
NotesSAA-C03
- The shared responsibility model
- Customer is responsible for security IN the loud
- AWS is responsible for security OF the cloud
- 6 Pillars of the Well-Architected Framework
- Operation Excellence
- Running and monitoring systems to deliver business value, and continually improving processes and procedures
- Performance Efficiency
- Using IT and computing resources efficiently
- Security
- Protecting info and systems
- Cost Optimization
- Avoiding unnecessary costs
- Reliability
- Ensuring a workload performs its intended function correctly and consistently
- Sustainability
- Minimizing the environmental impacts of running cloud workloads
- Operation Excellence
- IAM
- To secure the root account:
- Enable MFA on root acct
- Create an admin group for admins and assign appropriate privileges
- Create user accounts for admins - don't share
- Add appropriate users to admin groups
- IAM Policy documents
- JSON - key pairs
- IAM does not work at regional level, it works at global level
- Identity Providers > Federation Services
- AWS SSO
- Can add a provider/configure a provider
- Most common provider type is SAML
- Uses: AD Federation Services
- SAML provider establishes a trust between AWS and AD Federation Services
- Most common provider type is SAML
- IAM Federation
- Uses the SAML standard, which is Active Directory
- How to apply policies:
- EAR: Effect, Action, Resource
- Why are IAM users considered “permanent”?
- Because once their password, access key, or secret key is set, these credentials do not update or change without human interaction
- IAM Roles
- = an identity in IAM with specific permissions
- Temporary
- When you assume a role, it provides you with temporary security credential for your role session
- Assign policy to role
- More secure to use roles instead of credentials - don't have to hardcode credentials
- Preferred option from security perspective
- Can attach/detach roles to running EC2 instances without having to stop or terminate those instances
- To secure the root account:
- Simple Storage Solution
- S3 is object storage
- Manages data as objects rather than in file systems or data blocks
- Any type of file
- Cannot be used to run OS or DB, only static files
- Unlimited S3 storage
- Individual objects can be up to 5 TBs in size
- Universal Namespace
- All AWS accounts share S3 namespace so buckets must be globally unique
- S3 URLS:
- https://bucket-name.s3.Region.amazonaws.com/key-name
- When you successfully upload a file to an S3 bucket, you receive a HTTP 200 code
- S3 works off of a key-Value store
- Key = name of object
- Value = data itself
- Version id
- Metadata
- Lifecycle management
- Versioning
- All versions of an object are stored and can be retrieved, including deleted ones
- Once versioning is enabled, you cannot disable it, only suspend it
- Way to protect your objects from being accidentally deleted
- Turn versioning on
- Enable MFA
- Securing you S3 data
- Server-Side Encryption
- Can set default encryption on a bucket to encrypt all new objects when they are stored in that bucket
- Access Control Lists (ACLs)
- Define which AWS accounts or groups are granted access and type of access
- Way to get fine-grained access control - can assign ACLS to individual objects within a bucket
- Bucket Policies
- Bucket-wide policies that define what actions are allowed or denied on buckets
- In JSON format
- Server-Side Encryption
- Data Consistency Model with S3
- Strong Read-After-Write Consistency
- After a successful write of a new object (PUT) or an overwrite of an existing object, any subsequent read request immediately receives the latest version of the object
- Strong consistency for list operations, so after a write, you can immediately perform a listing of the objects in a bucket with all changes reflected
- Strong Read-After-Write Consistency
- ACLs vs Bucket Policies
- ACLs
- Work at an individual object level
- Ie: public or private object
- Bucket Policies
- Apply bucket-wide
- ACLs
- Storage Classes in S3
- S3 standard
- Default
- Redundantly across greater than or equal to 3 AZs
- Frequent access
- S3 Standard - Infrequently Accessed (IA)
- Infrequently accessed data, but data must be rapidly accessed when needed
- Pay to access data - per GB storage price and per-GB retrieval fee
- S3 One Zone - IA
- Like S3 standard IA but data is stored redundantly within single AZ
- Great for long-lived, IA NON critical data
- S3 Intelligent Tiering
- 2 Tiers:
- Frequent Access
- Infrequent Access
- Optimizes Costs - automatically moves data to most cost-effective tier
- 2 Tiers:
- Glacier
- Way of archiving your data long-term
- Pay for each time you access your data
- Cheap storage
- 3 Glacier options:
- Glacier Instant Retrieval
- S3 standard
- S3 is object storage
Long-term data archiving with instant retrieval
- Glacier Flexible Retrieval
Ideal storage class for archive data that does not require immediate access but needs the flexibility to retrieve large data sets at no cost,m such as backup or DR
Retrieval -minutes to 12 hours
- Glacier Deep Archive
Cheapest
Retain data sets for 7-10 years or longer to meet customer needs and regulatory requirements
Retrieval is 12 hours for standard and 48 hours for bulk
- Lifecycle mgmt in S3
- Automates moving objects between different storage tiers to max cost-effectiveness
- Can be used with versioning
- S3 Object Lock
- Can use object lock to store objects using a Write Once Read Many (WORM) model
- Can help prevent objects from being deleted or modified for a fixed amount of time OR indefinitely
- 2 modes of S3 Object Lock:
- Governance Mode
- Users cannot overwrite or delete an object version or alter its lock settings unless they have special permissions
- Compliance Mode
- A protected object version cannot be overwritten or deleted by any user
- When object is locked in compliance mode, its retention cannot be changed/object cannot be overwritten/deleted for duration of period
- Retention Period:
- Governance Mode
- Can use object lock to store objects using a Write Once Read Many (WORM) model
- Lifecycle mgmt in S3
Protect an object version for a fixed period of time
- Legal Holds:
Enables you to place a lock/hold on an object without an expiration period- remains in effect until removed
- Glacier Vault Locks
- Easily deploy and enforce compliance controls for individual Glacier vaults with a vault lock policy
- Can specify controls, such as WORM, in a vault lock policy and lock the policy from future edits
- Once locked, the policy can no longer be changed
- S3 Encryption
- TYpes of encryption available:
- Encryption in transit
- HTTPS-SSL/TLS
- Encryption at rest: Server Side Encryption
- Enabled by default with SSE-S3
- Encryption in transit
- TYpes of encryption available:
- Glacier Vault Locks
This setting applies to all objects within S3 buckets
If the file is to be encrypted at upload time, the x-amz-server-side-encryption parameter will be included in the request header
You can create a bucket policy that denies any s3 PUT (upload) that does not include this parameter in the request header
- 3 Types:
SSE-S3
S3-managed keys, using AES 256-bit encryption
Most common
SSE-KMS
AWS key mgmt service-managed keys
If you use SSE-KMS to encrypt you objects in S3, you must keep in mind the KMS region limits
Uploading AND downloading will count towards the limit
SSE-C
Customer-provided keys
- Encryption at rest: Client-Side Encryption
- You encrypt the files yourself before you upload them to S3
- Encryption at rest: Client-Side Encryption
- More folders/subfolder you have in S3, the better the performance
- S3 Performance:
- Uploads
- Multipart Uploads
- Recommended for files over 100 MB
- Required for files over 5GB
- = Parallelize uploads to increase efficiency
- Multipart Uploads
- Downloads
- S3 Byte-Range Fetches
- Parallelize downloads by specifying byte ranges
- If there is a failure in the download, it is only for that specific byte rance
- Used to speed up downloads
- Can be used to download partial amounts of a file - for ex: header info
- S3 Byte-Range Fetches
- Uploads
- S3 Replication
- Can replicate objects from one bucket to another
- Versioning MUST be enabled on both buckets (source and destination buckets)
- Turn on replication, then replication is automatic afterwards
- S3 Bach Replication
- Allows replication of existing objects to different buckets on demand
- Delete markers are NOT replicated by default
- Can enable it when creating the replication rule
- EC2: Elastic Cloud Compute
- Pricing Options
- On-Demand
- Pay by hour or second, depending on instance
- Flexible - low cost without upfront cost or commitment
- Use Cases:
- Apps with short-term, spikey, or unpredictable workloads that cannot be interrupted
- Compliance
- Licencing
- Reserved
- For 1-3 years
- Up to 72% discount compared to on-demand
- Use Cases:
- Predictable usage
- Specific capacity requirements
- Types of RIs:
- Standard RIs
- Convertible RIs
- On-Demand
- Pricing Options
Up to 54% off on-demand
You have the option to change to a different class of RI type of equal or greater value
- Scheduled RIs
Launch within timeframe you define
Match your capacity reservation to a predictable recurring schedule that only requires a fraction of day/wk/mo
- Reserved Instances operate at a REGIONAL level
- Spot
- Purchase unused capacity at a discount of up to 90%
- Prices fluctuate with supply and demand
- Say which price you want the capacity at and when it hits that price, you have your instance, when it moves away from that price, you lose it
- Use Cases:
- Flexible start and end times
- Cost sensitive
- Urgent need for large amounts of additional capacity
- Spot Fleet
- A collection of spot instances and (optionally) on-demand instances
- Attempts to launch that number of spot instances and on-demand instances to meet the target capacity you specified
It is fulfilled if there is available capacity and the max price you specified in the request exceeds the spot price
Launch pools - different details on when to launch
- 4 strategies with spot fleets available:
Capacity optimized
Spot instances come from the pool with optimal capacity for the number of instances launched
Diversified
Spot instances are distributed across all pools
Lowest price
Spot instances come from the pool with the lowest price
This is the default strategy
InstancePoolsToUseCount
Distributed across the number of spot instance pools you specify
This parameter is only valid when used in combo with lowestPrice
- Dedicated
- Physical EC2 server dedicated for your use
- Most expensive
- Dedicated
- Pricing Calculator
- Can use to estimate what your infrastructure will cost in AWS
- Bootstrap Scripts
- Script that runs when the instance first runs, has root privileges
- Starts with a shebang : #!/bin/bash
- EC2 Metadata
- Can use curl command in bootstrap to save metadata into a text file, for example
- Networking with EC2
- 3 different types of networking cards
- Elastic Network Interface (ENI)
- For basic, day-to-day networking
- Use cases:
- Elastic Network Interface (ENI)
- 3 different types of networking cards
Create a management network
Use network and security appliances in VPC
Create dual-homed instances with workloads and roles on distinct subnets
Create a low budget, HA solution
- EC2s by default will have ENI attached to it
- Enhanced Networking (EN)
- For single root I/O virtualization (SR-10V) to provide high performance
- For high performance networking between 10 Gbps-100 Gbps
- Types of EN
Elastic Network Adapter (ENA)
Supports network speeds of up to 100 Gbps for supported instance types
Intel 82599 Virtual Function (VF) Interfaces
Used in Older instances
Always choose ENA over VF
- Elastic Fabric Adapter (EFA)
- Accelerates High performance Computing (HPC) and ML apps
- Can also use OS-Bypass
- Elastic Fabric Adapter (EFA)
Enables HPC and ML apps to bypass the OS Kernal and communicate directly with the EFA device - only linux
- Optimizing EC2 with Placement Groups
- 3 types of placement groups
- Cluster Placement Groups
- Grouping of instances within a single AZ
- Recommended for apps that need low network latency, high network throughput or both
- Only certain instance types can be launched into a cluster PG
- Cannot span multiple AZs
- AWS recommends homogenous instances within cluster
- Spread Placement Group
- Each placed on distinct underlying hardware
- Recommended for apps that have small number of critical instances that should be kept separate
- Used for individual instances
- Can span multiple AZs
- Partition Placement Group
- Each partition PG has its own set of racks, each rack has its own network and power source
- No two partitions within PG share the same racks, allowing you to isolate impact of HW failure
- EC2 divides each group into logical segments called partitions (basically = a rack)
- Can span multiple AZs
- Cluster Placement Groups
- You can't merge PGs
- You can move an existing instance into a PG
- Must be in stopped state
- Has to be done via CLI or SDK
- 3 types of placement groups
- EC2 Hibernation
- When you hibernate an EC2 instance, the OS is told to perform suspend-to-disk
- Saves the contents from the instance memory (RAM)to your EBS root volume
- We persist the instance EBS root volume and any attached EBS data volumes
- Instance RAM must be less than 150GB
- Instance families include - C, M, and R instance families
- Available for Windows, Linux 2 AMI, Ubuntu
- Instances cannot be hibernated for more than 60 days
- Available for on-demand and reserved instances
- When you hibernate an EC2 instance, the OS is told to perform suspend-to-disk
- Deploying vCenter in AWS with VMWare Cloud on AWS
- Used by orgs for private cloud deployment
- Use Cases - why VMWare on AWS
- Hybrid Cloud
- Cloud Migration
- Disaster Recovery
- Leverage AWS Services
- AWS Outposts
- Brings the AWS data center directly to you, on-prem
- Allows you to have AWS services in your data center
- Benefits:
- Allows for hybrid cloud
- Fully managed by AWS
- Consistency
- Outposts Family members
- Outposts Racks - large
- Outposts Servers - smaller
- Optimizing EC2 with Placement Groups
- Elastic Block Storage
- Elastic Block Storage
- Virtual disk, storage volume you can attach to EC2 instances
- Can install all sorts, use like any system disk, including apps, OS’s, run DBs, store data, create file systems
- Designed for mission critical workloads - HA and auto replicated within single AZ
- Different EBS Volume Types
- General Purpose SSD
- gp2/3
- Balance of prices and performance
- Good for boot volumes and general apps
- Provisioned IOPS SSD (PIOPS)
- io1/2
- Super fast, high performance, most expensive
- IO intensive apps, high durability
- Throughput Optimized HDD (ST1)
- Low-cost HDD volume
- Frequently accessed, throughput-intensive workloads
- Throughput = used more for big data, data warehouses, ETL, and log processing
- Cost effective way to store mountains of data
- CANNOT be a boot volume
- Cold HDD (SC1)
- Lowest cost option
- Good choice for colder data requirement fewer scans/day
- Good for apps that need lowest cost and performance is not a factor
- CANNOT be a boot volume
- Only static images, file system
- General Purpose SSD
- IOPS vs Throughput
- IOPS
- Measures the number of read and write Operations/second
- Important for quick transactions, low-latency apps, transactional workloads
- Choose provisioned IOPS SSD (io1/2)
- Throughput
- Measures the number of bits read or written per sec (MB/s)
- Important metrics for large datasets, large IO sizes, complex queries
- Ability to deal with large datasets
- Choose throughput optimized HDD (ST1)
- IOPS
- Volumes vs Snapshots
- Volumes exist on EBS
- Must have a minimum of 1 volume per EC2 instance - called root device volume
- Snapshots exist on S3
- Point in time copy of a volume
- Are incremental
- For consistent snapshots: stop instance
- Can only share snapshots within region they were created, if want to share outside, have to copy to destination region first
- Volumes exist on EBS
- Things to know about EBS’s:
- Can resize on the fly, just resize the filesystem
- Can change volume types on the fly
- EBS will always be in the same AZ as EC2
- If we stop an instance, data is kept on EBS disk
- EBS volumes are NOT encrypted by default
- EBS Encryption
- Uses KMS customer master keys (CMK) when creating encrypted volumes and snapshots
- Data at rest is encrypted in volume
- Data inflight between instance and volume is encrypted
- All volumes created from the snapshot are encrypted
- End-to-end encryption
- Important to remember: copying an unencrypted snapshot allows encryption
- 4 steps to encrypt an unencrypted volume:
- Create a snapshot of the unencrypted volume
- Create a copy of the snapshot and select the encrypt option
- Create an AMI from the encrypted snapshot
- Use that AMI to launch new encrypted instances
- 4 steps to encrypt an unencrypted volume:
- Elastic Block Storage
- Elastic File System (EFS)
- Managed NFS (Network File System) that can be mounted on many EC2 instances
- Shared storage
- EFS are NAS files for EC2 instances based on Network File System (NFSv4)
- EC2 has a mount target that connects to the EFS
- Use Cases:
- Web server farms, content mgmt systems, shared db access
- Uses NFSv4 protocol
- Linux-Based AMIs only (not windows)
- Encryption at rest with KMS
- Performance
- Amazing performance capabilities
- 1000s concurrent connections
- 10 Gbps throughput
- Scales to petabytes
- Set the performance characteristics:
- General Purpose - web servers, content management
- Max I/O - big data, media processing
- Storage Tiers for EFS
- Standard - frequently accessed files
- Infrequently Accessed
- FSx For Windows
- Provides a fully managed native Microsoft Windows file system so you can easily move your windows-based apps that require file storage to AWS
- Built on Windows servers
- If see anything regarding:
- sharepoint service
- shared storage for windows
- Active directory migration
- Managed Windows Server that runs windows server message block (SMB) - based file services
- Supports AD users, ACLs, groups, and security policies, along with Distributed File System (DFS) namespaces and replication
- FSx for Lustre:
- Managed file system that is optimized for compute-intensive workloads
- Use Cases:
- High performance computing, AI, ML, Media Data processing workflows, electronic design automation
- With a Lustre, you can launch and run a Lustre file system that can process massive datasets at up to 100s of Gbps of throughput, millions of IOPS, and sub-millisec latencies
- When To pick EFS vs FSx for Windows vs FSx for Lustre
- EFS
- Need distributed, highly resilient storage for Linux
- FSx for Windows
- Central storage for windows (IIS server, AD, SQL Server, Sharepoint)
- FSx for Lustre
- High speed, high-capacity, AI, ML
- IMPORTANT: Can store data directly on S3
- EFS
- Amazon Machine Images: EBS vs Instance Store
- An AMI provides the info required to launch an instance
- *AMIs are region-specific
- 5 things you can base your AMIs on:
- Region
- OS
- Architecture (32 vs 64-bit)
- Launch permissions
- Storage for the root device (root volume)
- All AMIs are categorized as either backed by one of these:
- EBS
- The root device for an instance launched from the AMI is an EBS volume created from EBS snapshot
- CAN be stopped
- Will not lose data if instance is stopped
- By default, root volume will be deleted on termination, but you can tell AWS to keep the deleted root volume with EBS volume
- PERMANENT storage
- Instance Store
- Root device for an instance launched from the AMI is an instance store volume created from a template stored in S3
- Are ephemeral storage
- Meaning they cannot be stopped
- If underlying host fails, you will lose your data
- EBS
CAN reboot your data without losing your data
- If you delete your instance, you will lose the instance store volume
- AWS Backup
- Allows you to consolidate your backups across multiple AWS Services such as EC2, EBS, EFS, FSx for Lustre, FSx for Windows file server and AWS Storage Gateway
- Backups can be used with AWS Organizations to backup multiple AWS accounts in your org
- Gives you centralized control across all services, in multiple AWS accounts across the entire AWS org
- Benefits
- Central management
- Automation
- Improved Compliance
- Policies can be enforced, and encryption
- Auditing is easy
- Relational Database Service
- 6 different RDS engines
- SQL Server
- Oracle
- MySQL
- PostgreSQL
- MariaDB
- Aurora
- When to use RDS’s:
- Generally used for Online Transaction Processing (OLTP) workloads
- OLTP: transaction
- Large numbers of small transactions in real-time
- Different than OLAP (Online Analytical Processing)
- OLAP:
- OLTP: transaction
- Generally used for Online Transaction Processing (OLTP) workloads
- 6 different RDS engines
Processes complex queries to analyze historical data
All about data analysis using large amounts of data as well as complex queries that take a long time
RDS’s are NOT suitable for this purpose → data warehouse option like Redshift which is optimized for OLAP
- Multi-AZ RDSs
- Aurora cannot be single AZ
- All others can be configured to be multi-AZ
- Creates an exact copy of your prod db in another AZ, automatically
- When you write to your prod db, this write will automatically synchronize to the standard db
- Unplanned Failure or Maintenance:
- Amazon auto detects any issues and will auto failover to the standby db via updating DNS
- Multi-AZ is for DISASTER RECOVERY, not for performance
- CANNOT connect to standby db when primary db is active
- Aurora cannot be single AZ
- Increase read performance with read replicas
- Read replica is a read-only copy of the primary db
- You run queries against the read-only copy and not the primary db
- Read replicas are for PERFORMANCE boosting
- Each read replica has its own unique DNS endpoint
- Read replicas can be promoted as their own dbs, but it breaks the replication
- For analytics for example
- Multiple read replicas are supported = up to 5 to each db instance
- Read replicas require auto backups to be turned on
- Aurora
- MySQL and Postgre-compatible RD engine that combines speed and availability of high-end commercial dbs with the simplicity and cost-effectiveness of open-source db
- 2 copies of data in each AZ with minimum of 3 AZs → 6 copies of data
- Aurora storage is self-healing
- Data blocks and disks are continuously scanned for errors and repaired automatically
- 3 types of Aurora Replicas Available:
- Aurora Replicas = 15 read replicas
- MySQL Replicas = 5 read replicas with Aurora MySQL
- PostgreSQL = 5 read replicas with Aurora PostgreSQL
- Aurora Serverless
- An on-demand, auto-scaling configuration for the MySQL-compatible and PostgreSQL-compatible editions of Aurora
- An Aurora serverless db cluster automatically starts up, shuts down, and scales capacity up or down based on your app’s needs
- Use Cases:
- For spikey workloads
- Relatively simple, cost-effective option for infrequent, intermittent, or unpredictable workloads
- Multi-AZ RDSs
- DynamoDB
- Proprietary NON-relational DB
- Fast and flexible NoSQL db service for all applications that need constant, single-digit millisecond latency at any scale
- Fully managed db and supports both document and key-value data modules
- Use Cases:
- Flexible data model and reliable performance make it great fit for mobile, web, gaming, ad-tech, IoT, etc
- 4 facts on DynamoDB:
- All stored on SSD Storage
- Spread across 3 geographically distinct data center
- Eventually consistent reads by default
- This means that all copies of data is usually reached within a second. Repeating a read after a short time should return the updated data. Best read performance
- Can opt for strongly consistent reads
- This means that all copies return a result that reflects all writes that received a successful response prior to that read
- DynamoDB Accelerator (DAX)
- Fully managed, HA, in-memory cache
- 10x performance improvement
- Reduces request time from milliseconds to microseconds
- Compatible with DynamoDB API calls
- Sits in front of DynamoDB
- DynamoDB Security
- Encryption at rest with KMS
- Can connect with site-to-site VPN
- Can connect with Direct Connect (DX)
- Works with IAM policies and roles
- Fine-grained access
- Integrates with CloudWatch and CloudTrail
- VPC endpoints-compatible
- DynamoDB Transactions
- ACID Diagram/Methodology
- Atomic
- All changes to the data must be performed successfully or not at al
- Consistent
- Data must be in a constant state before and after the transaction
- Isolated
- No other process can change the data while the transaction is running
- Durable
- The changes made by a transaction must persist
- Atomic
- ACID basically means if anything fails, it all rolls back
- DynamoDB transactions provide developers ACID across 1 or more tables within a single aws acct and region
- You can use transactions when building apps that require coordinated inserts, deletes, or updates to multiple items as part of a single logical business operation
- DynamoDB transactions have to be enabled in DynamoDB to use ACID
- Use Cases:
- Financial Transactions, fulfilling orders
- 3 options for reads
- Eventual consistency
- Strong consistency
- Transactional
- 2 options for writes:
- Standard
- Transactional
- ACID Diagram/Methodology
- DynamoDB Backups
- On-Demand Backup and Restore
- Point-In-Time Recovery (PITR)
- Protects against accidental writes or deletes
- Restore to any point in the last 35 days
- Incremental backups
- NOT enabled by default
- Latest restorable: 5 minutes in the past
- DynamoDB Streams
- Are time-ordered sequence of item-level changes in a table (FIFO)
- Data is completely sequenced
- These sequences are stored in DynamoDB Streams
- Stored for 24 hours
- Sequences are broken up into shards
- A shard is a bunch of data that has sequential sequence numbers
- Everytime you make a change to DynamoDB table, that change is going to be stored sequentially in a stream record, which is broken up into shards
- Can combine streams with Lambda functions for functionality like stored procedures
- DynamoDB Global Tables
- Managed multi-master, multi-region replication
- Way of replicating your DynamoDB tables from one region to another
- Great for globally distributed apps
- This is based on DynamoDB streams
- Streams must be turned on to enable Global Tables
- Multi-region redundancy for disaster recovery or HA
- Natively built into DynamoDB
- Mongo-DB-compatible DBs in Amazon DocumentDB
- DocumentDB
- Allows you to run MongoDB in the AWS cloud
- A managed db service that scales with your workloads and safely and durably stores your db info
- NoSQL
- Direct move for MongoDB
- Cannot run Mongo workloads on DynamoDB so MUST use DocumentDB
- DocumentDB
- Amazon Keyspaces
- Run Apache Cassandra Workloads with Keyspaces
- Cassandra is a distributed (runs on many machines) database that uses NoSQL, primarily for big data solutions
- Keyspaces allows you to run cassandra workloads on AWS and is fully managed and serverless, auto-scaled
- Amazon Neptune
- Implement GraphDBs - stores nodes and relationships instead of tables or documents
- Amazon Quantum Ledger DB (QLDB)
- For Ledger DB
- Are NoSQL dbs that are immutable, transparent, and have a cryptographically verifiable transaction log that is owned by one authority
- QLDB is fully managed ledger db
- For Ledger DB
- Amazon Timestream
- Time-series data are data points that are logged over a series of time, allowing you to track your data
- A serverless, fully managed db service for time-series data
- Can analyze trillions of events/day up to 1000x faster and at 1/10th the cost of traditional RDSs
- Virtual Private Cloud (VPC) Networking
- VPC Overview
- Virtual data center in the cloud
- Logically isolated part of AWS cloud where you can define your own network with complete control of your virtual network
- Can additionally create a hardware VPN connection between your corporate data center and your VPC and leverage the AWS cloud as an extension of your corporate data center
- Attach a Virtual Private Gateway to our VPC to establish a VPN and connect to our instances over private corporate data center
- By default we have 1 VPC in each region
- What can we do with a VPC
- Use route table to configure between subnets
- Use Internet Gateway to create secure access to internet
- Use Network Access Control Lists (NACLs) to block specific IP addresses
- Default VPC
- User friendly
- All subnets in default VPC have a route out to the internet
- Each EC2 instance has a public and private IP address
- Has route table and NACL associated with it
- Custom VPC
- Steps to set up a VPC Connection:
- Choose IPv4 CIDER
- Note: first 4 IP addresses and last IP address in CIDR block are reserved by Amazon
- Choose Tenancy
- By default, creates:
- Security Group
- Route Table
- NACL
- Create subnet associations
- Create internet gateway and attach to VPC
- Set up route table with route out to internet
- Associate subnet with VPC
- Create Security group
- With inbound, outbound rules
- Associate EC2 instance with Security Group
- Choose IPv4 CIDER
- VPC Overview
- Using NAT Gateways for internet access within private subnet
- For example, we need to patch db server
- NAT Gateway:
- You can use Network Access Translation (NAT) gateway to enable instances in a private subnet to connect to the internet or other AWS services while preventing the internet from initiating a connection with those instances
- How to do this:
- Create a NAT Gateway in our public subnet
- Allow our EC2 instance (in private subnet) to connect to the NAT Gateway
- 5 facts to remember:
- Redundant inside the AZ
- Starts at 5 Gbps and scales to 45 Gbps
- No need to patch
- Not associated with any security groups
- Automatically assigned a public IP address
- Security Groups
- Are virtual firewalls for EC2 instances
- By default, everything is blocked
- Are stateful - this means that if you send a request from your instance, the response traffic for that request is allowed to flow in, regardless of inbound security group rules
- Ie: responses to allowed inbound traffic are allowed to flow out regardless of outbound rules
- Are virtual firewalls for EC2 instances
- Network ACLs
- Are frontline of defense, optional layer of security for your VPC that acts as a firewall for controlling traffic in and out of one or more subnets
- You may match NACL rules similar to Security Groups as an added layer of security
- Overview:
- Default NACLs
- VPC automatically comes with default NACL and by default it allows all inbound and outbound traffic
- Custom NACLs
- By default block all inbound and outbound traffic until you add rules
- Each subnet in your VPC must be associated with a NACL
- If you don't explicitly associate a subnet with a NACL, the subnet is auto associated with the default NACL
- Can associate a NACL with multiple subnets, but each subnet can only have a single NACL associated with it at a time
- Have separate inbound and outbound NACLs
- Default NACLs
- Block IP addresses with NACLs NOT with Security Groups
- NACLs contain a numbered list of rules that are evaluated in order, starting with lowest numbered rule
- Once a match is found, stop going through list
- If you want to deny a single IP address, you have to deny FIRST before you allow all
- NACLs are stateless
- This means that responses to allowed inbound traffic are subject to the rules for outbound traffic and visa versa
- NACLs contain a numbered list of rules that are evaluated in order, starting with lowest numbered rule
- VPC Endpoints
- Enables you to privately connect your VPC to supported AWS services and VPC endpoint services powered by PrivateLink without requiring an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection
- Like a NAT gateway but it doesnt use the public internet, it uses Amazon’s backbone network - stays within AWS environment
- Endpoints are virtual devices
- Horizontally scaled, redundant, and HA VPC components that allow communication between instances on your VPC and services without imposing availability risks or bandwidth constraints on your network traffic
- Remember that NAT gateways have 5-45 Gbps restriction - you dont want that restriction if you have an EC2 instance writing to S3, so you may have it go through the virtual endpoint (VPC endpoint)
- 2 Types of endpoints:
- Interface Endpoint
- An ENI with a private IP address that serves as an entry point for traffic headed to a supported service
- Gateway Endpoint
- Similar to NAT gateway
- Virtual device that supports connection to S3 and DynamoDB
- Interface Endpoint
- Use Case: you want to connect to AWS services without leaving the Amazon internal network = VPC endpoint
- VPC Peering
- Allows you to connect 1 VPC with another via a direct network route using private IP addresses
- Instances behave as if they were on the same private network
- Can peer VPCs with other AWS accounts as well as other VPCs in same account
- Can peer between regions
- Is in a star configuration with one central VPC
- No transitive peering
- Cannot have overlapping CIDR address ranges between peered VPCs
- Allows you to connect 1 VPC with another via a direct network route using private IP addresses
- PrivateLink
- Opening up your services in a VPC to another VPC can be done in two ways:
- Open VPC up to internet
- Use VPC Peering - whole network is accessible to peer
- Best way to expose a service VPC to tens, hundreds, thousands of customer VPC is through PrivateLink
- Does Not require peering, no route tables, no NAT gateways, no internet gateways, etc
- DOES require a Network Load Balancer on the service VPC and and ENI on the customer VPC
- Opening up your services in a VPC to another VPC can be done in two ways:
- CloudHub
- Useful if you have multiple sites, each with its own VPN connection, use CH to connect those sites together
- Overview:
- Hub and spoke model
- Low cost and easy to manage
- Operates over public internet, but all traffic between customer gateway and CloudHub is encrypted
- Essentially aggregating VPN connections to single entry point
- Direct Connect (DX)
- A cloud service solution that makes it easy to establish a dedicated network connection from your premises to AWS
- Private connectivity
- Can reduce network costs, increase bandwidth throughput, and provide a more consistent network experience than internet-based connections
- Instead of VPN
- Two types of Direct Connect Connections:
- Dedicated Connection
- Physical ethernet connection associated with a single customer
- Hosted Connection
- Physical ethernet connection that an AWS Direct Connect Partner (verizon, etc) provisions on behalf of a customer
- Dedicated Connection
- Transit Gateway
- Connects VPCs and on-prem networks through a central hub
- Simplifies network by ending complex peering relationships
- Acts as a cloud router - each connection is only made once
- Connect VPCs to Transit Gateway
- Everything connected to TG will be able to talk directly
- Facts
- Allows you to have transitive peering between thousands of VPCs and on-prem datacenters
- Works on regional basis, but can have it across multiple regions
- Can use it across multiple AWS account using RAM (Resource Access Manager)
- Use route table to limit how VPCs talk to one another
- Supports IP Multicast which is not supported by any other AWS Service
- Wavelength
- Embeds AWS compute and storage service within 5G networks, providing mobile edge computing infrastructure for developing, deploying, and scaling ultra-low-latency applications
- Route53
- Overview
- Domain Registrars: are authorities that can assign domain names directly under one or more top-level Domain
- Common DNS Record Types
- SOA: Start Of Authority Record
- Stores info about:
- Name of server that supplied the data for the zone
- Administrator of the zone
- Current version of the data file
- The default number of seconds for the TTL file on resource records
- How it works:
- Starts with NS (Name Server) records
- Stores info about:
- SOA: Start Of Authority Record
- Overview
NS records are used by top-level domain servers to direct traffic to the content DNS server that contains the authoritative DNS records
- So browser goes to top level domain first (.com) and will look up ‘ACG’,
- TLD will give the browser an NS record where the SOA will be stored
- Browser will browse over to the NS records and get SOA
- Start of Authority contains all of our DNS records
- A Record (or address record)
- The fundamental type of DNS record
- Used by a computer to translate the name of the domain to an IP address
- Most common type of DNS record
- TTL = time to live
- Length that a DNS record is cached on either the resolving server or the user’s own local PC
- The lower the TTL, the faster changes to DNS records take to propagate through the internet
- CNAME
- Canonical name can be used to resolve one domain name to another
- Ex m.acg.com and mobile.acg.com resolve to same
- Canonical name can be used to resolve one domain name to another
- Alias Records
- Used to map resource sets in your hosted zone to load balancers, CloudFront distros, or S3 buckets that are configured as websites
- Works like a CNAME record in that it can map one dns name to another, but
- CNAMES cannot be used for naked domain names/zone apex record
- Alias Records CAN be used to map naked domain names/zone apex record
- Route53 Overview
- Amazon’s DNS service, that allows you to register domain names, create hosted zones, and manage and create DNS records
- 7 Routing Policies available with Route53:
- Simple Routing Service
- Can only have one record with multiple IP addresses
- If you specify multiple values in a record, route53 returns all values to the user in a random order
- Weighted Routing Policy
- Allows you to split your traffic based on assigned weights
- Health Checks
- Simple Routing Service
Can set health checks on individual record sets/servers
So if a record set/server fails a health check, it will be removed from route53 until it passes the check
While it is down, no traffic will be routed to it, but will resume when it passes
- Create a health check for each weighted route that we are going to create to monitor the endpoint, monitor by IP address
- Failover Routing Policy
- When you want to create an active/passive setup
- Route53 will monitor the health of your primary site using health checks and auto-route traffic if primary site fails the check
- Geolocation Routing
- Lets you choose where your traffic will be sent based on the geographical location of your users
- Based on the location from which DNS queries originate; the end location of your user
- Geoproximity Routing Policy
- Can route traffic flow to build a routing system that uses a combo of:
Geographic location
Latency
Availability to route traffic from your users to your close or on-prem endpoints
- Can build from scratch or use templates and customize
- Latency Routing Policy
- Allows you to route your traffic based on the lowest network latency for your end user
- Create a latency resource record set for the EC2 (or ELB) resource in each region that hosts your website
When route53 receives a query for your site, it selects the latency resource record set for the region that gives you the lowest latency
- Multivalue Answer Routing Policy
- Lets you configure route53 to return multiple values, such as IP addresses for your web server, in response to DNS queries
- Basically similar to simple routing, however, it allows you to put health checks on each record set
- Multivalue Answer Routing Policy
- Elastic Load Balancers (ELBs)
- Auto distributes incoming traffic across multiple targets
- Can also be done across AZs
- 3 types of ELBs
- Application Load Balancer
- Best suited for balancing of HTTP and HTTPs Traffic
- Operates at layer 7
- Application-aware load balancer
- Intelligent load balancer
- Network Load Balancer
- Operates at the connection level (Level 4)
- Capable of handling millions of requests/sec, low latencies
- A performance load balancer
- Classic Load Balancer
- Legacy load balancer
- Can load balance HTTP/HTTPs applications and use Layer-7 specific features such as X-forwarded and sticky sessions
- For Test/Dev
- Application Load Balancer
- ELBs can be configured with Health Checks
- They periodically send requests to the load balancer’s registered instances to test their states [InService vs OutOfService returns]
- Application Load Balancers
- Layer 7, App-Aware Load Balancing
- After the load balancer receives a request, it evaluates the listener rules in priority order to determine which rule to apply and then selects a target from the target group for the rule action
- Listeners
- A listener checks for connection requests from clients when using the protocol and port you configure
- You define the rules that determine how the load balancer routes requests to its registered targets
- Each rule consists of priority, one or more actions, and one or more conditions
- Rules
- When conditions of rule are met, actions are performed
- Must define a default rule for each listener
- Target Group
- Each target group routes requests to one or more registered targets using the protocol and port you specify
- Path-Based Routing
- Enable path patterns to make load balancing decisions based on path
- /image → certain EC2 instance
- Limitations of App Load Balancers:
- Can ONLY support HTTP/HTTPS listeners
- Can enable sticky sessions with app load balancers, but traffic will be sent at the target group level, not specific EC2 instance
- Layer 7, App-Aware Load Balancing
- Network Load Balancer
- Layer 4, Connection layer
- Can handle millions of requests/sec
- When network load balancer has only unhealthy registered targets, it routes requests to ALL the registered targets - known as fail-open mode
- How it works
- Connection request received
- Load balancer selects a target from the target group for the default rule
- It attempts to open a TCP connection to the selected target on the port specified in the listener configuration
- Listeners
- A listener checks for connection requests from clients using the protocol and port you configure
- The listener on a network load balancer then forwards the request to the target group
- Connection request received
- Auto distributes incoming traffic across multiple targets
There are NO rules, unlike the Application load balancers - cannot do intelligent routing at level 4
- Target Groups
- Each target group routes requests to one or more registered targets
- Supported protocols: TCP, TLS, UDP, TCP_UDP
- Encryption
- You can use a TLS listener to offload the work of encryption and decryption to your load balancer
- Target Groups
- Use Cases:
- Best for load balancing TCP traffic when extreme performance is required
- Or if you need to use protocols that aren't supported by app load balancer
- Classic Load Balancer
- Legacy
- Can load balance HTTP/HTTPs apps and use Layer 7-spec features
- Can also use strict layer 4 load balancing for apps that rely purely on TCP protocol
- X-Forwarded-For Header
- When traffic is sent from a load balancer, the server access logs contain the IP address of the proxy or load balancer only
- To see the original IP address of the client the x-forwarded-for request header is used
- Gateway Timeouts with Classic load balancer
- If your application stops responding, the classic load balancer responds with a 504 error
- This means that the application is having issue
- Means the gateway has timed out
- If your application stops responding, the classic load balancer responds with a 504 error
- Sticky Sessions
- Typically the classic load balancer routes each request independently to the registered EC2 instance with smallest load
- But with sticky sessions enabled, user will be sent to the same EC2 instance
- Problem could occur if we remove one of our EC2 instances while the user still has a sticky session going
- Load balancer will still try to route our user to that EC2 instance and they will get an error
- To fix this, we have to disable sticky sessions
- Deregistration Delay
- Aka Connection Draining with Classic load balancers
- Allows load balancers to keep existing connections open if the EC2 instances are deregistered or become unhealthy
- Can disable this if you want your load balancer to immediately close connections
- CloudWatch
- Monitoring and observability platform to give us insight into our AWS architecture
- Features
- System metrics
- The more managed a service is, the more you get out of the box
- Application Metrics
- By installing CloudWatch agent, you can get info from inside your EC2 instances
- Alarms
- No default alarms
- Can create an alarm to stop, terminate, reboot, or recover EC2 instances
- System metrics
- 2 kinds of metrics:
- Default
- CPU util, network throughput
- Custom
- Will need to be provided with CloudWatch agent installed on the host and reported back to CloudWatch because AWS cannot see past the hypervisor level for EC2 instances
- Ex: EC2 memory util, EBS storage capacity
- Default
- Standard vs Detailed monitoring
- Standard/Basic monitoring for EC2 provides metrics for your instances every 5 minutes
- Detailed monitoring provides metrics every 1 minute
- A period is the length of time associated with a specific CloudWatch stat - default period is 60 seconds
- CloudWatch Logs
- Tool that allows you to monitor, store, and access log files from a variety of different sources
- Gives you the ability to query your logs to look for potential issues or relevant data
- Terms:
- Log Event: data point, contains timestamp and data
- Log Stream: collection of log events from a single source
- Log Group: collection of log streams
- Ex may group all Apache web server host logs
- Features:
- Filter Patterns
- CloudWatch Log Insights
- Allows you to query all your logs using SQL-like interactive solution
- Alarms
- What services act as a source for CloudWatch logs?
- EC2, Lambda, CloudTrend, RDS
- CloudWatch is our go-to log tool, except for if the exam asks for a real-time solution (then it will be kinesis)
- Amazon Managed Grafana
- Fully managed service that allows us to securely visualize our data for instantly querying, correlating, and visualizing your operational metrics, logs, and traces from different sources
- Overview
- Grafana made easy
- Logical separation with workspaces
- Workspaces are logical Grafana servers that allow for separation of data visualizations and querying
- Data Sources for Grafana: CloudWatch, Managed Service for Prometheus, OpenSearch Service, Timestream
- Use Cases:
- Container metrics visualizations
- Connect to data sources like Prometheus for visualizing EKS, ECS, or own Kube cluster metrics
- IoT
- Container metrics visualizations
- Amazon Managed Service for Prometheus
- Serverless, Prometheus-compatible service used for securely monitoring container metrics at scale
- Overview
- Still use open-source prometheus, but gives you AWS managed scaling and HA
- Auto Scaling
- HA- replicates data across three AZs in same region
- EKS and self-managed Kubernetes clusters
- PromQL: the open source query language for exploring and extracting data
- Data Retention:
- Data store in workspaces for 150 days, after that, deleted
- VPC Flow Logs
- Can configure to send to S3 bucket
- Horizontal and Vertical Scaling
- Launch Templates
- Specifies all of the needed settings that go into building out an EC2 instance
- More than just auto-scaling
- More granularity
- AWS recommends Launch templates over Configurations
- Configurations are only for auto-scaling, are immutable, limited configuration options, don't use them
- Create template for Auto Scaling Group
- Launch Templates
- Auto Scaling
- Auto Scaling Groups
- Contains a collection of EC2 instances that are treated as a collective group for the purposes of scaling and management
- What goes into auto scaling group?
- Define your template
- Pick from available launch templates or launch configurations
- Pick your networking and purchasing
- Pick networking space and purchasing options
- ELB configuration
- ELB sits in front of auto scaling group
- EC2 instances are registered behind a load balancer
- Auto scaling can be set to respect the load balancer health checks
- Set Scaling policies
- Min/Max/Desired capacity
- Notifications
- SNS can act as notification tool, alert when a scaling event occurs
- Define your template
- Step Scaling Policies
- Increase or decrease the current capacity of a scalable target based on scaling adjustments, known as step adjustments
- Adjustments vary based on the size of the alarm breach
- All alarms that are breached are evaluated by application auto scaling
- Instance Warm-Up and Cooldown
- Warm-up period - time for EC2s to come up before being placed behind LB
- Cooldown - pauses auto scaling for a set amount of time (default is 5 minutes)
- Warmup and cooldown help to avoid thrashing
- Scaling types
- Reactive Scaling
- Once the load is there, you measure it and then determine if you need to create more or less resources
- Respond to data points in real-time, react
- Scheduled Scaling
- Predictable workload, create a scaling event to handle
- Predictive Scaling
- AWS uses ML algorithms to determine
- They are reevaluated every 24 hours to create a forecast for the next 48
- Reactive Scaling
- Steady Scaling
- Allows us to create a situation where the failure of a legacy codebase or resource that cant be scaled down can auto recover from failure
- Set Min/Max/Desired = 1
- CloudWatch is your number one tool for alerting auto scaling that you need more or less of something
- Scaling Relational DBs
- Most scaling options
- 4 ways to scale Relational DBs/4 types of scaling we can use to adjust our RD performance
- Vertical Scaling
- Resizing the db from one size to another, can create greater performance, increase power
- Scaling Storage
- Storage can be resized up, not down
- Except aurora which auto scales
- Read Replicas
- Way to scale “horizontally” - create read only copies of our data
- Aurora Serverless
- Can offload scaling to AWS - excels with unpredictable workloads
- Vertical Scaling
- Scaling Non Relational DBs
- DynamoDB
- AWS managed - simplified
- Provisioned Model
- Use case: predictable workload
- Need to overview past usage to predict and set limits
- Most cost effective
- On-Demand
- Use case: sporadic workload
- Pay more
- Can switch from on-demand to provisioned only once per 24 hours per table
- Non-Relational DB scaling
- Access patterns
- Design matters
- Avoiding hot keys will lead to better performance
- DynamoDB
- Auto Scaling Groups
- Simple Queue Service (SQS)
- Fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless apps
- Can sit between frontend and backend and kind of replace the Load Balancer
- Web front end dumps messages into the queue and then backend resources can poll that queue looking for that data whenever it is ready
- Does not require that active connection that the load balancer requires
- Poll-Based Messaging
- We have a producer of messages, consumer comes and gets message when ready
- Messaging queue that allows asynchronous processing or work
- SQS Settings
- Delivery Delay - default 0, up to 15 minutes
- Message Size - up to 256 KB text in any format
- Encryption - encrypted in transit by default, now added encryption at rest default with SSE-SQS
- SSE-SQS = Server-Side Encryption using SQS-owned encryption
- Encryption at rest using the default SSE-SQS is supported at no charge for both standard and FIFO using HTTPS endpoints
- SSE-SQS = Server-Side Encryption using SQS-owned encryption
- Message Retention
- Default retention is 4 days, can be set from 1 minute - 14 days, then purged
- Long vs Short Polling
- Long polling is not the default, but should be
- Short Polling
- Connect, checks if work, immediately disconnects if no work
- Burns CPU, additional API calls cost money
- Long Polling
- Connect, check if work, waits a bit
- Mostly will be the right answer
- Queue Depth
- This value can be a trigger for auto scaling
- Visibility Timeout
- Used to ensure proper handling of the message by backend EC2 instances
- Backend polls for the message, sees it, downloads that message from SQS to do work - after backend downloads message, SQS puts a lock on that message called the visibility timeout, where the message remains in the queue but no one else can see it
- So if other instances are polling that queue, the will not see the locked message
- Default visibility timeout is 30 seconds, but can be changed
- If that EC2 instance that downloaded the message fails to process that message and reach out to the queue to tell SQS that it is done, and tells it to purge that message, that message is going to reappear in the queue
- Dead-Letter Queues
- If there is a problem with the message, if the message cannot be processed by our backend process and we did not implement DLQ - the message would get pulled by a backend EC2 for processing, the EC2 would have an error processing it, so we would hit our 30 sec visibility timeout. So, the message would unlock, another EC2 would pick it up, etc, etc, until we hit our message retention period, then that message would be deleted
- By implementing DLQ: we create another SQS Queue that we can temporarily sideline messages into
- How it works:
- Set up a new queue and select it as the DLQ when setting up the primary SQS queue
- Set a number for retries in the primary queue
Once the message hits that limit, it gets moved to the DLW where it stays until message retention period, then deleted
- Can create SQS DLQ for SNS topics
- SQS FIFO
- Standard SQS offers best effort ordering and tries not to duplicate, but may - nearly unlimited transactions/sec
- SQS FIFO guarantees the order and that no duplication will occur
- Limited to 300 messages/sec
- How it works:
- Message group ID field is a tag that specifies that a message belongs to a specific message group
- Message Deduplication ID is the token used to ensure no duplication within the deduplication interval: a unique value that ensures that your messages are unique
- More expensive than standard SQS
- Simple Notification Service (SNS)
- Used to push out notifications - proactively deliver the notification to an end-point rather than leaving it in a queue
- Fully managed messaging service for both application-to-application (A2A) and application-to-person (A2P) communication
- Texts and emails to users
- Push-Based Messaging
- Consumer does not have control to receive when ready, the sender sends it all the way to the consumer
- Will proactively deliver messages to the endpoints that are Subscribed to it
- SNS topics are subscribed to
- SNS Settings
- Subscribers
- what/who is going to receive the data from the topic
- Ex: Kinesis firehose, SQS, Lambda, email, HTTP(S), etc
- what/who is going to receive the data from the topic
- Message Size
- Max size of 256 text in any format
- SNS does not retry, even if they fail to deliver
- Can store in an SQS DLQ to handle
- SNS FIFO only supports SQS as a subscriber
- Messages are encrypted in transit by default, and you can add encryption at rest
- Access Policies
- Can control who/what can publish to those SNS topics
- A resource policy can be added to a topic, similar to S3
- Have to make sure AP is set up properly with SNS to SQS so that SNS can have access to SQS Queue
- Subscribers
- CloudWatch uses SNS to deliver alarms
- API Gateway
- Fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale
- “Front-door” to our apps so we can control what users talk to our resources
- Key features:
- Security
- Add security- one of the main reasons for using API Gateway in front of our applications
- Allows you to easily protect your endpoints by attaching a WAF; Can front API Gateway with a WAF - security at the edge
- Stop Abuse
- Set up rate limiting, DDoS protection
- Static stuff to S3, basically everything else to API Gateway
- Security
- Preferred method is to get API calls into your application and AWS environment
- Avoid hardcoding our access keys/secret keys with API Gateway
- Do not have to generate an IAM user to make calls to the backend, just send API call to API Gateway in front
- API Gateway is versioning supported
- AWS Batch
- AWS Managed service that allows us to run batch computing workloads within AWS- these workloads run on either EC2 or Fargate/ECS
- Capable of provisioning accurately sized compute resources based on number of jobs submitted and optimizes the distribution of workloads
- Removes any heavy lifting for configuration and management of infrastructure required for computing
- Components:
- Jobs = units of work that are submitted to Batch (ie: shell scripts, executables, docker images)
- Job Definitions = specify how your jobs are to be run, essentially the blueprint for the resources in the job
- Job Queues = jobs get submitted to specific queues and reside there until scheduled to run in a compute environment
- Compute Environment = set of managed or unmanaged compute resources used to run your jobs (EC2 or ECS/Fargate)
- Fargate or EC2 Compute Environments
- Fargate is the recommended way of launching most batch jobs
- Scales and matches your needs with less likelihood of over provisioning
- EC2 is sometimes the best choice, though:
- When you need a custom AMI (can only be run via EC2)
- When you have high vCPU requirements
- When you have high GiB requirements
- Need GPU or Graviton CPU requirement
- When you need to use linusParameters parameter field
- When you have a large number of jobs, best to run on EC2 because jobs are dispatched at a higher rate than Fargate
- Fargate is the recommended way of launching most batch jobs
- Batch vs Lambda
- Lambda has a 15 minute execution time limit, batch does not
- Lambda has limited disk space
- Lambda has limited runtimes, batch uses docker so any runtime can be used
- AWS Managed service that allows us to run batch computing workloads within AWS- these workloads run on either EC2 or Fargate/ECS
- Amazon MQ
- Managed message broker service allowing easier migration of existing applications to the AWS Cloud
- Makes it easy for users to migrate to a message broker in the cloud from an existing application
- Can use a variety of programming languages, OS’s, and messaging protocols
- MQ Engine types:
- Currently supports both Apache ActiveMQ or RabbitMQ engine types
- SNS with SQS vs AmazonMQ
- Both have topics and queues
- Both allow for one-to-one or one-to-many messaging designs
- MQ is easy application migration: so if you are migrating an existing application, likely want MQ
- If you are starting with new Application - easier and better to use SNS with SQS
- AmazonMQ requires that you have private networking like VPC, Direct Connect, or VPN while SNS and SQS are publicly accessible by default
- MQ has NO default AWS integrations and does not integrate as easily with other services
- Both have topics and queues
- Configuring Brokers
- Single_Instance Broker
- One broker lives within one AZ
- RabbitMQ has a network load balancer in front in a single instance broker environment
- MQ Brokers
- Offers HA architectures to minimize downtime during maintenance
- Architecture depends on broker engine type
- AmazonMQ for Apache ActiveMQ
- With active/standby deployments, one instance will remain available at all times
- Configure network of brokers with separate maintenance windows
- AmazonMQ for RabbitMQ
- Cluster deployment are logical groupings of three broker nodes across multiple AZs sitting behind a Network LB
- MQ is good for specific messaging protocols: JMS or messaging protocols like AMQP0-9-1, AMQP 1.0, MQTT, OpenWire, and STOMP
- Single_Instance Broker
- AWS Step Functions
- A serverless orchestration service combining different AWS services for business applications
- Provides a graphical console for easier application workflow views and flows
- Components
- State Machine: a particular workflow with different event-driven steps
- Tasks: specific states within a workflow (state machine) representing a single unit of work
- States: every single step within a workflow = a state
- Two different types of workflows with Step Functions:
- Standard
- Exactly-once execution
- Can run for up to 1 year
- Useful for long-running workflows that need to have auditable history
- Rates up to 2000 executions/sec
- Pricing based per state transition
- Express
- Have an ‘at-least-once’ execution → means possible duplication you have to handle
- Only run for up to 5 minutes
- Useful for high-event-rate workloads
- Use Case: IoT data streaming
- Pricing based on number of executions, durations, and memory consumed
- Standard
- States and State Machines
- Individual states are flexible
- Leverage states to either make decisions based on input, perform certain actions, or pass input
- Amazon States Language (ASL)
- States and workflows are defined in ASL
- States are elements within your state machines
- States are referred to by name, name in unique within workflow
- Individual states are flexible
- Integrates with Lambda, Batch, Dynamo, SNS, Fargate, API Gateway, etc
- Different States that exist:
- Pass - no work
- Task - single unit of work performed
- Choice - adds branching logic to state machines
- Wait - time delay
- Succeed - stops executions successfully
- Fail - stops executions and mark as failures
- Parallel - runs parallel branches of executions within state machines
- Map - runs a set of steps based on elements of an input array
- Amazon AppFlow
- Fully managed service that allows us to securely exchange data between a SaaS App and AWS
- Ex: Salesforce migrating data to S3
- Entire purpose is to ingest data
- Pulls data records from third-party SaaS vendors and stores them in S3
- Bi-directional: allows for bi-directional data transfers with some combinations of source and destination
- Concepts:
- Flow: transfer data between sources and destinations
- Data Mapping: determines how your source data is stored within your destination
- Filters: criteria set to control which data is transferred
- Trigger: determines how the flow is started
- Multiple options/supported types:
- Run on demand
- Run on event
- Run on schedule
- Multiple options/supported types:
- Fully managed service that allows us to securely exchange data between a SaaS App and AWS
- Redshift Databases
- Fully managed, petabyte-scale data warehouse service in the cloud
- Very large relational db traditionally used in big data
- Because it is relational, you can use standard SQL and BI tools to interact with it
- Best use is for BI applications
- Can store massive amounts of data - up to 16 PB of data
- Means you do not have to split up your large datasets
- Not a replacement for a traditional RDS - it would fall apart as the backend of your web app, for example
- Elastic Map Reduce (EMR)
- ETL tool
- Managed big data platform that allows you to process vast amounts of data using open-source tools, such as Spark, Hive, HBase, Flink, Hudi, and Presto
- Quickly use open source tools and get them running in our environment
- For this exam, EMR will be run on EC2 instances and you pick the open-source tool for AWS to manage on them
- Open-source cluster, managed fleet of EC2 instances running open-source tools
- Amazon Kinesis
- Allows you to ingest, process, and analyze real-time streaming data
- 2 forms of Kinesis:
- Data Streams
- Real-time streaming for ingesting data
- You are responsible for creating the consumer and scaling the stream
- Process for Kinesis Data Streams:
- Producers creating data
- Connect producers to Data Stream
- Decide how many shards you are going to create
- Data Streams
Shards can only handle a certain amount of data
- Consumer takes data in, processes it, and puts it into endpoints
You have to create the consumer
Endpoint could be S3, Dynamo, Redshift, EMR, …
You have to use the Kinesis SDK to build the consumer application
Handle scaling with the amount of shards
- Data Firehose
- Data transfer tool to get info into S3, Redshift, ElasticSearch, or Splunk
- Near-real-time
- Plug and play with AWS architecture
- Process for Kinesis Data Firehose:
- Limited supported endpoints- ElasticSearch service, S3, and Redshift, some 3rd party endpoints supported as well
- Place Data Firehose in between input and endpoint
- Handles the scaling and the building out of the consumer
- Data Firehose
- Kinesis Data Analytics
- Paired with Data Stream/Firehose, it does the analysis using standard SQL
- Makes it easy to tie Data Analytics into your pipeline
- Data comes in with Streams/Firehose and Data Analytics can transform/sanitize/format data in real-time as it gets pushed through
- Serverless, fully managed, auto scaling
- Kinesis vs SQS
- SQS does NOT provide real-time message delivery
- Kinese DOES provide real-time message delivery
- Amazon Athena
- An interactive query that makes it easy to analyze data in S3 using SQL
- Allows you to directly query data in your S3 buckets without loading it into a database
- “Serverless SQL”
- Can use Athena to query logs stored in S3
- Amazon Glue
- A serverless data ingestion service that makes it easy to discover, prepare, and combine data
- Allows you to perform ETL workloads without managing underlying servers
- Effectively replaces EMR - and with Glue, you don't have to spin up EC2 instances or use 3rd party tools to ETL
- Using Athena and Glue together:
- AWS S3 data is unstructured, unformatted – deploy Glue Crawlers to build a catalog/structure for that data
- Glue produces Data Catalog
- After glue, we have some options:
- Can use Amazon Redshift Spectrum - allows us to use Redshift without having to load data into Redshift db
- Athena - use to query the data catalog, and can even use Quicksight to visualize data
- AWS S3 data is unstructured, unformatted – deploy Glue Crawlers to build a catalog/structure for that data
- Amazon QuickSight
- Amazon's version of Tableau
- Fully managed BI data visualization service, easily create dashboards
- AWS Data Pipeline
- A managed ETL service for automating management and transformation of your data, automatic retries for data-driven workflow
- Data driven web-service that allows you to define data-driven workflows
- Steps are dependent on previous tasks completing successfully
- Define parameters for data transformations - enforces your chosen logic
- Auto retries failed attempts
- Configure notifications via SNS
- Integrates easily with Dynamo, Redshift, RDS, S3 for data storage, and integrates with EC2 and EMR for compute needs
- Components:
- Pipeline Definition = specify the logic of you data management
- Managed Compute = service will create EC2 instances to perform your activities or leverage existing EC2
- Task Runners = (EC2) poll for different tasks and perform them when found
- Data Nodes= define the locations and types of data that will be input and output
- Activities = pipeline components that define the work to perform
- Use Cases:
- Processing data in EMR using Hadoop streaming
- Importing or exporting DynamoDB data
- Copying CSV files or data between S3 buckets
- Exporting RDS data to S3
- Copying data to Redshift
- Amazon Managed Streaming for Apache Kafka (Amazon MSK)
- Fully managed service for running data streaming apps that leverage Apache Kafka
- Provides control-plane operations; creates, updates, and deletes clusters as required
- Can leverage the Kafka data-plane operations for production and consuming streaming data
- Good for existing operations; allows support for existing apps, tools, and plugins
- Components:
- Broker Nodes
- Specify the amount of broker nodes per AZ you want at time of cluster creation
- Zookeeper Nodes
- Created for you
- Producers, Consumers, and Topics
- Kafka data-plane operations allow creation of topics and ability to produce/consume data
- Flexible Cluster Operations
- Perform cluster operations with the console, AWS CLI, or APIs within any SDK
- Broker Nodes
- Resiliency in AmazonMSK:
- Auto Recovery
- Detected broker failures result in mitigation or replacement of unhealthy nodes
- Tries to reduce storage from other brokers during failures to reduce data needing replication
- Impact time is limited to however long it takes MSK to complete detection and recovery
- After successful recovery, producer and consumer apps continue to communicate with the same IP as before
- Features:
- MSK Serverless
- Cluster type within AmazonMSK offering serverless cluster management - auto provisioning and scaling
- Fully compatible with Apache Kafka - use the same client apps for prod/cons data
- MSK Connect
- Allows developers to easily stream data to and from Apache Kafka clusters
- MSK Serverless
- Security
- Integrates with Amazon KMS for SSE requirements
- Will always encrypt data at rest by default
- TLS1.2 by default in transit between brokers in clusters
- Logging
- Broker logs can be delivered to services like CloudWatch, S3, Data Firehose
- By default, metrics are gathered and sent to CloudWatch
- MSK API calls are logged to CloudFront
- Amazon OpenSearch Service
- Managed service allowing you to run search and analytics engines for various use cases
- It is the successor to Amazon ElasticSearch Service
- Features:
- Allows you to perform quick analysis - quickly ingest, search, and analyze data in your clusters - commonly a part of an ETL process
- Easily scale cluster infrastructure running the OpenSearch services
- Security: leverage IAM for access control, VPC security groups, encryption at rest and in transit, and field-level security
- Multi-AZ capable service with Master nodes and automated snapshots
- Allows for SQL support for BI apps
- Integrates with CloudWatch, CloudTrail, S3, Kinesis - can set log streams to OpenSearch Service
- Logging solution involving creating visualization of log file analytics or BI tools/imports
- Serverless Overview
- Benefits
- Easy of use: we bring code, AWS handles everything else
- Event-Based: can be brought online in response to an event then go back offline
- True “pay for what you use” architecture: pay for provisioned resources and the length of runtime
- Example serverless services: Lambda, Fargate
- Benefits
- Lambda
- Serverless compute service that lets you run code without provisioning or managing the underlying server
- How to build a lambda function:
- Runtime selection: pick from an available run-time or bring your own. This is the environment your code will run in
- Set permissions: if your lambda function needs to make an API call in AWS, you need to attach a role
- Networking definitions: optionally, you can define the VPC, subnet, and security groups your functions are a part of
- Resource definitions: define the amount of available memory will allocate how much CPU and RAM your code gets
- Define Trigger: select what is going to kick off your lambda function to start
- Lambda has built-in logging and monitoring using CloudWatch
- AWS Serverless Application Repository
- Serverless App Repository
- Service that makes it easy for users to easily find, deploy, or even publish their own serverless apps
- Can share privately within organization or publicly
- How it works:
- You upload your application code and a Manifest File
- Manifest File: is known as the Serverless Application Model (SAM) Template
- SAM templates are basically CloudFormation templates
- You upload your application code and a Manifest File
- Deeply integrated with the AWS lambda service - actually appears in the console
- 2 Options in Serverless App Repository:
- Publish: define apps with the SAM templates and make them available for others to find and deploy
- When you first publish your app, it is set to private by default
- Deploy: find and deploy published apps
- Publish: define apps with the SAM templates and make them available for others to find and deploy
- Serverless App Repository
- Container Overview
- Container
- Standard unit of software that packages up code and all its dependencies
- Terms:
- Docker File: text document that contains all the commands or instructions that will be used to build an image
- Image: Docker files build images, immutable file that contains the code, libraries, dependencies, and configuration files needed to build an app
- Registry: like GitHub for images, stores docker images for distribution
- Container: a running copy of image
- ECS: Elastic Container Service
- Management of containers at scale
- Integrates natively with ELB
- Easy integration with roles to get permissions for containers - containers can have individual roles attached to them
- ECS only works in AWS
- EKS: Elastic Kubernetes Service
- Kubernetes: open source container manager, can be used on-prem and in the cloud
- EKS is the AWS-managed version
- ECS vs EKS
- ECS - simple, easy to integrate, but it does not work on-prem
- EKS - flexible, works in cloud and on-prem, but it is more work to configure and integrate with AWS
- Fargate
- Serverless compute engine for containers that works with both ECS and EKS (requires one of them)
- EC2 vs Fargate for container management
- If you use EC2:
- You are responsible for underlying OS
- Can better deal with long-running containers
- Multiple containers can share the same host
- If you use Fargate:
- No OS access - don’t have to manage
- Pay based on resources allocated and time run
- Better for short-running tasks
- Isolated environments
- If you use EC2:
- Fargate vs Lambda
- Use fargate when you have more consistent workloads, allows for docker use across the organization and a greater level of control for developers
- Use lambda when you have unpredictable or inconsistent workloads, use for applications that can be expressed as a single function (lambda function responds to event and shuts down)
- Container
- EventBridge (formerly known as CloudWatch Events)
- Serverless event bus, allows you to pass events from a server to an endpoint
- Essentially the glue that holds your serverless apps together
- Creating an EventBridge Rule:
- Define Pattern: scheduled/invoked/etc?
- Select Event Bus: AWS-based event/Custom event/Partner event?
- Select your target: what happens when this event kicks off?
- Remember to tag it
- Remember:
- EventBridge is the glue - it triggers an action based on some event in AWS, holds together a serverless application and Lambda functions
- An API call in AWS can alert a variety of endpoints
- EventBridge is the glue - it triggers an action based on some event in AWS, holds together a serverless application and Lambda functions
- Serverless event bus, allows you to pass events from a server to an endpoint
- Amazon Elastic Container Registry (ECR)
- AWS-managed container image registry that offers secure, scalable, and reliable infrastructure
- Private container image repositories with resources-based permissions via IAM
- Supported formats include: Open Container Initiative (OCI) images, docker images, and OCI artifact
- Components:
- Registry
- A private registry provided to each AWS account, regional
- Can create one or more registries for image storage
- Authentication Token
- Required for pushing/pulling images to/from registries
- Repository
- Contains all of your Docker Images, OCI Images, and Artifacts
- Repository Policy
- Control all access to repository and images
- Image
- Container images that get pushed to and pulled from your repositories
- Registry
- Amazon ECR Public is a similar service for public image repository
- Features:
- Lifecycle policies
- Helps management of images in your repository
- Defines rules for cleaning up unused images
- It does give you the ability to test your rules before applying them to repository
- Image Scanning
- Helps identify software vulnerabilities in your container images
- Repositories can be set to scan on push
- Retrieve results of scans for each image
- Sharing
- Cross-Region Support
- Cross-Account support
- Both are configured per repository and per region > each registry is regional for each account
- Cache Rules
- Pull through cache rules allow for caching public repositories privately
- ECR periodically reaches out to check current caching status
- Tag Mutability
- Prevents image tags from being overwritten
- Configure this setting per repository
- Lifecycle policies
- Service Integrations:
- Bring your own containers - can integrate with your own container infrastructure
- ECS - use container images in ECS container definitions
- EKS - pull images from EKS clusters
- Amazon Linux Containers - can be used locally for your software development
- EKS Distro
- EKS Distro aka EKS-D
- Kubernetes distribution based on and used by Amazon EKS
- Same versions and dependencies deployed by EKS
- EKS-D is fully your responsibility, fully managed by you, unlike EKS
- Can run EKS-D anywhere, on-prem, cloud, etc
- EKS Distro aka EKS-D
- EKS Anywhere and ECS Anywhere
- EKS Anywhere
- An on-prem way to manage Kubernetes clusters with the same practices used in EKS, with these clusters on-prem
- Based on EKS-Distro allows for deployment, usage, and management methods for clusters in data centers
- Can use lifecycle management of multiple kubernetes clusters and operate independently of AWS Services
- Concepts:
- Kubernetes control plane management operated completely by customer
- Control plane location within customer center
- Updates are done entirely via manual CLI or Flux
- ECS Anywhere
- Feature of ECS allowing the management of container-based apps on-prem
- No orchestration needed: no need to install and operate local container orchestration software, meaning more operational efficiency
- Completely managed solution enabling standardization of container management across environment
- Inbound Traffic
- No ELB support - customer managed, on-prem
- EXTERNAL = new launch type noted as ‘EXTERNAL’ for creating services or running tasks
- Requirements for ECS Anywhere:
- On local server, must have the following installed:
- SSM Agent
- ESC Agent
- Docker
- Must first register external instances as SSM Managed Instances
- Can easily create an installation script within ECS console to run on your instances
- Scripts contain SSM activation keys and commands for required software
- On local server, must have the following installed:
- EKS Anywhere
- Auto Scaling DBs on Demand with Aurora Serverless
- Aurora Provisioned vs Aurora Serverless
- Provisioned is typical Aurora service
- Aurora Serverless
- On-demand and Auto Scaling configuration for Aurora db service
- Automation of monitoring workloads and adjusting capacity for dbs
- Based on demand - capacity adjusted
- Billed per-second only for resources consumed by db clusters
- Concepts for Aurora Serverless
- Aurora Capacity Units (ACUs) = a measurement on how your clusters scale
- Set minimum and maximum of ACUs for scaling → can be 0
- Allocate quickly by AWS managed warm pools
- Combo of 2 GiB of memory, matching CPU and networking
- Same data resiliency as provisioned - 6 copies of data across 3 AZs
- Use Cases:
- Variable workloads
- Multi-tenant apps - let the service manage db capacity for each individual app
- New apps
- Dev and Test
- Mixed-Use Apps: apps that might serve more than one purpose with different traffic spikes
- Capacity planning: easily swap from provisioned to serverless or vise-versa
- Aurora Provisioned vs Aurora Serverless
- Amazon X-Ray
- Application Insights - collects application data for viewing, filtering, and gaining insights about requests and responses
- View calls to downstream AWS resources and other microservices/APIs or dbs
- Receives traces from your applications for allowing insights
- Integrated services can add tracing headers, send trace data, or run the X-Ray daemon
- Concepts:
- Segments: data containing resource names, request details, etc
- Subsegments: segments providing more granular timing info and data
- Service graph: graphical representation of interacting services in requests
- Traces: trace ID tracks paths of requests and traces collect all segments in a request
- Tracing Header: extra HTTP header containing sampling decisions and trace ID
- Tracing header continuing added info is named: X-Amzn-Trace-ID
- X-Ray Daemon
- AWS Software application that listens on UDP port 2000. It collects raw segment data and sends it to the X-Ray API
- When daemon is running, it works alongside the X-Ray SDK
- Integrations:
- EC2- installed, running agent
- ECS- installed within tasks
- Lambda- on/off toggle, built-in/available for functions
- Beanstalk- a configuration option
- API Gateway- can add to stages as desired
- SNS and SQS- view time taken for messages in queues within topics
- GraphQL interfaces in AppSync
- AppSync
- Robust, scalable GraphQL interface for app developers
- Combines data from multiple sources
- Enables interaction for developers via GraphQL, which is a data language that enables apps to fetch data from servers
- Seamless integration with React, ReactNative, iOS, and Android
- Especially used for fetching app data, declarative coding, and frontend app data fetching
- AppSync
- Layer 4 DDoS Attacks aka SYN flood
- Work at the transport layer
- How it works:
- SYN flood overwhelms the server by sending a large number of SYN packets and then ignoring the SYN-ACKs returned by the server
- Causes the server to use up resources waiting for a set amount of time for the ACK
- There are only so many concurrent TCP connections that a web app server can have open - so attacker could take all the allowed connections causing the server to not be able to respond to legitimate traffic
- SYN flood overwhelms the server by sending a large number of SYN packets and then ignoring the SYN-ACKs returned by the server
- Amplification Attacks aka Reflection Attacks
- When an attacker may send a third party server (such as an NTP server) a request using a spoofed IP address. That server will then respond to that request with a greater payload than the initial request (28-54 xs larger) to the spoofed IP
- Attackers can coordinate this and use multiple NTP servers a second to send legitimate NTP traffic to the target
- Include things such as NTP, SSDP, DNS, CharGEN, SNMP attacks, etc
- When an attacker may send a third party server (such as an NTP server) a request using a spoofed IP address. That server will then respond to that request with a greater payload than the initial request (28-54 xs larger) to the spoofed IP
- Layer 7 Attack
- Occurs when a web server receives a flood of GET or POST requests, usually from a botnet or large number of compromised computers
- Causes legitimate users to not be able to connect to the web server because it is busy responding to the flood of requests from the botnet
- Occurs when a web server receives a flood of GET or POST requests, usually from a botnet or large number of compromised computers
- Logging API Calls using CloudTrail
- CloudTrail Overview:
- Increases visibility into your user and resource activity by recording AWS Management Console actions and API calls
- Can identify which users and accounts called AWS, the source IP from which the calls were made and when
- Just tracks API calls:
- Every call is logged into an S3 bucket by CloudTrail
- RDP and SSH traffic is NOT logged
- DOES include anything done in the console
- What is logged in a CloudTrail logged event?
- Metadata around the API calls
- Id of the API caller
- Time of call
- Source IP of API caller
- Request parameters
- Response elements returned by the service
- What CloudTrail allows for:
- After-the-fact incident investigation
- Near real-time intrusion detection → integrate with Lambda function to create an intrusion detection system that you can customize
- Logging for industry and regulatory compliance
- CloudTrail Overview:
- Amazon Shield
- AWS Shield
- Free DDoS Protection
- Protects all AWS customers on ELBs, CloudFront, and Route53
- Protects against SYN/UDP floods, reflection attacks and other Layer 3 and Layer 4 attacks
- AWS Shield-Enhanced
- Provides enhanced protections for apps running on ELB, CloudFront, Route53 against larger and more sophisticated attacks
- Offers always-on, flow-based monitoring of network traffic and active application monitoring to provide near real-time notifications of DDoS attacks
- 24/7 access to the DDoS Response Team (DRT) to help mitigate and manage app-layer DDoS attacks
- Protects your AWS bill against higher fees due to ELB, CloudFront, and Route53 usage spikes during a DDoS attack
- Costs $3000/month
- AWS Shield
- Web Application Firewall
- Web Application Firewall that allows you to monitor the HTTP and HTTPS requests that are forwarded on to CloudFront or Application Load Balancer
- Lets you control access to your content
- Can configure conditions such as what IP addresses are allowed to make this request or what query string parameters need to be passed for the request to be allowed
- The Application Load Balancer or CloudFront will either allow this content to be received or give an HTTP 403 status code
- Operates at Layer 7
- At the most basic level, WAF allows 3 behaviors:
- Allow all requests except the ones you specify
- Block all requests except for the ones you specify
- Count the requests that match the properties you specify
- Can define conditions by using characteristics of web requests such as:
- IP addresses that the requests originate from
- Country that the requests originate from
- Values in requests headers
- Presence of a SQL code that is likely to be malicious (ie: SQL Injection)
- Presence of a script that is likely to be malicious (ie: cross-site scripting)
- Strings that appear in requests - either specific strings or strings that match regex patterns
- WAF can:
- Can protect against Layer 7 DDoS attacks like cross-site scripting, SQL injections
- Can block specific countries or specific IP addresses
- GuardDuty
- Threat detection service that uses ML to continuously monitor for malicious behavior
- Unusual API calls, calls from a known malicious IP
- Attempts to disable CloudTrail logging
- Unauthorized Deployments
- Compromised Instances
- Recon by would-be attackers
- Port scanning and failed logins
- Features
- Alerts appear in GuardDuty console and CloudWatch events
- Receives feeds from 3rd parties like Proofpoint and CrowdStrike, as well as AWS Security, about known malicious domains and IP addresses
- Monitors CloudTrail logs, VPC flow logs and DNS logs
- Allows you to centralize threat detection across multiple AWS Accounts
- Automated response using CloudWatch Events and Lambda
- Gives you ML and anomaly detection
- Basically threat detection with AI
- Setting up GuardDuty:
- 7-14 days to set a baseline = normal behavior
- You will only see findings that GuardDuty detects as a threat
- Cost
- 30 days free
- Charges based on:
- Quality of CloudTrail events
- Volume of DNS and VPC Flow logs data
- Threat detection service that uses ML to continuously monitor for malicious behavior
- Firewall Manager
- A security management service in a single pane of glass
- Allows you to centrally set up and manage firewall rules across multiple AWS accounts and apps in AWS Organizations
- Can create new AWS WAF Rules for your App Load Balancers, API Gateways, and CloudFront distributions
- Can also mitigate DDoS attacks using shield Advanced for your App Load Balancers, Elastic IP addresses, CloudFront distributions, and more
- Benefits:
- Simplifies management firewall rules across accounts
- Ensure compliance of existing and new apps
- Monitoring S3 Buckets with Macie
- Macie
- Automated analysis of data - uses ML and pattern matching to discover sensitive data stored in S3
- Uses AI to recognize if your S3 objects contain sensitive data, such as PII, PHI, and financial data
- Buckets:
- Alerts you to unencrypted buckets
- Alerts you about public buckets
- Can also alert you about buckets shared with AWS accounts outside of those defined in your AWS Orgs
- Great for frameworks like HIPAA
- Macie Alerts
- You can filter and search Macie alerts in AWS console
- Alerts sent to Amazon EventBridge can be integrated with your security incident and event management (SIEM) system
- Can be integrated with AWS Security Hub for a broader analysis of your organization's security posture
- Can also be integrated with other AWS Services, such as Step Functions, to automatically take remediation actions
- Macie
- Inspector
- An automated security assessment service that helps improve the security and compliance of apps deployed on AWS
- Auto assesses apps for vulnerabilities or deviations from best practices
- Inspects EC2 instances and networks
- Assessment findings:
- After performing an assessment, Inspector produces a detailed list of security findings by level of security
- These findings can be reviewed directly or as part of detailed assessment reports available via Inspector console to API
- 2 types of assessments:
- Network Assessments
- Network configuration analysis to check for ports reachable from outside the VPC
- Inspector agent not required
- Host Assessments
- Vulnerable software (CVE), host hardening (CIS Benchmarks), and security best practices to review
- Inspector agent is required
- Network Assessments
- How does it work:
- Create assessment target
- Install agents on EC2 instances
- AWS will auto install the agent for instances that allow Systems Manager run commands
- Create Assessment Templates
- Perform Assessment run
- Review findings against the rules
- Key Management Service (KMS) and CloudHSM
- KMS
- AWS KMS is a managed service that makes it easy for you to create and control the encryption keys used to encrypt your data
- KSM Integrations
- Integrates with other services (EBS, S3, and RDS, etc) to make it simple to encrypt your data with encryption keys you manage
- Controlling your keys
- Provides you with centralized control over the lifecycle and permissions of your keys
- Can create new keys whenever you wish and you can control who can manage keys separately from who can use them
- CMK = Customer Master Key
- Logical representation of a master key
- CMK includes metadata such as they Key ID, creation date description, and key state
- CMK also contains the key material used to encrypt/decrypt data
- Getting started with CMK:
- You start the service by requesting the creation of a CMK
- You control the lifecycle of a CMK as well as who can use or manage it
- HSM - Hardware Security Module
- A physical computing device that safeguards and manages digital keys and performs encryption and decryption functions
- HSM contains one or more secure cryptoprocessor chips
- 3 ways to generate a CMK:
- AWS creates the CMK for you
- KMS
Key material for CMK is generated within HSMs managed by AWS KMS
- Import key material from your own key management infrastructure and associate it with a CMK
- Have they key material generated and used in an AWS CloudHSM Cluster as part of the custom key store feature in KMS
- Key Rotation:
- If KMS HSMs were used to generate your keys, you can have AWS KMS auto rotate CMKs every year
- Auto key rotation is not supported for imported keys, asymmetric keys or keys generated in an AWS CloudHSM cluster using KMS custom key store feature
- If KMS HSMs were used to generate your keys, you can have AWS KMS auto rotate CMKs every year
- Policies
- Primary way to manage access to your KMS CMKs is with policies
- Policies re documents that describe who has access to what
- Policies attached to an IAM Identity = identity-based policies (IAM policies), policies attached to other kinds of resources are called resource-based policies
- Key Policies
- In KMS, you must attach resource-based policies to your customer master keys (CMKs) → these are key policies
- All CMKs must have a key policy
- 3 ways to control permissions:
- Use the key policy- controlling access this way means the full scope of access to the CMK is defined in a single document (the key policy)
- Use IAM policies in combo with key policy- controlling access this way enables you to manage all the permissions for your IAM identities in IAM
- Use grants in combo with key policy- enables you to allow access to CMK in the key policy, as well as allow users to delegate their access to others
- Primary way to manage access to your KMS CMKs is with policies
- CloudHSM
- Cloud-based Hardware Security Module that enables you to easily generate and use your own encryption keys on the AWS Cloud
- Basically renting physical device from AWS
- Cloud-based Hardware Security Module that enables you to easily generate and use your own encryption keys on the AWS Cloud
- KMS vs CloudHSM
- KSM
- Shared tenancy of underlying Hardware
- Auto key rotation
- Auto key generation
- CloudHSM
- Dedicated HSM to you
- Full control of underlying hardware
- Full control of users, groups, keys, etc
- No auto key rotation
- KSM
- Secrets Manager
- Service that securely stores, encrypts, and rotates your db credentials and other secrets
- Encryption in transit and at rest using KMS
- Auto rotates credentials
- Apply fine-grained access control using IAM policies
- Costs money, but highly scalable
- What else can it do
- Your app makes an API call to Secrets Manager to retrieve the secret programmatically
- Reduces the risk of credentials being compromised
- What can be stored?
- RDS credentials
- Credentials for non-RDS dbs
- Any other type of secret, provided you can store it as a key-value pair (SSH keys, API keys)
- Important: If you enable rotation, Secrets Manager immediately rotates the secret once to test the configuration
- You have to ensure that all of your apps that use these creds are updated to retrieve the creds from this secret using Secrets Manager
- If you apps are still using embedded creds, do not enable rotation
- Recommended to enable rotation if your apps are not already using embedded creds
- Service that securely stores, encrypts, and rotates your db credentials and other secrets
- Parameter Store
- A capability of AWS Systems Manager that provides, secure, hierarchical storage for config data management and secrets management
- Can store things like passwords, db strings, AMI IDs, and license credentials as parameter values - can store as plain text or encrypted
- Parameter store is free
- 2 Big limits to Parameter Store:
- Limit to number of parameters you can store (current max is 10k)
- No key rotation
- Parameter Store vs Secrets Manager
- Minimize cost → Parameter Store
- Need more than 10k secrets, key rotation, or the ability to generate passwords using CloudFormation → Secrets Manager
- Pre Signed URLs or Cookies
- All objects in S3 are private by default- only object owner has permissions to access
- Pre Signed URLS
- Owner can share objects with others by creating a pre-signed URL, using their own credentials, to grant the time-limited permission to download the objects
- When you create a pre signed URL for your object, you must provide your security credentials, specify a bucket name and an object key, and indicate the HTTP method (or GET to download the object) as well as expiration date and time
- URLs are only valid for specified duration
- To generate a pre signed URL for an object, must do through CLI
- > aws S3 presign s3://nameofbucket/objectname --expires-in 3600
- Way to share an object in a private bucket?
- Pre signed URLs
- Owner can share objects with others by creating a pre-signed URL, using their own credentials, to grant the time-limited permission to download the objects
- Pre signed Cookies
- Useful when you want to provide access to multiple restricted files
- The cookie will be saved on the user’s computer and they will be able to browse the entire comments of the restricted content
- Use case:
- Subscription to download files
- IAM Policy Documents
- Amazon Resource Names (ARNs)
- These uniquely ID a resource within Amazon
- All ARNs begin with:
- arn:partition:service:region:account_id
- Ex: arn:aws:ec2:eu-central-1:123456789012
- arn:partition:service:region:account_id
- And end with:
- Resource
- resource_type/resource
- Ex: my_awesome_bucket/image.jpg
- resource_type/resource/qualifier
- resource_type:resource
- Resource_type:resource:qualifier
- Note: for global services, for example, we will have no region, so there will be a :: aka omitted value in the arn
- IAM Policies
- Are JSON docs that define permissions
- IAM/Identity Policy = applying policies to users/groups
- Resource Policy = apply to S3, CMKs, etc
- They are basically a list of statements:
- {“Version”:”2012-10-17”,
- Amazon Resource Names (ARNs)
“Statement”:[
{...},
{...}
]
}
- Each statement matches an AWS API request
- Each statement has an effect of Allow or Deny
- Matched based on action
- Permission boundaries
- Used to delegate admin to other users
- Prevent privilege escalation or unnecessarily broad permissions
- Control max permissions an IAM policy can grant
- Exam tips:
- If permission is not explicitly allowed, it is implicitly denied
- An explicit deny > anything else
- AWS joins all applicable policies
- AWS managed vs customer managed
- AWS Certificate Manager
- Allows you to create, manage, and deploy public and private SSL certificates use with other services
- Integrates with other services - such as ELB, CloudFront distros, API Gateway - allowing you to easily manage and deploy SSL certs in environment
- Benefits:
- Do not have to pay for SSL certificates
- Provisions both public and private certificates for free
- You will still pay for the resources that utilize your certificates - such as ELBs
- Automated Renewals and Deployment
- Can automate the renewal of your SSL certificate and then auto update the new certificate with ACM-integrated services, such as ELB, CloudFront, API Gateway
- Easy to set up
- Do not have to pay for SSL certificates
- Allows you to create, manage, and deploy public and private SSL certificates use with other services
- AWS Audit Manager
- Continuously audit your AWS usage and make sure you stay compliant with industry standards and regulations
- It is an automated service that produces reports specific to auditors for PCI compliance, etc
- Use Cases:
- Transition from Manual to Automated Evidence Collection
- Allows you to produce automated reports for auditors and reduce manual
- Continuous Auditing and Compliance
- Continuous basis, as your environment evolves and adapts, you can produce automated reports to evaluate your environment against industry standards
- Internal Risk Assessments
- Can create a new framework from the beginning or customize pre built frameworks
- Can launch assessments to auto collect evidence, helping you validate if your internal policies are being followed
- Transition from Manual to Automated Evidence Collection
- AWS Artifact
- Single source you can visit to get the compliance-related info that matters to you, such as security and compliance reports
- What is available?
- Huge number of reports available
- Service Organization control (SOC) reports
- Payment Card Industry (PCI) reports
- As well as other certifications - HIPAA, etc
- Huge number of reports available
- AWS Cognito
- Provides authentication, authorization, and user management for your web and mobile apps in a single service without the need for custom code
- Users can sign-in directly with a UN/PW they create or through a third party (FB, Amazon, Google, etc)
- ⇒ authorization engine
- Provides the following features:
- Sign-up and sign-in options for your apps
- Access for guest users
- Acts as an identity broker between your application and web ID providers, so you don’t have to write any custom code
- Synchronizes user data across multiple devices
- Recommended for all mobile apps that call AWS Services
- Use cases:
- Authentication
- Users can sign in using a user pool or a 3rd party identity provider, such as FB
- 3rd Party Authentication
- Users can authenticate using identity pools that require an identity pool (IdP) token
- Access Server-Side Resources
- A signed-in user is given a token that allows them access to resources that you specify
- Access AWS AppSync Resources
- Users can be given access to AppSync resources with tokens received from a user or identity pool in Cognito
- Authentication
- User Pools and Identity Pools
- Two main components of Cognito
- User Pools
- Directories of users that provide sign-up and sign-in options for your application users
- Identity Pools
- Allows you to give your users access to other AWS Services
- You can use identity pools and user pools together or separately
- User Pools
- Two main components of Cognito
- How it works - broadly
- When you use the basic authflow, your app first presents an ID token from an authorized Amazon Cognito user pool or third-party identity provider in a GetID request.
- The app exchanges the token for an identity ID in your identity pool.
- The identity ID is then used with the same identity provider token in a GetOpenIdToken request.
- GetOpenIdToken returns a new OAuth 2.0 token that is issued by your identity pool.
- You can then use the new token in an AssumeRoleWithWebIdentity request to retrieve AWS API credentials.
- The basic workflow gives you more granular control over the credentials that you distribute to your users.
- The GetCredentialsForIdentity request of the enhanced authflow requests a role based on the contents of an access token.
- The AssumeRoleWithWebIdentity request in the classic workflow grants your app a greater ability to request credentials for any AWS Identity and Access Management role that you have configured with a sufficient trust policy.
- You can also request a custom role session duration.
- Cognito Sequence
- Device/App connects to a User Pool in Cognito - You are authenticating and getting tokens
- Once you've got that token, your device is going to exchange that token to an identity pool, and then the identity pool with hand over some AWS credentials
- Then you can use those credentials to access your AWS Services
- Basic Cognito Sequence:
- Request to user pool, authenticates and gets token
- Exchanges token and get AWS creds
- Use AWS creds to access AWS services
- Provides authentication, authorization, and user management for your web and mobile apps in a single service without the need for custom code
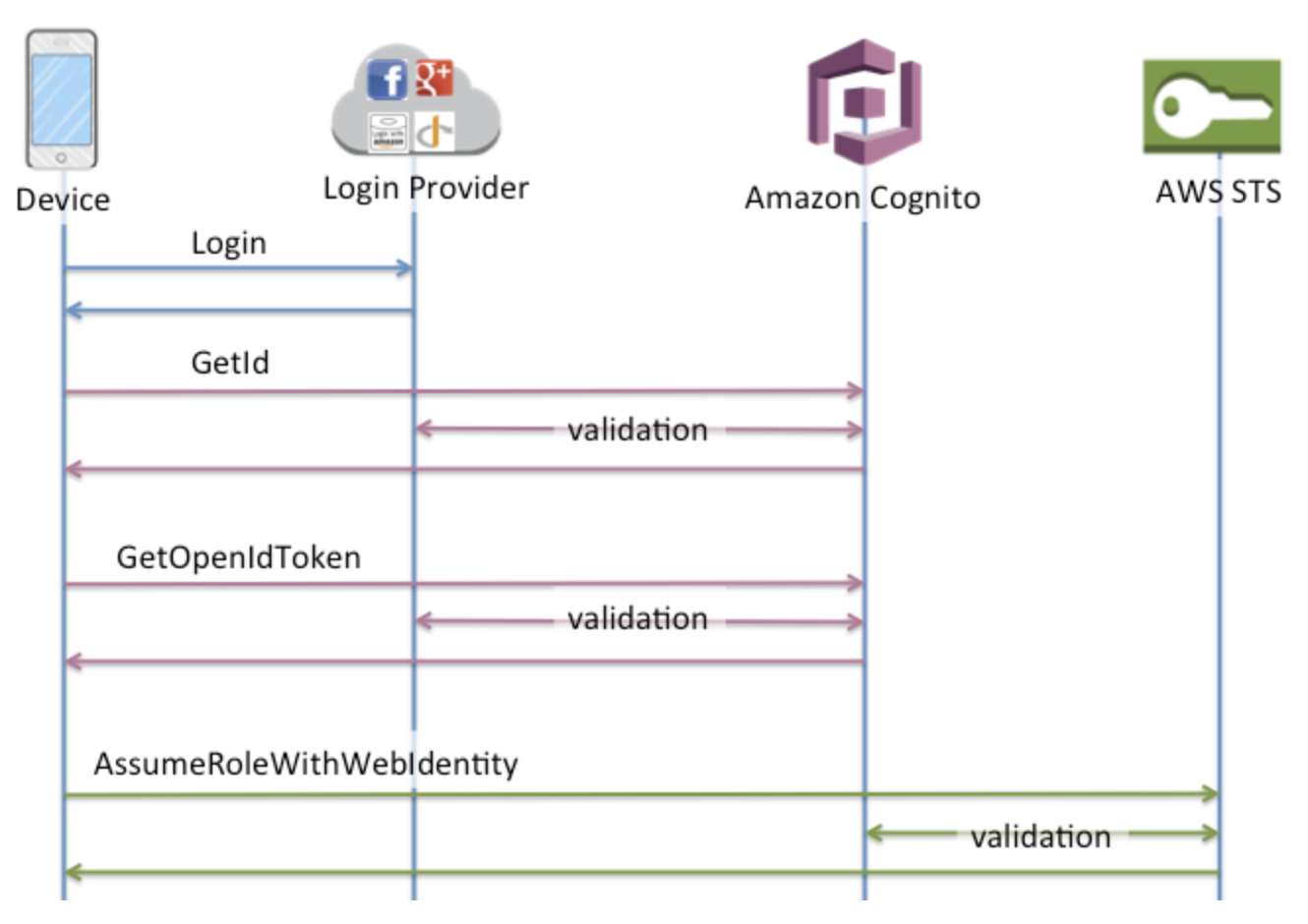
- Amazon Detective
- You can analyze, investigate and quickly identify the root cause of potential security issues or suspicious activities
- Detective pulls data from your AWS resources and uses ML, statistical analysis, and graph theory to build a linked set of data that enables you to quickly figure out the root cause of your security issues
- To auto create an overview of users, resources, and the interactions between them over time
- Sources for Detective:
- VPC flow logs, CloudTrail logs, EKS audit logs, and GuardDuty findings
- Use Cases:
- Triage Security Findings - generates visualizations
- Threat Hunting
- Exam Tips:
- Operates across multiple services and analyzes root cause of an event
- If you see “root cause” or “graph theory”, think Detective
- Don’t confuse with Inspector
- Inspector = Automated vulnerability management service that continually scans EC2 and container workloads for software vulnerabilities and unintentioned network exposure
- AWS Network Firewall
- Physical firewall protection - a managed service that makes it easy to deploy physical firewall protection across your VPCs
- Managed infrastructure
- Includes a firewall rules engine that gives you complete control over your network traffic
- Allowing you to do things such as block outbound Server Message Block (SMB) requests to stop the spread of malicious activity
- Benefits:
- Physical infrastructure in the AWS datacenter that is managed by AWS
- Network Firewall works with Firewall Manager
- FW Manager with Network Firewall added: Allows you to centrally manage security policies across existing and newly created accounts and VPC
- Also provides an Intrusion Detection System (IPS) that gives you active traffic flow inspection
- See IPS, think Network Firewall
- Use Cases:
- Filter Internet Traffic
- Use methods like ACL rules, stateful inspection, protocol detection, and intrusion prevention to filter your internet traffic
- Filter Outbound Traffic
- Provide the URL/domain name, IP address, and content-based outbound traffic filtering
- Help you stop possible data loss and block known malicious communicators
- Inspect VPC-to-VPC Traffic
- Auto inspect traffic moving from one VPC to another as well as across multiple accounts
- Filter Internet Traffic
- Exam Tips:
- Scenario about filtering your network traffic before it reaches your internet gateway
- Or if you require IPS or any hardware firewall requirements
- Physical firewall protection - a managed service that makes it easy to deploy physical firewall protection across your VPCs
- AWS Security Hub
- Single place to view all of your security alerts from services like GuardDuty, Inspector, Macie, and Firewall Manager
- Works across multiple accounts
- Use Cases:
- Conduct Cloud Security Posture Management (CSPM)- use automated checks that comply with common frameworks (for ex: Center for Information Security (CIS) or PSI DSS) to help reduce your risk
- Correlate security findings to discover new insights
- Aggregate all your security findings in one place, allowing security staff to more easily identify threats and alerts
- Single place to view all of your security alerts from services like GuardDuty, Inspector, Macie, and Firewall Manager
- CloudFormation
- Overview:
- Written in declarative programming language supports either JSON or YAML formatting
- Creates immutable architecture - easily create/destroy architecture
- Creates the same API calls that you would make manually
- Steps in CloudFormation:
- Step 1: write code
- Step 2: Deploy your template
- When you upload your template, CloudFormation engine will go through the process of making the needed AWS API calls on your behalf
- Create CloudFormation Stack
- Set parameters that are defined in your template and allow you to input custom values when you create or update a stack
- Parameters come from the code in the template
- Set parameters that are defined in your template and allow you to input custom values when you create or update a stack
- 3 sections of CloudFormation template:
- Parameters
- Mappings = values that fill themselves in during formation
- Resource Section
- If CloudFormation finds an error, it rolls back to the last known good state
- Overview:
- Elastic Beanstalk
- The Amazon PaaS tool - one stop for everything AWS
- Automation
- Automates all of your deployments
- You can templatize what you would like your environment to look like
- Deployments handled for us- upload code, test your code in a staging environment, then deploy to production
- Handles building out the insides of your EC2 instances for you
- Configuring Elastic Beanstalk
- Pick your platform
- Pick language - supports docker which means we can run all sorts of languages/environments inside a container on Elastic Beanstalk
- Additional Configurations
- Basically bundles all the wizards from across AWS services and gives you a place to configure all these in Beanstalk
- Pick your platform
- Exam Tips:
- Bring your code and that is all
- Elastic Beanstalk = PaaS tool
- It builds the platform and stacks your application on top
- Not serverless - Beanstalk creates and manages standard EC2 architecture
- Systems Manager
- Suite of tools designed to let you view, control and automate both your AWS architecture and on-prem architecture
- Features of Systems Manager
- Automation Documents [now called Runbooks]
- Can be used to control your instances or AWS resources
- Run Command
- Executes commands on your hosts
- Patch Manager
- Manage app versions
- Parameter Store
- Secret Values
- Hybrid Architecture
- Control you on-prem architecture
- Session Manager
- Allows you to connect and remotely interact with your architecture
- Automation Documents [now called Runbooks]
- All it takes for EC2/on-prem to be managed by Systems Manager is to:
- Install Systems Manager Agent
- And give the instance a role/permissions to communicate to the Systems Manager
- Caching
- Types of Caching
- Internal: in front of database to store frequent queries, for example
- External: CDN = Content Delivery Network
- AWS Caching Options
- CloudFront = External
- ElastiCache = Internal
- DAX = DynamoDB Solution
- Global Accelerator = External
- Types of Caching
- Global Caching with CloudFront
- CloudFront Overview
- Fast Content Delivery Network (CDN) service that securely delivers data, videos, apps, and APIs to customers globally
- Helps reduce latency and provide higher transfer speeds using AWS edge locations
- First user makes request through CloudFront at an Edge location, CloudFront will go to S3 and grab object, it will hold a copy of that object at the Edge Location
- First user’s request is not faster, but all after are pulling from Edge location
- Fast Content Delivery Network (CDN) service that securely delivers data, videos, apps, and APIs to customers globally
- CloudFront Settings
- Security
- Defaults to HTTPS connections with the ability to add custom SSL certifications
- Put secure connection on static S3 connections
- Global Distribution
- Cannot pick specific countries, just general areas
- Endpoint Support - AWS and Non-AWS
- Can be used to front AWS endpoints as well as non-AWS applications
- Expiring Content
- You can force an expiration of content from the cache if you cannot wait for the TTL
- Can restrict access to your content via CloudFront using signed URLs or signed cookies
- Security
- Exam Tips:
- Solution for external customer performance issue
- CloudFront Overview
- Caching your data with ElastiCache and DAX
- ElastiCache
- Managed version of 2 open source technologies
- Memcached
- Redis
- Neither of these tools are specific to AWS but by using ElastiCache, you can spin up 1 or the other, or both to avoid a lot of common issues
- ElastiCache can sit in front of almost any database, but it really excels being placed in front of RDS’s
- Memcached vs Redis
- Both sit in front of database and cache common queries that you make
- Memcached
- Simple db caching solution
- Not a db by itself
- No failover, no multi-AZ support, no backups
- Redis
- Supported as a caching solution
- But also has the ability to function as a standalone NoSQL db
- Managed version of 2 open source technologies
- ElastiCache
“Caching Solution” but also can be the answer if you are looking for a NoSQL solution and DynamoDB isn’t present
Has failover, multi-AZ, backup support
- DynamoDB Accelerator (DAX)
- It is an In-Memory Cache
- Reduce DynamoDB response times from milliseconds to microseconds
- DAX lives inside a VPC, you specify which - is highly available
- You are in control
- You determine the node size and count for the cluster, TTL for the data, and maintenance windows for changes and updates
- It is an In-Memory Cache
- DynamoDB Accelerator (DAX)
- Fixing IP Caching with Global Accelerator
- Global Accelerator
- A networking service that sits in front of your apps and sends your users’ traffic through AWS’s global network infrastructure
- Can increase performance and help deal with IP Caching
- IP Caching Issue
- User connecting to ELB, caches that ELB’s IP address (for the period defined by TTL)
- If that ELB goes offline and its IP changes, the user will be trying to connect with wrong IP
- Global accelerator solves this problem by sitting in front of ELB
- User is served 1 of only 2 IP addresses - that never change
- Even if ELB’s IP changes, user connection doesn't change
- Top 3 features of Global Accelerator:
- Masks Complex Architecture
- Global Accelerator IPs never change for users
- Speeds things up
- Traffic is routed through AWS’s global network infrastructure
- Weighted Pools
- Create weighted groups behind the IPs to test out new features or handle failure in your environment
- Masks Complex Architecture
- Creating Global Accelerator
- Listeners = port/port range
- Listeners direct traffic to one or more endpoint groups (endpoints = such as load balancers)
- Each listener can have multiple endpoint groups
- Each endpoint group can only include endpoints that are in one Region
- Adjust the weight here
- Global Accelerator solves IP caching
- A networking service that sits in front of your apps and sends your users’ traffic through AWS’s global network infrastructure
- Global Accelerator
- AWS Organizations
- Managing accounts with AWS Organizations
- Free governance tool that allows you to create and manage multiple AWS accounts - can control your accounts from a single location
- Applying standards across accounts (ex: Prod, Dev, Beta, etc)
- Key features in Organizations
- It is vital to create a Logging Account
- It is best practice to create a specific account dedicated to logging
- Ship all logs to one central location with Organizations
- CloudTrail supports logs aggregation
- Programmatic Creation: easily create and destroy new AWS accounts with API calls
- Reserve Instances: RIs can be shared across all accounts
- Consolidated Billing
- Service Control Policies (SCPs) can limit users’ permissions
- SCPs are in JSON format
- Once implemented, these policies will be applied to every single resource inside an account
- They are the ultimate way to restrict permissions and even apply to the root account
- Effectively a global policy and the only way to restrict what the root user can do
- SCPs never give permissions, they ONLY TAKE away the possible permissions that can be handed out
- Deny rules - deny specific things globally
- Allow rules - even more restrictive because it limits all of the permissions we could hand out
- It is vital to create a Logging Account
- Managing accounts with AWS Organizations
- Resource Access Manager (RAM)
- Free service that allows you to share AWS resources with other accounts and within your organization
- Allows you to easily share resources rather than having to create duplicate copies
- What can be shared?
- Transit Gateways
- VPC Subnets
- License Manager
- Route53 Resolver
- Dedicated Hosts
- Etc
- Can set permissions for what actions are allowed to happen on shared resources
- RAM vs VPC Peering
- Use RAM when sharing resources within the same region
- Use VPC Peering when sharing resources across regions
- Setting up Cross Account Role Access
- Cross-Account Role Access
- Allows you to set up temporary access you can easily control
- Set up primary user and then other users assume roles rather than having to create many many accounts
- Steps to set up Cross-Account Role Access:
- Create an IAM Role
- Grant access to allow users to temporarily assume role
- Exam Tips
- It is preferred to create cross-account roles rather than add additional IAM users
- Auditing - temporary access, temporary employees
- Cross-Account Role Access
- AWS Config
- Inventory management and control tool
- Allows you to show the history of your infrastructure along with creating rules to make sure it conforms to the best practices you’ve laid out
- 3 things it allows us to do:
- Allows us to query our architecture
- Can easily discover what architecture you have in your account - query by resource type, tag, even see deleted resources
- Rules can be created to flag when something is going wrong/out of compliance
- Whenever a rule is violated, you can be alerted or even have it auto fixed
- Shows history of Environment
- When did something change, who made that call, etc
- Allows us to query our architecture
- Can open up specific CloudTrail event that is tied to that event in Config
- Can auto remediate issues
- Can select remediation actions
- For example, can auto kick off an Automation Document that will block public access
- Can select remediation actions
- Exam Tips
- Config = Setting standards
- Directory Service
- Fully managed version of Active Directory
- Allows you to offload the painful parts of keeping AD online to AWS while still giving you the full control and flexibility AD provides
- Available Types:
- Managed Microsoft AD
- Entire AD suite, easily build out AD in AWS
- AD Connector
- Creates a tunnel between AWS and your on-prem AD
- Want to leave AD in physical data center
- Get an endpoint that you can authenticate against in AWS while leaving all of your actual users and data on-prem
- Simple AD
- Standalone directory powered by Linux Samba AD-Compatible server
- Just an authentication service
- Managed Microsoft AD
- AWS Cost Explorer
- Easy-to-use tool that allows you to visualize your cloud costs
- Can generate reports based on a variety of factors, including resource tags
- What can it do?
- Break down costs on a service-by-service basis
- Can break out by time, can estimate next month
- Filter and breakdown data however we want
- Exam tips
- Have to set tags as “cost allocation tag” to use
- Cost Explorer and Budgets go hand-in-hand
- Easy-to-use tool that allows you to visualize your cloud costs
- AWS Budgets
- Allows organizations to easily plan and set expectations around cloud costs
- Easily track your ongoing spending and create alerts to let users know where they are close to exceeding their allotted spend
- Types of Budgets - you get 2 free each month
- Cost Budgets
- Usage Budgets
- Reservation Budgets - RIs
- Savings Plan Budgets
- Exam Tips
- Can be alerted on current spend or projected spend
- Can create a budget using tags as a filter
- Allows organizations to easily plan and set expectations around cloud costs
- AWS Costs and Usage Reports (CUR)
- Most comprehensive set of cost and usage data available for AWS spending
- Publishes billing reports to AWS S3 for centralized collection
- These breakdown costs by the time span (hour, day, month), service and resource, or by tags
- Daily updates to reports in S3 in CSV formats
- Integrates with other services - Athena, Redshift, QuickSight
- Use Cases for AWS CUR:
- Within Organizations for entire OU groups or individual accounts
- Tracks Savings Plans utilizations, changes, and current allocations
- Monitor On-Demand capacity reservations
- Break down your AWS data transfer charges: external and inter-Regional
- Dive deeper into cost allocation tag resources spending
- Exam Tip
- Most comprehensive overview of spending
- Reducing compute spend using Savings Plans and AWS Compute Optimizer
- AWS Compute Optimizer
- Optimizes, analyzes configurations and utilization metrics of your AWS resources
- Reports current usage optimizations and potential recommendations
- Graphs
- Informed decisions
- Which resources work with this service?
- EC2, Auto Scaling Groups, EBS, Lambda
- Supported Account Types
- Standalone AWS account without Organizations enabled
- Member Account - single member account within an Organization
- Management Account
- When you enable at the AWS Organization management account, you get recommendations based on entire organization (or lock down to 1 account)
- Things to know:
- Disabled by default
- Must opt in to leverage Compute Optimizer
- After opting in, enhance recommendations via activation of recommendation preferences
- Disabled by default
- Savings Plans
- Offer flexible pricing modules for up to 72% savings on compute
- Lower prices for EC2 instances regardless of instance family, size, OS, tenancy, or Region
- Savings can also apply to Lambda and Fargate usage
- SageMaker plans available for lowering SageMaker instance pricing
- Require Commitments
- 1 or 3 year options
- Pricing Plan options:
- Pay all upfront - most reduced
- Partial upfront
- No upfront
- Savings Plan Types:
- Compute Savings
- AWS Compute Optimizer
Most flexible savings plan
Applies to any EC2 compute, Lambda, or Fargate usage
Up to 66% savings on compute
- EC2 Instance Savings
Stricter savings plan
Applies only to EC2 instances of a specific instance family in specific regions
Up to 72% savings
- SageMaker Savings
Only SageMaker Instances - any region and any component, regardless of family or sizing
Up to 64% savings
- Using and applying Savings Plan
- View recommendations in AWS billing console
- Recommendations are auto calculated to make purchasing easier
- Add to cart and purchase directly within account
- Apply to usage rates AFTER your RIs are applied and exhausted
- RIs have to be used first
- If in a consolidated billing family; savings applied to account owner first, then can be spread to others if sharing enabled
- Using and applying Savings Plan
- Trusted Advisor for Auditing
- Trusted Advisor Overview
- Fully managed best practice auditing tool
- It will scan 5 different parts of your account and look for places when you could improve your adoption of the recommended best practice provided by AWS
- 5 Questions Trusted Advisor Asks:
- Cost Optimizations: Are you spending money on resources that are not needed?
- Performance: Are your services configured properly for your environment?
- Security: Is your AWS architecture full of vulnerabilities?
- Fault Tolerance: Are you protected when something fails?
- Service Limits: Do you have room to scale?
- Want to link Trusted Advisor with an automated response to alert users or fix the problem
- Use EventBridge (CloudWatch Events) to kick of Lambda function to fix problem
- To get the most useful checks, you will need a Business or Enterprise support plan
- Trusted Advisor Overview
- Control Tower to enforce account Governance
- Control Tower Overview
- Governance: Easy way to set up and govern an AWS multi-account environment
- Orchestration: automates account creation and security controls via other AWS Services
- Extension: extends AWS Organizations to prevent governance drift, and leverabes different guardrails
- New AWS Accounts: users can provision new AWS accounts quickly, using central administration-established compliance policies
- Simple Terms: quickest way to create and manage a secure, compliance, multi-account environment based on best practices
- Features and Terms
- Landing Zone
- Well-architected, multi-account environment based on compliance and security best practices
- Basically a container that holds all of your Organizational Units, your accounts within there OU’s, and users/other resources that you want to force compliance on
- Can scale to fit whatever side you need
- Guardrails
- High-level rules providing continuous governance for the AWS Environment
- 2 Types
- Preventative
- Detective
- Account Factory
- Configurable account template for standardizing pre-approved configurations of new accounts
- CloudFormation Stack Set
- Automated deployments of templates deploying repeated resources for governance
- Management account would deploy a stack set to either the entire organization unit or the entire organization itself using repeatedly deployed resources
- Shared Accounts
- Three accounts used by Control Tower
- 2 of which are created during landing zone creation: Log Archive and Audit
- Three accounts used by Control Tower
- Landing Zone
- More on GuardRails
- High-level rules written in plain language providing ongoing governance
- 2 types:
- Preventative:
- Ensures accounts maintain governance by disallowing violating actions
- Leverages service control policies (SCPs) within Organizations
- Statuses of: Enforced or Not Enabled
- Supported in all regions
- Detective:
- Detects and alerts on noncompliant resources within all accounts
- Leverages AWS Config Rules
- Preventative:
- Control Tower Overview
Config Rules - it alerts, does NOT remediate unless you leverage other resources
- Statuses: clear, in violation or not enabled
- Only apply to certain regions
Only going to work in regions that are supported by Control Tower
Which is currently not every region
- Control Tower Diagram
- Start with management account - with Organization and Control Tower enabled
- Control Tower creates 2 accounts (“shared accounts”)
- Log Archive Account
- Audit Account
- Control Tower places an SCP on every account that exists within our Organization → Preventative Guardrails
- Control Tower places AWS Config Rules in each account as well → Detective Guardrails
- All of our Config and CloudTrail logs get sent to the Log Archive shared account - to centralize logging
- Will also set up notifications for any governance violations that may occur
- All governance will be sent to the auditing account - including configuration events, aggregate security notifications, and drift notifications
- Go to an SNS topic in the audit account, you can use to alert the correct team
- All governance will be sent to the auditing account - including configuration events, aggregate security notifications, and drift notifications
- Control Tower Diagram
- AWS License Manager
- Manage Software Licenses
- Licenses made easy - simplifies managing software licenses with different vendors
- Centralized: helps centrally manage licenses across AWS accounts and on-prem environments
- Set usage limits
- Control and visibility into usage of licenses and enabling license usage limits
- Reduce overages and penalties via inventory tracking and rule-based controls for consumption
- Versatile- support any software based on vCPU physical cores, sockets, and number of machines
- AWS Personal Health Dashboard (aka AWS Health)
- Monitoring Health Events
- Visibility of resource performance and availability of AWS services or accounts
- View how the health events affect you and your services, resources, and accounts
- AWS maintains timeliness and relevant info within the events
- View upcoming maintenance tasks that may affect your accounts and resources
- Alerts- near instant delivery of notifications and alerts to speed up troubleshooting or prevention actions
- Automates actions based on incoming events using EventBridge
- Health Event → EventBridge → SNS topic, etc
- Concepts
- AWS Health Event = notifications sent on behalf of AWS services or AWS
- Account-specific event: events specific to your AWS account or AWS organization
- Public event = events reported on services that are public
- AWS Health Dashboard
- Dashboard showing account and public events, as well as service health
- Event type code = include the affected services and the specific type of event
- Event type category = associated category will be attached to every event
- Event status = open, closed, or upcoming
- Affected Entities
- Exam tip
- Look out for questions about checking alerts for service health and automating the reboot of EC2 instances for AWS Maintenance
- Monitoring Health Events
- AWS Service Catalog and AWS Proton
- Standardizing Deployments using AWS Service Catalog
- Allows organizations to create and manage catalogs of approved IT services for deployments within AWS
- Multipurpose catalogs - list things like AMIs, server software, databases, and other pre-configured components
- Centralized management of IT service and maintain compliance
- End-User Friendly - easily deploy approved items
- CloudFormation
- Catalogs are written and listed using CloudFormation templates
- Benefits:
- Standardize
- Self-service deployments
- Fine-grained Access Control
- Versioning within Catalogs- propagate changes automatically
- AWS Proton
- Creates and manages infrastructure and deployment tooling for users as well as serverless and container-based apps
- How it works:
- Automate IaC provisioning and deployments
- Define standardized infrastructure for your serverless and container-based apps
- Use templates to define and manage app stacks that contain ALL components
- Automatically provisions resources, configures CI/CD, and deploys the code
- Supports AWS CloudFormation and Terraform IaC providers
- Proton is an all encompassing tool/service for deployments of your applications
- Standardization, empower developers
- Standardizing Deployments using AWS Service Catalog
- Optimizing Architectures with the AWS Well-Architected Tool
- Review 6 Pillars of the Well-Architected Framework:
- Operational Excellence
- Reliability
- Security
- Performing Efficiency
- Cost Optimization
- Sustainability
- Well-Architected Tool
- Provides a consistent process for measuring cloud architecture
- Enables assistance with documenting workloads and architectures
- Guides for making workloads reliable, secure, efficient, and cost effective
- Measure workloads against years of AWS best practice
- Intended for specific audiences: technical teams, CTOs, architecture and operations teams
- Review 6 Pillars of the Well-Architected Framework:
- AWS Snow Family
- Ways to move data to AWS
- Internet
- Could be slow, presents security risks
- Direct Connect
- Not always practical - not for short periods of time
- Physical
- Bypass internet entirely, and bundle data to physically move
- Internet
- Snow Family
- Set of secure appliances that provide petabyte-scale data collection and processing solutions at the edge and migrate large-scale data into and out of AWS
- Offers built-in computing capabilities, enabling customers to run their operations in remote locations that do not have data center access or reliable network connectivity
- Members of the Snow Family:
- Snowcone
- Ex: climbing a wind turbine to collect data
- Smallest device
- 8TB of storage, 4 GB memory, 2 vCPUs
- Easily migrate data to AWS after you’ve processed it
- IoT sensor integration
- Perfect for edge computing where space and power are constrained
- Snowball Edge
- Ex: on a boat
- Jack of all trades
- 48-81TB storage
- Storage, compute (less than Edge Compute), and GPU flavors, varying amount of CPU/RAM
- Perfect for off-the-grid computing or migration to AWS
- Snowmobile
- Literally a semi truck of hard drives
- 100PB of storage
- Designed for exabyte-scale data center migration
- Snowcone
- Set of secure appliances that provide petabyte-scale data collection and processing solutions at the edge and migrate large-scale data into and out of AWS
- Ways to move data to AWS
- Storage Gateway and Types
- Storage Gateway
- A hybrid cloud storage service that helps you merge on-prem resources with the cloud
- Can help with a one-time migration or a long-term pairing of your architecture with AWS
- Types of Storage Gateway:
- File Gateway
- Caching local files
- NFS or SMB Mount - basically a network file share
- Mount locally and backs up data into S3
- Keep a local copy of recently used files
- Versions of File Gateway:
- Backup all data into cloud and Storage Gateway just act as the method of doing that - data lives in S3
- Or you can keep a local cached copy of most recently used files - so you don’t have to download from S3
- Keep data on-prem, backups go to S3
- Scenario - extend on-prem storage
- Helps with migrations to AWS
- Volume Gateway
- Backup drives
- iSCSI mount
- Backing up these disks that the VMs are reading/writing to
- Same cached or stored mode as File Gateway - all backed up to S3
- Can create EBS snapshots and restore volumes inside AWS
- Easy way to migrate on-prem volumes to become EBS volumes inside AWS
- Perfect for backups and migration to AWS
- Tape Gateway
- Ditch the physical tapes and backup to Tape Gateway
- Stores inside S3 Glacier, Deep Archive, etc
- Directly integrated as a VM on-prem so it doesn’t change the current workflow
- It is encrypted
- File Gateway
- Exam Tips
- Storage Gateway = Hybrid Storage
- Complement existing architecture
- Storage Gateway = Hybrid Storage
- Storage Gateway
- AWS DataSync
- Agent-based solution for migrating on-prem storage to AWS
- Easily move data between NFS and SMB shares and AWS storage solution
- Migration Tool
- Using DataSync:
- On-prem
- Have on-prem server and install DataSync agent
- Configure DataSync service to tell it where data is going to go
- Secure transmission with TLS
- Supports S3, EFS, and FSx
- On-prem
- AWS Transfer Family
- Allows you to easily move files in and out of S3 or EFS using SFTP, FTP over SSL (FTPS), or FTP
- How does it transfer:
- Legacy users/apps have processes to transfer data, if want to now transfer to S3 or EFS can put Transfer Family (SFTP, FTPS, FTP) where the old endpoint was and have that service transfer to AWS S3/EFS
- Transfer Family Members
- AWS Transfer for SFTP and AWS Transfer for FTPS - transfers from outside of your AWS environment into S3/EFS
- AWS Transfer for FTP - only supported within the VPC and not over public internet
- Exam Tips
- Bringing legacy app storage to cloud
- DNS entry (endpoint) stays the same in legacy app
- We just swap out the old endpoint to become S3
- Migration Hub
- Single place to track the progress of your app migration to AWS
- Integrates with Server Migration Service (SMS) and Database Migration Service (DMS)
- Server Migration Service (SMS)
- Schedule movement for VMWare server migration
- All scheduled time, takes a copy of your underlying VSphere volume, bring that data into S3
- It converts that volume in S3 into an EBS Snapshot
- Creates and AMI from that
- Can use AMI to launch EC2 instance
- Essentially gives you an easy way to take your VM architecture and convert it to an AMI
- Database Migration Service (DMS)
- Takes on-prem/EC2/RDS old Oracle (or SQL Server) and runs the AWS Schema Conversion Tool on it
- To convert it to an Amazon Aurora DB
- Takes on-prem/EC2/RDS MySQL DB and consolidate it with DMS into Aurora
- Directory Service
- Fully managed version of Active Directory
- Allows you to offload the painful parts of keeping AD online to AWS while still giving you the full control and flexibility AD provides
- Available Types:
- Managed Microsoft AD
- Entire AD suite, easily build out AD in AWS
- AD Connector
- Creates a tunnel between AWS and your on-prem AD
- Want to leave AD in physical data center
- Get an endpoint that you can authenticate against in AWS while leaving all of your actual users and data on-prem
- Simple AD
- Standalone directory powered by Linux Samba AD-Compatible server
- Just an authentication service
- Managed Microsoft AD
- AWS Cost Explorer
- Easy-to-use tool that allows you to visualize your cloud costs
- Can generate reports based on a variety of factors, including resource tags
- What can it do?
- Break down costs on a service-by-service basis
- Can break out by time, can estimate next month
- Filter and breakdown data however we want
- Exam tips
- Have to set tags as “cost allocation tag” to use
- Cost Explorer and Budgets go hand-in-hand
- Easy-to-use tool that allows you to visualize your cloud costs
- AWS Budgets
- Allows organizations to easily plan and set expectations around cloud costs
- Easily track your ongoing spending and create alerts to let users know where they are close to exceeding their allotted spend
- Types of Budgets - you get 2 free each month
- Cost Budgets
- Usage Budgets
- Reservation Budgets - RIs
- Savings Plan Budgets
- Exam Tips
- Can be alerted on current spend or projected spend
- Can create a budget using tags as a filter
- Allows organizations to easily plan and set expectations around cloud costs
- AWS Costs and Usage Reports (CUR)
- Most comprehensive set of cost and usage data available for AWS spending
- Publishes billing reports to AWS S3 for centralized collection
- These breakdown costs by the time span (hour, day, month), service and resource, or by tags
- Daily updates to reports in S3 in CSV formats
- Integrates with other services - Athena, Redshift, QuickSight
- Use Cases for AWS CUR:
- Within Organizations for entire OU groups or individual accounts
- Tracks Savings Plans utilizations, changes, and current allocations
- Monitor On-Demand capacity reservations
- Break down your AWS data transfer charges: external and inter-Regional
- Dive deeper into cost allocation tag resources spending
- Exam Tip
- Most comprehensive overview of spending
- Reducing compute spend using Savings Plans and AWS Compute Optimizer
- AWS Compute Optimizer
- Optimizes, analyzes configurations and utilization metrics of your AWS resources
- Reports current usage optimizations and potential recommendations
- Graphs
- Informed decisions
- Which resources work with this service?
- EC2, Auto Scaling Groups, EBS, Lambda
- Supported Account Types
- Standalone AWS account without Organizations enabled
- Member Account - single member account within an Organization
- Management Account
- When you enable at the AWS Organization management account, you get recommendations based on entire organization (or lock down to 1 account)
- Things to know:
- Disabled by default
- Must opt in to leverage Compute Optimizer
- After opting in, enhance recommendations via activation of recommendation preferences
- Disabled by default
- Savings Plans
- Offer flexible pricing modules for up to 72% savings on compute
- Lower prices for EC2 instances regardless of instance family, size, OS, tenancy, or Region
- Savings can also apply to Lambda and Fargate usage
- SageMaker plans available for lowering SageMaker instance pricing
- Require Commitments
- 1 or 3 year options
- Pricing Plan options:
- Pay all upfront - most reduced
- Partial upfront
- No upfront
- Savings Plan Types:
- Compute Savings
- AWS Compute Optimizer
Most flexible savings plan
Applies to any EC2 compute, Lambda, or Fargate usage
Up to 66% savings on compute
- EC2 Instance Savings
Stricter savings plan
Applies only to EC2 instances of a specific instance family in specific regions
Up to 72% savings
- SageMaker Savings
Only SageMaker Instances - any region and any component, regardless of family or sizing
Up to 64% savings
- Migrating Workloads to AWS using AWS Application Discovery Service or AWS Application Migration Service (MGN)
- Application Discovery Service
- Helps you plan your migrations to the cloud via collection of usage and configuration data from on-prem servers
- Integrates with AWS Migration Hub which simplifies migrations and tracking migration statuses
- Helps you easily view discovered services, group them by application, and track each application migration
- How do we discover our on-prem servers?
- 2 Discovery Types
- Agentless
- 2 Discovery Types
- Application Discovery Service
Completed via the Agentless Collector
It is an OVA file within the VMWare vCenter
OVA file = deployable file for a new type of VM appliance that you can deploy in vCenter
Once you deploy the OVA, it identifies hosts and VMs in vCenter
Helps track and collect IP addresses and MAC addresses, info on resource allocations (memory and CPUs), and host names
Collects utilization data metrics
- Agent-Based
Via an AWS Application Discovery Agent that is deployed
Install this agent on each VM and physical server
There is an installer for Linux and for Windows
Collects more info than agentless process
Static Configuration data, time-series performance info, network connections and OS processes
- Application Migration Service (MGN)
- An automated lift and shift servicer for expediting migration of apps to AWS
- Used for physical, virtual, or cloud servers to avoid cutover windows or disruptions - flexible
- Replicates source servers into AWS and auto converts and launches on AWS to migrate quickly
- 2 key features are RTO and RPO:
- Recovery Time Objective
- Typically just minutes; depending on OS boot time
- Recovery Point Objective
- Measured in the sub-second range
- Can recover at any point after migration
- Recovery Time Objective
- Application Migration Service (MGN)
- Migraging DBs from On-Prem to AWS Database Migration Service (DMS)
- Migration tool for relational, Data Warehouses, NoSQL databases, and other data stores
- Migrate data into cloud or on-prem: either into or out of AWS
- Can be one-time migration or continuous replicate ongoing changes
- Conversion Tool called Schema Conversion Tool (SCT) used to transfer database schemas to new platforms
- How does DMS work?
- It's basically just a server running replication software
- Create a source and target connections
- Schedule tasks to run on DMS server to move data
- AWS creates the tables and primary keys *if they don't exist on the target)
- Optionally create you target tables beforehand
- Leverage the SCT for creating some or all of your tables, indexes, and more
- Source and target data stores are referred to as endpoints
- Important Concepts
- Can migrate between source and target endpoints with the same engine types
- Can also utilize SCT to migrate between source and target endpoints with different engines
- Important to know that at least 1 endpoint most live within an AWS Service
- AWS Schema Conversion Tool (SCT)
- Convert
- Supports many engine types
- Many types of relational databases including both OLAP and OLTP, even supports data warehouses
- Supports many endpoints
- Any supported RDS engine type: Aurora, Redshift
- Can use the converted schemas with dbs running on EC2 or data stored in S3
- So don't have to migrate to a db service, per se, can be EC2 or S3
- 3 Migration Types:
- Full Load
- All existing data is moved from sources to targets in parallel
- Any updates to your tables while this is in progress are cached on your replication server
- Full Load and Change Data Capture (CDC)
- CDC guarantees transactional integrity of the target db- only one
- CDC Only
- Only replicate the data changes from the source db
- Full Load
- Migrating Large Data Stores via AWS Snowball
- With terabyte migrations, can run into bandwidth throttle/network throttles on network
- Can leverage Snowball Edge
- Leverage certain Snowball Edge devices and S3 with DMS to migrate large data sets quickly
- Can still leverage SCT to extract data into Snowball devices and then into S3
- Load converted data
- DMS can still load the extracted data from S3 and migrate to chosen destination
- Also CDC compatible
- Migration tool for relational, Data Warehouses, NoSQL databases, and other data stores
- Replicating and Tracking Migrations with AWS Migration Hub
- Migration Hub
- Single place to discover existing servers, plan migration efforts and track migration statuses
- Visualize connection and server/db statuses that are a part of your migrations
- Options to start migrations immediately or group servers into app groups first
- Integrates with App Migration Service or DMS
- ONLY discovers and plans migrations and works with the other mentioned services to actually do the migrations
- Migration Phases
- Discover- find servers and databases to plan you migrations
- Migrate - connect tools to Migration Hub, and migrate
- Track
- Server Migration Service (SMS)
- Automate migrating on-prem services to cloud
- Flexible - covers broad range of supported VMs
- Works by incremental replications of server VMs over to AWS AMIs that can be deployed on EC2
- Can handle volume replication
- Incremental Testing
- Minimize downtime
- Migration Hub
- Amplify
- For Quickly deploying web apps
- Offers tools for front-end web and mobile developers to quickly build full-stack applications on AWS
- Offers 2 services:
- Amplify Hosting
- Support for common single-pane application (SPA) frameworks like React, Angular, and Vue
- Also supports Gatsby and Hugo static site generators
- Allows for separate prod and staging environments for the frontend and backend
- Support for Server-Side Rendering (SSR) apps like Next.js
- Remember cannot do dynamic websites in S3, so any answer with Server-Side Rendering would be Amplify
- Support for common single-pane application (SPA) frameworks like React, Angular, and Vue
- Amplify Studio
- Easy Authentication and Authorization
- Simplified Development
- Visual development environment to simplify creation of full-stack web or mobile apps
- Ready-to-use components, easy creation of backends and automated connections between the frontend and backend
- Amplify Hosting
- Exam Tip
- Amplify is the answer in scenario based questions like managed server-side rendering in AWS, easy mobile development, and developers running full-stack applications
- Device Farm
- For testing App Services
- Application testing service for testing and interacting with Android, iOS, and web apps on real devices
- 2 primary testing methods:
- Automated
- Upload scripts or use built-in tests for automatic parallel tests on mobile devices
- Remote Access
- You can swipe, gesture, and interact with the devices in real time via web browser
- Automated
- Amazon Pinpoint
- Enables you to engage with customers through a variety of different messaging channels
- Generally used by marketers, business users, and developers
- Terms:
- Projects
- Collection of info, segments, campaigns, and journeys
- Channels
- Platform you intend to engage your audience with
- Segments
- Dynamic or imported; designates which users receive specific messages
- Campaigns
- Initiatives engaging specific audience segments using tailored messages
- Journeys
- Multi-step engagements
- Message Templates
- Content and settings for easily reusing repeated messages
- Projects
- Leverage Machine Learning modules to predict user patterns
- 3 Primary uses:
- Marketing
- Transactions - order confirmations, shipping notifications
- Bulk Communications
- Enables you to engage with customers through a variety of different messaging channels
- Analyzing Text using Comprehend, Kendra, and Textract
- Comprehend
- Uses Natural Language Processing (NLP) to help you understand the meaning and sentiment in your text
- Ex: automate understanding reviews as positive or negative
- Automating comprehension at scale
- Use Cases:
- Analyze call center analytics
- Index and Search product reviews
- Legal briefs management
- Process financial data
- Uses Natural Language Processing (NLP) to help you understand the meaning and sentiment in your text
- Kendra
- Allows you to create an intelligent search service powered by machine learning
- Enterprise search applications - bridge between different silos of information (S3, file servers, websites), allowing you to have all the data intelligently in one place
- Use Cases:
- Research and Development Acceleration
- Improve Customer Interaction
- Minimize Regulatory and Compliance Risks
- Increase Employee productivity
- Can do research for you
- Textract
- Uses Machine Learning to automatically extract text, handwriting, and data from scanned documents
- Goes beyond OCR (Optical Character Recognition) by adding Machine Learning
- Turn text into data
- Use Cases:
- Convert handwritten/filled forms
- Comprehend
- AWS Forecast
- Time-series forecasting service that uses Machine Learning and it built to give you important business insights
- Can send your data to forecast and it will automatically learn your data, select the right Machine Learning algorithm, and then help you forecast your data
- Use cases:
- IoT, DevOps, Analytics
- AWS Fraud Detector
- AWS AI service built to detect fraud in your data
- Create a fraud detection machine learning model that is based on your data - can quickly automate this
- Use Cases:
- Identify suspicious online transactions
- Detect new account fraud
- Prevent Trial and Loyalty program abuse
- Improve account takeover detection
- Working with Text and Speech using Polly, Transcribe, and Lex
- Transcribe
- Speech to text
- Lex
- Build conversational interfaces in your apps using NLP
- Polly
- Turns text into lifelike speech
- Alexa uses: Transcribe → Lex (sends answer/text to) → Polly
- Transcribe
- Rekognition
- Computer vision product that automates the recognition of pictures and video using deep learning and neural networks
- Use these processes to understand and label images and videos
- Main use case is Content Moderation
- Also facial detection and analysis
- Celebrity recognition
- Streaming video events detection
- Ring, ex
- SageMaker
- To train learning models
- Way to build Machine Learning models in AWS Cloud
- 4 Parts
- Ground Truth: set up and manage labeling jobs for training datasets using active learning and human labeling
- Notebook: managed Jupyter notebook (python)
- Training: train and tune models
- Inference: Package and deploy Machine Learning models at scale
- Deployment Types:
- Online Usage- if need immediate response
- Offline Usage- otherwise
- Elastic Inference - used to decrease cost
- Translate
- Machine learning service that allows you to automate language translation
- Uses deep learning and neural networks
- Elastic Transcoder
- For converting media files
- Allows businesses/developers to convert (transcode) media files from original source format into versions that are optimized for various devices
- Benefits:
- Easy to use - APIs, SDKs, or via management console
- Elastically scalable
- AWS Kinesis Video Streams
- Way of streaming media content from a large number of devices to AWS and then running analytics, Machine Learning, and playback and other processing
- Ex: Ring
- Elastically scales
- Access data through easy-to-use APIs
- Use Cases:
- Smart Home- ring
- Smart city- CCTV
- Industrial Automation
- Way of streaming media content from a large number of devices to AWS and then running analytics, Machine Learning, and playback and other processing
NotesSAA-C03
- The shared responsibility model
- Customer is responsible for security IN the loud
- AWS is responsible for security OF the cloud
- 6 Pillars of the Well-Architected Framework
- Operation Excellence
- Running and monitoring systems to deliver business value, and continually improving processes and procedures
- Performance Efficiency
- Using IT and computing resources efficiently
- Security
- Protecting info and systems
- Cost Optimization
- Avoiding unnecessary costs
- Reliability
- Ensuring a workload performs its intended function correctly and consistently
- Sustainability
- Minimizing the environmental impacts of running cloud workloads
- Operation Excellence
- IAM
- To secure the root account:
- Enable MFA on root acct
- Create an admin group for admins and assign appropriate privileges
- Create user accounts for admins - don't share
- Add appropriate users to admin groups
- IAM Policy documents
- JSON - key pairs
- IAM does not work at regional level, it works at global level
- Identity Providers > Federation Services
- AWS SSO
- Can add a provider/configure a provider
- Most common provider type is SAML
- Uses: AD Federation Services
- SAML provider establishes a trust between AWS and AD Federation Services
- Most common provider type is SAML
- IAM Federation
- Uses the SAML standard, which is Active Directory
- How to apply policies:
- EAR: Effect, Action, Resource
- Why are IAM users considered “permanent”?
- Because once their password, access key, or secret key is set, these credentials do not update or change without human interaction
- IAM Roles
- = an identity in IAM with specific permissions
- Temporary
- When you assume a role, it provides you with temporary security credential for your role session
- Assign policy to role
- More secure to use roles instead of credentials - don't have to hardcode credentials
- Preferred option from security perspective
- Can attach/detach roles to running EC2 instances without having to stop or terminate those instances
- To secure the root account:
- Simple Storage Solution
- S3 is object storage
- Manages data as objects rather than in file systems or data blocks
- Any type of file
- Cannot be used to run OS or DB, only static files
- Unlimited S3 storage
- Individual objects can be up to 5 TBs in size
- Universal Namespace
- All AWS accounts share S3 namespace so buckets must be globally unique
- S3 URLS:
- https://bucket-name.s3.Region.amazonaws.com/key-name
- When you successfully upload a file to an S3 bucket, you receive a HTTP 200 code
- S3 works off of a key-Value store
- Key = name of object
- Value = data itself
- Version id
- Metadata
- Lifecycle management
- Versioning
- All versions of an object are stored and can be retrieved, including deleted ones
- Once versioning is enabled, you cannot disable it, only suspend it
- Way to protect your objects from being accidentally deleted
- Turn versioning on
- Enable MFA
- Securing you S3 data
- Server-Side Encryption
- Can set default encryption on a bucket to encrypt all new objects when they are stored in that bucket
- Access Control Lists (ACLs)
- Define which AWS accounts or groups are granted access and type of access
- Way to get fine-grained access control - can assign ACLS to individual objects within a bucket
- Bucket Policies
- Bucket-wide policies that define what actions are allowed or denied on buckets
- In JSON format
- Server-Side Encryption
- Data Consistency Model with S3
- Strong Read-After-Write Consistency
- After a successful write of a new object (PUT) or an overwrite of an existing object, any subsequent read request immediately receives the latest version of the object
- Strong consistency for list operations, so after a write, you can immediately perform a listing of the objects in a bucket with all changes reflected
- Strong Read-After-Write Consistency
- ACLs vs Bucket Policies
- ACLs
- Work at an individual object level
- Ie: public or private object
- Bucket Policies
- Apply bucket-wide
- ACLs
- Storage Classes in S3
- S3 standard
- Default
- Redundantly across greater than or equal to 3 AZs
- Frequent access
- S3 Standard - Infrequently Accessed (IA)
- Infrequently accessed data, but data must be rapidly accessed when needed
- Pay to access data - per GB storage price and per-GB retrieval fee
- S3 One Zone - IA
- Like S3 standard IA but data is stored redundantly within single AZ
- Great for long-lived, IA NON critical data
- S3 Intelligent Tiering
- 2 Tiers:
- Frequent Access
- Infrequent Access
- Optimizes Costs - automatically moves data to most cost-effective tier
- 2 Tiers:
- Glacier
- Way of archiving your data long-term
- Pay for each time you access your data
- Cheap storage
- 3 Glacier options:
- Glacier Instant Retrieval
- S3 standard
- S3 is object storage
Long-term data archiving with instant retrieval
- Glacier Flexible Retrieval
Ideal storage class for archive data that does not require immediate access but needs the flexibility to retrieve large data sets at no cost,m such as backup or DR
Retrieval -minutes to 12 hours
- Glacier Deep Archive
Cheapest
Retain data sets for 7-10 years or longer to meet customer needs and regulatory requirements
Retrieval is 12 hours for standard and 48 hours for bulk
- Lifecycle mgmt in S3
- Automates moving objects between different storage tiers to max cost-effectiveness
- Can be used with versioning
- S3 Object Lock
- Can use object lock to store objects using a Write Once Read Many (WORM) model
- Can help prevent objects from being deleted or modified for a fixed amount of time OR indefinitely
- 2 modes of S3 Object Lock:
- Governance Mode
- Users cannot overwrite or delete an object version or alter its lock settings unless they have special permissions
- Compliance Mode
- A protected object version cannot be overwritten or deleted by any user
- When object is locked in compliance mode, its retention cannot be changed/object cannot be overwritten/deleted for duration of period
- Retention Period:
- Governance Mode
- Can use object lock to store objects using a Write Once Read Many (WORM) model
- Lifecycle mgmt in S3
Protect an object version for a fixed period of time
- Legal Holds:
Enables you to place a lock/hold on an object without an expiration period- remains in effect until removed
- Glacier Vault Locks
- Easily deploy and enforce compliance controls for individual Glacier vaults with a vault lock policy
- Can specify controls, such as WORM, in a vault lock policy and lock the policy from future edits
- Once locked, the policy can no longer be changed
- S3 Encryption
- TYpes of encryption available:
- Encryption in transit
- HTTPS-SSL/TLS
- Encryption at rest: Server Side Encryption
- Enabled by default with SSE-S3
- Encryption in transit
- TYpes of encryption available:
- Glacier Vault Locks
This setting applies to all objects within S3 buckets
If the file is to be encrypted at upload time, the x-amz-server-side-encryption parameter will be included in the request header
You can create a bucket policy that denies any s3 PUT (upload) that does not include this parameter in the request header
- 3 Types:
SSE-S3
S3-managed keys, using AES 256-bit encryption
Most common
SSE-KMS
AWS key mgmt service-managed keys
If you use SSE-KMS to encrypt you objects in S3, you must keep in mind the KMS region limits
Uploading AND downloading will count towards the limit
SSE-C
Customer-provided keys
- Encryption at rest: Client-Side Encryption
- You encrypt the files yourself before you upload them to S3
- Encryption at rest: Client-Side Encryption
- More folders/subfolder you have in S3, the better the performance
- S3 Performance:
- Uploads
- Multipart Uploads
- Recommended for files over 100 MB
- Required for files over 5GB
- = Parallelize uploads to increase efficiency
- Multipart Uploads
- Downloads
- S3 Byte-Range Fetches
- Parallelize downloads by specifying byte ranges
- If there is a failure in the download, it is only for that specific byte rance
- Used to speed up downloads
- Can be used to download partial amounts of a file - for ex: header info
- S3 Byte-Range Fetches
- Uploads
- S3 Replication
- Can replicate objects from one bucket to another
- Versioning MUST be enabled on both buckets (source and destination buckets)
- Turn on replication, then replication is automatic afterwards
- S3 Bach Replication
- Allows replication of existing objects to different buckets on demand
- Delete markers are NOT replicated by default
- Can enable it when creating the replication rule
- EC2: Elastic Cloud Compute
- Pricing Options
- On-Demand
- Pay by hour or second, depending on instance
- Flexible - low cost without upfront cost or commitment
- Use Cases:
- Apps with short-term, spikey, or unpredictable workloads that cannot be interrupted
- Compliance
- Licencing
- Reserved
- For 1-3 years
- Up to 72% discount compared to on-demand
- Use Cases:
- Predictable usage
- Specific capacity requirements
- Types of RIs:
- Standard RIs
- Convertible RIs
- On-Demand
- Pricing Options
Up to 54% off on-demand
You have the option to change to a different class of RI type of equal or greater value
- Scheduled RIs
Launch within timeframe you define
Match your capacity reservation to a predictable recurring schedule that only requires a fraction of day/wk/mo
- Reserved Instances operate at a REGIONAL level
- Spot
- Purchase unused capacity at a discount of up to 90%
- Prices fluctuate with supply and demand
- Say which price you want the capacity at and when it hits that price, you have your instance, when it moves away from that price, you lose it
- Use Cases:
- Flexible start and end times
- Cost sensitive
- Urgent need for large amounts of additional capacity
- Spot Fleet
- A collection of spot instances and (optionally) on-demand instances
- Attempts to launch that number of spot instances and on-demand instances to meet the target capacity you specified
It is fulfilled if there is available capacity and the max price you specified in the request exceeds the spot price
Launch pools - different details on when to launch
- 4 strategies with spot fleets available:
Capacity optimized
Spot instances come from the pool with optimal capacity for the number of instances launched
Diversified
Spot instances are distributed across all pools
Lowest price
Spot instances come from the pool with the lowest price
This is the default strategy
InstancePoolsToUseCount
Distributed across the number of spot instance pools you specify
This parameter is only valid when used in combo with lowestPrice
- Dedicated
- Physical EC2 server dedicated for your use
- Most expensive
- Dedicated
- Pricing Calculator
- Can use to estimate what your infrastructure will cost in AWS
- Bootstrap Scripts
- Script that runs when the instance first runs, has root privileges
- Starts with a shebang : #!/bin/bash
- EC2 Metadata
- Can use curl command in bootstrap to save metadata into a text file, for example
- Networking with EC2
- 3 different types of networking cards
- Elastic Network Interface (ENI)
- For basic, day-to-day networking
- Use cases:
- Elastic Network Interface (ENI)
- 3 different types of networking cards
Create a management network
Use network and security appliances in VPC
Create dual-homed instances with workloads and roles on distinct subnets
Create a low budget, HA solution
- EC2s by default will have ENI attached to it
- Enhanced Networking (EN)
- For single root I/O virtualization (SR-10V) to provide high performance
- For high performance networking between 10 Gbps-100 Gbps
- Types of EN
Elastic Network Adapter (ENA)
Supports network speeds of up to 100 Gbps for supported instance types
Intel 82599 Virtual Function (VF) Interfaces
Used in Older instances
Always choose ENA over VF
- Elastic Fabric Adapter (EFA)
- Accelerates High performance Computing (HPC) and ML apps
- Can also use OS-Bypass
- Elastic Fabric Adapter (EFA)
Enables HPC and ML apps to bypass the OS Kernal and communicate directly with the EFA device - only linux
- Optimizing EC2 with Placement Groups
- 3 types of placement groups
- Cluster Placement Groups
- Grouping of instances within a single AZ
- Recommended for apps that need low network latency, high network throughput or both
- Only certain instance types can be launched into a cluster PG
- Cannot span multiple AZs
- AWS recommends homogenous instances within cluster
- Spread Placement Group
- Each placed on distinct underlying hardware
- Recommended for apps that have small number of critical instances that should be kept separate
- Used for individual instances
- Can span multiple AZs
- Partition Placement Group
- Each partition PG has its own set of racks, each rack has its own network and power source
- No two partitions within PG share the same racks, allowing you to isolate impact of HW failure
- EC2 divides each group into logical segments called partitions (basically = a rack)
- Can span multiple AZs
- Cluster Placement Groups
- You can't merge PGs
- You can move an existing instance into a PG
- Must be in stopped state
- Has to be done via CLI or SDK
- 3 types of placement groups
- EC2 Hibernation
- When you hibernate an EC2 instance, the OS is told to perform suspend-to-disk
- Saves the contents from the instance memory (RAM)to your EBS root volume
- We persist the instance EBS root volume and any attached EBS data volumes
- Instance RAM must be less than 150GB
- Instance families include - C, M, and R instance families
- Available for Windows, Linux 2 AMI, Ubuntu
- Instances cannot be hibernated for more than 60 days
- Available for on-demand and reserved instances
- When you hibernate an EC2 instance, the OS is told to perform suspend-to-disk
- Deploying vCenter in AWS with VMWare Cloud on AWS
- Used by orgs for private cloud deployment
- Use Cases - why VMWare on AWS
- Hybrid Cloud
- Cloud Migration
- Disaster Recovery
- Leverage AWS Services
- AWS Outposts
- Brings the AWS data center directly to you, on-prem
- Allows you to have AWS services in your data center
- Benefits:
- Allows for hybrid cloud
- Fully managed by AWS
- Consistency
- Outposts Family members
- Outposts Racks - large
- Outposts Servers - smaller
- Optimizing EC2 with Placement Groups
- Elastic Block Storage
- Elastic Block Storage
- Virtual disk, storage volume you can attach to EC2 instances
- Can install all sorts, use like any system disk, including apps, OS’s, run DBs, store data, create file systems
- Designed for mission critical workloads - HA and auto replicated within single AZ
- Different EBS Volume Types
- General Purpose SSD
- gp2/3
- Balance of prices and performance
- Good for boot volumes and general apps
- Provisioned IOPS SSD (PIOPS)
- io1/2
- Super fast, high performance, most expensive
- IO intensive apps, high durability
- Throughput Optimized HDD (ST1)
- Low-cost HDD volume
- Frequently accessed, throughput-intensive workloads
- Throughput = used more for big data, data warehouses, ETL, and log processing
- Cost effective way to store mountains of data
- CANNOT be a boot volume
- Cold HDD (SC1)
- Lowest cost option
- Good choice for colder data requirement fewer scans/day
- Good for apps that need lowest cost and performance is not a factor
- CANNOT be a boot volume
- Only static images, file system
- General Purpose SSD
- IOPS vs Throughput
- IOPS
- Measures the number of read and write Operations/second
- Important for quick transactions, low-latency apps, transactional workloads
- Choose provisioned IOPS SSD (io1/2)
- Throughput
- Measures the number of bits read or written per sec (MB/s)
- Important metrics for large datasets, large IO sizes, complex queries
- Ability to deal with large datasets
- Choose throughput optimized HDD (ST1)
- IOPS
- Volumes vs Snapshots
- Volumes exist on EBS
- Must have a minimum of 1 volume per EC2 instance - called root device volume
- Snapshots exist on S3
- Point in time copy of a volume
- Are incremental
- For consistent snapshots: stop instance
- Can only share snapshots within region they were created, if want to share outside, have to copy to destination region first
- Volumes exist on EBS
- Things to know about EBS’s:
- Can resize on the fly, just resize the filesystem
- Can change volume types on the fly
- EBS will always be in the same AZ as EC2
- If we stop an instance, data is kept on EBS disk
- EBS volumes are NOT encrypted by default
- EBS Encryption
- Uses KMS customer master keys (CMK) when creating encrypted volumes and snapshots
- Data at rest is encrypted in volume
- Data inflight between instance and volume is encrypted
- All volumes created from the snapshot are encrypted
- End-to-end encryption
- Important to remember: copying an unencrypted snapshot allows encryption
- 4 steps to encrypt an unencrypted volume:
- Create a snapshot of the unencrypted volume
- Create a copy of the snapshot and select the encrypt option
- Create an AMI from the encrypted snapshot
- Use that AMI to launch new encrypted instances
- 4 steps to encrypt an unencrypted volume:
- Elastic Block Storage
- Elastic File System (EFS)
- Managed NFS (Network File System) that can be mounted on many EC2 instances
- Shared storage
- EFS are NAS files for EC2 instances based on Network File System (NFSv4)
- EC2 has a mount target that connects to the EFS
- Use Cases:
- Web server farms, content mgmt systems, shared db access
- Uses NFSv4 protocol
- Linux-Based AMIs only (not windows)
- Encryption at rest with KMS
- Performance
- Amazing performance capabilities
- 1000s concurrent connections
- 10 Gbps throughput
- Scales to petabytes
- Set the performance characteristics:
- General Purpose - web servers, content management
- Max I/O - big data, media processing
- Storage Tiers for EFS
- Standard - frequently accessed files
- Infrequently Accessed
- FSx For Windows
- Provides a fully managed native Microsoft Windows file system so you can easily move your windows-based apps that require file storage to AWS
- Built on Windows servers
- If see anything regarding:
- sharepoint service
- shared storage for windows
- Active directory migration
- Managed Windows Server that runs windows server message block (SMB) - based file services
- Supports AD users, ACLs, groups, and security policies, along with Distributed File System (DFS) namespaces and replication
- FSx for Lustre:
- Managed file system that is optimized for compute-intensive workloads
- Use Cases:
- High performance computing, AI, ML, Media Data processing workflows, electronic design automation
- With a Lustre, you can launch and run a Lustre file system that can process massive datasets at up to 100s of Gbps of throughput, millions of IOPS, and sub-millisec latencies
- When To pick EFS vs FSx for Windows vs FSx for Lustre
- EFS
- Need distributed, highly resilient storage for Linux
- FSx for Windows
- Central storage for windows (IIS server, AD, SQL Server, Sharepoint)
- FSx for Lustre
- High speed, high-capacity, AI, ML
- IMPORTANT: Can store data directly on S3
- EFS
- Amazon Machine Images: EBS vs Instance Store
- An AMI provides the info required to launch an instance
- *AMIs are region-specific
- 5 things you can base your AMIs on:
- Region
- OS
- Architecture (32 vs 64-bit)
- Launch permissions
- Storage for the root device (root volume)
- All AMIs are categorized as either backed by one of these:
- EBS
- The root device for an instance launched from the AMI is an EBS volume created from EBS snapshot
- CAN be stopped
- Will not lose data if instance is stopped
- By default, root volume will be deleted on termination, but you can tell AWS to keep the deleted root volume with EBS volume
- PERMANENT storage
- Instance Store
- Root device for an instance launched from the AMI is an instance store volume created from a template stored in S3
- Are ephemeral storage
- Meaning they cannot be stopped
- If underlying host fails, you will lose your data
- EBS
CAN reboot your data without losing your data
- If you delete your instance, you will lose the instance store volume
- AWS Backup
- Allows you to consolidate your backups across multiple AWS Services such as EC2, EBS, EFS, FSx for Lustre, FSx for Windows file server and AWS Storage Gateway
- Backups can be used with AWS Organizations to backup multiple AWS accounts in your org
- Gives you centralized control across all services, in multiple AWS accounts across the entire AWS org
- Benefits
- Central management
- Automation
- Improved Compliance
- Policies can be enforced, and encryption
- Auditing is easy
- Relational Database Service
- 6 different RDS engines
- SQL Server
- Oracle
- MySQL
- PostgreSQL
- MariaDB
- Aurora
- When to use RDS’s:
- Generally used for Online Transaction Processing (OLTP) workloads
- OLTP: transaction
- Large numbers of small transactions in real-time
- Different than OLAP (Online Analytical Processing)
- OLAP:
- OLTP: transaction
- Generally used for Online Transaction Processing (OLTP) workloads
- 6 different RDS engines
Processes complex queries to analyze historical data
All about data analysis using large amounts of data as well as complex queries that take a long time
RDS’s are NOT suitable for this purpose → data warehouse option like Redshift which is optimized for OLAP
- Multi-AZ RDSs
- Aurora cannot be single AZ
- All others can be configured to be multi-AZ
- Creates an exact copy of your prod db in another AZ, automatically
- When you write to your prod db, this write will automatically synchronize to the standard db
- Unplanned Failure or Maintenance:
- Amazon auto detects any issues and will auto failover to the standby db via updating DNS
- Multi-AZ is for DISASTER RECOVERY, not for performance
- CANNOT connect to standby db when primary db is active
- Aurora cannot be single AZ
- Increase read performance with read replicas
- Read replica is a read-only copy of the primary db
- You run queries against the read-only copy and not the primary db
- Read replicas are for PERFORMANCE boosting
- Each read replica has its own unique DNS endpoint
- Read replicas can be promoted as their own dbs, but it breaks the replication
- For analytics for example
- Multiple read replicas are supported = up to 5 to each db instance
- Read replicas require auto backups to be turned on
- Aurora
- MySQL and Postgre-compatible RD engine that combines speed and availability of high-end commercial dbs with the simplicity and cost-effectiveness of open-source db
- 2 copies of data in each AZ with minimum of 3 AZs → 6 copies of data
- Aurora storage is self-healing
- Data blocks and disks are continuously scanned for errors and repaired automatically
- 3 types of Aurora Replicas Available:
- Aurora Replicas = 15 read replicas
- MySQL Replicas = 5 read replicas with Aurora MySQL
- PostgreSQL = 5 read replicas with Aurora PostgreSQL
- Aurora Serverless
- An on-demand, auto-scaling configuration for the MySQL-compatible and PostgreSQL-compatible editions of Aurora
- An Aurora serverless db cluster automatically starts up, shuts down, and scales capacity up or down based on your app’s needs
- Use Cases:
- For spikey workloads
- Relatively simple, cost-effective option for infrequent, intermittent, or unpredictable workloads
- Multi-AZ RDSs
- DynamoDB
- Proprietary NON-relational DB
- Fast and flexible NoSQL db service for all applications that need constant, single-digit millisecond latency at any scale
- Fully managed db and supports both document and key-value data modules
- Use Cases:
- Flexible data model and reliable performance make it great fit for mobile, web, gaming, ad-tech, IoT, etc
- 4 facts on DynamoDB:
- All stored on SSD Storage
- Spread across 3 geographically distinct data center
- Eventually consistent reads by default
- This means that all copies of data is usually reached within a second. Repeating a read after a short time should return the updated data. Best read performance
- Can opt for strongly consistent reads
- This means that all copies return a result that reflects all writes that received a successful response prior to that read
- DynamoDB Accelerator (DAX)
- Fully managed, HA, in-memory cache
- 10x performance improvement
- Reduces request time from milliseconds to microseconds
- Compatible with DynamoDB API calls
- Sits in front of DynamoDB
- DynamoDB Security
- Encryption at rest with KMS
- Can connect with site-to-site VPN
- Can connect with Direct Connect (DX)
- Works with IAM policies and roles
- Fine-grained access
- Integrates with CloudWatch and CloudTrail
- VPC endpoints-compatible
- DynamoDB Transactions
- ACID Diagram/Methodology
- Atomic
- All changes to the data must be performed successfully or not at al
- Consistent
- Data must be in a constant state before and after the transaction
- Isolated
- No other process can change the data while the transaction is running
- Durable
- The changes made by a transaction must persist
- Atomic
- ACID basically means if anything fails, it all rolls back
- DynamoDB transactions provide developers ACID across 1 or more tables within a single aws acct and region
- You can use transactions when building apps that require coordinated inserts, deletes, or updates to multiple items as part of a single logical business operation
- DynamoDB transactions have to be enabled in DynamoDB to use ACID
- Use Cases:
- Financial Transactions, fulfilling orders
- 3 options for reads
- Eventual consistency
- Strong consistency
- Transactional
- 2 options for writes:
- Standard
- Transactional
- ACID Diagram/Methodology
- DynamoDB Backups
- On-Demand Backup and Restore
- Point-In-Time Recovery (PITR)
- Protects against accidental writes or deletes
- Restore to any point in the last 35 days
- Incremental backups
- NOT enabled by default
- Latest restorable: 5 minutes in the past
- DynamoDB Streams
- Are time-ordered sequence of item-level changes in a table (FIFO)
- Data is completely sequenced
- These sequences are stored in DynamoDB Streams
- Stored for 24 hours
- Sequences are broken up into shards
- A shard is a bunch of data that has sequential sequence numbers
- Everytime you make a change to DynamoDB table, that change is going to be stored sequentially in a stream record, which is broken up into shards
- Can combine streams with Lambda functions for functionality like stored procedures
- DynamoDB Global Tables
- Managed multi-master, multi-region replication
- Way of replicating your DynamoDB tables from one region to another
- Great for globally distributed apps
- This is based on DynamoDB streams
- Streams must be turned on to enable Global Tables
- Multi-region redundancy for disaster recovery or HA
- Natively built into DynamoDB
- Mongo-DB-compatible DBs in Amazon DocumentDB
- DocumentDB
- Allows you to run MongoDB in the AWS cloud
- A managed db service that scales with your workloads and safely and durably stores your db info
- NoSQL
- Direct move for MongoDB
- Cannot run Mongo workloads on DynamoDB so MUST use DocumentDB
- DocumentDB
- Amazon Keyspaces
- Run Apache Cassandra Workloads with Keyspaces
- Cassandra is a distributed (runs on many machines) database that uses NoSQL, primarily for big data solutions
- Keyspaces allows you to run cassandra workloads on AWS and is fully managed and serverless, auto-scaled
- Amazon Neptune
- Implement GraphDBs - stores nodes and relationships instead of tables or documents
- Amazon Quantum Ledger DB (QLDB)
- For Ledger DB
- Are NoSQL dbs that are immutable, transparent, and have a cryptographically verifiable transaction log that is owned by one authority
- QLDB is fully managed ledger db
- For Ledger DB
- Amazon Timestream
- Time-series data are data points that are logged over a series of time, allowing you to track your data
- A serverless, fully managed db service for time-series data
- Can analyze trillions of events/day up to 1000x faster and at 1/10th the cost of traditional RDSs
- Virtual Private Cloud (VPC) Networking
- VPC Overview
- Virtual data center in the cloud
- Logically isolated part of AWS cloud where you can define your own network with complete control of your virtual network
- Can additionally create a hardware VPN connection between your corporate data center and your VPC and leverage the AWS cloud as an extension of your corporate data center
- Attach a Virtual Private Gateway to our VPC to establish a VPN and connect to our instances over private corporate data center
- By default we have 1 VPC in each region
- What can we do with a VPC
- Use route table to configure between subnets
- Use Internet Gateway to create secure access to internet
- Use Network Access Control Lists (NACLs) to block specific IP addresses
- Default VPC
- User friendly
- All subnets in default VPC have a route out to the internet
- Each EC2 instance has a public and private IP address
- Has route table and NACL associated with it
- Custom VPC
- Steps to set up a VPC Connection:
- Choose IPv4 CIDER
- Note: first 4 IP addresses and last IP address in CIDR block are reserved by Amazon
- Choose Tenancy
- By default, creates:
- Security Group
- Route Table
- NACL
- Create subnet associations
- Create internet gateway and attach to VPC
- Set up route table with route out to internet
- Associate subnet with VPC
- Create Security group
- With inbound, outbound rules
- Associate EC2 instance with Security Group
- Choose IPv4 CIDER
- VPC Overview
- Using NAT Gateways for internet access within private subnet
- For example, we need to patch db server
- NAT Gateway:
- You can use Network Access Translation (NAT) gateway to enable instances in a private subnet to connect to the internet or other AWS services while preventing the internet from initiating a connection with those instances
- How to do this:
- Create a NAT Gateway in our public subnet
- Allow our EC2 instance (in private subnet) to connect to the NAT Gateway
- 5 facts to remember:
- Redundant inside the AZ
- Starts at 5 Gbps and scales to 45 Gbps
- No need to patch
- Not associated with any security groups
- Automatically assigned a public IP address
- Security Groups
- Are virtual firewalls for EC2 instances
- By default, everything is blocked
- Are stateful - this means that if you send a request from your instance, the response traffic for that request is allowed to flow in, regardless of inbound security group rules
- Ie: responses to allowed inbound traffic are allowed to flow out regardless of outbound rules
- Are virtual firewalls for EC2 instances
- Network ACLs
- Are frontline of defense, optional layer of security for your VPC that acts as a firewall for controlling traffic in and out of one or more subnets
- You may match NACL rules similar to Security Groups as an added layer of security
- Overview:
- Default NACLs
- VPC automatically comes with default NACL and by default it allows all inbound and outbound traffic
- Custom NACLs
- By default block all inbound and outbound traffic until you add rules
- Each subnet in your VPC must be associated with a NACL
- If you don't explicitly associate a subnet with a NACL, the subnet is auto associated with the default NACL
- Can associate a NACL with multiple subnets, but each subnet can only have a single NACL associated with it at a time
- Have separate inbound and outbound NACLs
- Default NACLs
- Block IP addresses with NACLs NOT with Security Groups
- NACLs contain a numbered list of rules that are evaluated in order, starting with lowest numbered rule
- Once a match is found, stop going through list
- If you want to deny a single IP address, you have to deny FIRST before you allow all
- NACLs are stateless
- This means that responses to allowed inbound traffic are subject to the rules for outbound traffic and visa versa
- NACLs contain a numbered list of rules that are evaluated in order, starting with lowest numbered rule
- VPC Endpoints
- Enables you to privately connect your VPC to supported AWS services and VPC endpoint services powered by PrivateLink without requiring an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection
- Like a NAT gateway but it doesnt use the public internet, it uses Amazon’s backbone network - stays within AWS environment
- Endpoints are virtual devices
- Horizontally scaled, redundant, and HA VPC components that allow communication between instances on your VPC and services without imposing availability risks or bandwidth constraints on your network traffic
- Remember that NAT gateways have 5-45 Gbps restriction - you dont want that restriction if you have an EC2 instance writing to S3, so you may have it go through the virtual endpoint (VPC endpoint)
- 2 Types of endpoints:
- Interface Endpoint
- An ENI with a private IP address that serves as an entry point for traffic headed to a supported service
- Gateway Endpoint
- Similar to NAT gateway
- Virtual device that supports connection to S3 and DynamoDB
- Interface Endpoint
- Use Case: you want to connect to AWS services without leaving the Amazon internal network = VPC endpoint
- VPC Peering
- Allows you to connect 1 VPC with another via a direct network route using private IP addresses
- Instances behave as if they were on the same private network
- Can peer VPCs with other AWS accounts as well as other VPCs in same account
- Can peer between regions
- Is in a star configuration with one central VPC
- No transitive peering
- Cannot have overlapping CIDR address ranges between peered VPCs
- Allows you to connect 1 VPC with another via a direct network route using private IP addresses
- PrivateLink
- Opening up your services in a VPC to another VPC can be done in two ways:
- Open VPC up to internet
- Use VPC Peering - whole network is accessible to peer
- Best way to expose a service VPC to tens, hundreds, thousands of customer VPC is through PrivateLink
- Does Not require peering, no route tables, no NAT gateways, no internet gateways, etc
- DOES require a Network Load Balancer on the service VPC and and ENI on the customer VPC
- Opening up your services in a VPC to another VPC can be done in two ways:
- CloudHub
- Useful if you have multiple sites, each with its own VPN connection, use CH to connect those sites together
- Overview:
- Hub and spoke model
- Low cost and easy to manage
- Operates over public internet, but all traffic between customer gateway and CloudHub is encrypted
- Essentially aggregating VPN connections to single entry point
- Direct Connect (DX)
- A cloud service solution that makes it easy to establish a dedicated network connection from your premises to AWS
- Private connectivity
- Can reduce network costs, increase bandwidth throughput, and provide a more consistent network experience than internet-based connections
- Instead of VPN
- Two types of Direct Connect Connections:
- Dedicated Connection
- Physical ethernet connection associated with a single customer
- Hosted Connection
- Physical ethernet connection that an AWS Direct Connect Partner (verizon, etc) provisions on behalf of a customer
- Dedicated Connection
- Transit Gateway
- Connects VPCs and on-prem networks through a central hub
- Simplifies network by ending complex peering relationships
- Acts as a cloud router - each connection is only made once
- Connect VPCs to Transit Gateway
- Everything connected to TG will be able to talk directly
- Facts
- Allows you to have transitive peering between thousands of VPCs and on-prem datacenters
- Works on regional basis, but can have it across multiple regions
- Can use it across multiple AWS account using RAM (Resource Access Manager)
- Use route table to limit how VPCs talk to one another
- Supports IP Multicast which is not supported by any other AWS Service
- Wavelength
- Embeds AWS compute and storage service within 5G networks, providing mobile edge computing infrastructure for developing, deploying, and scaling ultra-low-latency applications
- Route53
- Overview
- Domain Registrars: are authorities that can assign domain names directly under one or more top-level Domain
- Common DNS Record Types
- SOA: Start Of Authority Record
- Stores info about:
- Name of server that supplied the data for the zone
- Administrator of the zone
- Current version of the data file
- The default number of seconds for the TTL file on resource records
- How it works:
- Starts with NS (Name Server) records
- Stores info about:
- SOA: Start Of Authority Record
- Overview
NS records are used by top-level domain servers to direct traffic to the content DNS server that contains the authoritative DNS records
- So browser goes to top level domain first (.com) and will look up ‘ACG’,
- TLD will give the browser an NS record where the SOA will be stored
- Browser will browse over to the NS records and get SOA
- Start of Authority contains all of our DNS records
- A Record (or address record)
- The fundamental type of DNS record
- Used by a computer to translate the name of the domain to an IP address
- Most common type of DNS record
- TTL = time to live
- Length that a DNS record is cached on either the resolving server or the user’s own local PC
- The lower the TTL, the faster changes to DNS records take to propagate through the internet
- CNAME
- Canonical name can be used to resolve one domain name to another
- Ex m.acg.com and mobile.acg.com resolve to same
- Canonical name can be used to resolve one domain name to another
- Alias Records
- Used to map resource sets in your hosted zone to load balancers, CloudFront distros, or S3 buckets that are configured as websites
- Works like a CNAME record in that it can map one dns name to another, but
- CNAMES cannot be used for naked domain names/zone apex record
- Alias Records CAN be used to map naked domain names/zone apex record
- Route53 Overview
- Amazon’s DNS service, that allows you to register domain names, create hosted zones, and manage and create DNS records
- 7 Routing Policies available with Route53:
- Simple Routing Service
- Can only have one record with multiple IP addresses
- If you specify multiple values in a record, route53 returns all values to the user in a random order
- Weighted Routing Policy
- Allows you to split your traffic based on assigned weights
- Health Checks
- Simple Routing Service
Can set health checks on individual record sets/servers
So if a record set/server fails a health check, it will be removed from route53 until it passes the check
While it is down, no traffic will be routed to it, but will resume when it passes
- Create a health check for each weighted route that we are going to create to monitor the endpoint, monitor by IP address
- Failover Routing Policy
- When you want to create an active/passive setup
- Route53 will monitor the health of your primary site using health checks and auto-route traffic if primary site fails the check
- Geolocation Routing
- Lets you choose where your traffic will be sent based on the geographical location of your users
- Based on the location from which DNS queries originate; the end location of your user
- Geoproximity Routing Policy
- Can route traffic flow to build a routing system that uses a combo of:
Geographic location
Latency
Availability to route traffic from your users to your close or on-prem endpoints
- Can build from scratch or use templates and customize
- Latency Routing Policy
- Allows you to route your traffic based on the lowest network latency for your end user
- Create a latency resource record set for the EC2 (or ELB) resource in each region that hosts your website
When route53 receives a query for your site, it selects the latency resource record set for the region that gives you the lowest latency
- Multivalue Answer Routing Policy
- Lets you configure route53 to return multiple values, such as IP addresses for your web server, in response to DNS queries
- Basically similar to simple routing, however, it allows you to put health checks on each record set
- Multivalue Answer Routing Policy
- Elastic Load Balancers (ELBs)
- Auto distributes incoming traffic across multiple targets
- Can also be done across AZs
- 3 types of ELBs
- Application Load Balancer
- Best suited for balancing of HTTP and HTTPs Traffic
- Operates at layer 7
- Application-aware load balancer
- Intelligent load balancer
- Network Load Balancer
- Operates at the connection level (Level 4)
- Capable of handling millions of requests/sec, low latencies
- A performance load balancer
- Classic Load Balancer
- Legacy load balancer
- Can load balance HTTP/HTTPs applications and use Layer-7 specific features such as X-forwarded and sticky sessions
- For Test/Dev
- Application Load Balancer
- ELBs can be configured with Health Checks
- They periodically send requests to the load balancer’s registered instances to test their states [InService vs OutOfService returns]
- Application Load Balancers
- Layer 7, App-Aware Load Balancing
- After the load balancer receives a request, it evaluates the listener rules in priority order to determine which rule to apply and then selects a target from the target group for the rule action
- Listeners
- A listener checks for connection requests from clients when using the protocol and port you configure
- You define the rules that determine how the load balancer routes requests to its registered targets
- Each rule consists of priority, one or more actions, and one or more conditions
- Rules
- When conditions of rule are met, actions are performed
- Must define a default rule for each listener
- Target Group
- Each target group routes requests to one or more registered targets using the protocol and port you specify
- Path-Based Routing
- Enable path patterns to make load balancing decisions based on path
- /image → certain EC2 instance
- Limitations of App Load Balancers:
- Can ONLY support HTTP/HTTPS listeners
- Can enable sticky sessions with app load balancers, but traffic will be sent at the target group level, not specific EC2 instance
- Layer 7, App-Aware Load Balancing
- Network Load Balancer
- Layer 4, Connection layer
- Can handle millions of requests/sec
- When network load balancer has only unhealthy registered targets, it routes requests to ALL the registered targets - known as fail-open mode
- How it works
- Connection request received
- Load balancer selects a target from the target group for the default rule
- It attempts to open a TCP connection to the selected target on the port specified in the listener configuration
- Listeners
- A listener checks for connection requests from clients using the protocol and port you configure
- The listener on a network load balancer then forwards the request to the target group
- Connection request received
- Auto distributes incoming traffic across multiple targets
There are NO rules, unlike the Application load balancers - cannot do intelligent routing at level 4
- Target Groups
- Each target group routes requests to one or more registered targets
- Supported protocols: TCP, TLS, UDP, TCP_UDP
- Encryption
- You can use a TLS listener to offload the work of encryption and decryption to your load balancer
- Target Groups
- Use Cases:
- Best for load balancing TCP traffic when extreme performance is required
- Or if you need to use protocols that aren't supported by app load balancer
- Classic Load Balancer
- Legacy
- Can load balance HTTP/HTTPs apps and use Layer 7-spec features
- Can also use strict layer 4 load balancing for apps that rely purely on TCP protocol
- X-Forwarded-For Header
- When traffic is sent from a load balancer, the server access logs contain the IP address of the proxy or load balancer only
- To see the original IP address of the client the x-forwarded-for request header is used
- Gateway Timeouts with Classic load balancer
- If your application stops responding, the classic load balancer responds with a 504 error
- This means that the application is having issue
- Means the gateway has timed out
- If your application stops responding, the classic load balancer responds with a 504 error
- Sticky Sessions
- Typically the classic load balancer routes each request independently to the registered EC2 instance with smallest load
- But with sticky sessions enabled, user will be sent to the same EC2 instance
- Problem could occur if we remove one of our EC2 instances while the user still has a sticky session going
- Load balancer will still try to route our user to that EC2 instance and they will get an error
- To fix this, we have to disable sticky sessions
- Deregistration Delay
- Aka Connection Draining with Classic load balancers
- Allows load balancers to keep existing connections open if the EC2 instances are deregistered or become unhealthy
- Can disable this if you want your load balancer to immediately close connections
- CloudWatch
- Monitoring and observability platform to give us insight into our AWS architecture
- Features
- System metrics
- The more managed a service is, the more you get out of the box
- Application Metrics
- By installing CloudWatch agent, you can get info from inside your EC2 instances
- Alarms
- No default alarms
- Can create an alarm to stop, terminate, reboot, or recover EC2 instances
- System metrics
- 2 kinds of metrics:
- Default
- CPU util, network throughput
- Custom
- Will need to be provided with CloudWatch agent installed on the host and reported back to CloudWatch because AWS cannot see past the hypervisor level for EC2 instances
- Ex: EC2 memory util, EBS storage capacity
- Default
- Standard vs Detailed monitoring
- Standard/Basic monitoring for EC2 provides metrics for your instances every 5 minutes
- Detailed monitoring provides metrics every 1 minute
- A period is the length of time associated with a specific CloudWatch stat - default period is 60 seconds
- CloudWatch Logs
- Tool that allows you to monitor, store, and access log files from a variety of different sources
- Gives you the ability to query your logs to look for potential issues or relevant data
- Terms:
- Log Event: data point, contains timestamp and data
- Log Stream: collection of log events from a single source
- Log Group: collection of log streams
- Ex may group all Apache web server host logs
- Features:
- Filter Patterns
- CloudWatch Log Insights
- Allows you to query all your logs using SQL-like interactive solution
- Alarms
- What services act as a source for CloudWatch logs?
- EC2, Lambda, CloudTrend, RDS
- CloudWatch is our go-to log tool, except for if the exam asks for a real-time solution (then it will be kinesis)
- Amazon Managed Grafana
- Fully managed service that allows us to securely visualize our data for instantly querying, correlating, and visualizing your operational metrics, logs, and traces from different sources
- Overview
- Grafana made easy
- Logical separation with workspaces
- Workspaces are logical Grafana servers that allow for separation of data visualizations and querying
- Data Sources for Grafana: CloudWatch, Managed Service for Prometheus, OpenSearch Service, Timestream
- Use Cases:
- Container metrics visualizations
- Connect to data sources like Prometheus for visualizing EKS, ECS, or own Kube cluster metrics
- IoT
- Container metrics visualizations
- Amazon Managed Service for Prometheus
- Serverless, Prometheus-compatible service used for securely monitoring container metrics at scale
- Overview
- Still use open-source prometheus, but gives you AWS managed scaling and HA
- Auto Scaling
- HA- replicates data across three AZs in same region
- EKS and self-managed Kubernetes clusters
- PromQL: the open source query language for exploring and extracting data
- Data Retention:
- Data store in workspaces for 150 days, after that, deleted
- VPC Flow Logs
- Can configure to send to S3 bucket
- Horizontal and Vertical Scaling
- Launch Templates
- Specifies all of the needed settings that go into building out an EC2 instance
- More than just auto-scaling
- More granularity
- AWS recommends Launch templates over Configurations
- Configurations are only for auto-scaling, are immutable, limited configuration options, don't use them
- Create template for Auto Scaling Group
- Launch Templates
- Auto Scaling
- Auto Scaling Groups
- Contains a collection of EC2 instances that are treated as a collective group for the purposes of scaling and management
- What goes into auto scaling group?
- Define your template
- Pick from available launch templates or launch configurations
- Pick your networking and purchasing
- Pick networking space and purchasing options
- ELB configuration
- ELB sits in front of auto scaling group
- EC2 instances are registered behind a load balancer
- Auto scaling can be set to respect the load balancer health checks
- Set Scaling policies
- Min/Max/Desired capacity
- Notifications
- SNS can act as notification tool, alert when a scaling event occurs
- Define your template
- Step Scaling Policies
- Increase or decrease the current capacity of a scalable target based on scaling adjustments, known as step adjustments
- Adjustments vary based on the size of the alarm breach
- All alarms that are breached are evaluated by application auto scaling
- Instance Warm-Up and Cooldown
- Warm-up period - time for EC2s to come up before being placed behind LB
- Cooldown - pauses auto scaling for a set amount of time (default is 5 minutes)
- Warmup and cooldown help to avoid thrashing
- Scaling types
- Reactive Scaling
- Once the load is there, you measure it and then determine if you need to create more or less resources
- Respond to data points in real-time, react
- Scheduled Scaling
- Predictable workload, create a scaling event to handle
- Predictive Scaling
- AWS uses ML algorithms to determine
- They are reevaluated every 24 hours to create a forecast for the next 48
- Reactive Scaling
- Steady Scaling
- Allows us to create a situation where the failure of a legacy codebase or resource that cant be scaled down can auto recover from failure
- Set Min/Max/Desired = 1
- CloudWatch is your number one tool for alerting auto scaling that you need more or less of something
- Scaling Relational DBs
- Most scaling options
- 4 ways to scale Relational DBs/4 types of scaling we can use to adjust our RD performance
- Vertical Scaling
- Resizing the db from one size to another, can create greater performance, increase power
- Scaling Storage
- Storage can be resized up, not down
- Except aurora which auto scales
- Read Replicas
- Way to scale “horizontally” - create read only copies of our data
- Aurora Serverless
- Can offload scaling to AWS - excels with unpredictable workloads
- Vertical Scaling
- Scaling Non Relational DBs
- DynamoDB
- AWS managed - simplified
- Provisioned Model
- Use case: predictable workload
- Need to overview past usage to predict and set limits
- Most cost effective
- On-Demand
- Use case: sporadic workload
- Pay more
- Can switch from on-demand to provisioned only once per 24 hours per table
- Non-Relational DB scaling
- Access patterns
- Design matters
- Avoiding hot keys will lead to better performance
- DynamoDB
- Auto Scaling Groups
- Simple Queue Service (SQS)
- Fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless apps
- Can sit between frontend and backend and kind of replace the Load Balancer
- Web front end dumps messages into the queue and then backend resources can poll that queue looking for that data whenever it is ready
- Does not require that active connection that the load balancer requires
- Poll-Based Messaging
- We have a producer of messages, consumer comes and gets message when ready
- Messaging queue that allows asynchronous processing or work
- SQS Settings
- Delivery Delay - default 0, up to 15 minutes
- Message Size - up to 256 KB text in any format
- Encryption - encrypted in transit by default, now added encryption at rest default with SSE-SQS
- SSE-SQS = Server-Side Encryption using SQS-owned encryption
- Encryption at rest using the default SSE-SQS is supported at no charge for both standard and FIFO using HTTPS endpoints
- SSE-SQS = Server-Side Encryption using SQS-owned encryption
- Message Retention
- Default retention is 4 days, can be set from 1 minute - 14 days, then purged
- Long vs Short Polling
- Long polling is not the default, but should be
- Short Polling
- Connect, checks if work, immediately disconnects if no work
- Burns CPU, additional API calls cost money
- Long Polling
- Connect, check if work, waits a bit
- Mostly will be the right answer
- Queue Depth
- This value can be a trigger for auto scaling
- Visibility Timeout
- Used to ensure proper handling of the message by backend EC2 instances
- Backend polls for the message, sees it, downloads that message from SQS to do work - after backend downloads message, SQS puts a lock on that message called the visibility timeout, where the message remains in the queue but no one else can see it
- So if other instances are polling that queue, the will not see the locked message
- Default visibility timeout is 30 seconds, but can be changed
- If that EC2 instance that downloaded the message fails to process that message and reach out to the queue to tell SQS that it is done, and tells it to purge that message, that message is going to reappear in the queue
- Dead-Letter Queues
- If there is a problem with the message, if the message cannot be processed by our backend process and we did not implement DLQ - the message would get pulled by a backend EC2 for processing, the EC2 would have an error processing it, so we would hit our 30 sec visibility timeout. So, the message would unlock, another EC2 would pick it up, etc, etc, until we hit our message retention period, then that message would be deleted
- By implementing DLQ: we create another SQS Queue that we can temporarily sideline messages into
- How it works:
- Set up a new queue and select it as the DLQ when setting up the primary SQS queue
- Set a number for retries in the primary queue
Once the message hits that limit, it gets moved to the DLW where it stays until message retention period, then deleted
- Can create SQS DLQ for SNS topics
- SQS FIFO
- Standard SQS offers best effort ordering and tries not to duplicate, but may - nearly unlimited transactions/sec
- SQS FIFO guarantees the order and that no duplication will occur
- Limited to 300 messages/sec
- How it works:
- Message group ID field is a tag that specifies that a message belongs to a specific message group
- Message Deduplication ID is the token used to ensure no duplication within the deduplication interval: a unique value that ensures that your messages are unique
- More expensive than standard SQS
- Simple Notification Service (SNS)
- Used to push out notifications - proactively deliver the notification to an end-point rather than leaving it in a queue
- Fully managed messaging service for both application-to-application (A2A) and application-to-person (A2P) communication
- Texts and emails to users
- Push-Based Messaging
- Consumer does not have control to receive when ready, the sender sends it all the way to the consumer
- Will proactively deliver messages to the endpoints that are Subscribed to it
- SNS topics are subscribed to
- SNS Settings
- Subscribers
- what/who is going to receive the data from the topic
- Ex: Kinesis firehose, SQS, Lambda, email, HTTP(S), etc
- what/who is going to receive the data from the topic
- Message Size
- Max size of 256 text in any format
- SNS does not retry, even if they fail to deliver
- Can store in an SQS DLQ to handle
- SNS FIFO only supports SQS as a subscriber
- Messages are encrypted in transit by default, and you can add encryption at rest
- Access Policies
- Can control who/what can publish to those SNS topics
- A resource policy can be added to a topic, similar to S3
- Have to make sure AP is set up properly with SNS to SQS so that SNS can have access to SQS Queue
- Subscribers
- CloudWatch uses SNS to deliver alarms
- API Gateway
- Fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale
- “Front-door” to our apps so we can control what users talk to our resources
- Key features:
- Security
- Add security- one of the main reasons for using API Gateway in front of our applications
- Allows you to easily protect your endpoints by attaching a WAF; Can front API Gateway with a WAF - security at the edge
- Stop Abuse
- Set up rate limiting, DDoS protection
- Static stuff to S3, basically everything else to API Gateway
- Security
- Preferred method is to get API calls into your application and AWS environment
- Avoid hardcoding our access keys/secret keys with API Gateway
- Do not have to generate an IAM user to make calls to the backend, just send API call to API Gateway in front
- API Gateway is versioning supported
- AWS Batch
- AWS Managed service that allows us to run batch computing workloads within AWS- these workloads run on either EC2 or Fargate/ECS
- Capable of provisioning accurately sized compute resources based on number of jobs submitted and optimizes the distribution of workloads
- Removes any heavy lifting for configuration and management of infrastructure required for computing
- Components:
- Jobs = units of work that are submitted to Batch (ie: shell scripts, executables, docker images)
- Job Definitions = specify how your jobs are to be run, essentially the blueprint for the resources in the job
- Job Queues = jobs get submitted to specific queues and reside there until scheduled to run in a compute environment
- Compute Environment = set of managed or unmanaged compute resources used to run your jobs (EC2 or ECS/Fargate)
- Fargate or EC2 Compute Environments
- Fargate is the recommended way of launching most batch jobs
- Scales and matches your needs with less likelihood of over provisioning
- EC2 is sometimes the best choice, though:
- When you need a custom AMI (can only be run via EC2)
- When you have high vCPU requirements
- When you have high GiB requirements
- Need GPU or Graviton CPU requirement
- When you need to use linusParameters parameter field
- When you have a large number of jobs, best to run on EC2 because jobs are dispatched at a higher rate than Fargate
- Fargate is the recommended way of launching most batch jobs
- Batch vs Lambda
- Lambda has a 15 minute execution time limit, batch does not
- Lambda has limited disk space
- Lambda has limited runtimes, batch uses docker so any runtime can be used
- AWS Managed service that allows us to run batch computing workloads within AWS- these workloads run on either EC2 or Fargate/ECS
- Amazon MQ
- Managed message broker service allowing easier migration of existing applications to the AWS Cloud
- Makes it easy for users to migrate to a message broker in the cloud from an existing application
- Can use a variety of programming languages, OS’s, and messaging protocols
- MQ Engine types:
- Currently supports both Apache ActiveMQ or RabbitMQ engine types
- SNS with SQS vs AmazonMQ
- Both have topics and queues
- Both allow for one-to-one or one-to-many messaging designs
- MQ is easy application migration: so if you are migrating an existing application, likely want MQ
- If you are starting with new Application - easier and better to use SNS with SQS
- AmazonMQ requires that you have private networking like VPC, Direct Connect, or VPN while SNS and SQS are publicly accessible by default
- MQ has NO default AWS integrations and does not integrate as easily with other services
- Both have topics and queues
- Configuring Brokers
- Single_Instance Broker
- One broker lives within one AZ
- RabbitMQ has a network load balancer in front in a single instance broker environment
- MQ Brokers
- Offers HA architectures to minimize downtime during maintenance
- Architecture depends on broker engine type
- AmazonMQ for Apache ActiveMQ
- With active/standby deployments, one instance will remain available at all times
- Configure network of brokers with separate maintenance windows
- AmazonMQ for RabbitMQ
- Cluster deployment are logical groupings of three broker nodes across multiple AZs sitting behind a Network LB
- MQ is good for specific messaging protocols: JMS or messaging protocols like AMQP0-9-1, AMQP 1.0, MQTT, OpenWire, and STOMP
- Single_Instance Broker
- AWS Step Functions
- A serverless orchestration service combining different AWS services for business applications
- Provides a graphical console for easier application workflow views and flows
- Components
- State Machine: a particular workflow with different event-driven steps
- Tasks: specific states within a workflow (state machine) representing a single unit of work
- States: every single step within a workflow = a state
- Two different types of workflows with Step Functions:
- Standard
- Exactly-once execution
- Can run for up to 1 year
- Useful for long-running workflows that need to have auditable history
- Rates up to 2000 executions/sec
- Pricing based per state transition
- Express
- Have an ‘at-least-once’ execution → means possible duplication you have to handle
- Only run for up to 5 minutes
- Useful for high-event-rate workloads
- Use Case: IoT data streaming
- Pricing based on number of executions, durations, and memory consumed
- Standard
- States and State Machines
- Individual states are flexible
- Leverage states to either make decisions based on input, perform certain actions, or pass input
- Amazon States Language (ASL)
- States and workflows are defined in ASL
- States are elements within your state machines
- States are referred to by name, name in unique within workflow
- Individual states are flexible
- Integrates with Lambda, Batch, Dynamo, SNS, Fargate, API Gateway, etc
- Different States that exist:
- Pass - no work
- Task - single unit of work performed
- Choice - adds branching logic to state machines
- Wait - time delay
- Succeed - stops executions successfully
- Fail - stops executions and mark as failures
- Parallel - runs parallel branches of executions within state machines
- Map - runs a set of steps based on elements of an input array
- Amazon AppFlow
- Fully managed service that allows us to securely exchange data between a SaaS App and AWS
- Ex: Salesforce migrating data to S3
- Entire purpose is to ingest data
- Pulls data records from third-party SaaS vendors and stores them in S3
- Bi-directional: allows for bi-directional data transfers with some combinations of source and destination
- Concepts:
- Flow: transfer data between sources and destinations
- Data Mapping: determines how your source data is stored within your destination
- Filters: criteria set to control which data is transferred
- Trigger: determines how the flow is started
- Multiple options/supported types:
- Run on demand
- Run on event
- Run on schedule
- Multiple options/supported types:
- Fully managed service that allows us to securely exchange data between a SaaS App and AWS
- Redshift Databases
- Fully managed, petabyte-scale data warehouse service in the cloud
- Very large relational db traditionally used in big data
- Because it is relational, you can use standard SQL and BI tools to interact with it
- Best use is for BI applications
- Can store massive amounts of data - up to 16 PB of data
- Means you do not have to split up your large datasets
- Not a replacement for a traditional RDS - it would fall apart as the backend of your web app, for example
- Elastic Map Reduce (EMR)
- ETL tool
- Managed big data platform that allows you to process vast amounts of data using open-source tools, such as Spark, Hive, HBase, Flink, Hudi, and Presto
- Quickly use open source tools and get them running in our environment
- For this exam, EMR will be run on EC2 instances and you pick the open-source tool for AWS to manage on them
- Open-source cluster, managed fleet of EC2 instances running open-source tools
- Amazon Kinesis
- Allows you to ingest, process, and analyze real-time streaming data
- 2 forms of Kinesis:
- Data Streams
- Real-time streaming for ingesting data
- You are responsible for creating the consumer and scaling the stream
- Process for Kinesis Data Streams:
- Producers creating data
- Connect producers to Data Stream
- Decide how many shards you are going to create
- Data Streams
Shards can only handle a certain amount of data
- Consumer takes data in, processes it, and puts it into endpoints
You have to create the consumer
Endpoint could be S3, Dynamo, Redshift, EMR, …
You have to use the Kinesis SDK to build the consumer application
Handle scaling with the amount of shards
- Data Firehose
- Data transfer tool to get info into S3, Redshift, ElasticSearch, or Splunk
- Near-real-time
- Plug and play with AWS architecture
- Process for Kinesis Data Firehose:
- Limited supported endpoints- ElasticSearch service, S3, and Redshift, some 3rd party endpoints supported as well
- Place Data Firehose in between input and endpoint
- Handles the scaling and the building out of the consumer
- Data Firehose
- Kinesis Data Analytics
- Paired with Data Stream/Firehose, it does the analysis using standard SQL
- Makes it easy to tie Data Analytics into your pipeline
- Data comes in with Streams/Firehose and Data Analytics can transform/sanitize/format data in real-time as it gets pushed through
- Serverless, fully managed, auto scaling
- Kinesis vs SQS
- SQS does NOT provide real-time message delivery
- Kinese DOES provide real-time message delivery
- Amazon Athena
- An interactive query that makes it easy to analyze data in S3 using SQL
- Allows you to directly query data in your S3 buckets without loading it into a database
- “Serverless SQL”
- Can use Athena to query logs stored in S3
- Amazon Glue
- A serverless data ingestion service that makes it easy to discover, prepare, and combine data
- Allows you to perform ETL workloads without managing underlying servers
- Effectively replaces EMR - and with Glue, you don't have to spin up EC2 instances or use 3rd party tools to ETL
- Using Athena and Glue together:
- AWS S3 data is unstructured, unformatted – deploy Glue Crawlers to build a catalog/structure for that data
- Glue produces Data Catalog
- After glue, we have some options:
- Can use Amazon Redshift Spectrum - allows us to use Redshift without having to load data into Redshift db
- Athena - use to query the data catalog, and can even use Quicksight to visualize data
- AWS S3 data is unstructured, unformatted – deploy Glue Crawlers to build a catalog/structure for that data
- Amazon QuickSight
- Amazon's version of Tableau
- Fully managed BI data visualization service, easily create dashboards
- AWS Data Pipeline
- A managed ETL service for automating management and transformation of your data, automatic retries for data-driven workflow
- Data driven web-service that allows you to define data-driven workflows
- Steps are dependent on previous tasks completing successfully
- Define parameters for data transformations - enforces your chosen logic
- Auto retries failed attempts
- Configure notifications via SNS
- Integrates easily with Dynamo, Redshift, RDS, S3 for data storage, and integrates with EC2 and EMR for compute needs
- Components:
- Pipeline Definition = specify the logic of you data management
- Managed Compute = service will create EC2 instances to perform your activities or leverage existing EC2
- Task Runners = (EC2) poll for different tasks and perform them when found
- Data Nodes= define the locations and types of data that will be input and output
- Activities = pipeline components that define the work to perform
- Use Cases:
- Processing data in EMR using Hadoop streaming
- Importing or exporting DynamoDB data
- Copying CSV files or data between S3 buckets
- Exporting RDS data to S3
- Copying data to Redshift
- Amazon Managed Streaming for Apache Kafka (Amazon MSK)
- Fully managed service for running data streaming apps that leverage Apache Kafka
- Provides control-plane operations; creates, updates, and deletes clusters as required
- Can leverage the Kafka data-plane operations for production and consuming streaming data
- Good for existing operations; allows support for existing apps, tools, and plugins
- Components:
- Broker Nodes
- Specify the amount of broker nodes per AZ you want at time of cluster creation
- Zookeeper Nodes
- Created for you
- Producers, Consumers, and Topics
- Kafka data-plane operations allow creation of topics and ability to produce/consume data
- Flexible Cluster Operations
- Perform cluster operations with the console, AWS CLI, or APIs within any SDK
- Broker Nodes
- Resiliency in AmazonMSK:
- Auto Recovery
- Detected broker failures result in mitigation or replacement of unhealthy nodes
- Tries to reduce storage from other brokers during failures to reduce data needing replication
- Impact time is limited to however long it takes MSK to complete detection and recovery
- After successful recovery, producer and consumer apps continue to communicate with the same IP as before
- Features:
- MSK Serverless
- Cluster type within AmazonMSK offering serverless cluster management - auto provisioning and scaling
- Fully compatible with Apache Kafka - use the same client apps for prod/cons data
- MSK Connect
- Allows developers to easily stream data to and from Apache Kafka clusters
- MSK Serverless
- Security
- Integrates with Amazon KMS for SSE requirements
- Will always encrypt data at rest by default
- TLS1.2 by default in transit between brokers in clusters
- Logging
- Broker logs can be delivered to services like CloudWatch, S3, Data Firehose
- By default, metrics are gathered and sent to CloudWatch
- MSK API calls are logged to CloudFront
- Amazon OpenSearch Service
- Managed service allowing you to run search and analytics engines for various use cases
- It is the successor to Amazon ElasticSearch Service
- Features:
- Allows you to perform quick analysis - quickly ingest, search, and analyze data in your clusters - commonly a part of an ETL process
- Easily scale cluster infrastructure running the OpenSearch services
- Security: leverage IAM for access control, VPC security groups, encryption at rest and in transit, and field-level security
- Multi-AZ capable service with Master nodes and automated snapshots
- Allows for SQL support for BI apps
- Integrates with CloudWatch, CloudTrail, S3, Kinesis - can set log streams to OpenSearch Service
- Logging solution involving creating visualization of log file analytics or BI tools/imports
- Serverless Overview
- Benefits
- Easy of use: we bring code, AWS handles everything else
- Event-Based: can be brought online in response to an event then go back offline
- True “pay for what you use” architecture: pay for provisioned resources and the length of runtime
- Example serverless services: Lambda, Fargate
- Benefits
- Lambda
- Serverless compute service that lets you run code without provisioning or managing the underlying server
- How to build a lambda function:
- Runtime selection: pick from an available run-time or bring your own. This is the environment your code will run in
- Set permissions: if your lambda function needs to make an API call in AWS, you need to attach a role
- Networking definitions: optionally, you can define the VPC, subnet, and security groups your functions are a part of
- Resource definitions: define the amount of available memory will allocate how much CPU and RAM your code gets
- Define Trigger: select what is going to kick off your lambda function to start
- Lambda has built-in logging and monitoring using CloudWatch
- AWS Serverless Application Repository
- Serverless App Repository
- Service that makes it easy for users to easily find, deploy, or even publish their own serverless apps
- Can share privately within organization or publicly
- How it works:
- You upload your application code and a Manifest File
- Manifest File: is known as the Serverless Application Model (SAM) Template
- SAM templates are basically CloudFormation templates
- You upload your application code and a Manifest File
- Deeply integrated with the AWS lambda service - actually appears in the console
- 2 Options in Serverless App Repository:
- Publish: define apps with the SAM templates and make them available for others to find and deploy
- When you first publish your app, it is set to private by default
- Deploy: find and deploy published apps
- Publish: define apps with the SAM templates and make them available for others to find and deploy
- Serverless App Repository
- Container Overview
- Container
- Standard unit of software that packages up code and all its dependencies
- Terms:
- Docker File: text document that contains all the commands or instructions that will be used to build an image
- Image: Docker files build images, immutable file that contains the code, libraries, dependencies, and configuration files needed to build an app
- Registry: like GitHub for images, stores docker images for distribution
- Container: a running copy of image
- ECS: Elastic Container Service
- Management of containers at scale
- Integrates natively with ELB
- Easy integration with roles to get permissions for containers - containers can have individual roles attached to them
- ECS only works in AWS
- EKS: Elastic Kubernetes Service
- Kubernetes: open source container manager, can be used on-prem and in the cloud
- EKS is the AWS-managed version
- ECS vs EKS
- ECS - simple, easy to integrate, but it does not work on-prem
- EKS - flexible, works in cloud and on-prem, but it is more work to configure and integrate with AWS
- Fargate
- Serverless compute engine for containers that works with both ECS and EKS (requires one of them)
- EC2 vs Fargate for container management
- If you use EC2:
- You are responsible for underlying OS
- Can better deal with long-running containers
- Multiple containers can share the same host
- If you use Fargate:
- No OS access - don’t have to manage
- Pay based on resources allocated and time run
- Better for short-running tasks
- Isolated environments
- If you use EC2:
- Fargate vs Lambda
- Use fargate when you have more consistent workloads, allows for docker use across the organization and a greater level of control for developers
- Use lambda when you have unpredictable or inconsistent workloads, use for applications that can be expressed as a single function (lambda function responds to event and shuts down)
- Container
- EventBridge (formerly known as CloudWatch Events)
- Serverless event bus, allows you to pass events from a server to an endpoint
- Essentially the glue that holds your serverless apps together
- Creating an EventBridge Rule:
- Define Pattern: scheduled/invoked/etc?
- Select Event Bus: AWS-based event/Custom event/Partner event?
- Select your target: what happens when this event kicks off?
- Remember to tag it
- Remember:
- EventBridge is the glue - it triggers an action based on some event in AWS, holds together a serverless application and Lambda functions
- An API call in AWS can alert a variety of endpoints
- EventBridge is the glue - it triggers an action based on some event in AWS, holds together a serverless application and Lambda functions
- Serverless event bus, allows you to pass events from a server to an endpoint
- Amazon Elastic Container Registry (ECR)
- AWS-managed container image registry that offers secure, scalable, and reliable infrastructure
- Private container image repositories with resources-based permissions via IAM
- Supported formats include: Open Container Initiative (OCI) images, docker images, and OCI artifact
- Components:
- Registry
- A private registry provided to each AWS account, regional
- Can create one or more registries for image storage
- Authentication Token
- Required for pushing/pulling images to/from registries
- Repository
- Contains all of your Docker Images, OCI Images, and Artifacts
- Repository Policy
- Control all access to repository and images
- Image
- Container images that get pushed to and pulled from your repositories
- Registry
- Amazon ECR Public is a similar service for public image repository
- Features:
- Lifecycle policies
- Helps management of images in your repository
- Defines rules for cleaning up unused images
- It does give you the ability to test your rules before applying them to repository
- Image Scanning
- Helps identify software vulnerabilities in your container images
- Repositories can be set to scan on push
- Retrieve results of scans for each image
- Sharing
- Cross-Region Support
- Cross-Account support
- Both are configured per repository and per region > each registry is regional for each account
- Cache Rules
- Pull through cache rules allow for caching public repositories privately
- ECR periodically reaches out to check current caching status
- Tag Mutability
- Prevents image tags from being overwritten
- Configure this setting per repository
- Lifecycle policies
- Service Integrations:
- Bring your own containers - can integrate with your own container infrastructure
- ECS - use container images in ECS container definitions
- EKS - pull images from EKS clusters
- Amazon Linux Containers - can be used locally for your software development
- EKS Distro
- EKS Distro aka EKS-D
- Kubernetes distribution based on and used by Amazon EKS
- Same versions and dependencies deployed by EKS
- EKS-D is fully your responsibility, fully managed by you, unlike EKS
- Can run EKS-D anywhere, on-prem, cloud, etc
- EKS Distro aka EKS-D
- EKS Anywhere and ECS Anywhere
- EKS Anywhere
- An on-prem way to manage Kubernetes clusters with the same practices used in EKS, with these clusters on-prem
- Based on EKS-Distro allows for deployment, usage, and management methods for clusters in data centers
- Can use lifecycle management of multiple kubernetes clusters and operate independently of AWS Services
- Concepts:
- Kubernetes control plane management operated completely by customer
- Control plane location within customer center
- Updates are done entirely via manual CLI or Flux
- ECS Anywhere
- Feature of ECS allowing the management of container-based apps on-prem
- No orchestration needed: no need to install and operate local container orchestration software, meaning more operational efficiency
- Completely managed solution enabling standardization of container management across environment
- Inbound Traffic
- No ELB support - customer managed, on-prem
- EXTERNAL = new launch type noted as ‘EXTERNAL’ for creating services or running tasks
- Requirements for ECS Anywhere:
- On local server, must have the following installed:
- SSM Agent
- ESC Agent
- Docker
- Must first register external instances as SSM Managed Instances
- Can easily create an installation script within ECS console to run on your instances
- Scripts contain SSM activation keys and commands for required software
- On local server, must have the following installed:
- EKS Anywhere
- Auto Scaling DBs on Demand with Aurora Serverless
- Aurora Provisioned vs Aurora Serverless
- Provisioned is typical Aurora service
- Aurora Serverless
- On-demand and Auto Scaling configuration for Aurora db service
- Automation of monitoring workloads and adjusting capacity for dbs
- Based on demand - capacity adjusted
- Billed per-second only for resources consumed by db clusters
- Concepts for Aurora Serverless
- Aurora Capacity Units (ACUs) = a measurement on how your clusters scale
- Set minimum and maximum of ACUs for scaling → can be 0
- Allocate quickly by AWS managed warm pools
- Combo of 2 GiB of memory, matching CPU and networking
- Same data resiliency as provisioned - 6 copies of data across 3 AZs
- Use Cases:
- Variable workloads
- Multi-tenant apps - let the service manage db capacity for each individual app
- New apps
- Dev and Test
- Mixed-Use Apps: apps that might serve more than one purpose with different traffic spikes
- Capacity planning: easily swap from provisioned to serverless or vise-versa
- Aurora Provisioned vs Aurora Serverless
- Amazon X-Ray
- Application Insights - collects application data for viewing, filtering, and gaining insights about requests and responses
- View calls to downstream AWS resources and other microservices/APIs or dbs
- Receives traces from your applications for allowing insights
- Integrated services can add tracing headers, send trace data, or run the X-Ray daemon
- Concepts:
- Segments: data containing resource names, request details, etc
- Subsegments: segments providing more granular timing info and data
- Service graph: graphical representation of interacting services in requests
- Traces: trace ID tracks paths of requests and traces collect all segments in a request
- Tracing Header: extra HTTP header containing sampling decisions and trace ID
- Tracing header continuing added info is named: X-Amzn-Trace-ID
- X-Ray Daemon
- AWS Software application that listens on UDP port 2000. It collects raw segment data and sends it to the X-Ray API
- When daemon is running, it works alongside the X-Ray SDK
- Integrations:
- EC2- installed, running agent
- ECS- installed within tasks
- Lambda- on/off toggle, built-in/available for functions
- Beanstalk- a configuration option
- API Gateway- can add to stages as desired
- SNS and SQS- view time taken for messages in queues within topics
- GraphQL interfaces in AppSync
- AppSync
- Robust, scalable GraphQL interface for app developers
- Combines data from multiple sources
- Enables interaction for developers via GraphQL, which is a data language that enables apps to fetch data from servers
- Seamless integration with React, ReactNative, iOS, and Android
- Especially used for fetching app data, declarative coding, and frontend app data fetching
- AppSync
- Layer 4 DDoS Attacks aka SYN flood
- Work at the transport layer
- How it works:
- SYN flood overwhelms the server by sending a large number of SYN packets and then ignoring the SYN-ACKs returned by the server
- Causes the server to use up resources waiting for a set amount of time for the ACK
- There are only so many concurrent TCP connections that a web app server can have open - so attacker could take all the allowed connections causing the server to not be able to respond to legitimate traffic
- SYN flood overwhelms the server by sending a large number of SYN packets and then ignoring the SYN-ACKs returned by the server
- Amplification Attacks aka Reflection Attacks
- When an attacker may send a third party server (such as an NTP server) a request using a spoofed IP address. That server will then respond to that request with a greater payload than the initial request (28-54 xs larger) to the spoofed IP
- Attackers can coordinate this and use multiple NTP servers a second to send legitimate NTP traffic to the target
- Include things such as NTP, SSDP, DNS, CharGEN, SNMP attacks, etc
- When an attacker may send a third party server (such as an NTP server) a request using a spoofed IP address. That server will then respond to that request with a greater payload than the initial request (28-54 xs larger) to the spoofed IP
- Layer 7 Attack
- Occurs when a web server receives a flood of GET or POST requests, usually from a botnet or large number of compromised computers
- Causes legitimate users to not be able to connect to the web server because it is busy responding to the flood of requests from the botnet
- Occurs when a web server receives a flood of GET or POST requests, usually from a botnet or large number of compromised computers
- Logging API Calls using CloudTrail
- CloudTrail Overview:
- Increases visibility into your user and resource activity by recording AWS Management Console actions and API calls
- Can identify which users and accounts called AWS, the source IP from which the calls were made and when
- Just tracks API calls:
- Every call is logged into an S3 bucket by CloudTrail
- RDP and SSH traffic is NOT logged
- DOES include anything done in the console
- What is logged in a CloudTrail logged event?
- Metadata around the API calls
- Id of the API caller
- Time of call
- Source IP of API caller
- Request parameters
- Response elements returned by the service
- What CloudTrail allows for:
- After-the-fact incident investigation
- Near real-time intrusion detection → integrate with Lambda function to create an intrusion detection system that you can customize
- Logging for industry and regulatory compliance
- CloudTrail Overview:
- Amazon Shield
- AWS Shield
- Free DDoS Protection
- Protects all AWS customers on ELBs, CloudFront, and Route53
- Protects against SYN/UDP floods, reflection attacks and other Layer 3 and Layer 4 attacks
- AWS Shield-Enhanced
- Provides enhanced protections for apps running on ELB, CloudFront, Route53 against larger and more sophisticated attacks
- Offers always-on, flow-based monitoring of network traffic and active application monitoring to provide near real-time notifications of DDoS attacks
- 24/7 access to the DDoS Response Team (DRT) to help mitigate and manage app-layer DDoS attacks
- Protects your AWS bill against higher fees due to ELB, CloudFront, and Route53 usage spikes during a DDoS attack
- Costs $3000/month
- AWS Shield
- Web Application Firewall
- Web Application Firewall that allows you to monitor the HTTP and HTTPS requests that are forwarded on to CloudFront or Application Load Balancer
- Lets you control access to your content
- Can configure conditions such as what IP addresses are allowed to make this request or what query string parameters need to be passed for the request to be allowed
- The Application Load Balancer or CloudFront will either allow this content to be received or give an HTTP 403 status code
- Operates at Layer 7
- At the most basic level, WAF allows 3 behaviors:
- Allow all requests except the ones you specify
- Block all requests except for the ones you specify
- Count the requests that match the properties you specify
- Can define conditions by using characteristics of web requests such as:
- IP addresses that the requests originate from
- Country that the requests originate from
- Values in requests headers
- Presence of a SQL code that is likely to be malicious (ie: SQL Injection)
- Presence of a script that is likely to be malicious (ie: cross-site scripting)
- Strings that appear in requests - either specific strings or strings that match regex patterns
- WAF can:
- Can protect against Layer 7 DDoS attacks like cross-site scripting, SQL injections
- Can block specific countries or specific IP addresses
- GuardDuty
- Threat detection service that uses ML to continuously monitor for malicious behavior
- Unusual API calls, calls from a known malicious IP
- Attempts to disable CloudTrail logging
- Unauthorized Deployments
- Compromised Instances
- Recon by would-be attackers
- Port scanning and failed logins
- Features
- Alerts appear in GuardDuty console and CloudWatch events
- Receives feeds from 3rd parties like Proofpoint and CrowdStrike, as well as AWS Security, about known malicious domains and IP addresses
- Monitors CloudTrail logs, VPC flow logs and DNS logs
- Allows you to centralize threat detection across multiple AWS Accounts
- Automated response using CloudWatch Events and Lambda
- Gives you ML and anomaly detection
- Basically threat detection with AI
- Setting up GuardDuty:
- 7-14 days to set a baseline = normal behavior
- You will only see findings that GuardDuty detects as a threat
- Cost
- 30 days free
- Charges based on:
- Quality of CloudTrail events
- Volume of DNS and VPC Flow logs data
- Threat detection service that uses ML to continuously monitor for malicious behavior
- Firewall Manager
- A security management service in a single pane of glass
- Allows you to centrally set up and manage firewall rules across multiple AWS accounts and apps in AWS Organizations
- Can create new AWS WAF Rules for your App Load Balancers, API Gateways, and CloudFront distributions
- Can also mitigate DDoS attacks using shield Advanced for your App Load Balancers, Elastic IP addresses, CloudFront distributions, and more
- Benefits:
- Simplifies management firewall rules across accounts
- Ensure compliance of existing and new apps
- Monitoring S3 Buckets with Macie
- Macie
- Automated analysis of data - uses ML and pattern matching to discover sensitive data stored in S3
- Uses AI to recognize if your S3 objects contain sensitive data, such as PII, PHI, and financial data
- Buckets:
- Alerts you to unencrypted buckets
- Alerts you about public buckets
- Can also alert you about buckets shared with AWS accounts outside of those defined in your AWS Orgs
- Great for frameworks like HIPAA
- Macie Alerts
- You can filter and search Macie alerts in AWS console
- Alerts sent to Amazon EventBridge can be integrated with your security incident and event management (SIEM) system
- Can be integrated with AWS Security Hub for a broader analysis of your organization's security posture
- Can also be integrated with other AWS Services, such as Step Functions, to automatically take remediation actions
- Macie
- Inspector
- An automated security assessment service that helps improve the security and compliance of apps deployed on AWS
- Auto assesses apps for vulnerabilities or deviations from best practices
- Inspects EC2 instances and networks
- Assessment findings:
- After performing an assessment, Inspector produces a detailed list of security findings by level of security
- These findings can be reviewed directly or as part of detailed assessment reports available via Inspector console to API
- 2 types of assessments:
- Network Assessments
- Network configuration analysis to check for ports reachable from outside the VPC
- Inspector agent not required
- Host Assessments
- Vulnerable software (CVE), host hardening (CIS Benchmarks), and security best practices to review
- Inspector agent is required
- Network Assessments
- How does it work:
- Create assessment target
- Install agents on EC2 instances
- AWS will auto install the agent for instances that allow Systems Manager run commands
- Create Assessment Templates
- Perform Assessment run
- Review findings against the rules
- Key Management Service (KMS) and CloudHSM
- KMS
- AWS KMS is a managed service that makes it easy for you to create and control the encryption keys used to encrypt your data
- KSM Integrations
- Integrates with other services (EBS, S3, and RDS, etc) to make it simple to encrypt your data with encryption keys you manage
- Controlling your keys
- Provides you with centralized control over the lifecycle and permissions of your keys
- Can create new keys whenever you wish and you can control who can manage keys separately from who can use them
- CMK = Customer Master Key
- Logical representation of a master key
- CMK includes metadata such as they Key ID, creation date description, and key state
- CMK also contains the key material used to encrypt/decrypt data
- Getting started with CMK:
- You start the service by requesting the creation of a CMK
- You control the lifecycle of a CMK as well as who can use or manage it
- HSM - Hardware Security Module
- A physical computing device that safeguards and manages digital keys and performs encryption and decryption functions
- HSM contains one or more secure cryptoprocessor chips
- 3 ways to generate a CMK:
- AWS creates the CMK for you
- KMS
Key material for CMK is generated within HSMs managed by AWS KMS
- Import key material from your own key management infrastructure and associate it with a CMK
- Have they key material generated and used in an AWS CloudHSM Cluster as part of the custom key store feature in KMS
- Key Rotation:
- If KMS HSMs were used to generate your keys, you can have AWS KMS auto rotate CMKs every year
- Auto key rotation is not supported for imported keys, asymmetric keys or keys generated in an AWS CloudHSM cluster using KMS custom key store feature
- If KMS HSMs were used to generate your keys, you can have AWS KMS auto rotate CMKs every year
- Policies
- Primary way to manage access to your KMS CMKs is with policies
- Policies re documents that describe who has access to what
- Policies attached to an IAM Identity = identity-based policies (IAM policies), policies attached to other kinds of resources are called resource-based policies
- Key Policies
- In KMS, you must attach resource-based policies to your customer master keys (CMKs) → these are key policies
- All CMKs must have a key policy
- 3 ways to control permissions:
- Use the key policy- controlling access this way means the full scope of access to the CMK is defined in a single document (the key policy)
- Use IAM policies in combo with key policy- controlling access this way enables you to manage all the permissions for your IAM identities in IAM
- Use grants in combo with key policy- enables you to allow access to CMK in the key policy, as well as allow users to delegate their access to others
- Primary way to manage access to your KMS CMKs is with policies
- CloudHSM
- Cloud-based Hardware Security Module that enables you to easily generate and use your own encryption keys on the AWS Cloud
- Basically renting physical device from AWS
- Cloud-based Hardware Security Module that enables you to easily generate and use your own encryption keys on the AWS Cloud
- KMS vs CloudHSM
- KSM
- Shared tenancy of underlying Hardware
- Auto key rotation
- Auto key generation
- CloudHSM
- Dedicated HSM to you
- Full control of underlying hardware
- Full control of users, groups, keys, etc
- No auto key rotation
- KSM
- Secrets Manager
- Service that securely stores, encrypts, and rotates your db credentials and other secrets
- Encryption in transit and at rest using KMS
- Auto rotates credentials
- Apply fine-grained access control using IAM policies
- Costs money, but highly scalable
- What else can it do
- Your app makes an API call to Secrets Manager to retrieve the secret programmatically
- Reduces the risk of credentials being compromised
- What can be stored?
- RDS credentials
- Credentials for non-RDS dbs
- Any other type of secret, provided you can store it as a key-value pair (SSH keys, API keys)
- Important: If you enable rotation, Secrets Manager immediately rotates the secret once to test the configuration
- You have to ensure that all of your apps that use these creds are updated to retrieve the creds from this secret using Secrets Manager
- If you apps are still using embedded creds, do not enable rotation
- Recommended to enable rotation if your apps are not already using embedded creds
- Service that securely stores, encrypts, and rotates your db credentials and other secrets
- Parameter Store
- A capability of AWS Systems Manager that provides, secure, hierarchical storage for config data management and secrets management
- Can store things like passwords, db strings, AMI IDs, and license credentials as parameter values - can store as plain text or encrypted
- Parameter store is free
- 2 Big limits to Parameter Store:
- Limit to number of parameters you can store (current max is 10k)
- No key rotation
- Parameter Store vs Secrets Manager
- Minimize cost → Parameter Store
- Need more than 10k secrets, key rotation, or the ability to generate passwords using CloudFormation → Secrets Manager
- Pre Signed URLs or Cookies
- All objects in S3 are private by default- only object owner has permissions to access
- Pre Signed URLS
- Owner can share objects with others by creating a pre-signed URL, using their own credentials, to grant the time-limited permission to download the objects
- When you create a pre signed URL for your object, you must provide your security credentials, specify a bucket name and an object key, and indicate the HTTP method (or GET to download the object) as well as expiration date and time
- URLs are only valid for specified duration
- To generate a pre signed URL for an object, must do through CLI
- > aws S3 presign s3://nameofbucket/objectname --expires-in 3600
- Way to share an object in a private bucket?
- Pre signed URLs
- Owner can share objects with others by creating a pre-signed URL, using their own credentials, to grant the time-limited permission to download the objects
- Pre signed Cookies
- Useful when you want to provide access to multiple restricted files
- The cookie will be saved on the user’s computer and they will be able to browse the entire comments of the restricted content
- Use case:
- Subscription to download files
- IAM Policy Documents
- Amazon Resource Names (ARNs)
- These uniquely ID a resource within Amazon
- All ARNs begin with:
- arn:partition:service:region:account_id
- Ex: arn:aws:ec2:eu-central-1:123456789012
- arn:partition:service:region:account_id
- And end with:
- Resource
- resource_type/resource
- Ex: my_awesome_bucket/image.jpg
- resource_type/resource/qualifier
- resource_type:resource
- Resource_type:resource:qualifier
- Note: for global services, for example, we will have no region, so there will be a :: aka omitted value in the arn
- IAM Policies
- Are JSON docs that define permissions
- IAM/Identity Policy = applying policies to users/groups
- Resource Policy = apply to S3, CMKs, etc
- They are basically a list of statements:
- {“Version”:”2012-10-17”,
- Amazon Resource Names (ARNs)
“Statement”:[
{...},
{...}
]
}
- Each statement matches an AWS API request
- Each statement has an effect of Allow or Deny
- Matched based on action
- Permission boundaries
- Used to delegate admin to other users
- Prevent privilege escalation or unnecessarily broad permissions
- Control max permissions an IAM policy can grant
- Exam tips:
- If permission is not explicitly allowed, it is implicitly denied
- An explicit deny > anything else
- AWS joins all applicable policies
- AWS managed vs customer managed
- AWS Certificate Manager
- Allows you to create, manage, and deploy public and private SSL certificates use with other services
- Integrates with other services - such as ELB, CloudFront distros, API Gateway - allowing you to easily manage and deploy SSL certs in environment
- Benefits:
- Do not have to pay for SSL certificates
- Provisions both public and private certificates for free
- You will still pay for the resources that utilize your certificates - such as ELBs
- Automated Renewals and Deployment
- Can automate the renewal of your SSL certificate and then auto update the new certificate with ACM-integrated services, such as ELB, CloudFront, API Gateway
- Easy to set up
- Do not have to pay for SSL certificates
- Allows you to create, manage, and deploy public and private SSL certificates use with other services
- AWS Audit Manager
- Continuously audit your AWS usage and make sure you stay compliant with industry standards and regulations
- It is an automated service that produces reports specific to auditors for PCI compliance, etc
- Use Cases:
- Transition from Manual to Automated Evidence Collection
- Allows you to produce automated reports for auditors and reduce manual
- Continuous Auditing and Compliance
- Continuous basis, as your environment evolves and adapts, you can produce automated reports to evaluate your environment against industry standards
- Internal Risk Assessments
- Can create a new framework from the beginning or customize pre built frameworks
- Can launch assessments to auto collect evidence, helping you validate if your internal policies are being followed
- Transition from Manual to Automated Evidence Collection
- AWS Artifact
- Single source you can visit to get the compliance-related info that matters to you, such as security and compliance reports
- What is available?
- Huge number of reports available
- Service Organization control (SOC) reports
- Payment Card Industry (PCI) reports
- As well as other certifications - HIPAA, etc
- Huge number of reports available
- AWS Cognito
- Provides authentication, authorization, and user management for your web and mobile apps in a single service without the need for custom code
- Users can sign-in directly with a UN/PW they create or through a third party (FB, Amazon, Google, etc)
- ⇒ authorization engine
- Provides the following features:
- Sign-up and sign-in options for your apps
- Access for guest users
- Acts as an identity broker between your application and web ID providers, so you don’t have to write any custom code
- Synchronizes user data across multiple devices
- Recommended for all mobile apps that call AWS Services
- Use cases:
- Authentication
- Users can sign in using a user pool or a 3rd party identity provider, such as FB
- 3rd Party Authentication
- Users can authenticate using identity pools that require an identity pool (IdP) token
- Access Server-Side Resources
- A signed-in user is given a token that allows them access to resources that you specify
- Access AWS AppSync Resources
- Users can be given access to AppSync resources with tokens received from a user or identity pool in Cognito
- Authentication
- User Pools and Identity Pools
- Two main components of Cognito
- User Pools
- Directories of users that provide sign-up and sign-in options for your application users
- Identity Pools
- Allows you to give your users access to other AWS Services
- You can use identity pools and user pools together or separately
- User Pools
- Two main components of Cognito
- How it works - broadly
- When you use the basic authflow, your app first presents an ID token from an authorized Amazon Cognito user pool or third-party identity provider in a GetID request.
- The app exchanges the token for an identity ID in your identity pool.
- The identity ID is then used with the same identity provider token in a GetOpenIdToken request.
- GetOpenIdToken returns a new OAuth 2.0 token that is issued by your identity pool.
- You can then use the new token in an AssumeRoleWithWebIdentity request to retrieve AWS API credentials.
- The basic workflow gives you more granular control over the credentials that you distribute to your users.
- The GetCredentialsForIdentity request of the enhanced authflow requests a role based on the contents of an access token.
- The AssumeRoleWithWebIdentity request in the classic workflow grants your app a greater ability to request credentials for any AWS Identity and Access Management role that you have configured with a sufficient trust policy.
- You can also request a custom role session duration.
- Cognito Sequence
- Device/App connects to a User Pool in Cognito - You are authenticating and getting tokens
- Once you've got that token, your device is going to exchange that token to an identity pool, and then the identity pool with hand over some AWS credentials
- Then you can use those credentials to access your AWS Services
- Basic Cognito Sequence:
- Request to user pool, authenticates and gets token
- Exchanges token and get AWS creds
- Use AWS creds to access AWS services
- Provides authentication, authorization, and user management for your web and mobile apps in a single service without the need for custom code
- Amazon Detective
- You can analyze, investigate and quickly identify the root cause of potential security issues or suspicious activities
- Detective pulls data from your AWS resources and uses ML, statistical analysis, and graph theory to build a linked set of data that enables you to quickly figure out the root cause of your security issues
- To auto create an overview of users, resources, and the interactions between them over time
- Sources for Detective:
- VPC flow logs, CloudTrail logs, EKS audit logs, and GuardDuty findings
- Use Cases:
- Triage Security Findings - generates visualizations
- Threat Hunting
- Exam Tips:
- Operates across multiple services and analyzes root cause of an event
- If you see “root cause” or “graph theory”, think Detective
- Don’t confuse with Inspector
- Inspector = Automated vulnerability management service that continually scans EC2 and container workloads for software vulnerabilities and unintentioned network exposure
- AWS Network Firewall
- Physical firewall protection - a managed service that makes it easy to deploy physical firewall protection across your VPCs
- Managed infrastructure
- Includes a firewall rules engine that gives you complete control over your network traffic
- Allowing you to do things such as block outbound Server Message Block (SMB) requests to stop the spread of malicious activity
- Benefits:
- Physical infrastructure in the AWS datacenter that is managed by AWS
- Network Firewall works with Firewall Manager
- FW Manager with Network Firewall added: Allows you to centrally manage security policies across existing and newly created accounts and VPC
- Also provides an Intrusion Detection System (IPS) that gives you active traffic flow inspection
- See IPS, think Network Firewall
- Use Cases:
- Filter Internet Traffic
- Use methods like ACL rules, stateful inspection, protocol detection, and intrusion prevention to filter your internet traffic
- Filter Outbound Traffic
- Provide the URL/domain name, IP address, and content-based outbound traffic filtering
- Help you stop possible data loss and block known malicious communicators
- Inspect VPC-to-VPC Traffic
- Auto inspect traffic moving from one VPC to another as well as across multiple accounts
- Filter Internet Traffic
- Exam Tips:
- Scenario about filtering your network traffic before it reaches your internet gateway
- Or if you require IPS or any hardware firewall requirements
- Physical firewall protection - a managed service that makes it easy to deploy physical firewall protection across your VPCs
- AWS Security Hub
- Single place to view all of your security alerts from services like GuardDuty, Inspector, Macie, and Firewall Manager
- Works across multiple accounts
- Use Cases:
- Conduct Cloud Security Posture Management (CSPM)- use automated checks that comply with common frameworks (for ex: Center for Information Security (CIS) or PSI DSS) to help reduce your risk
- Correlate security findings to discover new insights
- Aggregate all your security findings in one place, allowing security staff to more easily identify threats and alerts
- Single place to view all of your security alerts from services like GuardDuty, Inspector, Macie, and Firewall Manager
- CloudFormation
- Overview:
- Written in declarative programming language supports either JSON or YAML formatting
- Creates immutable architecture - easily create/destroy architecture
- Creates the same API calls that you would make manually
- Steps in CloudFormation:
- Step 1: write code
- Step 2: Deploy your template
- When you upload your template, CloudFormation engine will go through the process of making the needed AWS API calls on your behalf
- Create CloudFormation Stack
- Set parameters that are defined in your template and allow you to input custom values when you create or update a stack
- Parameters come from the code in the template
- Set parameters that are defined in your template and allow you to input custom values when you create or update a stack
- 3 sections of CloudFormation template:
- Parameters
- Mappings = values that fill themselves in during formation
- Resource Section
- If CloudFormation finds an error, it rolls back to the last known good state
- Overview:
- Elastic Beanstalk
- The Amazon PaaS tool - one stop for everything AWS
- Automation
- Automates all of your deployments
- You can templatize what you would like your environment to look like
- Deployments handled for us- upload code, test your code in a staging environment, then deploy to production
- Handles building out the insides of your EC2 instances for you
- Configuring Elastic Beanstalk
- Pick your platform
- Pick language - supports docker which means we can run all sorts of languages/environments inside a container on Elastic Beanstalk
- Additional Configurations
- Basically bundles all the wizards from across AWS services and gives you a place to configure all these in Beanstalk
- Pick your platform
- Exam Tips:
- Bring your code and that is all
- Elastic Beanstalk = PaaS tool
- It builds the platform and stacks your application on top
- Not serverless - Beanstalk creates and manages standard EC2 architecture
- Systems Manager
- Suite of tools designed to let you view, control and automate both your AWS architecture and on-prem architecture
- Features of Systems Manager
- Automation Documents [now called Runbooks]
- Can be used to control your instances or AWS resources
- Run Command
- Executes commands on your hosts
- Patch Manager
- Manage app versions
- Parameter Store
- Secret Values
- Hybrid Architecture
- Control you on-prem architecture
- Session Manager
- Allows you to connect and remotely interact with your architecture
- Automation Documents [now called Runbooks]
- All it takes for EC2/on-prem to be managed by Systems Manager is to:
- Install Systems Manager Agent
- And give the instance a role/permissions to communicate to the Systems Manager
- Caching
- Types of Caching
- Internal: in front of database to store frequent queries, for example
- External: CDN = Content Delivery Network
- AWS Caching Options
- CloudFront = External
- ElastiCache = Internal
- DAX = DynamoDB Solution
- Global Accelerator = External
- Types of Caching
- Global Caching with CloudFront
- CloudFront Overview
- Fast Content Delivery Network (CDN) service that securely delivers data, videos, apps, and APIs to customers globally
- Helps reduce latency and provide higher transfer speeds using AWS edge locations
- First user makes request through CloudFront at an Edge location, CloudFront will go to S3 and grab object, it will hold a copy of that object at the Edge Location
- First user’s request is not faster, but all after are pulling from Edge location
- Fast Content Delivery Network (CDN) service that securely delivers data, videos, apps, and APIs to customers globally
- CloudFront Settings
- Security
- Defaults to HTTPS connections with the ability to add custom SSL certifications
- Put secure connection on static S3 connections
- Global Distribution
- Cannot pick specific countries, just general areas
- Endpoint Support - AWS and Non-AWS
- Can be used to front AWS endpoints as well as non-AWS applications
- Expiring Content
- You can force an expiration of content from the cache if you cannot wait for the TTL
- Can restrict access to your content via CloudFront using signed URLs or signed cookies
- Security
- Exam Tips:
- Solution for external customer performance issue
- CloudFront Overview
- Caching your data with ElastiCache and DAX
- ElastiCache
- Managed version of 2 open source technologies
- Memcached
- Redis
- Neither of these tools are specific to AWS but by using ElastiCache, you can spin up 1 or the other, or both to avoid a lot of common issues
- ElastiCache can sit in front of almost any database, but it really excels being placed in front of RDS’s
- Memcached vs Redis
- Both sit in front of database and cache common queries that you make
- Memcached
- Simple db caching solution
- Not a db by itself
- No failover, no multi-AZ support, no backups
- Redis
- Supported as a caching solution
- But also has the ability to function as a standalone NoSQL db
- Managed version of 2 open source technologies
- ElastiCache
“Caching Solution” but also can be the answer if you are looking for a NoSQL solution and DynamoDB isn’t present
Has failover, multi-AZ, backup support
- DynamoDB Accelerator (DAX)
- It is an In-Memory Cache
- Reduce DynamoDB response times from milliseconds to microseconds
- DAX lives inside a VPC, you specify which - is highly available
- You are in control
- You determine the node size and count for the cluster, TTL for the data, and maintenance windows for changes and updates
- It is an In-Memory Cache
- DynamoDB Accelerator (DAX)
- Fixing IP Caching with Global Accelerator
- Global Accelerator
- A networking service that sits in front of your apps and sends your users’ traffic through AWS’s global network infrastructure
- Can increase performance and help deal with IP Caching
- IP Caching Issue
- User connecting to ELB, caches that ELB’s IP address (for the period defined by TTL)
- If that ELB goes offline and its IP changes, the user will be trying to connect with wrong IP
- Global accelerator solves this problem by sitting in front of ELB
- User is served 1 of only 2 IP addresses - that never change
- Even if ELB’s IP changes, user connection doesn't change
- Top 3 features of Global Accelerator:
- Masks Complex Architecture
- Global Accelerator IPs never change for users
- Speeds things up
- Traffic is routed through AWS’s global network infrastructure
- Weighted Pools
- Create weighted groups behind the IPs to test out new features or handle failure in your environment
- Masks Complex Architecture
- Creating Global Accelerator
- Listeners = port/port range
- Listeners direct traffic to one or more endpoint groups (endpoints = such as load balancers)
- Each listener can have multiple endpoint groups
- Each endpoint group can only include endpoints that are in one Region
- Adjust the weight here
- Global Accelerator solves IP caching
- A networking service that sits in front of your apps and sends your users’ traffic through AWS’s global network infrastructure
- Global Accelerator
- AWS Organizations
- Managing accounts with AWS Organizations
- Free governance tool that allows you to create and manage multiple AWS accounts - can control your accounts from a single location
- Applying standards across accounts (ex: Prod, Dev, Beta, etc)
- Key features in Organizations
- It is vital to create a Logging Account
- It is best practice to create a specific account dedicated to logging
- Ship all logs to one central location with Organizations
- CloudTrail supports logs aggregation
- Programmatic Creation: easily create and destroy new AWS accounts with API calls
- Reserve Instances: RIs can be shared across all accounts
- Consolidated Billing
- Service Control Policies (SCPs) can limit users’ permissions
- SCPs are in JSON format
- Once implemented, these policies will be applied to every single resource inside an account
- They are the ultimate way to restrict permissions and even apply to the root account
- Effectively a global policy and the only way to restrict what the root user can do
- SCPs never give permissions, they ONLY TAKE away the possible permissions that can be handed out
- Deny rules - deny specific things globally
- Allow rules - even more restrictive because it limits all of the permissions we could hand out
- It is vital to create a Logging Account
- Managing accounts with AWS Organizations
- Resource Access Manager (RAM)
- Free service that allows you to share AWS resources with other accounts and within your organization
- Allows you to easily share resources rather than having to create duplicate copies
- What can be shared?
- Transit Gateways
- VPC Subnets
- License Manager
- Route53 Resolver
- Dedicated Hosts
- Etc
- Can set permissions for what actions are allowed to happen on shared resources
- RAM vs VPC Peering
- Use RAM when sharing resources within the same region
- Use VPC Peering when sharing resources across regions
- Setting up Cross Account Role Access
- Cross-Account Role Access
- Allows you to set up temporary access you can easily control
- Set up primary user and then other users assume roles rather than having to create many many accounts
- Steps to set up Cross-Account Role Access:
- Create an IAM Role
- Grant access to allow users to temporarily assume role
- Exam Tips
- It is preferred to create cross-account roles rather than add additional IAM users
- Auditing - temporary access, temporary employees
- Cross-Account Role Access
- AWS Config
- Inventory management and control tool
- Allows you to show the history of your infrastructure along with creating rules to make sure it conforms to the best practices you’ve laid out
- 3 things it allows us to do:
- Allows us to query our architecture
- Can easily discover what architecture you have in your account - query by resource type, tag, even see deleted resources
- Rules can be created to flag when something is going wrong/out of compliance
- Whenever a rule is violated, you can be alerted or even have it auto fixed
- Shows history of Environment
- When did something change, who made that call, etc
- Allows us to query our architecture
- Can open up specific CloudTrail event that is tied to that event in Config
- Can auto remediate issues
- Can select remediation actions
- For example, can auto kick off an Automation Document that will block public access
- Can select remediation actions
- Exam Tips
- Config = Setting standards
- Directory Service
- Fully managed version of Active Directory
- Allows you to offload the painful parts of keeping AD online to AWS while still giving you the full control and flexibility AD provides
- Available Types:
- Managed Microsoft AD
- Entire AD suite, easily build out AD in AWS
- AD Connector
- Creates a tunnel between AWS and your on-prem AD
- Want to leave AD in physical data center
- Get an endpoint that you can authenticate against in AWS while leaving all of your actual users and data on-prem
- Simple AD
- Standalone directory powered by Linux Samba AD-Compatible server
- Just an authentication service
- Managed Microsoft AD
- AWS Cost Explorer
- Easy-to-use tool that allows you to visualize your cloud costs
- Can generate reports based on a variety of factors, including resource tags
- What can it do?
- Break down costs on a service-by-service basis
- Can break out by time, can estimate next month
- Filter and breakdown data however we want
- Exam tips
- Have to set tags as “cost allocation tag” to use
- Cost Explorer and Budgets go hand-in-hand
- Easy-to-use tool that allows you to visualize your cloud costs
- AWS Budgets
- Allows organizations to easily plan and set expectations around cloud costs
- Easily track your ongoing spending and create alerts to let users know where they are close to exceeding their allotted spend
- Types of Budgets - you get 2 free each month
- Cost Budgets
- Usage Budgets
- Reservation Budgets - RIs
- Savings Plan Budgets
- Exam Tips
- Can be alerted on current spend or projected spend
- Can create a budget using tags as a filter
- Allows organizations to easily plan and set expectations around cloud costs
- AWS Costs and Usage Reports (CUR)
- Most comprehensive set of cost and usage data available for AWS spending
- Publishes billing reports to AWS S3 for centralized collection
- These breakdown costs by the time span (hour, day, month), service and resource, or by tags
- Daily updates to reports in S3 in CSV formats
- Integrates with other services - Athena, Redshift, QuickSight
- Use Cases for AWS CUR:
- Within Organizations for entire OU groups or individual accounts
- Tracks Savings Plans utilizations, changes, and current allocations
- Monitor On-Demand capacity reservations
- Break down your AWS data transfer charges: external and inter-Regional
- Dive deeper into cost allocation tag resources spending
- Exam Tip
- Most comprehensive overview of spending
- Reducing compute spend using Savings Plans and AWS Compute Optimizer
- AWS Compute Optimizer
- Optimizes, analyzes configurations and utilization metrics of your AWS resources
- Reports current usage optimizations and potential recommendations
- Graphs
- Informed decisions
- Which resources work with this service?
- EC2, Auto Scaling Groups, EBS, Lambda
- Supported Account Types
- Standalone AWS account without Organizations enabled
- Member Account - single member account within an Organization
- Management Account
- When you enable at the AWS Organization management account, you get recommendations based on entire organization (or lock down to 1 account)
- Things to know:
- Disabled by default
- Must opt in to leverage Compute Optimizer
- After opting in, enhance recommendations via activation of recommendation preferences
- Disabled by default
- Savings Plans
- Offer flexible pricing modules for up to 72% savings on compute
- Lower prices for EC2 instances regardless of instance family, size, OS, tenancy, or Region
- Savings can also apply to Lambda and Fargate usage
- SageMaker plans available for lowering SageMaker instance pricing
- Require Commitments
- 1 or 3 year options
- Pricing Plan options:
- Pay all upfront - most reduced
- Partial upfront
- No upfront
- Savings Plan Types:
- Compute Savings
- AWS Compute Optimizer
Most flexible savings plan
Applies to any EC2 compute, Lambda, or Fargate usage
Up to 66% savings on compute
- EC2 Instance Savings
Stricter savings plan
Applies only to EC2 instances of a specific instance family in specific regions
Up to 72% savings
- SageMaker Savings
Only SageMaker Instances - any region and any component, regardless of family or sizing
Up to 64% savings
- Using and applying Savings Plan
- View recommendations in AWS billing console
- Recommendations are auto calculated to make purchasing easier
- Add to cart and purchase directly within account
- Apply to usage rates AFTER your RIs are applied and exhausted
- RIs have to be used first
- If in a consolidated billing family; savings applied to account owner first, then can be spread to others if sharing enabled
- Using and applying Savings Plan
- Trusted Advisor for Auditing
- Trusted Advisor Overview
- Fully managed best practice auditing tool
- It will scan 5 different parts of your account and look for places when you could improve your adoption of the recommended best practice provided by AWS
- 5 Questions Trusted Advisor Asks:
- Cost Optimizations: Are you spending money on resources that are not needed?
- Performance: Are your services configured properly for your environment?
- Security: Is your AWS architecture full of vulnerabilities?
- Fault Tolerance: Are you protected when something fails?
- Service Limits: Do you have room to scale?
- Want to link Trusted Advisor with an automated response to alert users or fix the problem
- Use EventBridge (CloudWatch Events) to kick of Lambda function to fix problem
- To get the most useful checks, you will need a Business or Enterprise support plan
- Trusted Advisor Overview
- Control Tower to enforce account Governance
- Control Tower Overview
- Governance: Easy way to set up and govern an AWS multi-account environment
- Orchestration: automates account creation and security controls via other AWS Services
- Extension: extends AWS Organizations to prevent governance drift, and leverabes different guardrails
- New AWS Accounts: users can provision new AWS accounts quickly, using central administration-established compliance policies
- Simple Terms: quickest way to create and manage a secure, compliance, multi-account environment based on best practices
- Features and Terms
- Landing Zone
- Well-architected, multi-account environment based on compliance and security best practices
- Basically a container that holds all of your Organizational Units, your accounts within there OU’s, and users/other resources that you want to force compliance on
- Can scale to fit whatever side you need
- Guardrails
- High-level rules providing continuous governance for the AWS Environment
- 2 Types
- Preventative
- Detective
- Account Factory
- Configurable account template for standardizing pre-approved configurations of new accounts
- CloudFormation Stack Set
- Automated deployments of templates deploying repeated resources for governance
- Management account would deploy a stack set to either the entire organization unit or the entire organization itself using repeatedly deployed resources
- Shared Accounts
- Three accounts used by Control Tower
- 2 of which are created during landing zone creation: Log Archive and Audit
- Three accounts used by Control Tower
- Landing Zone
- More on GuardRails
- High-level rules written in plain language providing ongoing governance
- 2 types:
- Preventative:
- Ensures accounts maintain governance by disallowing violating actions
- Leverages service control policies (SCPs) within Organizations
- Statuses of: Enforced or Not Enabled
- Supported in all regions
- Detective:
- Detects and alerts on noncompliant resources within all accounts
- Leverages AWS Config Rules
- Preventative:
- Control Tower Overview
Config Rules - it alerts, does NOT remediate unless you leverage other resources
- Statuses: clear, in violation or not enabled
- Only apply to certain regions
Only going to work in regions that are supported by Control Tower
Which is currently not every region
- Control Tower Diagram
- Start with management account - with Organization and Control Tower enabled
- Control Tower creates 2 accounts (“shared accounts”)
- Log Archive Account
- Audit Account
- Control Tower places an SCP on every account that exists within our Organization → Preventative Guardrails
- Control Tower places AWS Config Rules in each account as well → Detective Guardrails
- All of our Config and CloudTrail logs get sent to the Log Archive shared account - to centralize logging
- Will also set up notifications for any governance violations that may occur
- All governance will be sent to the auditing account - including configuration events, aggregate security notifications, and drift notifications
- Go to an SNS topic in the audit account, you can use to alert the correct team
- All governance will be sent to the auditing account - including configuration events, aggregate security notifications, and drift notifications
- Control Tower Diagram
- AWS License Manager
- Manage Software Licenses
- Licenses made easy - simplifies managing software licenses with different vendors
- Centralized: helps centrally manage licenses across AWS accounts and on-prem environments
- Set usage limits
- Control and visibility into usage of licenses and enabling license usage limits
- Reduce overages and penalties via inventory tracking and rule-based controls for consumption
- Versatile- support any software based on vCPU physical cores, sockets, and number of machines
- AWS Personal Health Dashboard (aka AWS Health)
- Monitoring Health Events
- Visibility of resource performance and availability of AWS services or accounts
- View how the health events affect you and your services, resources, and accounts
- AWS maintains timeliness and relevant info within the events
- View upcoming maintenance tasks that may affect your accounts and resources
- Alerts- near instant delivery of notifications and alerts to speed up troubleshooting or prevention actions
- Automates actions based on incoming events using EventBridge
- Health Event → EventBridge → SNS topic, etc
- Concepts
- AWS Health Event = notifications sent on behalf of AWS services or AWS
- Account-specific event: events specific to your AWS account or AWS organization
- Public event = events reported on services that are public
- AWS Health Dashboard
- Dashboard showing account and public events, as well as service health
- Event type code = include the affected services and the specific type of event
- Event type category = associated category will be attached to every event
- Event status = open, closed, or upcoming
- Affected Entities
- Exam tip
- Look out for questions about checking alerts for service health and automating the reboot of EC2 instances for AWS Maintenance
- Monitoring Health Events
- AWS Service Catalog and AWS Proton
- Standardizing Deployments using AWS Service Catalog
- Allows organizations to create and manage catalogs of approved IT services for deployments within AWS
- Multipurpose catalogs - list things like AMIs, server software, databases, and other pre-configured components
- Centralized management of IT service and maintain compliance
- End-User Friendly - easily deploy approved items
- CloudFormation
- Catalogs are written and listed using CloudFormation templates
- Benefits:
- Standardize
- Self-service deployments
- Fine-grained Access Control
- Versioning within Catalogs- propagate changes automatically
- AWS Proton
- Creates and manages infrastructure and deployment tooling for users as well as serverless and container-based apps
- How it works:
- Automate IaC provisioning and deployments
- Define standardized infrastructure for your serverless and container-based apps
- Use templates to define and manage app stacks that contain ALL components
- Automatically provisions resources, configures CI/CD, and deploys the code
- Supports AWS CloudFormation and Terraform IaC providers
- Proton is an all encompassing tool/service for deployments of your applications
- Standardization, empower developers
- Standardizing Deployments using AWS Service Catalog
- Optimizing Architectures with the AWS Well-Architected Tool
- Review 6 Pillars of the Well-Architected Framework:
- Operational Excellence
- Reliability
- Security
- Performing Efficiency
- Cost Optimization
- Sustainability
- Well-Architected Tool
- Provides a consistent process for measuring cloud architecture
- Enables assistance with documenting workloads and architectures
- Guides for making workloads reliable, secure, efficient, and cost effective
- Measure workloads against years of AWS best practice
- Intended for specific audiences: technical teams, CTOs, architecture and operations teams
- Review 6 Pillars of the Well-Architected Framework:
- AWS Snow Family
- Ways to move data to AWS
- Internet
- Could be slow, presents security risks
- Direct Connect
- Not always practical - not for short periods of time
- Physical
- Bypass internet entirely, and bundle data to physically move
- Internet
- Snow Family
- Set of secure appliances that provide petabyte-scale data collection and processing solutions at the edge and migrate large-scale data into and out of AWS
- Offers built-in computing capabilities, enabling customers to run their operations in remote locations that do not have data center access or reliable network connectivity
- Members of the Snow Family:
- Snowcone
- Ex: climbing a wind turbine to collect data
- Smallest device
- 8TB of storage, 4 GB memory, 2 vCPUs
- Easily migrate data to AWS after you’ve processed it
- IoT sensor integration
- Perfect for edge computing where space and power are constrained
- Snowball Edge
- Ex: on a boat
- Jack of all trades
- 48-81TB storage
- Storage, compute (less than Edge Compute), and GPU flavors, varying amount of CPU/RAM
- Perfect for off-the-grid computing or migration to AWS
- Snowmobile
- Literally a semi truck of hard drives
- 100PB of storage
- Designed for exabyte-scale data center migration
- Snowcone
- Set of secure appliances that provide petabyte-scale data collection and processing solutions at the edge and migrate large-scale data into and out of AWS
- Ways to move data to AWS
- Storage Gateway and Types
- Storage Gateway
- A hybrid cloud storage service that helps you merge on-prem resources with the cloud
- Can help with a one-time migration or a long-term pairing of your architecture with AWS
- Types of Storage Gateway:
- File Gateway
- Caching local files
- NFS or SMB Mount - basically a network file share
- Mount locally and backs up data into S3
- Keep a local copy of recently used files
- Versions of File Gateway:
- Backup all data into cloud and Storage Gateway just act as the method of doing that - data lives in S3
- Or you can keep a local cached copy of most recently used files - so you don’t have to download from S3
- Keep data on-prem, backups go to S3
- Scenario - extend on-prem storage
- Helps with migrations to AWS
- Volume Gateway
- Backup drives
- iSCSI mount
- Backing up these disks that the VMs are reading/writing to
- Same cached or stored mode as File Gateway - all backed up to S3
- Can create EBS snapshots and restore volumes inside AWS
- Easy way to migrate on-prem volumes to become EBS volumes inside AWS
- Perfect for backups and migration to AWS
- Tape Gateway
- Ditch the physical tapes and backup to Tape Gateway
- Stores inside S3 Glacier, Deep Archive, etc
- Directly integrated as a VM on-prem so it doesn’t change the current workflow
- It is encrypted
- File Gateway
- Exam Tips
- Storage Gateway = Hybrid Storage
- Complement existing architecture
- Storage Gateway = Hybrid Storage
- Storage Gateway
- AWS DataSync
- Agent-based solution for migrating on-prem storage to AWS
- Easily move data between NFS and SMB shares and AWS storage solution
- Migration Tool
- Using DataSync:
- On-prem
- Have on-prem server and install DataSync agent
- Configure DataSync service to tell it where data is going to go
- Secure transmission with TLS
- Supports S3, EFS, and FSx
- On-prem
- AWS Transfer Family
- Allows you to easily move files in and out of S3 or EFS using SFTP, FTP over SSL (FTPS), or FTP
- How does it transfer:
- Legacy users/apps have processes to transfer data, if want to now transfer to S3 or EFS can put Transfer Family (SFTP, FTPS, FTP) where the old endpoint was and have that service transfer to AWS S3/EFS
- Transfer Family Members
- AWS Transfer for SFTP and AWS Transfer for FTPS - transfers from outside of your AWS environment into S3/EFS
- AWS Transfer for FTP - only supported within the VPC and not over public internet
- Exam Tips
- Bringing legacy app storage to cloud
- DNS entry (endpoint) stays the same in legacy app
- We just swap out the old endpoint to become S3
- Migration Hub
- Single place to track the progress of your app migration to AWS
- Integrates with Server Migration Service (SMS) and Database Migration Service (DMS)
- Server Migration Service (SMS)
- Schedule movement for VMWare server migration
- All scheduled time, takes a copy of your underlying VSphere volume, bring that data into S3
- It converts that volume in S3 into an EBS Snapshot
- Creates and AMI from that
- Can use AMI to launch EC2 instance
- Essentially gives you an easy way to take your VM architecture and convert it to an AMI
- Database Migration Service (DMS)
- Takes on-prem/EC2/RDS old Oracle (or SQL Server) and runs the AWS Schema Conversion Tool on it
- To convert it to an Amazon Aurora DB
- Takes on-prem/EC2/RDS MySQL DB and consolidate it with DMS into Aurora
- Directory Service
- Fully managed version of Active Directory
- Allows you to offload the painful parts of keeping AD online to AWS while still giving you the full control and flexibility AD provides
- Available Types:
- Managed Microsoft AD
- Entire AD suite, easily build out AD in AWS
- AD Connector
- Creates a tunnel between AWS and your on-prem AD
- Want to leave AD in physical data center
- Get an endpoint that you can authenticate against in AWS while leaving all of your actual users and data on-prem
- Simple AD
- Standalone directory powered by Linux Samba AD-Compatible server
- Just an authentication service
- Managed Microsoft AD
- AWS Cost Explorer
- Easy-to-use tool that allows you to visualize your cloud costs
- Can generate reports based on a variety of factors, including resource tags
- What can it do?
- Break down costs on a service-by-service basis
- Can break out by time, can estimate next month
- Filter and breakdown data however we want
- Exam tips
- Have to set tags as “cost allocation tag” to use
- Cost Explorer and Budgets go hand-in-hand
- Easy-to-use tool that allows you to visualize your cloud costs
- AWS Budgets
- Allows organizations to easily plan and set expectations around cloud costs
- Easily track your ongoing spending and create alerts to let users know where they are close to exceeding their allotted spend
- Types of Budgets - you get 2 free each month
- Cost Budgets
- Usage Budgets
- Reservation Budgets - RIs
- Savings Plan Budgets
- Exam Tips
- Can be alerted on current spend or projected spend
- Can create a budget using tags as a filter
- Allows organizations to easily plan and set expectations around cloud costs
- AWS Costs and Usage Reports (CUR)
- Most comprehensive set of cost and usage data available for AWS spending
- Publishes billing reports to AWS S3 for centralized collection
- These breakdown costs by the time span (hour, day, month), service and resource, or by tags
- Daily updates to reports in S3 in CSV formats
- Integrates with other services - Athena, Redshift, QuickSight
- Use Cases for AWS CUR:
- Within Organizations for entire OU groups or individual accounts
- Tracks Savings Plans utilizations, changes, and current allocations
- Monitor On-Demand capacity reservations
- Break down your AWS data transfer charges: external and inter-Regional
- Dive deeper into cost allocation tag resources spending
- Exam Tip
- Most comprehensive overview of spending
- Reducing compute spend using Savings Plans and AWS Compute Optimizer
- AWS Compute Optimizer
- Optimizes, analyzes configurations and utilization metrics of your AWS resources
- Reports current usage optimizations and potential recommendations
- Graphs
- Informed decisions
- Which resources work with this service?
- EC2, Auto Scaling Groups, EBS, Lambda
- Supported Account Types
- Standalone AWS account without Organizations enabled
- Member Account - single member account within an Organization
- Management Account
- When you enable at the AWS Organization management account, you get recommendations based on entire organization (or lock down to 1 account)
- Things to know:
- Disabled by default
- Must opt in to leverage Compute Optimizer
- After opting in, enhance recommendations via activation of recommendation preferences
- Disabled by default
- Savings Plans
- Offer flexible pricing modules for up to 72% savings on compute
- Lower prices for EC2 instances regardless of instance family, size, OS, tenancy, or Region
- Savings can also apply to Lambda and Fargate usage
- SageMaker plans available for lowering SageMaker instance pricing
- Require Commitments
- 1 or 3 year options
- Pricing Plan options:
- Pay all upfront - most reduced
- Partial upfront
- No upfront
- Savings Plan Types:
- Compute Savings
- AWS Compute Optimizer
Most flexible savings plan
Applies to any EC2 compute, Lambda, or Fargate usage
Up to 66% savings on compute
- EC2 Instance Savings
Stricter savings plan
Applies only to EC2 instances of a specific instance family in specific regions
Up to 72% savings
- SageMaker Savings
Only SageMaker Instances - any region and any component, regardless of family or sizing
Up to 64% savings
- Migrating Workloads to AWS using AWS Application Discovery Service or AWS Application Migration Service (MGN)
- Application Discovery Service
- Helps you plan your migrations to the cloud via collection of usage and configuration data from on-prem servers
- Integrates with AWS Migration Hub which simplifies migrations and tracking migration statuses
- Helps you easily view discovered services, group them by application, and track each application migration
- How do we discover our on-prem servers?
- 2 Discovery Types
- Agentless
- 2 Discovery Types
- Application Discovery Service
Completed via the Agentless Collector
It is an OVA file within the VMWare vCenter
OVA file = deployable file for a new type of VM appliance that you can deploy in vCenter
Once you deploy the OVA, it identifies hosts and VMs in vCenter
Helps track and collect IP addresses and MAC addresses, info on resource allocations (memory and CPUs), and host names
Collects utilization data metrics
- Agent-Based
Via an AWS Application Discovery Agent that is deployed
Install this agent on each VM and physical server
There is an installer for Linux and for Windows
Collects more info than agentless process
Static Configuration data, time-series performance info, network connections and OS processes
- Application Migration Service (MGN)
- An automated lift and shift servicer for expediting migration of apps to AWS
- Used for physical, virtual, or cloud servers to avoid cutover windows or disruptions - flexible
- Replicates source servers into AWS and auto converts and launches on AWS to migrate quickly
- 2 key features are RTO and RPO:
- Recovery Time Objective
- Typically just minutes; depending on OS boot time
- Recovery Point Objective
- Measured in the sub-second range
- Can recover at any point after migration
- Recovery Time Objective
- Application Migration Service (MGN)
- Migraging DBs from On-Prem to AWS Database Migration Service (DMS)
- Migration tool for relational, Data Warehouses, NoSQL databases, and other data stores
- Migrate data into cloud or on-prem: either into or out of AWS
- Can be one-time migration or continuous replicate ongoing changes
- Conversion Tool called Schema Conversion Tool (SCT) used to transfer database schemas to new platforms
- How does DMS work?
- It's basically just a server running replication software
- Create a source and target connections
- Schedule tasks to run on DMS server to move data
- AWS creates the tables and primary keys *if they don't exist on the target)
- Optionally create you target tables beforehand
- Leverage the SCT for creating some or all of your tables, indexes, and more
- Source and target data stores are referred to as endpoints
- Important Concepts
- Can migrate between source and target endpoints with the same engine types
- Can also utilize SCT to migrate between source and target endpoints with different engines
- Important to know that at least 1 endpoint most live within an AWS Service
- AWS Schema Conversion Tool (SCT)
- Convert
- Supports many engine types
- Many types of relational databases including both OLAP and OLTP, even supports data warehouses
- Supports many endpoints
- Any supported RDS engine type: Aurora, Redshift
- Can use the converted schemas with dbs running on EC2 or data stored in S3
- So don't have to migrate to a db service, per se, can be EC2 or S3
- 3 Migration Types:
- Full Load
- All existing data is moved from sources to targets in parallel
- Any updates to your tables while this is in progress are cached on your replication server
- Full Load and Change Data Capture (CDC)
- CDC guarantees transactional integrity of the target db- only one
- CDC Only
- Only replicate the data changes from the source db
- Full Load
- Migrating Large Data Stores via AWS Snowball
- With terabyte migrations, can run into bandwidth throttle/network throttles on network
- Can leverage Snowball Edge
- Leverage certain Snowball Edge devices and S3 with DMS to migrate large data sets quickly
- Can still leverage SCT to extract data into Snowball devices and then into S3
- Load converted data
- DMS can still load the extracted data from S3 and migrate to chosen destination
- Also CDC compatible
- Migration tool for relational, Data Warehouses, NoSQL databases, and other data stores
- Replicating and Tracking Migrations with AWS Migration Hub
- Migration Hub
- Single place to discover existing servers, plan migration efforts and track migration statuses
- Visualize connection and server/db statuses that are a part of your migrations
- Options to start migrations immediately or group servers into app groups first
- Integrates with App Migration Service or DMS
- ONLY discovers and plans migrations and works with the other mentioned services to actually do the migrations
- Migration Phases
- Discover- find servers and databases to plan you migrations
- Migrate - connect tools to Migration Hub, and migrate
- Track
- Server Migration Service (SMS)
- Automate migrating on-prem services to cloud
- Flexible - covers broad range of supported VMs
- Works by incremental replications of server VMs over to AWS AMIs that can be deployed on EC2
- Can handle volume replication
- Incremental Testing
- Minimize downtime
- Migration Hub
- Amplify
- For Quickly deploying web apps
- Offers tools for front-end web and mobile developers to quickly build full-stack applications on AWS
- Offers 2 services:
- Amplify Hosting
- Support for common single-pane application (SPA) frameworks like React, Angular, and Vue
- Also supports Gatsby and Hugo static site generators
- Allows for separate prod and staging environments for the frontend and backend
- Support for Server-Side Rendering (SSR) apps like Next.js
- Remember cannot do dynamic websites in S3, so any answer with Server-Side Rendering would be Amplify
- Support for common single-pane application (SPA) frameworks like React, Angular, and Vue
- Amplify Studio
- Easy Authentication and Authorization
- Simplified Development
- Visual development environment to simplify creation of full-stack web or mobile apps
- Ready-to-use components, easy creation of backends and automated connections between the frontend and backend
- Amplify Hosting
- Exam Tip
- Amplify is the answer in scenario based questions like managed server-side rendering in AWS, easy mobile development, and developers running full-stack applications
- Device Farm
- For testing App Services
- Application testing service for testing and interacting with Android, iOS, and web apps on real devices
- 2 primary testing methods:
- Automated
- Upload scripts or use built-in tests for automatic parallel tests on mobile devices
- Remote Access
- You can swipe, gesture, and interact with the devices in real time via web browser
- Automated
- Amazon Pinpoint
- Enables you to engage with customers through a variety of different messaging channels
- Generally used by marketers, business users, and developers
- Terms:
- Projects
- Collection of info, segments, campaigns, and journeys
- Channels
- Platform you intend to engage your audience with
- Segments
- Dynamic or imported; designates which users receive specific messages
- Campaigns
- Initiatives engaging specific audience segments using tailored messages
- Journeys
- Multi-step engagements
- Message Templates
- Content and settings for easily reusing repeated messages
- Projects
- Leverage Machine Learning modules to predict user patterns
- 3 Primary uses:
- Marketing
- Transactions - order confirmations, shipping notifications
- Bulk Communications
- Enables you to engage with customers through a variety of different messaging channels
- Analyzing Text using Comprehend, Kendra, and Textract
- Comprehend
- Uses Natural Language Processing (NLP) to help you understand the meaning and sentiment in your text
- Ex: automate understanding reviews as positive or negative
- Automating comprehension at scale
- Use Cases:
- Analyze call center analytics
- Index and Search product reviews
- Legal briefs management
- Process financial data
- Uses Natural Language Processing (NLP) to help you understand the meaning and sentiment in your text
- Kendra
- Allows you to create an intelligent search service powered by machine learning
- Enterprise search applications - bridge between different silos of information (S3, file servers, websites), allowing you to have all the data intelligently in one place
- Use Cases:
- Research and Development Acceleration
- Improve Customer Interaction
- Minimize Regulatory and Compliance Risks
- Increase Employee productivity
- Can do research for you
- Textract
- Uses Machine Learning to automatically extract text, handwriting, and data from scanned documents
- Goes beyond OCR (Optical Character Recognition) by adding Machine Learning
- Turn text into data
- Use Cases:
- Convert handwritten/filled forms
- Comprehend
- AWS Forecast
- Time-series forecasting service that uses Machine Learning and it built to give you important business insights
- Can send your data to forecast and it will automatically learn your data, select the right Machine Learning algorithm, and then help you forecast your data
- Use cases:
- IoT, DevOps, Analytics
- AWS Fraud Detector
- AWS AI service built to detect fraud in your data
- Create a fraud detection machine learning model that is based on your data - can quickly automate this
- Use Cases:
- Identify suspicious online transactions
- Detect new account fraud
- Prevent Trial and Loyalty program abuse
- Improve account takeover detection
- Working with Text and Speech using Polly, Transcribe, and Lex
- Transcribe
- Speech to text
- Lex
- Build conversational interfaces in your apps using NLP
- Polly
- Turns text into lifelike speech
- Alexa uses: Transcribe → Lex (sends answer/text to) → Polly
- Transcribe
- Rekognition
- Computer vision product that automates the recognition of pictures and video using deep learning and neural networks
- Use these processes to understand and label images and videos
- Main use case is Content Moderation
- Also facial detection and analysis
- Celebrity recognition
- Streaming video events detection
- Ring, ex
- SageMaker
- To train learning models
- Way to build Machine Learning models in AWS Cloud
- 4 Parts
- Ground Truth: set up and manage labeling jobs for training datasets using active learning and human labeling
- Notebook: managed Jupyter notebook (python)
- Training: train and tune models
- Inference: Package and deploy Machine Learning models at scale
- Deployment Types:
- Online Usage- if need immediate response
- Offline Usage- otherwise
- Elastic Inference - used to decrease cost
- Translate
- Machine learning service that allows you to automate language translation
- Uses deep learning and neural networks
- Elastic Transcoder
- For converting media files
- Allows businesses/developers to convert (transcode) media files from original source format into versions that are optimized for various devices
- Benefits:
- Easy to use - APIs, SDKs, or via management console
- Elastically scalable
- AWS Kinesis Video Streams
- Way of streaming media content from a large number of devices to AWS and then running analytics, Machine Learning, and playback and other processing
- Ex: Ring
- Elastically scales
- Access data through easy-to-use APIs
- Use Cases:
- Smart Home- ring
- Smart city- CCTV
- Industrial Automation
- Way of streaming media content from a large number of devices to AWS and then running analytics, Machine Learning, and playback and other processing