymes have specific shapes and need specific conditions to work and be effective
- other protein functions include defense, storage, transport, cellular communication, movement, and structural support
- proteins are all constructed from the same set of 20 amino acids, linked in unbranched polymers
- ==peptide bond==: bond between amino acids forming a polymer
- ==polypeptide==: unbranched polymers of amino acids
- ==protein==: biologically functional molecule made up of polypeptides, each folded and coiled into a specific three-dimensional structure
- almost all proteins can be broken down into urea when they are not needed anymore, so that it can be released from the body as urine
- water soluble proteins are easier to break down into urea than other proteins
^^Types of Proteins^^
- %%enzymatic proteins%%:
- selective acceleration of chemical reactions
- ex. digestive enzymes catalyze the hydrolysis of bonds in food molecules
- %%storage proteins%%:
- storage of amino acids
- ex. Casein, the protein of milk, is the major source of amino acids for baby mammals
- %%defensive proteins%%:
- protection against disease
- ex. antibodies inactivate and help destroy viruses and bacteria → tell white blood cells which dangerous cells need to be destroyed
- %%transport proteins%%:
- transport of substances
- ex. hemoglobin is a protein transports oxygen around the body
- %%hormonal proteins%%:
- coordination of an organism’s activities → helps cells, organs, and organ systems talk to each other
- ex. insulin, secreted by the pancreas, causes other tissues to take up glucose, thus regulating blood sugar within the body → insulin unlocks channels in cells to allow glucose in (does not go into cells or break down glucose on its own)
- %%contractile and motor proteins%%:
- used for movement
- ex. responsible for the undulations of cilia and flagella / actin and myosin proteins are responsible for the contraction of muscles
- %%receptor proteins%%:
- response of cell to chemical stimuli
- ex. receptors built into the membrane of a nerve cell detect signaling molecules released by other nerve cells
- %%structural proteins%%:
- used for support
- ex. Keratin is the protein of hair, horns, feather, and other skin appendages
^^Amino Acid Monomers^^
- ==amino acids==: organic molecules with amino (N-terminus) and carboxyl groups (C-terminus)
- amino acids differ in their properties due to differing side chains, called R groups
- non-polar side chains (hydrophobic)
- electrically charged side chains (acid and base) (hydrophilic)
- polar side chains (hydrophilic)
- amino acids are linked by covalent bonds called ==peptide bonds==
- form of dehydration synthesis
- OH from C-terminus of amino #1 and H from N-terminus of amino #2 form water and create a straight bond between the remaining C and N
- 3 amino acids = tripeptide , 4+ amino acids = polypeptide
- each polypeptide has a unique linear sequence of amino acids, with a carboxyl end and an amino end
^^Protein Structure and Function^^
- the specific activities of proteins result from their intricate three-dimensional architecture
- as soon as polypeptide chains are formed, they have to be formed into a specific structure and taken to where it is to be used, if not, then spliceosomes come along and cut up the bonds so that the amino acids can be used again and recycled
- B-cells remember how to build the antibodies (versions of the virus that still has the same protein but without the ability to multiply) - B-cells memorize the shape of the virus to quickly make the antibodies when they encounter the virus again
- a functional protein consists of one or more polypeptides precisely twisted, folded, and coiled into a unique shape
- the sequence of amino acids determines a protein’s three-dimensional structure and its structure determines how the protein works
- the function of a protein usually depends on its ability to recognize and bind to some other molecule
^^Four Levels of Protein Structure^^
- proteins share three superimposed levels of structure → primary, secondary, and tertiary structure
- %%primary structure%%:
- a protein’s unique sequence of amino acids
- like the order of letters in a long word
- determined by inherited genetic information: DNA → RNA → polypeptide (this is how our body comes up with unique characteristics)
- %%secondary structure%%:
- consists of coils and folds in the polypeptide chain
- result from hydrogen bonds between repeating constituents of the polypeptide backbone
- can have alpha helix and beta pleated sheets together but held together loosely
- %%tertiary structure%%:
- overall shape of a polypeptide is determined by interactions among various side chains (R groups), rather than interactions between backbone constituents
- interactions include hydrogen bonds, ionic bonds, hydrophobic interactions, and LDF
- strong covalent bonds called disulfide bridges may reinforce the protein’s structure
- more compressed together, forms a specific shape
- %%quaternary structure%%:
- results when a protein consists of two or more polypeptide chains
- combinations of tertiary structures
- Ex. collagen (3 polypeptides coiled) and hemoglobin (4 polypeptides - two alpha, two beta)
- Factors Affecting Protein Structure
- changed primary structure, pH, salt concentration, temperature, other environmental factors
- ==denaturation==: loss of a protein’s native structure
- if a protein does not have its ideal conditions, it will become denatured, but if you return it to ideal conditions, it will return back to functioning normally
^^Protein Folding in the Cell^^
- it is hard to predict a protein’s structure from its primary structure
- most proteins probably go through several stages on their way to a stable structure
- diseases such as Alzheimer’s, Parkinson’s, and mad cow disease are associated with misfolded proteins
Concept 5.5: Nucleic acids store, transmit, and help express hereditary information
- the amino acid sequence of a polypeptide is programmed by a unit of inheritance called a ==gene==
- genes consist of DNA, a ==nucleic acid== made of monomers called nucleotides
- DNA is a carboxylic acid and a polymer (monomer made up of nitrogenous base, pentose sugar, and acid group)
^^The Roles of Nucleic Acid^^
there are two types of nucleic acid → deoxyribonucleic acid (DNA) and ribonucleic acid (RNA)
DNA provides directions for its own replication
DNA directs synthesis of messenger RNA (mRNA), and through mRNA, controls protein synthesis
This process is called ==gene expression==
- recessive and dominant genes are determined by their coiling → in the double helix, recessive genes will remain tight close to the dominant genes so that only the dominant gene is expressed / copied
- the dominant gene unwinds to be read, copied, and transformed into RNA
@@Stages of Synthesis:@@
- mRNA made out of freed bases in the nucleus (DNA code determines code of RNA)
- mRNA exits nucleus
- Ribosome takes mRNA and reads the code
- tRNA brings amino acids read from the “recipe” to the ribosome
- tRNA carries amino acids to ribosomes
- A chain of amino acids is formed
- Protein is formed out of amino acids
each gene along a DNA molecule directs synthesis of a messenger RNA (mRNA)
- the mRNA molecule interacts with the cell’s protein-synthesizing machinery to direction production of a polypeptide
the flow of genetic information can be summarized as DNA → RNA → polypeptide
^^The Components of Nucleic Acids^^
- nucleic acids are polymers called ==polynucleotides== → same as saying DNA
- each polynucleotide is made of monomers called ==nucleotides==
- each nucleotide consists of a nitrogenous base, a pentose sugar, and one or more phosphate groups
- free floating nucleotides will have three phosphate groups
- if it is part of DNA, it will have one phosphate group
- in DNA sugar is deoxyribose, in RNA the sugar is ribose
- ==nucleoside==: portion of a nucleotide without the phosphate group
- SO nucleotide = nucleoside + phosphate group
^^Nucleotide Polymers^^
- nucleotides are linked together by a ==phosphodiester linkage== to build a polynucleotide
- phosphodiester linkage consists of a phosphate group that links the sugar of two nucleotides
- these links create a backbone of sugar-phosphate units with nitrogenous bases as appendages
- the sequence of bases along a DNA or mRNA polymer is unique for each gene
^^The Structures of DNA and RNA molecules^^
- DNA molecules have two polynucleotides spiraling around an imaginary axis, forming a ==double helix==
- on almost all genes, only one side of the DNA is the actual gene, while the other side is just there for protection → only one strand might have the gene to be read
- the backbone of DNA run in opposite 5’ → 3’ directions from each other, an arrangement referred to as antiparallel
- 5’ and 3’ come from which direction the carbons in the pentose sugar is pointing
- the strands are also complementary to each other → makes it possible to generate two identical copies of each DNA molecule in a cell preparing to divide
- RNA is single-stranded, meaning that it has more variable forms
- complementary pairing can also occur between two RNA molecules or between parts of the same molecule
- in RNA, thymine is replace with uracil (U)
Concept 5.6: Genomics and proteomics have transformed biological inquiry and applications
- once the structure of DNA and its relationship to amino acid sequence was understood, biologists sought to “decode” genes by learning their base sequences
- the first chemical techniques for DNA sequencing were developed in the 1970s and refined over the next 20 years
- it is enlightening to sequence the full complement of DNA in an organism’s genome
- the rapid development of faster and less expensive methods of sequencing was a side effect of the Human Genome Project
- Many genomes have been sequenced, generating large sets of data