Ch 4 - Logical Database Design and the Relational Model
Data Structure
Tables (relations), rows, columns
Data manipulation
Powerful SQL operations for retrieving and modifying data
Data integrity
Mechanism for implementing business rules that maintain integrity of manipulated data
Relation
A relation is a named, two-dimensional table of data
Consists of rows (records) and columns (attribute or fireld)
Reqs for a table to qualify as a relation:
Unique name
Every attrb. value must be atomic
Every row must be unique
Attr. (columns) in tables must have unique names
The order of the columns must be irrelevant
The order of the rows must be irrelevant
All relations are in 1st Normal form
Correspondence with E-R Model
Relations (tables) correspond with entity types and with manytomany relationship types
Rows correspond with entity instances and with to many relationship instances
Columns correspond with attributes
Key Field
Keys are special fields that serve two main purposes:
Primary keys are unique identifiers of the relation. Examples include employee numbers, social security numbers, etc. This guarantees that all rows are unique.
Primary keys
Unique identifiers of the relations. This guarantees that all rows are unique
Foreign Keys
Identifiers that enable a department relation (on the many sid of a relationship) to refer to its parent relation (on the one sid of the relationship)
Key can be simple (single field) or composite (more than one field)
Keys used as indexes to keep up the response to user queries
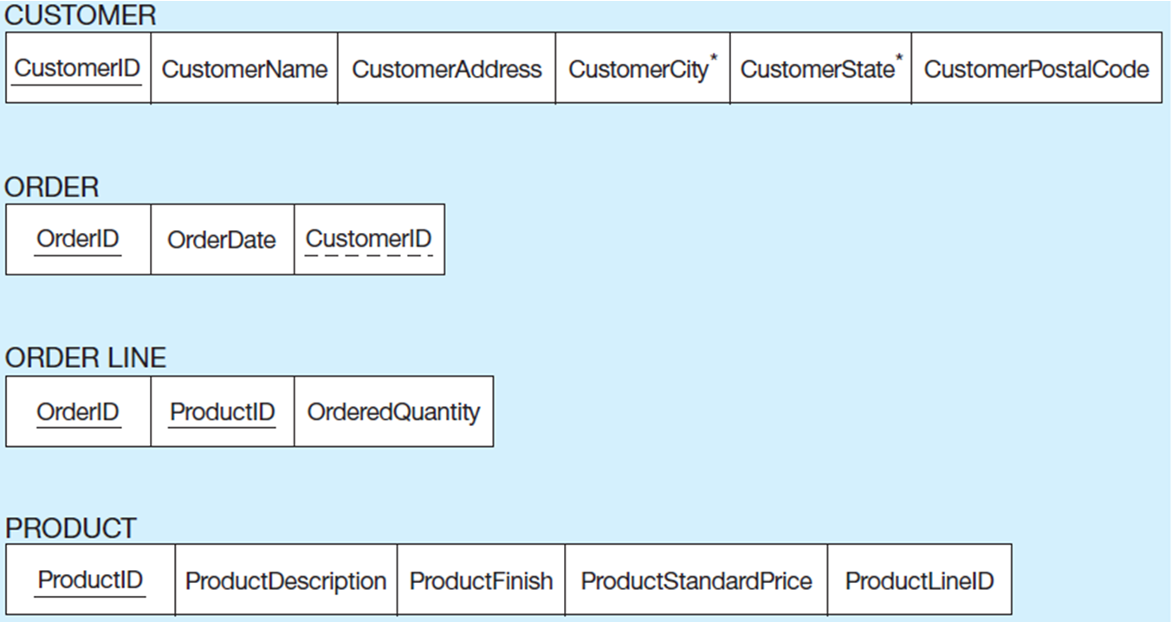
Schema for Four Relations
EER Notation
Integrity Constraints
Domain Constraints
Allowable values for an attribute (data types and restrictions on values)
Only valid values
Entity Integrity
No primary key attribute may be null. All primary key fields MUST contain data values
Referential Integrity
Rules that maintain consistency between the rows of two related tables
Any foreign key value (on the relation of the many side) must match a primary key value in the relation of the one side
Ex; Delete Rules
Restrict
don’t allow delete of “parent’ side if related rows exist in “dependent” side
Cascade
automatically delete “dependent” side rows that correspond with the “parent” side row to be deleted
Set-to-Null
set the foreign key in the dependent side to null if deleting from the parent side → not allowed for weak entities
Drawn via arrows from dependent to parent table
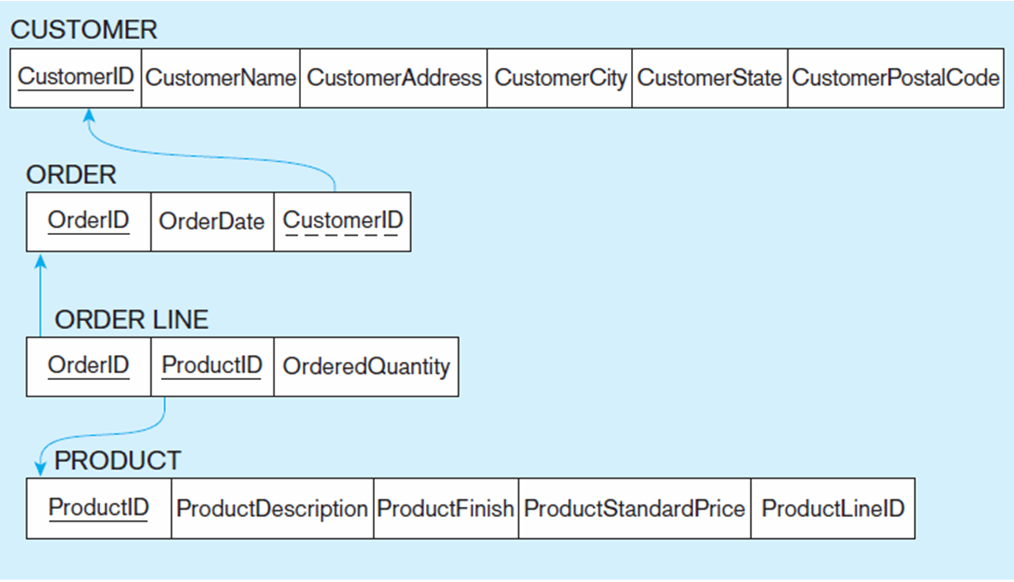
SQL Table Defintions
Referential integrity constraints are implemented with foreign key to primary key references

Transforming EER Diagrams into Relations
Mapping Regular Entities to Relations
Simple attributes: E-R attributes map directly onto the relation
Compose attributes: Use only their simple, component attributes
Make each element a distinct column
Multivalued attributes; Become a separate relation with a foreign key taken from the superior entity
Example of Mapping a Regular Entity
a) Customer entity type

b) Customer relation

a) customer entity type with composite attribute

a) customer entity type with composite attribute
b) Customer relation with address details

a) Employee entity type with multivalued attribute

b) employee and employee skill relations

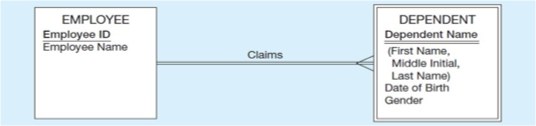
Mapping Weak Entities
Becomes a separate relation with a foreign key taken from the superior entity
Primary key composed of:
Partial identifier of weak entity
Primary key of identifying relation (strong entity)
a) Weak entity DEPENDENT
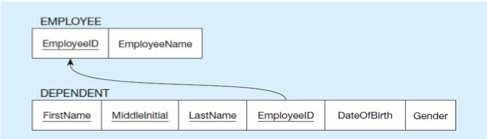
b) Relations resulting from weak entity
Mapping Binary Relationships
One-to-many
Primary key on the one side becomes a foreign key on the many side
Many-to-many
Create a new relation with the primary keys of the two entities as its primary key
One-to-one
Primary key on mandatory side becomes a foreign key on optional side
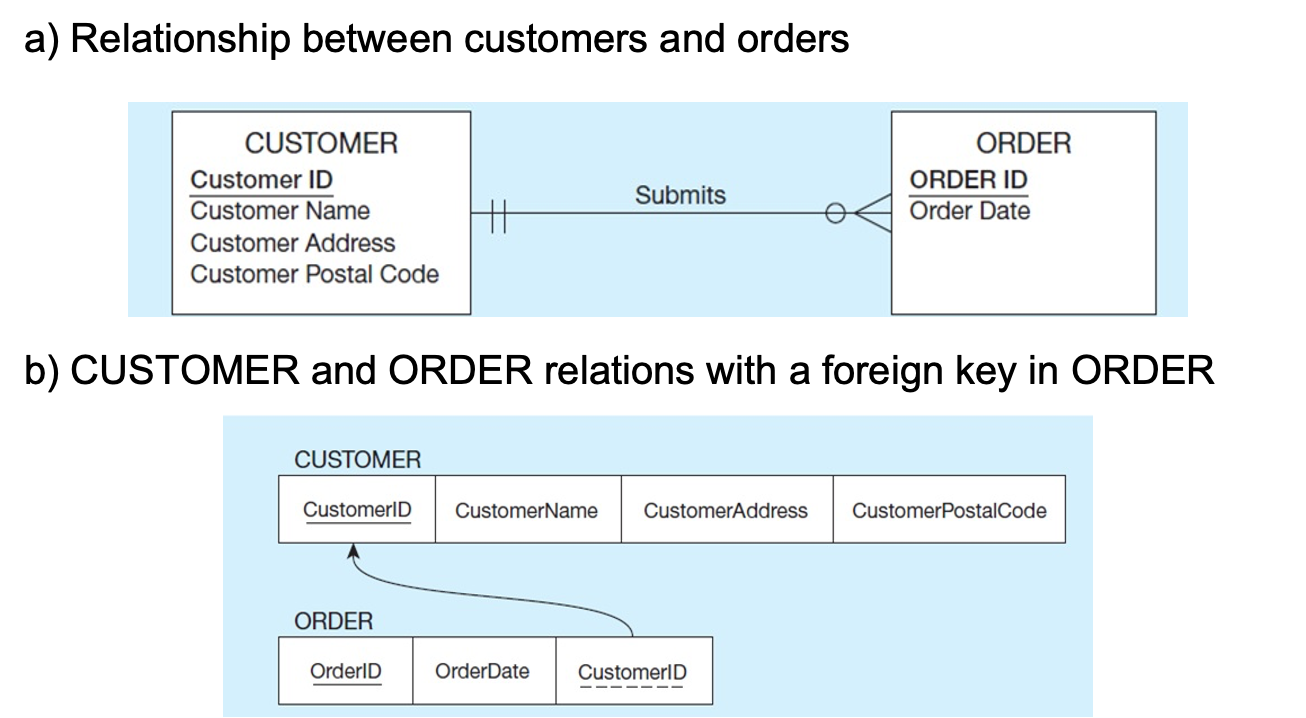
Mapping a 1:N Relationship
Mapping a M:N

Data Normalization
Primarily a tool to validate and improve a logical design so that it satisfies certain constraints that avoid unnecessary duplication of data
The process of decomposing relations with anomalies to produce smaller, well-structured relations
Well Structured Relations
Relations that contain minimal data redundancy and allow users to insert, delete, and update rows without causing data inconsistencies
Goal is to avoid anomalies
Insertion Anomaly – adding new rows forces user to create duplicate data
Deletion Anomaly – deleting rows may cause a loss of data that would be needed for other future rows
Modification Anomaly – changing data in a row forces changes to other rows because of duplication
Bad Relation
