


Splunk O11y Cloud Certified Metrics User (Splk-4001 dumps exam questions)
This is a very valuable Splunk O11y Cloud Certified Metrics User (splk-4001) practice material. Students who want to work in splunk can save this valuable material. It can make you progress and even enhance your promotion success. Rate.
As a teacher engaged in education in the IT field, I have mastered a lot of materials from various IT manufacturers. Today I will only share the latest materials for splunk certification. In the future, I will share a valuable learning material every day to help you achieve your goals. Of course, you also You can browse the IT material website I run: geekcert.com. All materials are included here.
Splunk O11y Cloud Certified Metrics User (Splk-4001) exam questions and answers
Question 1:
For which types of charts can individual plot visualization be set?
A. Line, Bar, Column
B. Bar, Area, Column
C. Line, Area, Column
D. Histogram, Line, Column
Correct Answer: C
The correct answer is C. Line, Area, Column. For line, area, and column charts, you can set the individual plot visualization to change the appearance of each plot in the chart. For example, you can change the color, shape, size, or style of the lines, areas, or columns. You can also change the rollup function, data resolution, or y-axis scale for each plot To set the individual plot visualization for line, area, and column charts, you need to select the chart from the Metric Finder, then click on Plot Chart Options and choose Individual Plot Visualization from the list of options. You can then customize each plot according to your preferences To learn more about how to use individual plot visualization in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/metrics/charts.html#Individual-plot-visualization https://docs.splunk.com/Observability/gdi/metrics/charts.html#Set-individual-plot- visualization
Question 2:
Which of the following is optional, but highly recommended to include in a datapoint?
A. Metric name
B. Timestamp
C. Value
D. Metric type
Correct Answer: D
The correct answer is D. Metric type. A metric type is an optional, but highly recommended field that specifies the kind of measurement that a datapoint represents. For example, a metric type can be gauge, counter, cumulative counter, or histogram. A metric type helps Splunk Observability Cloud to interpret and display the data correctly To learn more about how to send metrics to Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/metrics/metrics.html#Metric-types https://docs.splunk.com/Observability/gdi/metrics/metrics.html
Question 3:
A customer deals with a holiday rush of traffic during November each year, but does not want to be flooded with alerts when this happens. The increase in traffic is expected and consistent each year. Which detector condition should be used when creating a detector for this data?
A. Outlier Detection
B. Static Threshold
C. Calendar Window
D. Historical Anomaly
Correct Answer: D
historical anomaly is a detector condition that allows you to trigger an alert when a signal deviates from its historical pattern. Historical anomaly uses machine learning to learn the normal behavior of a signal based on its past data, and then compares the current value of the signal with the expected value based on the learned pattern. You can use historical anomaly to detect unusual changes in a signal that are not explained by seasonality, trends, or cycles. Historical anomaly is suitable for creating a detector for the customer\'s data, because it can account for the expected and consistent increase in traffic during November each year. Historical anomaly can learn that the traffic pattern has a seasonal component that peaks in November, and then adjust the expected value of the traffic accordingly. This way, historical anomaly can avoid triggering alerts when the traffic increases in November, as this is not an anomaly, but rather a normal variation. However, historical anomaly can still trigger alerts when the traffic deviates from the historical pattern in other ways, such as if it drops significantly or spikes unexpectedly.
Question 4:
Changes to which type of metadata result in a new metric time series?
A. Dimensions
B. Properties
C. Sources
D. Tags
Correct Answer: A
The correct answer is A. Dimensions. Dimensions are metadata in the form of key-value pairs that are sent along with the metrics at the time of ingest. They provide additional information about the metric, such as the name of the host that sent the metric, or the location of the server. Along with the metric name, they uniquely identify a metric time series (MTS)1 Changes to dimensions result in a new MTS, because they create a different combination of metric name and dimensions. For example, if you change the hostname dimension from host1 to host, you will create a new MTS for the same metric name1 Properties, sources, and tags are other types of metadata that can be applied to existing MTSes after ingest. They do not contribute to uniquely identify an MTS, and they do not create a new MTS when changed To learn more about how to use metadata in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/metrics-and-metadata/metrics.html#Dimensions https://docs.splunk.com/Observability/metrics-and-metadata/metrics-dimensions-mts.html
Question 5:
The Sum Aggregation option for analytic functions does which of the following?
A. Calculates the number of MTS present in the plot.
B. Calculates 1/2 of the values present in the input time series.
C. Calculates the sum of values present in the input time series across the entire environment or per group.
D. Calculates the sum of values per time series across a period of time.
Correct Answer: C
According to the Splunk Test Blueprint - O11y Cloud Metrics User document1, one of the metrics concepts that is covered in the exam is analytic functions. Analytic functions are mathematical operations that can be applied to metrics to transform, aggregate, or analyze them. The Splunk O11y Cloud Certified Metrics User Track document2 states that one of the recommended courses for preparing for the exam is Introduction to Splunk Infrastructure Monitoring, which covers the basics of metrics monitoring and visualization. In the Introduction to Splunk Infrastructure Monitoring course, there is a section on Analytic Functions, which explains that analytic functions can be used to perform calculations on metrics, such as sum, average, min, max, count, etc. The document also provides examples of how to use analytic functions in charts and dashboards. One of the analytic functions that can be used is Sum Aggregation, which calculates the sum of values present in the input time series across the entire environment or per group. The document gives an example of how to use Sum Aggregation to calculate the total CPU usage across all hosts in a group by using the following syntax: sum(cpu.utilization) by hostgroup
Question 6:
A DevOps engineer wants to determine if the latency their application experiences is growing fester after a new software release a week ago. They have already created two plot lines, A and B, that represent the current latency and the latency a week ago, respectively. How can the engineer use these two plot lines to determine the rate of change in latency?
A. Create a temporary plot by dragging items A and B into the Analytics Explorer window.
B. Create a plot C using the formula (A-B) and add a scale:percent function to express the rate of change as a percentage.
C. Create a plot C using the formula (A/B-l) and add a scale: 100 function to express the rate of change as a percentage.
D. Create a temporary plot by clicking the Change% button in the upper-right corner of the plot showing lines A and B.
Correct Answer: C
The correct answer is C. Create a plot C using the formula (A/B-l) and add a scale: 100 function to express the rate of change as a percentage. To calculate the rate of change in latency, you need to compare the current latency (plot A) with the latency a week ago (plot B). One way to do this is to use the formula (A/B-l), which gives you the ratio of the current latency to the previous latency minus one. This ratio represents how much the current latency has increased or decreased relative to the previous latency. For example, if the current latency is 200 ms and the previous latency is 100 ms, then the ratio is (200/100-l) = 1, which means the current latency is 100% higher than the previous latency To express the rate of change as a percentage, you need to multiply the ratio by 100. You can do this by adding a scale: 100 function to the formula. This function scales the values of the plot by a factor of 100. For example, if the ratio is 1, then the scaled value is 100%2 To create a plot C using the formula (A/B-l) and add a scale: 100 function, you need to follow these steps: Select plot A and plot B from the Metric Finder. Click on Add Analytics and choose Formula from the list of functions. In the Formula window, enter (A/B-l) as the formula and click Apply. Click on Add Analytics again and choose Scale from the list of functions. In the Scale window, enter 100 as the factor and click Apply. You should see a new plot C that shows the rate of change in latency as a percentage. To learn more about how to use formulas and scale functions in Splunk Observability Cloud, you can refer to these documentations. https://www.mathsisfun.com/numbers/percentage-change.html https://docs.splunk.com/Observability/gdi/metrics/analytics.html#Scale https://docs.splunk.com/Observability/gdi/metrics/analytics.html#Formula https://docs.splunk.com/Observability/gdi/metrics/analytics.html#Scale
Question 7:
What is one reason a user of Splunk Observability Cloud would want to subscribe to an alert?
A. To determine the root cause of the Issue triggering the detector.
B. To perform transformations on the data used by the detector.
C. To receive an email notification when a detector is triggered.
D. To be able to modify the alert parameters.
Correct Answer: C
One reason a user of Splunk Observability Cloud would want to subscribe to an alert is C. To receive an email notification when a detector is triggered. A detector is a component of Splunk Observability Cloud that monitors metrics or events and triggers alerts when certain conditions are met. A user can create and configure detectors to suit their monitoring needs and goals A subscription is a way for a user to receive notifications when a detector triggers an alert. A user can subscribe to a detector by entering their email address in the Subscription tab of the detector page. A user can also unsubscribe from a detector at any time When a user subscribes to an alert, they will receive an email notification that contains information about the alert, such as the detector name, the alert status, the alert severity, the alert time, and the alert message. The email notification also includes links to view the detector, acknowledge the alert, or unsubscribe from the detector To learn more about how to use detectors and subscriptions in Splunk Observability Cloud, you can refer to these documentations. https://docs.splunk.com/Observability/alerts-detectors-notifications/detectors.html https://docs.splunk.com/Observability/alerts-detectors-notifications/subscribe-to-detectors.html
Question 8:
What information is needed to create a detector?
A. Alert Status, Alert Criteria, Alert Settings, Alert Message, Alert Recipients
B. Alert Signal, Alert Criteria, Alert Settings, Alert Message, Alert Recipients
C. Alert Signal, Alert Condition, Alert Settings, Alert Message, Alert Recipients
D. Alert Status, Alert Condition, Alert Settings, Alert Meaning, Alert Recipients
Correct Answer: C
According to the Splunk Observability Cloud documentation1, to create a detector, you need the following information:
Alert Signal: This is the metric or dimension that you want to monitor and alert on. You can select a signal from a chart or a dashboard, or enter a SignalFlow query to define the signal.
Alert Condition: This is the criteria that determines when an alert is triggered or cleared. You can choose from various built-in alert conditions, such as static threshold, dynamic threshold, outlier, missing data, and so on. You can also specify
the severity level and the trigger sensitivity for each alert condition. Alert Settings: This is the configuration that determines how the detector behaves and interacts with other detectors. You can set the detector name, description, resolution,
run lag, max delay, and detector rules. You can also enable or disable the detector, and mute or unmute the alerts.
Alert Message: This is the text that appears in the alert notification and event feed. You can customize the alert message with variables, such as signal name, value, condition, severity, and so on. You can also use markdown formatting to
enhance the message appearance.
Alert Recipients: This is the list of destinations where you want to send the alert notifications. You can choose from various channels, such as email, Slack, PagerDuty, webhook, and so on. You can also specify the notification frequency and
suppression settings.
Question 9:
A customer is experiencing issues getting metrics from a new receiver they have configured in the OpenTelemetry Collector. How would the customer go about troubleshooting further with the logging exporter?
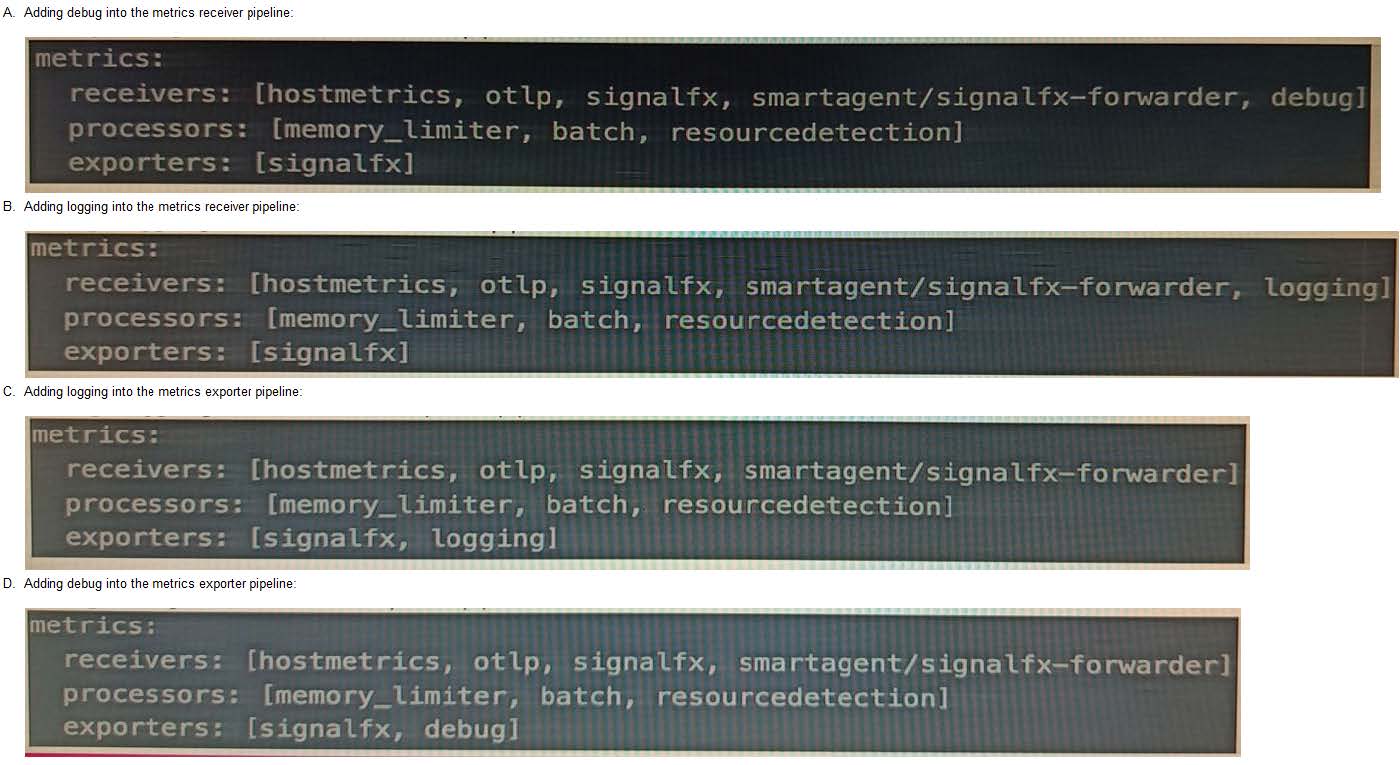
A. Option A
B. Option B
C. Option C
D. Option D
Correct Answer: B
The correct answer is B. Adding logging into the metrics receiver pipeline. The logging exporter is a component that allows the OpenTelemetry Collector to send traces, metrics, and logs directly to the console. It can be used to diagnose and troubleshoot issues with telemetry received and processed by the Collector, or to obtain samples for other purposes To activate the logging exporter, you need to add it to the pipeline that you want to diagnose. In this case, since you are experiencing issues with a new receiver for metrics, you need to add the logging exporter to the metrics receiver pipeline. This will create a new plot that shows the metrics received by the Collector and any errors or warnings that might occur The image that you have sent with your question shows how to add the logging exporter to the metrics receiver pipeline. You can see that the exporters section of the metrics pipeline includes logging as one of the options. This means that the metrics received by any of the receivers listed in the receivers section will be sent to the logging exporter as well as to any other exporters listed To learn more about how to use the logging exporter in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/opentelemetry/components/logging- exporter.html https://docs.splunk.com/Observability/gdi/opentelemetry/exposed- endpoints.html
Question 10:
To smooth a very spiky cpu.utilization metric, what is the correct analytic function to better see if the cpu. utilization for servers is trending up over time?
A. Rate/Sec
B. Median
C. Mean (by host)
D. Mean (Transformation)
Correct Answer: D
The correct answer is D. Mean (Transformation).
According to the web search results, a mean transformation is an analytic function that returns the average value of a metric or a dimension over a specified time interval. A mean transformation can be used to smooth a very spiky metric, such as cpu.utilization, by reducing the impact of outliers and noise. A mean transformation can also help to see if the metric is trending up or down over time, by showing the general direction of the average value. For example, to smooth the cpu.utilization metric and see if it is trending up over time, you can use the following SignalFlow code: mean(1h, counters("cpu.utilization")) This will return the average value of the cpu.utilization counter metric for each metric time series (MTS) over the last hour. You can then use a chart to visualize the results and compare the mean values across different MTS. Option A is incorrect because rate/sec is not an analytic function, but rather a rollup function that returns the rate of change of data points in the MTS reporting interval1. Rate/sec can be used to convert cumulative counter metrics into counter metrics, but it does not smooth or trend a metric. Option B is incorrect because median is not an analytic function, but rather an aggregation function that returns the middle value of a metric or a dimension over the entire time range1. Median can be used to find the typical value of a metric, but it does not smooth or trend a metric. Option C is incorrect because mean (by host) is not an analytic function, but rather an aggregation function that returns the average value of a metric or a dimension across all MTS with the same host dimension1. Mean (by host) can be used to compare the performance of different hosts, but it does not smooth or trend a metric. Mean (Transformation) is an analytic function that allows you to smooth a very spiky metric by applying a moving average over a specified time window. This can help you see the general trend of the metric over time, without being distracted by the short-term fluctuations To use Mean (Transformation) on a cpu.utilization metric, you need to select the metric from the Metric Finder, then click on Add Analytics and choose Mean (Transformation) from the list of functions. You can then specify the time window for the moving average, such as 5 minutes, 15 minutes, or 1 hour. You can also group the metric by host or any other dimension to compare the smoothed values across different servers2 To learn more about how to use Mean (Transformation) and other analytic functions in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/metrics/analytics.html#Mean-Transformation https://docs.splunk.com/Observability/gdi/metrics/analytics.html
Question 11:
A customer operates a caching web proxy. They want to calculate the cache hit rate for their service. What is the best way to achieve this?
A. Percentages and ratios
B. Timeshift and Bottom N
C. Timeshift and Top N
D. Chart Options and metadata
Correct Answer: A
According to the Splunk O11y Cloud Certified Metrics User Track document, percentages and ratios are useful for calculating the proportion of one metric to another, such as cache hits to cache misses, or successful requests to failed
requests. You can use the percentage() or ratio() functions in SignalFlow to compute these values and display them in charts. For example, to calculate the cache hit rate for a service, you can use the following SignalFlow code:
percentage(counters("cache.hits"), counters("cache.misses")) This will return the percentage of cache hits out of the total number of cache attempts. You can also use the ratio() function to get the same result, but as a decimal value instead
of a percentage.
ratio(counters("cache.hits"), counters("cache.misses"))
Question 12:
Where does the Splunk distribution of the OpenTelemetry Collector store the configuration files on Linux machines by default?
A. /opt/splunk/
B. /etc/otel/collector/
C. /etc/opentelemetry/
D. /etc/system/default/
Correct Answer: B
The correct answer is B. /etc/otel/collector/ According to the web search results, the Splunk distribution of the OpenTelemetry Collector stores the configuration files on Linux machines in the /etc/otel/collector/ directory by default. You can verify this by looking at the first result, which explains how to install the Collector for Linux manually. It also provides the locations of the default configuration file, the agent configuration file, and the gateway configuration file. To learn more about how to install and configure the Splunk distribution of the OpenTelemetry Collector, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/opentelemetry/install-linux-manual.html https://docs.splunk.com/Observability/gdi/opentelemetry.html
Question 13:
The built-in Kubernetes Navigator includes which of the following?
A. Map, Nodes, Workloads, Node Detail, Workload Detail, Group Detail, Container Detail
B. Map, Nodes, Processors, Node Detail, Workload Detail, Pod Detail, Container Detail
C. Map, Clusters, Workloads, Node Detail, Workload Detail, Pod Detail, Container Detail
D. Map, Nodes, Workloads, Node Detail, Workload Detail, Pod Detail, Container Detail
Correct Answer: D
The correct answer is D. Map, Nodes, Workloads, Node Detail, Workload Detail, Pod Detail, Container Detail. The built-in Kubernetes Navigator is a feature of Splunk Observability Cloud that provides a comprehensive and intuitive way to monitor the performance and health of Kubernetes environments. It includes the following views: Map: A graphical representation of the Kubernetes cluster topology, showing the relationships and dependencies among nodes, pods, containers, and services. You can use the map to quickly identify and troubleshoot issues in your cluster Nodes: A tabular view of all the nodes in your cluster, showing key metrics such as CPU utilization, memory usage, disk usage, and network traffic. You can use the nodes view to compare and analyze the performance of different nodes1 Workloads: A tabular view of all the workloads in your cluster, showing key metrics such as CPU utilization, memory usage, network traffic, and error rate. You can use the workloads view to compare and analyze the performance of different workloads, such as deployments, stateful sets, daemon sets, or jobs1 Node Detail: A detailed view of a specific node in your cluster, showing key metrics and charts for CPU utilization, memory usage, disk usage, network traffic, and pod count. You can also see the list of pods running on the node and their status. You can use the node detail view to drill down into the performance of a single node Workload Detail: A detailed view of a specific workload in your cluster, showing key metrics and charts for CPU utilization, memory usage, network traffic, error rate, and pod count. You can also see the list of pods belonging to the workload and their status. You can use the workload detail view to drill down into the performance of a single workload Pod Detail: A detailed view of a specific pod in your cluster, showing key metrics and charts for CPU utilization, memory usage, network traffic, error rate, and container count. You can also see the list of containers within the pod and their status. You can use the pod detail view to drill down into the performance of a single pod Container Detail: A detailed view of a specific container in your cluster, showing key metrics and charts for CPU utilization, memory usage, network traffic, error rate, and log events. You can use the container detail view to drill down into the performance of a single container To learn more about how to use Kubernetes Navigator in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/observability/infrastructure/monitor/k8s-nav.html#Kubernetes- Navigator: https://docs.splunk.com/observability/infrastructure/monitor/k8s- nav.html#Detail-pages https://docs.splunk.com/observability/infrastructure/monitor/k8s- nav.html
Question 14:
A user wants to add a link to an existing dashboard from an alert. When they click the dimension value in the alert message, they are taken to the dashboard keeping the context. How can this be accomplished? (select all that apply)
A. Build a global data link.
B. Add a link to the Runbook URL.
C. Add a link to the field.
D. Add the link to the alert message body.
Correct Answer: AC
The possible ways to add a link to an existing dashboard from an alert are: Build a global data link. A global data link is a feature that allows you to create a link from any dimension value in any chart or table to a dashboard of your choice. You can specify the source and target dashboards, the dimension name and value, and the query parameters to pass along. When you click on the dimension value in the alert message, you will be taken to the dashboard with the context preserved Add a link to the field. A field link is a feature that allows you to create a link from any field value in any search result or alert message to a dashboard of your choice. You can specify the field name and value, the dashboard name and ID, and the query parameters to pass along. When you click on the field value in the alert message, you will be taken to the dashboard with the context preserved Therefore, the correct answer is A and C. To learn more about how to use global data links and field links in Splunk Observability Cloud, you can refer to these documentations. https://docs.splunk.com/Observability/gdi/metrics/charts.html#Global-data-links https://docs.splunk.com/Observability/gdi/metrics/search.html#Field-links
Question 15:
An SRE creates a new detector to receive an alert when server latency is higher than 260 milliseconds. Latency below 260 milliseconds is healthy for their service. The SRE creates a New Detector with a Custom Metrics Alert Rule for latency and sets a Static Threshold alert condition at 260ms.
How can the number of alerts be reduced?
A. Adjust the threshold.
B. Adjust the Trigger sensitivity. Duration set to 1 minute.
C. Adjust the notification sensitivity. Duration set to 1 minute.
D. Choose another signal.
Correct Answer: B
According to the Splunk O11y Cloud Certified Metrics User Track document1, trigger sensitivity is a setting that determines how long a signal must remain above or below a threshold before an alert is triggered. By default, trigger sensitivity is set to Immediate, which means that an alert is triggered as soon as the signal crosses the threshold. This can result in a lot of alerts, especially if the signal fluctuates frequently around the threshold value. To reduce the number of alerts, you can adjust the trigger sensitivity to a longer duration, such as 1 minute, 5 minutes, or 15 minutes. This means that an alert is only triggered if the signal stays above or below the threshold for the specified duration. This can help filter out noise and focus on more persistent issues.
geekcert.com provides more latest Splunk O11y Cloud Certified Metrics User (splk-4001) practice materials
Finally, I wish everyone good luck!
Splunk O11y Cloud Certified Metrics User (Splk-4001 dumps exam questions)
This is a very valuable Splunk O11y Cloud Certified Metrics User (splk-4001) practice material. Students who want to work in splunk can save this valuable material. It can make you progress and even enhance your promotion success. Rate.
As a teacher engaged in education in the IT field, I have mastered a lot of materials from various IT manufacturers. Today I will only share the latest materials for splunk certification. In the future, I will share a valuable learning material every day to help you achieve your goals. Of course, you also You can browse the IT material website I run: geekcert.com. All materials are included here.
Splunk O11y Cloud Certified Metrics User (Splk-4001) exam questions and answers
Question 1:
For which types of charts can individual plot visualization be set?
A. Line, Bar, Column
B. Bar, Area, Column
C. Line, Area, Column
D. Histogram, Line, Column
Correct Answer: C
The correct answer is C. Line, Area, Column. For line, area, and column charts, you can set the individual plot visualization to change the appearance of each plot in the chart. For example, you can change the color, shape, size, or style of the lines, areas, or columns. You can also change the rollup function, data resolution, or y-axis scale for each plot To set the individual plot visualization for line, area, and column charts, you need to select the chart from the Metric Finder, then click on Plot Chart Options and choose Individual Plot Visualization from the list of options. You can then customize each plot according to your preferences To learn more about how to use individual plot visualization in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/metrics/charts.html#Individual-plot-visualization https://docs.splunk.com/Observability/gdi/metrics/charts.html#Set-individual-plot- visualization
Question 2:
Which of the following is optional, but highly recommended to include in a datapoint?
A. Metric name
B. Timestamp
C. Value
D. Metric type
Correct Answer: D
The correct answer is D. Metric type. A metric type is an optional, but highly recommended field that specifies the kind of measurement that a datapoint represents. For example, a metric type can be gauge, counter, cumulative counter, or histogram. A metric type helps Splunk Observability Cloud to interpret and display the data correctly To learn more about how to send metrics to Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/metrics/metrics.html#Metric-types https://docs.splunk.com/Observability/gdi/metrics/metrics.html
Question 3:
A customer deals with a holiday rush of traffic during November each year, but does not want to be flooded with alerts when this happens. The increase in traffic is expected and consistent each year. Which detector condition should be used when creating a detector for this data?
A. Outlier Detection
B. Static Threshold
C. Calendar Window
D. Historical Anomaly
Correct Answer: D
historical anomaly is a detector condition that allows you to trigger an alert when a signal deviates from its historical pattern. Historical anomaly uses machine learning to learn the normal behavior of a signal based on its past data, and then compares the current value of the signal with the expected value based on the learned pattern. You can use historical anomaly to detect unusual changes in a signal that are not explained by seasonality, trends, or cycles. Historical anomaly is suitable for creating a detector for the customer\'s data, because it can account for the expected and consistent increase in traffic during November each year. Historical anomaly can learn that the traffic pattern has a seasonal component that peaks in November, and then adjust the expected value of the traffic accordingly. This way, historical anomaly can avoid triggering alerts when the traffic increases in November, as this is not an anomaly, but rather a normal variation. However, historical anomaly can still trigger alerts when the traffic deviates from the historical pattern in other ways, such as if it drops significantly or spikes unexpectedly.
Question 4:
Changes to which type of metadata result in a new metric time series?
A. Dimensions
B. Properties
C. Sources
D. Tags
Correct Answer: A
The correct answer is A. Dimensions. Dimensions are metadata in the form of key-value pairs that are sent along with the metrics at the time of ingest. They provide additional information about the metric, such as the name of the host that sent the metric, or the location of the server. Along with the metric name, they uniquely identify a metric time series (MTS)1 Changes to dimensions result in a new MTS, because they create a different combination of metric name and dimensions. For example, if you change the hostname dimension from host1 to host, you will create a new MTS for the same metric name1 Properties, sources, and tags are other types of metadata that can be applied to existing MTSes after ingest. They do not contribute to uniquely identify an MTS, and they do not create a new MTS when changed To learn more about how to use metadata in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/metrics-and-metadata/metrics.html#Dimensions https://docs.splunk.com/Observability/metrics-and-metadata/metrics-dimensions-mts.html
Question 5:
The Sum Aggregation option for analytic functions does which of the following?
A. Calculates the number of MTS present in the plot.
B. Calculates 1/2 of the values present in the input time series.
C. Calculates the sum of values present in the input time series across the entire environment or per group.
D. Calculates the sum of values per time series across a period of time.
Correct Answer: C
According to the Splunk Test Blueprint - O11y Cloud Metrics User document1, one of the metrics concepts that is covered in the exam is analytic functions. Analytic functions are mathematical operations that can be applied to metrics to transform, aggregate, or analyze them. The Splunk O11y Cloud Certified Metrics User Track document2 states that one of the recommended courses for preparing for the exam is Introduction to Splunk Infrastructure Monitoring, which covers the basics of metrics monitoring and visualization. In the Introduction to Splunk Infrastructure Monitoring course, there is a section on Analytic Functions, which explains that analytic functions can be used to perform calculations on metrics, such as sum, average, min, max, count, etc. The document also provides examples of how to use analytic functions in charts and dashboards. One of the analytic functions that can be used is Sum Aggregation, which calculates the sum of values present in the input time series across the entire environment or per group. The document gives an example of how to use Sum Aggregation to calculate the total CPU usage across all hosts in a group by using the following syntax: sum(cpu.utilization) by hostgroup
Question 6:
A DevOps engineer wants to determine if the latency their application experiences is growing fester after a new software release a week ago. They have already created two plot lines, A and B, that represent the current latency and the latency a week ago, respectively. How can the engineer use these two plot lines to determine the rate of change in latency?
A. Create a temporary plot by dragging items A and B into the Analytics Explorer window.
B. Create a plot C using the formula (A-B) and add a scale:percent function to express the rate of change as a percentage.
C. Create a plot C using the formula (A/B-l) and add a scale: 100 function to express the rate of change as a percentage.
D. Create a temporary plot by clicking the Change% button in the upper-right corner of the plot showing lines A and B.
Correct Answer: C
The correct answer is C. Create a plot C using the formula (A/B-l) and add a scale: 100 function to express the rate of change as a percentage. To calculate the rate of change in latency, you need to compare the current latency (plot A) with the latency a week ago (plot B). One way to do this is to use the formula (A/B-l), which gives you the ratio of the current latency to the previous latency minus one. This ratio represents how much the current latency has increased or decreased relative to the previous latency. For example, if the current latency is 200 ms and the previous latency is 100 ms, then the ratio is (200/100-l) = 1, which means the current latency is 100% higher than the previous latency To express the rate of change as a percentage, you need to multiply the ratio by 100. You can do this by adding a scale: 100 function to the formula. This function scales the values of the plot by a factor of 100. For example, if the ratio is 1, then the scaled value is 100%2 To create a plot C using the formula (A/B-l) and add a scale: 100 function, you need to follow these steps: Select plot A and plot B from the Metric Finder. Click on Add Analytics and choose Formula from the list of functions. In the Formula window, enter (A/B-l) as the formula and click Apply. Click on Add Analytics again and choose Scale from the list of functions. In the Scale window, enter 100 as the factor and click Apply. You should see a new plot C that shows the rate of change in latency as a percentage. To learn more about how to use formulas and scale functions in Splunk Observability Cloud, you can refer to these documentations. https://www.mathsisfun.com/numbers/percentage-change.html https://docs.splunk.com/Observability/gdi/metrics/analytics.html#Scale https://docs.splunk.com/Observability/gdi/metrics/analytics.html#Formula https://docs.splunk.com/Observability/gdi/metrics/analytics.html#Scale
Question 7:
What is one reason a user of Splunk Observability Cloud would want to subscribe to an alert?
A. To determine the root cause of the Issue triggering the detector.
B. To perform transformations on the data used by the detector.
C. To receive an email notification when a detector is triggered.
D. To be able to modify the alert parameters.
Correct Answer: C
One reason a user of Splunk Observability Cloud would want to subscribe to an alert is C. To receive an email notification when a detector is triggered. A detector is a component of Splunk Observability Cloud that monitors metrics or events and triggers alerts when certain conditions are met. A user can create and configure detectors to suit their monitoring needs and goals A subscription is a way for a user to receive notifications when a detector triggers an alert. A user can subscribe to a detector by entering their email address in the Subscription tab of the detector page. A user can also unsubscribe from a detector at any time When a user subscribes to an alert, they will receive an email notification that contains information about the alert, such as the detector name, the alert status, the alert severity, the alert time, and the alert message. The email notification also includes links to view the detector, acknowledge the alert, or unsubscribe from the detector To learn more about how to use detectors and subscriptions in Splunk Observability Cloud, you can refer to these documentations. https://docs.splunk.com/Observability/alerts-detectors-notifications/detectors.html https://docs.splunk.com/Observability/alerts-detectors-notifications/subscribe-to-detectors.html
Question 8:
What information is needed to create a detector?
A. Alert Status, Alert Criteria, Alert Settings, Alert Message, Alert Recipients
B. Alert Signal, Alert Criteria, Alert Settings, Alert Message, Alert Recipients
C. Alert Signal, Alert Condition, Alert Settings, Alert Message, Alert Recipients
D. Alert Status, Alert Condition, Alert Settings, Alert Meaning, Alert Recipients
Correct Answer: C
According to the Splunk Observability Cloud documentation1, to create a detector, you need the following information:
Alert Signal: This is the metric or dimension that you want to monitor and alert on. You can select a signal from a chart or a dashboard, or enter a SignalFlow query to define the signal.
Alert Condition: This is the criteria that determines when an alert is triggered or cleared. You can choose from various built-in alert conditions, such as static threshold, dynamic threshold, outlier, missing data, and so on. You can also specify
the severity level and the trigger sensitivity for each alert condition. Alert Settings: This is the configuration that determines how the detector behaves and interacts with other detectors. You can set the detector name, description, resolution,
run lag, max delay, and detector rules. You can also enable or disable the detector, and mute or unmute the alerts.
Alert Message: This is the text that appears in the alert notification and event feed. You can customize the alert message with variables, such as signal name, value, condition, severity, and so on. You can also use markdown formatting to
enhance the message appearance.
Alert Recipients: This is the list of destinations where you want to send the alert notifications. You can choose from various channels, such as email, Slack, PagerDuty, webhook, and so on. You can also specify the notification frequency and
suppression settings.
Question 9:
A customer is experiencing issues getting metrics from a new receiver they have configured in the OpenTelemetry Collector. How would the customer go about troubleshooting further with the logging exporter?
A. Option A
B. Option B
C. Option C
D. Option D
Correct Answer: B
The correct answer is B. Adding logging into the metrics receiver pipeline. The logging exporter is a component that allows the OpenTelemetry Collector to send traces, metrics, and logs directly to the console. It can be used to diagnose and troubleshoot issues with telemetry received and processed by the Collector, or to obtain samples for other purposes To activate the logging exporter, you need to add it to the pipeline that you want to diagnose. In this case, since you are experiencing issues with a new receiver for metrics, you need to add the logging exporter to the metrics receiver pipeline. This will create a new plot that shows the metrics received by the Collector and any errors or warnings that might occur The image that you have sent with your question shows how to add the logging exporter to the metrics receiver pipeline. You can see that the exporters section of the metrics pipeline includes logging as one of the options. This means that the metrics received by any of the receivers listed in the receivers section will be sent to the logging exporter as well as to any other exporters listed To learn more about how to use the logging exporter in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/opentelemetry/components/logging- exporter.html https://docs.splunk.com/Observability/gdi/opentelemetry/exposed- endpoints.html
Question 10:
To smooth a very spiky cpu.utilization metric, what is the correct analytic function to better see if the cpu. utilization for servers is trending up over time?
A. Rate/Sec
B. Median
C. Mean (by host)
D. Mean (Transformation)
Correct Answer: D
The correct answer is D. Mean (Transformation).
According to the web search results, a mean transformation is an analytic function that returns the average value of a metric or a dimension over a specified time interval. A mean transformation can be used to smooth a very spiky metric, such as cpu.utilization, by reducing the impact of outliers and noise. A mean transformation can also help to see if the metric is trending up or down over time, by showing the general direction of the average value. For example, to smooth the cpu.utilization metric and see if it is trending up over time, you can use the following SignalFlow code: mean(1h, counters("cpu.utilization")) This will return the average value of the cpu.utilization counter metric for each metric time series (MTS) over the last hour. You can then use a chart to visualize the results and compare the mean values across different MTS. Option A is incorrect because rate/sec is not an analytic function, but rather a rollup function that returns the rate of change of data points in the MTS reporting interval1. Rate/sec can be used to convert cumulative counter metrics into counter metrics, but it does not smooth or trend a metric. Option B is incorrect because median is not an analytic function, but rather an aggregation function that returns the middle value of a metric or a dimension over the entire time range1. Median can be used to find the typical value of a metric, but it does not smooth or trend a metric. Option C is incorrect because mean (by host) is not an analytic function, but rather an aggregation function that returns the average value of a metric or a dimension across all MTS with the same host dimension1. Mean (by host) can be used to compare the performance of different hosts, but it does not smooth or trend a metric. Mean (Transformation) is an analytic function that allows you to smooth a very spiky metric by applying a moving average over a specified time window. This can help you see the general trend of the metric over time, without being distracted by the short-term fluctuations To use Mean (Transformation) on a cpu.utilization metric, you need to select the metric from the Metric Finder, then click on Add Analytics and choose Mean (Transformation) from the list of functions. You can then specify the time window for the moving average, such as 5 minutes, 15 minutes, or 1 hour. You can also group the metric by host or any other dimension to compare the smoothed values across different servers2 To learn more about how to use Mean (Transformation) and other analytic functions in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/metrics/analytics.html#Mean-Transformation https://docs.splunk.com/Observability/gdi/metrics/analytics.html
Question 11:
A customer operates a caching web proxy. They want to calculate the cache hit rate for their service. What is the best way to achieve this?
A. Percentages and ratios
B. Timeshift and Bottom N
C. Timeshift and Top N
D. Chart Options and metadata
Correct Answer: A
According to the Splunk O11y Cloud Certified Metrics User Track document, percentages and ratios are useful for calculating the proportion of one metric to another, such as cache hits to cache misses, or successful requests to failed
requests. You can use the percentage() or ratio() functions in SignalFlow to compute these values and display them in charts. For example, to calculate the cache hit rate for a service, you can use the following SignalFlow code:
percentage(counters("cache.hits"), counters("cache.misses")) This will return the percentage of cache hits out of the total number of cache attempts. You can also use the ratio() function to get the same result, but as a decimal value instead
of a percentage.
ratio(counters("cache.hits"), counters("cache.misses"))
Question 12:
Where does the Splunk distribution of the OpenTelemetry Collector store the configuration files on Linux machines by default?
A. /opt/splunk/
B. /etc/otel/collector/
C. /etc/opentelemetry/
D. /etc/system/default/
Correct Answer: B
The correct answer is B. /etc/otel/collector/ According to the web search results, the Splunk distribution of the OpenTelemetry Collector stores the configuration files on Linux machines in the /etc/otel/collector/ directory by default. You can verify this by looking at the first result, which explains how to install the Collector for Linux manually. It also provides the locations of the default configuration file, the agent configuration file, and the gateway configuration file. To learn more about how to install and configure the Splunk distribution of the OpenTelemetry Collector, you can refer to this documentation. https://docs.splunk.com/Observability/gdi/opentelemetry/install-linux-manual.html https://docs.splunk.com/Observability/gdi/opentelemetry.html
Question 13:
The built-in Kubernetes Navigator includes which of the following?
A. Map, Nodes, Workloads, Node Detail, Workload Detail, Group Detail, Container Detail
B. Map, Nodes, Processors, Node Detail, Workload Detail, Pod Detail, Container Detail
C. Map, Clusters, Workloads, Node Detail, Workload Detail, Pod Detail, Container Detail
D. Map, Nodes, Workloads, Node Detail, Workload Detail, Pod Detail, Container Detail
Correct Answer: D
The correct answer is D. Map, Nodes, Workloads, Node Detail, Workload Detail, Pod Detail, Container Detail. The built-in Kubernetes Navigator is a feature of Splunk Observability Cloud that provides a comprehensive and intuitive way to monitor the performance and health of Kubernetes environments. It includes the following views: Map: A graphical representation of the Kubernetes cluster topology, showing the relationships and dependencies among nodes, pods, containers, and services. You can use the map to quickly identify and troubleshoot issues in your cluster Nodes: A tabular view of all the nodes in your cluster, showing key metrics such as CPU utilization, memory usage, disk usage, and network traffic. You can use the nodes view to compare and analyze the performance of different nodes1 Workloads: A tabular view of all the workloads in your cluster, showing key metrics such as CPU utilization, memory usage, network traffic, and error rate. You can use the workloads view to compare and analyze the performance of different workloads, such as deployments, stateful sets, daemon sets, or jobs1 Node Detail: A detailed view of a specific node in your cluster, showing key metrics and charts for CPU utilization, memory usage, disk usage, network traffic, and pod count. You can also see the list of pods running on the node and their status. You can use the node detail view to drill down into the performance of a single node Workload Detail: A detailed view of a specific workload in your cluster, showing key metrics and charts for CPU utilization, memory usage, network traffic, error rate, and pod count. You can also see the list of pods belonging to the workload and their status. You can use the workload detail view to drill down into the performance of a single workload Pod Detail: A detailed view of a specific pod in your cluster, showing key metrics and charts for CPU utilization, memory usage, network traffic, error rate, and container count. You can also see the list of containers within the pod and their status. You can use the pod detail view to drill down into the performance of a single pod Container Detail: A detailed view of a specific container in your cluster, showing key metrics and charts for CPU utilization, memory usage, network traffic, error rate, and log events. You can use the container detail view to drill down into the performance of a single container To learn more about how to use Kubernetes Navigator in Splunk Observability Cloud, you can refer to this documentation. https://docs.splunk.com/observability/infrastructure/monitor/k8s-nav.html#Kubernetes- Navigator: https://docs.splunk.com/observability/infrastructure/monitor/k8s- nav.html#Detail-pages https://docs.splunk.com/observability/infrastructure/monitor/k8s- nav.html
Question 14:
A user wants to add a link to an existing dashboard from an alert. When they click the dimension value in the alert message, they are taken to the dashboard keeping the context. How can this be accomplished? (select all that apply)
A. Build a global data link.
B. Add a link to the Runbook URL.
C. Add a link to the field.
D. Add the link to the alert message body.
Correct Answer: AC
The possible ways to add a link to an existing dashboard from an alert are: Build a global data link. A global data link is a feature that allows you to create a link from any dimension value in any chart or table to a dashboard of your choice. You can specify the source and target dashboards, the dimension name and value, and the query parameters to pass along. When you click on the dimension value in the alert message, you will be taken to the dashboard with the context preserved Add a link to the field. A field link is a feature that allows you to create a link from any field value in any search result or alert message to a dashboard of your choice. You can specify the field name and value, the dashboard name and ID, and the query parameters to pass along. When you click on the field value in the alert message, you will be taken to the dashboard with the context preserved Therefore, the correct answer is A and C. To learn more about how to use global data links and field links in Splunk Observability Cloud, you can refer to these documentations. https://docs.splunk.com/Observability/gdi/metrics/charts.html#Global-data-links https://docs.splunk.com/Observability/gdi/metrics/search.html#Field-links
Question 15:
An SRE creates a new detector to receive an alert when server latency is higher than 260 milliseconds. Latency below 260 milliseconds is healthy for their service. The SRE creates a New Detector with a Custom Metrics Alert Rule for latency and sets a Static Threshold alert condition at 260ms.
How can the number of alerts be reduced?
A. Adjust the threshold.
B. Adjust the Trigger sensitivity. Duration set to 1 minute.
C. Adjust the notification sensitivity. Duration set to 1 minute.
D. Choose another signal.
Correct Answer: B
According to the Splunk O11y Cloud Certified Metrics User Track document1, trigger sensitivity is a setting that determines how long a signal must remain above or below a threshold before an alert is triggered. By default, trigger sensitivity is set to Immediate, which means that an alert is triggered as soon as the signal crosses the threshold. This can result in a lot of alerts, especially if the signal fluctuates frequently around the threshold value. To reduce the number of alerts, you can adjust the trigger sensitivity to a longer duration, such as 1 minute, 5 minutes, or 15 minutes. This means that an alert is only triggered if the signal stays above or below the threshold for the specified duration. This can help filter out noise and focus on more persistent issues.
geekcert.com provides more latest Splunk O11y Cloud Certified Metrics User (splk-4001) practice materials
Finally, I wish everyone good luck!