
GEOG 170 Final Review
Lecture 1 Introduction to Geospatial Technology
Geospatial Technology = tools used for location based data
Geographic Information System (GIS): a computer-based geospatial technology for storage, analysis, and management of location-based data.
Remote Sensing (RS): a technology that is used to acquire imagery of the earth's surface through the use of satellites or aircraft. The data collected by satellite devices are typically called satellite imagery, and data acquired by devices on aircraft are called aerial photos.
Global Positioning System (GPS): a technology that acquires real-time location information from a series of satellites in Earth’s orbit.
1.1 GIS
A GIS is both a database system with specific capabilities for managing geospatial data, as well as a set of operations for working with the data.
Could be a database of location based data and any other data (covid cases, jobs, etc)
The spatial component of this data allows the user to analyze the data both statistically and geographically, alone or in conjunction with other spatial information, and produce output in the form of maps.
1.2 Remote Sensing (RS)
Uses sensors to collect information about about area without contact
Data used for:
location of objects
physical makeup of objects
the health of vegetation
elevation of the objects
Can be incorporated into GIS softwares
1.3 Global Positioning System (GPS)
Using satellites, GPS provides locational information. Think phones and how they tell location to find nearby restaurants
Video:
Geographic Information Systems (GIS) and Mapping
GIS has revolutionized the way we perceive, interact with, and engage with the world around us.
Maps have evolved from ancient stick maps to modern digital maps and GIS-powered visualizations.
GIS enables the input of various data sources, such as maps and satellite imagery, to produce visualizations like maps, animations, and charts.
Mapping and Community Empowerment
Community-based participatory mapping programs, like those used in Borneo, have allowed marginalized communities to assert their land rights and plan for the future.
Native American communities are also using mapping to reclaim place names and traditional land use.
GIS Applications in the North State
Students have mapped the locations of wineries, vineyards, and olive oil producers to connect producers and consumers.
A map of community service organizations helps connect people in need with the appropriate resources.
Mapping stream conditions and trail systems supports conservation efforts and promotes healthy lifestyles.
Regional agencies use GIS to plan for transportation development and improve community livability.
The city of Redding is piloting a citizen-reporting application to improve service delivery.
The Democratization of Mapping
Maps are no longer solely controlled by those in power, but are a canvas for all to convey their priorities and sense of place.
Maps can be used to democratize, organize, advocate, design, and dream.
2. Who uses geospatial Technology?
Geospatial technology can be applied in many ways across a number of applications, including federal, state, and local government, forestry, law enforcement, public health, biology, environment, and transportation
2.1 Archeology
In archeology, we can use geospatial technology to pinpoint the location of artifacts uncovered on a dig, construct a map of the area, and then search for patterns on the site.
Archaeologists can also utilize historic maps, current aerial photographs or satellite imagery, and location information obtained on the site throughout the course of their work.
2.2 Environmental Monitoring
We can also use geospatial technology to monitor and analyze the processes that affect Earth’s environment. We can map and monitor land use changes, pollution, air quality, water quality, and global temperature levels, which are all important information for scientific research and for making smart decisions for the benefit of our environment.
2.3 Forestry
Geospatial technology is also very useful in forest monitoring, management, and protection. Modeling animal habitats and the pressures placed upon them, examining the spatial dimensions of forest fragmentation, and managing fires all acquire the assistance of geospatial technology.
2.4 Public health
Geospatial technology is used for a variety of health-related services. disease monitoring, tracking the source and spread of diseases, and mapping health-related issues are all tasks that can be completed using geospatial technology applications
2.5 Real Estate
Through geospatial technology, realtors and appraisers (as well as home buyers and sellers) can create and examine maps of houses and compare housing prices of nearby or similar properties. By examining high-resolution aerial images, one can also obtain other features of a property such as topography, terrain, transportation, and even whether it sits on a floodplain. You can also look at how a property is located in relation to schools, highways, waste-water treatment plants, and other urban features
Many types of decision making are reliant on geospatial information. When a new library is proposed to be built, the choice of location is important — the new site should maximize the number of people who can use it but minimize its impact on nearby sites. The same type of spatial thinking applies to the placement of new schools, fire stations, or fast-food restaurants. Spatial information fuels other decisions that are location dependent; for instance, historic preservation efforts seeking to defend historic Civil War battlefield areas from urban development.
4. Geospatial Technology for Everyone
You can examine satellite imagery or aerial photography of the entire globe, zoom from Earth orbit to a single street address, navigate through 3D cities or landscapes, measure global distances, and examine multiple layers of spatial data together, all with an intuitive interface. In many ways, the coolness and simplicity of use of Google Earth make it feel like a video game, but it’s far more than that. Google Earth is able to handle vast amounts of geospatial data swiftly and easily and enables users to specify and create their own location-based spatial data. It is used by scientists, GIS technicians, real estate managers, AND everyone else like YOU!
Lecture 2 Geographic Information and Representation
1. What is Geospatial Information?
1.1 What is information?
The scientific method to approach the outside world includes four processes: obtain direct observations, decode observations to data, convert data to information, and generate knowledge from all kinds of information
This process begins with observing, which could be human-sensed, manually recorded, or collected by devices (i.e., camera, satellites). Observations have no particular value by themselves. For example, the satellite signals we collected (Figure 2) are meaningless to us. Typically, we have to decode those signals and obtain the raw data, which becomes text or digital data stored in a file.
Raw data acquire value through relationships among objects and assumptions about those relationships. That is, you need context for the raw data. For example, the digit 120 do not mean much unless you know they measure temperature in degrees Fahrenheit (i.e., the context). Data become information when we can interpret them - either manually or with the help of tools, e.g. processing and displaying the data.
information can lead to higher levels of knowledge. if we put it in a geographic context, we can see a different picture altogether
if we put it in a geographic context, we can see a different picture altogether
1.2 What is Geographic Information?
Geographic information or geospatial information is information that has location (x,y) component as well as other associated attributes or characteristics.
Besides location, attributes are also critical for geographic information. In geography, attributes are spatially dependent variables. By spatially dependent we mean that the value of a variable may be similar to the values of its neighbors. For example, the price of a land parcel is highly related to the neighboring parcel.
Most of the time, geographic attributes are specific statistics tied to geographic location.
1.3 Geographic vs. Spatial Information
Although sometimes 'geographic' and 'spatial' are used interchangeably, geographic information is technically different than spatial information.
“Geographic” has to do with the Earth, its two-dimensional surface, or its three-dimensional atmosphere, oceans and sub-surface: An example of geographic data includes the depth of the frost line soil during the winter. The depth of the frost line is specifically in reference to the earth's surface. Another example of geographic data is the altitude of planes in the atmosphere. The height of the plane in the atmosphere is in relation to the earth's surface (sea level).
“Spatial” has to do with any multi-dimensional frame of reference: Medical images referenced to the human body; Engineering drawings referenced to a mechanical object; Architectural drawings referenced to a building
Therefore, 'geographic' is a subset of 'spatial'. All geographic (and spatial) information has an explicitly defined 'where"
2. How Do Maps Represent Geospatial Information?
2.1 What is a map?
A map is a spatial representation of geographic information presented graphically. It describes spatial relationships of specific features it aims to represent.
2.2 Information Drives Content and Design
Types of Maps:
Reference Maps: Depict locations
Thematic Maps: Depict spatially-referenced variables of interest
Navigational Maps: Depict paths and routes
Persuasive Maps: Present a graphical argument
2.2.1 Reference Maps
Emphasize the location of spatial phenomena
Summarize the landscape to aid discovery of locations
Geographic features are depicted as detailed and spatially accurate
Road maps, Google maps, Bing Map, mapquest.com, OpenStreetMap.org, USGS Topo maps
2.2.2 Thematic Maps
Depict information on a particular topic (also called "statistical map" or "single topic map")
Stress the geographical distribution of a particular topic
Typically less literal than reference maps
Weather, population density, and geology maps
2.2.3 Navigation Maps
Help navigators plan and follow travel routes
Include nautical and aeronautical charts
Nautical Charts: For water navigation
Aeronautical Charts: For air navigation (e.g., World Aeronautical Chart)
2.2.4 Persuasive Maps
Intended to convey an idea rather than communicate geographic information
Also called propaganda maps, often seen in public media
Advertising, political, and religious maps
Uses appealing images to persuade tourists
Less focus on geographic accuracy
2.3 Maps Can Be Difficult to Categorize
Some maps fall into multiple categories
Maps can be busy and convey a lot of information simultaneously
Importance of annotations and thematic content
Key Terms
Information: the interpretation of data with the aid of analysis or other tools
Geographic/geospatial information: information that has location (x,y) component as well as other associated attributes or characteristics
Map: a spatial representation of the geographic information that is presented graphically
Reference map: a type of map that emphasizes the location of spatial phenomena with purpose of summarizing the landscape to aid discovery of locations
Thematic map: a type of map specially designed to show a particular theme connected with a specific geographic area
Persuasive map: a type of map intended to convey an idea rather than communicate geographic information.
Lecture 3-1 Geodetics and Geomatics
1. Referencing Locations on the Earth's Surface
1.1 What are Geodetics and Geomatics?
Geodetics, also known as Geodesy, is the science of determining the actual size and shape of the earth. It covers the theories and technologies of measuring the precise location and motion of points on the earth's surface using various instruments, such as GPS, total stations, and theodolites.
Geomatics is a relatively new term applied to the practice formerly known as surveying. The name has gained widespread acceptance in the United States, Canada, the United Kingdom, and Austria. Geomatics encompasses the science, engineering, and art of gathering, analyzing, interpreting, distributing, and using geographic information. It involves a broad range of disciplines that work together to create a detailed and coherent picture of the physical world and our place in it. These disciplines include:
- Mapping and Surveying
- Geographic Information Systems (GIS)
- Global Positioning System (GPS)
- Remote Sensing
Therefore, geodetics can be viewed as part of geomatics.
1.2 Coordinate Systems
In geography, a coordinate system is "a reference system which uses one or more numbers, or coordinates, to determine and represent the locations of geographic features, imagery, and observations such as GPS locations within a common geographic reference framework." (ESRI)
Coordinate systems (either geographic or projected) provide a framework for defining real-world locations. There are two ways to pinpoint locations on maps:
Geographic Coordinate System (latitude, longitude)**: This system uses a three-dimensional spherical surface and measures of latitude and longitude to define locations on the Earth.
Projected Coordinate System (x, y)**: This system provides a mechanism to project maps of the Earth's spherical surface onto a two-dimensional Cartesian coordinate plane.
1.2.1 Geographic Coordinate System
A geographic coordinate system uses a three-dimensional spherical surface and measures of latitude and longitude to define locations on the Earth. It has been used for over 2,000 years as the worldwide location reference system. For example, Google Earth uses a geographic coordinate system by default (Figure 2).
Geographic coordinates (latitude and longitude) are measured in degrees, minutes, and seconds (DMS), or decimal degrees (DD), and represent angular distances calculated from the center of the Earth.
Degrees, minutes, and seconds (DMS): 65° 32' 15.275"
Decimal degrees (DD): 65.5375
Degrees and minutes (DM): 65° 32.25'
All these notations allow us to locate places on the Earth quite precisely. A degree of latitude is approximately 69 miles, a minute of latitude is approximately 1.15 miles, and a second of latitude is approximately 0.02 miles or just over 100 feet. The formula to convert DMS to DD is:
D + M/60 + S/3600
For example, given the DMS coordinate 45º56'18'', we can convert it to decimal degrees by the following method:
1. Let the integer number of degrees remain the same: 45
2. Divide the minutes by 60: 56/60 = 0.9333
3. Divide the seconds by 3600: 18/3600 = 0.005
4. Add the three together: 45 + 0.9333 + 0.005 = 45.9383°
1.2.2 Latitude
Latitude is the angular distance between the Equator and points to the north or south = up and down = east to west on the surface of the Earth A line connecting all points with the same latitude value is called a line of latitude. The Equator is an imaginary line that divides the Earth into Southern and Northern hemispheres, and it is equidistant from both poles, having a value of 0 degrees latitude
Latitude is expressed as degrees North (N) or South (S). There are 90 degrees of latitude going north from the Equator (the North Pole is at 90 degrees N) and 90 degrees to the south (the South Pole is at 90 degrees S). Northern latitudes are positive and southern latitudes are negative in GIS.
Called parallels
Example:
- Washington, DC’s latitude: 38°53'51.47" N or 38°53'51.47"
- Australia's Capital Hill latitude: 35°18’23.01" S or -35°18’23.01"
1.2.3 Longitude
Lines of longitude, called meridians, run perpendicular to lines of latitude and pass through both poles. The prime meridian is a meridian at which longitude is defined to be 0°. Unlike the equator, the prime meridian is arbitrary. By International Agreement signed in 1884, the meridian line through Greenwich, England, is given the value of 0 degrees of longitude, referred to as the Prime Meridian (Figure 5).
The Earth is divided into 360 degrees of longitude, ranging from 180 degrees West (W) to 180 degrees East (E) of the Prime Meridian. Longitudes can also be specified without directional designators (West and East) using positive and negative signs:
- East of the prime meridian: positive values up to 180 degrees
- West of the prime meridian: negative values up to 180 degrees
Example:
- Washington, DC’s longitude: 77º2'11.64" W or -77º2'11.64"
- Australia's Capitol Hill longitude: 149º07'32.83" E or 149º7'32.83"
The Prime Meridian and its opposite meridian at 180° longitude form a great circle dividing the Earth into Eastern and Western Hemispheres.
A degree is composed of 60 minutes, and a minute is composed of 60 seconds
Common Knowledge
- 15 degrees of longitude = 1 hour time difference
The Prime Meridian at Greenwich became the center of world time in 1884, forming the basis for national time-zone systems and international commerce.
1.2.4 Great Circles and Aviation
The shortest distance between two locations on a sphere, such as the Earth, is called a great circle. This path is formed by a plane slicing through the Earth through the two points and through the center of the Earth, resulting in a seemingly curved path on a map.
When making measurements on a sphere, the distance between two points is referred to as the great circle
2. Describing the Shape of the Earth
2.1 Ellipsoid/Spheroid
The actual shape of the Earth is complex, so we use a mathematical model to represent the Earth's surface. The Earth is a spheroid (not perfect sphere) slightly larger in radius at the equator than at the poles (Figure 10).
An ellipsoid (or spheroid) is like a sphere except that the major axis (equator) is larger than the minor axis (meridian passing through the North and South poles). However, the Earth is not a perfect ellipsoid. Different regions use different ellipsoids to model the curvature of Earth's surface accurately (Figure 11).
The earth is also lumpy, making it even harder to map
Different regions use a different ellipsoid to model the curvature of Earth's surface.
2.2 Geodetic Datums
A geodetic datum is a reference baseline for positions and mapping, representing the shape and size of the Earth. It is defined by specifying:
- The ellipsoid
- The coordinates of a base point
- The direction north
Datums can be horizontal or vertical:
Horizontal datums: measure a specific position on the Earth's surface using coordinate systems such as latitude and longitude. Examples include:
Vertical datums: measure elevations. A commonly used vertical datum is the geoid, which represents the mean sea level (MSL).
The geoid is a hypothetical Earth surface representing the MSL, considering variations in gravitational potential due to the Earth's mass distribution (Figure 13).
The word datum has multiple meanings:
Abstract coordinate system
A datum is a system that provides known locations for maps and surveys, and is used as a starting point for work such as construction surveys, property boundaries, and floodplain maps.
Horizontal datums measure positions (latitude and longitude) on the surface of the Earth, while vertical datums are used to measure land elevations and water depth
Lecture 3-2 Map Projections
1. What is a Map Projection?
Map projection: mathematical process of representing Earth's 3D curved surface on a 2D flat map.
Globes provide accurate Earth representation but are impractical for many uses.
Map projections make it possible to carry maps on paper or digital devices.
Locations on the spherical Earth are described using latitude and longitude.
On a flat map, locations are described using Cartesian coordinates (X & Y).
very projection distorts at least one aspect of the real world: shape, area, distance, or direction.
2. Are these good maps?
- Mercator Projection (Figure 2)
- Designed by Gerardus Mercator in 1569 for maritime navigation.
- Strengths and weaknesses:
- Eurocentric, places the northern hemisphere on top.
- Distorts polar regions, making Greenland appear larger than South America.
- Africa appears similar in size to Greenland, though it's 14 times larger.
- Common criticisms focus on size and placement distortions.
- McArthur’s Universal Corrective Map of the World (Figure 3)
- Created by Stuart McArthur, first published in 1979.
- South-up map, challenges the conventional north-up perspective.
- Highlights the arbitrary nature of map orientation.
- Peters Projection (Figure 4)
- Addresses size distortions of the Mercator projection.
- Preserves area but distorts shapes, especially in the tropics.
- Greenland and Alaska are shown in correct size relative to Mexico.
- Useful for comparing country sizes but not perfect in shape representation.
- General Criteria for a "Good" Map
- A good map serves its intended purpose accurately.
- McArthur’s map challenges perceptions of global orientation.
- Hundreds of projections exist, each distorting shape, area, distance, or direction.
- Projections preserve one or two properties or compromise between all.
- Scale and area size affect distortions.
- Tissot’s Indicatrix (Figure 5)
- Visualizes projection distortions using circles.
- Circles show distortions in area and shape when projected.
- Example map: shape and area preserved along the equator, distortion increases towards poles.
3. Categories of Map Projections
Least distorted at points of contact
- Projections by Surface
- Cylindrical
- Projects Earth onto a cylinder.
- Tangent or secant cases.
- Unwrapped to form a flat surface, least distortion along tangent or secant lines.
- cannot preserve both direction and shape
- Conical
- Projects Earth onto a cone.
- Tangent or secant cases.
- Least distortion along standard parallels.
- Planar (Azimuthal)
- Projects Earth onto a plane.
- Tangent or secant cases.
- Three classes based on focus: polar, equatorial, oblique.
- Shows accurate directions from the focus.
- Projections by Geometric Distortion
- Conformal
- Preserves shape (angles).
- Examples: Mercator, Lambert Conformal Conic.
- Equivalent (Equal-area)
- Preserves area.
- Examples: Peters projection, Sinusoidal projection.
- Equidistant
- Preserves distance from the center or along lines.
- Examples: Plate carrée, Azimuthal equidistant.
- Azimuthal (Zenithal)
- Directions from a central point to all other points
- Examples: Gnomonic, Lambert Azimuthal Equal-Area.
- Compromise
- Minimizes distortions in shape, area, distance, and direction.
- Examples: Robinson, Winkel Tripel.
4. What makes a projection good?
- Preservation of Earth's properties
- Area: Albers Equal Area.
- Shape: Lambert Conformal Conic.
- Direction: Lambert Azimuthal Equal Area.
- Distance: Specific lines.
Cannot perserve all 4
What should a good map do:
Meeting the map's purpose
- Choose a projection based on required spatial property accuracy.
- Conformal projections: important for angular relationships.
- Used in topographic maps, navigation charts, weather maps.
If your map requires that a particular spatial property be accurately represented, then a good projection must preserve that property. For example, use a conformal projection when the map's main purpose involves measuring angles, showing accurate local directions, or representing the shapes of features or contour lines. Conformal projections are typically used in:
- Equal-area projections: important for area representation.
- Used in population density maps, world political maps.
Minimizing distortion in the area of interest
- Tropical regions: cylindrical projection.
- Middle latitudes: conic projection.
- Polar regions: azimuthal projection.
Key Terms:
Map projection: a mathematical process of transforming a particular region of the earth's three-dimensional curved surface onto a two-dimensional map.
Tissot’s Indicatrix: circles used to visualize distortions due to a map projection. These circles are equal in area before projection, but distorted afterwards.
Projection surface: a simple geometric shape capable of being flattened without stretching, such as a cylinder, cone, or plane.
Cylindrical projection: a type of map projection that projects Earth onto a cylinder by touching the earth on one line or intersecting the earth through two lines
Conic projection: a type of map projection that projects Earth onto a cone that is either tangent to the Earth at a single parallel, or secant at two parallels.
Planar projection: a type of map projection that projects Earth's surface onto a flat plane by placing the plane at a point on the globe.
Conformal projection: a type of map projection where angles on the globe are preserved (thus preserving shape) on the map over small areas.
Equal-area/equivalent projection: a projection that preserves the relative size of Earth's regions.
Equidistant projection: a projection that preserves accurate distances from the center of the projection or along given lines.
Compromise projection: a projection that maintains a balance between distortions of shape, area, distance and direction, rather than perfectly preserving one geometric property at the expense of others.
Lecture 4-1 Coordinate Systems
1. Cartesian Coordinate System
Once map data are projected onto a two-dimensional surface (a plane), features must be referenced by a planar coordinate system instead of a geographic coordinate system. The geographic coordinate system (latitude-longitude), which is based on angles measured on a sphere, is not valid for measurements on a plane. Because degrees of latitude and longitude don't have a standard length, you can’t measure distances or areas accurately or display the data easily on a flat map or computer screen.
Therefore, a Cartesian coordinate system is used. A cartesian coordinate system is defined by a pair of orthogonal (x, y) axes drawn through an origin (Figure 1), where the origin (0, 0) is at the lower left of the planar section. Geographic calculations and analysis are done in Cartesian or Planar coordinates (x, y).
Compared to the geographic coordinate system, the biggest advantage of the Cartesian coordinate system is how it simplifies locating and measuring. Grid coordinate systems based on the Cartesian coordinate system are especially handy for map analysis procedures such as finding the distance or direction between locations or determining the area of a feature.
2. Universal Transverse Mercator (UTM) Coordinate System
2.1 UTM Basics
Universal Transverse Mercator (UTM) is the most commonly used global projected coordinate system. It is used by federal government agencies such as the USGS.
UTM uses a two-dimensional Cartesian coordinate system to give locations on the surface of the Earth. It extends around the world from 84oN to 80oS. The UTM system is not a single map projection. The system instead divides the Earth into 60 North-South zones covering the earth from East to West. Each zone has a central meridian and covers a six-degree band of longitude.
2.2 UTM Zone
UTM zones are numbered from 1 to 60 starting from 180° longitude at the International Date Line (Read more in Box 1) and proceeding eastward. Therefore, Zone 1 lies between the 180°W to 174°W longitude lines and is centered at 177°W; Zone 2 is between 174°W and 168°W longitude. Zone 60 covers longitude 174°E to 180°E (the International Date Line) (Figure 3). Each zone is also formatted with an "N" or "S" after the zone number, indicating whether the zone is in the North or South hemisphere. We will learn more about why this is done in the following sections.
The world is divided into 24 time zones, each of which is about 15 degrees of longitude wide, and each of which represents one hour of time (Figure B1.1). The numbers on the map indicate how many hours one must add to or subtract from the local time to get the time at the Greenwich meridian. For example, we can see that U.S. has four time zones, including East Day Time Zone in the east coast region, Central time zone in the central area, mountain time zone, and pacific time zone.
The International Date Line (IDL) is an imaginary line of longitude on the Earth’s surface located at about 180 degrees east (or west) of the Greenwich Meridian. The date line is shown as an uneven red vertical line in Figure B1.1: it marks the divide where the date changes by one day. It makes some deviations from the longitude 180-degree meridian to avoid dividing countries in two, especially in the Polynesia region. The time difference between either side of the International Date Line is not always exactly 24 hours because of local time zone variation.
2.3 UTM Eastings and Northings
Each zone has its own easting and northing values that cannot extend to other zones. Each zone has separate origins for the northern and southern hemispheres. To understand how these origins are specified, it is useful to understand a few terms and concepts.
2.3.1 Easting
In a UTM coordinate system, easting is the east-west x-coordinate, which is the distance from the origin. Easting varies from near zero to near 1,000,000 m. In both the northern and southern hemispheres, the center line (central meridian) of each zone has an easting value (x values) of 500,000 m to ensure that there are no negative values (Figure 5). This value, called false easting, is added to all x-coordinates so that there are no negative easting values in the zone. Since this 500,000m value is arbitrary. eastings are sometimes referred to as "false eastings".
2.3.2 Northing
Similarly, northing is the north-south y-coordinate in a projected coordinate system. In the northern hemisphere, a northing value of 0 m is assigned to the equator. Since no false northing value is added, a UTM northing value for a zone in the northern hemisphere is the number of meters north of the equator. In the southern hemisphere, false northing of 10,000,000 m is given to the equator so that all northing (y-axis) values are positive numbers.
Since the equator has different northing values for the northern and southern hemisphere, every location that lies exactly on the equator has two UTM coordinate pairs. For example, the coordinates for the intersection of the equator and the central meridian of UTM Zone 10 are written as follows:
500,000m E, 0m N (zone 10 North)
500,000m E, 10,000,000m S (zone 10 South)
Some examples of this concept:
A point south of equator with a northing of 7,587,834m N is 10,000,000 – 7,587,834 = 2,412,166m south of the equator.
A point 34m south of the equator has a northing of 9,999,966m N.
A point 34m north of the equator has a northing of 34m N.
The north-south distance between two points north of the equator with northings of 4,867,834m N and 4,812,382m N is 4,867,834 – 4,812,382 = 55452m. (Note: these calculations are only used to help you understand the difference between northing values in UTM northern and southern hemisphere. You will not need to calculate this for homework, quizzes, or exams.)
2.4 UTM coordinate formatting
UTM coordinates are simple to recognize because they usually have a six-digit integer as an easting value, followed by a seven digit integer as a northing value.
The first six-digit integer is the easting x-coordinate in meters
The second seven-digit integer is the northing y-coordinate in meters
The third value is the zone number and hemisphere
For example, the location of the State Capitol Dome in Madison, Wisconsin, in UTM is:
305,900m E, 4,771,650m N, Zone 16 North
2.5 UTM limitations
The near-global extent (UTM grid extends around the world from 84oN to 80oS) of the UTM grid makes it a valuable worldwide referencing system. The UTM grid is indicated on all recent USGS topographic maps. Most GPS vendors program the UTM into their receivers. However, UTM has limitations:
Suitable for medium-scale mapping but not national-level
Designed for areas with N-S extent, and thus not good for areas with a large E-W extent (good for areas that are taller than they are wide)
Distortions are relatively small, but still may be too large for specific purposes like high-accuracy surveying.
Distortions become especially problematic at high latitudes; this is part of why Canada, with giant swaths of Arctic territory, uses a Lambert Conformal Conic projection suited for mid- to high latitudes
UTM coordinates will differ when different datums are used
Zone boundaries follow meridians instead of political or natural boundaries. Thus, it usually takes more than one UTM zone to cover a state or country completely. For example, Wisconsin falls into Zones 15 and 16 (Figure 4).
3. State Plane Coordinate (SPC)
3.1 SPC Basics
The State Plane Coordinate (SPC) system was created in the 1930s by U.S. land surveyors as a way to define property boundaries in a way that would make them easier to measure. They are widely used by surveyors, engineers, planners, and state and local governments. They provide a common basis for assigning coordinate values to all areas of a State.
The idea was to completely cover the U.S. and its territories with grids laying over map projection surfaces so that the maximum scale distortion error would not exceed one part in 10,000. To support high-accuracy applications, each state is divided into one or more zones and all US states have adopted their own specialized state plane coordinate systems.
As a result, the United States was divided into 124 zones with each zone having its own projection. Most states have several zones, shown in Figure 7. Projections are chosen for different zones to minimize distortions. With few exceptions, all state plane zones are based on either the Lambert Conformal Conic Projection (Figure 7, in brown) or the Transverse Mercator Projection (Figure 7, in light grey) based on the Clarke 1866 ellipsoid and NAD 27 datum.
Lambert conformal conic projection is used for states of predominantly east-west extent. For example, Colorado is a Lambert state with three zones.
Transverse Mercator projection is used for states of predominately north-source extent, such as Arizona and New Mexico.
For states with more than one zone, the names North, South, East, West, and Central are used to identify zones. States without letters have only one grid zone, such as SC and NC. California is different from most states: it has seven zones all based on the Lambert Conformal Conic projection and its zones are numbered with Roman numerals.
3.2 SPC Origin
As mentioned earlier, UTM zone boundaries follow meridians instead of political or natural boundaries. However, here we can see that the SPC zone boundaries follow state and county boundaries. Each zone has its own central meridian that defines the vertical axis for the zone; this means that two different states have completely different reference systems. For example in Oregon, a northing of 5,000 meters does not tell us anything about how far we are from a point in Washington State.
An origin is established to the west and south of the zone, usually 2,000,000 feet west of the central meridian for Lambert conformal conic zones and 5,000,000 feet west of the central meridian for Transverse Mercator zones. Again, this is to prevent negative coordinate values. The central meridian has an easting value of 2,000,000 ft for Lambert conformal conic zones, and an easting value of 5,000,000 ft for Transverse Mercator zones. The origin for northings in each zone is a parallel just south of the counties in the zone, called the latitude of origin. The intersection of the parallel and central meridian has a northing of 0 feet.
To illustrate this, let's look at Oregon (Figure 8). It uses the Lambert conformal conic projection for both the north and south zones. The central meridian is the same for both zones, with an easing of 2,000,000 feet in the original system. In Figure 8 the two red dots indicate the latitudes of the origins: the North Zone's origin is located at the top red dot, and the South Zone's origin is at the bottom red dot.
4. Coordinate Determination On Maps
Along the margins of most maps, you will find one or more sets of coordinates that reference locations on the earth's surface. For example, Figure 9 shows a USGS 1:24,000-scale topographic map, where three types of coordinates are provided: SPC feet, UTM in meters, and latitude/longitude degrees. The map has UTM grid lines spaced every kilometer or 1000 meters. The vertical grid lines determine East-West position and the horizontal grid lines determine North-South position.
In SPC, states of greater north-south extent use which projection?
Group of answer choices
Lambert conformal conic projection
Transverse Mercator projection
KEY TAKEAWAYS:
Cartesian coordinate system: a coordinate system that specifies points on a plane using a pair of numerical coordinates, which are distances from an origin point.
Universal Transverse Mercator (UTM): a two-dimensional cartesian coordinate system that records locations on the surface of the Earth. It divides the Earth into 60 zones, with each covering a six-degree band of longitude. It uses a secant transverse Mercator projection in each zone.
Easting: the east-west x-coordinate; defined as the distance from an origin in a projected coordinate system.
Northing: the north-south y-coordinate in a projected coordinate system.
State plane coordinate (SPC) system: a set of 124 geographic zones or coordinate systems designed for specific regions of the U.S. Each state contains one or more state plane zones, the boundaries of which usually follow county lines.
Origin of SPC zone: a point established to the west and south of the SPC zone with easting and northing values of 0.
Lecture 4-2 Map Scale
1. What is map scale?
1.1 The purpose of map scale
Earth is big. Maps are small. If your map is to cover a large area, then everything on the map has to be shrunk from its real size. We use scale to indicate distance so that we can cover a reasonable area of the region and display it on paper or a screen.
Map scale expresses the relationship between distances on the map and their corresponding ground distances. Using map scale, measurements made on a map can be converted to ground units. In other words, we are able to know the real distance between two places by measuring their distance on the map using simple tools like a ruler.
A map is meaningless without a scale. For example, in Figure 1, both maps show a view of Middle Earth (the fictional setting of the Lord of the Rings books). But the left map doesn't have a scale, while the right map has a scale bar. Suppose we want to know the distance between the center of Rohan and the center of Gondor. Looking at the left map we might say, "Well, it seems quite close on the map." However, with the map on the right, we can use the scale bar at the bottom to calculate the real distance in miles. We will do this later in this lecture.
1.2 Types of map scale
There are three standard options for representing scale: representative fraction (RF), verbal scale, and scale bar.
1.2.1 Representative fraction (RF)
Representative fraction (RF) is the ratio between a distance on the map and actual ground distance. The representative fraction can be written in the format as either 1/x or 1:x , where the numerator is always 1 and the denominator (x) represents distance on the ground.
1/50,000 or 1:50,000
Above is the representative fraction 1 to 50,000. This means that one unit on the map equals 50,000 units on the ground.
Note that an R.F. has no units (inches, centimeters, etc.), which means that an R.F. scale can be compared between different maps. If you choose to measure in inches, one inch on the map represents 50,000 inches on the ground. If you choose to measure in centimeters, one centimeter on the map represents 50,000 centimeters on the ground.
1.2.2 Verbal scale
Another way to express scale is the verbal scale. It uses words to describe the ratio between the map's scale and the real world. This is the easiest scale to understand because it generally uses familiar units.
There are many ways to express scale verbally. For example, here are three ways to indicate the map scale of 1 inch to 2 miles.
1 inch to 2 miles
1 inch equals 2 miles
1 inch = 2 miles
Converting an R.F. scale to a verbal scale is very easy: simply select ONE unit and apply it to BOTH map and ground numbers. A representative fraction of 1:63,360 can be expressed with the verbal scale "1 inch to 63,360 inches." Since 63,360 inches are equal to 1 mile, you can also express this as '1 inch to 1 mile."
How about 1:72,000?
1:72,000 means that one inch on the map equals to 72,000 inches on the ground (or, remember you can use another unit: "one centimeter equals 72,000 centimeters" would also work). Now we need to convert the small unit (in this case, inch) on the ground distance to some common large unit (e.g., miles). Assuming we want to use mile as the unit, then we just divide 72,000 by 63,360 (since 1 mile = 63,360 inches):
Therefore, we may express the R.F. scale 1:72,000 as “1 inch to 1.1361 miles” on a verbal scale.
(Note: YOU CANNOT MIX UNITS in an R.F.! Doing so will change the numerical relationship of the R.F.)
1.2.3 Scale bar
A scale bar, sometimes also called graphic scale, uses a bar or line to represent a scale. It is usually divided into several segments. It is a graphic ruler printed on the map. Figure 2 shows some scale bars: note that there are two scale bars on this map. The upper one shows a long line that means the length of the line represents 10 miles (63,360 inches) on the earth. The lower one shows a shorter line that means the length of the line represents 10 kilometers on the earth. Both lines are divided into intervals of 5 and 1.
There are several good reasons to use a graphic scale.
a) A scale bar is a straightforward, easy way to determine distances on a map.
b) A scale bar changes size in proportion to the physical size of the map.
The first two methods (RF and verbal scale) would be ineffective if the map is reproduced by a method such as photocopying, which may change the size of the map. If the map size changes, the scale is lost: an inch measured on a smaller/enlarged map does not equal an inch on the original map. A graphic scale solves this problem because it doesn't change size if the map changes size; the map reader can use it with a ruler to determine distances on the map.
In the U.S., a graphic scale often includes both metric and imperial units. If a map’s size changes after scanning, photocopying, or enlargement on a screen, the scale bar is also enlarged or reduced; this means it's still accurate and can be used to measure map distance. As long as the size of the graphics scale is changed along with the map, it will be accurate.
For example, Google Maps uses a scale bar which resizes when you zoom in or out. Figure 3 shows two views of Madison: the first figure shows a full view of the Madison area, which has a line segment with the word "2 mi" in the bottom right corner. This is a scale bar. It means that in the current view, the length of the line on this map represents 2 miles on the ground. As we zoom in to get more details of the University of Wisconsin-Madison, the scale bar resizes. In the right figure, the scale bar now shows that the length of the line represents 2,000 feet on the ground.
1.3 Large scale vs. small scale
Choice of scale is important for the cartographer to accurately portray the correct amount of details on the map.
A small scale map shows a large area with few details.
A large scale map shows a small area with more details.
Figure 4 shows two views of the same location but at different scales. In the small scale map on the left, the features are pretty small. Only major highways, cities, and counties are shown. In the large scale map on the right, only Chicago is covered, but it provides much more detailed information such as local streets, roads, parks, and rivers.
A large scale map is referred to as "large" because the representative fraction (e.g. 1/25,000) is a larger fraction than one on a small scale map. A small scale map may have an RF of 1/250,000 to 1/7,500,000. Large scale maps will have an RF of 1:50,000 or greater (i.e. 1:10,000).
1.4 Transitioning between scales
In a paper map, the scale is FIXED.
In a computer-based map or a web-based map, the scale is DYNAMIC and changeable.
A typical GIS system (like Google Maps) would include a series of maps with different scales. The maps are carefully designed so that when you zoom in or out, the content remains legible and clear (so the transitions between scales are smooth). We saw this in Figure 3.
As the map scale becomes larger – and as the area becomes smaller – the accuracy of measurements made on the map typically increases. As you zoom in on the map, more geometric detail and additional information are shown. The six maps in Figure 6 show different levels of detail for a hydrologic map of the Austin area in the state of Texas. The rivers that are lines at smaller scales (the upper maps) become more detailed polygons at larger scales (the lower maps). Small creeks are not displayed in the small scale maps at the top but are shown in the large scale maps at the bottom. There are also more stream labels as the map scale increases. In the last two large scale maps, full street networks are displayed.
2. How can we calculate map scale?
There are three steps to calculate map scale:
1) Measure the distance between any two points on the map. This distance is the map distance (MD).
2) Determine the horizontal distance between these same two points on the ground. This distance is the ground distance (GD).
3) Use the representative fraction (RF) formula, and remember that RF must be expressed as:
RF = 1/x = MD/GD
3. How does map scale influence map content and appearance?
3.1 Scale and generalization
Scale influences generalization and symbolization of geographic features on the map.
Map generalization is the elimination of map detail as the scale decreases. As the scale of the area decreases, some geographic features must be eliminated from the map.
Now let’s look at an example in Figure 7. In a large scale map, say 1:5,000, every building, road, and the river is displayed. Decreasing the map scale to 1:500,000 means we can no longer display every building, road, and river; cities are now indicated by colored patches crossed by fewer lines. If we continue to decrease the map scale to 1:5,000,000, cities will be displayed as simple dots.
3.2 Mismeasurement (not required)
Another effect of the map scale is uncertainty in the size and shape of geographic features.
Take a look at Figure 8: suppose the coast of Britain is measured using a 200 km ruler, specifying that both ends of the ruler must touch the coast. Now cut the ruler in half and repeat the measurement, then repeat again with another shorter ruler. It has been demonstrated that the measured length of coastlines and other natural features appear to increase as the unit of measurement (the ruler) is decreased.
It's important to remember that any measurement you take of a geographic feature, it's size, shape, height, or anything else, cannot be perfectly accurate.
In summary: map scales introduce other kinds of distortion such as generalization of features, and mismeasurement, which, along with distortion brought by map projections, all contribute to the total map distortion. In addition to these distortions, the way we represent Earth’s surface through symbolization adds another source of error. For example, when would you use a straight line or a curvy line to represent a stream?
Map scale: the mathematical relationship between distances on the map and their corresponding ground distances
Representative fraction: the ratio between map and ground distances
Verbal scale: a type of map scale that expresses the relationship between map distance and ground distance using words
Scale bar: a map element used to graphically represent the scale of a map. A scale bar is typically a line or a bar, segmented like a ruler and marked in units proportional to the map's scale
Map generalization: the elimination of map details as scale decreases
Lecture 5-1 GPS Basics
1. Fundamentals of GPS System
1.1 The origin of GPS
Historically humans found their direction by landmarks, but this was very unreliable.
Since World War II, LORAN (long-range navigation) has been used for marine navigation. LORAN uses radio signals from multiple transmitters that are used to determine the location and speed of the receiver. It is good for sailing, but its utility is limited within coastal areas.
During the 1960s, the U.S. Navy used a system called Transit, which determined the location of sea-going vessels with satellites. The drawback of Transit was that it didn’t provide continuous location information—you would have to wait a long time to locate your position rather than always knowing where you were. The Naval Research Laboratory Timation program was another early satellite navigation program of the 1960s, which used accurate clock timings for ground position determination from orbit.
Because of these limitations, the Department of Defense (DOD) finally said: “We need something better for navigation: all-day, all-night, and covers all terrain.”
After spending 12 billion dollars, the global positioning system (GPS) was devised and implemented in the early 1990s. GPS is also called NAVSTAR (Navigation System, Timing and Ranging), which is the official U.S. DOD name for GPS. It is a satellite-based navigation system with global coverage (GNSS) and can provide accurate positioning 24 hours a day anywhere in the world. Right now, GPS is provided free of charge by US.
The core of GPS is a constellation of satellites. The first satellite in the system was launched in 1978. The twenty-fourth GPS satellite was launched in 1993. The system was declared fully operational in April, 1995.
1.2 GPS components
The GPS consists of 3 main components: space segment, control segment, and user segment.
The Space Segment is a constellation of satellites for broadcasting positioning signals.
The Control segment is a set of ground stations for monitoring, tracking, and correcting those signals.
The User Segment is composed of all GPS devices that receive its signals, like your smart phone, handheld GPS, or car navigation system.
These three segments are organized and administered separately, but work together to make up GPS.
1.2.1 Space Segment
The space segment is a constellation of GPS satellites positioned in medium earth orbit at an altitude of 20,200 km (12,552 miles) above the earth’s surface. GPS satellites broadcast a set of signals down to the Earth. These signals contain information about 1) the position of the satellite, and 2) the precise time at which the signal was transmitted from the satellite.
The GPS constellation is composed of 24 satellites. All satellites are divided into 6 orbital planes. There are 4 satellites in each plane. Figure 4 shows the structure of the GPS satellite constellation: the 6 orbital planes are shown in colored circles, and the colored points lay on the circles are individual satellites. The orbits are at about 20,200 km. The inclination angle of the orbital planes with respect to the equator is 55.
1.2.2 Control Segment
The control segment of GPS represents a series of worldwide ground control stations that track and monitor the signals being transmitted by the satellites. These control stations are spread out to enable continuous monitoring of the satellites.
A control station monitors the signals from the satellites and sends correction information back to the satellite (Figure 5). The control stations also transmit satellite data to the master control station at Schriever Air Force Base, in Colorado Springs (Figure 6). Right now the control system consists of five ground stations including the master station: Colorado Springs (where the master control station is located), Kwajalein, Diego Garcia, Ascension Island, and Hawaii.
1.2.3 User segment
The user segment of the GPS represents a GPS receiver somewhere on Earth that is receiving signals from the satellites. Each GPS receiver also has a clock and a processor to “decode” the satellite’s signals. Depending on the unit, the receiver may also have a graphical display to show location and speed information. Figure 7 shows some examples of GPS receivers.
1.3 Other GNSS
other countries have developed (or are in the process of developing) their own versions of GPS, presumably to not be completely dependent on U.S. technology. Here are some examples:
GLONASS was the name of the USSR’s counterpart to GPS and operated in a similar fashion. It provides an alternative to Global Positioning System (GPS) and is the only alternative navigational system in operation with global coverage and of comparable precision. GLONASS consisted of a full constellation of satellites with an orbital setup similar to GPS. By 2001, however, there were only a few GLONASS satellites in operation, but Russia now has a renewed program and more GLONASS satellites have been launched.
Galileo: the European Union’s version of GPS, which, when completed, is projected to have a constellation of 30 satellites and operate in a similar fashion to GPS.
COMPASS (BeiDou-2): China’s version of GPS currently under construction. The system will be a constellation of 35 satellites.
2. How does GPS find a location?
2.1 GPS positioning steps
Satellites send signals containing location and time to the GPS receiver.
The GPS receiver searches and obtains signals from at least three satellites. The more satellites it finds, the higher accuracy it can achieve.
The GPS receiver a) calculates its distance to the satellites, and b) determines its location using the method of “trilateration”.
2.2 Calculating distance between satellite and receiver
In order to find your current position, an GPS receiver first calculates the distance from its location to each satellite using the equation below:
Distance = time delay * speed of light
Satellite radio waves travel at approximately the speed of light: 180,000 miles per second. This is the "speed of light" in the equation. For the "time delay", the satellite signal contains information about the satellite’s status, orbit, time (T), and location it's broadcasting the signal from. When PS receivers get the signal, it records the current time (T1) and also gets the time the signal was sent from the satellite (T). The time delay can be calculated by subtracting the time when the signal was sent from the time the signal was received, or: T1 - T.
Let's look at an example illustrated in Figure 9: a GPS receiver received the signal at T + 3, and also knew that the signal was sent at T. This means the distance can be calculated by:
Distance = t * c = 3 x 180,000 miles per second = 540,000 miles
2.3 Determining the location of receiver (Trilateration)
After find out the distances between the receiver and satellites, a technique called “trilateration” is used to determine exact position. In order to perform Trilateration, signals from at least 3 satellites are required. However this only gives you the horizontal location of a point on the Earth's surface, and this is called a two-dimensional fix (2D fix). Most of the time, a fourth satellite is used to improve the accuracy and help to provide a three-dimensional fix (3D fix), which includes elevation. In order to understand trilateration, let's start by looking at a simpler version - 2D trilateration.
2.3.1 2D Trilateration
Trilateration in two dimensions is commonly used when plotting a location on a map.
Imagine that you are on a trip and arrive in an unknown location. You are lucky to find three persons who provide you enough information to calculate where you are (Figure 10):
The first person you bump into tells you (somewhat unhelpfully) that you are 50 miles away from City A (Figure 10). That puts you somewhere on a circle (the green circle in Figure 10) sweeping outward 50 miles from City A. This isn't very useful information; you could be anywhere on the green line.
The second person tells you (again, not being overly helpful) that you’re located 60 miles away from City B. This puts your location somewhere on a circle 60 miles from City B—but when you combine this with the information that places you 50 miles away from City A, you can narrow your location considerably. You are either at p1 or p2.
Luckily, the third person you see tells you that you’re 50 miles from City C. You will notice that p2 is the only option that fits all three of the distances from your reference points, so you can disregard p1 and be happy that you're not lost anymore.
2.3.2 3D Trilateration
The same concept applies to GPS. Rather than locating yourself relative to three other points on a map, the GPS receiver is finding its distances relative to three satellites. Also, since a position on a 3D Earth is being found with reference to positions surrounding it, a spherical distance is calculated rather than a flat circular distance. This process is referred to as trilateration in 3D (or 3D trilateration).
GPS is based on satellite ranging, i.e. finding the distance between GPS receiver and satellites. In this situation satellites are precise referenced points (just like the cities A, B, and C we used in the Figure 10), which means the receiver knows the exact locations of the satellites. We will determine our distance from the satellites (section 2.2).
Suppose we receive a signal from one satellite (Figure 11, first panel) and we calculate that it is 12,000 miles from our current position. Therefore, we know that we are somewhere on the surface of sphere which has a diameter of 12,000 miles and satellite 1 at its center.
We also know that we are 11,000 miles from satellite 2. Now we can narrow it down to the points where the two spheres intersect (Figure 11, second panel).
If we also know that we are 11,500 miles from satellite 3 (Figure 11, third panel) we can further narrow it down further: we have to be at one of two points where three spheres intersect (the two yellow dots in figure 11 panel 3). However only one point, located on Earth's surface, is possible (the other point is in outer space, and we at least know we're not there!)
3. Errors and Limitations of GPS Systems
3.1 Sources of GPS errors
GPS has been designed to be as accurate as possible, but there are still errors. Table 1 shows some examples of the source of errors and the amount of error contributed by each source.
Table 1. Sources and amount of errors in GPS system
Error source | Amount of Error |
Satellite clocks | 1.5 to 3.6 meters |
Atmospheric conditions - Ionosphere | 5 to 7 meters |
Atmospheric conditions - Troposphere | 0.5 to 0.7 meters |
Multipath | 0.6 to 1.2 meters |
Selective availability | Eliminated by May 2000 |
Typically with an ordinary civilian receiver, like your smart phone, the accuracy of GPS would be about 15 meters (or less) in the horizontal direction.
3.1.1 Satellite clocks
Both satellites and receivers need a clock to record time. The satellite's clocks can contain errors. The role of the receiver and satellite clocks is very important in calculating precise locations (Section 2.2). We need to know the time when a signal was sent from the satellite and the time when the signal reached to the receiver. Therefore we need to synchronize the receiver's clock with the satellite's clock. However inevitable inaccuracies in determining time means there will be an error of about 1.5-3.6m in determining the receiver's location.
3.1.2 Selective availability (SA)
The U.S. Department of Defense, worried about enemies making use of GPS, instituted Selective Availability (SA) with the goal of intentionally making the positioning information less accurate. This intentional degradation of GPS signals is called selective availability. When SA was active, civilian GPS receivers could only get position accuracy within 100 meters. This, naturally, limited GPS applications in the civilian sector – who wants to try to land an airplane using GPS when the runway's location could be 100 meters off?
SA proved costly to the DOD during the 1991 Gulf War and the 1994 Haiti campaign, because the military quality GPS devices were in short supply. After the Gulf War, the U.S. Army announced it would install GPS in all armored vehicles to help minimize friendly fire incidents (which were a major source of casualties in Operation Desert Storm) caused by armored unit commanders lost in the featureless Iraqi desert or out of position during ground attacks.
In 2000 the Pentagon deactivated SA. However the U.S. military still controls GPS and SA could be reactivated at any time.
3.1.3 Atmospheric conditions
The atmosphere is one of the largest sources of error due to atmospheric refraction. The satellites send signals to GPS receivers, but particles in the atmosphere can alter the speed of signal and cause delays. This causes inaccurate measurements of the time delay.
3.1.4 Multipath errors
Multipath errors occur when GPS satellite signals reflect off surfaces, such as trees or buildings, before they reach the GPS receiver (Figure 12). These reflections delay the signal and cause inaccuracies. Multi-path is the greatest source of error in forests lands and is the most difficult to combat. Other causes of multipath error include: topography (hills and valleys), tall buildings, vehicles, cliffs, tree canopies, and other structures that obstruct the line of sight between the receiver and the satellites.
3.2 Ways to minimize errors
Very slight inaccuracies in time (hundredths of seconds) can skew location information by thousands of miles. To obtain the highest accuracy using GPS, one needs a clear view of the sky at all times, and the GPS signal has to be able to avoid trees, buildings, and other obstructions that could cause multipath errors. You also want signals from the maximum number of satellites with the best viewing geometry possible. In fact these criteria are almost impossible to satisfy, and there are other ways to improve the accuracy of GPS positioning, e.g. Differential GPS (DGPS), Wide Area Augmentation System (WAAS), and Local area system (LAAS)
3.2.1 Differential GPS (DGPS)
Differential GPS (or DGPS) uses a series of base stations at specific locations on the ground to provide a correction for GPS position determination.
A base station receives satellite signals, and its position is very precisely documented. Since correct, highly accurate coordinates of the base station are known, the base station can calculate a correction to compensate for errors between the exact location and calculated location from GPS. Then the base station will broadcast this correction out to receivers. Thus, when you are using DGPS, your receiver is picking up the usual four satellite signals plus an additional correction from a nearby base station (Figure 13).
3.2.2 Wide Area Augmentation System (WAAS) (not required)
Wide Area Augmentation System (WAAS) is a satellite-based, new “real-time” DGPS correction method, developed by the Federal Aviation Administration (FAA) to obtain more accurate position information for aircraft.
WAAS operates through a series of 25 base stations spread throughout the United States that collect and monitor the signals sent by the GPS satellites. These base stations calculate position correction information (similar to the operation of DGPS) and relay correction information to the master control station. Master control station will then transmit this correction to a WAAS satellite.
These WAAS satellites then broadcast this correction signal back to Earth. The correction information can help GPS receivers remove signal errors, and it allows for significant increases in accuracy and reliability. If your receiver can pick up the WAAS signal, you can determine your position accuracy can reach 3 meters. However, like with regular GPS, obstructions can block this signal.
Figure 14 shows how WAAS works: it includes geostationary WAAS satellites that can receive and broadcast correction signals, 25 WAAS control stations across the west and east coasts of the U.S., and receivers in aircraft. The aircraft receiver gets both GPS signals and correction signals from the WAAS satellites.
Another system for improving GPS positioning accuracy is the local area system (LAAS), which is used for aircraft approaches and landings. Combined, these two systems can provide seamless navigation coverage for aircraft.
GPS (as normally available to the civilian user) provides a nominal fix accuracy of
Group of answer choices
100 meters with Selective Availability enabled.
Key ideas:
Global Positioning System (GPS): a space-based satellite navigation system that provides location and time information in all weather conditions, anywhere on or near the Earth where there is an unobstructed line of sight to four or more GPS satellites.
Space segment: a constellation of 24 satellites that broadcast positioning signals.
Control segment: a set of ground control stations for monitoring, tracking and correcting signals broadcast by GPS satellites.
User segment: GPS receivers for receiving signals.
Trilateration: The process used by GPS to determine the location of a receiver by measuring the distances to three or more satellites.
Selective availability (SA): the intentional degradation of GPS signals by the U.S. military. SA was turned off in 2000.
Differential GPS: a correction method that uses a series of base stations at known locations on the ground to provide a correction of GPS positional information.
Distance = time delay * speed of light (i.e., signal)
Lecture 5-2 GPS Application
1. Why do we use GPS?
Why do we use GPS? There are many reasons: it provides accurate positioning, it can get people to their destinations, it's cheap...
Right now a standard civilian GPS receiver offers accurate positions within a few meters of error while costing less than $100. The availability of GPS receivers played a major role in the “geospatial revolution” – over 80% of data collected now has a geospatial component, and GPS is one of the most important technologies used to collect high quality geospatial data.
Generally GPS has made many processes more efficient, added comfort to our life, and helped in emergency response and health services. Let's first look at two stories:
Example 1: Why can't we walk straight?
So without eyes we can't walk or drive straight. Even if your eyes are open and you're in an unknown place, what if I ask you to walk to an unfamiliar park? You can always ask for directions. But with a smartphone, which always comes equipped with a GPS receiver, you can find it yourself.
Example 2: Korean Airline Flight 007 air crash
On September 1, 1983, Korean Airlines Flight 007 was scheduled to fly from New York City to Seoul via Anchorage, Alaska. The plane was shot down by a Soviet interceptor over the Sea of Japan (Figure 1). An investigation revealed that the pilots had set their starting point wrong, and the error was magnified as they flew. To avoid such disasters, and to provide safer landings, the Federal Aviation Administration asked Stanford to test an airborne GPS system, which would have kept the plane on course and out of the Soviet Union's air defense area.
2. Functions and applications of GPS
GPS has five basic functions: navigation, location, timing, mapping, and tracking (Figure 2), which are widely applied in both public and private sectors such as the military, industry, transportation, recreation, and science. Many applications use a combination of the above functions. Let's go through each function and check out some real-world examples.
2.1 Navigation
Navigation is the process of getting from one location to another. This is what GPS was designed for: it allows us to navigate on water, air, or land; it allows planes to land in the middle of mountains and helps medical evacuation helicopters take the fastest route.
While GPS is today used in all corners of our life, it was originally conceived and developed by U.S military. The military used it to help their aircraft and ships navigate. They also used it to guide weapons (i.e. missiles) to kill.
GPS is also used in automated cars, which allows robots to drive instead of humans. In 2011 the state of Nevada passed the first law allowing automated cars to drive on the roads. Automated vehicles are able to travel the same streets and highways as human drivers, with only a red license plate marking them as robots.
Google's self-driving car is a project to develop technology for autonomous cars. In May, 2014, Google released a new prototype of the driverless car, which is equipped with two seats and no steering wheel, and runs at 25mph (Figure 3). Watch this video (A first driverLinks to an external site.) to learn more about this project.
2.2 Locating
GPS is the first system that can give accurate and precise location information anytime, anywhere and under any weather conditions. Some examples are:
Measuring the movement of volcanoes and glaciers.
Measuring the growth of mountains.
Measuring the location of icebergs - this is very valuable for ship captains to avoid possible disasters.
Storing the location of where you were - most GPS receivers on the market will allow you to record a certain location. This allows you to find these points again with minimal effort and is useful in hard-to-navigate areas such as dense forest.
Tsunamis, also called seismic sea waves or tidal waves, are caused by earthquakes, submarine landslides or submarine volcanic eruptions. Faster tsunami warnings could be issued using GPS data alongside earthquake detection technology. Traditional seismic instruments, on which current warning systems are based, take a long time to accurately assess an earthquake's strength. However, GPS stations can measure large vertical changes in ground elevation in real time. Therefore, GPS data, when added to preliminary seismic data from the same location, could help cut the time lag from 20 minutes to three minutes.
2.3 Timing
Although you might not notice it, GPS brings precise time to us all. GPS satellites carry an atomic clock that contributes very precise time data to GPS signals. The accuracy is measured in nano seconds, which is 100 billionths of a second.
This incredibly accurate time information is used in many applications that rely on perfect synchronization. For example, communication systems, electrical power grids, and financial networks all rely on precision timing for synchronization and operational efficiency. With the GPS timing function, we can all synchronize our watches and make sure international events are actually happening at the same time.
2.4 Mapping
GPS can also be used to create maps by recording a series of locations as well as useful information. This function is used by scientists to collect field data, as well as by industrial and governmental bodies in making geospatial policy.
Here is an example where researchers used GPS-tagged tweets (also known as geotagged tweets), to identify what neighborhoods in San Fransisco are most visited by outsiders. They argue that neighborhoods where outsiders tweet a lot are susceptible to short term gentrification. Gentrification is the process whereby rents in a neighborhood increase due to wealthier residents moving into lower income areas, leading to displacement of low-income communities. Combining this data with other conventional demographic information (income, race, rental prices etc.) the researchers identify neighborhoods where the city can intervene to ward off, stop or slow down the rate of displacement caused by gentrification.
2.5 Tracking
You might have seen this in action movies: the suspect or witness is wearing a small disguised GPS receiver which continuously sends its position to the police. In fact you may have used this yourself: the "Find my phone" app tracks the location of your phone at all times.
Tracking is a way of monitoring people and things such as packages, or moving vehicles. In transportation, GPS is also used to monitor traffic flow by tracking taxis and personal cars.
Another example: GPS-equipped shoes can be used to help patients suffering from Alzheimer’s disease (Figure 5). Another case is to locate missing children. The idea is that if a child was kidnapped or wandered off while wearing GPS-equipped shoes, watches, or a cell phone, you could easily track them down. You can also use GPS system to track your pet.
3. Other issues with GPS
3.1 Privacy concerns
GPS can serve as a surveillance technology with privacy implications. In February 2020, the Wall Street Journal reported that the U.S. government, including Immigrations and Customs Enforcement, was buying sensitive location data from commercial databases in order track people suspected of immigration violations. However, the Supreme Court has argued that government agencies cannot gain access to location data without a search warrant granted by a judge. Still, law enforcement agencies continue to track people using GPS without obtaining search warrants. GPS raises serious concerns about the emergence of the "surveillance state," a situation where government rules by constantly monitoring its citizens, with or without their consent.
3.2 GPS Addiction
Using GPS to navigate has become second nature for many drivers. This can go very wrong: blindly following GPS directions can put you on top of a mountain, or unable to go forward or turn around. Over-reliance on GPS navigation systems can be a serious problem (Figure 6).
Even though GPS is very helpful in determining your location in an unfamiliar area, this information isn't perfectly reliable. GPS companies might be relying on old maps with roads that have been closed or don’t actually exist. This can cause you to follow an incorrect or even dangerous route. Always be skeptical of routes provided by your GPS and trust local sources for direction
Navigation: the process of getting from one location to another based on transportation information.
Atomic clock: a timekeeping device that uses an atom's electronic transition frequency in the microwave, optical, or ultraviolet region of the electromagnetic spectrum as a frequency standard for its timekeeping element. The most accurate way to keep time, it is used in GPS to ensure accurate positioning.
Lecture 6-1 Aerial Photography
1. The history of Aerial Photography
remote sensing is the process of obtaining information ("sensing") without physical contact ("remote"). In geography and environmental sciences, remote sensing refers to technologies that measure objects on Earth surface through sensors onboard aircraft or satellites. Sensors are instruments that receive and measure electromagnetic signals. Human eyes are sensors that receive light and convey image information to the brain. A digital camera has a sensor that receives light and captures pictures. But the sensors used in remote sensing are more complex and specially designed to measure electromagnetic signals at different wavelengths. Airborne sensors are mounted on aircraft and capture images of Earth's surface from the sky. These images are called aerial photographs. Spaceborne sensors are onboard satellites, and the images collected by satellites are called satellite images
Humans have been capturing images of the ground from the sky for over 200 years. Advancements in sensors were coupled with the developments of aerial platforms (the vessels or instruments from which the images are taken, Figure 1) that could be used to take images. Balloons and birds (specifically pigeons) were commonly used before airplanes. Nowadays airplanes and satellites are the major platforms for taking pictures of Earth's surface. Also UAVs (unmanned aerial vehicles) have become frequently used platforms in military and civilian remote sensing applications.
2. How are Aerial Photos Taken?
Aerial photos are obtained by flying aircraft along flight lines (the paths that the aircraft follow), north-south or east-west (Figure 4). Photos are taken along straight flight lines with 60% to 80% overlap, that is each individual photo overlaps its neighbor by 60-80%. Typically more than one flight line is required to cover the area to be mapped, and adjacent flight lines get a 20%-30% side overlap to ensure no gaps in the coverage. This overlap allows for 3D viewing of aerial photographs using the principle of stereopsis.
3. Aerial Photograph Categories
3.1 Based on photo color
Electromagnetic spectrum
In high school physics courses, we learned that light is made of "electromagnetic (EM) waves." Our eyes perceive light in different colors, which correspond to different EM wavelengths. For example when we see a red car, it means the EM energy reflected from the car is in the red wavelengths (620-750mm), while other wavelengths are absorbed by the car. However human eyes and most common cameras cannot see a wide range of EM wavelengths. Of the entire EM spectrum, visible light (the part we can see) is only a tiny portion (Figure 6). Sensors used in remote sensing are much more sensitive than our eyes. They can detect EM energy in both the visible and non-visible areas of the spectrum. In this section you will find some aerial photos that are similar to the regular photos taken by the camera in your phone, but others are quite different.
Panchromatic photo
Panchromatic (meaning "all-colors") photos record or capture electromagnetic energy in the 300 to 700 micrometer (nm) wavelength, including all visible portions of light (Figure 6). Panchromatic aerial photos are usually in grayscale (that is, they are black and white aerial photos). The more visible light gathered by the camera, the lighter the tone in the final photo (Figure 7).
True color photo
True color photos look the similar to the photos you take with camera or phone. They capture three major wavelength of visible light - red, green, and blue. These colors are composited together in the digital imager or film (Figure 7) in such a way that red light is displayed in red, green light is displayed in green, and blue light is displayed in blue.
Color infrared (CIR) photo (false color image)
Another distinctive type of aerial photo is color infrared (CIR), captured using film or a digital sensor that is sensitive to both visible and infrared light (Figure 6). Infrared energy is invisible to our eyes, but is reflected very well by green, healthy vegetation. In CIR photos near-infrared (NIR) energy is displayed in the color red, red light is displayed with the color green, and green light is displayed in the color blue (Figure 8). Blue light is not shown in the image, as it is filtered out by the sensor or film (Figure 8). Color infrared photos are a type of false color imagery. The use of near-infrared energy helps to highlight vegetation: as you can see in Figure 7, all the green vegetation (near-infrared) is colored red in the CIR photo.
Comparison between panchromatic, true color, and CIR photos
Usually it's easier to interpret true color than black-and-white photos; color photos show features in the same colors we see through our eyes, and capture the colors uniquely associated with landscape features. For example: green represents vegetation such as trees or grass.
The most obvious difference between true color and color infrared photos is that in color infrared photos vegetation appears red (Figure 9). Red tones in color infrared aerial photographs are always associated with live vegetation and the lightness or intensity of the red color can tell you a lot about the vegetation itself; its density, health and how vigorously it is growing. Dead vegetation will appear as various shades of tan, while vivid, healthy green canopies appear bright red. Color infrared photographs are typically used to help differentiate vegetation types (Figure 10)
3.2 Based on photo geometry
When taking an aerial photo with a camera or sensor on an airplane, the shooting angle matters. The angle is usually defined by the camera axis, which is an imaginary line that defines the path light travels to hit the camera lens or sensor. Depending on the camera's position and the camera axis angles with respect to the ground, aerial photographs can be vertical, low oblique or high oblique (Figure 11).
Vertical aerial photo
Vertical aerial photographs are photos taken from an aerial platform (either moving or stationary) where the camera axis is truly vertical to the ground (Figure 11). Typically, vertical photos are shot straight down from a hole in the belly of the airplane. Vertical photographs are mainly used in photogrammetry and image interpretation (Figure 12).
Oblique aerial photo
Oblique aerial photographs are photos taken at an angle, which means that camera axis is tilted away from vertical (Figure 11).
Low Oblique photographs are typically taken from 300-1,000 feet above the ground, at a 5-30 degree angle, through the open door of a helicopter. This is a good way to show the facade of a building without showing too much of the roof. The most detailed images of this type are low-altitude aerial photos (Figure 12).
High Oblique photographs are taken from 8,000-13,000 feet above the ground from an airplane, at a 30-60 degree angle, from an open window of the airplane. This is a good way to show areas from 2-20 square miles. Photos taken at high altitudes (1,500-10,000 feet) provide less environmental information since the image scale is much smaller, but high-altitude high-oblique photos have a distinct advantage: more ground area can be imaged in a single photo.
In a high oblique photo the apparent horizon is shown. In a low oblique photo the apparent horizon is not shown. Often because of atmospheric haze or other obstructions, the true horizon of a photo cannot be seen (Figure 12).

3.3 Orthophotos
Relief displacement
On vertical air photos, the scale of the photo will most likely be distorted radially away from its center. Tall objects (such as steep cliffs, towers, and buildings) have a tendency to “bend” outward from the center point toward the edges of the photo - this effect is called relief displacement. The geometric center of the photo is called THE principal point.
For example in Figure 13, when we look at the photo’s principal point, it is like looking straight down at the ground. However if you look outward from the principal point you will see that the tall buildings seem to be leaning away from the center of the photo.
Another example is a photo of the Washington Monument (Figure 14). Why does the Washington Monument seem to lean differently in these images? The reason is that the amount of relief displacement in air photos is influenced by the height of the camera above the ground and the angle of the camera. The left image is taken using a higher oblique angle in a lower position. Therefore the relief displacement is much larger. Typically, the higher the aircraft and the smaller the angle between the ground and the camera, the less severe the relief displacement.
Orthophoto
The effects of relief displacement can be removed from the aerial photograph by the rectification process to create an Orthophotograph (or Orthophoto). Orthophotos are vertical aerial photographs which have been geometrically "corrected". The rectification process removes relief displacement. An orthophoto is a uniform-scale photograph. Since an orthophoto has a uniform scale, it is possible to measure the ground distance on it like you would on a map. An orthophoto can also serve as a base map onto which other map information can be overlaid.
Because most GIS programs can perform rectification, aerial photography is an excellent data source for many types of projects, especially those that require spatial data from the same location over a length of time. Typical applications include land-use surveys and habitat analysis. Large sets of orthophotos, typically taken from multiple sources and divided into "tiles" (each typically 256 x 256 pixels in size), are widely used in online map systems such as Google Maps. OpenStreetMap offers the use of similar orthophotos for deriving new map data. Google Earth overlays orthophotos or satellite imagery onto a digital elevation model to simulate 3D landscapes.
For example, Figure 15 shows two air photos of Tenth Legion, Virginia. The left is a vertical aerial photo without rectification, while the right one is an orthophoto where the relief displacement has been removed. We can see that power line running over the hills is shown as a straight line in the orthophoto, while it appears curved in the left photo due to relief displacement.
4. Are They Maps?
Let's review some definitions:
Aerial photograph: Images/photos taken from cameras/sensors mounted on aircraft.
Satellite imagery: Images taken from sensors mounted on satellites.
Orthophoto: Images in which distortion from the camera angle and topography has been removed and corrected.
Many people think that these images are the same as maps, but they are NOT. Maps are representational drawings of Earth's features while images are actual pictures of the Earth.
Maps have uniform scale, which means that the map scale at any location on the map is the same.
Maps are orthogonal representations of the earth's surface, meaning that they are directionally and geometrically accurate (at least within the limitations imposed by projecting a 3-dimensional object onto 2 dimensions).
Maps use symbols to represent the real world, while aerial photos, satellite images, and orthophotos show actual objects on Earth's surface.
Aerial photos have non-uniform scale, and can display a high degree of radial/relief distortion. That means the topography is distorted, and until corrections are made through rectification, measurements made from a photograph are not accurate. Nevertheless aerial photographs are a powerful tool for studying the earth's environment since they show actual features and not just symbols.
Orthophotos and some satellite imageries have been geometrically "corrected", and therefore have uniform scales. However, while you may be able to see roads on these image, they are not labeled as roads. You must interpret what you see on an image because it is not labeled for you. Therefore, they are NOT maps.
Key Terms
aerial photography: the technique and process of taking photographs of the ground from an elevated position
aerial photo: photos or images taken by sensors on board aircraft or other platforms above Earth's surface
mosaicking: the process of merging different photos from each flight line into one big aerial photo
electromagnetic spectrum: the range of all possible wavelengths of electromagnetic radiation/energy
panchromatic photo: records electromagnetic energy in visible wavelengths and displays it in grayscale/black & white
true color photo: photos that are displayed with red light in red, blue light in blue, and green light in green (how your eyes perceive color)
color infrared photo: photos that display near infrared light in red, red light in green, and green light in blue. In these photos green plants look red.
vertical aerial photo: photos taken from an aerial platform (either moving or stationary) where the camera axis is truly vertical to the ground
oblique aerial photo: photo taken by a camera at an angle; the camera's axis is inclined away from vertical
principal point: the geometric center point of the photo
relief displacement: effect seen in photos where tall objects (such as cliffs, towers) have a tendency to bend outward from the principal point towards the edges of the photo
orthophoto: aerial photos which have been geometrically rectified, correcting and removing the effects of relief displacement
Lecture 6-2 Image Interpretation
1. Elements of image interpretation
Photo or image interpretation is the process of extracting qualitative and quantitative information from a photo or image using human knowledge or experiences.
Most of the time, one can recognize many features on a photo without any training. This is particularly true if you are familiar with the area in the photo. But many objects look quite different from above, and differentiating between similar objects can be difficult. For an instance, distinguishing tree species or crop types (such as wheat vs. corn) does not come easily. Interpreting features in aerial photos is a skill that takes study and practice to develop.
There are eight elements/clues used in image interpretation (Figure 1).
Tone/color -- lightness/darkness/color of an object
Texture -- coarse or fine, such as in a corn field (distinct rows) vs. wheat field (closely-grown plants)
Shape -- square, circular, irregular
Size -- small to large, especially compared to known objects
Shadow -- objects like buildings and trees cast shadows that indicate vertical height and shape
Pattern -- many similar objects may be scattered on the landscape, such as oil wells
Site -- the characteristics of the location; for example, don't expect a wetland to be in downtown Chicago
Association -- an object's relation to other known objects -- for example, a building at a freeway off-ramp may be a gas station based on its relative location
1.1 Tone/color
Tone refers to the relative brightness or color of objects in an image. Generally, tone is the fundamental element for distinguishing between different targets or features. For example, Figure 2 shows different crops in agricultural fields: you can tell there are many crops in different stages of growth from the variety of shades of green.
In a panchromatic image (which, as we learned in the last lecture, is displayed in black and white) tone is the brightness of a particular object. Objects in a panchromatic image reflect unique tones according to their reflectance. For example, dry sand appears white, while wet sand appears black. In black and white near-infrared images, water is black and healthy vegetation is white to light gray.
Color is more convenient for the identification of object details. For example, vegetation types and species can be easily distinguished using color information. Sometimes color infrared photographs or false color images will give more specific information, depending on the filter used and the object being imaged.
1.2 Size
Size is information about the length and width of objects in the image. The relative size of objects in an image can offer good clues to what they are.
In this example (Figure 3), there is a middle school located next to houses. Can you tell which is the school complex and which are the houses? Large buildings in the bottom right corner suggest that they are part of a school complex, whereas small buildings would indicate residential use (single-family homes).
1.3 Shape
Shape refers to the general form, structure, or outline of individual objects. Shape can be a very distinctive clue in image interpretation. For example, agricultural fields and man-made features (e.g., urban or agricultural features) tend to have straight lines, sharp angles, and regular forms while natural features (e.g., forest edges) are generally more irregular. Roads can have turns at right angles, while railroads do not.
In the Figure 4, you can locate a river because it does not follow a straight line, whereas the straight feature (right image) is a man-made canal.
A vertical aerial photograph shows clear shapes of objects as viewed from above. The crown of a conifer tree looks like a circle, while that of a deciduous tree has an irregular shape. Airports, harbors, factories and so on, can also be identified by their shape.
1.4 Pattern
The arrangement of individual objects may create a distinctive pattern. For example, rows of houses or apartments, regularly spaced agricultural fields, interchanges of highways etc., can be identified by their unique patterns.
This is most apparent for man-made features: city street grids, airport runways, agricultural fields, etc. Patterns in the natural environment may also be noticeable, for example bedrock fractures, drainage networks, etc.
Man-made features such as cities tend to have very regular patterns, while natural features do not have regular patterns. In Figure 5, the left image shows a common street pattern with regularly spaced houses, and the right image shows irregular drainage patterns in the mountains.
1.5 Texture
Texture is a micro image characteristic. It describes the frequency of change and arrangement of tones in particular areas of an image. The texture of objects can be identified as fine (smooth) or rough (coarse).
The visual impression of smoothness or roughness of an area can be a valuable clue in image interpretation. For example water bodies are typically fine textured, while grass is medium (homogeneous grassland exhibits a smooth texture), and brush is rough (e.g., coniferous forests usually show a coarse texture), although there are always exceptions.
Coarse textures (Figure 6) would consist of a mottled tone where the tone changes abruptly over a small area, whereas smooth textures would have very little tonal variation
Texture also refers to grouped objects that are too small or too close together to create distinctive patterns. Therefore, texture is a group of repeated small patterns. Examples include tree crowns in a forest canopy, individual plants in an agricultural field, cars in a traffic jam, etc. The difference between texture and pattern is largely determined by photo scale.
1.6 Shadow
Shadow is also helpful in interpretation: it can provide an idea of the profile and relative height of a feature, which makes it easier to identify.
Trees, buildings, bridges and towers are examples of features that cast distinctive shadows. Figure 7 (left) is an image of buildings in downtown San Francisco. Shorter buildings have smaller shadows while taller buildings have longer shadows. Figure 7 (right) is an overhead view of two pyramids showing the large shadows they cast, which is characteristic of tall features.
1.7 Site, situation & association
Site represents the location characteristics of a feature, while association means relating a feature to other nearby features.
Sometimes objects that are difficult to identify on their own can be understood from their association with objects that are more easily identified. For examples, commercial properties may be associated close to major transportation routes, whereas residential areas would be associated with schools, playgrounds, and sports fields.
In the pictures (Figure 8), can you tell which image is a mountain lake and one is a high desert lake? What are the features around the lake that helped you figure it out?
Because of the color and texture, we know that there are trees and vegetation around the lake in the left figure, so it's likely a mountain lake. The lake in the right figure is surrounded by bright sand and little vegetation, which tells us that it is a desert lake.
Key Terms
image interpretation: the process of extracting qualitative and quantitative information from a photo or image using human knowledge or experiences.
tone: the relative brightness or color of objects in an image
texture: the frequency of change and arrangement of tones in particular areas of an image
site: the location characteristics of an item in the image
association: relation between an object and other nearby features in an image
Lecture 7-1 Satellite Remote Sensing Fundamentals
1. What is Satellite Remote Sensing?
1.1 Definition
“Remote sensing is the art and science of obtaining information about an object without being in direct physical contact with the object.”
The National Oceanic and Atmospheric Administration (NOAA) provides another definition which fits better with this course:
"Remote sensing is the science and technology of obtaining information about objects or areas from a distance, typically from aircraft or satellites."
As a tool that provides data and information about Earth's surface, remote sensing is a key component of geospatial technologies.
1.2 Satellites
Satellite remote sensing means sensors aboard satellites capture "pictures" of Earth's surface.
Does the word "satellite" remind you of an action movie scene? A computer expert taps a keyboard while the view from a spy satellite zooms in to a clear view of the building where their target is hiding? You might have an impression that remote sensing satellites can move to track any target and zoom in to read a license plate. In fact, remote sensing satellites for civilian use are not that mysterious and a little more complex.
Typically in remote sensing we categorize the satellites by the type of orbits they operate in, such as geostationary orbit, polar orbit, and sun-synchronous orbit.
In a geostationary orbit, a satellite travels at the same speed as the Earth's rotation, which means it monitors the same place on Earth all the time (Figure 1). Many weather satellites are in geostationary orbit so they can continuously collect information about the same area.
1.3 The advantages of remote sensing
Traditionally, people collect geospatial information through field sampling or surveys. For example to make a topographic map, geographers need to work for months or even years in the study area to make measurements. With the aid of remote sensing and Geographic Information System (GIS), we can now collect global topographic information for both land and ocean over days instead of years. Compared to traditional data collecting methods, remote sensing has the following advantages:
1. It is capable of rapidly acquiring up-to-date information over a large geographical area.
2. It provides frequent and repetitive looks of the same area.
3. It is cheap with less labor input.
4. It provides data from remote and inaccessible regions, like deep inside deserts.
5. The observations of remote sensing are objective.
Remote sensing has redefined maps. Google Earth is a good example: map users todays enjoy high-resolution aerial and satellite imagery covering the entire Earth. Figure 2 shows an example of how remote sensing imagery helps our understanding of the world. With a high resolution image as a background, Google Earth highlights a massive engineering project in Dubai. (What is the biggest different you find between these two images?
2. How does Satellite Remote Sensing Work?
2.1 Physical basis: electromagnetic radiation
Remote sensing measures the electromagnetic radiation reflected by objects. Electromagnetic radiation of different wavelengths has different properties. Wavelengths are expressed in units like micrometers or nanometers. A micrometer (um) is one-millionth of a meter (roughly the size of a single bacterium). A nanometer is one-billionth of a meter. The electromagnetic spectrum is used to describe the characteristics of electromagnetic waves at different wavelengths (Figure 3).
The electromagnetic spectrum (Figure 3) shows the range of all possible wavelengths of electromagnetic radiation. The electromagnetic spectrum goes from shorter wavelengths (gamma and x-rays) to longer wavelengths (microwaves, broadcast radio waves). There are several regions of the electromagnetic spectrum which are useful for remote sensing.
The light which our eyes can detect is part of the visible spectrum. The visible light portion of the spectrum is at wavelengths between 0.4 and 0.7 micrometers (400-700 nanometers). The longest visible wavelength is red and the shortest visible wavelength is violet. Common wavelengths of what we perceive as particular colors are listed below.
Violet: 0.4 - 0.446 micrometers
Blue: 0.446 - 0.500 micrometers
Green: 0.500 - 0.578 micrometers
Yellow: 0.578 - 0.592 micrometers
Orange: 0.592 - 0.620 micrometers
Red: 0.620 - 0.7 micrometers
Blue, green, and red are the primary visible wavelengths, and most remote sensors are equipped to detect energy at these wavelengths. Visible wavelengths are useful in remote sensing to identify different objects. Combining information from visible and near infrared wavelengths, scientists are able to assess changes on Earth, i.e. damage from earthquakes or volcanic eruption, and land cover changes in cities, neighborhoods, forests, and farms.
Infrared
Infrared radiation is very important to remote sensing. Infrared wavelengths range from approximately 0.7 to 100 micrometers, which is more than 100 times as wide as the visible portion of the spectrum. The infrared (IR) region can be divided into two categories based on their properties - the near IR and the far/thermal IR.
Near IR radiation is used in ways very similar to visible radiation. The near IR covers wavelengths from approximately 0.7 um to 3.0 um. Near IR is particularly sensitive to green vegetation. Green leaves reflect most of the near infrared radiation they receive from the sun. Therefore, most remote sensors on satellites can measure near infrared radiation, which lets them monitor the health of forests, crops, and other vegetation.
The thermal/far IR covers wavelengths from approximately 3.0 um to 100 um. Thermal IR energy is more commonly known as "heat." Objects that have a temperature above absolute zero (-273 C) emit far IR radiation. Therefore, all features in the landscape, such as vegetation, soil, rock, water, and people, emit thermal infrared radiation. In this way, remote sensing can detect forest fires, snow, and urban areas by measuring their heat.
Microwave
The microwave region is 1 mm to 1 m. This covers the longest wavelengths used for remote sensing. In your daily life you use microwave wavelengths to heat your food. In remote sensing, microwave radiation is used to measure water and ozone content in the atmosphere, to sense soil moisture, and to map sea ice and pollutants such as oil slicks.
2.2 Remote sensing process
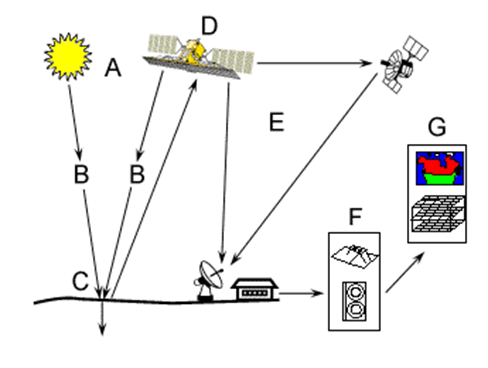
A. Energy Source or Illumination - The first requirement for remote sensing is to have an energy source which illuminates or provides electromagnetic energy to the target of interest.
a. The main source used in remote sensing is the sun. Most visible light sensed by satellites is reflected solar radiation.
b. Sometimes the electromagnetic radiation is generated by the remote sensing platform. Some remote sensors emit microwave radiation to illuminate the object and measure the reflected microwave radiation; this is also known as radar.
c. The energy can also be emitted by the object itself. All objects on Earth emit thermal infrared radiation, which can be detected by remote sensors.
B. Radiation passes through the Atmosphere - as the energy travels from its source (e.g. the sun) to the target, it will interact with the atmosphere it passes through. Another energy/atmosphere interaction takes place as the energy travels from the target to the sensor.
C. Interaction with the Target - once the energy makes its way to the target through the atmosphere, it interacts with the target depending on the properties of both the target and the radiation.
D. Recording of Energy by the Sensor - after the energy has been reflected by, or emitted from the target, the sensor onboard the satellite collects and records the electromagnetic radiation.
E. Transmission, Reception, and Processing - the energy recorded by the sensor has to be transmitted to a receiving station where the data are processed into an image (hardcopy and/or digital).
F. Interpretation and Analysis - the processed image is interpreted, visually and/or digitally, to extract information about the target.
G. Application - the final element of the remote sensing process is achieved when we use the information extracted from the imagery to find new information or to solve a particular problem.
2.2.1 Source of Electromagnetic Energy (Illumination)
Depending on the type of illumination source used, we can divide sensors into passive remote sensing and active remote sensing
Passive remote sensing measures energy that comes from an external source such as sun or the target itself. If the energy comes from the sun and is reflected by the target, satellite sensors can only perceive the target when it is illuminated by the sun. Naturally there is no reflected energy available from the sun at night. Energy that is emitted directly from the object (such as thermal infrared energy) can be detected day or night, as long as the amount of energy is large enough to be recorded by the sensor.
Active remote sensing, on the other hand, provides its own source for illumination. The sensor emits radiation toward the target and measures the radiation reflected from that target. Advantages of active sensors include the ability to obtain measurements 24 hours a day. Active sensors can be used to examine wavelengths that are not sufficiently provided by the sun, such as microwaves, or to better control the way a target is illuminated. Some examples of active sensors are laser range-finding, radar, and lidar (which is like radar but uses laser pulses instead of microwaves or radio waves).
2.2.2 Radiation and the Atmosphere
Before the Sun's radiation reaches the Earth's surface, it has to travel through the atmosphere. Particles and gases in the atmosphere can affect the radiation passing through it. A portion of the Sun's EM energy never reaches Earth's surface, and thus can't be recorded by satellite sensors. This is because the atmosphere contains gases that absorb EM energy of different wavelengths; these gases include nitrogen dioxide (NO2), oxygen (O2), carbon dioxide (CO2), ozone (O3), and water vapor (H2O). For example ozone absorbs radiation in the ultraviolet wavelengths; thus the atmosphere protects you from harmful "UV rays." Water vapor and carbon dioxide absorb some portions of the IR spectrum. Most of the radiation in the visible part of the EM spectrum (visible light) is not absorbed by these atmospheric gases, and so it reaches Earth's surface and is reflected by the objects.
2.2.3 Interaction with the Target
After interacting with the atmosphere, some EM radiation finally makes it to Earth’s surface and interacts with our targets. One of three things can happen to that energy (on a wavelength-by-wavelength basis): it can transmit through the target, it can be absorbed by the target, or it can be reflected off the target.
Transmittance occurs when energy simply passes through a surface. Think of light passing through a windshield of a car.
Absorption occurs when energy is trapped and held by a target.
Reflection: Most of the radiation not absorbed is reflected back into the atmosphere, some of it towards the satellite. This upwelling radiation undergoes another round of scattering and absorption as it passes through the atmosphere before finally being detected and measured by the sensor.
Here are two examples of how different objects on Earth's surface interact with solar radiation:
Trees and Leaves (Figure 6)
- A chemical compound in leaves called chlorophyll strongly absorbs radiation in the red and blue wavelengths of visible light, but reflects green wavelengths. Hence leaves appear "greenest" in the summer, when chlorophyll content is at its maximum. In fall, there is less chlorophyll in the leaves, so there is less absorption and more reflection of the red wavelengths, making the leaves appear red or yellow (yellow is a combination of red and green wavelengths).
- Near infrared wavelengths also interact with leaves. As you saw in previous videos, the cell structure of healthy leaves enhances the reflection of near infrared radiation. In figure 6 you can see how green and infrared energy is reflected by leaves, while the red and blue energy is absorbed.
Water (Figure 7)
- Typically, water reflects much less radiation than other objects; this means water always looks dark in remote sensing images. Longer wavelength (i.e. red and infrared) radiation is absorbed more by water than shorter visible wavelengths. Thus water typically looks blue or blue-green due to stronger reflectance at these short wavelengths, and darker if viewed at red or near infrared wavelengths. If there is suspended sediment present in the upper layers of the water, the water will appear brighter. Chlorophyll in algae absorbs more of the blue wavelengths and reflects the green, making the water appear greener.
2.2.4 Spectral signature
The above examples show how different objects have different absorption and reflection properties at different wavelengths. We call these properties the "spectral signature" of an object. Think of it this way: we have our own unique signature that we use for identification, like when you sign a credit card receipt. In the same way, each type of object on Earth's surface has a unique spectral signature. To describe a spectral signature we usually graph the object's reflectance vs. wavelength (Figure 8). Reflectance describes the fraction energy reflected by an object. The higher the reflectance, the brighter the object would look in remote sensing images. In Figure 8 we can see water has an overall low reflectance in visible wavelengths and zero reflectance in other wavelengths. Green vegetation has very high reflectance in near infrared. We can distinguish different objects in remote sensing images by comparing their spectral signatures.
2.2.5 Recording and processing of remote sensing image
After traveling through the atmosphere again, the radiation reflected or emitted from Earth's surface are recorded by the remote sensors on the satellites. These signals are then presented in the form of images, which might look like photos captured by your digital camera. These images are composed of "pixels" (Figure 9). Each pixel corresponds to a location on Earth, and each has a value indicating the amount of energy being measured by the sensor. More explicitly: each value represents the average brightness in a certain wavelength for a portion of the surface, represented by little square units (pixels) in the image. Figure 9 shows that as we zoom in on the remote sensing image, we can clearly see these tiny squares (pixels), each with a number indicating the level of energy reflected. In the next lecture we will explore the properties of satellite and remote sensing images.
2.2.6 Composite Multi-band Images
When looking at photos on computer screens, each pixel's color corresponds to three values of red, green, and blue. For a remote sensing image, those values are the brightness values of each of those three wavelengths. In remote sensing these wavelengths are called "bands" which each cover a range of wavelengths in the electromagnetic spectrum. For example the red band corresponds to wavelengths between 0.62 - 0.7 micrometers. The displayed colors, either red, green, or blue, are called "channels." Any of the bands of an image can be displayed in any of the channels. As there are only three color channels on a computer screen (red, green, blue), only three bands can be displayed at the same time in a color composite image.
A true color image, as we learned in Aerial Photography, is an image where red band is displayed in the red channel, the green band is displayed in the green channel, and the blue band is displayed in the blue channel. This makes a color composite that looks very similar to how our eyes perceive the world. Figure 10 shows a view of New York City's Central Park. The trees and lawns are green, the lake is blue and the roofs of buildings are bright, which is the same thing you'd see if you were in an airplane flying above the park.
In remote sensing, a typical color composite (like in near infrared aerial photos) is to display the near infrared band in the red channel, the green band in the blue channel, and the red band in the green channel. Figure 11 shows how this is done. The three images of different bands (near infrared, red, and green) are displayed in red, green, and blue channels respectively. Combining these grey-scale images gives us a color image. As we discussed before, vegetation reflects most near infrared radiation, and therefore vegetation appears bright in the near infrared band. As near infrared is displayed in the red channel, vegetation looks bright red in the final image.
Key Terms
remote sensing: the science of obtaining information about objects or areas from a distance, typically from aircraft or satellites
geostationary orbit: an orbit where the satellite travels at the same speed as Earth's rotation, which means it is always monitoring the same region of Earth.
polar orbit: a type of orbit where satellites pass above or nearly-above both poles of the Earth and make several passes per day.
sun-synchronous orbit: a type of near-polar orbit where satellites always pass the same location on Earth's surface at the same local time.
electromagnetic spectrum: the range of all possible wavelengths of electromagnetic radiation/energy
infrared: the portion of the electromagnetic spectrum from approximately 0.7 to 100 micrometers
visible wavelengths: the wavelengths between 0.4 and 0.7 micrometers; energy at these wavelengths are visible to human eyes.
microwave: the region of the electromagnetic spectrum from approximately 1 to 1,000 millimeters.
passive remote sensing: a type of remote sensing technology where the sensor measures EM energy reflected by the target that originates from an external source such as sun or the target itself.
active remote sensing: a type of remote sensing technology where the sensor provides its own energy source for illuminating the target, and then detects the reflected energy.
transmittance: when an electromagnetic (EM) wave passes straight through an object
absorption: when EM energy is trapped and held by an object rather than passing through or reflecting off it.
reflection: the change in direction of a wave at an interface between two different media so that the wave returns into the medium from which it originated. In remote sensing, it is the process where EM energy is reflected back to the atmosphere instead of being absorbed or transmitted by the object.
spectral signature: the properties of an object as described by its absorption and reflection properties at different wavelengths
pixels: tiny uniform regions that make up a remote sensing image, each with its own unique value
band: a range of wavelengths detected by a remote sensor (e.g. green band, near-infrared band)
channel: the displayed color (red, green, or blue) on electronic screens. Different bands can be displayed in different channels, as in color composite images.
Lecture 7-2 Remote Sensing Application
1. Capabilities of Sensors: Resolution
A satellite sensor has three characteristics that define its capabilities: spatial resolution, temporal resolution, and spectral resolution.
1.1 Spatial resolution
Spatial resolution is a measure of the smallest object or area on the ground that can be detected by the sensor. If a sensor has a spatial resolution of 10 meters, it means that one pixel in an image from the sensor represents a 10x10 meter area on the ground.
A sensor’s spatial resolution will affect the detail you can see in an image. In Figure 1 you can see how a sensor with a 0.5 meter spatial resolution can detect much more detail than a sensor with spatial resolution of 10 meters. In the 20x20 meter resolution image, you can't see the houses or buildings. The reason is that only one or two pixels on the image represent one house, and one or two pixels do not form any shape that we can recognize as a house. Figure 2 demonstrates how a house can or cannot be recognized in images of different resolutions.
Images where only large features are distinguishable have low resolution, while in high resolution images, small objects can be detected. Generally speaking, the higher the resolution of an image, the more detail it contains. Commercial satellites provide imagery in resolutions ranging from less than a meter to several kilometers. We will introduce some commercial and public satellites and sensors in section 2.
1.2 Temporal resolution
Temporal resolution is the revisit period of a satellite sensor for a specific location. It is the length of time for a satellite to return to the exact same area at the same viewing angle. For example, Landsat needs 16 days to revisit the same area, and MODIS needs one day.
If a satellite needs less than 3 days to revisit the same place, we would say it has high temporal resolution. A high temporal resolution image is required to monitor conditions that can change quickly or require rapid responses (i.e. hurricanes, tornadoes, or wildfires). If a satellite needs 4-16 days to revisit the same place, it has medium temporal resolution; if it takes more than 16 days to revisit the same place, it has low temporal resolution.
1.3 Spectral resolution
Spectral resolution specifies the number of spectral bands -- portions of the electromagnetic spectrum -- that can be detected by the sensor. For example (Figure 3), if a sensor is measuring the visible portion of the spectrum and treating the entire 0.4 to 0.7 micrometer range as if it was one band, it will produce a black & white image. However, if a sensor (Figure 3) is treating the visible portion of electromagnetic spectrum as three individual bands including the “blue” band from 0.4 to 0.5 micrometer, “green” band from 0.5 to 0.6 micrometers, and “red” band from 0.6 to 0.7 micrometers, it will produce a color image.
The finer the spectral resolution, the narrower the wavelength ranges for a particular channel or band.
High spectral resolution: ~200 bands
Medium spectral resolution: 3~15 bands
Low spectral resolution: ~3 bands
Based on the bands that the sensor can detect, they are classified into three categories (Figure 4):
Panchromatic sensor: a sensor measuring the visible portion of the spectrum and treating the entire 0.4 to 0.7 micrometer range as a single band.
Multi spectral sensor: a sensor that measures several broad bands. For example, we can divide the visible and near-infrared portions of the spectrum into four bands: blue, green, red and a near-infrared band.
Hyperspectral sensor: a sensor that measures many narrow contiguous bands. A hyperspectral sensor can sense over 200 bands.
1.4 Resolution trade-offs
Because of technical constraints, there are always limiting factors in spatial, temporal, and spectral resolution for the design and utilization of satellite sensors. For example, high spatial resolution is always associated with a low temporal and spectral resolution, and vice versa.
One of the reasons is related to the "swath" of the satellite. As you see in the previous video, as the satellite revolves around the Earth, the sensor "sees" a certain portion of the Earth's surface. The part of the surface imaged by the sensor is referred to as the swath (Figure 5). With a narrow swath, the sensor needs to orbit the earth many times to completely cover the whole globe, which means long revisit times and lower temporal resolution. At the same time, if the swath is narrow, it means the sensor scans a small area each time, which allows it to sense at a high spatial resolution. However, to achieve a higher temporal resolution, the swath size needs to be increased. In the same way, a large swath size means that spatial resolution has to be reduced as a compromise.
As a result remote sensors are always designed with trade-offs. Figure 6 shows the spatial and temporal resolution of several current satellite remote sensing systems. You can see that some sensors have high temporal resolution, but low spatial resolution, like GOES, AVHRR, and MODIS. Some of them have low temporal resolution and high spatial resolution. There are also some with medium spectral, temporal, and spatial resolution, like Landsat and SPOT. However there are none with high resolutions in all three aspects.
2. Examples of remote sensing programs
Hundreds of remote sensing satellites have been launched by many countries for various applications. Figure 7 shows some of the NASA (National Aeronautics and Space Administration of USA) earth observation satellites. These satellites were launched with the primary mission of systematic and long-term measurement of Earth's surface and atmosphere. Other satellites launched by governments are used for weather forecasting. Commercial companies can also launch satellites for commercial and public use. Most of these satellites features very high resolution images that can be used in both the private and public sectors. In this section we will mainly introduce five remote sensing satellites/sensors/missions, which are either commonly applied in scientific research and public services or represent the latest technology.
2.1 EOS: NASA Earth Observation System
Over the last decade NASA had launched many satellites to help us understand Earth's systems responses to natural and human-induced changes; this helps us predict and observe climate change, weather patterns and natural hazards. One of the most well-known programs is the Earth Observing System (EOS), which is a constellation of satellites that measure the clouds, oceans, vegetation, ice, and atmosphere of the Earth. EOS has three flagship satellites, Aqua, Terra and Aura, which are equipped with fifteen sensors
Terra was launched in 1999 as a collaboration between the United States, Canada and Japan, and continues its remote sensing mission today. "Terra" means Earth in Latin, which is an appropriate name for the satellite; its instruments measure the natural processes involved with Earth’s land and climate (Figure 8).
Aqua was launched in 2002 as a joint mission between the United States, Brazil and Japan. In Latin "Aqua" means water, indicating that the main purpose of the satellite is to examine Earth’s water cycle (Figure 8). Aqua's main goal is to monitor precipitation, atmospheric water vapor, and the ocean. Terra and Aqua were designed to work in concert with one another. Both Aqua and Terra carry a MODIS and a CERES sensor, which in essence doubled the data collection of these these sensors and increased their temporal resolution.
Aura was launched from Vandenberg Air Force Base on July 15, 2004. The name "Aura" comes from the Latin word for air. Aura carries four instruments, which obtain measurements of ozone, aerosols and key gases in the atmosphere (Figure 8).
2.2 Suomi NPP: the next-generation Earth observation satellite
The Suomi National Polar-orbiting Partnership (NPP) is the first satellite launched as part of a next-generation satellite system which will succeed the Earth Observation System (EOS). Suomi NPP launched on Oct. 28, 2001 from Vandenberg Air Force Base in California. It is named after Verner E. SuomiLinks to an external site., a meteorologist at the University of Wisconsin - Madison. Suomi NPP is in a sun-synchronous orbit 824 km above the Earth. It orbits the Earth about 14 times a day and images almost the entire surface. Every day it crosses the equator at about 1:30 pm local time. This makes it a high-temporal resolution satellite.
There are five sensors aboard Suomi NPP:
• Advanced Technology Microwave Sounder (ATMS)
ATMS is a multi-channel microwave radiometer. It is a passive sensor, which means it measures the microwave radiation of the sun reflected by objects on Earth's surface. ATMS has 22 bands and is used to retrieve profiles of atmospheric temperature and moisture for weather forecasting. These measurements are important for weather and climate research.
• Visible Infrared Imaging Radiometer Suite (VIIRS)
VIIRS is a sensor that collects visible and infrared imagery of the land, atmosphere, cryosphere, and oceans. It has 9 bands in visible and near IR wavelengths, 8 bands in Mid-IR, and 4 bands in Long-IR, which makes it a high-spectral resolution sensor. VIIRS has about 650 m - 750 m spatial resolution, and images the entire globe in two days. VIIRS data is used to measure cloud and aerosol properties, ocean color, sea and land surface temperature, ice motion and temperature, fires, and Earth's albedo. Climatologists use VIIRS data to improve our understanding of global climate change. For example, VIIRS captured a view of the phytoplankton-rich waters off the coast of Argentina (Figure 9). The Patagonian Shelf Break is a biologically rich patch of ocean where airborne dust from the land, iron-rich currents from the south, and upwelling currents from the depths provide a bounty of nutrients for the grass of the sea—phytoplankton. In turn, those floating sunlight harvesters become food for some of the richest fisheries in the world.
• Cross-track Infrared Soundear (CrIS)
CrIS is a fourier transform spectrometer with 1,305 spectral channels in far infrared wavelengths. It can provide three-dimensional temperature, pressure, and moisture profiles of the atmosphere. These profiles are used to enhance weather forecasting models, and they will facilitate both short- and long-term weather forecasting. Over longer timescales, they will help improve understanding of climate phenomena such as El Niño and La Niña.
• Ozone Mapping Profiler Suite (OMPS)
OMPS measures the global distribution of the total atmospheric ozone column on a daily basis. Ozone is an important molecule in the atmosphere because it partially blocks harmful ultra-violet light from the sun. OMPS enhances the ability of scientists to measure the vertical structure of ozone (Figure 10), which is important in understanding the chemistry of how ozone interacts with other gases in the atmosphere.
• Clouds and the Earth's Radiant Energy System (CERES)
CERES is a three-channel sensor measuring the solar-reflected and Earth-emitted radiation from the top of the atmosphere to the surface. The three channels include a shortwave (visible light) channel, a longwave (infrared light) channel, and a total channel measuring all wavelengths. These measurements are critical for understanding climate change.
2.3 Landsat Program: the longest continuous Earth-observation program
2.3.1 History of the Landsat Program
The Landsat satellites were launched and managed by NASA and USGS for long-term continuous Earth surface observation. The first satellite in the program (Landsat 1) launched in 1972. Since then Landsat satellites have collected information about Earth's surface for decades. The mission is to provide repetitive acquisition of medium resolution multispectral data of the Earth's surface on a global basis. The data from the Landsat spacecraft constitute the longest record of the Earth's continental surfaces as seen from space. It is a record unmatched in quality, detail, coverage, and value for global change research and has applications in agriculture, cartography, geology, forestry, regional planning, surveillance and education. Table 1 and Figure 11 show the history of the program.
Landsat 5, launched on March 1st, 1984, provided data for 29 years before retirement. It provided the longest continuous Earth observation records with 30 meter spatial resolution, 16-day revisit time, and 7 spectral bands that are essential to monitor changes on Earth's surface.
After the failure of Landsat 6, Landsat 7, equipped with a sensor similar to that on Landsat 5, was launched on April 15, 1999. However after working together with Landsat 5 to provide even more frequent observations, Landsat 7 had an equipment failure: the Scan Line Corrector (SLC) broke on May 2003, which means any images taken after that date have data gaps. However in spite of this failure, Landsat 7 still provides valuable images today.Figure 12 shows a comparison of images before and after the SLC failure.
Landsat 8, launched on February 11, 2013, joins Landsat 7 to continue capturing hundreds of images of the Earth's surface each day.
In April 2008 all archived Landsat scenes were made available for download free of charge by USGS.
2.3.2 Sensors used on Landsat Satellites
Landsat satellites carry sensors with medium spatial, temporal, and spectral resolution; their images are the most widely used of all satellite images.
MSS (Multi-Spectral Scanner) is the sensor that was used on Landsat 1 through 5. It takes measurements in 4 different bands: red, green, and two near infrared bands at 80-meter spatial resolution.
Landsat 4 and 5 were also equipped with a new sensor called the TM (Thematic Mapper). TM is also a multispectral sensor with seven bands: blue, green, red, three bands in the near infrared, and one band in far infrared. TM has 30 meter resolution in the visible and near infrared bands, and 120 meter resolution in the thermal/far infrared band.
Landsat 7 was launched in 1999, not carrying either the MSS or TM, but a new sensor called ETM+ (Enhanced Thematic Mapper +). ETM+ senses the same 7 bands as the TM, but with improved spatial resolution in the thermal band: from 120 meter resolution to 60 meter resolution. It also includes a new band: a panchromatic band with a spatial resolution of 15 meters. Landsat 7’s temporal resolution is still 16 days, but can acquire about 250 images per day.
Landsat 8, launched in 2013, carries two brand new sensors: the Operational Land Imager (OLI) and Thermal Infrared Sensor (TIRS). OLI collects data in 9 bands (Table 2), including four in visible wavelengths, one in near IR, two in shortwave IR, a panchromatic band in visible wavelengths, and an additional "cirrus" band. Compared to ETM+, OLI adds another band (Band 1) in the violet wavelength for better observations in coastal area and a band (Band 9 "cirrus") in near IR to detect cirrus clouds. TIRS collects data in two bands in thermal/far infrared wavelengths.
2.3.3 Applications of Landsat Data
Landsat data are valuable for decision makers in fields such as agriculture, forestry, land use, water resources and natural resource exploration. Over the past decade, Landsat has been intensively used to understand changes in global natural and social environment including land cover and land use changes, deletion of coastal wetlands, human population changes, and global urbanization.
Agricultural productivity evaluation and crop forecasting also require satellite data because they can use the data to accurately predict crop yields. Similarly, understanding current conditions of and changes in fresh water supplies also requires systematic repetitive coverage provided by the Landsat system.
Figure 13 shows two Landsat images of the Amazon rain forest. The left was taken in 1975, while the right one was taken in 2012. These two images highlight dramatic change in forest: deforestation taking on a "fishbone" pattern following major roads. These images are actually not true color. Near infrared bands are displayed in the green channel, therefore dense rain forests are green. But the shortwave infrared band which highlights villages and roads is displayed in red. Therefore the pink or purple color you see in the images represents human-made features like roads, houses and villages. Farmland is represented in light brown colors.
Landsat data has also been used in wildfire monitoring (Figure 14). Intense wildfires usually happen in conifer forests, though they occur infrequently—once every 100 to 300 years. Fire returns nutrients to the soil and replaces old tree stands and ground debris with young forest. In 1988, Yellowstone National Park experienced a severe fire season: fifty wildfires ignited, seven of which grew into major wildfires. By the end of the year 793,000 acres had burned. Figure 14 is a false color composite image taken by Landsat 5 in 1989. Green is natural forest, while the red areas are burnt. It takes many decades for a conifer forest to recover to pre-fire conditions, and through the use of Landsat, researchers have been able to chronicle the forest's recovery over the past two decades.
2.4 Geostationary Operational Environmental Satellites (GEOS) System: Your "Weather Guy" in the Space
In the United States, your local television or newspaper weather report probably uses one or more weather satellite images collected from the Geostationary Operational Environmental Satellites (GOES) system. The GOES series of satellites is the primary weather observation platform for the United States.
The GOES system, operated by the United States National Environmental Satellite, Data, and Information Service (NESDIS), supports weather forecasting, severe storm tracking, and meteorology research. Spacecraft and ground-based elements of the system work together to provide a continuous stream of environmental data. The National Weather Service (NWS) uses the GOES system for its United States weather monitoring and forecasting operations, and scientific researchers use the data to better understand land, atmosphere, ocean, and climate interactions.
The GOES system uses geostationary satellites, 35,790 km above the earth, which — since the launch of SMS-1 in 1974 — have been essential to U.S. weather monitoring and forecasting. The GOES satellites provide new imagery every 15 minutes. The sensors in GOES satellites detect 3 spectral bands: visible, infrared, and water vapor.
The latest generation, GOES 15 (Figure 15 left), launched on March 4, 2010, represents an advance in data products for weather forecasting and storm warnings over previous satellites.
Figure 15 (right) is an image of Hurricane Katrina on August 28, 2005, at 11:45 a.m. (EDT), captured by GOES-12. At that time, the storm was at Category 5 strength and projected to impact New Orleans. Now, after more than 10 years of stellar service, NOAA’s Geostationary Operational Environmental Satellite (GOES)-12 spacecraft will be retired.
2.5 QuickBird: Commercial Very High Resolution Image
QuickBird is a commercial satellite operated by DigitalGlobe (Figure 16, left). It was launched from Vandenberg air force base in California on October 18, 2011. At the time of its launch it was the highest resolution commercial satellite in operation. Now there are sensors with even higher spatial resolution, including the WorldView and GeoEye satellites also operated by DigitalGlobe.
QuickBird has two sensors --- a four-band (blue, green, red, and near-infrared) multispectral sensor with 2.4-meter spatial resolution and a panchromatic sensor with 0.61-meter spatial resolution. Both sensors provide off-nadir views (they can point in a direction other than straight down) and provide global coverage every 2 and 6 days, respectively. QuickBird circles the globe 450 km above the Earth on a sun-synchronous orbit. Note that it might seem to you that QuickBird has both super high spatial and temporal resolution. But actually, the high temporal resolution is made possible by its off-nadir view capabilities, which has limited scientific usage compared to the at-nadir (straight-down) views supplied by Suomi-NPP and Landsat. The 0.61-meter and 2.4-meter imagery are extremely high-resolution, allowing very detailed information to be seen in an image (Figure 17 right). The data contributes to mapping, agricultural and urban planning, weather research, and military surveillance.
DigitalGlobe maintains the largest sub-meter resolution constellation of satellites, and QuickBird is one of these. Their other satellites include WorldView-1, WorldView-2, IKONOS, GeoEye-1, and WorldView-3. Many of the images you see in Google Earth come from these satellites. Table 3 shows the spatial resolution of these satellites. WorldView - 3 provides the highest spatial resolution in the panchromatic band with 31cm. Figure 16 compares images with 30cm and 70cm resolution. High resolution images such as these can be used to produce map images that clearly show smaller features such as cars and trees; these images are useful for natural resource management, urban planning, and emergency response.
2.6 Other remote sensing satellites
The satellite systems we introduced are only a small set of the Earth-observing platforms orbiting hundreds of miles over your head dedicated to monitoring sea surface temperature, glaciers, and particles in the atmosphere. There are other important systems launched by the European Space Agency (ESA), India, Japan, China, and Brazil.
Envisat is a satellite launched by ESA in 2002, which carries 10 instruments including ASAR (Advanced Synthetic Aperture Radar), an active microwave sensor mainly used for sea forecasting and monitoring sea ice, and MERIS (Medium Resolution Imaging Spectrometer) a multi-spectral imaging spectrometer with 300m spatial resolution and 15 spectral bands.
The ESA's Sentinel mission has a few satellites in operation: Sentinel-1 is a polar-orbiting, all-weather, day-and-night radar imaging satellite that tracks ocean processes. The first Sentinel-1 satellite was launched on April 3, 2014. Sentinel-2 is a polar-orbiting, multispectral high-resolution imaging mission for land monitoring that provides imagery of vegetation, soil and water cover, inland waterways and coastal areas. Sentinel-2A, the first of two Sentinel-2 satellites, launched on June 12, 2015. It carries sensors that can image in 13 spectral bands, with 4 bands at 10 m spatial resolution, 6 bands at 20m resolution and 3 bands at 60m resolution. This will provide even more Landsat-type data.
The Meteosat series of satellites are Europe’s geostationary weather observation satellites. The first generation of Meteosat satellites, Meteosat-1 to Meteosat-7, provide continuous and reliable meteorological observations. They provide images of the Earth and its atmosphere every half-hour in three spectral channels (visible, infrared, and water vapor) via the Meteosat Visible and Infrared Imager (MVIRI) sensor. The latest generation satellite, MSG-3, was launched on July 5, 2012. The next satellite (MSG-4) is planned for launch in 2015.
Key Terms
spatial resolution: a measure of the smallest object or area on the ground that can be detected by the sensor
spectral resolution: the number of spectral bands -- portions of the electromagnetic spectrum -- that a sensor can collect energy in.
temporal resolution: the revisit period of a satellite's sensor for a specific location on the Earth. It is also the length of time for a satellite to complete one orbit cycle of the globe.
panchromatic sensor: a sensor measuring the visible portion of the spectrum, which treats the entire 0.4 to 0.7 micrometer range as if it was one band.
multispectral sensor: a sensor that collects information across several bands, each of which are broad portions of the electromagnetic spectrum.
hyperspectral sensor: a sensor that collects information across very many narrow, contiguous bands. A hyperspectral sensor could be able to sense over 200 bands.
swath: the strip of the Earth’s surface from which geographic data are collected by a satellite
Lecture 8-1 Introduction to GIS
1. GIS: a Geospatial Technology
1.1 Geospatial technology components
Geospatial technologies include three major components: GPS, RS, and GIS. While GPS and RS are useful in collecting data, a GIS is used to store and manipulate the acquired geospatial data.
GPS: A system of satellites which can provide precise (100 meter to sub-centimeter) locations on the earth’s surface.
RS: Use of satellites or aircraft to capture information about Earth's surface.
GIS: Software systems with the capability for input, storage, manipulation/analysis, and output/display of geographic (spatial) information.
1.2 GIS: What does the 'S' stand for?
GIS can be many things. The acronym is used in a number of ways:
Geographic Information Systems: the technology - “GIS”
Geographic Information Science: the concepts and theory - “GIScience”
Geographic Information Studies: the societal context - “GIStudies”
In this course, we refer to GIS as Geographic Information Systems. GIScience describes the larger scientific domain associated with geographic information systems, their application in scientific research, and the fundamental scientific study of geographic information.
GIS: emphasizes technology and tools for the management and analysis of spatial information.
GIScience: a new interdisciplinary field built around the use and theory of GIS, which studies the underlying conceptual and fundamental issues arising from the use of GIS and related technologies, such as: spatial analysis, map projections, accuracy, and scientific visualization.
GIStudies: understand the social, legal and ethical issues associated with the application of GI Systems and GI Science.
2. Why GIS matters?
2.1 Location, location, location!
Everything that happens, happens somewhere. Knowing where something happens can be critically important. Problems that involve location, either in the information used to solve them or in the solutions themselves, are termed geographic problems. Geographic Problems (Figure 1; Figure 2) which are associated with location, include the following examples:
Health care managers choose where to locate clinics and hospitals
Delivery companies design and update daily routes and schedules
Tourists navigate to a destination in an unfamiliar city
Forestry companies plan for sustainable tree harvest and replanting programs
All of the above involve location information, and we use GIS to solve these problems. GIS is capable of recording, analyzing, and displaying information about LOCATIONS. A GIS is a system for analyzing and solving geographic problems.
Hurricane Katrina was the the third most intense tropical cyclone in the United States (Figure 2). It flooded 80% of New Orleans caused an estimated $81 billion (2005 US dollars) in damage and killed 1,836 people. Figure 3 shows the flooding of the I-10 interstate Highway, caused by the breaching of the levees near the 17th Street Canal.
Dealing with the aftermath posed a number of geographic problems. Many of the GIS maps that were used to deal with the situation were produced by volunteers, as well as official agencies. The initial demand for GIS maps were from first responders and emergency staff on the ground, who needed street maps for search and rescue.
In addition, other “situational awareness” maps were required by incident commanders to find areas that had likely experienced (or would experience) flooding, road closures, and access restrictions. These maps are also essential to determine the availability of shelters and kitchens, locations of water and ice distribution points, and the locations of environmentally hazardous sites. For example, Figure 4 shows the New Orleans area and a prediction of the effects of a Katrina-like 32 foot storm surge, combined with 20-foot wave action, as modeled in a GIS. The city boundary is in green, and the limit of the storm surge is in red.
2.2 How does GIS fit in?
To solve geographic problems, a GIS maps the locations of things and phenomena, and analyzes patterns.
Through maps we can first find a feature, which means that we can use maps to see where or what an individual feature is. In addition, we can also find patterns over things and phenomena. While looking at the distribution of features on the map instead of just an individual feature, you can see patterns emerge. A GIS can show the spatial patterns of things, which otherwise cannot be seen only through maps. Therefore, it helps us to discover the correlation among things and make smart decisions.
Now let’s look at several examples showing how we can use a GIS to help find patterns on a map.
Example 1: Figure 5 maps population data in the U.S. state of Maine, with different population densities represented by different colors. With this map we can easily identify that counties with population densities exceeding 500 person per square mile are mostly located in southwestern areas; this is represented with orange and red colors. This is the spatial pattern of population distribution.
Example 2: Another example comes from mapping the concentration of uncredentialed teachers vs. the distribution of family income in Los Angeles (Figure 6). Such maps help uncover correlations between different demographic data, such as socioeconomic status, family income, education levels, and race. With this map, we can see that concentrations of uncredentialed teachers are mostly located in poor communities.
Example 3: The real power of GIS comes through combining data layers for a more complex analysis. Different map layers are at the same projection, covering the same geographic area, but showing different data (Figure 7). These layers are overlaid for analysis across layers. For example, to find a suitable location for a new road, we need to compile maps of various environmental and social factors to make the best decision.
2.3 GIS applications
GIS can be applied in many areas to solve different geographic problems. Figure 9 shows a list of fields in which GIS is being used in professional practice (such as urban planning, management and policy making), scientific research (such as in environmental science and political science), and many other fields, such as civil engineering, education administration, real estate, health care and business.

3. GIS Fundamentals
3.1 Definitions
Everyone has a favorite definition of GIS, and there are many to choose from, suggesting that those definitions work well in different circumstances with different groups. Some common definitions are:
Container of maps
Computerized tools for solving geographic problems
Spatial decision support system
Mechanized inventory of geographically distributed features and facilities
Methods for revealing patterns and processes in geographic information
Tool to automate time-consuming tasks.
GIS is usually viewed as a container of maps by the general public. Figure 10 shows a traditional map cabinet (used to hold printed maps in a setting like a research library or archive). A GIS could be thought of as the digital or electronic equivalent of the map cabinet. However, it is more than that. GIS is a computerized tool for solving geographic problems, a spatial decision support system, a mechanized inventory for geographical features and facilities, a tool for revealing what is otherwise hidden in geographic information, and finally, a tool for performing operations on geographic data that are too tedious, expensive or inaccurate to perform manually.
3.2 A brief history of GIS
GIS is built upon knowledge from geography, cartography, computer science, and mathematics
GPS and RS technologies collect massive amounts of data. This means we need technology to help process and analyze these data. This is one of the major drivers for the development of GIS. Geographic Information Science is a new interdisciplinary field built out of the use and theory of GIS. The development of GIS has been gone through three stages: innovation, commercialization, and exploitation.
Innovation
The first stage is the era of innovation. The first GIS was the Canada geographic information system (CGIS) designed in the early 1960s as a computerized map-measuring tool to provide large-scale assessment of land use in Canada. CGIS was conceived by Roger Tomlinson, who is known as “the father of GIS.” In 1964, The Harvard Lab for computer graphics and spatial analysis was established under the direction of Howard Fisher at Harvard university. In 1966, SYMAP, the first raster GIS, was created by Harvard researchers. This lab was home to several legendary people in GIS. For example, Jack Dangermond (seen in the first video), who established ESRI (Environmental System Research Institute), and Jim Meadlock, one of the founders for Integraph company, all came from the Harvard lab. In 1969 Jack Dangermond, a student from the Harvard lab and his wife Laura formed ESRI to undertake projects in GIS. Jim Meadlock and four others that worked on the guidance systems for Saturn rockets formed M&S Computing, later renamed Intergraph. At the same time, several key academic conferences, such as AutoCarto, were hosted.
Commercialization
The second stage of GIS development is the era of commercialization, which dates from the early 1980s, when the price of sufficiently powerful computers fell below a critical threshold. ArcInfo was the first major commercial GIS software system. It set a new standard for the industry.
Exploitation
GIS entered the era of exploitation in the 2000s when the Internet became the major delivery vehicle for GIS services and applications. Right now, GIS has more than 1 million core users, and there are perhaps 5 million casual users of GIS.
3.3 GIS Components
A GIS has six components: hardware, software, procedures, data, people, and network.
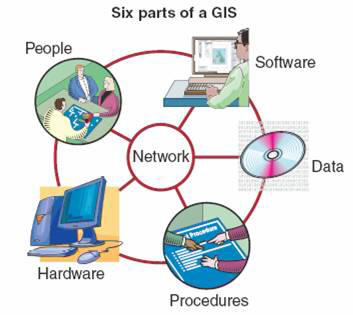
At the very center of this diagram is the NETWORK, which makes modern GIS possible. The sharing of data, dissemination of maps, graphics, and information, and the ability to connect a GIS to Internet Services that extend its capabilities. Note that the network needs to be at the center of the diagram, because it connects all the components.
HARDWARE is the foundation of GIS. GIS hardware used to consist of mainframe computers. Today we can use smart phones and other mobile devices for use in a GIS. The most typical and common GIS hardware configuration consists of a desktop computer or workstation that is used to perform most of the functions of a GIS. A client-server arrangement is very common, meaning that simple computer hardware or mobile device (a client) is intentionally paired with a more sophisticated powerful computer hardware (a server) to create a complete working system.
SOFTWARE allows a GIS to perform location-based analysis. GIS software packages include commercial software purchased from a vendor such as ESRI, Bentley, or Intergraph, as well as scripts, modules, and macros that can be used to extend the capabilities of GIS software. An important part of GIS software today is a web browser and all the associated web protocols, which are used to create novel GIS web applications.
DATA is the essence of GIS. GIS data is a digital representation of selected aspects of specific area son the Earth’s surface or near-surface, built to serve problem solving or scientific research. GIS data is typically stored in a database. The size of a typical GIS database varies widely. A GIS dataset for a small project might be 1 Megabyte in size. An entire street network for a small country might be 1 Gigabyte in size. Larger datasets, including elevation data for the entire Earth at 30m intervals can take up terabytes of storage, and more detailed datasets of the entire earth can be many many times larger. The dataset used in a GIS can be VERY large. A GIS, by nature, stores detailed information about the Earth. This means that a GIS Professional needs to be very careful and deliberate about data storage and the time required for data processing.
In addition to these four components, a GIS also requires PROCEDURES for managing all GIS activities, such as organization, budgets, training, customer mapping requests, quality assurance and quality control.
Finally, a GIS is useless without the PEOPLE who design, program, maintain, and use it.
Among the six components of a GIS, which do you think is the most expensive? It's data.
3.4 GIS Workflow
The workflow for a GIS is represented as a loop when applied in a real-world application (Figure 13).
First, we collect and edit spatial data.
Second, we visualize/display the data and perform spatial/statistical analysis to understand phenomena and patterns.
Third, we design and produce maps as reported results for decision makers.
The decisions made will produce effects in the real world. Therefore we collect the feedback and restart the loop to further improve our decisions and policies.
Key Terms
Geographic Information Systems (GIS): Software systems with the capability for input, storage, manipulation/analysis, and output/display of geographic (spatial) information
Geographic Information Science: a new interdisciplinary field built out of the use and theory of GIS, which studies the underlying conceptual and fundamental issues arising from the use of GIS and related technologies, such as: spatial analysis, map projections, accuracy, and scientific visualization.
Geographic Information Studies: to understand the social, legal and ethical issues associated with the application of GI Systems and GI Science.
Geographic Problems: problems that involve an aspect of location, either in the information used to solve them, or in the solutions themselves.
Lecture 8-2 Geospatial Data
1. Geospatial Data
Data is fundamental to geospatial technologies. Geospatial data consists of two parts: spatial data and attribute data/non-spatial data.
Spatial data: Spatial data indicates the location of geographic features, which is usually expressed with geographic coordinates. From Lecture 3 we know there are two types of coordinate systems to pinpoint locations: geographic coordinate systems displaying locations as latitude and longitude, and projected coordinate systems that store locations in units of length, such as meters and inches.
Attribute data (non-spatial data): Attribute data (non-spatial data) describes the properties of geographic features. Examples are statistics, text, images, sound, etc., all of which can serve as descriptive information to tell us what a feature is.
2. Spatial Data Models
2.1 Two types of data models
In GIS, two different models are used to store, organize, and manage spatial data. The first one is the vector data model, by which we represent the geographic features with Points, Lines and Polygons. The second type is the raster data model, where the geographic features are divided and represented by evenly spaced grid cells (or pixels). For example, aerial photos and remote sensing images are raster data.
In theory, both data models can be used to represent individual features or continuous surfaces. However in practice, we typically use the vector data model to represent discrete data, such as locations of restaurants, streets, and house parcels, and use the raster data model to represent continuous data, such as elevation, air temperature, population.
Figure 1 shows an example of the difference between the two models. In the real world we have geographic features, such as cities, suburbs, roads, forests, and rivers. In GIS, in order to store and manage these information, we need to conceptualize or generalize them into symbols and images. For example, we can use points to store the location of each household, use lines to represent streets, and use polygons to show land parcels. These features are discrete in space, and are mostly stored as vector data. There are some features such as elevation which changes continuously across the land. To represent these features, we typically use raster data to manage them as a two-dimensional image.
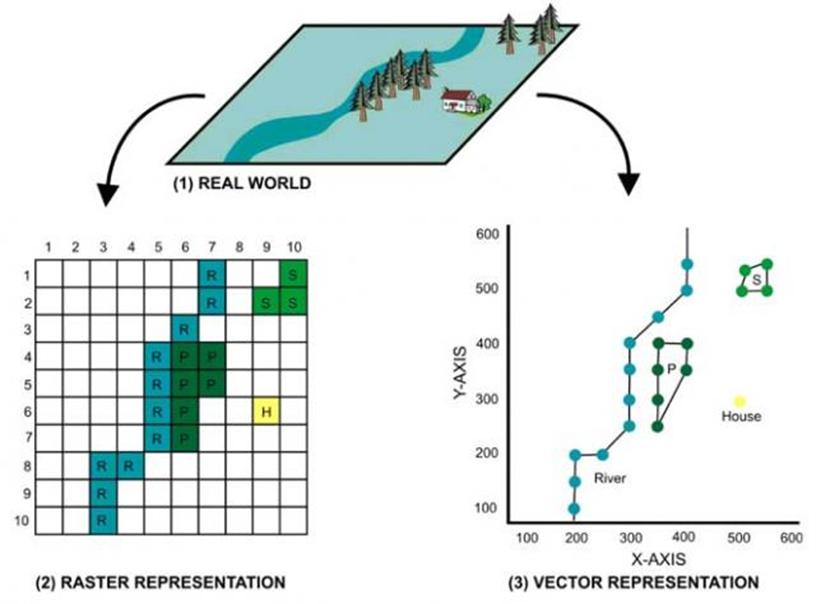
2.2 Raster data model
The Raster Data Model is a spatial data model that defines space as an array of equally sized cells arranged in rows and columns (Figure 3). All geographic variation is then expressed by assigning properties or attributes to these cells. The cells are also called pixels.
One grid cell is one unit that holds one number, which means that every cell is assigned a value, even if it is “missing”. In that case the grid cell will be assigned with value as N/A, 0, or Null. The value is the property of the geographic features you want to describe with this raster data, such as elevation, land cover type, population, etc. A cell/pixel has a resolution, given as the cell size in ground units. The grid cell is the smallest unit of resolution and may vary from centimeters to kilometers depending on the application.
Mostly, you won't be able to see individual pixels when you look at the whole raster image. But as you zoom in to a small area, you can see it is made up of small grid cells pixels with different colors (Figure 4).
Figure 5 shows a raster image of land cover types. Different colors represent different land cover classes. If you look closely, you can see the area is broken down into individual grid cells or pixels.
Raster data are very common. All the .jpg, .png, or .tiff images in you computer are raster, even though they might not be geospatial data. Aerial photos and remote sensing images are all geospatial data in a raster format that can be used in GIS. Figure 6 is an aerial photo showing the center of Madison. This is a typical raster dataset with high resolution.
2.3 Vector data model
In a vector data model, points, lines, and polygons are used to represent geographic features.
Points represent objects that are represented with a single (x, y) coordinate pair. For example, things like houses and cities, which are usually too small to be represented by area or polygon in a map, are displayed as points.
Lines represent linear features, which have a certain length but are too narrow to be shown as areas or polygons, such as rivers and roads. In GIS lines are stored as series of (x, y) coordinates connected by straight lines.
Polygons represent features depicted by a closed loop of (x, y) coordinates which enclose an area. These features are usually too large to be depicted as points or lines. Features like a forest patch or a lake are usually represented as polygons.
Figure 7 shows five different but related vector data layers of the contiguous United States. The cities are drawn in a point vector layer. The roads and rivers are line vector layers. The lakes and states are polygon data .layers
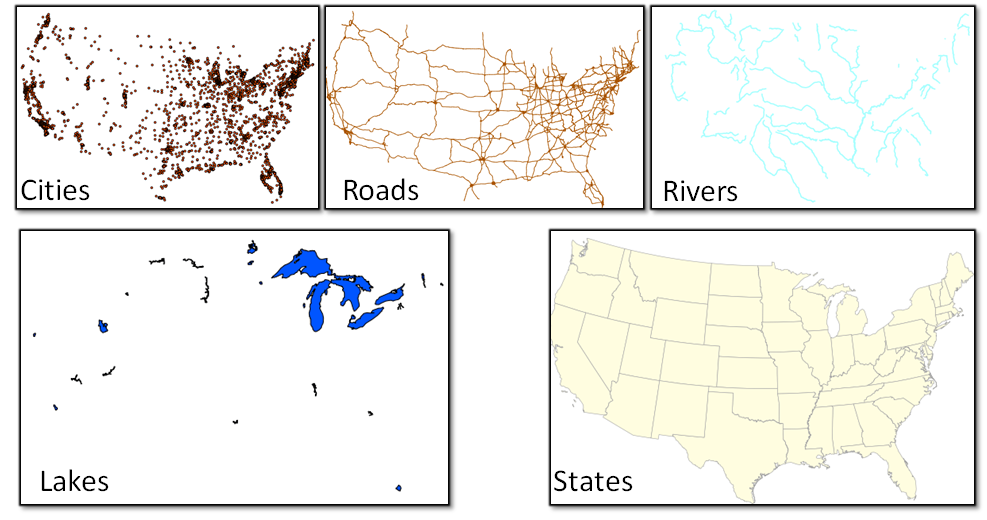
When these five data layers are displayed together in the GIS software, they generate the map in Figure 8. Layers can be turned on and off individually. The left side shows the order of the layers.
The states layer (polygon/area) is at the bottom; it is the base layer. The city layer (point) is at the top. The layer order determines how the map is drawn, with the top layer displayed at the top and the other layers below it. If the states layer moves to the top, it will cover everything else except the great lakes, since they are outside of the state polygon boundaries.
Now let's look at the UW campus map in Figure 9. This is a Google Map. Note that this Google map uses in a vector data model.
Q: Which features are polygons?
A: Since this is a large scale map (How can we tell?), it includes a lot of detail. The buildings, rivers, parks, and even the roads are represented as polygons.
Now let's zoom out to see an overview of the Midwestern states (Figure 10).
Q: Again, which features are polygons?
A: All previous campus polygons are eliminated, as only the great lakes, large national parks, and states are shown as polygons. This is because as you zoom out of a map, polygons will continuously get smaller until they are so tiny that they become illegible and can't be shown as individual areas. You would instead use points or lines instead. Below we can see that Madison is now represented as a point, while roads are shown as lines.
Vector data can be collected using a GPS unit, ground survey, or obtained through raster-vector conversion procedures from scanned images. We can also digitize a printed map to collect vector data. Figure 11 shows an analyst using a digitizer to collect vector data from a printed map.
3. Attribute Data
3.1 What is an attribute table?
Attribute data are descriptive information about geographic features. Attribute data is important in GIS to link a geographic location or feature to its properties. Some examples of attributes include county population, land cover type, and air temperature. These information can be used to find, query, and symbolize features or raster cells. For example, we can use different colors and symbols to represent houses, streets, lakes, and rivers.
Generally, attribute data is stored in an attribute table. In such a table, each row represents a feature and each column represents an attribute. Each data layer displayed in a GIS software has an attribute table of information linked to it. The GIS software cross-references the attribute data with the geospatial features displayed in the map, allowing searches based on either or both.
Attribute tables are used in both vector and raster data, but in different ways.
3.2 Attribute tables for vector data
In Figure 12 the upper left picture is an attribute table for the states of the contiguous U.S., represented in a vector data model. In this table each column is an attribute or property of a state, such as the sub region this state belongs to, the abbreviation of the state, and the population of the state. Each row represents a geographic feature - in this case, a state. For example, the highlighted row refers to the state of Wisconsin. We can tell that Wisconsin is in the East North Central region, its abbreviation is "WI", and its population in 2000 is 5,363,675.
A GIS is capable of cross-referencing the attribute data with the geospatial features, allowing queries based on attributes or geographic locations. If we click row 7 in this attribute table, we see that the Wisconsin polygon is highlighted in yellow (Figure 11, upper right figure). If we click the polygon of Wisconsin on the map (Figure 11, lower left), we can obtain all the attributes for Wisconsin as a list (Figure 11, lower right). You will learn more about this function as we move on through this course.
3.2 Attribute tables for raster data
While almost every piece of vector data in a GIS has an attribute table, raster data does not always have one. Data, such as average air temperature, precipitation or elevation, are simple numerical values; we don't usually need to know the properties of different values, say 75F and 98F.
For some raster data an attribute table is necessary. In such data each cell or pixel is assigned a single value, each defines a class (i.e. urban), a category (i.e. mid-west region), or a group (i.e. low-income households). In this case the attribute table will typically have rows associated with each unique value (class/category) and provide the properties of this class, group, category, or membership.
Figure 13 is an example of the attribute table for a raster data. There are four types of land cover: forest land, wetland, crop land, and urban, each of which is displayed with a specific color in the map and a numerical value (1-4) in the attribute table. While the rows of the attribute table represents four land cover types (values 1 - 4), the columns show properties of these categories, such as type, count of pixel, and area. For example, forest land is recorded as 1 in the data. There are a total of 9 forest land grid cells, which comprises 8,100 square meters.
3.3 Comparing raster data attributes and vector data attributes
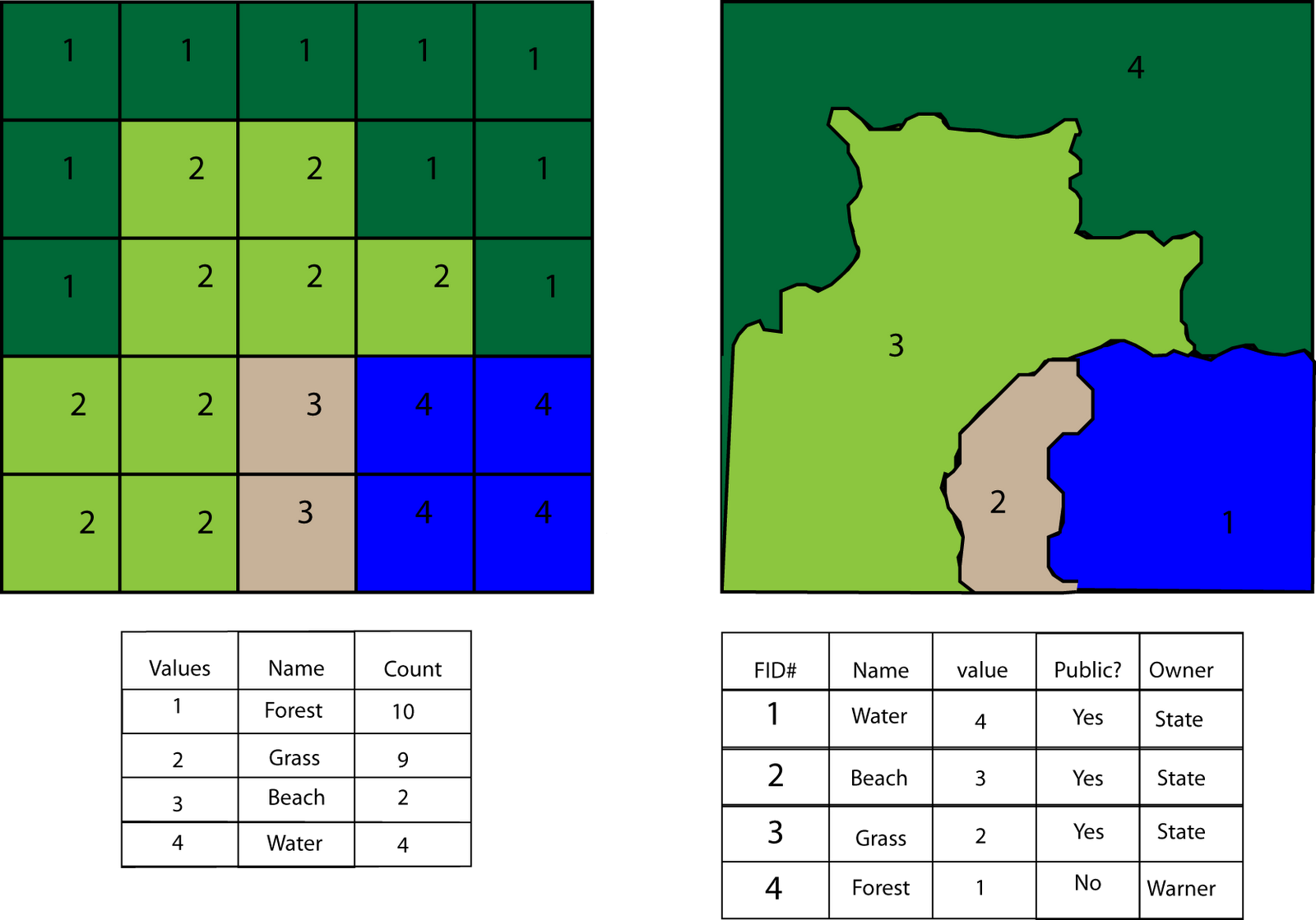
In the raster dataset, the geographic features are represented by pixels/grids, each of which has a unique value (1-4). In the left map of Figure 14, each of the four values (1-4) indicating a land cover type has a unique color. In the attribute table (Figure 14, lower left), each row corresponds to a certain class, and the columns includes the properties of each class such as the name and number of pixels for each. For example, class 3 (brown in the raster data image), represents the land cover type "beach" which has 2 pixels in the image.
In the vector dataset the land cover classes, i.e. water, beach, grass, and forest, are represented by polygons, and they are displayed by different colors in the map (Figure 14, upper right). There are four different features/polygons in the vector data. Therefore, the attribute table also has four rows (excluding the name row), each of which represents a polygon. There are five columns, each representing one attribute. For example, the second row shows the land cover type "beach." It has a value of 3 (this matches the raster data). The other columns tell you that this feature is public and owned by the state. Note that the first column - "FID#" is a unique indicator of the polygons. In most GIS systems, "FID#" is a necessary column in every vector dataset and is always kept as the first column.
Key Terms
spatial data: data indicating the location of geographic features, usually expressed in geographic coordinates
attribute data: data that describes the properties of geographic features
raster data model: a spatial data model that defines space as an array of equally sized cells arranged in rows and columns
pixel: the smallest cells of equal size which are assigned unique values in a raster data model
resolution: the pixel size (in ground units) in a raster data model
vector data model: represents geographic features with points, lines and polygons
point (vector): a feature in a vector data model represented with a single (x, y) coordinate pair
line (vector): a linear feature in a vector data model, which has a certain length but is too narrow to be shown as an area or polygon
polygon (vector): a feature in a vector data model depicted with a closed loop of (x, y) coordinates, which encloses an area
attribute table: a table to store attribute data, where each row represents a feature and each column represents a different attribute of the feature
Attribute data in vector data model are typically stored into tables, while attribute data in raster data model are stored as values associated with each cell.
Lecture 9-1 Query and Spatial Analysis
1. Database and Data Query
1.1 What is a data query?
The data query is the most fundamental function in GIS and geospatial databases. For example, you can use it to search for nearby restaurants using Google Maps. In a more technical way queries can manipulate a geospatial database and select only the records you want.
In GIS, queries are composed using the Structured Query Language (SQL) format, like a mathematical function. SQL is a specific format that is used to query a database to find attributes that meet certain conditions. For example, in a data layer made up of points representing cities in the U.S., each city has a series of attributes, including name, state, area, population, and average household income. How do we find the city of Madison, Wisconsin and its associated attributes? We can build a SQL query in our GIS program (Figure 1):
“NAME”= “Madison” AND “ST” = “WI”.
Note that "ST" here is the column name in the attribute table for the name of State. One has to specify "ST" = "WI", otherwise, the result would be a list of cities named "Madison".
1.2 Basic SQL syntax
In SQL, a simple query will use one of the following relational operators.
Equal (=): used when you want to find all values that match the query. For an instance, querying for CITY_NAME = ‘Madison’ will locate all records that exactly match the characters 'Madison'.
Not Equal (<>): used when you want to find all the records that do not match a particular value. For example, querying for CITY_NAME <> 'Madison' will return all the records that do not match the word ‘Madison,’ that is every city but Madison.
Greater Than (>) or Greater Than Or Equal To (>=): used for selecting values that are more than (or more than or equal to) a particular value. For example, you would use it to find all cities with a population greater than or equal to 100,000.
Less Than (<) or Less Than Or Equal To (=<): used for selecting values below (or below and equal to) a particular value.
A simple query only uses one operator and one field as in the above examples. A compound query enables you to make selections using multiple criteria. In order to construct a query linking multiple criteria together, we need boolean operators: AND, OR, NOT.
AND
If you want to select cities in the U.S that have a population over 50,000 (a variable called POP2000 in the attribute table) and an average household income (a variable called AVERAGEHI) of more than $30,000. A compound query can combine these two requests: POP2000 > 50000 AND AVERAGEHI > 30000.
OR
A different query could be built by saying: POP2000 > 50000 OR AVERAGEHI > 30000. This would return cities with a population of greater than 50,000, cities with an average household income of greater than $30,000, and cities that meet both criteria.
NOT
When you want all of the data related to one criteria, but exclude what relates to the second criteria, you would use a NOT query. If you want to select cities with a high population, but not those with a higher average household income, you could build a query like: POP2000 >= 50000 NOT AVERAGEHI > 30000 to find those cities.
1.3 Spatial query
Database queries that take place in the attribute table, while very important, are not usually considered spatial analysis. This is because there is no "spatial" relationship involved in the process. Spatial Query is also known as "select by location" in some GIS software (e.g., ArcGIS). The spatial query tool allows you to select features based on their location relative to other features. For an instance, if you want to know how many houses were affected by a recent flood, you could select all the homes that fall within the flood boundary.
We can use a variety of methods to select the point, line, or polygon features in one layer that are close to or overlap with features in the same or another layer, such as:
Select points or lines that fall within polygons
Select points or lines within a certain distance of a point, line or polygon
Select polygons that either entirely or partially fall within another polygon.
2. Spatial Analysis
2.1 Spatial analysis: the crux of GIS
Spatial analysis is considered to be the crux of GIS, because it includes all of the transformations, manipulations, and methods that can be applied to geographic data. The process turns data into information to support decisions, and reveals hidden patterns; for example, patterns in the occurrence of diseases may hint at the mechanisms that cause the disease.
To be simple, spatial analysis is the process of transforming data into useful information.
A pioneer example of a spatial query, where different layers of data were incorporated into an analysis, took place in 19th century London. In 1854 John Snow was trying to determine the cause of a cholera epidemic. At the time nobody knew much about cholera's causes. Snow created a map with both the location of cholera deaths (represented as the black dots in the map) and water pumps (the P circles) that supplied residents with drinking water. This showed Broad Street at the center of the epidemic, and that led him to correctly conclude that the Broad Street water pump was the source of the outbreak (Figure 3). This was one of the first examples of spatial analysis where the spatial relationship of the data significantly contributed to understanding a phenomenon.
2.2 Spatial analytical operations
There are four fundamental functions/operations of GIS spatial analysis, including:
Reclassifying maps
Overlaying data
Measuring distance and proximity
Characterizing neighborhoods
Please note what we cover here is just the tip of the iceberg of GIS functions. A GIS can offer many powerful functions for manipulating and analyzing geospatial data. For example, ESRI ArcGIS (one of the most popular GIS programs) has more than 1,000 functions.
2.2.1 Reclassifying Maps
Reclassification is reassigning values on an existing map based on the values of an attribute, e.g. land cover group. By looking at an attribute for a single data layer, we re-classify the data layer based on that attribute's range of values. Reclassification can be applied to both raster and vector data models.
The reclassification of raster data is very straightforward. In Figure 4, the Base Raster (the original raster map) has pixel values ranging from 1 to 20. After reclassification by mapping the old values to new values via the table in the middle, the new image (output raster) only contains values from 1 to 5.
2.2.2 Overlaying data
GIS often involves combining information from different data layers. For example:
What are the land uses for this soil type?
Whose parcels are within the 100-year floodplain?
Which interstate highways pass through Madison?
The way we answer such questions is to overlay data layers on top of each other and construct a new layer or map containing the combined information. When two or more layers are combined together to create composite maps, this is referred to as an overlay operation in GIS.
Overlay can involve simple operations such as laying a road map over a map of local wetlands (Figure 6), or more sophisticated operations such as multiplying and adding map attributes of different values to determine average values and co-occurrences. Overlaying operations can be performed on both raster or vector data. However, raster and vector data differ significantly in the way overlay operations are implemented.
2.2.2.1 Overlay for vector data
Overlaying vector data involves combining two or more vector data layers, which share the same geographical boundaries, in order to create a new data layer. Most GIS software provides the following overlay tools for vector data: Intersect, Union, Identity, Symmetrical difference, Erase and many others (Figure 7).
Intersect
Intersecting means only the features that both layers have in common are retained in a new layer. This type of operation is commonly used when you want to determine an area that meets two criteria. In the first row of Figure 7 only areas that the "square layer" and the "circle layer" share in common are retained, resulting in a new layer with irregular shapes.
Suppose you need to find all agricultural lands within 10 miles of a river (its floodplain). In this case, we need two layers: a river floodplain layer (which is a buffer layer containing all areas within 10 miles of rivers, referred to "buffer" in the next section), and a layer indicating all agricultural lands. You would intersect both layers to find areas that are covered by both layers.
Identity
In the Identity operation, an input layer is specified so that all of its features will be retained in the new layer. Additionally, the intersection of this layer and a second layer will be created and added to the new layer. In the second row of Figure 7, the second row, all the squares are present in the resulted layer, as well as the irregular shapes from the intersect operation (the first row).
For example, instead of getting only the intersection of the river floodplain and agricultural lands, you may want a new layer showing all floodplain areas and indicate which parts of it are agricultural lands and which are not. This is a process of identification, where you want to identify agricultural land and non-agricultural land in the floodplain. This is why this operation is called "identity."
Union
After a union operation, all of the features from both layers are combined together into a new layer. In Figure 7 (the forth row), you will find everything remains: the squares, the circles, as well as their intersections. This operation is often used to combine features from two layers.
Following the river floodplain and agricultural land example, after a union overlay operation, the new data layer will have all the features from both the floodplain and agricultural land layers. In particular, there will be three different types of features: agricultural land on floodplain, agricultural land outside floodplain, and non-agricultural land on floodplain. Think: what kind of features will you get if you use an intersection or identify operation? (You will answer this question in the self-assessment of this lecture.)
Symmetrical difference
In this operation all of the features of both layers are retained, except for the areas they have in common (the result of intersection). You can compare the third row (symmetrical difference) and the forth row (union), you will see that in symmetrical difference, only the intersected parts are left out.
Such operation would work in such case: "well, all agricultural lands within 11 miles of the rivers would be in danger in flood, therefore let's exclude them from our development plan."
2.2.2.2 Overlay for raster data
Overlay in raster is much simpler – the attributes of each cell/pixel from two or more layers are combined according to a set of rules. Within a raster dataset, each cell has a single value, and two raster layers can be overlaid in a variety of ways. The only thing to note is that in order to overlay raster data, the pixels in each layer need to be the same size.
The most common way to overlay raster data is to use a simple mathematical operator (sometimes referred to as Map Algebra), such as addition or multiplication. “Map algebra” is similar to traditional algebra where basic operations, such as addition, subtraction and exponentiation, are logically sequenced for specific variables to form equations.
Let’s look at three examples. The first one is addition, where the values of each grid cell from two different layers are added together (Figure 8).
The same thing can also be performed using multiplication. In Figure 9, both layers have values of 1 or 0. For example, the first layer could be a map of agricultural and non-agricultural land, with 1 indicating "agricultural" and 0 indicating "non-agricultural". The second layer could be a development area map, with 1 indicating "under development" and 0 indicating "will develop later". In this way, after multiplication, only cells which have value of 1 in both layers would be 1, otherwise they will be 0. In the resulting layer, 1 indicates "agricultural land under development", and 0 indicates everything else.
In the third example (Figure 10), overlay is done by determining the maximum value from two layers. Here, we want to get the maximum amount of rainfall in 1980 and 1981.

Figure 11 shows a real example of spatial overlay. Two data layers, land cover type and land slope, are overlaid to create a new layer called coincidence. The COVERTYPE layers contains three land cover types, forest (3), meadow (2), and open water (1). The SLOPE_CLASSES layers also contains three classes, which correspond to different slope levels. The new data layer simply identifies each combination of covertype and slope for each pixel. Three land cover types and three slope groups result in 9 combinations. Here we can see that a pixel with a value of 9 indicates the cover type 3 (forest) and slope class 3 (>30% slope), symbolized on the map with the color green.
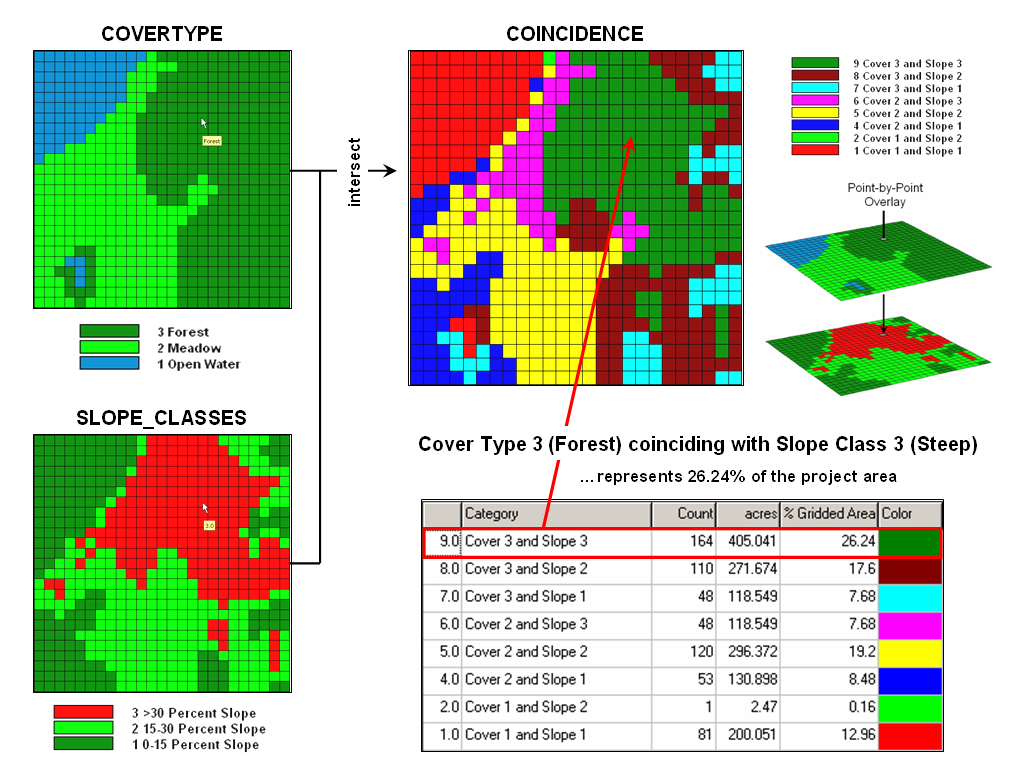
2.2.3 Distance & proximity functions
Distance & proximity functions are operations that use information about the proximity, or nearness, between features. Two popular functions:
Buffer
Near operations
Buffer and Near operations can be applied to both vector and raster data. Here we mainly focus on vector data.
2.2.3.1 Buffer
A buffer creates an area within a user-defined distance of an existing entity/feature. This feature could be a point, a line, or a polygon. Buffers have many uses, for example determining areas impacted by a proposed highway, and determining the service area of a proposed hospital. Buffer can be performed on both raster and vector data. In Figure 12, we create a 60-meter buffer on the road (a line feature), and therefore we can analyze parcels that may be impacted by the road.
After buffering point data, circles are created around each point feature. If you wanted to know how many restaurants are within one mile of our current building, you would create a one-mile buffer area around the point object representing the building, and determine how many restaurants lie within the buffer. If you want to find the air pollution zone caused by the vehicle gas emission along a major interstate, you can construct a buffer zone within 100 meters of a major interstate, which is a buffer around a line. We can also buffer around an area. For example, we can create a conservation zone for all wildlife around a wetlands area.
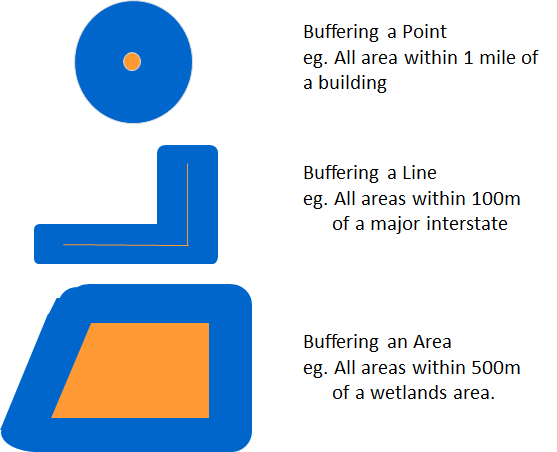
2.2.3.2 Near operations
Near operations can be used to determine the shortest distance (within the search radius) from a feature in one layer to the nearest feature in another layer. For example, you might use "Near" to find the closest bus stops to tourist destinations or the closest stream for a set of wildlife observations.
Figure 14 shows the results of a "Near" operation performed on a point data layer and a river data layer (line features) in ArcGIS. The left figure shows some points near the river, where the points are symbolized using color gradients based on their distance to a river; they are labeled with their distance to the river. If we look at the attribute table, we find the following two fields will be added to the attribute table of the input features:
NearDistance — the nearest distance between the particular point and the river. (Note, one can draw countless lines connecting a point to any point on the river. There is one line that is the shortest representing this nearest distance).
NearAngle — the direction from the particular to the nearest place/point of the river.
Near operations (Figure 15) can be used to find the nearest distance between points, point to line, and point to polygon. The Near Features can include one or more different shape types. For instance, finding the nearest distance from points to lines and polygons, and the nearest distance from lines to polygons and points.
2.2.4 Neighborhood analysis
Neighborhood analysis evaluates the characteristics of an area surrounding a specific location. It is mainly used on raster data.
In a raster dataset, neighborhood statistics are useful to obtain information for each cell based on a specified neighborhood. For example when examining ecosystem stability, it is useful to obtain the variety of species residing in each neighborhood in order to identify locations that are lacking variability in the distribution of species.
In Figure 16, the grid cell (black) is determined by the maximum value of its neighborhood. The neighborhood of a cell is defined as the 8 cells surrounding the cell and the cell itself, which makes a 3 cell x 3 cell window. In this case the maximum value of the neighborhood for the black grid cell is 42. Therefore, in the map showing the neighborhood analysis, the cell of the same location will have the value 42. All grid cells in the dataset can calculate a new value from its neighborhood by moving this 3x3 window and determining the new "local" maximum.
The new value could also be determined by other statistics, such as mean, median, minimum, range, slope, aspect and majority. Figure 17 shows examples of these operations.
2.3 More about spatial analysis
All effective spatial analysis requires an intelligent user, not just a powerful computer. The mathematics and statistics methods used in these operations are only tools to help an analyst investigate data. Interpreting results is the most important step of spatial analysis; human knowledge and expertise is needed to detect patterns. Spatial analysis is best seen as a collaboration between the computer and the user, in which both play vital roles.
Key Terms
data query: access a database and select only the records you want from the attribute table.
Structured Query Language (SQL): a format used to query a database to find attributes that meet certain conditions.
spatial query: a tool that allows selecting features based on their location relative to other features either in the same or another layer, e.g., finding restaurants within 50 miles of your home.
spatial analysis: the process of transforming data into useful information.
map reclassification: reassigning values of an existing map based on the classes or values from a specific attribute.
overlay: when two or more layers sharing the same boundaries (but with different properties/attributes) are combined to create a new map.
intersection: results in a new layer that only contains areas that both layers have in common
identity: an input layer is specified so that all its features will be retained in the new layer, while all the features from an intersection of this layer and a second layer will also be created in the new layer
union: all features from both layers are combined into a new layer
symmetric difference: all features of both layers are retained, except for the areas they have in common (the result of intersection)
map algebra: basic operations such as addition, multiplication, and exponents are used to form equations that combine different raster layers
buffer: creates a new area within a user-defined distance of an existing point, line, or polygon feature
near operation: determines the shortest distance (within the search radius) from a feature in one layer to the nearest feature in another layer
neighborhood analysis: evaluates the characteristics of an area surrounding a specific location/cell/pixel, mostly used in raster data.
Lecture 9-2 Empower Applications with Spatial Analysis
1. Spatial Analysis for Different Data Models
Spatial analysis operations can differ between vector and raster data:
Spatial analysis for vector data
Vector data analysis typically includes buffering, overlaying, and network analysis. We covered proximity (buffer, nearness operations) and overlay functions in the last lecture. Network analysis provides spatial analysis over network-based data (i.e. road network, river network), such as routing, travel directions, closest facility, and service area.
Spatial analysis for raster data
Raster analysis is done by combining layers to create a new layer with new cell/pixel values. In addition to buffering/Proximity and reclassification (covered in the last lecture), terrain analysis (e.g., slope and hillshade calculation) and interpolation are typical raster analyses.
2. GIS Problem-Solving Process: A Practical Example
2.1 Basic GIS analysis process
a. State the problem
b. Collect and edit data
c. Analyze the problem by performing spatial analysis on the data
d. Produce maps for decision and policy makers that show the results of your analysis
2.2 Problem statement
You are a property developer in Cape Town, South Africa and you want to purchase a farm on which to build a new residential development. Your market research shows that the farm needs to satisfy the following requirements:
It needs to be in Swellendam, a small town 2.5 hours west of Cape Town
You don’t want to build any access roads longer than 500 meters. This means that the farm has to be easily accessible from main routes.
The targeted consumers will probably have children, so the farm must be within a reasonable distance (by car) from a school.
The farm must be between 100 and 150 hectares in area.
In the next sections we will solve this problem using two different data models: vector and raster.
2.3 Spatial analysis using vector data
2.3.1 Collecting data
The following data are needed to solve this problem:
DATA1 - FARM: available farms near the city of Cape Town
DATA2 - ROAD: roads that are running through these farms
DATA3 - SCHOOL: location of schools
For this example, the data has already been provided. But in reality you may need to find a provider for the datasets in question.
2.2.2 GIS workflow
First let's decide which operations should be performed and in what sequence. Typically we prepare a GIS workflow diagram to visualize the spatial analysis processes
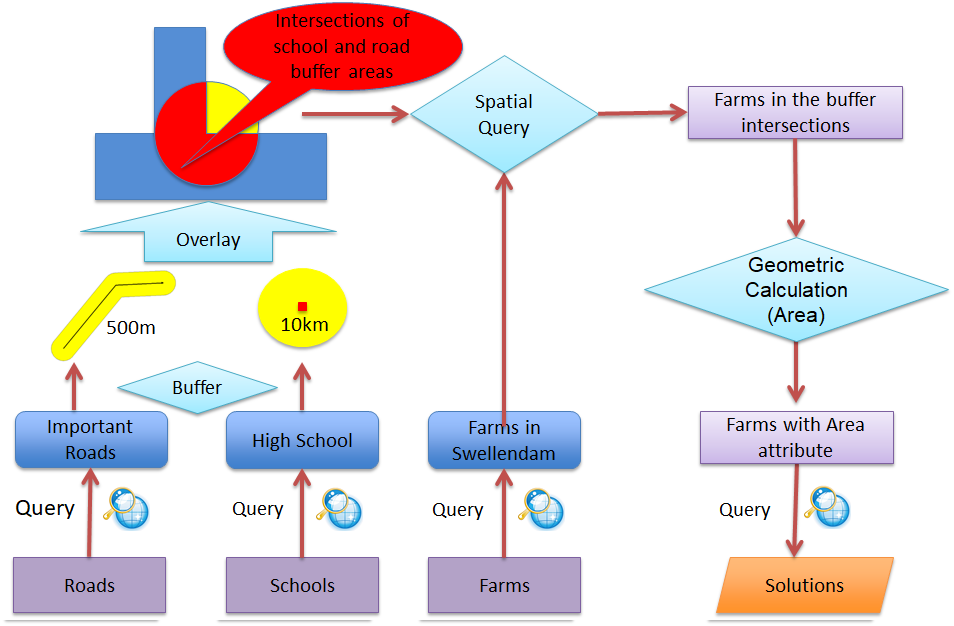
Figure 2 shows the GIS operation workflow on the three vector datasets: road, school and farm.
We need to perform a series of attribute-based queries over those three datasets to identify:
Important roads (main roads) from all types of roads
High schools from all kinds of schools
Farms that are in Swellendam, Western Cape, South Africa (the first criteria)
To ensure that the selected farms are located within reasonable driving distance to main roads and high schools, we create buffers:
500 m buffer for the important roads data layer
10 km area for the high schools
Perform an overlay operation over the two buffer areas to find places within reasonable distance to both high schools and main roads.
Perform a spatial query using two layers: the intersected layer from step 3 and the farms data layer. This selects farms located in the intersections of school and road buffer areas.
Since we need to select farms between 100-150 hectares in size, we have to perform a geometric calculation over the selected farms to find their areas.
Finally we perform a simple attribute-based query to select farms with area greater than 100 and less than 150 hectares (which is our last criteria). This leads to the solutions to our problem.
2.2.3 GIS operations and solutions
Various GIS operations are performed during this vector data GIS workflow:
Attribute-based query helps us select important roads, high schools, and farms based only on their attribute tables.
Buffer is performed over the school and road layers to get their accessible regions.
Overlay is performed to get intersections of school and road buffer zones, and to locate areas accessible to both schools and roads.
Spatial Query is used to select farms within the intersections of school and road buffer areas.
Finally geometric calculations gives us the area of each farm, so we can choose the ones with the right size.
After performing all the operations, we can get our final farms satisfying all three criteria: polygons in the red color (Figure 3). In this final map,
Star-shaped points are high schools
The purple lines are major roads.
The big orange circles indicate the 10km buffer zone for high schools.
The long-tube shape pink polygons along some roads are the 500 meters buffer areas for roads, which are also less than 10 km away from the high schools.
The green colored polygons indicate farms that are within 500 meters of a road and within 10 km of a high school.
The red colored polygons are the final results of selected farms, which are between 100 to 150 hectares in size.
2.3 Finding the best location using raster data
2.3.1 Adding another criterion: slope
So far we have identified several farms that might be suitable based on our three criteria. Let’s add one more criterion to locate the ideal farm:
The perfect farm should be flat enough for residential houses. It needs to have areas with a slope of less than five degrees.
In order to make sure our farm meets this criterion, we need to integrate elevation data, a typical raster dataset. Based on the elevation data we can calculate slope.
2.3.2 GIS Workflow
Let’s see how to select farms that meet the slope criterion (Figure 4).
Collect the Digital Elevation Model (DEM) data representing the elevation for the whole area. A DEM shows the elevation or height of a terrain's surface in the raster format.
Perform terrain analysis over the DEM to calculate the slope for the whole area.
Reclassify the slope layer into two categories: areas with slope more than 5 degrees, and areas with slope equal to or less than 5 degrees. We choose these two categories because our criterion states that the farm must have a slope of less than 5 degrees.
As our previous solution is represented in vector polygons (Figure 3), to combine the raster analysis results we need to convert the raster slope class data to vector data. The resulting vector data layer contains polygons which fall into two categories: slope less than 5 degrees and slope greater than 5 degrees.
Now we have two vector layers: previous solutions (Figure 3) from vector analysis and suitable terrain in vector format. If we overlay our two vector layers we get final solutions that meet all criteria including the slope requirement.
2.3.3 GIS Operations (Raster Data Analysis)
The following GIS operations based on raster data are involved.
Calculate slope from the elevation data. This is know as terrain analysis, which is not covered in this course.
Reclassification of the slope map: reassign grid cells (pixels) with a slope value less than or equal to 5 degree as 1, and those with slope of more than 5 degrees as 0.
Convert raster slope class data to a vector polygon layer.
The following sections show examples of how to perform these operations in QGIS.
2.3.3.1 Calculating the slope
"Slope calculation with DEM (Terrain models)" is a common tool in GIS softwares. The result is a raster data layer with each cell value indicate the slope of the area. In Figure 5, we can see black pixels being flat terrain and white pixels indicting steep terrain.
Then, we reclassify the slope map (Figure 6a) into two categories: slope less than or equal to 5 degrees (value 1 in the result), and slope more than 5 degree (value 0 in the result). Figure 6b shows the Map Algebra used to perform this reclassification. In the raster calculator we enter "slope" <= 5 to define the first class with value equals to 1, and all the other cells would be the other class (value = 0). Figure 6c shows the final result: a two-class raster dataset. We can see that there are only two colors in the figure: black and white. The white areas (value = 1) are flat areas suitable for construction.
Then, we reclassify the slope map (Figure 6a) into two categories: slope less than or equal to 5 degrees (value 1 in the result), and slope more than 5 degree (value 0 in the result). Figure 6b shows the Map Algebra used to perform this reclassification. In the raster calculator we enter "slope" <= 5 to define the first class with value equals to 1, and all the other cells would be the other class (value = 0). Figure 6c shows the final result: a two-class raster dataset. We can see that there are only two colors in the figure: black and white. The white areas (value = 1) are flat areas suitable for construction.
Now we have two vector layers: the previous solutions from vector analysis (red polygons in Figure 3), and suitable terrain in vector format (Figure 7c). After we overlay (intersect) our two vector layers, we get our final solutions as visualized in the final map (Figure 8), with yellow polygons indicating farms that meet all criteria including the slope requirement. In the final map:
The green polygons are areas with a slope less than 5 degrees.
The white polygons with red outlines are farms that meet the first three criteria but are not flat enough for construction.
The yellow polygons with red outlines are the farms that meet all four criteria and are most suitable for residential development.
Key Terms
GIS workflow: a diagram used to illustrate the process and flow of geospatial data and spatial analysis. It is a useful framework for solving GIS problems.
Digital Elevation Model (DEM): a typical data model to represent the elevation or height of a surface at the per-pixel level.
Lecture 10 Spatial Statistics & Pattern Analysis
1. Fundamentals of Spatial Statistics
Spatial statistics uses spatial relationships (such as distance, area, height, orientation, centrality and other spatial characteristics) between features to understand distributions and analyze spatial patterns in GIS. Unlike traditional statistical methods, spatial statistics are specifically deployed on spatial or geographic data. This provides us a better understanding of geographic phenomena and causes of geographic patterns.
GIS systems provide a variety of Spatial Statistics tools. For example, Figure 1 shows the set of spatial statistics tools provided in ESRI ArcGIS.
In this lecture, we will look at two types of spatial statistics:
Tools Measuring Geographic Distributions: These identify characteristics of a distribution. They can be used to answer questions like where is the center of a set of features and how they are distributed around that center.
Tools Analyzing Patterns and Mapping Clusters: These tools can describe spatial patterns and enable us to answer questions like “Are features random, clustered, or evenly dispersed across the study area?”
Note: spatial statistics tools mainly deal with points, lines, and polygons in vector data sets.
2. Measuring Geographic Distributions
An example: we have 7 parks in a city (Figure 2). Given this map, we want to answer these questions:
Where is the center of the 7 parks?
How are these parks distributed around the center?
What's the optimal location for a fire station which allows fast access in case of an emergency in these parks?
To answer those two questions we use tools like Mean Center, Median Center, and Standard Distance.
2.1 Mean center
The easiest way to locate the fire station is to place it at the mean center of all parks. The mean center is the “average” position of the points. To get this position mathematically, we need to calculate the average x and y coordinates of all sites.
In Figure 2b, the (x,y) coordinates of all 7 parks (blue crosses) are given in the map. The average x coordinate is the sum of all x coordinates divided by the total number of points n. In this case, n = 7, since we have 7 parks total.
Average x coordinate = (580 + 380 + 480 + 400 + 500 + 550 + 300)/7 = 456
Similarly, the mean center of Y would be calculated by the sum of all y coordinates divided by the total number of points n.
Average y coordinate = (700 + 650 + 620 + 500 + 350 + 250 + 200)/7 = 467
These equations give the Mean Center coordinate of all parks: (456,467). It's shown as a green cross on the map in Figure 3.
2.2 Median center
Another way is to place the fire station at the median center of all parks. The median of a list of numbers is the middle one if these numbers are sorted from lowest to highest. To get the median center, we will sort get the medians of the x and y coordinates separately.
In the 7 parks example, the median of all x coordinates is: 480.
x coordinates (ascending order): 300 380 400 480 500 550 580
The median of the y coordinates is 500.
y coordinates (ascending order): 200 250 350 500 620 650 700
Therefore, the median center is (480, 500).
2.3 Standard distance
Both the mean center and median center are measures of the central tendency, which provides answers to the fire station locating question. To understand how these parks are distributed around the center we use Standard Distance (SD).
Standard Distance (SD) is the most common way to measure the dispersion of point distributions. It can measure the degree to which points are concentrated or dispersed around the mean center. SD is calculated using the following formula:
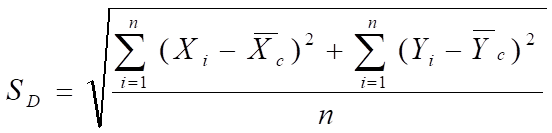
The left side of the numerator is the sum of the mean squares of the distance of each point to the mean center in the X direction. The right side is the sum of the mean squares of the distance of each point to the mean center in the Y direction. After adding the two sums together, dividing by the total number of points n, and taking square root, it would give us the standard distance.
Now, back to the 7 parks example, we have calculated the mean center as (456, 467). Therefore, X̄c = 456, and Ȳc = 467. The table in Figure 4 shows the process of calculating the standard distance of the 7 parks. The rows correspond to the 7 parks. The second and the fifth columns are the x and y coordinates respectively.
Subtraction: In the third column, we subtract the mean X coordinate (X̄c) from each of the X in the second column. Similarly, we also subtract the mean Y coordinate (Ȳc) from the Y coordinates.
Square: The squares of these subtractions are shown in the fourth and seventh columns.
Sum up the squares for X and we get around 59971 (the red number in the ninth row). Similarly, sum up the squares for Y and we get 244342.9.
Finally, add the two sums of squares up, divide the total by 7 ( the number of parks), and apply a final square root. This step is shown as an equation at the bottom of Figure 4.
After the above processes, we get an SD of our 7 parks of 208.5. This means the average distance between the parks and the mean center is about 208.5.
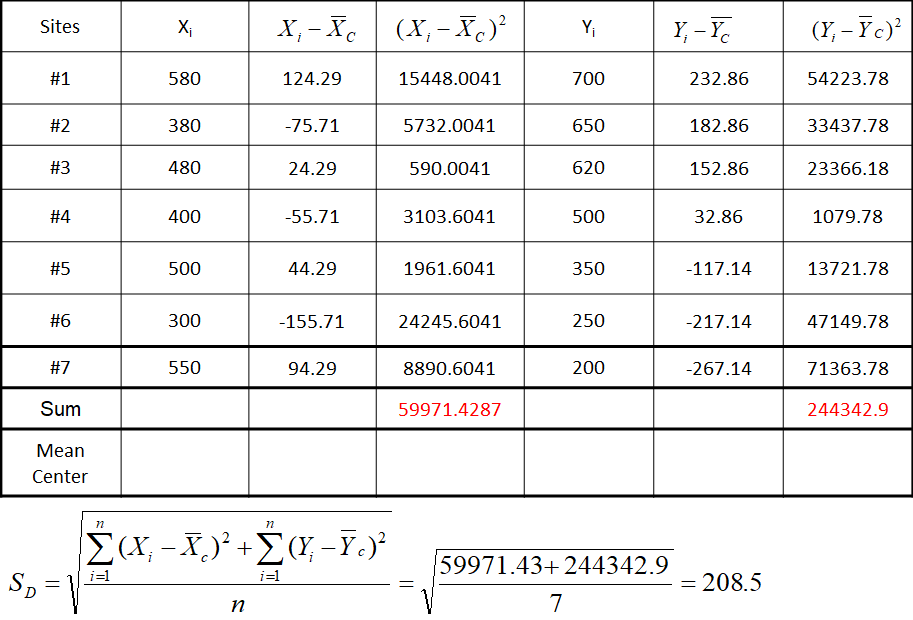
3. Analyzing Spatial Patterns
3.1 Characterizing spatial patterns
Spatial patterns of features can reveal underlying causes of distributions, which help decision making. Some common questions are:
Are the features distributed randomly?
Are some locations more likely to contain features than others?
Does the presence of one point make it more or less likely for other points to appear nearby?
There are three major ways in which features can be arranged:
Clustered: Features are concentrated in one or a few relatively small areas and form groups, and the presence of one feature may attract others.
Regular: Features are consistently spaced and regularly arranged.
Random: Features exhibit no apparent order in their arrangement. There seems to be some clustering and some regularity, but not enough to distinguish the pattern as clustered or regular.
Take Figure 6 for example: what is the pattern of the points? Note that human brains can almost always find spatial patterns, even when these patterns in the data do not exist!
These points were created using the random data generator in QGIS. So these data are completely random. But I think all of us would agree that we could see, perhaps some clusters and some empty spaces. Our brain can recognize patterns and find meanings from them, but in reality no patterns exist in these data.
We need spatial statistics methods to objectively quantify how random these data are. Are they random, or they are clustered?
A couple of quantitative methods measure the degree to which features are clustered, regularly, or randomly distributed across the study area. These include Average nearest neighbor, High/low clustering, Multi-distance spatial cluster analysis, and Spatial autocorrelation.
In this lecture, we will focus on the last one - Spatial autocorrelation (Moran’s I).
3.2 Spatial Autocorrelation
3.2.1 Positive and negative spatial autocorrelation
Spatial autocorrelation describes the similarity of a variable (such as house price) at different locations across space. It is one of the most widely used measures of the degree to which point features are clustered together (positive spatial autocorrelation) or evenly dispersed (negative spatial autocorrelation).
If there are some patterns in the spatial distribution of a variable, it is said to be spatially autocorrelated. Positive spatial autocorrelation means geographically nearby values of a variable tend to be similar: high values tend to be located near high values, medium values near medium values, and low values near low values. Demographic and socio-economic characteristics, such as population density and house price, are good examples of variables exhibiting positive spatial autocorrelation; expensive houses tend to be located near other expensive houses. Negative spatial autocorrelation describes patterns in which neighboring areas are unlike, or where dissimilar values tend to be together.
To illustrate these concepts, Figure 7 shows three synthetic examples. In the left most image, a clear separation and clustering of dark cells and white cells shows an extreme case of positive spatial autocorrelation. In the right most image, a check board pattern is a case of negative spatial autocorrelation where dissimilar values are next to each other. However, in the middle image where no clear pattern can be found, there is no spatial autocorrelation.
3.2.2 Measuring spatial autocorrelation: Moran’s I
There are a number of general measures of spatial autocorrelation, such as Moran’s I, Geary’s C, Ripley’s K, and Join Count Analysis. The most widely used one is Moran’s Index (Moran's I).
Moran's I is one of the oldest indicators of spatial autocorrelation. It is a standard for determining spatial autocorrelation based on both feature locations and feature attributes. Given a set of spatial features and an associated attribute, Moran’s I evaluates whether the pattern expressed is clustered, dispersed, or random.
Moran’s I varies from +1.0 for perfect positive correlation to –1.0 for perfect negative correlation. If Moran’s I equal to 0, it means a random pattern, indicating geographically random phenomena and chaotic landscapes (Figure 9):
A chess board (Figure 9 left) is an example of the negative spatial autocorrelation: black and white cells are intermixed, with every black cell (high value) adjacent to white cells (low value). This indicates that all the neighbors are not similar. The Moran's I statistic for the chess board is -1, giving us an almost perfect negative autocorrelation.
In the middle picture of Figure 9, black cells cluster with black cells, and white squares cluster with white squares. The Moran’s I value would be close to 1, a nearly perfect positive autocorrelation.
In the right picture of Figure 9, there are some areas negatively autocorrelated (with black and white cells intermixed) and some areas have same colored cells clustered. Therefore, in the end, Moran’s I is equal to zero. There is no spatial pattern in this map.

Key Terms
Spatial statistics: a method in GIS that uses spatial relationships (such as distance, area, height, orientation, centrality and/or other spatial characteristics of data) between different features to understand spatial distributions and analyze spatial patterns.
Geographic distribution: the arrangement of features on Earth's surface.
Mean center: a single x,y coordinate value that represents the average x-coordinate value and the average y-coordinate value of all features in a study area.
Median center: a single x,y coordinate value that represents the median x-coordinate value and the median y-coordinate value of all features in a study area.
Standard distance: a measure of the dispersion of features around their mean center.
Spatial cluster: spatial features that are concentrated in one/a few relatively small areas and form groups.
Spatial autocorrelation: describes the similarity of a variable at different locations across space.
Moran's Index (Moran's I): a standard measure of spatial autocorrelation which varies from -1 (perfect negative correlation) to 1 (perfect positive correlation).
Lecture 11 Making a Map with GIS
1. What is a Map?
1.1 Definition
A map is an essential and distinctive tool for geographers to present spatial data and phenomena. Here is a common definition of a map:
“A graphic depiction of all or part of a geographic realm in which the real-world features have been replaced by symbols in their correct spatial location at a reduced scale.”
On maps, a road in the real world is represented by a line (Figure 1). The line is a symbol which has no meaning without a legend and interpretation by the user. Mapping is more complicated than taking the final product of a GIS analysis, giving it a legend and a title, and hitting "print." There are many design considerations that should be taken into account to produce a good map.
1.2 Map elements
Map elements are the building blocks of maps. Figure 2 is a simple map showing ecological zones of Joshua Tree National Park. We can see it includes elements like a title, the source of data (credits), scale, and symbols. These are the elements that comprise a map.
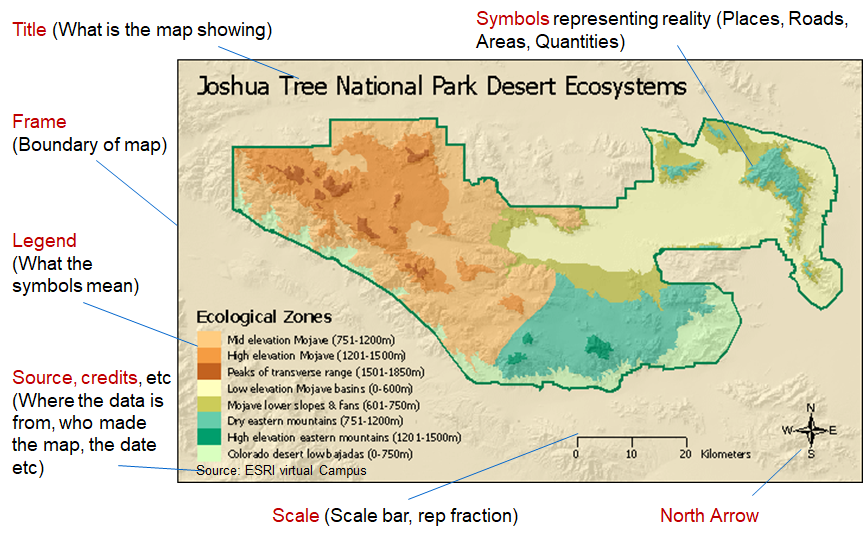
Making sure that all map elements are properly applied is important; it ensures the information contained in the map is clearly conveyed to readers. Most maps have a concise title, an explanation of the map's scale, and a north arrow. Choice in map orientation (portrait versus landscape) and placement of map elements are also important to the visual appeal of the map.
1.2.1 Title/Subtitle
All maps should have a title which describes the content of the map. The title usually conveys the following information:
What is the content of the map?
Where is the geographic area?
When did the geographic phenomenon or event occur?
The title should be the biggest text on the page. Sometimes a smaller subtitle is used to provide more information.
Figure 3 is a map depicting the 2008 U.S. presidential election results. It is titled "United States Presidential Election 2008" which indicates the content. The smaller subtitle indicates that the vote results are county-level data collected on Nov 6, 2008. This text tells you what you need to know about the content of the map.
1.2.2 Projection
The projection used to create a map influences the representation of area, distance, direction, and shape. These characteristics are important to the interpretation of the map.
Including projection and coordinate system information is especially important when someone else wants to combine your map with other data in GIS. Figure 4 is a map showing unemployment rates vs. suicide incidence in the U.S., and the text in the top right says it is in the North American Equidistant Conic projection.
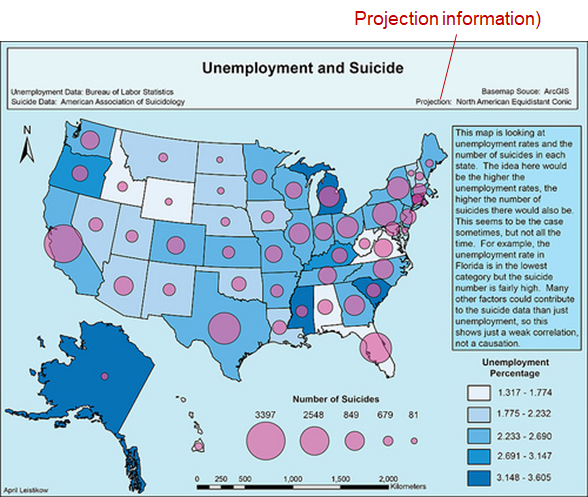
1.2.3 Legend
The legend tells the reader what the symbols and colors on the map represent. A symbol is a picture on the map that represents something in the real world. Maps use a legend to explain the meaning of each symbol used in the map.
The legend usually includes a small picture of each symbol used on the map along with a written description of its meaning. In Figure 4 there are two legends: the one on the right bottom corner means that the map uses different colors to show the unemployment rate of each state. The legend at the middle bottom of the map indicates that on top of each state, circles with different sizes are used to illustrate the number of suicides within each state. Another example can be found in Figure 5. The top left legend and the bottom legend show how air temperatures and precipitation levels are represented by colors. The top right is a legend for a map showing per-pupil public education expenditure.
1.2.4 Source and credits
Maps may also include some information related to the sources and credits of the map, such as:
Data sources and citations (i.e., data source: UN World Fact Book)
The map makers and the date of creation
Disclaimers and legal information
Map series information
Copyright and use issues
Unless it is absolutely clear from the context in which a map appears, readers will need to know the sources from which the map's information was derived. One must identify the sources so readers can check the original information. Often the timing, accuracy, and reliability of sources are critical to the interpretation of a map and should be noted. Sometimes it is also important to indicate how the data was processed, grouped, generalized, or categorized.
1.2.5 Direction indicator
A map's direction indicator is usually displayed as a North arrow or graticule. A directional indicator should be used 1) if the map is not oriented north, and 2) the map is of an area unfamiliar to your intended audience. Directional indicators can often be left out the map if the orientation is obvious.
If North is not a constant direction (i.e. the map covers a large area as in Figure 6), a graticule or grid can be used to indicate direction since the lines of longitude (meridians) run north to south and the lines of latitude run east to west.
Most of the time in medium to small-area maps, a single north arrow is enough to indicate direction. In Figure 4 you'll see a simple north arrow at the top left. There are many directional indicators of different styles available in a GIS software package (such as ESRI ArcGIS, Figure 7). If a north arrow is included, one should avoid making it too large or too elaborate.
1.2.6 Scale
Every map should tell the reader its scale. To represent scale on the map, we can choose from different styles such as a verbal scale, a representative fraction, or most commonly, a graphic scale. The choice of scale will influence how much information the map can contain and what symbols and features can be used to create the map. Please review "Lecture 6 - Map Scale" to review the concept of map scale.
1.2.7 Inset
Some maps have insets — smaller maps on the same sheet of paper. Inset maps can be used to show more detail or to show a larger region that isn't shown on the main map. For spatial informations that cannot fit in the same spatial context, we need an inset to either scale down or scale up.
Scale-down inset
The left figure in Figure 8 shows a map of Tennessee. However, the reader may not know where that state is. Therefore an inset map of the U.S. is shown at the bottom left corner with the same shading. This is called a scale down inset: an inset which zooms out to show the location of the main mapped area.
Scale-up inset
The scale-up inset is the opposite. For example, a map of Manhattan is quite often an inset in a map of New York City because it shows a lot more detail that we can't get from the main map. Figure 8 (right) shows a population map of California with a scale-up inset showing more detail for the San Francisco bay area.
1.2.8 Label
A label is a piece of text attached to the map’s features. GIS packages typically allow you to label map features: adding things like the names of rivers, roads or cities to the map using an automatic placement tool or allowing you to move and place individual labels.
Labels should follow a strict set of rules. Point, line, and area features have difference placement rules. For example, as shown in Figure 9, point labels should be placed above and to the right of point features. Line labels should follow the direction of the line, and curve along with the line if necessary. Area labels should be placed on a gently curved line following the shape of the feature
In summary, almost maps must include certain basic elements that provide the reader with critical information. Some elements are found on almost all maps no matter the type, while others depend heavily on the context in which the map will be read.
These are elements found on virtually every map:
Scale
Direction Indicator
Legend
Sources Of Information
Essential elements that are sensitive to context and included on most maps:
Title
Projection
Cartographer
Date Of Production
Elements that are used selectively to assist in communication:
Neatlines (a neatline is merely the boundary separating the map from the rest of the page)
Inset
2. Mapping Spatial Data in Six Steps
2.1 Choose a map type
The first step is to choose an appropriate map type. Map types are methods cartographers designed for cartographic representation.
In the 3000-year history of cartography, cartographers have designed numerous ways of showing data on a map. We have introduced reference maps and thematic maps, but these categories can be further divided into different map types. For example reference maps include a variety of map types that show the boundaries and names of geographic areas. There are different types of thematic maps, such as choropleth maps and cartograms. (We will introduce thematic maps in the lecture on thematic maps).
There is not a single GIS package/software that supports all map types. For example, if you want to create a 3 dimensional map, many GIS software would be unhelpful. Fortunately, most GIS tools do support the design of several basic map types. The same data can be mapped by different methods. Choosing the correct method requires understanding what you are mapping and your goals for the map.
2.2 Choose a layout & a template
In GIS, a map is put together by assembling all of the elements together in a layout. A good way to think of a layout is a digital version of a piece of paper with all map elements arranged on it. Choice of map layout, such as direction of the page (portrait versus landscape) and placement of map elements affects the visual results of the map.
GIS software usually includes several map templates which are pre-created designs. Just like how PowerPoint gives you presentation templates, you can select a pre-designed map template in most GIS software.
Using a template will take your GIS data and place elements like the title, legend, and north arrow at pre-determined locations and sizes on the layout. Templates are useful to create a quick printable map layout, but GIS software will also allow you to design a map from scratch.
2.3 Display attributes on the map
A layer’s attributes are usually displayed as information on the map. For example, to create a map of the 2008 U.S. presidential election results by State (Figure 10), each polygon representing that State would have an attribute designating whether Barack Obama or John McCain had a higher number of votes for that State (red states were won by McCain, blue states were won by Obama).
2.4 Classify data
More than often, the attributes are not simply two choices (as in Figure 10 where each county is marked either Obama or McCain). Attributes such as the percentage of colleges and universities per state are numerical data, having a wide range of values. In order to best display such data on a map, data classification is required.
Before we make a map we need to classify the attributes into categories. Data classification is the process of arranging data into a few classes or categories to simplify and clarify presentation. Each class can be represented with different symbols and colors. There are two purposes of classification: 1) to make the process of reading and understanding a map easier; 2) to show attributes or patterns that might not be self-evident.
Figure 11 shows a classification of the world's population density. The density figures range from 0 to more than 1,000. We thus classify them into nine categories when displaying them on the
map.
GIS software typically gives several options for data classification. However, each method classifies data differently and can result in very different representations on the map. Therefore, we need to use the optimal method based on data, desired output and goals of the maps.
There are four typical methods of data classification available: natural breaks, quantile, equal intervals, and standard deviation. Figure 12 shows four different maps which use different classification methods based on the same data to show the percentage of seasonal homes in each state. Note that the number of classes or categories is the same (four) for each map.
Natural Breaks
The Natural Breaks method takes all the values and looks at how they’re grouped together. This method identifies breakpoints between classes using a statistical formula, which minimizes the variance within each of class and maximizes the differences between classes. In this way, Natural Breaks finds groupings and patterns inherent in your data. For example, in Figure 12a, states with the lowest percentages of seasonal homes values (such as Nebraska, Oklahoma, and Texas) end up in one class, and states with the highest percentages of seasonal homes (such as Maine, Vermont, and New Hampshire) end up together in another class.
Quantile
The quantile method tries to distribute values so that each range has a similar number of features in it. For instance, with 51 states being mapped (plus the District of Columbia as a 51st area), each of the four groups will have ~13 states in each class. Since the break points between the ranges are based on the total number of items being mapped, rather than the actual data values being mapped, the Quantile method causes a relatively even distribution of values on the map.
Equal Intervals
The Equal Interval method (shown in Figure 12c) creates a number of equally sized ranges of values and then splits the data values into these ranges. In the seasonal home maps, the data is divided into four classes, and the range of values goes from the state with the lowest seasonal home percentage (0.6% of the total housing stock in Illinois) to the state with the highest seasonal home percentage (15.6% in Maine). Equal Interval takes the complete span of data values (15% = 15.6% - 0.6% in this case) and divides it by the number of classes (in this case, four), and that value (in this case, 15% / 4 = 3.75%) is used to compute the break point between classes. So the first class represents states that have a seasonal home value of 3.75% more than the class’ lowest end (for instance, the first class would have values between 0.6% and 4.35%). Note that this method simply classifies data based on the range of all values (including the highest and lowest) but does not take into account clusters of data or how the data is distributed. As such, only a few states end up in the upper class because their percentages of seasonal homes were greater than three-fourths of the total span of values.
Standard Deviation
A standard deviation is a value's average distance from the mean (average) of all values. In the standard deviation method, the breakpoints are based on these statistical values. For example, in Figure 12d, the GIS software calculated the average of all United States seasonal home values (3.9%) and the standard deviation (3.1%). These values are used to set up the breakpoints. The breakpoint of the first range is a half of the standard deviation value lower than the mean: mean minus 0.5 times the standard deviation (3.9% - 0.5 * 3.1% = 2.34%). The fourth range consists of those counties with a value greater than 1.5 times the standard deviation away from the mean. The other ranges are similarly defined by the mean and standard deviation values of the housing data.
Each method classifies data differently and can result in very different results displayed on the maps. Figure 13 shows six different maps of the percentage of foreign born Florida residents. Each of the maps was created using a different data classification technique. Note that each map has the data broken into the same number of classes (six).
Quantile method: each class contains the same number of features.
Equal interval method: divides the range of attribute values into equal sized sub-ranges. The features are then classified based on those sub-ranges.
Standard deviation method: identifies breakpoints between classes using a combination of mean and standard deviation.
Natural Breaks method: finds groupings and patterns inherent in your data. It minimizes the sum of the variance within each of the classes to make them more unique.
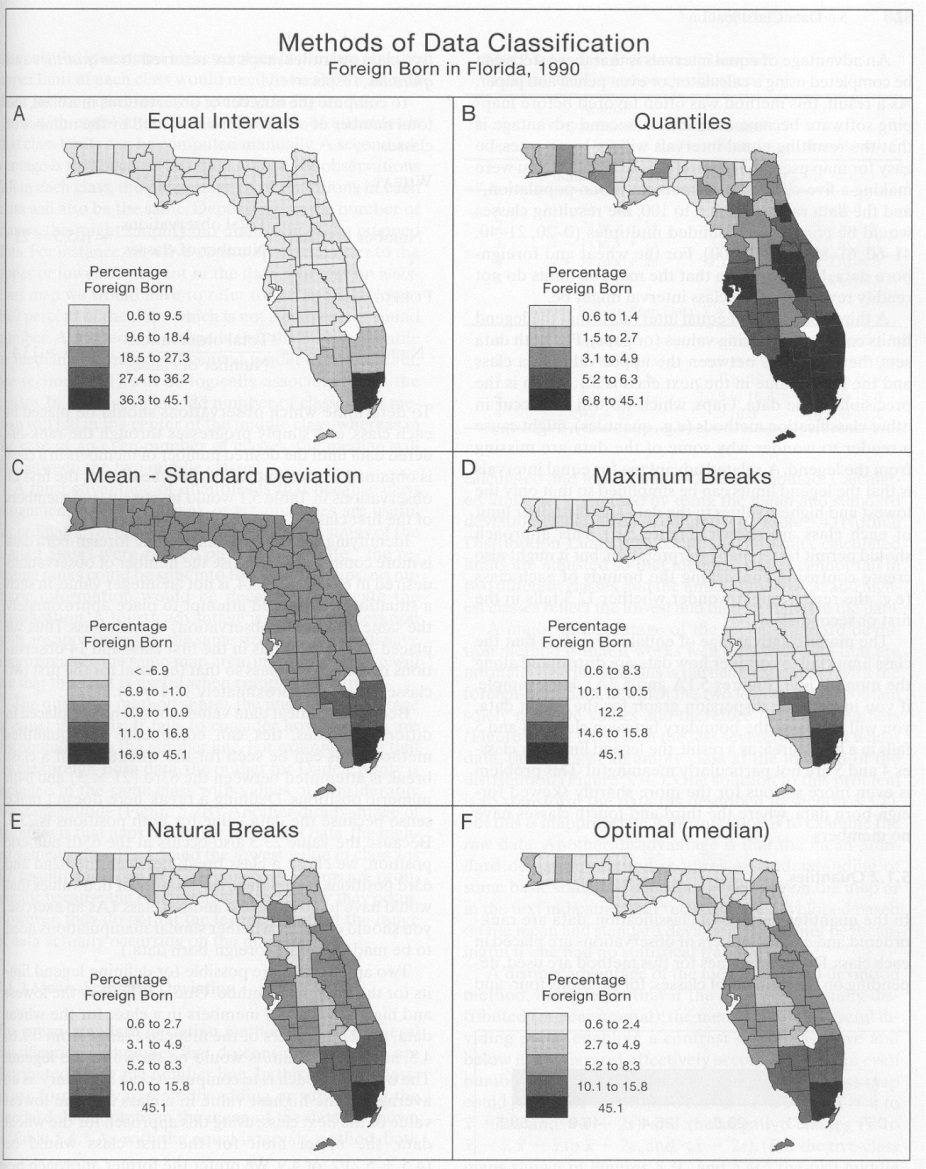
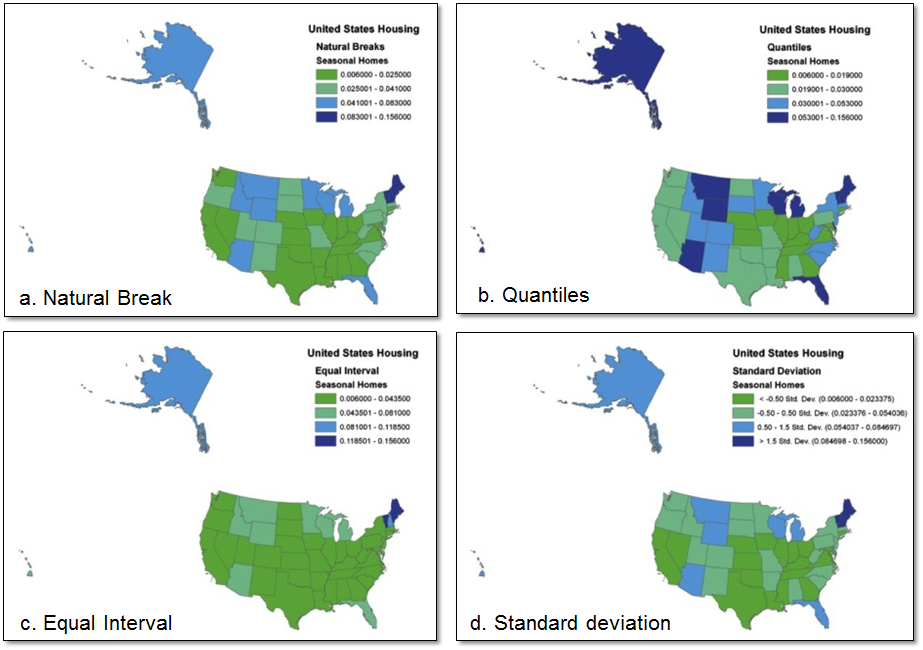
2.5 Symbolize the data
Symbolization is the process of choosing symbols to represent features, attribute values, or classes of attribute values. The most important requirement for map symbols is that they should be readily recognizable and suited to the scale of the map. In cartography, the ways in which a symbol can vary (which are often called visual variables) includes shape, size, and color. We can use symbols with a specific combination of shapes, sizes, and colors to represent anything on a map (Figure 14).
Shape: Map symbols with different shapes imply differences in quality or type. Sometimes map symbols are designed to reflect the characteristics of the features. For example, a map showing the location of clinics uses a cross symbol. Crosses remind us of clinics and hospitals. A map showing the location of airports uses an airplane symbol. Rivers and roads are represented by lines.
Size: We can use symbols with different sizes to intuitively suggest differences in quantity or degree. For example, a map showing the location of houses can use differently-sized circles to indicate the size of the houses; a big circle means a big house.
Color: The choice of color is important to making an attractive map, and different colors can also indicate changes in quantity. For example we can use green, yellow and red to indicate small, medium, and large (Figure 14). Just like in Figure 5, we use colors from purple to red to indicate low to high air temperature.
3.6 Export the map
Once a map has been designed and formatted, it is time to share it. There are several formats in which a map can be distributed; two common formats are JPEG (Joint Photographic Experts Group) and TIFF (Tagged Image File Format).
Images saved in JPEG format can experience some data loss due to the file compression involved. Consequently, JPEG images have smaller file sizes.
Images saved in TIFF format have a much larger file size but are a good choice for sharper, more detailed graph
Key Terms
map: a graphic depiction of all or part of a geographic realm in which the real-world features have been replaced by symbols in their correct spatial location at a reduced scale
legend: a guide to what the map's symbols represent. It usually includes a small picture of each symbol used on the map along with a written description of its meaning.
directional indicator: an element showing the direction of the map which usually comes as a north arrow or graticule
inset: smaller maps used to reveal details not shown on the larger map
label: a piece of text attached to map features
reference map: a type of map that emphasizes the geographic location of features
thematic map: a type of map designed to show a particular theme connected with a specific geographic area
map layout: a collection of map elements laid out and organized on a page
data classification (mapping attributes): the process of arranging attribute data into a few classes or categories to simplify and clarify presentation
symbolization: the process of choosing the symbols (a combination of shape, size, and color) to represent features, attribute values, or classes of attribute values
Lecture 12 Thematic Maps I - Qualitative and Quantitative Data
1. Map Types
Reference maps show the simplest properties of geographic features in a specific area, such as political boundaries, roads, water bodies, and cities. One example of a reference map is a world map, which shows the boundaries of continents, oceans, and countries, their names, as well as important water bodies (Figure 1).
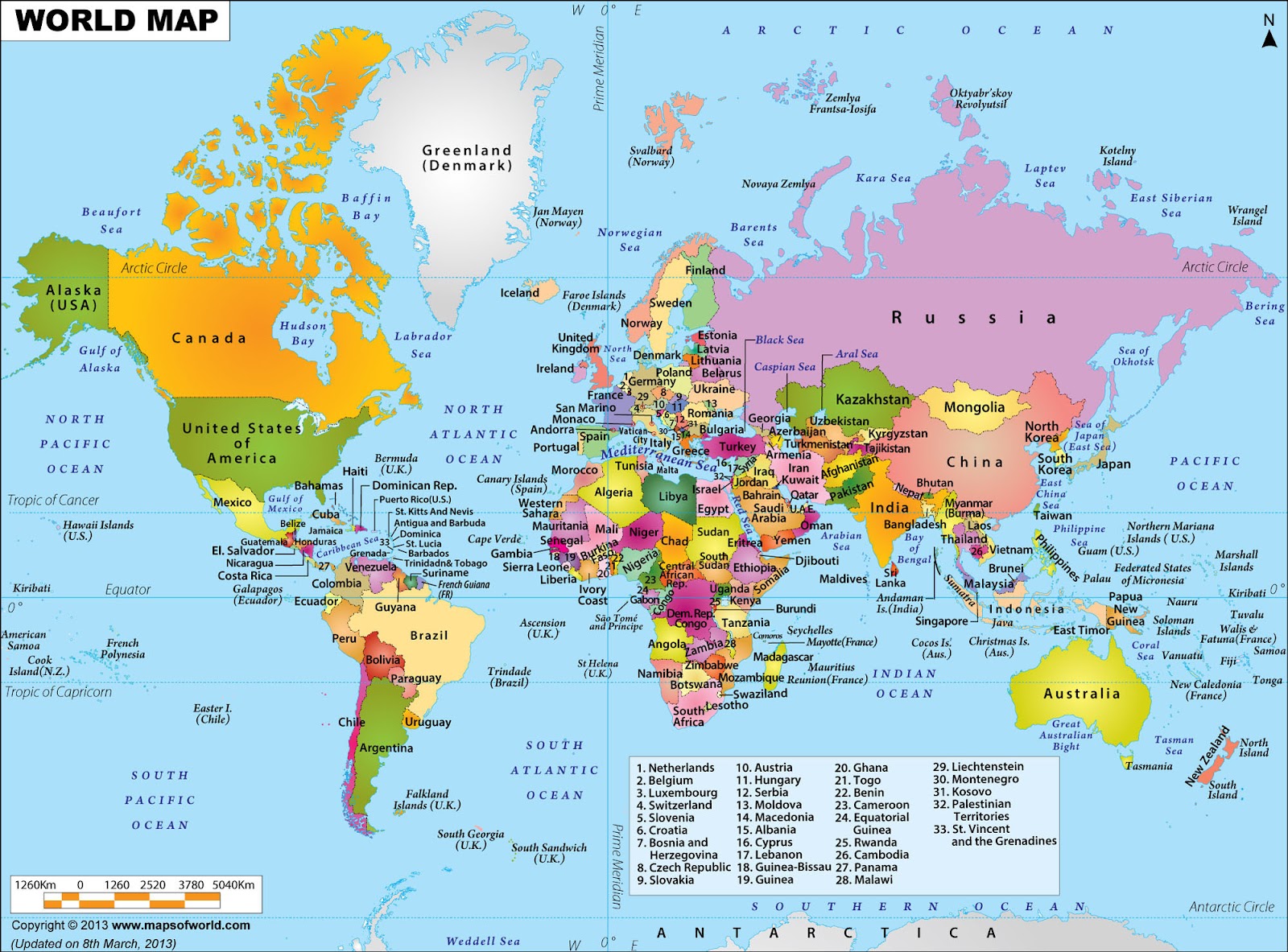
One of the most commonly used reference maps is a topographic map. A topographic map shows topological features including terrain elevation, water networks, boundaries, roads, towns, cities, and labels showing the names of important features. For example, Figure 2 is a 1:62,500-scale topographic map of Madison from 1940. The brown irregular curves are contour lines that represent changes in the terrain's elevation. The blue lines and patterns shows water features such as lakes, swamps and streams. Some important features like the big lakes and towns are labeled with their names.
A thematic map is another type of map that shows one or a few themes of information for a specific area, which is often coded, colored, or grouped for convenience. These maps usually describe the physical, social, political, environmental, and cultural properties of defined area. For example, the left panel in Figure 3 shows U.S. poverty levels in 2010; it does this by coloring counties by the percent of people under the poverty line.
2. Geospatial (GIS) Data
2.1 Overview
Maps are used to display data, both spatial and non-spatial. A good map lets data speak to the reader in an attractive way. Before we go further into the art and science of map making, we need to understand data itself.

"Phenomena are all the stuff in the real world. Data are records of observations of phenomena."
Maps show us data, not phenomena. Therefore, carefully think about the data you're mapping; it is important to think about how the data relates to real world phenomena and how the interpretation of the data affects our understanding of the phenomena. There are many ways to classify data, each of which emphasizes a specific aspect of the data:
Classify based on how the data is organized in digital format (Figure 4)
Vector or raster data
Classify based on what kind of geographic phenomena the data represents:
Continuous or discrete data
Point, Line, Area, or Volume data
Classify based on how the data defines or describes the geographic phenomena:
Qualitative or quantitative data
Classify based on levels of measurement. Here a measurement level describes the nature of numerical information about geographic features.
Nominal, ordinal, interval, or ratio data
2.2 Point, Line, Area, or Volume data
Geographic data can be categorized the physical shape/dimension of geographic phenomena, such as point, line, area and volume. For example, a point phenomenon is something that occurs at a point in space defined solely by a geographic location without width or area at the scale of the map. We can use point data to depict point phenomena.

Point phenomena describes things like houses or cities, which may be too small to be represented by areas or polygons on a map for a given scale. For example, in a world map of major cities, each city is represented as a point (Figure 6).
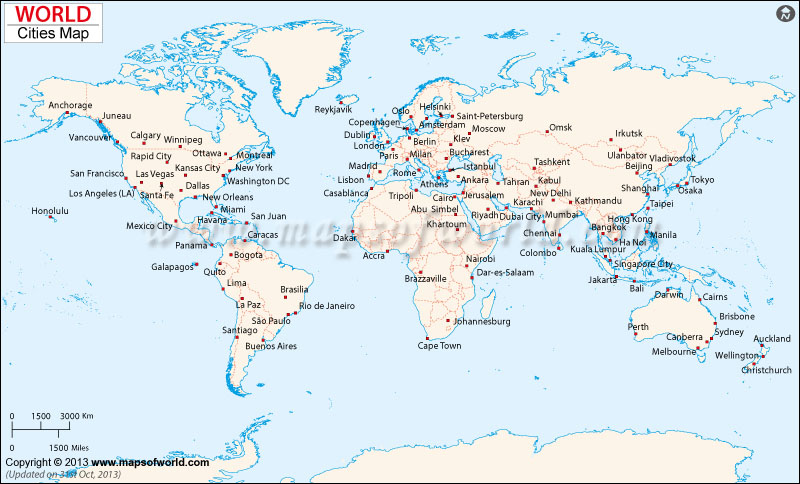
Line phenomena describes features that follow a line without a defined width at a certain scale. A river or road map are good examples of line phenomena (Figure 7).
Area phenomena occupies an area on the map, such as houses, forests, lakes, counties, and even buildings at a large enough scale. For example, in Figure 3, counties are areas/polygons.
Volume phenomena occupies a volume in space (including length, width, and depth) at the scale of the map. Examples include mountains and ocean trenches.
Note that the classification of geographic features as point, line, area, volume only matters at a specific scale of the map. Almost everything in the real world is a volume to us; a house, a farm, or a city occupies space. However, those features could be abstracted as points, lines or areas depending on the map’s scale.
For example, a large-scale city map (such as Madison, WI) for reference purpose might show the location and dimension of all the buildings in a city block, or the location of all the churches, social organizations, and bars in an urban neighborhood. However, in a small-scale map of all cities in the U.S., each city is represented as a single point.
2.3 Discrete and continuous
Data describing the geographic phenomena could be discrete or continuous.
Discrete data represents discrete phenomena with distinct boundaries. A district, houses, towns, agricultural fields, rivers, highways are good examples of discrete phenomena. Sometimes discrete data is also called categorical data, which often represents objects. These objects usually belong to a class (for example, soil type), a category (for example, land-use type), or a group (for example, political party). Such objects (categorical objects) have known and definable boundaries. For example, Figure 8 shows a land use map for Chicago in 1950. The land use types, such as development, forest, and agriculture, are discrete phenomena represented with specific colors in bounded areas. Note that discrete phenomena change abruptly, like laws change from one jurisdiction to another. In this example, when agricultural land is converted to urban land, its value in the map changes from agriculture to development directly. There is nothing in between.
Continuous data represent continuous phenomena which have no defined borders, but a smooth transition from one value to another. Examples of continuous surfaces are elevation, aspect, slope, the radiation levels from a nuclear plant, and the salt concentration from a salt marsh as it moves inland. Continuous phenomena, such as air temperature, precipitation, and elevation vary continuously without incremental steps. For example, Figure 9 shows an air temperature map of the U.S. Note that the temperature is a value that changes continuously, i.e. from 66 to 66.01. There is always something in between two values of temperature.
2.4 Qualitative and quantitative
Data can be organized into two broad categories: qualitative (differences in kind) or quantitative (differences in amount). This is a fundamental classification of the GIS data, as each one has distinctive methods of analysis and symbolization.
Qualitative data show the categories of things expressed by means of a natural language description. Examples include land cover types, soil types, language and religion, and major in college. Figure 6 shows qualitative data: the name of major cities of the world. Figure 8 shows another example, which is the land use types across Chicago.
Quantitative data depicts the magnitude (e.g., size, importance) of things, expressed in numbers. Such data can be quantified and verified. Examples include population density and annual rainfall. Figure 3 shows the percent of population in poverty of each county in the U.S., which is expressed as a quantity. Figure 9 shows air temperature, another example of quantitative data.
In a word, qualitative data describes things, whereas quantitative data measures things.
2.5 Level of measurements
The level of measurement is a way to describe the the scaling of data in statistics. There are typically four levels of measurement. They can help us to better understand the nature of the data we are going to map and design the most suitable way of analyzing and displaying it.
Nominal (qualitative)
Ordinal (quantitative)
Interval (quantitative)
Ratio (quantitative)
The first belongs to qualitative data, and the other belong to quantitative data.
2.5.1 Nominal
Nominal data has no order and thus only gives names or labels to various categories. Nominal data consists of categories used to distinguish different types of features. Values in nominal data are used to distinguish one feature/object/phenomena from another. They may also establish the group, class, member, or category with which the object is associated. These values are qualities, not quantities. Classes for land use, soil types, or any other attribute qualify as nominal measurements.
Other familiar examples of nominal data include,
Gender
Religion
College major
Jersey numbers
The values of nominal data are NOT always descriptive. They could be stored as words or a numerical code. For example, social security numbers, zip codes, and telephone numbers are all nominal data. The difference between these numbers and values in quantitative data (such as air temperature) is that these numbers, such as zip codes, have no numerical meaning and are not measurements of anything. They serve the same function as a name.
Nominal data are descriptions for features with no order. For example, jersey numbers in basketball, though numerical, are measures at the nominal level. This number does not imply order or convey quantitative information (size or importance of each category). A player with the jersey number 30 is not more of anything than a player with the jersey number 15. Nominal scales are therefore qualitative rather than quantitative.
Figure 11 gives an example of a map of a nominal data - election results. Based on the legend, we know that there are four nominal values: McCain, Obama, No Returns yet, and Returns available. Each state is assigned to one of those categories.
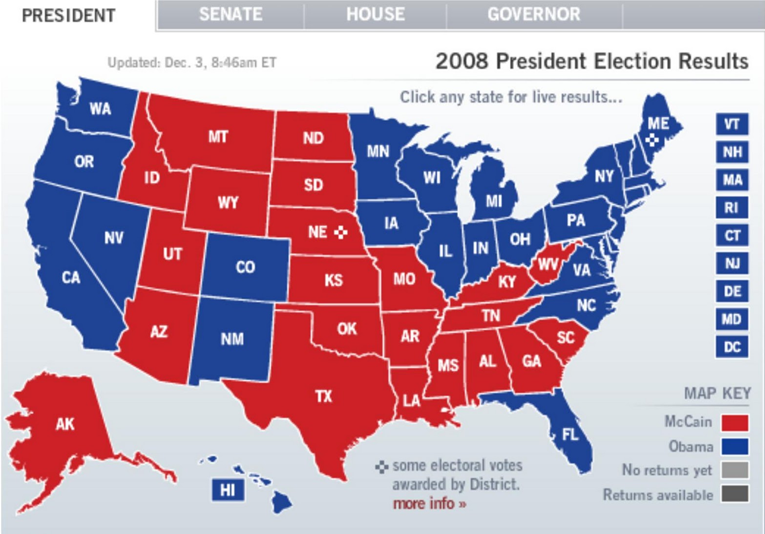
2.5.2 Ordinal
Ordinal data includes values with order, which allows comparisons of the degree between two values. Examples of ordinal data include: scale of tree size (small, medium, and tall), scale of pain (ranked from 1 to 10), movie ratings (one star to five stars), scale of hotness (hot, hotter, hottest), etc..
Ordinal variables have meaningful order, but the intervals or difference between values are not necessarily equal. For example, the gap (Figure 12) between hot and hotter may be small, whereas there might be a big discrepancy between hotter and hottest. Patients are asked to express the amount of pain they are feeling in a scale of 1 to 10. A score of 7 means more pain that a score of 5, and that is more than a score of 3. But the difference between the 7 and the 5 may not be the same as that between 5 and 3. The values simply express an order. There is still no quantifiable numeric difference between the values.
Ordinal values show the position in a rank, such as first, second, and third place, but they do not establish magnitude or relative proportions. How much better, worse, healthier, or stronger something is cannot be demonstrated from ordinal numbers. For example, a runner who was first place in a race probably did not run twice as fast as the second-place runner. Knowing the winners only by ranking place does not mean you know how much faster the first-place runner was compared with the second-place runner. This explains why nominal data is qualitative.
Figure 13 is an ordinal map showing the groundwater productivity for the area around Pohang City, Korea. The ground water productivity ranges from very high to low. Here, we use different colors to indicate different ranks.
2.5.3 Interval
Interval data consists of numerical values on a magnitude scale that has an arbitrary zero point. Those numerical value can order from low to high, with a numeric difference between the classes. Land elevations are an excellent example of interval-level data, since the zero level (datum defined by geoid) is arbitrarily defined as mean sea level.
When looking at interval-level data on a map, know that the numerical intervals (differences) between values are meaningful, but ratios between two values are meaningless.
A good example of an interval scale is the Fahrenheit scale for temperature. Equal differences on this scale represent equal differences in temperature. For example, the difference between a temperature of 30 degrees and 20 degrees is the same difference as between 20 degrees and 10 degrees, where both are 10 degrees lower. However, a temperature of 30 degrees is not twice as warm as one of 15 degrees. You can not say, for example, that one day is twice as hot as another day
Here is another example. A student who scores 90% is probably a better student than someone who scores 45%. The difference between the two scores is 45%. But this doesn’t make the first student twice as smart.
Figure 14 is a map of global annual mean temperature. Temperature is an example of interval data. In addition to being ranked from low to high, temperature also includes numerical values.
2.5.4 Ratio
Ratio data also consists of numerical values on a magnitude scale. However, in contrast to interval-level data, the zero point is not arbitrary. The zero point is clearly defined and typically the zero point denotes absence of the phenomenon.
You will find many thematic maps showing ratio-level data, such as maps showing population density (or any other density), annual precipitation, crime rate, tree heights, tax rate, family income, all of which are ratio-level data. We could have zero crime rate, which denotes a total absence of crime. Therefore ratio-level data have all the properties of interval-level data, but in addition, it also has a natural zero value. When the variable equals 0.0, there is none of that variable.
While ratios are meaningless for interval data, ratios between two values are meaningful for ratio data. Good examples of ratio-level data include height, weight, or measurement of time. A weight of 4 grams is twice as much as a weight of 2 grams; therefore weight is ratio-level data.
Figure 15 shows the population in Florida by county. Since population can have a zero point that indicates a total absence of population, it is ratio-level data.
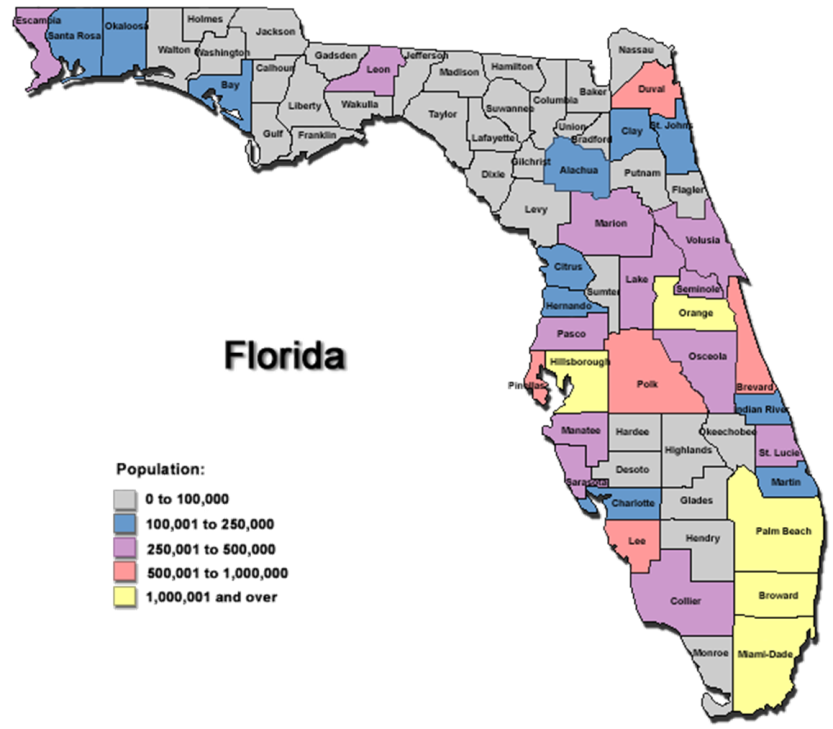
Key Terms
Reference Map: a type of map showing the simplest properties of the geographic features in a specific area, such as political boundaries, roads, water bodies and cities.
Topographic Map: a type of map showing topological features including terrain, water networks, boundaries, roads, towns, cities, as well as labels showing the names of important features.
Thematic Map: a type of map showing one or a few themes of information for a specific area, which is often coded, colored, or grouped for convenience. These maps can portray physical, social, political, cultural, economic, sociological, agricultural, or any other aspects of a specific area, such as a city, state, region, nation, or continent.
Point Phenomenon: phenomenon that occurs at a point in space defined solely by a geographic location without width or area at the scale of the map.
Line Phenomenon: phenomenon that describes a thing that follows a line without width at the scale of the map.
Area Phenomenon: phenomenon that occupies an area on the map; depending on the scale, this could include a house, a forest, a lake, a county, or even buildings.
Volume Phenomenon: phenomenon that occupies a volume in space (including length, width, and depth) at the scale of the map.
Discrete Data: data that represent discrete phenomena or an object with distinct boundaries. These phenomena/objects usually belong to a class (e.g. soil type), a category (e.g. land-use type), or a group (e.g. political party), which have definable boundaries.
Continuous Data: data that represent continuous phenomena which has no defined borders, but which has a smooth transition from one value to another.
Qualitative Data: data that shows the categories of things expressed by means of a natural language description (e.g. words) or sometimes numbers which have no numerical meaning (e.g. basketball jersey numbers).
Quantitative Data: data that portrays the magnitude (e.g., size, importance) of things, expressed in numbers.
Nominal Data: qualitative data that has no order and thus only gives names or labels to various categories.
Ordinal Data: quantitative data that includes values with order, which allows comparisons of the degree between two values.
Standard deviation cannot be calculated
Interval Data: quantitative data that consists of numerical values on a magnitude scale that has an arbitrary zero point. Those numerical values can order from low to high with a numeric difference between the classes, but with no absolute value for the numbers and an arbitrary zero point.
Ratio Data: quantitative data that consists of numerical values on a magnitude scale. However, in contrast to interval-level data, the zero point is not arbitrary: there is a clear definition of the zero point. Typically, the zero point denotes absence of the phenomenon.
Lecture 13 Thematic Maps II: Qualitative Map
1. Overview of Thematic Maps
From the last lecture, we know that mappable data can be qualitative or quantitative. Qualitative data shows the types/categories of features, while quantitative data portray the magnitude of features/attributes.
Thematic maps can also be qualitative or quantitative depending on the type of data mapped. Qualitative maps describe the location or distribution of a phenomenon and use nominal and ordinal data. Quantitative maps describe the magnitude or value of a phenomenon and use interval or ratio data.
Figure 1 is a map of the U.S. death rate by county between 1988-1992. According to the legend and title, we can see that this map is displaying ratio-level data. Therefore, this is a quantitative thematic map.
Figure 2 shows another map of the U.S.'s largest ancestry populations by county in 2000. The legend tells us that each county in the map is colored based on the ancestry type that has the largest population in that county. The data is nominal. (Do you know why?) Thus this is a qualitative thematic map.
Based on how many attributes/variables/phenomenon are displayed on a map, thematic maps can either display a single theme or multiple themes.
Single-theme maps depict only one theme (i.e. one attribute) at a time. This means only one column in the attribute table will be displayed on the map.
Multivariate maps depict the geographical relationships between two or more phenomena.
Both single-theme and multivariate maps use points, lines, and areas to display features. In this lecture, we will learn how to use point, line, and area symbols to create qualitative thematic maps.
2. Single-theme Maps
2.1 Graphic elements/visual variables for qualitative mapping
Cartographers use different symbols or graphic elements on the map to represent points, lines, and areas features. Certain graphic elements work well for qualitative data because they do not encode magnitude or quantitative information; others, such as color intensity or size, work better for displaying quantitative data.
The visual variables that effectively display qualitative differences are shape, orientation, and color hue (Figure 3).
Different shapes imply differences in type rather than differences in magnitude. A square is different from a circle, but a reader would not assume that a square is more than a circle; it's just different. For example in Figure 3, a house symbol represents a house, while a pickaxe symbol represents a mine. Different types of lines can also represent different kinds of transportation corridors. A shape can also be repeated to create a pattern.
Likewise, orientation can be used to create patterns that show qualitative differences for features. For example, a tree symbol oriented north or east can show whether the tree is dead or alive.
Color hue simply means different colors. Symbols with different hues imply differences in quality or type. For example, we can change the color hue indicate whether a tree is dead or alive; green for live, and brown for dead.
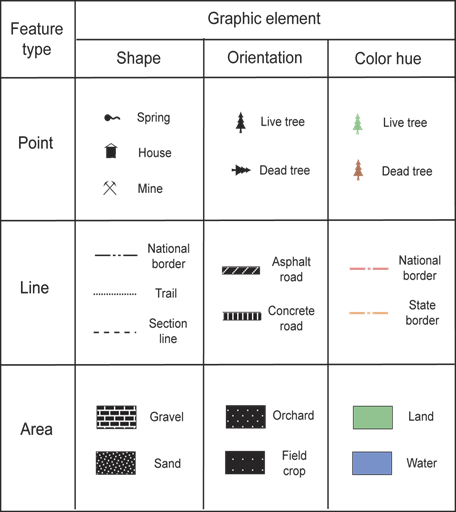
Figure 4 is an example of a single-themed map using color to differentiate forest classes in northwest Oregon. Note that color lightness is also used: the symbols for the first few classes in the legend are greens of different lightness. We usually want to represent the geographic feature in colors similar to how it would appear in the real world. Therefore, trees or forests are usually green.
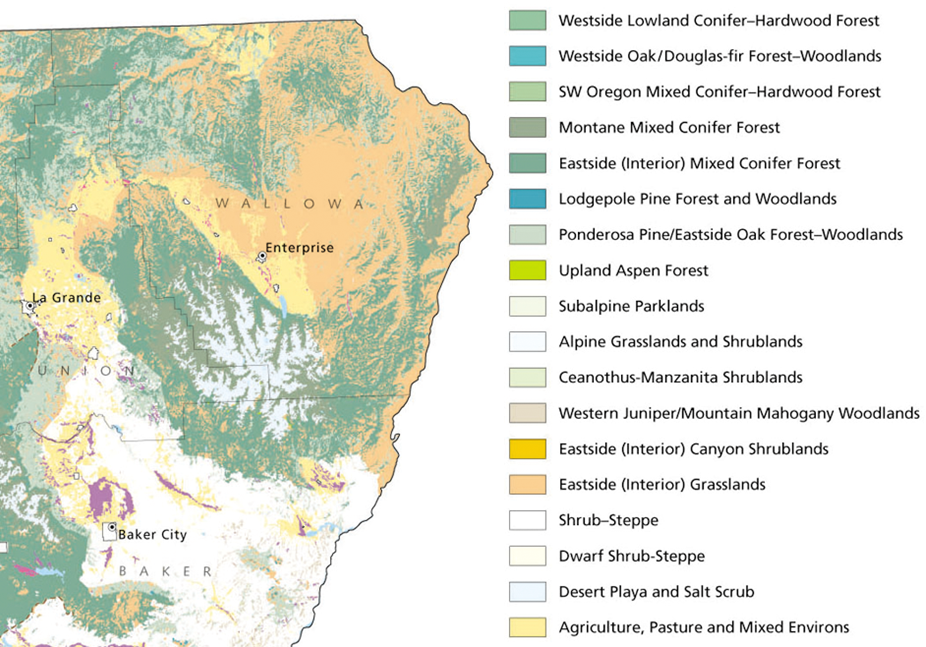
2.2 Point feature maps
Point feature maps use symbols which show the location of an object. The point symbols can be geometric, mimetic, or pictographic (Figure 5).
Geometric symbols use simple shapes, such as squares, circles, and triangles to represent features. As they are simple they usually require a legend to be interpreted correctly.
Pictographic symbols are designed to look very similar to their real-world counterparts. For example, Figure 5 (D) shows a realistic symbol of a house. These detailed symbols immediately remind map readers of the real-world features they are supposed to represent.
Mimetic symbols lie between geometric and pictographic symbols. They are often created from a combination of geometric shapes, such as a square with a triangle on the top to represent a house. Sometimes, they can be more complex, like a small cartoon. These symbols can be both intuitive and simple, and are popular in mapping point features. For example in Figure 5, both B and C are adequate to indicate a house without the complicated colors and textures of D. You will find mimetic symbols on tourist maps, recreational maps, and airport maps.
2.3 Line feature maps
Line features, such as roads, streams, or boundaries can be represented with different line symbols. Appropriate visual variables such as shape, orientation, and color hue can differentiate line features of different types (Figure 8).
Shape is commonly used to distinguish categories of line features. For example administrative boundaries are often shown with dashed lines, and railroads are shown using a solid line with cross-hatches that mimic railroad ties.
Different color hues can differentiate feature categories. We can use colors to show different boundary lines: in Figure 8, a red line means a national border, and a yellow line means a state border. For example, Figure 9 shows a map of railroad line ownership where different owners get different line colors. Some hues have been standardized for certain features. For example rivers are usually shown with blue lines, administrative boundaries are displayed with red lines, roads with black lines, and contour lines in brown.
Typically, variations in both color hue and shape are used to represent a greater variety of line features.
Although line features may have no actual width in the spatial data, the real geographic features they represent usually have an actual width on the ground. For example, a river has width in reality but is usually shown with a narrow line on a map.
Figure 10 is an example of a line feature map: the streams in the Columbia River watershed. The lines do not accurately reflect stream width; the width of the lines actually shows variations in stream flow, not the actual width of the stream in real life. If you measured the width of a blue line that represents a stream and converted it to real-world ground distance using the scale, it would be much wider than the real-life stream.
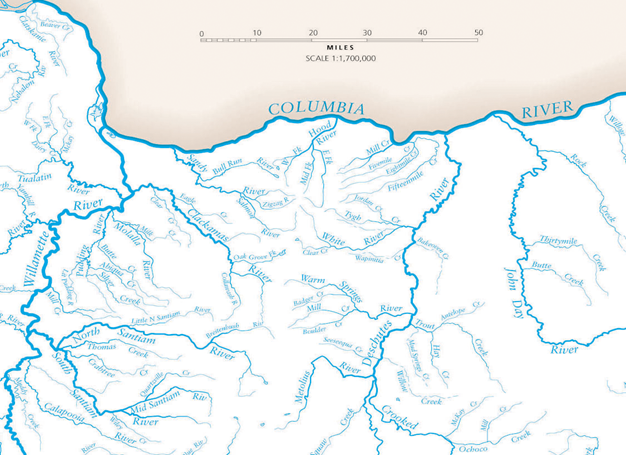
2.4 Area feature maps
To create area symbols that represent different types of area features, we can use color hue and/or patterns (Figure 11).
For example we can use two colors to show the states carried by the democratic (blue) and republican (red) party presidential candidate in an election map. Alternatively, we can use donkeys as mimetic symbols to fill the Democratic states as a pattern, and elephants for the Republican ones. We might also use a combination of pattern and hue (red elephants and blue donkeys) to make it even more obvious; but most area features are differentiated simply by color.
Figure 12 shows an example of a qualitative thematic map: a map of ecoregions. Colors, such as red, green, purple, and brown, are used to distinguish different ecoregions. Within each type of ecoregion, color lightness and color intensity are used to show sub-classes.
3. Multivariate Maps
In single-theme maps, only one attribute of geographic features are depicted. Sometimes we want to show more information on the map and create associations between two or more geographic phenomena, such as population and GDP of a bunch of countries, or the spatial distribution of water bodies and human settlements. Multivariate maps simultaneously display multiple themes or feature attributes. Typically, we use a different symbol to represent each attribute/phenomena.
For example, Figure 13 shows a multivariate map showing both the location of cholera deaths and the locations of water pumps. The pumps are represented by a mimetic symbol of a circle with the letter "P" inside. Cholera deaths are represented by dots. Displaying both symbols helps a map reader find a spatial relationship between the two features.
The above example shows a common way to depict two or more attributes on the same map: use a separate symbol for each attribute/theme/phenomena. By varying the symbol’s shape, color hue, or orientation, qualitative attributes can be differentiated from one another. This is simple for point or line features, but for area features, which can overlap one another, there is more to consider than just choosing different symbols.
When overlaying two or more types of area symbols, the most common method is to display one attribute using color hue and show the other attribute using pattern shape (repeating a shape within the feature polygon).
Figure 14 shows a map of shellfish distribution in a coastal region of Oregon. The bottom layer displays the type of ocean bottom, symbolized by different colors. Another layer showing shellfish type is placed above the "Bottom Type" layer. In this layer, different area symbols are filled with different patterns. The vertical and horizontal dashed line pattern symbols show where crab or shrimp are harvested. The areas with “+” signs show where both crab and shrimp are harvested.
This map allows you to see if there's any geographical relationship between the ocean bottom type and the type of shellfish harvested. For example, we can see that crab is mostly harvested from areas with sand bottoms.
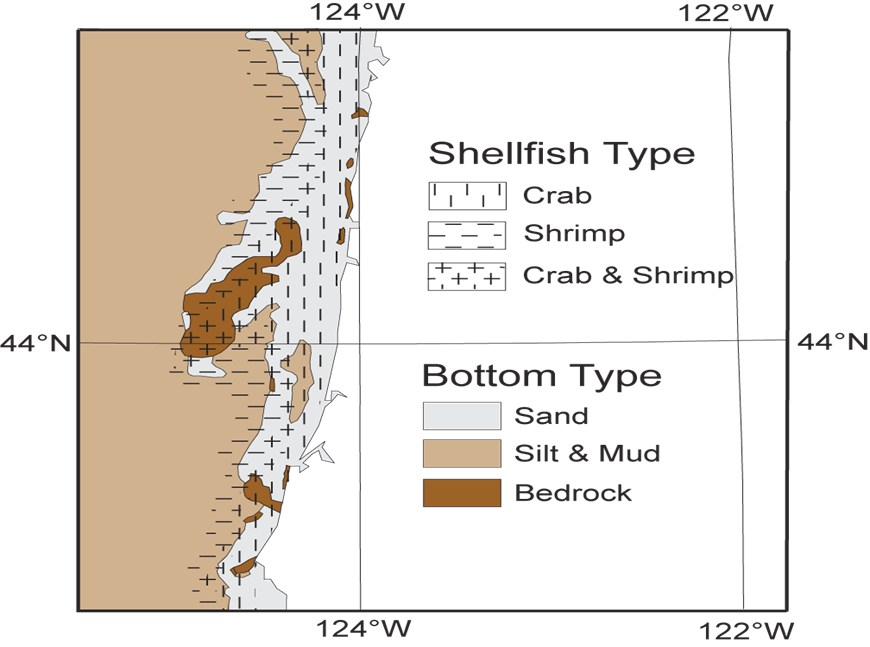
4. Qualitative Change Map
A qualitative change map is a type of map that shows the change of geographic phenomena. Mapping change is difficult because it can be hard to find symbols explicit enough to convey the correct information to the reader. Qualitative change maps display changes that are qualitative/categorical rather than quantitative. There are two types of qualitative changes:
Change in the category of features over time at the same location.
Change in the location of a feature over time.
There are a variety of ways show change on a map. Figure 15 shows locations whose attributes have changed over a certain time period. In this map, red areas represent land-cover change from non-urban to urban from 1986 to 2002 in the Minneapolis-St. Paul region of Minnesota. Note how the legend uses red to encode "change from non urban to urban"; this makes it easy to see that most of the change occurred at the edge of the core urban area.
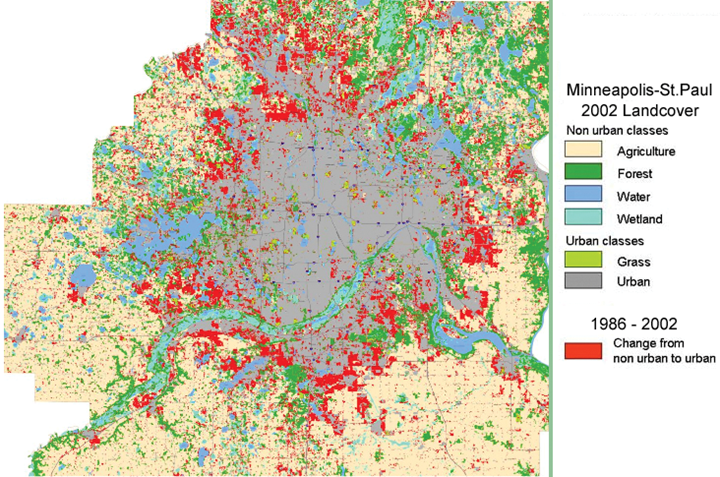
Figure 16 shows another way to map changes in attributes. This maps displays change in Portland, Oregon building use between 1879, 1908, and 1955. Instead of marking building change with special symbols, this map shows three maps in a time series. They use the same basemap and symbols which helps the readers understand changes in the number of buildings and their use. This example shows another way to map changes: show a time series of maps side by side that 1) cover the same area and 2) use the same symbols and legend.
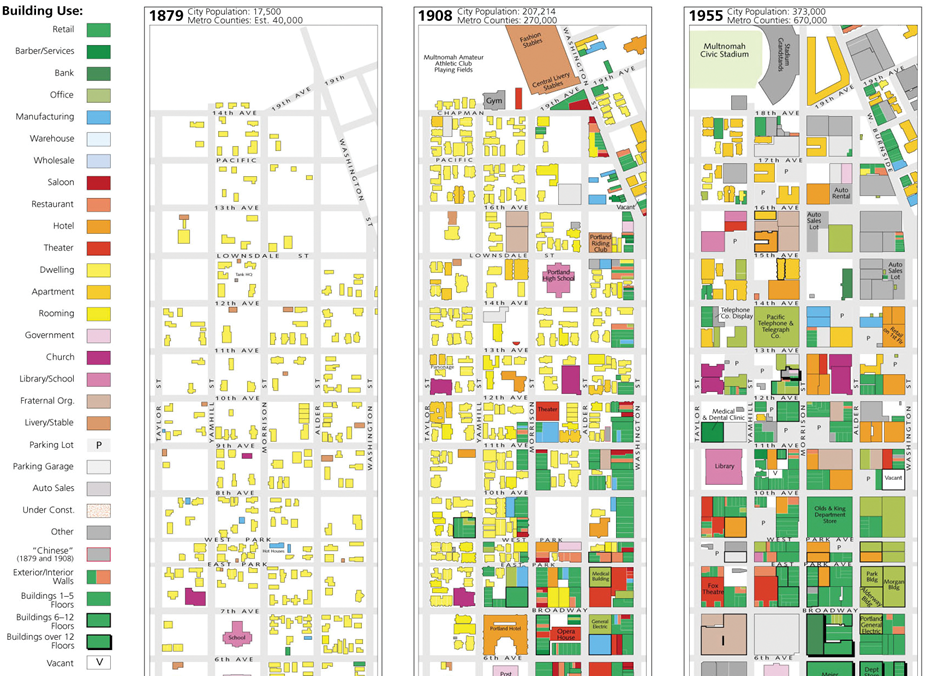
The maps in Figure 17 also show change using a series of maps over different times. These maps show dam construction over different time periods. Each map displays dams constructed during that time period with a dark purple color, and previously-constructed dams with a light purple color.
These maps let us study the long-term pattern of changes in a region by showing changes at each time period as well as cumulative changes before that time period.
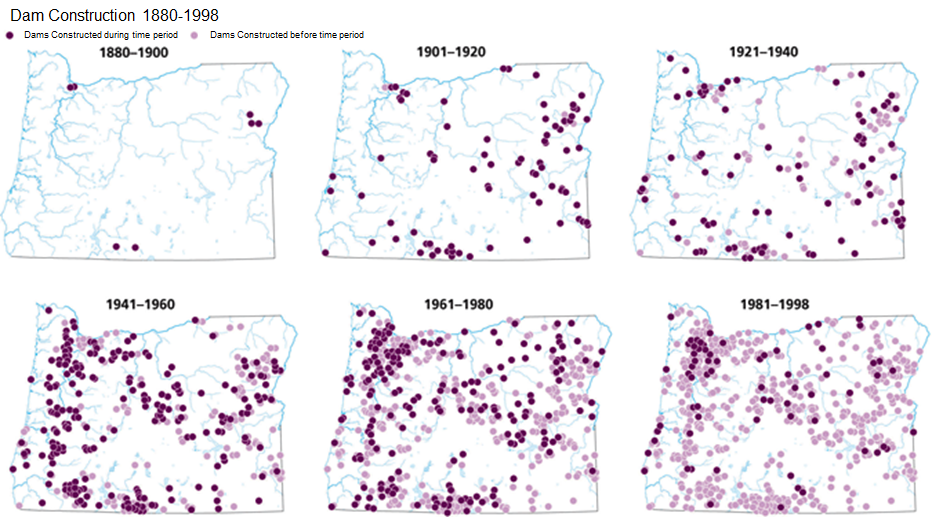
The three examples (Figure 15-18) show attribute changes over time in the same location. What if the location of a phenomena is also changing? This falls into the second category of qualitative change maps. Figure 18 shows the location of the Mt. St. Helens volcanic ash plume at different time periods after eruption. In this map a series of red lines, which are called isochrones (lines of equal time difference), show the range of the ash at different times: 3 hours, 6 hours, and 9 hours after the eruption.
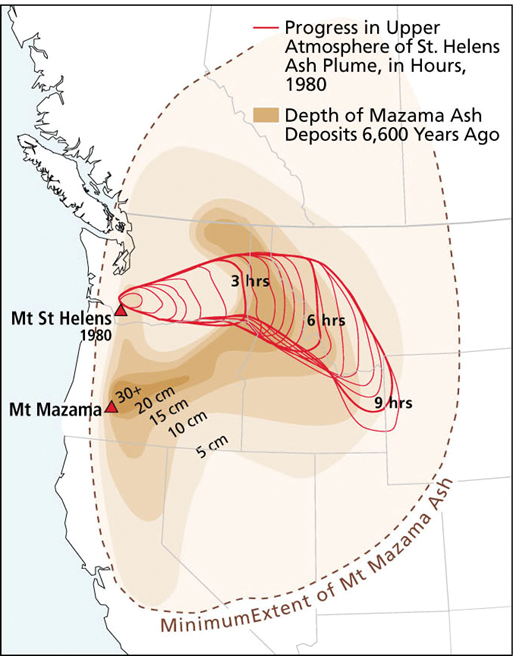
Key Terms
Qualitative Map: a map showing the location/distribution of a phenomenon using nominal data
Quantitative Map: a map showing the magnitude/value of a phenomenon using ordinal, interval or ratio data
Single-theme Map: a map that only depicts one theme or attribute at a time
Multivariate Map: a map that simultaneously displays two or more themes or feature attributes to describe geographic relationships between the phenomena
Geometric symbol: symbols that use simple shapes, such as squares, circles, and triangles to represent different features
Pictographic symbol: symbols that look similar to the real-world features they represent
Mimetic Symbol: symbols that imitate or closely resemble the thing it represents using simple designs, e.g. an icon of a picnic table to represent a picnic area
Qualitative Change Map: a map showing the qualitative change of geographic phenomena/features over time, such as a change in feature category or the change in the location of features.
Lecture 14 Thematic Maps III: Quantitative Map
1. Quantitative Maps and Visual Variables
1.1. Overview of Quantitative Maps
Quantitative thematic maps describe any numerical information about spatial features and their relationships. These maps answer questions like how many, large, wide, fast, high, or deep things are, using interval or ratio data. Figure 1 shows four quantitative thematic maps made using different mapping methods: isoline, choropleth, proportional symbol, and dot density. All of them convey magnitude information.
Different isolines in the upper left map indicate different amounts of solar radiation.
In the upper right map, different tones represents different portions of residents over 65 years old (choropleth).
In the bottom left map, circles of different sizes indicate different population levels for each county (proportional symbol).
In the bottom right map, different numbers of dots represent the potato planting area for each county in Wisconsin (dot density).
We will look at these quantitative mapping methods in detail later in this lecture.
1.2 Visual Variables in Quantitative Maps
For qualitative maps, we use the visual variables color hue, orientation, and shape. For quantitative maps, we prefer visual variables that can effectively impart the magnitude of phenomena to the reader: these include size, pattern texture, color lightness/color value, and color saturation/intensity (Figure 2).
Map symbols with different sizes imply differences in quantity. For point features, a larger circle implies greater quantity than a smaller circle. For line features, a wider line indicates a larger quantity than a narrower line. For area features, more volume indicates a greater quantity.
Pattern texture can imply quantitative differences by density. A finer, more tightly-packed grid is higher in quantity than a loose, coarse grid.
Color lightness can imply an increase in quantity using the darkness of the color. For example, dark blue indicates higher magnitudes than light blue.
Color saturation (or color intensity) is a subtle visual variable that is best used to show subtle variations.
A well-designed series of symbols uses variation in one or more of these visual variables to show differences in magnitude.
In Figure 3, the size (height) of the bars is used to show the population of each county in the state of Oregon in 2000. The higher the bar, the higher the population.
1.3 Quantitative Thematic Map Classification
Similar to qualitative maps, quantitative thematic maps can also be classified as single-theme maps or multivariate maps.
Single-theme maps for quantitative data can depict point, line, area, and continuous surface features or phenomena. For each type of features, we will introduce the most common method(s) to quantitatively display their attributes. Multivariate maps show the relationship between multiple attributes. There are several ways to overlay multiple layers of symbols to create multivariate maps. Figure 4 summarizes the common methods in each category of quantitative thematic maps. We will go through each of them in the following sections. You might want to refer to this figure while you are reading.

2. Single-theme Maps
2.1 Proportional symbol and graduated symbol map
For point features, proportional and graduated symbols are commonly used to show quantitative information.
Proportional maps use symbol size to represent the data value.
Graduated maps use symbol size to represent groups of values; this means that the quantitative values are grouped into intervals, and all the features within a class are shown with symbols of the same size.
Figure 5 shows three county level population maps in the San Francisco Bay area. These maps use the same data but different symbols. The left map uses mimetic proportional symbols (left), where human-shaped symbols are sized according to population. Here each symbol of a particular size represents an exact population value (e.g. the largest one represents 800,000 people). The middle and right maps use simple geometric symbols, but one uses proportional symbols, and the other uses graduated symbols.
The simplest way to tell the difference between proportional and graduated symbols is to look at the legend. In the right map, each symbol has a range of data values, which indicates that this is a graduated symbol map. Another difference is that in a proportional symbol map, symbols on the map could have a size not listed in the legend, but in graduated map, since data are grouped in intervals and each is associated with a certain symbol size, every symbol on the map must have a size listed in the legend. In the right map in Figure 5, there aren't any symbols whose size is between any two symbol sizes in the legend.
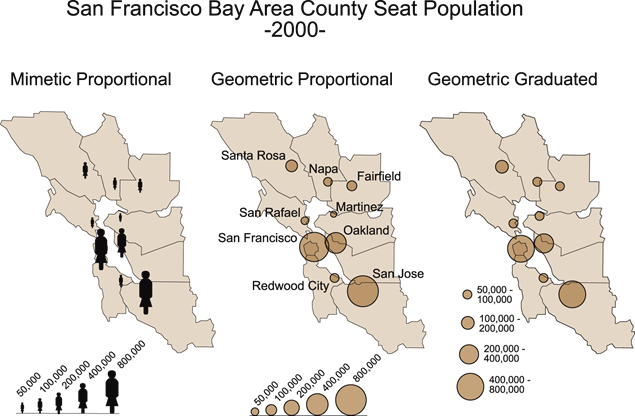
2.2 Flow Maps
Flow is defined as the movement things from one place to another, such as migrations of people, the spread of disease, and the shipment of goods between regions. Flow maps can show these transportations spatially using a line symbol called a flow line.
On most flow maps, the size (width) of the flow line is proportional to the magnitude of the flow. For example, Figure 6 shows jobs provided to Oregon by foreign-owned companies. The width of the line indicates the number of the jobs.
The direction of flow is also important. Sometimes, arrows are added to one end of the flow line to show flow direction. In Figure 6, all the flow lines have an arrow pointing to Oregon, which means that the jobs are provide to Oregon.
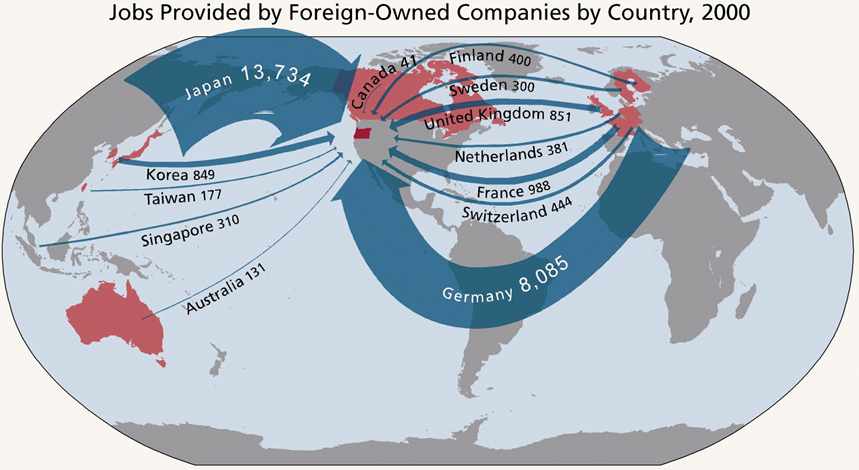
In addition to size (width) of the flow line (Figure 6), the magnitude of flow can be also shown by varying the texture, color saturation and color lightness of the lines.
Figure 7 shows a traffic flow map in Google Maps. From the legend you can see that the color of the flow lines indicates the condition of traffic. Heavy traffic is represented with red, and light traffic is in green. In addition the double lines mean that the road has two directions, while the single lines indicate one-way roads.
2.3 Choropleth Maps
Choropleth maps represent quantitative properties of area features by varying the lightness or intensity of color. Choropleth maps typically show density or rate information about area features (e.g., counties, states, countries, etc), such as population density or tax rate, rather than straightforward values such as totals. Figure 8 is a simple choropleth map showing graduation rates by state. Choropleth maps are perhaps the most common and effective thematic map.
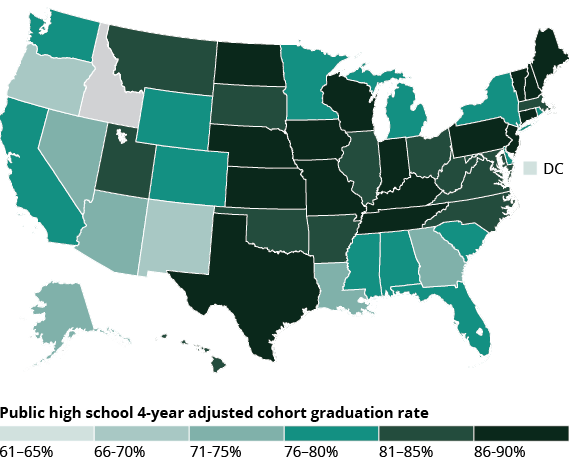
To make a choropleth map, in addition to choosing the appropriate symbols (i.e. color hue, intensity, lightness) to represent the quantity of the area features, we also need to decide how to associate data values with symbols. One way is group data into classes; remember from Lecture 11 (Section 3.4) that data reclassification is an essential step in mapping. The same methods introduced in that lecture (equal interval, natural breaks, standard deviation, and quantile) also apply here.
Figure 9 shows a series of maps of Oregon population density using different data reclassification methods.
The first map in Figure 9 uses equal interval classes to divide the range of attribute values into equal sized groups. This means each group has the same interval. However, since equal interval does not account for data distribution, it may result in having most data values placed into one or two classes. For example in this map, we can see the population density of most counties fall into the first class (0.7 -390) represented with light brown color.
The natural breaks method used in the second map divides the data into classes according to the distribution of the values. This method minimizes the differences within classes and maximizes the differences between classes. For example, based on the distribution shown in Figure 10, the natural breaks are placed at 60, 150, 1000 persons per square mile. The data is divided into four classes (0.7- 60, 60- 150, 150 – 1000, 1000 - 1561). The choropleth map based on these intervals shows population variation in Oregon counties better than the first map. This classification method can show data that is NOT evenly distributed, and makes it easier to see patterns. It is an unbiased, scientific method to determine ranges. GIS software typically uses this classification method by default.
Instead of grouping the data values, we can also symbolize the data using continuous color intensity by assigning each data value a unique shade. We simply call this method "unclassified". To create an unclassified map, a unique shade/color is assigned to a unique data value. Therefore, each unique data value is in its own class and gets its own color. The last map in Figure 9 uses continuous brown shades ranging from white for the lowest density county to dark brown for the highest density. Since we did not categorize the data into classes, the map gives you an unbiased picture of Oregon population.

Changing the number of classes results in different map appearances and can convey different messages to readers. Figure 11 shows maps of Oregon population density using different numbers of classes.
The simplest map has only two classes: above and below the median. Clearly, less information is shown in this map, because one could not compare two counties in the same color. More information is shown if four classes (e.g. using quartiles or percentiles) are used. We can increase the amount of information by using more classes, but when more classes are used the map can become more difficult to read. When eight classes are used (Figure 11 bottom), it can get hard to differentiate between colors.

2.4 Cartograms
Rather than accurately display areas and use symbols with different colors/sizes to represent the attribute, cartograms distort areas in proportion to the magnitude of the variable (such as population). This can make it easier to see differences between areas and the distribution of the data.
For example, Figure 12 is a cartogram showing the world population at 2010. The size of each country is proportional to its population rather than its geographic area. In this way countries are scaled on the basis of population. You can see the size of each country is distorted, but it allows you to see the population distribution clearly and intuitively since the mapped size of each country is proportional to the size of its population.
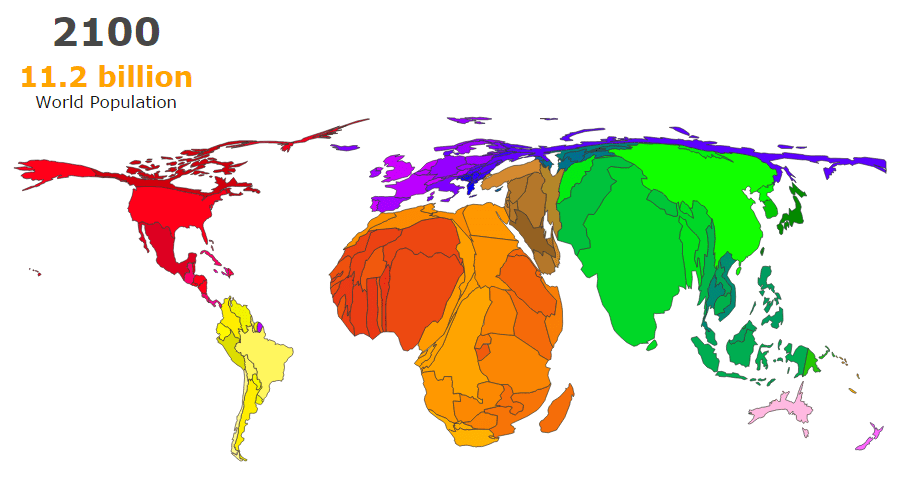
Although cartograms are a little strange, they help overcome some of the problems that map readers have with point symbol and choropleth maps when there is a large range in the size of areal mapping units.
There are a couple of ways to make cartograms: 1) Non-contiguous cartograms, 2) Pseudo-contiguous cartograms, and 3) Contiguous cartograms. Let's look at their differences through an example in Figure 13, which shows three types of cartograms for the population of California counties.
A Non-contiguous cartogram looks exploded, meaning neighboring areas don't need to touch. This map preserves the shapes of area as much as possible but doesn't attempt to preserve any adjacencies from the original map. Each county is enlarged or reduced in proportion to its population.
A pseudo-contiguous cartogram typically transforms each area into a simple shape (square in this example). Therefore, the shape for each county is not preserved, but is represented by uniform squares instead. Even though mapped areas share common boundaries and looks contiguous at first glance, the boundaries are not real. This is why these maps are called “pseudo-contiguous”
Contiguous cartograms are the most common cartograms. On these cartograms the contiguity of neighbors is preserved, and shapes are maintained to some extent, while the area of each feature still represents the quantity. In this example, despite the shape distortion, you can see precisely which counties have the greatest population.
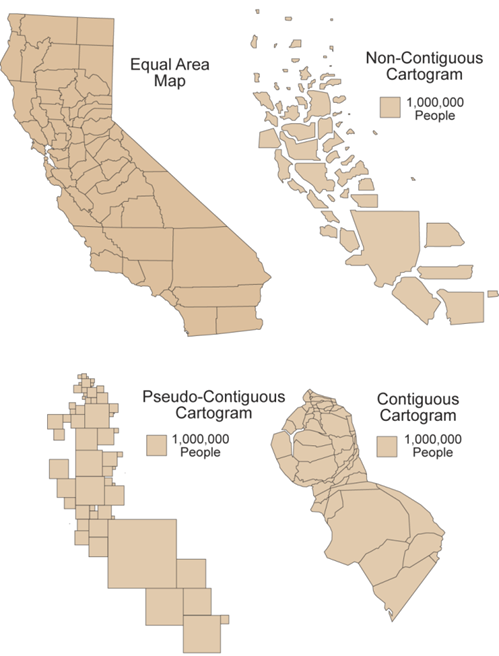
2.5 Prism Maps
A prism map shows the magnitude of a theme variable (or attribute) by varying the heights of area based on its value.
Here is an example of a prism map for California population by county (Figure 14). Each county boundary has been raised above the base level to a height proportional to its population. The map looks like a three-dimensional stepped surface.
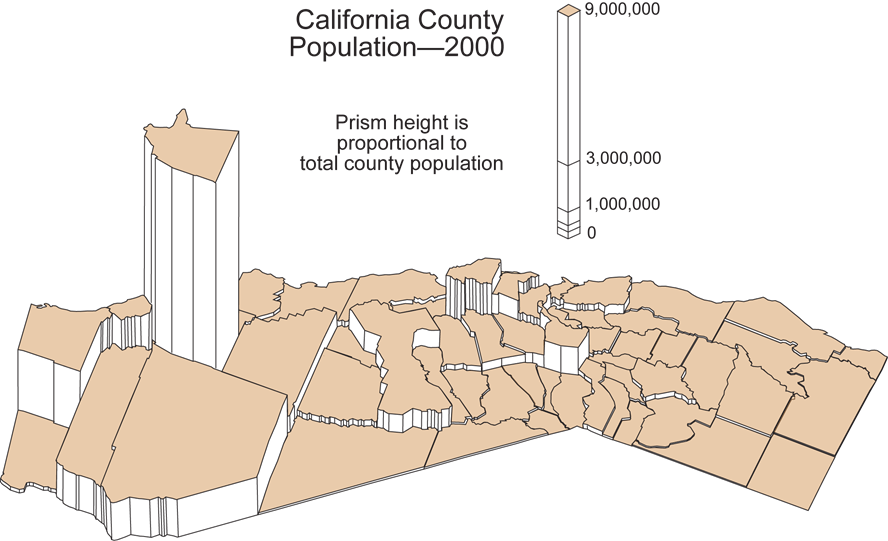
2.6 Continuous Surface Maps
So far we have talked about mapping point, line and area features, which are all discrete features. We can also map a continuous surface. Continuous surface maps are used to show quantities that vary smoothly over space.
Temperature and elevation are examples of continuous surfaces that change gradually from place to place. Density distributions, such as population density, are also continuous surfaces. In Figure 15 the density of bike share stations (stations per square mile) is mapped as a continuous surface. This map differs from a choropleth map in that the changes are gradual rather than abrupt.
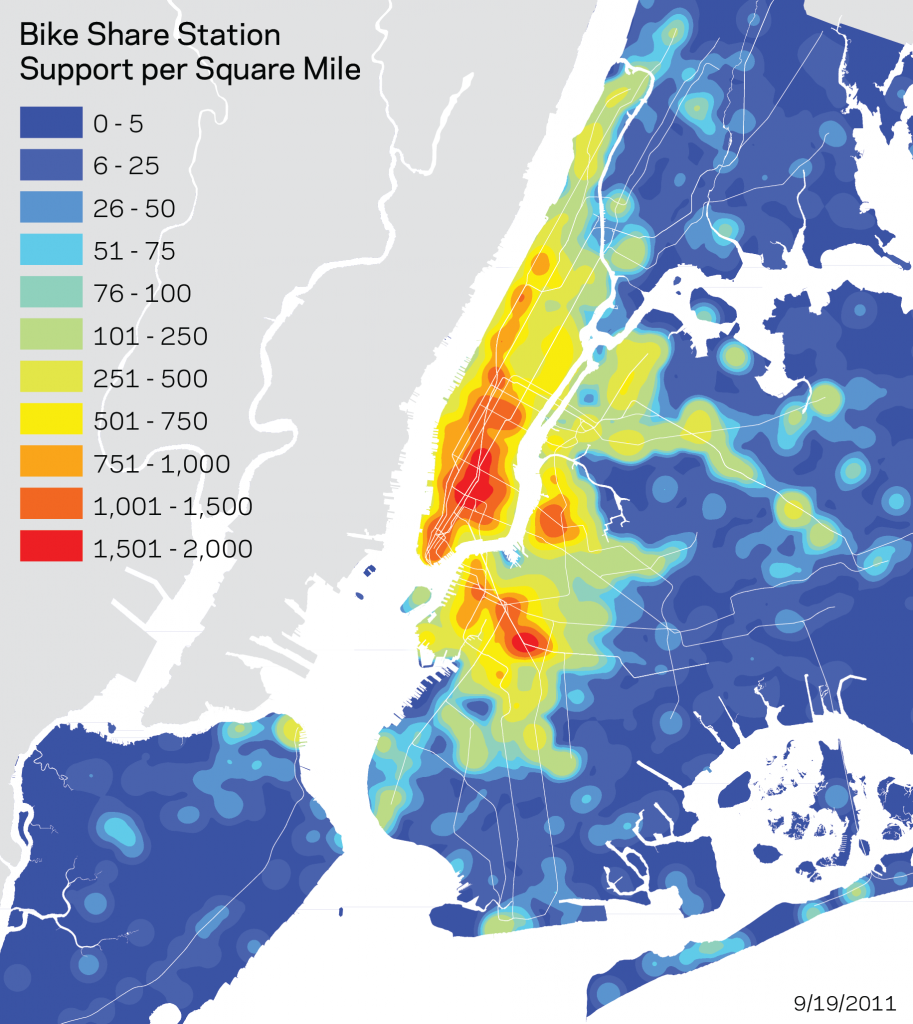
There are several ways to map a continuous surface. Many of the mapping methods were originally used to portray terrain elevation. Here we are also focusing on the mapping of other types of continuous surfaces.
The most important methods for mapping continuous surfaces:
Isoline/Isopleth Map
Dot Density Map
3D Perspective Map
2.6.1 Isoline/Isopleth Map
Isoline is a line that connects points of equal value on a map. Isolines are commonly used to show quantities that vary smoothly over the Earth's surface. For example, they are used on weather maps to connect areas of equal air pressure, and on topographic maps to connect areas of equal elevation.
In Figure 16, an isoline map is used to show average annual hours of sunshine in the Pacific Northwest region of the U.S. Each isoline is labeled with its value. For example, the line labeled "3000" means that every location on the line has an average of 3000 hours of sunshine per year. From this map, we can see a strong regional pattern: hours of sunshine decrease as you move from south to north.
There are two important rules of isoline maps. First, the intervals between isolines are equal. In this example the interval is 200, therefore the isoline values increase from 1800, to 2000, and on and on in increments of 200 until 3000. The second rule says that there is always a high and low side of a particular isoline. For example, if a isoline is 500 feet (152 m) in elevation, one side of it must be higher than 500 feet and the other side must be lower. It is impossible that both sides are higher or lower at the same time. Now, check both rules in Figure 16.
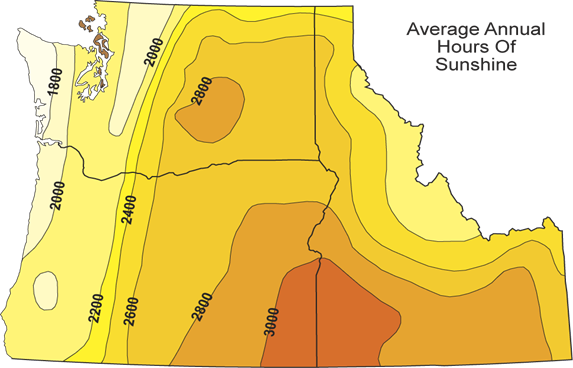
To assist map readers in understanding patterns, some maps use a progression of color lightness, color intensities, or textures added between isolines, and ranges of similar value are filled with similar colors or patterns. You can see a progression in magnitude from low to high, with the isolines outlining different magnitude zones. Figure 16 shows a progression of orange to light yellow to indicate values moving from high to low.
Sometimes isolines are not labeled (Figure 17), which encourages map readers to see the general pattern of highs and lows on the surface rather than concentrate on individual isolines. Since the lines are not labeled, numerical range information for each color or texture is be found in the map legend.
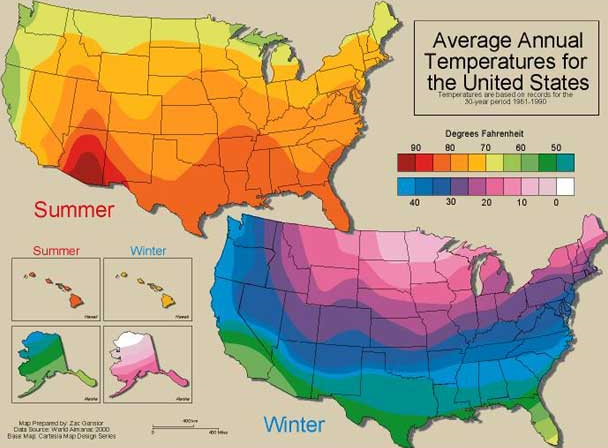
The isolines examples shown above describe values that exist at points, such as temperature or elevation values. There is another type of isoline map where the values are ratios that only exist over areas, such as population per square kilometer or crop yield per acre. This is call an isopleth.
Isopleths look identical to standard isoline maps, but they they show a density or ratio surface where the values can’t physically exist at points. Figure 18 is an example of an isopleth map - the population density of California is mapped as isopleths.
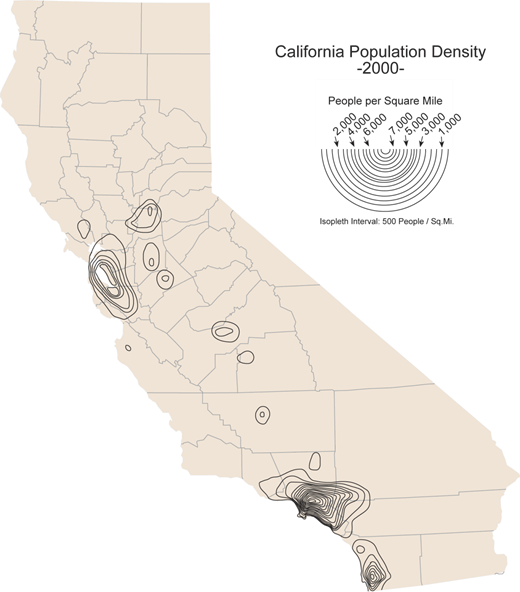
Isoline = data at a point
Isopleth = data over an area
2.6.2 Dot Density Maps
A dot density map uses dots to represent data values within a polygon. It's a useful method to show variations in density across a surface. Please note that dot density mapping is only used with polygons/areas. In dot density maps, each dot represents more than one feature, and the total number of dots represents the polygon’s data value. Dot density maps usually include a legend defining how much is represented by each dot.
Figure 19 is a dot density map showing population density across Cuyahoga County, Ohio. As indicated by the legend, each dot represents 150 people. Based on the attribute value of a polygon feature, we can calculate how many points should be included within a polygon. For example we know that the population in the city of Berea is 15,000 people. Since 1 dot represents 150 people, there should be 100 dots in the polygon for Berea.
Please note that on such map, the location of dots does not show the specific location of people; there isn't a literal concentration of 150 people at each dot. Rather, the density of dots in each area represents the population density in the county.
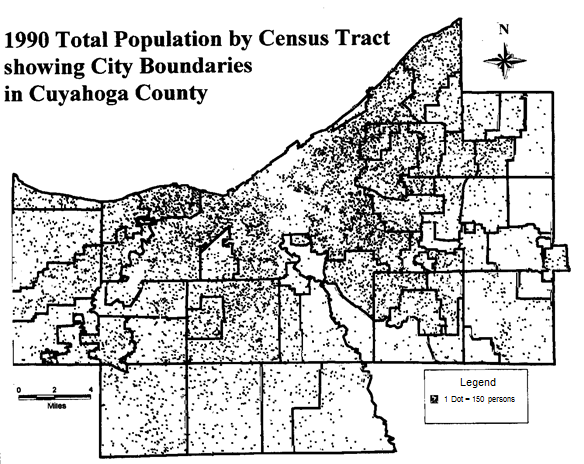
In dot density map, there are many ways to change how data is displayed on dot density maps, including
Dot value (which means the number of features represented by a dot)
Dot size (the size of the dot )
Dot color
Dot shape
The aim of dot density maps is to present an image of changing density across the region rather than giving precise locational information. Therefore, to make a good map, one needs to determine the appropriate dot, size, shape, color, and value, to avoid giving readers mistaken impressions of the changes in density.
2.6.3 3D Perspective Maps
A continuous surface can also be represented in a three-dimensional (3D) perspective map. If the mapmaker constructs closely spaced line profiles in two directions and in perspective view, you gain an impression not of individual lines but of a continuously varying 3D surface called a fishnet. The fishnet map uses lines to depict the continuous surface. In this map you can see undulations in the surface.
Notice how your attention is focused not on any one line or any one quadrilateral that is formed by the lines but on vertical undulations in the surface. It is actually the angle and length of sides of the quadrilateral that depict the surface. Note how differently this map shows the variability in California population density than does the prism map in Figure 14.
Your ability to see all locations on the map is determined by the viewpoint and viewing angle selected by the mapmaker. In Figure 20, the California population density surface is shown at a 30-degree angle above the horizon from both a north (Figure 20, top) and south (Figure 20, bottom) viewpoint. Different peaks and valleys in the surface are hidden from view on each map. Two or more maps are often required to see parts of the surface depending on the data distribution. Animated 3D perspective maps are ideal for viewing the details of a continuous surface.
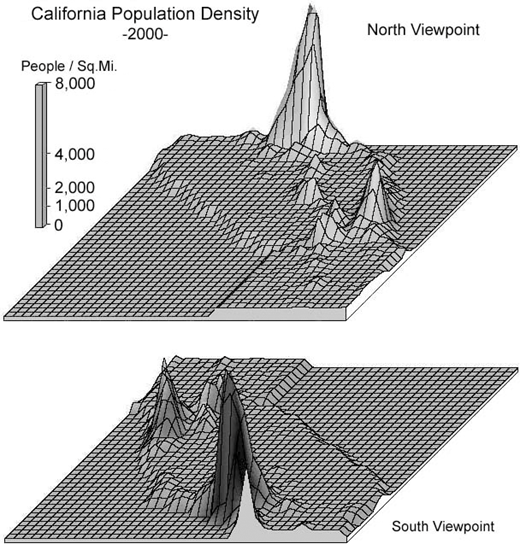
3. Multivariate Maps
Multivariate maps are used to display more than one attributes on the same map. Here we introduce three methods of combining two or more themes on a single map: combined method, point symbols, and bar/pie chart.
3.1 Combined method
The most straightforward method to show multiple quantitative attributes on a single multivariate map is to combine two or more of the mapping methods we introduced in the previous section, where each mapping method is applied to one theme/attribute.
Figure 21 combines two different mapping methods - Choropleth and Proportional Symbol - to display two related variables (mining employment and production by region). A choropleth map shows the number of people employed in the mining industry of each region, while the proportional point symbols show mining production values in millions of dollars.
The advantage of combining mapping methods is that the map effectively displays 2-3 few variables, and is useful for inspecting individual distributions.
The limitations: 1) as the number of variables increases, readability decreases; 2) it is difficult to convey the relative importance of the themes/attributes displayed on the map.
Figure 22 shows another example. This map shows the spatial relationship between the spread of the West Nile virus and states' distance from the Mississippi River. To show the spread of the west nile virus, a prism map is used. The height of each prism is proportional to the number of confirmed cases of the virus. The top of each prism is colored according to its distance from the Mississippi River; the variable “distance from the Mississippi River” is displayed using a choropleth.
The map shows a strong relationship between the incidence of the virus and proximity to the Mississippi river.
3.2 Multivariate Point symbol
Another method to show multivariate quantitative data on a single map is by using multivariate point symbols. There are two ways to use make point symbols multivariate:
Display two or more variables in a single point symbol using different visual elements
Segment a point symbol to show the relative magnitudes of attributes for the features.
3.2.1 Single Point Symbol
Figure 23 is a multivariate map showing the United Nations World Happiness index, 2017, where seven social status factors are displayed using Chernoff faces. Chernoff faces use facial expressions to illustrate multiple attributes (refer to the legend in Figure 23):
The shape of the face shows levels overall happiness
The eyes represent expectation of health
The mouth indicates having someone to count on
The eyebrows represent trust in authority
and so on

3.2.2 Segmented Point Symbol
Segmented point symbols are divided to multiple parts, with each part indicating one variable. The total magnitude for each attribute is represented using point symbols that vary in size.
Figure 24 shows Oregon state income tax and local property tax per county. The legend says that each cube is divided into two parts: the left red part indicates the income tax, while the right yellow part indicates the property tax. While the volume of each cube shows the total taxes due in each county, the volume of each part (either left or right) indicates the amount of each type of tax due (income or property).
3.3 Pie or Bar Charts
Pie or Bar Charts are a very effective way to display multiple attributes, where each component (bar or slice) of the chart corresponds to attribute.
Figure 25 shows how to use bar and pie charts to represent three different attributes: property, income, and sale tax. Property is shown by the red bar/slice, income in blue, and sales tax in yellow. The size of each part in the chart is determined by the value of each attribute. In the bar chart, the height of each bar indicates the value of each attribute. In the pie chart, the size of the circle relates to the total tax due of an area. Each part of the pie shows you the relative proportion of each type of the tax (property, income, or sales).
Note that Pie or Bar Charts are only used with polygons.
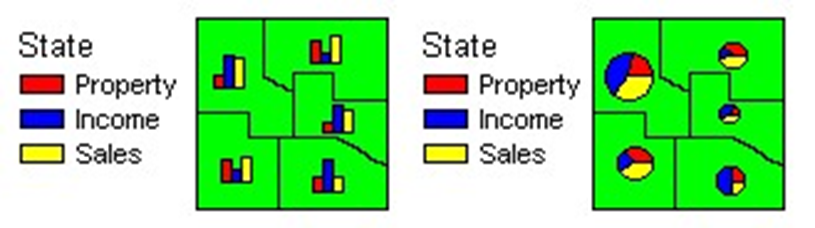
Key Terms
Quantitative Thematic Map: a type of map that describes any magnitude/numerical information about spatial features and their relationships. Such maps answer questions like how much, many, large, wide, fast, high, or deep things are, using interval or ratio data.
Proportional Symbol Map: maps that use various symbol sizes to represent the value of the attribute mapped.
Graduated Symbol Map: maps that use symbols with various sizes to represent different groups of values, which means the quantitative values are grouped into intervals and all the features within an interval are shown with same sized symbol.
Flow Map: maps that show movement of things from one place to another using a line symbol with direction.
Choropleth Map: maps that represent quantitative properties of area features using lightness/intensity of colors.
Cartogram: a type of map that distorts area (size and geographic borders) in proportion to the magnitude of an attribute (such as population) in order to add visual contrast to the data and and show its distribution.
Prism Map: a type of map that shows the magnitude of an attribute by varying the heights of areas.
Continuous Surface Map: a type of map used to show quantitative variables that vary smoothly over a surface.
Isoline: a line that connects points of equal value on a map. Isolines are commonly used to show quantities that vary smoothly over a surface.
Isopleth: a type of isoline, in which the values are ratios that exist over areas, such as population per square kilometer or crop yield per acre.
Dot Density Map: a type of map that uses dots to represent data values associated with a polygon. It is only used with polygons/areas. In dot density maps, each dot represents more than one feature, and the total number of dots within a polygon represents the polygon’s data value.
3D Perspective Map: a type of map that uses the vertical height of each cell in a fishnet to represent quantitative variables that vary smoothly across a surface.
Fishnet: a type of 3D surface constructed by closely spaced line profiles in two directions. From a perspective view, the height of each grid varies to create an impression of 3D.
proportional symbol is not suitable for presenting the information of density
GEOG 170 Final Review
Lecture 1 Introduction to Geospatial Technology
Geospatial Technology = tools used for location based data
Geographic Information System (GIS): a computer-based geospatial technology for storage, analysis, and management of location-based data.
Remote Sensing (RS): a technology that is used to acquire imagery of the earth's surface through the use of satellites or aircraft. The data collected by satellite devices are typically called satellite imagery, and data acquired by devices on aircraft are called aerial photos.
Global Positioning System (GPS): a technology that acquires real-time location information from a series of satellites in Earth’s orbit.
1.1 GIS
A GIS is both a database system with specific capabilities for managing geospatial data, as well as a set of operations for working with the data.
Could be a database of location based data and any other data (covid cases, jobs, etc)
The spatial component of this data allows the user to analyze the data both statistically and geographically, alone or in conjunction with other spatial information, and produce output in the form of maps.
1.2 Remote Sensing (RS)
Uses sensors to collect information about about area without contact
Data used for:
location of objects
physical makeup of objects
the health of vegetation
elevation of the objects
Can be incorporated into GIS softwares
1.3 Global Positioning System (GPS)
Using satellites, GPS provides locational information. Think phones and how they tell location to find nearby restaurants
Video:
Geographic Information Systems (GIS) and Mapping
GIS has revolutionized the way we perceive, interact with, and engage with the world around us.
Maps have evolved from ancient stick maps to modern digital maps and GIS-powered visualizations.
GIS enables the input of various data sources, such as maps and satellite imagery, to produce visualizations like maps, animations, and charts.
Mapping and Community Empowerment
Community-based participatory mapping programs, like those used in Borneo, have allowed marginalized communities to assert their land rights and plan for the future.
Native American communities are also using mapping to reclaim place names and traditional land use.
GIS Applications in the North State
Students have mapped the locations of wineries, vineyards, and olive oil producers to connect producers and consumers.
A map of community service organizations helps connect people in need with the appropriate resources.
Mapping stream conditions and trail systems supports conservation efforts and promotes healthy lifestyles.
Regional agencies use GIS to plan for transportation development and improve community livability.
The city of Redding is piloting a citizen-reporting application to improve service delivery.
The Democratization of Mapping
Maps are no longer solely controlled by those in power, but are a canvas for all to convey their priorities and sense of place.
Maps can be used to democratize, organize, advocate, design, and dream.
2. Who uses geospatial Technology?
Geospatial technology can be applied in many ways across a number of applications, including federal, state, and local government, forestry, law enforcement, public health, biology, environment, and transportation
2.1 Archeology
In archeology, we can use geospatial technology to pinpoint the location of artifacts uncovered on a dig, construct a map of the area, and then search for patterns on the site.
Archaeologists can also utilize historic maps, current aerial photographs or satellite imagery, and location information obtained on the site throughout the course of their work.
2.2 Environmental Monitoring
We can also use geospatial technology to monitor and analyze the processes that affect Earth’s environment. We can map and monitor land use changes, pollution, air quality, water quality, and global temperature levels, which are all important information for scientific research and for making smart decisions for the benefit of our environment.
2.3 Forestry
Geospatial technology is also very useful in forest monitoring, management, and protection. Modeling animal habitats and the pressures placed upon them, examining the spatial dimensions of forest fragmentation, and managing fires all acquire the assistance of geospatial technology.
2.4 Public health
Geospatial technology is used for a variety of health-related services. disease monitoring, tracking the source and spread of diseases, and mapping health-related issues are all tasks that can be completed using geospatial technology applications
2.5 Real Estate
Through geospatial technology, realtors and appraisers (as well as home buyers and sellers) can create and examine maps of houses and compare housing prices of nearby or similar properties. By examining high-resolution aerial images, one can also obtain other features of a property such as topography, terrain, transportation, and even whether it sits on a floodplain. You can also look at how a property is located in relation to schools, highways, waste-water treatment plants, and other urban features
Many types of decision making are reliant on geospatial information. When a new library is proposed to be built, the choice of location is important — the new site should maximize the number of people who can use it but minimize its impact on nearby sites. The same type of spatial thinking applies to the placement of new schools, fire stations, or fast-food restaurants. Spatial information fuels other decisions that are location dependent; for instance, historic preservation efforts seeking to defend historic Civil War battlefield areas from urban development.
4. Geospatial Technology for Everyone
You can examine satellite imagery or aerial photography of the entire globe, zoom from Earth orbit to a single street address, navigate through 3D cities or landscapes, measure global distances, and examine multiple layers of spatial data together, all with an intuitive interface. In many ways, the coolness and simplicity of use of Google Earth make it feel like a video game, but it’s far more than that. Google Earth is able to handle vast amounts of geospatial data swiftly and easily and enables users to specify and create their own location-based spatial data. It is used by scientists, GIS technicians, real estate managers, AND everyone else like YOU!
Lecture 2 Geographic Information and Representation
1. What is Geospatial Information?
1.1 What is information?
The scientific method to approach the outside world includes four processes: obtain direct observations, decode observations to data, convert data to information, and generate knowledge from all kinds of information
This process begins with observing, which could be human-sensed, manually recorded, or collected by devices (i.e., camera, satellites). Observations have no particular value by themselves. For example, the satellite signals we collected (Figure 2) are meaningless to us. Typically, we have to decode those signals and obtain the raw data, which becomes text or digital data stored in a file.
Raw data acquire value through relationships among objects and assumptions about those relationships. That is, you need context for the raw data. For example, the digit 120 do not mean much unless you know they measure temperature in degrees Fahrenheit (i.e., the context). Data become information when we can interpret them - either manually or with the help of tools, e.g. processing and displaying the data.
information can lead to higher levels of knowledge. if we put it in a geographic context, we can see a different picture altogether
if we put it in a geographic context, we can see a different picture altogether
1.2 What is Geographic Information?
Geographic information or geospatial information is information that has location (x,y) component as well as other associated attributes or characteristics.
Besides location, attributes are also critical for geographic information. In geography, attributes are spatially dependent variables. By spatially dependent we mean that the value of a variable may be similar to the values of its neighbors. For example, the price of a land parcel is highly related to the neighboring parcel.
Most of the time, geographic attributes are specific statistics tied to geographic location.
1.3 Geographic vs. Spatial Information
Although sometimes 'geographic' and 'spatial' are used interchangeably, geographic information is technically different than spatial information.
“Geographic” has to do with the Earth, its two-dimensional surface, or its three-dimensional atmosphere, oceans and sub-surface: An example of geographic data includes the depth of the frost line soil during the winter. The depth of the frost line is specifically in reference to the earth's surface. Another example of geographic data is the altitude of planes in the atmosphere. The height of the plane in the atmosphere is in relation to the earth's surface (sea level).
“Spatial” has to do with any multi-dimensional frame of reference: Medical images referenced to the human body; Engineering drawings referenced to a mechanical object; Architectural drawings referenced to a building
Therefore, 'geographic' is a subset of 'spatial'. All geographic (and spatial) information has an explicitly defined 'where"
2. How Do Maps Represent Geospatial Information?
2.1 What is a map?
A map is a spatial representation of geographic information presented graphically. It describes spatial relationships of specific features it aims to represent.
2.2 Information Drives Content and Design
Types of Maps:
Reference Maps: Depict locations
Thematic Maps: Depict spatially-referenced variables of interest
Navigational Maps: Depict paths and routes
Persuasive Maps: Present a graphical argument
2.2.1 Reference Maps
Emphasize the location of spatial phenomena
Summarize the landscape to aid discovery of locations
Geographic features are depicted as detailed and spatially accurate
Road maps, Google maps, Bing Map, mapquest.com, OpenStreetMap.org, USGS Topo maps
2.2.2 Thematic Maps
Depict information on a particular topic (also called "statistical map" or "single topic map")
Stress the geographical distribution of a particular topic
Typically less literal than reference maps
Weather, population density, and geology maps
2.2.3 Navigation Maps
Help navigators plan and follow travel routes
Include nautical and aeronautical charts
Nautical Charts: For water navigation
Aeronautical Charts: For air navigation (e.g., World Aeronautical Chart)
2.2.4 Persuasive Maps
Intended to convey an idea rather than communicate geographic information
Also called propaganda maps, often seen in public media
Advertising, political, and religious maps
Uses appealing images to persuade tourists
Less focus on geographic accuracy
2.3 Maps Can Be Difficult to Categorize
Some maps fall into multiple categories
Maps can be busy and convey a lot of information simultaneously
Importance of annotations and thematic content
Key Terms
Information: the interpretation of data with the aid of analysis or other tools
Geographic/geospatial information: information that has location (x,y) component as well as other associated attributes or characteristics
Map: a spatial representation of the geographic information that is presented graphically
Reference map: a type of map that emphasizes the location of spatial phenomena with purpose of summarizing the landscape to aid discovery of locations
Thematic map: a type of map specially designed to show a particular theme connected with a specific geographic area
Persuasive map: a type of map intended to convey an idea rather than communicate geographic information.
Lecture 3-1 Geodetics and Geomatics
1. Referencing Locations on the Earth's Surface
1.1 What are Geodetics and Geomatics?
Geodetics, also known as Geodesy, is the science of determining the actual size and shape of the earth. It covers the theories and technologies of measuring the precise location and motion of points on the earth's surface using various instruments, such as GPS, total stations, and theodolites.
Geomatics is a relatively new term applied to the practice formerly known as surveying. The name has gained widespread acceptance in the United States, Canada, the United Kingdom, and Austria. Geomatics encompasses the science, engineering, and art of gathering, analyzing, interpreting, distributing, and using geographic information. It involves a broad range of disciplines that work together to create a detailed and coherent picture of the physical world and our place in it. These disciplines include:
- Mapping and Surveying
- Geographic Information Systems (GIS)
- Global Positioning System (GPS)
- Remote Sensing
Therefore, geodetics can be viewed as part of geomatics.
1.2 Coordinate Systems
In geography, a coordinate system is "a reference system which uses one or more numbers, or coordinates, to determine and represent the locations of geographic features, imagery, and observations such as GPS locations within a common geographic reference framework." (ESRI)
Coordinate systems (either geographic or projected) provide a framework for defining real-world locations. There are two ways to pinpoint locations on maps:
Geographic Coordinate System (latitude, longitude)**: This system uses a three-dimensional spherical surface and measures of latitude and longitude to define locations on the Earth.
Projected Coordinate System (x, y)**: This system provides a mechanism to project maps of the Earth's spherical surface onto a two-dimensional Cartesian coordinate plane.
1.2.1 Geographic Coordinate System
A geographic coordinate system uses a three-dimensional spherical surface and measures of latitude and longitude to define locations on the Earth. It has been used for over 2,000 years as the worldwide location reference system. For example, Google Earth uses a geographic coordinate system by default (Figure 2).
Geographic coordinates (latitude and longitude) are measured in degrees, minutes, and seconds (DMS), or decimal degrees (DD), and represent angular distances calculated from the center of the Earth.
Degrees, minutes, and seconds (DMS): 65° 32' 15.275"
Decimal degrees (DD): 65.5375
Degrees and minutes (DM): 65° 32.25'
All these notations allow us to locate places on the Earth quite precisely. A degree of latitude is approximately 69 miles, a minute of latitude is approximately 1.15 miles, and a second of latitude is approximately 0.02 miles or just over 100 feet. The formula to convert DMS to DD is:
D + M/60 + S/3600
For example, given the DMS coordinate 45º56'18'', we can convert it to decimal degrees by the following method:
1. Let the integer number of degrees remain the same: 45
2. Divide the minutes by 60: 56/60 = 0.9333
3. Divide the seconds by 3600: 18/3600 = 0.005
4. Add the three together: 45 + 0.9333 + 0.005 = 45.9383°
1.2.2 Latitude
Latitude is the angular distance between the Equator and points to the north or south = up and down = east to west on the surface of the Earth A line connecting all points with the same latitude value is called a line of latitude. The Equator is an imaginary line that divides the Earth into Southern and Northern hemispheres, and it is equidistant from both poles, having a value of 0 degrees latitude
Latitude is expressed as degrees North (N) or South (S). There are 90 degrees of latitude going north from the Equator (the North Pole is at 90 degrees N) and 90 degrees to the south (the South Pole is at 90 degrees S). Northern latitudes are positive and southern latitudes are negative in GIS.
Called parallels
Example:
- Washington, DC’s latitude: 38°53'51.47" N or 38°53'51.47"
- Australia's Capital Hill latitude: 35°18’23.01" S or -35°18’23.01"
1.2.3 Longitude
Lines of longitude, called meridians, run perpendicular to lines of latitude and pass through both poles. The prime meridian is a meridian at which longitude is defined to be 0°. Unlike the equator, the prime meridian is arbitrary. By International Agreement signed in 1884, the meridian line through Greenwich, England, is given the value of 0 degrees of longitude, referred to as the Prime Meridian (Figure 5).
The Earth is divided into 360 degrees of longitude, ranging from 180 degrees West (W) to 180 degrees East (E) of the Prime Meridian. Longitudes can also be specified without directional designators (West and East) using positive and negative signs:
- East of the prime meridian: positive values up to 180 degrees
- West of the prime meridian: negative values up to 180 degrees
Example:
- Washington, DC’s longitude: 77º2'11.64" W or -77º2'11.64"
- Australia's Capitol Hill longitude: 149º07'32.83" E or 149º7'32.83"
The Prime Meridian and its opposite meridian at 180° longitude form a great circle dividing the Earth into Eastern and Western Hemispheres.
A degree is composed of 60 minutes, and a minute is composed of 60 seconds
Common Knowledge
- 15 degrees of longitude = 1 hour time difference
The Prime Meridian at Greenwich became the center of world time in 1884, forming the basis for national time-zone systems and international commerce.
1.2.4 Great Circles and Aviation
The shortest distance between two locations on a sphere, such as the Earth, is called a great circle. This path is formed by a plane slicing through the Earth through the two points and through the center of the Earth, resulting in a seemingly curved path on a map.
When making measurements on a sphere, the distance between two points is referred to as the great circle
2. Describing the Shape of the Earth
2.1 Ellipsoid/Spheroid
The actual shape of the Earth is complex, so we use a mathematical model to represent the Earth's surface. The Earth is a spheroid (not perfect sphere) slightly larger in radius at the equator than at the poles (Figure 10).
An ellipsoid (or spheroid) is like a sphere except that the major axis (equator) is larger than the minor axis (meridian passing through the North and South poles). However, the Earth is not a perfect ellipsoid. Different regions use different ellipsoids to model the curvature of Earth's surface accurately (Figure 11).
The earth is also lumpy, making it even harder to map
Different regions use a different ellipsoid to model the curvature of Earth's surface.
2.2 Geodetic Datums
A geodetic datum is a reference baseline for positions and mapping, representing the shape and size of the Earth. It is defined by specifying:
- The ellipsoid
- The coordinates of a base point
- The direction north
Datums can be horizontal or vertical:
Horizontal datums: measure a specific position on the Earth's surface using coordinate systems such as latitude and longitude. Examples include:
Vertical datums: measure elevations. A commonly used vertical datum is the geoid, which represents the mean sea level (MSL).
The geoid is a hypothetical Earth surface representing the MSL, considering variations in gravitational potential due to the Earth's mass distribution (Figure 13).
The word datum has multiple meanings:
Abstract coordinate system
A datum is a system that provides known locations for maps and surveys, and is used as a starting point for work such as construction surveys, property boundaries, and floodplain maps.
Horizontal datums measure positions (latitude and longitude) on the surface of the Earth, while vertical datums are used to measure land elevations and water depth
Lecture 3-2 Map Projections
1. What is a Map Projection?
Map projection: mathematical process of representing Earth's 3D curved surface on a 2D flat map.
Globes provide accurate Earth representation but are impractical for many uses.
Map projections make it possible to carry maps on paper or digital devices.
Locations on the spherical Earth are described using latitude and longitude.
On a flat map, locations are described using Cartesian coordinates (X & Y).
very projection distorts at least one aspect of the real world: shape, area, distance, or direction.
2. Are these good maps?
- Mercator Projection (Figure 2)
- Designed by Gerardus Mercator in 1569 for maritime navigation.
- Strengths and weaknesses:
- Eurocentric, places the northern hemisphere on top.
- Distorts polar regions, making Greenland appear larger than South America.
- Africa appears similar in size to Greenland, though it's 14 times larger.
- Common criticisms focus on size and placement distortions.
- McArthur’s Universal Corrective Map of the World (Figure 3)
- Created by Stuart McArthur, first published in 1979.
- South-up map, challenges the conventional north-up perspective.
- Highlights the arbitrary nature of map orientation.
- Peters Projection (Figure 4)
- Addresses size distortions of the Mercator projection.
- Preserves area but distorts shapes, especially in the tropics.
- Greenland and Alaska are shown in correct size relative to Mexico.
- Useful for comparing country sizes but not perfect in shape representation.
- General Criteria for a "Good" Map
- A good map serves its intended purpose accurately.
- McArthur’s map challenges perceptions of global orientation.
- Hundreds of projections exist, each distorting shape, area, distance, or direction.
- Projections preserve one or two properties or compromise between all.
- Scale and area size affect distortions.
- Tissot’s Indicatrix (Figure 5)
- Visualizes projection distortions using circles.
- Circles show distortions in area and shape when projected.
- Example map: shape and area preserved along the equator, distortion increases towards poles.
3. Categories of Map Projections
Least distorted at points of contact
- Projections by Surface
- Cylindrical
- Projects Earth onto a cylinder.
- Tangent or secant cases.
- Unwrapped to form a flat surface, least distortion along tangent or secant lines.
- cannot preserve both direction and shape
- Conical
- Projects Earth onto a cone.
- Tangent or secant cases.
- Least distortion along standard parallels.
- Planar (Azimuthal)
- Projects Earth onto a plane.
- Tangent or secant cases.
- Three classes based on focus: polar, equatorial, oblique.
- Shows accurate directions from the focus.
- Projections by Geometric Distortion
- Conformal
- Preserves shape (angles).
- Examples: Mercator, Lambert Conformal Conic.
- Equivalent (Equal-area)
- Preserves area.
- Examples: Peters projection, Sinusoidal projection.
- Equidistant
- Preserves distance from the center or along lines.
- Examples: Plate carrée, Azimuthal equidistant.
- Azimuthal (Zenithal)
- Directions from a central point to all other points
- Examples: Gnomonic, Lambert Azimuthal Equal-Area.
- Compromise
- Minimizes distortions in shape, area, distance, and direction.
- Examples: Robinson, Winkel Tripel.
4. What makes a projection good?
- Preservation of Earth's properties
- Area: Albers Equal Area.
- Shape: Lambert Conformal Conic.
- Direction: Lambert Azimuthal Equal Area.
- Distance: Specific lines.
Cannot perserve all 4
What should a good map do:
Meeting the map's purpose
- Choose a projection based on required spatial property accuracy.
- Conformal projections: important for angular relationships.
- Used in topographic maps, navigation charts, weather maps.
If your map requires that a particular spatial property be accurately represented, then a good projection must preserve that property. For example, use a conformal projection when the map's main purpose involves measuring angles, showing accurate local directions, or representing the shapes of features or contour lines. Conformal projections are typically used in:
- Equal-area projections: important for area representation.
- Used in population density maps, world political maps.
Minimizing distortion in the area of interest
- Tropical regions: cylindrical projection.
- Middle latitudes: conic projection.
- Polar regions: azimuthal projection.
Key Terms:
Map projection: a mathematical process of transforming a particular region of the earth's three-dimensional curved surface onto a two-dimensional map.
Tissot’s Indicatrix: circles used to visualize distortions due to a map projection. These circles are equal in area before projection, but distorted afterwards.
Projection surface: a simple geometric shape capable of being flattened without stretching, such as a cylinder, cone, or plane.
Cylindrical projection: a type of map projection that projects Earth onto a cylinder by touching the earth on one line or intersecting the earth through two lines
Conic projection: a type of map projection that projects Earth onto a cone that is either tangent to the Earth at a single parallel, or secant at two parallels.
Planar projection: a type of map projection that projects Earth's surface onto a flat plane by placing the plane at a point on the globe.
Conformal projection: a type of map projection where angles on the globe are preserved (thus preserving shape) on the map over small areas.
Equal-area/equivalent projection: a projection that preserves the relative size of Earth's regions.
Equidistant projection: a projection that preserves accurate distances from the center of the projection or along given lines.
Compromise projection: a projection that maintains a balance between distortions of shape, area, distance and direction, rather than perfectly preserving one geometric property at the expense of others.
Lecture 4-1 Coordinate Systems
1. Cartesian Coordinate System
Once map data are projected onto a two-dimensional surface (a plane), features must be referenced by a planar coordinate system instead of a geographic coordinate system. The geographic coordinate system (latitude-longitude), which is based on angles measured on a sphere, is not valid for measurements on a plane. Because degrees of latitude and longitude don't have a standard length, you can’t measure distances or areas accurately or display the data easily on a flat map or computer screen.
Therefore, a Cartesian coordinate system is used. A cartesian coordinate system is defined by a pair of orthogonal (x, y) axes drawn through an origin (Figure 1), where the origin (0, 0) is at the lower left of the planar section. Geographic calculations and analysis are done in Cartesian or Planar coordinates (x, y).
Compared to the geographic coordinate system, the biggest advantage of the Cartesian coordinate system is how it simplifies locating and measuring. Grid coordinate systems based on the Cartesian coordinate system are especially handy for map analysis procedures such as finding the distance or direction between locations or determining the area of a feature.
2. Universal Transverse Mercator (UTM) Coordinate System
2.1 UTM Basics
Universal Transverse Mercator (UTM) is the most commonly used global projected coordinate system. It is used by federal government agencies such as the USGS.
UTM uses a two-dimensional Cartesian coordinate system to give locations on the surface of the Earth. It extends around the world from 84oN to 80oS. The UTM system is not a single map projection. The system instead divides the Earth into 60 North-South zones covering the earth from East to West. Each zone has a central meridian and covers a six-degree band of longitude.
2.2 UTM Zone
UTM zones are numbered from 1 to 60 starting from 180° longitude at the International Date Line (Read more in Box 1) and proceeding eastward. Therefore, Zone 1 lies between the 180°W to 174°W longitude lines and is centered at 177°W; Zone 2 is between 174°W and 168°W longitude. Zone 60 covers longitude 174°E to 180°E (the International Date Line) (Figure 3). Each zone is also formatted with an "N" or "S" after the zone number, indicating whether the zone is in the North or South hemisphere. We will learn more about why this is done in the following sections.
The world is divided into 24 time zones, each of which is about 15 degrees of longitude wide, and each of which represents one hour of time (Figure B1.1). The numbers on the map indicate how many hours one must add to or subtract from the local time to get the time at the Greenwich meridian. For example, we can see that U.S. has four time zones, including East Day Time Zone in the east coast region, Central time zone in the central area, mountain time zone, and pacific time zone.
The International Date Line (IDL) is an imaginary line of longitude on the Earth’s surface located at about 180 degrees east (or west) of the Greenwich Meridian. The date line is shown as an uneven red vertical line in Figure B1.1: it marks the divide where the date changes by one day. It makes some deviations from the longitude 180-degree meridian to avoid dividing countries in two, especially in the Polynesia region. The time difference between either side of the International Date Line is not always exactly 24 hours because of local time zone variation.
2.3 UTM Eastings and Northings
Each zone has its own easting and northing values that cannot extend to other zones. Each zone has separate origins for the northern and southern hemispheres. To understand how these origins are specified, it is useful to understand a few terms and concepts.
2.3.1 Easting
In a UTM coordinate system, easting is the east-west x-coordinate, which is the distance from the origin. Easting varies from near zero to near 1,000,000 m. In both the northern and southern hemispheres, the center line (central meridian) of each zone has an easting value (x values) of 500,000 m to ensure that there are no negative values (Figure 5). This value, called false easting, is added to all x-coordinates so that there are no negative easting values in the zone. Since this 500,000m value is arbitrary. eastings are sometimes referred to as "false eastings".
2.3.2 Northing
Similarly, northing is the north-south y-coordinate in a projected coordinate system. In the northern hemisphere, a northing value of 0 m is assigned to the equator. Since no false northing value is added, a UTM northing value for a zone in the northern hemisphere is the number of meters north of the equator. In the southern hemisphere, false northing of 10,000,000 m is given to the equator so that all northing (y-axis) values are positive numbers.
Since the equator has different northing values for the northern and southern hemisphere, every location that lies exactly on the equator has two UTM coordinate pairs. For example, the coordinates for the intersection of the equator and the central meridian of UTM Zone 10 are written as follows:
500,000m E, 0m N (zone 10 North)
500,000m E, 10,000,000m S (zone 10 South)
Some examples of this concept:
A point south of equator with a northing of 7,587,834m N is 10,000,000 – 7,587,834 = 2,412,166m south of the equator.
A point 34m south of the equator has a northing of 9,999,966m N.
A point 34m north of the equator has a northing of 34m N.
The north-south distance between two points north of the equator with northings of 4,867,834m N and 4,812,382m N is 4,867,834 – 4,812,382 = 55452m. (Note: these calculations are only used to help you understand the difference between northing values in UTM northern and southern hemisphere. You will not need to calculate this for homework, quizzes, or exams.)
2.4 UTM coordinate formatting
UTM coordinates are simple to recognize because they usually have a six-digit integer as an easting value, followed by a seven digit integer as a northing value.
The first six-digit integer is the easting x-coordinate in meters
The second seven-digit integer is the northing y-coordinate in meters
The third value is the zone number and hemisphere
For example, the location of the State Capitol Dome in Madison, Wisconsin, in UTM is:
305,900m E, 4,771,650m N, Zone 16 North
2.5 UTM limitations
The near-global extent (UTM grid extends around the world from 84oN to 80oS) of the UTM grid makes it a valuable worldwide referencing system. The UTM grid is indicated on all recent USGS topographic maps. Most GPS vendors program the UTM into their receivers. However, UTM has limitations:
Suitable for medium-scale mapping but not national-level
Designed for areas with N-S extent, and thus not good for areas with a large E-W extent (good for areas that are taller than they are wide)
Distortions are relatively small, but still may be too large for specific purposes like high-accuracy surveying.
Distortions become especially problematic at high latitudes; this is part of why Canada, with giant swaths of Arctic territory, uses a Lambert Conformal Conic projection suited for mid- to high latitudes
UTM coordinates will differ when different datums are used
Zone boundaries follow meridians instead of political or natural boundaries. Thus, it usually takes more than one UTM zone to cover a state or country completely. For example, Wisconsin falls into Zones 15 and 16 (Figure 4).
3. State Plane Coordinate (SPC)
3.1 SPC Basics
The State Plane Coordinate (SPC) system was created in the 1930s by U.S. land surveyors as a way to define property boundaries in a way that would make them easier to measure. They are widely used by surveyors, engineers, planners, and state and local governments. They provide a common basis for assigning coordinate values to all areas of a State.
The idea was to completely cover the U.S. and its territories with grids laying over map projection surfaces so that the maximum scale distortion error would not exceed one part in 10,000. To support high-accuracy applications, each state is divided into one or more zones and all US states have adopted their own specialized state plane coordinate systems.
As a result, the United States was divided into 124 zones with each zone having its own projection. Most states have several zones, shown in Figure 7. Projections are chosen for different zones to minimize distortions. With few exceptions, all state plane zones are based on either the Lambert Conformal Conic Projection (Figure 7, in brown) or the Transverse Mercator Projection (Figure 7, in light grey) based on the Clarke 1866 ellipsoid and NAD 27 datum.
Lambert conformal conic projection is used for states of predominantly east-west extent. For example, Colorado is a Lambert state with three zones.
Transverse Mercator projection is used for states of predominately north-source extent, such as Arizona and New Mexico.
For states with more than one zone, the names North, South, East, West, and Central are used to identify zones. States without letters have only one grid zone, such as SC and NC. California is different from most states: it has seven zones all based on the Lambert Conformal Conic projection and its zones are numbered with Roman numerals.
3.2 SPC Origin
As mentioned earlier, UTM zone boundaries follow meridians instead of political or natural boundaries. However, here we can see that the SPC zone boundaries follow state and county boundaries. Each zone has its own central meridian that defines the vertical axis for the zone; this means that two different states have completely different reference systems. For example in Oregon, a northing of 5,000 meters does not tell us anything about how far we are from a point in Washington State.
An origin is established to the west and south of the zone, usually 2,000,000 feet west of the central meridian for Lambert conformal conic zones and 5,000,000 feet west of the central meridian for Transverse Mercator zones. Again, this is to prevent negative coordinate values. The central meridian has an easting value of 2,000,000 ft for Lambert conformal conic zones, and an easting value of 5,000,000 ft for Transverse Mercator zones. The origin for northings in each zone is a parallel just south of the counties in the zone, called the latitude of origin. The intersection of the parallel and central meridian has a northing of 0 feet.
To illustrate this, let's look at Oregon (Figure 8). It uses the Lambert conformal conic projection for both the north and south zones. The central meridian is the same for both zones, with an easing of 2,000,000 feet in the original system. In Figure 8 the two red dots indicate the latitudes of the origins: the North Zone's origin is located at the top red dot, and the South Zone's origin is at the bottom red dot.
4. Coordinate Determination On Maps
Along the margins of most maps, you will find one or more sets of coordinates that reference locations on the earth's surface. For example, Figure 9 shows a USGS 1:24,000-scale topographic map, where three types of coordinates are provided: SPC feet, UTM in meters, and latitude/longitude degrees. The map has UTM grid lines spaced every kilometer or 1000 meters. The vertical grid lines determine East-West position and the horizontal grid lines determine North-South position.
In SPC, states of greater north-south extent use which projection?
Group of answer choices
Lambert conformal conic projection
Transverse Mercator projection
KEY TAKEAWAYS:
Cartesian coordinate system: a coordinate system that specifies points on a plane using a pair of numerical coordinates, which are distances from an origin point.
Universal Transverse Mercator (UTM): a two-dimensional cartesian coordinate system that records locations on the surface of the Earth. It divides the Earth into 60 zones, with each covering a six-degree band of longitude. It uses a secant transverse Mercator projection in each zone.
Easting: the east-west x-coordinate; defined as the distance from an origin in a projected coordinate system.
Northing: the north-south y-coordinate in a projected coordinate system.
State plane coordinate (SPC) system: a set of 124 geographic zones or coordinate systems designed for specific regions of the U.S. Each state contains one or more state plane zones, the boundaries of which usually follow county lines.
Origin of SPC zone: a point established to the west and south of the SPC zone with easting and northing values of 0.
Lecture 4-2 Map Scale
1. What is map scale?
1.1 The purpose of map scale
Earth is big. Maps are small. If your map is to cover a large area, then everything on the map has to be shrunk from its real size. We use scale to indicate distance so that we can cover a reasonable area of the region and display it on paper or a screen.
Map scale expresses the relationship between distances on the map and their corresponding ground distances. Using map scale, measurements made on a map can be converted to ground units. In other words, we are able to know the real distance between two places by measuring their distance on the map using simple tools like a ruler.
A map is meaningless without a scale. For example, in Figure 1, both maps show a view of Middle Earth (the fictional setting of the Lord of the Rings books). But the left map doesn't have a scale, while the right map has a scale bar. Suppose we want to know the distance between the center of Rohan and the center of Gondor. Looking at the left map we might say, "Well, it seems quite close on the map." However, with the map on the right, we can use the scale bar at the bottom to calculate the real distance in miles. We will do this later in this lecture.
1.2 Types of map scale
There are three standard options for representing scale: representative fraction (RF), verbal scale, and scale bar.
1.2.1 Representative fraction (RF)
Representative fraction (RF) is the ratio between a distance on the map and actual ground distance. The representative fraction can be written in the format as either 1/x or 1:x , where the numerator is always 1 and the denominator (x) represents distance on the ground.
1/50,000 or 1:50,000
Above is the representative fraction 1 to 50,000. This means that one unit on the map equals 50,000 units on the ground.
Note that an R.F. has no units (inches, centimeters, etc.), which means that an R.F. scale can be compared between different maps. If you choose to measure in inches, one inch on the map represents 50,000 inches on the ground. If you choose to measure in centimeters, one centimeter on the map represents 50,000 centimeters on the ground.
1.2.2 Verbal scale
Another way to express scale is the verbal scale. It uses words to describe the ratio between the map's scale and the real world. This is the easiest scale to understand because it generally uses familiar units.
There are many ways to express scale verbally. For example, here are three ways to indicate the map scale of 1 inch to 2 miles.
1 inch to 2 miles
1 inch equals 2 miles
1 inch = 2 miles
Converting an R.F. scale to a verbal scale is very easy: simply select ONE unit and apply it to BOTH map and ground numbers. A representative fraction of 1:63,360 can be expressed with the verbal scale "1 inch to 63,360 inches." Since 63,360 inches are equal to 1 mile, you can also express this as '1 inch to 1 mile."
How about 1:72,000?
1:72,000 means that one inch on the map equals to 72,000 inches on the ground (or, remember you can use another unit: "one centimeter equals 72,000 centimeters" would also work). Now we need to convert the small unit (in this case, inch) on the ground distance to some common large unit (e.g., miles). Assuming we want to use mile as the unit, then we just divide 72,000 by 63,360 (since 1 mile = 63,360 inches):
Therefore, we may express the R.F. scale 1:72,000 as “1 inch to 1.1361 miles” on a verbal scale.
(Note: YOU CANNOT MIX UNITS in an R.F.! Doing so will change the numerical relationship of the R.F.)
1.2.3 Scale bar
A scale bar, sometimes also called graphic scale, uses a bar or line to represent a scale. It is usually divided into several segments. It is a graphic ruler printed on the map. Figure 2 shows some scale bars: note that there are two scale bars on this map. The upper one shows a long line that means the length of the line represents 10 miles (63,360 inches) on the earth. The lower one shows a shorter line that means the length of the line represents 10 kilometers on the earth. Both lines are divided into intervals of 5 and 1.
There are several good reasons to use a graphic scale.
a) A scale bar is a straightforward, easy way to determine distances on a map.
b) A scale bar changes size in proportion to the physical size of the map.
The first two methods (RF and verbal scale) would be ineffective if the map is reproduced by a method such as photocopying, which may change the size of the map. If the map size changes, the scale is lost: an inch measured on a smaller/enlarged map does not equal an inch on the original map. A graphic scale solves this problem because it doesn't change size if the map changes size; the map reader can use it with a ruler to determine distances on the map.
In the U.S., a graphic scale often includes both metric and imperial units. If a map’s size changes after scanning, photocopying, or enlargement on a screen, the scale bar is also enlarged or reduced; this means it's still accurate and can be used to measure map distance. As long as the size of the graphics scale is changed along with the map, it will be accurate.
For example, Google Maps uses a scale bar which resizes when you zoom in or out. Figure 3 shows two views of Madison: the first figure shows a full view of the Madison area, which has a line segment with the word "2 mi" in the bottom right corner. This is a scale bar. It means that in the current view, the length of the line on this map represents 2 miles on the ground. As we zoom in to get more details of the University of Wisconsin-Madison, the scale bar resizes. In the right figure, the scale bar now shows that the length of the line represents 2,000 feet on the ground.
1.3 Large scale vs. small scale
Choice of scale is important for the cartographer to accurately portray the correct amount of details on the map.
A small scale map shows a large area with few details.
A large scale map shows a small area with more details.
Figure 4 shows two views of the same location but at different scales. In the small scale map on the left, the features are pretty small. Only major highways, cities, and counties are shown. In the large scale map on the right, only Chicago is covered, but it provides much more detailed information such as local streets, roads, parks, and rivers.
A large scale map is referred to as "large" because the representative fraction (e.g. 1/25,000) is a larger fraction than one on a small scale map. A small scale map may have an RF of 1/250,000 to 1/7,500,000. Large scale maps will have an RF of 1:50,000 or greater (i.e. 1:10,000).
1.4 Transitioning between scales
In a paper map, the scale is FIXED.
In a computer-based map or a web-based map, the scale is DYNAMIC and changeable.
A typical GIS system (like Google Maps) would include a series of maps with different scales. The maps are carefully designed so that when you zoom in or out, the content remains legible and clear (so the transitions between scales are smooth). We saw this in Figure 3.
As the map scale becomes larger – and as the area becomes smaller – the accuracy of measurements made on the map typically increases. As you zoom in on the map, more geometric detail and additional information are shown. The six maps in Figure 6 show different levels of detail for a hydrologic map of the Austin area in the state of Texas. The rivers that are lines at smaller scales (the upper maps) become more detailed polygons at larger scales (the lower maps). Small creeks are not displayed in the small scale maps at the top but are shown in the large scale maps at the bottom. There are also more stream labels as the map scale increases. In the last two large scale maps, full street networks are displayed.
2. How can we calculate map scale?
There are three steps to calculate map scale:
1) Measure the distance between any two points on the map. This distance is the map distance (MD).
2) Determine the horizontal distance between these same two points on the ground. This distance is the ground distance (GD).
3) Use the representative fraction (RF) formula, and remember that RF must be expressed as:
RF = 1/x = MD/GD
3. How does map scale influence map content and appearance?
3.1 Scale and generalization
Scale influences generalization and symbolization of geographic features on the map.
Map generalization is the elimination of map detail as the scale decreases. As the scale of the area decreases, some geographic features must be eliminated from the map.
Now let’s look at an example in Figure 7. In a large scale map, say 1:5,000, every building, road, and the river is displayed. Decreasing the map scale to 1:500,000 means we can no longer display every building, road, and river; cities are now indicated by colored patches crossed by fewer lines. If we continue to decrease the map scale to 1:5,000,000, cities will be displayed as simple dots.
3.2 Mismeasurement (not required)
Another effect of the map scale is uncertainty in the size and shape of geographic features.
Take a look at Figure 8: suppose the coast of Britain is measured using a 200 km ruler, specifying that both ends of the ruler must touch the coast. Now cut the ruler in half and repeat the measurement, then repeat again with another shorter ruler. It has been demonstrated that the measured length of coastlines and other natural features appear to increase as the unit of measurement (the ruler) is decreased.
It's important to remember that any measurement you take of a geographic feature, it's size, shape, height, or anything else, cannot be perfectly accurate.
In summary: map scales introduce other kinds of distortion such as generalization of features, and mismeasurement, which, along with distortion brought by map projections, all contribute to the total map distortion. In addition to these distortions, the way we represent Earth’s surface through symbolization adds another source of error. For example, when would you use a straight line or a curvy line to represent a stream?
Map scale: the mathematical relationship between distances on the map and their corresponding ground distances
Representative fraction: the ratio between map and ground distances
Verbal scale: a type of map scale that expresses the relationship between map distance and ground distance using words
Scale bar: a map element used to graphically represent the scale of a map. A scale bar is typically a line or a bar, segmented like a ruler and marked in units proportional to the map's scale
Map generalization: the elimination of map details as scale decreases
Lecture 5-1 GPS Basics
1. Fundamentals of GPS System
1.1 The origin of GPS
Historically humans found their direction by landmarks, but this was very unreliable.
Since World War II, LORAN (long-range navigation) has been used for marine navigation. LORAN uses radio signals from multiple transmitters that are used to determine the location and speed of the receiver. It is good for sailing, but its utility is limited within coastal areas.
During the 1960s, the U.S. Navy used a system called Transit, which determined the location of sea-going vessels with satellites. The drawback of Transit was that it didn’t provide continuous location information—you would have to wait a long time to locate your position rather than always knowing where you were. The Naval Research Laboratory Timation program was another early satellite navigation program of the 1960s, which used accurate clock timings for ground position determination from orbit.
Because of these limitations, the Department of Defense (DOD) finally said: “We need something better for navigation: all-day, all-night, and covers all terrain.”
After spending 12 billion dollars, the global positioning system (GPS) was devised and implemented in the early 1990s. GPS is also called NAVSTAR (Navigation System, Timing and Ranging), which is the official U.S. DOD name for GPS. It is a satellite-based navigation system with global coverage (GNSS) and can provide accurate positioning 24 hours a day anywhere in the world. Right now, GPS is provided free of charge by US.
The core of GPS is a constellation of satellites. The first satellite in the system was launched in 1978. The twenty-fourth GPS satellite was launched in 1993. The system was declared fully operational in April, 1995.
1.2 GPS components
The GPS consists of 3 main components: space segment, control segment, and user segment.
The Space Segment is a constellation of satellites for broadcasting positioning signals.
The Control segment is a set of ground stations for monitoring, tracking, and correcting those signals.
The User Segment is composed of all GPS devices that receive its signals, like your smart phone, handheld GPS, or car navigation system.
These three segments are organized and administered separately, but work together to make up GPS.
1.2.1 Space Segment
The space segment is a constellation of GPS satellites positioned in medium earth orbit at an altitude of 20,200 km (12,552 miles) above the earth’s surface. GPS satellites broadcast a set of signals down to the Earth. These signals contain information about 1) the position of the satellite, and 2) the precise time at which the signal was transmitted from the satellite.
The GPS constellation is composed of 24 satellites. All satellites are divided into 6 orbital planes. There are 4 satellites in each plane. Figure 4 shows the structure of the GPS satellite constellation: the 6 orbital planes are shown in colored circles, and the colored points lay on the circles are individual satellites. The orbits are at about 20,200 km. The inclination angle of the orbital planes with respect to the equator is 55.
1.2.2 Control Segment
The control segment of GPS represents a series of worldwide ground control stations that track and monitor the signals being transmitted by the satellites. These control stations are spread out to enable continuous monitoring of the satellites.
A control station monitors the signals from the satellites and sends correction information back to the satellite (Figure 5). The control stations also transmit satellite data to the master control station at Schriever Air Force Base, in Colorado Springs (Figure 6). Right now the control system consists of five ground stations including the master station: Colorado Springs (where the master control station is located), Kwajalein, Diego Garcia, Ascension Island, and Hawaii.
1.2.3 User segment
The user segment of the GPS represents a GPS receiver somewhere on Earth that is receiving signals from the satellites. Each GPS receiver also has a clock and a processor to “decode” the satellite’s signals. Depending on the unit, the receiver may also have a graphical display to show location and speed information. Figure 7 shows some examples of GPS receivers.
1.3 Other GNSS
other countries have developed (or are in the process of developing) their own versions of GPS, presumably to not be completely dependent on U.S. technology. Here are some examples:
GLONASS was the name of the USSR’s counterpart to GPS and operated in a similar fashion. It provides an alternative to Global Positioning System (GPS) and is the only alternative navigational system in operation with global coverage and of comparable precision. GLONASS consisted of a full constellation of satellites with an orbital setup similar to GPS. By 2001, however, there were only a few GLONASS satellites in operation, but Russia now has a renewed program and more GLONASS satellites have been launched.
Galileo: the European Union’s version of GPS, which, when completed, is projected to have a constellation of 30 satellites and operate in a similar fashion to GPS.
COMPASS (BeiDou-2): China’s version of GPS currently under construction. The system will be a constellation of 35 satellites.
2. How does GPS find a location?
2.1 GPS positioning steps
Satellites send signals containing location and time to the GPS receiver.
The GPS receiver searches and obtains signals from at least three satellites. The more satellites it finds, the higher accuracy it can achieve.
The GPS receiver a) calculates its distance to the satellites, and b) determines its location using the method of “trilateration”.
2.2 Calculating distance between satellite and receiver
In order to find your current position, an GPS receiver first calculates the distance from its location to each satellite using the equation below:
Distance = time delay * speed of light
Satellite radio waves travel at approximately the speed of light: 180,000 miles per second. This is the "speed of light" in the equation. For the "time delay", the satellite signal contains information about the satellite’s status, orbit, time (T), and location it's broadcasting the signal from. When PS receivers get the signal, it records the current time (T1) and also gets the time the signal was sent from the satellite (T). The time delay can be calculated by subtracting the time when the signal was sent from the time the signal was received, or: T1 - T.
Let's look at an example illustrated in Figure 9: a GPS receiver received the signal at T + 3, and also knew that the signal was sent at T. This means the distance can be calculated by:
Distance = t * c = 3 x 180,000 miles per second = 540,000 miles
2.3 Determining the location of receiver (Trilateration)
After find out the distances between the receiver and satellites, a technique called “trilateration” is used to determine exact position. In order to perform Trilateration, signals from at least 3 satellites are required. However this only gives you the horizontal location of a point on the Earth's surface, and this is called a two-dimensional fix (2D fix). Most of the time, a fourth satellite is used to improve the accuracy and help to provide a three-dimensional fix (3D fix), which includes elevation. In order to understand trilateration, let's start by looking at a simpler version - 2D trilateration.
2.3.1 2D Trilateration
Trilateration in two dimensions is commonly used when plotting a location on a map.
Imagine that you are on a trip and arrive in an unknown location. You are lucky to find three persons who provide you enough information to calculate where you are (Figure 10):
The first person you bump into tells you (somewhat unhelpfully) that you are 50 miles away from City A (Figure 10). That puts you somewhere on a circle (the green circle in Figure 10) sweeping outward 50 miles from City A. This isn't very useful information; you could be anywhere on the green line.
The second person tells you (again, not being overly helpful) that you’re located 60 miles away from City B. This puts your location somewhere on a circle 60 miles from City B—but when you combine this with the information that places you 50 miles away from City A, you can narrow your location considerably. You are either at p1 or p2.
Luckily, the third person you see tells you that you’re 50 miles from City C. You will notice that p2 is the only option that fits all three of the distances from your reference points, so you can disregard p1 and be happy that you're not lost anymore.
2.3.2 3D Trilateration
The same concept applies to GPS. Rather than locating yourself relative to three other points on a map, the GPS receiver is finding its distances relative to three satellites. Also, since a position on a 3D Earth is being found with reference to positions surrounding it, a spherical distance is calculated rather than a flat circular distance. This process is referred to as trilateration in 3D (or 3D trilateration).
GPS is based on satellite ranging, i.e. finding the distance between GPS receiver and satellites. In this situation satellites are precise referenced points (just like the cities A, B, and C we used in the Figure 10), which means the receiver knows the exact locations of the satellites. We will determine our distance from the satellites (section 2.2).
Suppose we receive a signal from one satellite (Figure 11, first panel) and we calculate that it is 12,000 miles from our current position. Therefore, we know that we are somewhere on the surface of sphere which has a diameter of 12,000 miles and satellite 1 at its center.
We also know that we are 11,000 miles from satellite 2. Now we can narrow it down to the points where the two spheres intersect (Figure 11, second panel).
If we also know that we are 11,500 miles from satellite 3 (Figure 11, third panel) we can further narrow it down further: we have to be at one of two points where three spheres intersect (the two yellow dots in figure 11 panel 3). However only one point, located on Earth's surface, is possible (the other point is in outer space, and we at least know we're not there!)
3. Errors and Limitations of GPS Systems
3.1 Sources of GPS errors
GPS has been designed to be as accurate as possible, but there are still errors. Table 1 shows some examples of the source of errors and the amount of error contributed by each source.
Table 1. Sources and amount of errors in GPS system
Error source | Amount of Error |
Satellite clocks | 1.5 to 3.6 meters |
Atmospheric conditions - Ionosphere | 5 to 7 meters |
Atmospheric conditions - Troposphere | 0.5 to 0.7 meters |
Multipath | 0.6 to 1.2 meters |
Selective availability | Eliminated by May 2000 |
Typically with an ordinary civilian receiver, like your smart phone, the accuracy of GPS would be about 15 meters (or less) in the horizontal direction.
3.1.1 Satellite clocks
Both satellites and receivers need a clock to record time. The satellite's clocks can contain errors. The role of the receiver and satellite clocks is very important in calculating precise locations (Section 2.2). We need to know the time when a signal was sent from the satellite and the time when the signal reached to the receiver. Therefore we need to synchronize the receiver's clock with the satellite's clock. However inevitable inaccuracies in determining time means there will be an error of about 1.5-3.6m in determining the receiver's location.
3.1.2 Selective availability (SA)
The U.S. Department of Defense, worried about enemies making use of GPS, instituted Selective Availability (SA) with the goal of intentionally making the positioning information less accurate. This intentional degradation of GPS signals is called selective availability. When SA was active, civilian GPS receivers could only get position accuracy within 100 meters. This, naturally, limited GPS applications in the civilian sector – who wants to try to land an airplane using GPS when the runway's location could be 100 meters off?
SA proved costly to the DOD during the 1991 Gulf War and the 1994 Haiti campaign, because the military quality GPS devices were in short supply. After the Gulf War, the U.S. Army announced it would install GPS in all armored vehicles to help minimize friendly fire incidents (which were a major source of casualties in Operation Desert Storm) caused by armored unit commanders lost in the featureless Iraqi desert or out of position during ground attacks.
In 2000 the Pentagon deactivated SA. However the U.S. military still controls GPS and SA could be reactivated at any time.
3.1.3 Atmospheric conditions
The atmosphere is one of the largest sources of error due to atmospheric refraction. The satellites send signals to GPS receivers, but particles in the atmosphere can alter the speed of signal and cause delays. This causes inaccurate measurements of the time delay.
3.1.4 Multipath errors
Multipath errors occur when GPS satellite signals reflect off surfaces, such as trees or buildings, before they reach the GPS receiver (Figure 12). These reflections delay the signal and cause inaccuracies. Multi-path is the greatest source of error in forests lands and is the most difficult to combat. Other causes of multipath error include: topography (hills and valleys), tall buildings, vehicles, cliffs, tree canopies, and other structures that obstruct the line of sight between the receiver and the satellites.
3.2 Ways to minimize errors
Very slight inaccuracies in time (hundredths of seconds) can skew location information by thousands of miles. To obtain the highest accuracy using GPS, one needs a clear view of the sky at all times, and the GPS signal has to be able to avoid trees, buildings, and other obstructions that could cause multipath errors. You also want signals from the maximum number of satellites with the best viewing geometry possible. In fact these criteria are almost impossible to satisfy, and there are other ways to improve the accuracy of GPS positioning, e.g. Differential GPS (DGPS), Wide Area Augmentation System (WAAS), and Local area system (LAAS)
3.2.1 Differential GPS (DGPS)
Differential GPS (or DGPS) uses a series of base stations at specific locations on the ground to provide a correction for GPS position determination.
A base station receives satellite signals, and its position is very precisely documented. Since correct, highly accurate coordinates of the base station are known, the base station can calculate a correction to compensate for errors between the exact location and calculated location from GPS. Then the base station will broadcast this correction out to receivers. Thus, when you are using DGPS, your receiver is picking up the usual four satellite signals plus an additional correction from a nearby base station (Figure 13).
3.2.2 Wide Area Augmentation System (WAAS) (not required)
Wide Area Augmentation System (WAAS) is a satellite-based, new “real-time” DGPS correction method, developed by the Federal Aviation Administration (FAA) to obtain more accurate position information for aircraft.
WAAS operates through a series of 25 base stations spread throughout the United States that collect and monitor the signals sent by the GPS satellites. These base stations calculate position correction information (similar to the operation of DGPS) and relay correction information to the master control station. Master control station will then transmit this correction to a WAAS satellite.
These WAAS satellites then broadcast this correction signal back to Earth. The correction information can help GPS receivers remove signal errors, and it allows for significant increases in accuracy and reliability. If your receiver can pick up the WAAS signal, you can determine your position accuracy can reach 3 meters. However, like with regular GPS, obstructions can block this signal.
Figure 14 shows how WAAS works: it includes geostationary WAAS satellites that can receive and broadcast correction signals, 25 WAAS control stations across the west and east coasts of the U.S., and receivers in aircraft. The aircraft receiver gets both GPS signals and correction signals from the WAAS satellites.
Another system for improving GPS positioning accuracy is the local area system (LAAS), which is used for aircraft approaches and landings. Combined, these two systems can provide seamless navigation coverage for aircraft.
GPS (as normally available to the civilian user) provides a nominal fix accuracy of
Group of answer choices
100 meters with Selective Availability enabled.
Key ideas:
Global Positioning System (GPS): a space-based satellite navigation system that provides location and time information in all weather conditions, anywhere on or near the Earth where there is an unobstructed line of sight to four or more GPS satellites.
Space segment: a constellation of 24 satellites that broadcast positioning signals.
Control segment: a set of ground control stations for monitoring, tracking and correcting signals broadcast by GPS satellites.
User segment: GPS receivers for receiving signals.
Trilateration: The process used by GPS to determine the location of a receiver by measuring the distances to three or more satellites.
Selective availability (SA): the intentional degradation of GPS signals by the U.S. military. SA was turned off in 2000.
Differential GPS: a correction method that uses a series of base stations at known locations on the ground to provide a correction of GPS positional information.
Distance = time delay * speed of light (i.e., signal)
Lecture 5-2 GPS Application
1. Why do we use GPS?
Why do we use GPS? There are many reasons: it provides accurate positioning, it can get people to their destinations, it's cheap...
Right now a standard civilian GPS receiver offers accurate positions within a few meters of error while costing less than $100. The availability of GPS receivers played a major role in the “geospatial revolution” – over 80% of data collected now has a geospatial component, and GPS is one of the most important technologies used to collect high quality geospatial data.
Generally GPS has made many processes more efficient, added comfort to our life, and helped in emergency response and health services. Let's first look at two stories:
Example 1: Why can't we walk straight?
So without eyes we can't walk or drive straight. Even if your eyes are open and you're in an unknown place, what if I ask you to walk to an unfamiliar park? You can always ask for directions. But with a smartphone, which always comes equipped with a GPS receiver, you can find it yourself.
Example 2: Korean Airline Flight 007 air crash
On September 1, 1983, Korean Airlines Flight 007 was scheduled to fly from New York City to Seoul via Anchorage, Alaska. The plane was shot down by a Soviet interceptor over the Sea of Japan (Figure 1). An investigation revealed that the pilots had set their starting point wrong, and the error was magnified as they flew. To avoid such disasters, and to provide safer landings, the Federal Aviation Administration asked Stanford to test an airborne GPS system, which would have kept the plane on course and out of the Soviet Union's air defense area.
2. Functions and applications of GPS
GPS has five basic functions: navigation, location, timing, mapping, and tracking (Figure 2), which are widely applied in both public and private sectors such as the military, industry, transportation, recreation, and science. Many applications use a combination of the above functions. Let's go through each function and check out some real-world examples.
2.1 Navigation
Navigation is the process of getting from one location to another. This is what GPS was designed for: it allows us to navigate on water, air, or land; it allows planes to land in the middle of mountains and helps medical evacuation helicopters take the fastest route.
While GPS is today used in all corners of our life, it was originally conceived and developed by U.S military. The military used it to help their aircraft and ships navigate. They also used it to guide weapons (i.e. missiles) to kill.
GPS is also used in automated cars, which allows robots to drive instead of humans. In 2011 the state of Nevada passed the first law allowing automated cars to drive on the roads. Automated vehicles are able to travel the same streets and highways as human drivers, with only a red license plate marking them as robots.
Google's self-driving car is a project to develop technology for autonomous cars. In May, 2014, Google released a new prototype of the driverless car, which is equipped with two seats and no steering wheel, and runs at 25mph (Figure 3). Watch this video (A first driverLinks to an external site.) to learn more about this project.
2.2 Locating
GPS is the first system that can give accurate and precise location information anytime, anywhere and under any weather conditions. Some examples are:
Measuring the movement of volcanoes and glaciers.
Measuring the growth of mountains.
Measuring the location of icebergs - this is very valuable for ship captains to avoid possible disasters.
Storing the location of where you were - most GPS receivers on the market will allow you to record a certain location. This allows you to find these points again with minimal effort and is useful in hard-to-navigate areas such as dense forest.
Tsunamis, also called seismic sea waves or tidal waves, are caused by earthquakes, submarine landslides or submarine volcanic eruptions. Faster tsunami warnings could be issued using GPS data alongside earthquake detection technology. Traditional seismic instruments, on which current warning systems are based, take a long time to accurately assess an earthquake's strength. However, GPS stations can measure large vertical changes in ground elevation in real time. Therefore, GPS data, when added to preliminary seismic data from the same location, could help cut the time lag from 20 minutes to three minutes.
2.3 Timing
Although you might not notice it, GPS brings precise time to us all. GPS satellites carry an atomic clock that contributes very precise time data to GPS signals. The accuracy is measured in nano seconds, which is 100 billionths of a second.
This incredibly accurate time information is used in many applications that rely on perfect synchronization. For example, communication systems, electrical power grids, and financial networks all rely on precision timing for synchronization and operational efficiency. With the GPS timing function, we can all synchronize our watches and make sure international events are actually happening at the same time.
2.4 Mapping
GPS can also be used to create maps by recording a series of locations as well as useful information. This function is used by scientists to collect field data, as well as by industrial and governmental bodies in making geospatial policy.
Here is an example where researchers used GPS-tagged tweets (also known as geotagged tweets), to identify what neighborhoods in San Fransisco are most visited by outsiders. They argue that neighborhoods where outsiders tweet a lot are susceptible to short term gentrification. Gentrification is the process whereby rents in a neighborhood increase due to wealthier residents moving into lower income areas, leading to displacement of low-income communities. Combining this data with other conventional demographic information (income, race, rental prices etc.) the researchers identify neighborhoods where the city can intervene to ward off, stop or slow down the rate of displacement caused by gentrification.
2.5 Tracking
You might have seen this in action movies: the suspect or witness is wearing a small disguised GPS receiver which continuously sends its position to the police. In fact you may have used this yourself: the "Find my phone" app tracks the location of your phone at all times.
Tracking is a way of monitoring people and things such as packages, or moving vehicles. In transportation, GPS is also used to monitor traffic flow by tracking taxis and personal cars.
Another example: GPS-equipped shoes can be used to help patients suffering from Alzheimer’s disease (Figure 5). Another case is to locate missing children. The idea is that if a child was kidnapped or wandered off while wearing GPS-equipped shoes, watches, or a cell phone, you could easily track them down. You can also use GPS system to track your pet.
3. Other issues with GPS
3.1 Privacy concerns
GPS can serve as a surveillance technology with privacy implications. In February 2020, the Wall Street Journal reported that the U.S. government, including Immigrations and Customs Enforcement, was buying sensitive location data from commercial databases in order track people suspected of immigration violations. However, the Supreme Court has argued that government agencies cannot gain access to location data without a search warrant granted by a judge. Still, law enforcement agencies continue to track people using GPS without obtaining search warrants. GPS raises serious concerns about the emergence of the "surveillance state," a situation where government rules by constantly monitoring its citizens, with or without their consent.
3.2 GPS Addiction
Using GPS to navigate has become second nature for many drivers. This can go very wrong: blindly following GPS directions can put you on top of a mountain, or unable to go forward or turn around. Over-reliance on GPS navigation systems can be a serious problem (Figure 6).
Even though GPS is very helpful in determining your location in an unfamiliar area, this information isn't perfectly reliable. GPS companies might be relying on old maps with roads that have been closed or don’t actually exist. This can cause you to follow an incorrect or even dangerous route. Always be skeptical of routes provided by your GPS and trust local sources for direction
Navigation: the process of getting from one location to another based on transportation information.
Atomic clock: a timekeeping device that uses an atom's electronic transition frequency in the microwave, optical, or ultraviolet region of the electromagnetic spectrum as a frequency standard for its timekeeping element. The most accurate way to keep time, it is used in GPS to ensure accurate positioning.
Lecture 6-1 Aerial Photography
1. The history of Aerial Photography
remote sensing is the process of obtaining information ("sensing") without physical contact ("remote"). In geography and environmental sciences, remote sensing refers to technologies that measure objects on Earth surface through sensors onboard aircraft or satellites. Sensors are instruments that receive and measure electromagnetic signals. Human eyes are sensors that receive light and convey image information to the brain. A digital camera has a sensor that receives light and captures pictures. But the sensors used in remote sensing are more complex and specially designed to measure electromagnetic signals at different wavelengths. Airborne sensors are mounted on aircraft and capture images of Earth's surface from the sky. These images are called aerial photographs. Spaceborne sensors are onboard satellites, and the images collected by satellites are called satellite images
Humans have been capturing images of the ground from the sky for over 200 years. Advancements in sensors were coupled with the developments of aerial platforms (the vessels or instruments from which the images are taken, Figure 1) that could be used to take images. Balloons and birds (specifically pigeons) were commonly used before airplanes. Nowadays airplanes and satellites are the major platforms for taking pictures of Earth's surface. Also UAVs (unmanned aerial vehicles) have become frequently used platforms in military and civilian remote sensing applications.
2. How are Aerial Photos Taken?
Aerial photos are obtained by flying aircraft along flight lines (the paths that the aircraft follow), north-south or east-west (Figure 4). Photos are taken along straight flight lines with 60% to 80% overlap, that is each individual photo overlaps its neighbor by 60-80%. Typically more than one flight line is required to cover the area to be mapped, and adjacent flight lines get a 20%-30% side overlap to ensure no gaps in the coverage. This overlap allows for 3D viewing of aerial photographs using the principle of stereopsis.
3. Aerial Photograph Categories
3.1 Based on photo color
Electromagnetic spectrum
In high school physics courses, we learned that light is made of "electromagnetic (EM) waves." Our eyes perceive light in different colors, which correspond to different EM wavelengths. For example when we see a red car, it means the EM energy reflected from the car is in the red wavelengths (620-750mm), while other wavelengths are absorbed by the car. However human eyes and most common cameras cannot see a wide range of EM wavelengths. Of the entire EM spectrum, visible light (the part we can see) is only a tiny portion (Figure 6). Sensors used in remote sensing are much more sensitive than our eyes. They can detect EM energy in both the visible and non-visible areas of the spectrum. In this section you will find some aerial photos that are similar to the regular photos taken by the camera in your phone, but others are quite different.
Panchromatic photo
Panchromatic (meaning "all-colors") photos record or capture electromagnetic energy in the 300 to 700 micrometer (nm) wavelength, including all visible portions of light (Figure 6). Panchromatic aerial photos are usually in grayscale (that is, they are black and white aerial photos). The more visible light gathered by the camera, the lighter the tone in the final photo (Figure 7).
True color photo
True color photos look the similar to the photos you take with camera or phone. They capture three major wavelength of visible light - red, green, and blue. These colors are composited together in the digital imager or film (Figure 7) in such a way that red light is displayed in red, green light is displayed in green, and blue light is displayed in blue.
Color infrared (CIR) photo (false color image)
Another distinctive type of aerial photo is color infrared (CIR), captured using film or a digital sensor that is sensitive to both visible and infrared light (Figure 6). Infrared energy is invisible to our eyes, but is reflected very well by green, healthy vegetation. In CIR photos near-infrared (NIR) energy is displayed in the color red, red light is displayed with the color green, and green light is displayed in the color blue (Figure 8). Blue light is not shown in the image, as it is filtered out by the sensor or film (Figure 8). Color infrared photos are a type of false color imagery. The use of near-infrared energy helps to highlight vegetation: as you can see in Figure 7, all the green vegetation (near-infrared) is colored red in the CIR photo.
Comparison between panchromatic, true color, and CIR photos
Usually it's easier to interpret true color than black-and-white photos; color photos show features in the same colors we see through our eyes, and capture the colors uniquely associated with landscape features. For example: green represents vegetation such as trees or grass.
The most obvious difference between true color and color infrared photos is that in color infrared photos vegetation appears red (Figure 9). Red tones in color infrared aerial photographs are always associated with live vegetation and the lightness or intensity of the red color can tell you a lot about the vegetation itself; its density, health and how vigorously it is growing. Dead vegetation will appear as various shades of tan, while vivid, healthy green canopies appear bright red. Color infrared photographs are typically used to help differentiate vegetation types (Figure 10)
3.2 Based on photo geometry
When taking an aerial photo with a camera or sensor on an airplane, the shooting angle matters. The angle is usually defined by the camera axis, which is an imaginary line that defines the path light travels to hit the camera lens or sensor. Depending on the camera's position and the camera axis angles with respect to the ground, aerial photographs can be vertical, low oblique or high oblique (Figure 11).
Vertical aerial photo
Vertical aerial photographs are photos taken from an aerial platform (either moving or stationary) where the camera axis is truly vertical to the ground (Figure 11). Typically, vertical photos are shot straight down from a hole in the belly of the airplane. Vertical photographs are mainly used in photogrammetry and image interpretation (Figure 12).
Oblique aerial photo
Oblique aerial photographs are photos taken at an angle, which means that camera axis is tilted away from vertical (Figure 11).
Low Oblique photographs are typically taken from 300-1,000 feet above the ground, at a 5-30 degree angle, through the open door of a helicopter. This is a good way to show the facade of a building without showing too much of the roof. The most detailed images of this type are low-altitude aerial photos (Figure 12).
High Oblique photographs are taken from 8,000-13,000 feet above the ground from an airplane, at a 30-60 degree angle, from an open window of the airplane. This is a good way to show areas from 2-20 square miles. Photos taken at high altitudes (1,500-10,000 feet) provide less environmental information since the image scale is much smaller, but high-altitude high-oblique photos have a distinct advantage: more ground area can be imaged in a single photo.
In a high oblique photo the apparent horizon is shown. In a low oblique photo the apparent horizon is not shown. Often because of atmospheric haze or other obstructions, the true horizon of a photo cannot be seen (Figure 12).
3.3 Orthophotos
Relief displacement
On vertical air photos, the scale of the photo will most likely be distorted radially away from its center. Tall objects (such as steep cliffs, towers, and buildings) have a tendency to “bend” outward from the center point toward the edges of the photo - this effect is called relief displacement. The geometric center of the photo is called THE principal point.
For example in Figure 13, when we look at the photo’s principal point, it is like looking straight down at the ground. However if you look outward from the principal point you will see that the tall buildings seem to be leaning away from the center of the photo.
Another example is a photo of the Washington Monument (Figure 14). Why does the Washington Monument seem to lean differently in these images? The reason is that the amount of relief displacement in air photos is influenced by the height of the camera above the ground and the angle of the camera. The left image is taken using a higher oblique angle in a lower position. Therefore the relief displacement is much larger. Typically, the higher the aircraft and the smaller the angle between the ground and the camera, the less severe the relief displacement.
Orthophoto
The effects of relief displacement can be removed from the aerial photograph by the rectification process to create an Orthophotograph (or Orthophoto). Orthophotos are vertical aerial photographs which have been geometrically "corrected". The rectification process removes relief displacement. An orthophoto is a uniform-scale photograph. Since an orthophoto has a uniform scale, it is possible to measure the ground distance on it like you would on a map. An orthophoto can also serve as a base map onto which other map information can be overlaid.
Because most GIS programs can perform rectification, aerial photography is an excellent data source for many types of projects, especially those that require spatial data from the same location over a length of time. Typical applications include land-use surveys and habitat analysis. Large sets of orthophotos, typically taken from multiple sources and divided into "tiles" (each typically 256 x 256 pixels in size), are widely used in online map systems such as Google Maps. OpenStreetMap offers the use of similar orthophotos for deriving new map data. Google Earth overlays orthophotos or satellite imagery onto a digital elevation model to simulate 3D landscapes.
For example, Figure 15 shows two air photos of Tenth Legion, Virginia. The left is a vertical aerial photo without rectification, while the right one is an orthophoto where the relief displacement has been removed. We can see that power line running over the hills is shown as a straight line in the orthophoto, while it appears curved in the left photo due to relief displacement.
4. Are They Maps?
Let's review some definitions:
Aerial photograph: Images/photos taken from cameras/sensors mounted on aircraft.
Satellite imagery: Images taken from sensors mounted on satellites.
Orthophoto: Images in which distortion from the camera angle and topography has been removed and corrected.
Many people think that these images are the same as maps, but they are NOT. Maps are representational drawings of Earth's features while images are actual pictures of the Earth.
Maps have uniform scale, which means that the map scale at any location on the map is the same.
Maps are orthogonal representations of the earth's surface, meaning that they are directionally and geometrically accurate (at least within the limitations imposed by projecting a 3-dimensional object onto 2 dimensions).
Maps use symbols to represent the real world, while aerial photos, satellite images, and orthophotos show actual objects on Earth's surface.
Aerial photos have non-uniform scale, and can display a high degree of radial/relief distortion. That means the topography is distorted, and until corrections are made through rectification, measurements made from a photograph are not accurate. Nevertheless aerial photographs are a powerful tool for studying the earth's environment since they show actual features and not just symbols.
Orthophotos and some satellite imageries have been geometrically "corrected", and therefore have uniform scales. However, while you may be able to see roads on these image, they are not labeled as roads. You must interpret what you see on an image because it is not labeled for you. Therefore, they are NOT maps.
Key Terms
aerial photography: the technique and process of taking photographs of the ground from an elevated position
aerial photo: photos or images taken by sensors on board aircraft or other platforms above Earth's surface
mosaicking: the process of merging different photos from each flight line into one big aerial photo
electromagnetic spectrum: the range of all possible wavelengths of electromagnetic radiation/energy
panchromatic photo: records electromagnetic energy in visible wavelengths and displays it in grayscale/black & white
true color photo: photos that are displayed with red light in red, blue light in blue, and green light in green (how your eyes perceive color)
color infrared photo: photos that display near infrared light in red, red light in green, and green light in blue. In these photos green plants look red.
vertical aerial photo: photos taken from an aerial platform (either moving or stationary) where the camera axis is truly vertical to the ground
oblique aerial photo: photo taken by a camera at an angle; the camera's axis is inclined away from vertical
principal point: the geometric center point of the photo
relief displacement: effect seen in photos where tall objects (such as cliffs, towers) have a tendency to bend outward from the principal point towards the edges of the photo
orthophoto: aerial photos which have been geometrically rectified, correcting and removing the effects of relief displacement
Lecture 6-2 Image Interpretation
1. Elements of image interpretation
Photo or image interpretation is the process of extracting qualitative and quantitative information from a photo or image using human knowledge or experiences.
Most of the time, one can recognize many features on a photo without any training. This is particularly true if you are familiar with the area in the photo. But many objects look quite different from above, and differentiating between similar objects can be difficult. For an instance, distinguishing tree species or crop types (such as wheat vs. corn) does not come easily. Interpreting features in aerial photos is a skill that takes study and practice to develop.
There are eight elements/clues used in image interpretation (Figure 1).
Tone/color -- lightness/darkness/color of an object
Texture -- coarse or fine, such as in a corn field (distinct rows) vs. wheat field (closely-grown plants)
Shape -- square, circular, irregular
Size -- small to large, especially compared to known objects
Shadow -- objects like buildings and trees cast shadows that indicate vertical height and shape
Pattern -- many similar objects may be scattered on the landscape, such as oil wells
Site -- the characteristics of the location; for example, don't expect a wetland to be in downtown Chicago
Association -- an object's relation to other known objects -- for example, a building at a freeway off-ramp may be a gas station based on its relative location
1.1 Tone/color
Tone refers to the relative brightness or color of objects in an image. Generally, tone is the fundamental element for distinguishing between different targets or features. For example, Figure 2 shows different crops in agricultural fields: you can tell there are many crops in different stages of growth from the variety of shades of green.
In a panchromatic image (which, as we learned in the last lecture, is displayed in black and white) tone is the brightness of a particular object. Objects in a panchromatic image reflect unique tones according to their reflectance. For example, dry sand appears white, while wet sand appears black. In black and white near-infrared images, water is black and healthy vegetation is white to light gray.
Color is more convenient for the identification of object details. For example, vegetation types and species can be easily distinguished using color information. Sometimes color infrared photographs or false color images will give more specific information, depending on the filter used and the object being imaged.
1.2 Size
Size is information about the length and width of objects in the image. The relative size of objects in an image can offer good clues to what they are.
In this example (Figure 3), there is a middle school located next to houses. Can you tell which is the school complex and which are the houses? Large buildings in the bottom right corner suggest that they are part of a school complex, whereas small buildings would indicate residential use (single-family homes).
1.3 Shape
Shape refers to the general form, structure, or outline of individual objects. Shape can be a very distinctive clue in image interpretation. For example, agricultural fields and man-made features (e.g., urban or agricultural features) tend to have straight lines, sharp angles, and regular forms while natural features (e.g., forest edges) are generally more irregular. Roads can have turns at right angles, while railroads do not.
In the Figure 4, you can locate a river because it does not follow a straight line, whereas the straight feature (right image) is a man-made canal.
A vertical aerial photograph shows clear shapes of objects as viewed from above. The crown of a conifer tree looks like a circle, while that of a deciduous tree has an irregular shape. Airports, harbors, factories and so on, can also be identified by their shape.
1.4 Pattern
The arrangement of individual objects may create a distinctive pattern. For example, rows of houses or apartments, regularly spaced agricultural fields, interchanges of highways etc., can be identified by their unique patterns.
This is most apparent for man-made features: city street grids, airport runways, agricultural fields, etc. Patterns in the natural environment may also be noticeable, for example bedrock fractures, drainage networks, etc.
Man-made features such as cities tend to have very regular patterns, while natural features do not have regular patterns. In Figure 5, the left image shows a common street pattern with regularly spaced houses, and the right image shows irregular drainage patterns in the mountains.
1.5 Texture
Texture is a micro image characteristic. It describes the frequency of change and arrangement of tones in particular areas of an image. The texture of objects can be identified as fine (smooth) or rough (coarse).
The visual impression of smoothness or roughness of an area can be a valuable clue in image interpretation. For example water bodies are typically fine textured, while grass is medium (homogeneous grassland exhibits a smooth texture), and brush is rough (e.g., coniferous forests usually show a coarse texture), although there are always exceptions.
Coarse textures (Figure 6) would consist of a mottled tone where the tone changes abruptly over a small area, whereas smooth textures would have very little tonal variation
Texture also refers to grouped objects that are too small or too close together to create distinctive patterns. Therefore, texture is a group of repeated small patterns. Examples include tree crowns in a forest canopy, individual plants in an agricultural field, cars in a traffic jam, etc. The difference between texture and pattern is largely determined by photo scale.
1.6 Shadow
Shadow is also helpful in interpretation: it can provide an idea of the profile and relative height of a feature, which makes it easier to identify.
Trees, buildings, bridges and towers are examples of features that cast distinctive shadows. Figure 7 (left) is an image of buildings in downtown San Francisco. Shorter buildings have smaller shadows while taller buildings have longer shadows. Figure 7 (right) is an overhead view of two pyramids showing the large shadows they cast, which is characteristic of tall features.
1.7 Site, situation & association
Site represents the location characteristics of a feature, while association means relating a feature to other nearby features.
Sometimes objects that are difficult to identify on their own can be understood from their association with objects that are more easily identified. For examples, commercial properties may be associated close to major transportation routes, whereas residential areas would be associated with schools, playgrounds, and sports fields.
In the pictures (Figure 8), can you tell which image is a mountain lake and one is a high desert lake? What are the features around the lake that helped you figure it out?
Because of the color and texture, we know that there are trees and vegetation around the lake in the left figure, so it's likely a mountain lake. The lake in the right figure is surrounded by bright sand and little vegetation, which tells us that it is a desert lake.
Key Terms
image interpretation: the process of extracting qualitative and quantitative information from a photo or image using human knowledge or experiences.
tone: the relative brightness or color of objects in an image
texture: the frequency of change and arrangement of tones in particular areas of an image
site: the location characteristics of an item in the image
association: relation between an object and other nearby features in an image
Lecture 7-1 Satellite Remote Sensing Fundamentals
1. What is Satellite Remote Sensing?
1.1 Definition
“Remote sensing is the art and science of obtaining information about an object without being in direct physical contact with the object.”
The National Oceanic and Atmospheric Administration (NOAA) provides another definition which fits better with this course:
"Remote sensing is the science and technology of obtaining information about objects or areas from a distance, typically from aircraft or satellites."
As a tool that provides data and information about Earth's surface, remote sensing is a key component of geospatial technologies.
1.2 Satellites
Satellite remote sensing means sensors aboard satellites capture "pictures" of Earth's surface.
Does the word "satellite" remind you of an action movie scene? A computer expert taps a keyboard while the view from a spy satellite zooms in to a clear view of the building where their target is hiding? You might have an impression that remote sensing satellites can move to track any target and zoom in to read a license plate. In fact, remote sensing satellites for civilian use are not that mysterious and a little more complex.
Typically in remote sensing we categorize the satellites by the type of orbits they operate in, such as geostationary orbit, polar orbit, and sun-synchronous orbit.
In a geostationary orbit, a satellite travels at the same speed as the Earth's rotation, which means it monitors the same place on Earth all the time (Figure 1). Many weather satellites are in geostationary orbit so they can continuously collect information about the same area.
1.3 The advantages of remote sensing
Traditionally, people collect geospatial information through field sampling or surveys. For example to make a topographic map, geographers need to work for months or even years in the study area to make measurements. With the aid of remote sensing and Geographic Information System (GIS), we can now collect global topographic information for both land and ocean over days instead of years. Compared to traditional data collecting methods, remote sensing has the following advantages:
1. It is capable of rapidly acquiring up-to-date information over a large geographical area.
2. It provides frequent and repetitive looks of the same area.
3. It is cheap with less labor input.
4. It provides data from remote and inaccessible regions, like deep inside deserts.
5. The observations of remote sensing are objective.
Remote sensing has redefined maps. Google Earth is a good example: map users todays enjoy high-resolution aerial and satellite imagery covering the entire Earth. Figure 2 shows an example of how remote sensing imagery helps our understanding of the world. With a high resolution image as a background, Google Earth highlights a massive engineering project in Dubai. (What is the biggest different you find between these two images?
2. How does Satellite Remote Sensing Work?
2.1 Physical basis: electromagnetic radiation
Remote sensing measures the electromagnetic radiation reflected by objects. Electromagnetic radiation of different wavelengths has different properties. Wavelengths are expressed in units like micrometers or nanometers. A micrometer (um) is one-millionth of a meter (roughly the size of a single bacterium). A nanometer is one-billionth of a meter. The electromagnetic spectrum is used to describe the characteristics of electromagnetic waves at different wavelengths (Figure 3).
The electromagnetic spectrum (Figure 3) shows the range of all possible wavelengths of electromagnetic radiation. The electromagnetic spectrum goes from shorter wavelengths (gamma and x-rays) to longer wavelengths (microwaves, broadcast radio waves). There are several regions of the electromagnetic spectrum which are useful for remote sensing.
The light which our eyes can detect is part of the visible spectrum. The visible light portion of the spectrum is at wavelengths between 0.4 and 0.7 micrometers (400-700 nanometers). The longest visible wavelength is red and the shortest visible wavelength is violet. Common wavelengths of what we perceive as particular colors are listed below.
Violet: 0.4 - 0.446 micrometers
Blue: 0.446 - 0.500 micrometers
Green: 0.500 - 0.578 micrometers
Yellow: 0.578 - 0.592 micrometers
Orange: 0.592 - 0.620 micrometers
Red: 0.620 - 0.7 micrometers
Blue, green, and red are the primary visible wavelengths, and most remote sensors are equipped to detect energy at these wavelengths. Visible wavelengths are useful in remote sensing to identify different objects. Combining information from visible and near infrared wavelengths, scientists are able to assess changes on Earth, i.e. damage from earthquakes or volcanic eruption, and land cover changes in cities, neighborhoods, forests, and farms.
Infrared
Infrared radiation is very important to remote sensing. Infrared wavelengths range from approximately 0.7 to 100 micrometers, which is more than 100 times as wide as the visible portion of the spectrum. The infrared (IR) region can be divided into two categories based on their properties - the near IR and the far/thermal IR.
Near IR radiation is used in ways very similar to visible radiation. The near IR covers wavelengths from approximately 0.7 um to 3.0 um. Near IR is particularly sensitive to green vegetation. Green leaves reflect most of the near infrared radiation they receive from the sun. Therefore, most remote sensors on satellites can measure near infrared radiation, which lets them monitor the health of forests, crops, and other vegetation.
The thermal/far IR covers wavelengths from approximately 3.0 um to 100 um. Thermal IR energy is more commonly known as "heat." Objects that have a temperature above absolute zero (-273 C) emit far IR radiation. Therefore, all features in the landscape, such as vegetation, soil, rock, water, and people, emit thermal infrared radiation. In this way, remote sensing can detect forest fires, snow, and urban areas by measuring their heat.
Microwave
The microwave region is 1 mm to 1 m. This covers the longest wavelengths used for remote sensing. In your daily life you use microwave wavelengths to heat your food. In remote sensing, microwave radiation is used to measure water and ozone content in the atmosphere, to sense soil moisture, and to map sea ice and pollutants such as oil slicks.
2.2 Remote sensing process
A. Energy Source or Illumination - The first requirement for remote sensing is to have an energy source which illuminates or provides electromagnetic energy to the target of interest.
a. The main source used in remote sensing is the sun. Most visible light sensed by satellites is reflected solar radiation.
b. Sometimes the electromagnetic radiation is generated by the remote sensing platform. Some remote sensors emit microwave radiation to illuminate the object and measure the reflected microwave radiation; this is also known as radar.
c. The energy can also be emitted by the object itself. All objects on Earth emit thermal infrared radiation, which can be detected by remote sensors.
B. Radiation passes through the Atmosphere - as the energy travels from its source (e.g. the sun) to the target, it will interact with the atmosphere it passes through. Another energy/atmosphere interaction takes place as the energy travels from the target to the sensor.
C. Interaction with the Target - once the energy makes its way to the target through the atmosphere, it interacts with the target depending on the properties of both the target and the radiation.
D. Recording of Energy by the Sensor - after the energy has been reflected by, or emitted from the target, the sensor onboard the satellite collects and records the electromagnetic radiation.
E. Transmission, Reception, and Processing - the energy recorded by the sensor has to be transmitted to a receiving station where the data are processed into an image (hardcopy and/or digital).
F. Interpretation and Analysis - the processed image is interpreted, visually and/or digitally, to extract information about the target.
G. Application - the final element of the remote sensing process is achieved when we use the information extracted from the imagery to find new information or to solve a particular problem.
2.2.1 Source of Electromagnetic Energy (Illumination)
Depending on the type of illumination source used, we can divide sensors into passive remote sensing and active remote sensing
Passive remote sensing measures energy that comes from an external source such as sun or the target itself. If the energy comes from the sun and is reflected by the target, satellite sensors can only perceive the target when it is illuminated by the sun. Naturally there is no reflected energy available from the sun at night. Energy that is emitted directly from the object (such as thermal infrared energy) can be detected day or night, as long as the amount of energy is large enough to be recorded by the sensor.
Active remote sensing, on the other hand, provides its own source for illumination. The sensor emits radiation toward the target and measures the radiation reflected from that target. Advantages of active sensors include the ability to obtain measurements 24 hours a day. Active sensors can be used to examine wavelengths that are not sufficiently provided by the sun, such as microwaves, or to better control the way a target is illuminated. Some examples of active sensors are laser range-finding, radar, and lidar (which is like radar but uses laser pulses instead of microwaves or radio waves).
2.2.2 Radiation and the Atmosphere
Before the Sun's radiation reaches the Earth's surface, it has to travel through the atmosphere. Particles and gases in the atmosphere can affect the radiation passing through it. A portion of the Sun's EM energy never reaches Earth's surface, and thus can't be recorded by satellite sensors. This is because the atmosphere contains gases that absorb EM energy of different wavelengths; these gases include nitrogen dioxide (NO2), oxygen (O2), carbon dioxide (CO2), ozone (O3), and water vapor (H2O). For example ozone absorbs radiation in the ultraviolet wavelengths; thus the atmosphere protects you from harmful "UV rays." Water vapor and carbon dioxide absorb some portions of the IR spectrum. Most of the radiation in the visible part of the EM spectrum (visible light) is not absorbed by these atmospheric gases, and so it reaches Earth's surface and is reflected by the objects.
2.2.3 Interaction with the Target
After interacting with the atmosphere, some EM radiation finally makes it to Earth’s surface and interacts with our targets. One of three things can happen to that energy (on a wavelength-by-wavelength basis): it can transmit through the target, it can be absorbed by the target, or it can be reflected off the target.
Transmittance occurs when energy simply passes through a surface. Think of light passing through a windshield of a car.
Absorption occurs when energy is trapped and held by a target.
Reflection: Most of the radiation not absorbed is reflected back into the atmosphere, some of it towards the satellite. This upwelling radiation undergoes another round of scattering and absorption as it passes through the atmosphere before finally being detected and measured by the sensor.
Here are two examples of how different objects on Earth's surface interact with solar radiation:
Trees and Leaves (Figure 6)
- A chemical compound in leaves called chlorophyll strongly absorbs radiation in the red and blue wavelengths of visible light, but reflects green wavelengths. Hence leaves appear "greenest" in the summer, when chlorophyll content is at its maximum. In fall, there is less chlorophyll in the leaves, so there is less absorption and more reflection of the red wavelengths, making the leaves appear red or yellow (yellow is a combination of red and green wavelengths).
- Near infrared wavelengths also interact with leaves. As you saw in previous videos, the cell structure of healthy leaves enhances the reflection of near infrared radiation. In figure 6 you can see how green and infrared energy is reflected by leaves, while the red and blue energy is absorbed.
Water (Figure 7)
- Typically, water reflects much less radiation than other objects; this means water always looks dark in remote sensing images. Longer wavelength (i.e. red and infrared) radiation is absorbed more by water than shorter visible wavelengths. Thus water typically looks blue or blue-green due to stronger reflectance at these short wavelengths, and darker if viewed at red or near infrared wavelengths. If there is suspended sediment present in the upper layers of the water, the water will appear brighter. Chlorophyll in algae absorbs more of the blue wavelengths and reflects the green, making the water appear greener.
2.2.4 Spectral signature
The above examples show how different objects have different absorption and reflection properties at different wavelengths. We call these properties the "spectral signature" of an object. Think of it this way: we have our own unique signature that we use for identification, like when you sign a credit card receipt. In the same way, each type of object on Earth's surface has a unique spectral signature. To describe a spectral signature we usually graph the object's reflectance vs. wavelength (Figure 8). Reflectance describes the fraction energy reflected by an object. The higher the reflectance, the brighter the object would look in remote sensing images. In Figure 8 we can see water has an overall low reflectance in visible wavelengths and zero reflectance in other wavelengths. Green vegetation has very high reflectance in near infrared. We can distinguish different objects in remote sensing images by comparing their spectral signatures.
2.2.5 Recording and processing of remote sensing image
After traveling through the atmosphere again, the radiation reflected or emitted from Earth's surface are recorded by the remote sensors on the satellites. These signals are then presented in the form of images, which might look like photos captured by your digital camera. These images are composed of "pixels" (Figure 9). Each pixel corresponds to a location on Earth, and each has a value indicating the amount of energy being measured by the sensor. More explicitly: each value represents the average brightness in a certain wavelength for a portion of the surface, represented by little square units (pixels) in the image. Figure 9 shows that as we zoom in on the remote sensing image, we can clearly see these tiny squares (pixels), each with a number indicating the level of energy reflected. In the next lecture we will explore the properties of satellite and remote sensing images.
2.2.6 Composite Multi-band Images
When looking at photos on computer screens, each pixel's color corresponds to three values of red, green, and blue. For a remote sensing image, those values are the brightness values of each of those three wavelengths. In remote sensing these wavelengths are called "bands" which each cover a range of wavelengths in the electromagnetic spectrum. For example the red band corresponds to wavelengths between 0.62 - 0.7 micrometers. The displayed colors, either red, green, or blue, are called "channels." Any of the bands of an image can be displayed in any of the channels. As there are only three color channels on a computer screen (red, green, blue), only three bands can be displayed at the same time in a color composite image.
A true color image, as we learned in Aerial Photography, is an image where red band is displayed in the red channel, the green band is displayed in the green channel, and the blue band is displayed in the blue channel. This makes a color composite that looks very similar to how our eyes perceive the world. Figure 10 shows a view of New York City's Central Park. The trees and lawns are green, the lake is blue and the roofs of buildings are bright, which is the same thing you'd see if you were in an airplane flying above the park.
In remote sensing, a typical color composite (like in near infrared aerial photos) is to display the near infrared band in the red channel, the green band in the blue channel, and the red band in the green channel. Figure 11 shows how this is done. The three images of different bands (near infrared, red, and green) are displayed in red, green, and blue channels respectively. Combining these grey-scale images gives us a color image. As we discussed before, vegetation reflects most near infrared radiation, and therefore vegetation appears bright in the near infrared band. As near infrared is displayed in the red channel, vegetation looks bright red in the final image.
Key Terms
remote sensing: the science of obtaining information about objects or areas from a distance, typically from aircraft or satellites
geostationary orbit: an orbit where the satellite travels at the same speed as Earth's rotation, which means it is always monitoring the same region of Earth.
polar orbit: a type of orbit where satellites pass above or nearly-above both poles of the Earth and make several passes per day.
sun-synchronous orbit: a type of near-polar orbit where satellites always pass the same location on Earth's surface at the same local time.
electromagnetic spectrum: the range of all possible wavelengths of electromagnetic radiation/energy
infrared: the portion of the electromagnetic spectrum from approximately 0.7 to 100 micrometers
visible wavelengths: the wavelengths between 0.4 and 0.7 micrometers; energy at these wavelengths are visible to human eyes.
microwave: the region of the electromagnetic spectrum from approximately 1 to 1,000 millimeters.
passive remote sensing: a type of remote sensing technology where the sensor measures EM energy reflected by the target that originates from an external source such as sun or the target itself.
active remote sensing: a type of remote sensing technology where the sensor provides its own energy source for illuminating the target, and then detects the reflected energy.
transmittance: when an electromagnetic (EM) wave passes straight through an object
absorption: when EM energy is trapped and held by an object rather than passing through or reflecting off it.
reflection: the change in direction of a wave at an interface between two different media so that the wave returns into the medium from which it originated. In remote sensing, it is the process where EM energy is reflected back to the atmosphere instead of being absorbed or transmitted by the object.
spectral signature: the properties of an object as described by its absorption and reflection properties at different wavelengths
pixels: tiny uniform regions that make up a remote sensing image, each with its own unique value
band: a range of wavelengths detected by a remote sensor (e.g. green band, near-infrared band)
channel: the displayed color (red, green, or blue) on electronic screens. Different bands can be displayed in different channels, as in color composite images.
Lecture 7-2 Remote Sensing Application
1. Capabilities of Sensors: Resolution
A satellite sensor has three characteristics that define its capabilities: spatial resolution, temporal resolution, and spectral resolution.
1.1 Spatial resolution
Spatial resolution is a measure of the smallest object or area on the ground that can be detected by the sensor. If a sensor has a spatial resolution of 10 meters, it means that one pixel in an image from the sensor represents a 10x10 meter area on the ground.
A sensor’s spatial resolution will affect the detail you can see in an image. In Figure 1 you can see how a sensor with a 0.5 meter spatial resolution can detect much more detail than a sensor with spatial resolution of 10 meters. In the 20x20 meter resolution image, you can't see the houses or buildings. The reason is that only one or two pixels on the image represent one house, and one or two pixels do not form any shape that we can recognize as a house. Figure 2 demonstrates how a house can or cannot be recognized in images of different resolutions.
Images where only large features are distinguishable have low resolution, while in high resolution images, small objects can be detected. Generally speaking, the higher the resolution of an image, the more detail it contains. Commercial satellites provide imagery in resolutions ranging from less than a meter to several kilometers. We will introduce some commercial and public satellites and sensors in section 2.
1.2 Temporal resolution
Temporal resolution is the revisit period of a satellite sensor for a specific location. It is the length of time for a satellite to return to the exact same area at the same viewing angle. For example, Landsat needs 16 days to revisit the same area, and MODIS needs one day.
If a satellite needs less than 3 days to revisit the same place, we would say it has high temporal resolution. A high temporal resolution image is required to monitor conditions that can change quickly or require rapid responses (i.e. hurricanes, tornadoes, or wildfires). If a satellite needs 4-16 days to revisit the same place, it has medium temporal resolution; if it takes more than 16 days to revisit the same place, it has low temporal resolution.
1.3 Spectral resolution
Spectral resolution specifies the number of spectral bands -- portions of the electromagnetic spectrum -- that can be detected by the sensor. For example (Figure 3), if a sensor is measuring the visible portion of the spectrum and treating the entire 0.4 to 0.7 micrometer range as if it was one band, it will produce a black & white image. However, if a sensor (Figure 3) is treating the visible portion of electromagnetic spectrum as three individual bands including the “blue” band from 0.4 to 0.5 micrometer, “green” band from 0.5 to 0.6 micrometers, and “red” band from 0.6 to 0.7 micrometers, it will produce a color image.
The finer the spectral resolution, the narrower the wavelength ranges for a particular channel or band.
High spectral resolution: ~200 bands
Medium spectral resolution: 3~15 bands
Low spectral resolution: ~3 bands
Based on the bands that the sensor can detect, they are classified into three categories (Figure 4):
Panchromatic sensor: a sensor measuring the visible portion of the spectrum and treating the entire 0.4 to 0.7 micrometer range as a single band.
Multi spectral sensor: a sensor that measures several broad bands. For example, we can divide the visible and near-infrared portions of the spectrum into four bands: blue, green, red and a near-infrared band.
Hyperspectral sensor: a sensor that measures many narrow contiguous bands. A hyperspectral sensor can sense over 200 bands.
1.4 Resolution trade-offs
Because of technical constraints, there are always limiting factors in spatial, temporal, and spectral resolution for the design and utilization of satellite sensors. For example, high spatial resolution is always associated with a low temporal and spectral resolution, and vice versa.
One of the reasons is related to the "swath" of the satellite. As you see in the previous video, as the satellite revolves around the Earth, the sensor "sees" a certain portion of the Earth's surface. The part of the surface imaged by the sensor is referred to as the swath (Figure 5). With a narrow swath, the sensor needs to orbit the earth many times to completely cover the whole globe, which means long revisit times and lower temporal resolution. At the same time, if the swath is narrow, it means the sensor scans a small area each time, which allows it to sense at a high spatial resolution. However, to achieve a higher temporal resolution, the swath size needs to be increased. In the same way, a large swath size means that spatial resolution has to be reduced as a compromise.
As a result remote sensors are always designed with trade-offs. Figure 6 shows the spatial and temporal resolution of several current satellite remote sensing systems. You can see that some sensors have high temporal resolution, but low spatial resolution, like GOES, AVHRR, and MODIS. Some of them have low temporal resolution and high spatial resolution. There are also some with medium spectral, temporal, and spatial resolution, like Landsat and SPOT. However there are none with high resolutions in all three aspects.
2. Examples of remote sensing programs
Hundreds of remote sensing satellites have been launched by many countries for various applications. Figure 7 shows some of the NASA (National Aeronautics and Space Administration of USA) earth observation satellites. These satellites were launched with the primary mission of systematic and long-term measurement of Earth's surface and atmosphere. Other satellites launched by governments are used for weather forecasting. Commercial companies can also launch satellites for commercial and public use. Most of these satellites features very high resolution images that can be used in both the private and public sectors. In this section we will mainly introduce five remote sensing satellites/sensors/missions, which are either commonly applied in scientific research and public services or represent the latest technology.
2.1 EOS: NASA Earth Observation System
Over the last decade NASA had launched many satellites to help us understand Earth's systems responses to natural and human-induced changes; this helps us predict and observe climate change, weather patterns and natural hazards. One of the most well-known programs is the Earth Observing System (EOS), which is a constellation of satellites that measure the clouds, oceans, vegetation, ice, and atmosphere of the Earth. EOS has three flagship satellites, Aqua, Terra and Aura, which are equipped with fifteen sensors
Terra was launched in 1999 as a collaboration between the United States, Canada and Japan, and continues its remote sensing mission today. "Terra" means Earth in Latin, which is an appropriate name for the satellite; its instruments measure the natural processes involved with Earth’s land and climate (Figure 8).
Aqua was launched in 2002 as a joint mission between the United States, Brazil and Japan. In Latin "Aqua" means water, indicating that the main purpose of the satellite is to examine Earth’s water cycle (Figure 8). Aqua's main goal is to monitor precipitation, atmospheric water vapor, and the ocean. Terra and Aqua were designed to work in concert with one another. Both Aqua and Terra carry a MODIS and a CERES sensor, which in essence doubled the data collection of these these sensors and increased their temporal resolution.
Aura was launched from Vandenberg Air Force Base on July 15, 2004. The name "Aura" comes from the Latin word for air. Aura carries four instruments, which obtain measurements of ozone, aerosols and key gases in the atmosphere (Figure 8).
2.2 Suomi NPP: the next-generation Earth observation satellite
The Suomi National Polar-orbiting Partnership (NPP) is the first satellite launched as part of a next-generation satellite system which will succeed the Earth Observation System (EOS). Suomi NPP launched on Oct. 28, 2001 from Vandenberg Air Force Base in California. It is named after Verner E. SuomiLinks to an external site., a meteorologist at the University of Wisconsin - Madison. Suomi NPP is in a sun-synchronous orbit 824 km above the Earth. It orbits the Earth about 14 times a day and images almost the entire surface. Every day it crosses the equator at about 1:30 pm local time. This makes it a high-temporal resolution satellite.
There are five sensors aboard Suomi NPP:
• Advanced Technology Microwave Sounder (ATMS)
ATMS is a multi-channel microwave radiometer. It is a passive sensor, which means it measures the microwave radiation of the sun reflected by objects on Earth's surface. ATMS has 22 bands and is used to retrieve profiles of atmospheric temperature and moisture for weather forecasting. These measurements are important for weather and climate research.
• Visible Infrared Imaging Radiometer Suite (VIIRS)
VIIRS is a sensor that collects visible and infrared imagery of the land, atmosphere, cryosphere, and oceans. It has 9 bands in visible and near IR wavelengths, 8 bands in Mid-IR, and 4 bands in Long-IR, which makes it a high-spectral resolution sensor. VIIRS has about 650 m - 750 m spatial resolution, and images the entire globe in two days. VIIRS data is used to measure cloud and aerosol properties, ocean color, sea and land surface temperature, ice motion and temperature, fires, and Earth's albedo. Climatologists use VIIRS data to improve our understanding of global climate change. For example, VIIRS captured a view of the phytoplankton-rich waters off the coast of Argentina (Figure 9). The Patagonian Shelf Break is a biologically rich patch of ocean where airborne dust from the land, iron-rich currents from the south, and upwelling currents from the depths provide a bounty of nutrients for the grass of the sea—phytoplankton. In turn, those floating sunlight harvesters become food for some of the richest fisheries in the world.
• Cross-track Infrared Soundear (CrIS)
CrIS is a fourier transform spectrometer with 1,305 spectral channels in far infrared wavelengths. It can provide three-dimensional temperature, pressure, and moisture profiles of the atmosphere. These profiles are used to enhance weather forecasting models, and they will facilitate both short- and long-term weather forecasting. Over longer timescales, they will help improve understanding of climate phenomena such as El Niño and La Niña.
• Ozone Mapping Profiler Suite (OMPS)
OMPS measures the global distribution of the total atmospheric ozone column on a daily basis. Ozone is an important molecule in the atmosphere because it partially blocks harmful ultra-violet light from the sun. OMPS enhances the ability of scientists to measure the vertical structure of ozone (Figure 10), which is important in understanding the chemistry of how ozone interacts with other gases in the atmosphere.
• Clouds and the Earth's Radiant Energy System (CERES)
CERES is a three-channel sensor measuring the solar-reflected and Earth-emitted radiation from the top of the atmosphere to the surface. The three channels include a shortwave (visible light) channel, a longwave (infrared light) channel, and a total channel measuring all wavelengths. These measurements are critical for understanding climate change.
2.3 Landsat Program: the longest continuous Earth-observation program
2.3.1 History of the Landsat Program
The Landsat satellites were launched and managed by NASA and USGS for long-term continuous Earth surface observation. The first satellite in the program (Landsat 1) launched in 1972. Since then Landsat satellites have collected information about Earth's surface for decades. The mission is to provide repetitive acquisition of medium resolution multispectral data of the Earth's surface on a global basis. The data from the Landsat spacecraft constitute the longest record of the Earth's continental surfaces as seen from space. It is a record unmatched in quality, detail, coverage, and value for global change research and has applications in agriculture, cartography, geology, forestry, regional planning, surveillance and education. Table 1 and Figure 11 show the history of the program.
Landsat 5, launched on March 1st, 1984, provided data for 29 years before retirement. It provided the longest continuous Earth observation records with 30 meter spatial resolution, 16-day revisit time, and 7 spectral bands that are essential to monitor changes on Earth's surface.
After the failure of Landsat 6, Landsat 7, equipped with a sensor similar to that on Landsat 5, was launched on April 15, 1999. However after working together with Landsat 5 to provide even more frequent observations, Landsat 7 had an equipment failure: the Scan Line Corrector (SLC) broke on May 2003, which means any images taken after that date have data gaps. However in spite of this failure, Landsat 7 still provides valuable images today.Figure 12 shows a comparison of images before and after the SLC failure.
Landsat 8, launched on February 11, 2013, joins Landsat 7 to continue capturing hundreds of images of the Earth's surface each day.
In April 2008 all archived Landsat scenes were made available for download free of charge by USGS.
2.3.2 Sensors used on Landsat Satellites
Landsat satellites carry sensors with medium spatial, temporal, and spectral resolution; their images are the most widely used of all satellite images.
MSS (Multi-Spectral Scanner) is the sensor that was used on Landsat 1 through 5. It takes measurements in 4 different bands: red, green, and two near infrared bands at 80-meter spatial resolution.
Landsat 4 and 5 were also equipped with a new sensor called the TM (Thematic Mapper). TM is also a multispectral sensor with seven bands: blue, green, red, three bands in the near infrared, and one band in far infrared. TM has 30 meter resolution in the visible and near infrared bands, and 120 meter resolution in the thermal/far infrared band.
Landsat 7 was launched in 1999, not carrying either the MSS or TM, but a new sensor called ETM+ (Enhanced Thematic Mapper +). ETM+ senses the same 7 bands as the TM, but with improved spatial resolution in the thermal band: from 120 meter resolution to 60 meter resolution. It also includes a new band: a panchromatic band with a spatial resolution of 15 meters. Landsat 7’s temporal resolution is still 16 days, but can acquire about 250 images per day.
Landsat 8, launched in 2013, carries two brand new sensors: the Operational Land Imager (OLI) and Thermal Infrared Sensor (TIRS). OLI collects data in 9 bands (Table 2), including four in visible wavelengths, one in near IR, two in shortwave IR, a panchromatic band in visible wavelengths, and an additional "cirrus" band. Compared to ETM+, OLI adds another band (Band 1) in the violet wavelength for better observations in coastal area and a band (Band 9 "cirrus") in near IR to detect cirrus clouds. TIRS collects data in two bands in thermal/far infrared wavelengths.
2.3.3 Applications of Landsat Data
Landsat data are valuable for decision makers in fields such as agriculture, forestry, land use, water resources and natural resource exploration. Over the past decade, Landsat has been intensively used to understand changes in global natural and social environment including land cover and land use changes, deletion of coastal wetlands, human population changes, and global urbanization.
Agricultural productivity evaluation and crop forecasting also require satellite data because they can use the data to accurately predict crop yields. Similarly, understanding current conditions of and changes in fresh water supplies also requires systematic repetitive coverage provided by the Landsat system.
Figure 13 shows two Landsat images of the Amazon rain forest. The left was taken in 1975, while the right one was taken in 2012. These two images highlight dramatic change in forest: deforestation taking on a "fishbone" pattern following major roads. These images are actually not true color. Near infrared bands are displayed in the green channel, therefore dense rain forests are green. But the shortwave infrared band which highlights villages and roads is displayed in red. Therefore the pink or purple color you see in the images represents human-made features like roads, houses and villages. Farmland is represented in light brown colors.
Landsat data has also been used in wildfire monitoring (Figure 14). Intense wildfires usually happen in conifer forests, though they occur infrequently—once every 100 to 300 years. Fire returns nutrients to the soil and replaces old tree stands and ground debris with young forest. In 1988, Yellowstone National Park experienced a severe fire season: fifty wildfires ignited, seven of which grew into major wildfires. By the end of the year 793,000 acres had burned. Figure 14 is a false color composite image taken by Landsat 5 in 1989. Green is natural forest, while the red areas are burnt. It takes many decades for a conifer forest to recover to pre-fire conditions, and through the use of Landsat, researchers have been able to chronicle the forest's recovery over the past two decades.
2.4 Geostationary Operational Environmental Satellites (GEOS) System: Your "Weather Guy" in the Space
In the United States, your local television or newspaper weather report probably uses one or more weather satellite images collected from the Geostationary Operational Environmental Satellites (GOES) system. The GOES series of satellites is the primary weather observation platform for the United States.
The GOES system, operated by the United States National Environmental Satellite, Data, and Information Service (NESDIS), supports weather forecasting, severe storm tracking, and meteorology research. Spacecraft and ground-based elements of the system work together to provide a continuous stream of environmental data. The National Weather Service (NWS) uses the GOES system for its United States weather monitoring and forecasting operations, and scientific researchers use the data to better understand land, atmosphere, ocean, and climate interactions.
The GOES system uses geostationary satellites, 35,790 km above the earth, which — since the launch of SMS-1 in 1974 — have been essential to U.S. weather monitoring and forecasting. The GOES satellites provide new imagery every 15 minutes. The sensors in GOES satellites detect 3 spectral bands: visible, infrared, and water vapor.
The latest generation, GOES 15 (Figure 15 left), launched on March 4, 2010, represents an advance in data products for weather forecasting and storm warnings over previous satellites.
Figure 15 (right) is an image of Hurricane Katrina on August 28, 2005, at 11:45 a.m. (EDT), captured by GOES-12. At that time, the storm was at Category 5 strength and projected to impact New Orleans. Now, after more than 10 years of stellar service, NOAA’s Geostationary Operational Environmental Satellite (GOES)-12 spacecraft will be retired.
2.5 QuickBird: Commercial Very High Resolution Image
QuickBird is a commercial satellite operated by DigitalGlobe (Figure 16, left). It was launched from Vandenberg air force base in California on October 18, 2011. At the time of its launch it was the highest resolution commercial satellite in operation. Now there are sensors with even higher spatial resolution, including the WorldView and GeoEye satellites also operated by DigitalGlobe.
QuickBird has two sensors --- a four-band (blue, green, red, and near-infrared) multispectral sensor with 2.4-meter spatial resolution and a panchromatic sensor with 0.61-meter spatial resolution. Both sensors provide off-nadir views (they can point in a direction other than straight down) and provide global coverage every 2 and 6 days, respectively. QuickBird circles the globe 450 km above the Earth on a sun-synchronous orbit. Note that it might seem to you that QuickBird has both super high spatial and temporal resolution. But actually, the high temporal resolution is made possible by its off-nadir view capabilities, which has limited scientific usage compared to the at-nadir (straight-down) views supplied by Suomi-NPP and Landsat. The 0.61-meter and 2.4-meter imagery are extremely high-resolution, allowing very detailed information to be seen in an image (Figure 17 right). The data contributes to mapping, agricultural and urban planning, weather research, and military surveillance.
DigitalGlobe maintains the largest sub-meter resolution constellation of satellites, and QuickBird is one of these. Their other satellites include WorldView-1, WorldView-2, IKONOS, GeoEye-1, and WorldView-3. Many of the images you see in Google Earth come from these satellites. Table 3 shows the spatial resolution of these satellites. WorldView - 3 provides the highest spatial resolution in the panchromatic band with 31cm. Figure 16 compares images with 30cm and 70cm resolution. High resolution images such as these can be used to produce map images that clearly show smaller features such as cars and trees; these images are useful for natural resource management, urban planning, and emergency response.
2.6 Other remote sensing satellites
The satellite systems we introduced are only a small set of the Earth-observing platforms orbiting hundreds of miles over your head dedicated to monitoring sea surface temperature, glaciers, and particles in the atmosphere. There are other important systems launched by the European Space Agency (ESA), India, Japan, China, and Brazil.
Envisat is a satellite launched by ESA in 2002, which carries 10 instruments including ASAR (Advanced Synthetic Aperture Radar), an active microwave sensor mainly used for sea forecasting and monitoring sea ice, and MERIS (Medium Resolution Imaging Spectrometer) a multi-spectral imaging spectrometer with 300m spatial resolution and 15 spectral bands.
The ESA's Sentinel mission has a few satellites in operation: Sentinel-1 is a polar-orbiting, all-weather, day-and-night radar imaging satellite that tracks ocean processes. The first Sentinel-1 satellite was launched on April 3, 2014. Sentinel-2 is a polar-orbiting, multispectral high-resolution imaging mission for land monitoring that provides imagery of vegetation, soil and water cover, inland waterways and coastal areas. Sentinel-2A, the first of two Sentinel-2 satellites, launched on June 12, 2015. It carries sensors that can image in 13 spectral bands, with 4 bands at 10 m spatial resolution, 6 bands at 20m resolution and 3 bands at 60m resolution. This will provide even more Landsat-type data.
The Meteosat series of satellites are Europe’s geostationary weather observation satellites. The first generation of Meteosat satellites, Meteosat-1 to Meteosat-7, provide continuous and reliable meteorological observations. They provide images of the Earth and its atmosphere every half-hour in three spectral channels (visible, infrared, and water vapor) via the Meteosat Visible and Infrared Imager (MVIRI) sensor. The latest generation satellite, MSG-3, was launched on July 5, 2012. The next satellite (MSG-4) is planned for launch in 2015.
Key Terms
spatial resolution: a measure of the smallest object or area on the ground that can be detected by the sensor
spectral resolution: the number of spectral bands -- portions of the electromagnetic spectrum -- that a sensor can collect energy in.
temporal resolution: the revisit period of a satellite's sensor for a specific location on the Earth. It is also the length of time for a satellite to complete one orbit cycle of the globe.
panchromatic sensor: a sensor measuring the visible portion of the spectrum, which treats the entire 0.4 to 0.7 micrometer range as if it was one band.
multispectral sensor: a sensor that collects information across several bands, each of which are broad portions of the electromagnetic spectrum.
hyperspectral sensor: a sensor that collects information across very many narrow, contiguous bands. A hyperspectral sensor could be able to sense over 200 bands.
swath: the strip of the Earth’s surface from which geographic data are collected by a satellite
Lecture 8-1 Introduction to GIS
1. GIS: a Geospatial Technology
1.1 Geospatial technology components
Geospatial technologies include three major components: GPS, RS, and GIS. While GPS and RS are useful in collecting data, a GIS is used to store and manipulate the acquired geospatial data.
GPS: A system of satellites which can provide precise (100 meter to sub-centimeter) locations on the earth’s surface.
RS: Use of satellites or aircraft to capture information about Earth's surface.
GIS: Software systems with the capability for input, storage, manipulation/analysis, and output/display of geographic (spatial) information.
1.2 GIS: What does the 'S' stand for?
GIS can be many things. The acronym is used in a number of ways:
Geographic Information Systems: the technology - “GIS”
Geographic Information Science: the concepts and theory - “GIScience”
Geographic Information Studies: the societal context - “GIStudies”
In this course, we refer to GIS as Geographic Information Systems. GIScience describes the larger scientific domain associated with geographic information systems, their application in scientific research, and the fundamental scientific study of geographic information.
GIS: emphasizes technology and tools for the management and analysis of spatial information.
GIScience: a new interdisciplinary field built around the use and theory of GIS, which studies the underlying conceptual and fundamental issues arising from the use of GIS and related technologies, such as: spatial analysis, map projections, accuracy, and scientific visualization.
GIStudies: understand the social, legal and ethical issues associated with the application of GI Systems and GI Science.
2. Why GIS matters?
2.1 Location, location, location!
Everything that happens, happens somewhere. Knowing where something happens can be critically important. Problems that involve location, either in the information used to solve them or in the solutions themselves, are termed geographic problems. Geographic Problems (Figure 1; Figure 2) which are associated with location, include the following examples:
Health care managers choose where to locate clinics and hospitals
Delivery companies design and update daily routes and schedules
Tourists navigate to a destination in an unfamiliar city
Forestry companies plan for sustainable tree harvest and replanting programs
All of the above involve location information, and we use GIS to solve these problems. GIS is capable of recording, analyzing, and displaying information about LOCATIONS. A GIS is a system for analyzing and solving geographic problems.
Hurricane Katrina was the the third most intense tropical cyclone in the United States (Figure 2). It flooded 80% of New Orleans caused an estimated $81 billion (2005 US dollars) in damage and killed 1,836 people. Figure 3 shows the flooding of the I-10 interstate Highway, caused by the breaching of the levees near the 17th Street Canal.
Dealing with the aftermath posed a number of geographic problems. Many of the GIS maps that were used to deal with the situation were produced by volunteers, as well as official agencies. The initial demand for GIS maps were from first responders and emergency staff on the ground, who needed street maps for search and rescue.
In addition, other “situational awareness” maps were required by incident commanders to find areas that had likely experienced (or would experience) flooding, road closures, and access restrictions. These maps are also essential to determine the availability of shelters and kitchens, locations of water and ice distribution points, and the locations of environmentally hazardous sites. For example, Figure 4 shows the New Orleans area and a prediction of the effects of a Katrina-like 32 foot storm surge, combined with 20-foot wave action, as modeled in a GIS. The city boundary is in green, and the limit of the storm surge is in red.
2.2 How does GIS fit in?
To solve geographic problems, a GIS maps the locations of things and phenomena, and analyzes patterns.
Through maps we can first find a feature, which means that we can use maps to see where or what an individual feature is. In addition, we can also find patterns over things and phenomena. While looking at the distribution of features on the map instead of just an individual feature, you can see patterns emerge. A GIS can show the spatial patterns of things, which otherwise cannot be seen only through maps. Therefore, it helps us to discover the correlation among things and make smart decisions.
Now let’s look at several examples showing how we can use a GIS to help find patterns on a map.
Example 1: Figure 5 maps population data in the U.S. state of Maine, with different population densities represented by different colors. With this map we can easily identify that counties with population densities exceeding 500 person per square mile are mostly located in southwestern areas; this is represented with orange and red colors. This is the spatial pattern of population distribution.
Example 2: Another example comes from mapping the concentration of uncredentialed teachers vs. the distribution of family income in Los Angeles (Figure 6). Such maps help uncover correlations between different demographic data, such as socioeconomic status, family income, education levels, and race. With this map, we can see that concentrations of uncredentialed teachers are mostly located in poor communities.
Example 3: The real power of GIS comes through combining data layers for a more complex analysis. Different map layers are at the same projection, covering the same geographic area, but showing different data (Figure 7). These layers are overlaid for analysis across layers. For example, to find a suitable location for a new road, we need to compile maps of various environmental and social factors to make the best decision.
2.3 GIS applications
GIS can be applied in many areas to solve different geographic problems. Figure 9 shows a list of fields in which GIS is being used in professional practice (such as urban planning, management and policy making), scientific research (such as in environmental science and political science), and many other fields, such as civil engineering, education administration, real estate, health care and business.
3. GIS Fundamentals
3.1 Definitions
Everyone has a favorite definition of GIS, and there are many to choose from, suggesting that those definitions work well in different circumstances with different groups. Some common definitions are:
Container of maps
Computerized tools for solving geographic problems
Spatial decision support system
Mechanized inventory of geographically distributed features and facilities
Methods for revealing patterns and processes in geographic information
Tool to automate time-consuming tasks.
GIS is usually viewed as a container of maps by the general public. Figure 10 shows a traditional map cabinet (used to hold printed maps in a setting like a research library or archive). A GIS could be thought of as the digital or electronic equivalent of the map cabinet. However, it is more than that. GIS is a computerized tool for solving geographic problems, a spatial decision support system, a mechanized inventory for geographical features and facilities, a tool for revealing what is otherwise hidden in geographic information, and finally, a tool for performing operations on geographic data that are too tedious, expensive or inaccurate to perform manually.
3.2 A brief history of GIS
GIS is built upon knowledge from geography, cartography, computer science, and mathematics
GPS and RS technologies collect massive amounts of data. This means we need technology to help process and analyze these data. This is one of the major drivers for the development of GIS. Geographic Information Science is a new interdisciplinary field built out of the use and theory of GIS. The development of GIS has been gone through three stages: innovation, commercialization, and exploitation.
Innovation
The first stage is the era of innovation. The first GIS was the Canada geographic information system (CGIS) designed in the early 1960s as a computerized map-measuring tool to provide large-scale assessment of land use in Canada. CGIS was conceived by Roger Tomlinson, who is known as “the father of GIS.” In 1964, The Harvard Lab for computer graphics and spatial analysis was established under the direction of Howard Fisher at Harvard university. In 1966, SYMAP, the first raster GIS, was created by Harvard researchers. This lab was home to several legendary people in GIS. For example, Jack Dangermond (seen in the first video), who established ESRI (Environmental System Research Institute), and Jim Meadlock, one of the founders for Integraph company, all came from the Harvard lab. In 1969 Jack Dangermond, a student from the Harvard lab and his wife Laura formed ESRI to undertake projects in GIS. Jim Meadlock and four others that worked on the guidance systems for Saturn rockets formed M&S Computing, later renamed Intergraph. At the same time, several key academic conferences, such as AutoCarto, were hosted.
Commercialization
The second stage of GIS development is the era of commercialization, which dates from the early 1980s, when the price of sufficiently powerful computers fell below a critical threshold. ArcInfo was the first major commercial GIS software system. It set a new standard for the industry.
Exploitation
GIS entered the era of exploitation in the 2000s when the Internet became the major delivery vehicle for GIS services and applications. Right now, GIS has more than 1 million core users, and there are perhaps 5 million casual users of GIS.
3.3 GIS Components
A GIS has six components: hardware, software, procedures, data, people, and network.
At the very center of this diagram is the NETWORK, which makes modern GIS possible. The sharing of data, dissemination of maps, graphics, and information, and the ability to connect a GIS to Internet Services that extend its capabilities. Note that the network needs to be at the center of the diagram, because it connects all the components.
HARDWARE is the foundation of GIS. GIS hardware used to consist of mainframe computers. Today we can use smart phones and other mobile devices for use in a GIS. The most typical and common GIS hardware configuration consists of a desktop computer or workstation that is used to perform most of the functions of a GIS. A client-server arrangement is very common, meaning that simple computer hardware or mobile device (a client) is intentionally paired with a more sophisticated powerful computer hardware (a server) to create a complete working system.
SOFTWARE allows a GIS to perform location-based analysis. GIS software packages include commercial software purchased from a vendor such as ESRI, Bentley, or Intergraph, as well as scripts, modules, and macros that can be used to extend the capabilities of GIS software. An important part of GIS software today is a web browser and all the associated web protocols, which are used to create novel GIS web applications.
DATA is the essence of GIS. GIS data is a digital representation of selected aspects of specific area son the Earth’s surface or near-surface, built to serve problem solving or scientific research. GIS data is typically stored in a database. The size of a typical GIS database varies widely. A GIS dataset for a small project might be 1 Megabyte in size. An entire street network for a small country might be 1 Gigabyte in size. Larger datasets, including elevation data for the entire Earth at 30m intervals can take up terabytes of storage, and more detailed datasets of the entire earth can be many many times larger. The dataset used in a GIS can be VERY large. A GIS, by nature, stores detailed information about the Earth. This means that a GIS Professional needs to be very careful and deliberate about data storage and the time required for data processing.
In addition to these four components, a GIS also requires PROCEDURES for managing all GIS activities, such as organization, budgets, training, customer mapping requests, quality assurance and quality control.
Finally, a GIS is useless without the PEOPLE who design, program, maintain, and use it.
Among the six components of a GIS, which do you think is the most expensive? It's data.
3.4 GIS Workflow
The workflow for a GIS is represented as a loop when applied in a real-world application (Figure 13).
First, we collect and edit spatial data.
Second, we visualize/display the data and perform spatial/statistical analysis to understand phenomena and patterns.
Third, we design and produce maps as reported results for decision makers.
The decisions made will produce effects in the real world. Therefore we collect the feedback and restart the loop to further improve our decisions and policies.
Key Terms
Geographic Information Systems (GIS): Software systems with the capability for input, storage, manipulation/analysis, and output/display of geographic (spatial) information
Geographic Information Science: a new interdisciplinary field built out of the use and theory of GIS, which studies the underlying conceptual and fundamental issues arising from the use of GIS and related technologies, such as: spatial analysis, map projections, accuracy, and scientific visualization.
Geographic Information Studies: to understand the social, legal and ethical issues associated with the application of GI Systems and GI Science.
Geographic Problems: problems that involve an aspect of location, either in the information used to solve them, or in the solutions themselves.
Lecture 8-2 Geospatial Data
1. Geospatial Data
Data is fundamental to geospatial technologies. Geospatial data consists of two parts: spatial data and attribute data/non-spatial data.
Spatial data: Spatial data indicates the location of geographic features, which is usually expressed with geographic coordinates. From Lecture 3 we know there are two types of coordinate systems to pinpoint locations: geographic coordinate systems displaying locations as latitude and longitude, and projected coordinate systems that store locations in units of length, such as meters and inches.
Attribute data (non-spatial data): Attribute data (non-spatial data) describes the properties of geographic features. Examples are statistics, text, images, sound, etc., all of which can serve as descriptive information to tell us what a feature is.
2. Spatial Data Models
2.1 Two types of data models
In GIS, two different models are used to store, organize, and manage spatial data. The first one is the vector data model, by which we represent the geographic features with Points, Lines and Polygons. The second type is the raster data model, where the geographic features are divided and represented by evenly spaced grid cells (or pixels). For example, aerial photos and remote sensing images are raster data.
In theory, both data models can be used to represent individual features or continuous surfaces. However in practice, we typically use the vector data model to represent discrete data, such as locations of restaurants, streets, and house parcels, and use the raster data model to represent continuous data, such as elevation, air temperature, population.
Figure 1 shows an example of the difference between the two models. In the real world we have geographic features, such as cities, suburbs, roads, forests, and rivers. In GIS, in order to store and manage these information, we need to conceptualize or generalize them into symbols and images. For example, we can use points to store the location of each household, use lines to represent streets, and use polygons to show land parcels. These features are discrete in space, and are mostly stored as vector data. There are some features such as elevation which changes continuously across the land. To represent these features, we typically use raster data to manage them as a two-dimensional image.
2.2 Raster data model
The Raster Data Model is a spatial data model that defines space as an array of equally sized cells arranged in rows and columns (Figure 3). All geographic variation is then expressed by assigning properties or attributes to these cells. The cells are also called pixels.
One grid cell is one unit that holds one number, which means that every cell is assigned a value, even if it is “missing”. In that case the grid cell will be assigned with value as N/A, 0, or Null. The value is the property of the geographic features you want to describe with this raster data, such as elevation, land cover type, population, etc. A cell/pixel has a resolution, given as the cell size in ground units. The grid cell is the smallest unit of resolution and may vary from centimeters to kilometers depending on the application.
Mostly, you won't be able to see individual pixels when you look at the whole raster image. But as you zoom in to a small area, you can see it is made up of small grid cells pixels with different colors (Figure 4).
Figure 5 shows a raster image of land cover types. Different colors represent different land cover classes. If you look closely, you can see the area is broken down into individual grid cells or pixels.
Raster data are very common. All the .jpg, .png, or .tiff images in you computer are raster, even though they might not be geospatial data. Aerial photos and remote sensing images are all geospatial data in a raster format that can be used in GIS. Figure 6 is an aerial photo showing the center of Madison. This is a typical raster dataset with high resolution.
2.3 Vector data model
In a vector data model, points, lines, and polygons are used to represent geographic features.
Points represent objects that are represented with a single (x, y) coordinate pair. For example, things like houses and cities, which are usually too small to be represented by area or polygon in a map, are displayed as points.
Lines represent linear features, which have a certain length but are too narrow to be shown as areas or polygons, such as rivers and roads. In GIS lines are stored as series of (x, y) coordinates connected by straight lines.
Polygons represent features depicted by a closed loop of (x, y) coordinates which enclose an area. These features are usually too large to be depicted as points or lines. Features like a forest patch or a lake are usually represented as polygons.
Figure 7 shows five different but related vector data layers of the contiguous United States. The cities are drawn in a point vector layer. The roads and rivers are line vector layers. The lakes and states are polygon data .layers
When these five data layers are displayed together in the GIS software, they generate the map in Figure 8. Layers can be turned on and off individually. The left side shows the order of the layers.
The states layer (polygon/area) is at the bottom; it is the base layer. The city layer (point) is at the top. The layer order determines how the map is drawn, with the top layer displayed at the top and the other layers below it. If the states layer moves to the top, it will cover everything else except the great lakes, since they are outside of the state polygon boundaries.
Now let's look at the UW campus map in Figure 9. This is a Google Map. Note that this Google map uses in a vector data model.
Q: Which features are polygons?
A: Since this is a large scale map (How can we tell?), it includes a lot of detail. The buildings, rivers, parks, and even the roads are represented as polygons.
Now let's zoom out to see an overview of the Midwestern states (Figure 10).
Q: Again, which features are polygons?
A: All previous campus polygons are eliminated, as only the great lakes, large national parks, and states are shown as polygons. This is because as you zoom out of a map, polygons will continuously get smaller until they are so tiny that they become illegible and can't be shown as individual areas. You would instead use points or lines instead. Below we can see that Madison is now represented as a point, while roads are shown as lines.
Vector data can be collected using a GPS unit, ground survey, or obtained through raster-vector conversion procedures from scanned images. We can also digitize a printed map to collect vector data. Figure 11 shows an analyst using a digitizer to collect vector data from a printed map.
3. Attribute Data
3.1 What is an attribute table?
Attribute data are descriptive information about geographic features. Attribute data is important in GIS to link a geographic location or feature to its properties. Some examples of attributes include county population, land cover type, and air temperature. These information can be used to find, query, and symbolize features or raster cells. For example, we can use different colors and symbols to represent houses, streets, lakes, and rivers.
Generally, attribute data is stored in an attribute table. In such a table, each row represents a feature and each column represents an attribute. Each data layer displayed in a GIS software has an attribute table of information linked to it. The GIS software cross-references the attribute data with the geospatial features displayed in the map, allowing searches based on either or both.
Attribute tables are used in both vector and raster data, but in different ways.
3.2 Attribute tables for vector data
In Figure 12 the upper left picture is an attribute table for the states of the contiguous U.S., represented in a vector data model. In this table each column is an attribute or property of a state, such as the sub region this state belongs to, the abbreviation of the state, and the population of the state. Each row represents a geographic feature - in this case, a state. For example, the highlighted row refers to the state of Wisconsin. We can tell that Wisconsin is in the East North Central region, its abbreviation is "WI", and its population in 2000 is 5,363,675.
A GIS is capable of cross-referencing the attribute data with the geospatial features, allowing queries based on attributes or geographic locations. If we click row 7 in this attribute table, we see that the Wisconsin polygon is highlighted in yellow (Figure 11, upper right figure). If we click the polygon of Wisconsin on the map (Figure 11, lower left), we can obtain all the attributes for Wisconsin as a list (Figure 11, lower right). You will learn more about this function as we move on through this course.
3.2 Attribute tables for raster data
While almost every piece of vector data in a GIS has an attribute table, raster data does not always have one. Data, such as average air temperature, precipitation or elevation, are simple numerical values; we don't usually need to know the properties of different values, say 75F and 98F.
For some raster data an attribute table is necessary. In such data each cell or pixel is assigned a single value, each defines a class (i.e. urban), a category (i.e. mid-west region), or a group (i.e. low-income households). In this case the attribute table will typically have rows associated with each unique value (class/category) and provide the properties of this class, group, category, or membership.
Figure 13 is an example of the attribute table for a raster data. There are four types of land cover: forest land, wetland, crop land, and urban, each of which is displayed with a specific color in the map and a numerical value (1-4) in the attribute table. While the rows of the attribute table represents four land cover types (values 1 - 4), the columns show properties of these categories, such as type, count of pixel, and area. For example, forest land is recorded as 1 in the data. There are a total of 9 forest land grid cells, which comprises 8,100 square meters.
3.3 Comparing raster data attributes and vector data attributes
In the raster dataset, the geographic features are represented by pixels/grids, each of which has a unique value (1-4). In the left map of Figure 14, each of the four values (1-4) indicating a land cover type has a unique color. In the attribute table (Figure 14, lower left), each row corresponds to a certain class, and the columns includes the properties of each class such as the name and number of pixels for each. For example, class 3 (brown in the raster data image), represents the land cover type "beach" which has 2 pixels in the image.
In the vector dataset the land cover classes, i.e. water, beach, grass, and forest, are represented by polygons, and they are displayed by different colors in the map (Figure 14, upper right). There are four different features/polygons in the vector data. Therefore, the attribute table also has four rows (excluding the name row), each of which represents a polygon. There are five columns, each representing one attribute. For example, the second row shows the land cover type "beach." It has a value of 3 (this matches the raster data). The other columns tell you that this feature is public and owned by the state. Note that the first column - "FID#" is a unique indicator of the polygons. In most GIS systems, "FID#" is a necessary column in every vector dataset and is always kept as the first column.
Key Terms
spatial data: data indicating the location of geographic features, usually expressed in geographic coordinates
attribute data: data that describes the properties of geographic features
raster data model: a spatial data model that defines space as an array of equally sized cells arranged in rows and columns
pixel: the smallest cells of equal size which are assigned unique values in a raster data model
resolution: the pixel size (in ground units) in a raster data model
vector data model: represents geographic features with points, lines and polygons
point (vector): a feature in a vector data model represented with a single (x, y) coordinate pair
line (vector): a linear feature in a vector data model, which has a certain length but is too narrow to be shown as an area or polygon
polygon (vector): a feature in a vector data model depicted with a closed loop of (x, y) coordinates, which encloses an area
attribute table: a table to store attribute data, where each row represents a feature and each column represents a different attribute of the feature
Attribute data in vector data model are typically stored into tables, while attribute data in raster data model are stored as values associated with each cell.
Lecture 9-1 Query and Spatial Analysis
1. Database and Data Query
1.1 What is a data query?
The data query is the most fundamental function in GIS and geospatial databases. For example, you can use it to search for nearby restaurants using Google Maps. In a more technical way queries can manipulate a geospatial database and select only the records you want.
In GIS, queries are composed using the Structured Query Language (SQL) format, like a mathematical function. SQL is a specific format that is used to query a database to find attributes that meet certain conditions. For example, in a data layer made up of points representing cities in the U.S., each city has a series of attributes, including name, state, area, population, and average household income. How do we find the city of Madison, Wisconsin and its associated attributes? We can build a SQL query in our GIS program (Figure 1):
“NAME”= “Madison” AND “ST” = “WI”.
Note that "ST" here is the column name in the attribute table for the name of State. One has to specify "ST" = "WI", otherwise, the result would be a list of cities named "Madison".
1.2 Basic SQL syntax
In SQL, a simple query will use one of the following relational operators.
Equal (=): used when you want to find all values that match the query. For an instance, querying for CITY_NAME = ‘Madison’ will locate all records that exactly match the characters 'Madison'.
Not Equal (<>): used when you want to find all the records that do not match a particular value. For example, querying for CITY_NAME <> 'Madison' will return all the records that do not match the word ‘Madison,’ that is every city but Madison.
Greater Than (>) or Greater Than Or Equal To (>=): used for selecting values that are more than (or more than or equal to) a particular value. For example, you would use it to find all cities with a population greater than or equal to 100,000.
Less Than (<) or Less Than Or Equal To (=<): used for selecting values below (or below and equal to) a particular value.
A simple query only uses one operator and one field as in the above examples. A compound query enables you to make selections using multiple criteria. In order to construct a query linking multiple criteria together, we need boolean operators: AND, OR, NOT.
AND
If you want to select cities in the U.S that have a population over 50,000 (a variable called POP2000 in the attribute table) and an average household income (a variable called AVERAGEHI) of more than $30,000. A compound query can combine these two requests: POP2000 > 50000 AND AVERAGEHI > 30000.
OR
A different query could be built by saying: POP2000 > 50000 OR AVERAGEHI > 30000. This would return cities with a population of greater than 50,000, cities with an average household income of greater than $30,000, and cities that meet both criteria.
NOT
When you want all of the data related to one criteria, but exclude what relates to the second criteria, you would use a NOT query. If you want to select cities with a high population, but not those with a higher average household income, you could build a query like: POP2000 >= 50000 NOT AVERAGEHI > 30000 to find those cities.
1.3 Spatial query
Database queries that take place in the attribute table, while very important, are not usually considered spatial analysis. This is because there is no "spatial" relationship involved in the process. Spatial Query is also known as "select by location" in some GIS software (e.g., ArcGIS). The spatial query tool allows you to select features based on their location relative to other features. For an instance, if you want to know how many houses were affected by a recent flood, you could select all the homes that fall within the flood boundary.
We can use a variety of methods to select the point, line, or polygon features in one layer that are close to or overlap with features in the same or another layer, such as:
Select points or lines that fall within polygons
Select points or lines within a certain distance of a point, line or polygon
Select polygons that either entirely or partially fall within another polygon.
2. Spatial Analysis
2.1 Spatial analysis: the crux of GIS
Spatial analysis is considered to be the crux of GIS, because it includes all of the transformations, manipulations, and methods that can be applied to geographic data. The process turns data into information to support decisions, and reveals hidden patterns; for example, patterns in the occurrence of diseases may hint at the mechanisms that cause the disease.
To be simple, spatial analysis is the process of transforming data into useful information.
A pioneer example of a spatial query, where different layers of data were incorporated into an analysis, took place in 19th century London. In 1854 John Snow was trying to determine the cause of a cholera epidemic. At the time nobody knew much about cholera's causes. Snow created a map with both the location of cholera deaths (represented as the black dots in the map) and water pumps (the P circles) that supplied residents with drinking water. This showed Broad Street at the center of the epidemic, and that led him to correctly conclude that the Broad Street water pump was the source of the outbreak (Figure 3). This was one of the first examples of spatial analysis where the spatial relationship of the data significantly contributed to understanding a phenomenon.
2.2 Spatial analytical operations
There are four fundamental functions/operations of GIS spatial analysis, including:
Reclassifying maps
Overlaying data
Measuring distance and proximity
Characterizing neighborhoods
Please note what we cover here is just the tip of the iceberg of GIS functions. A GIS can offer many powerful functions for manipulating and analyzing geospatial data. For example, ESRI ArcGIS (one of the most popular GIS programs) has more than 1,000 functions.
2.2.1 Reclassifying Maps
Reclassification is reassigning values on an existing map based on the values of an attribute, e.g. land cover group. By looking at an attribute for a single data layer, we re-classify the data layer based on that attribute's range of values. Reclassification can be applied to both raster and vector data models.
The reclassification of raster data is very straightforward. In Figure 4, the Base Raster (the original raster map) has pixel values ranging from 1 to 20. After reclassification by mapping the old values to new values via the table in the middle, the new image (output raster) only contains values from 1 to 5.
2.2.2 Overlaying data
GIS often involves combining information from different data layers. For example:
What are the land uses for this soil type?
Whose parcels are within the 100-year floodplain?
Which interstate highways pass through Madison?
The way we answer such questions is to overlay data layers on top of each other and construct a new layer or map containing the combined information. When two or more layers are combined together to create composite maps, this is referred to as an overlay operation in GIS.
Overlay can involve simple operations such as laying a road map over a map of local wetlands (Figure 6), or more sophisticated operations such as multiplying and adding map attributes of different values to determine average values and co-occurrences. Overlaying operations can be performed on both raster or vector data. However, raster and vector data differ significantly in the way overlay operations are implemented.
2.2.2.1 Overlay for vector data
Overlaying vector data involves combining two or more vector data layers, which share the same geographical boundaries, in order to create a new data layer. Most GIS software provides the following overlay tools for vector data: Intersect, Union, Identity, Symmetrical difference, Erase and many others (Figure 7).
Intersect
Intersecting means only the features that both layers have in common are retained in a new layer. This type of operation is commonly used when you want to determine an area that meets two criteria. In the first row of Figure 7 only areas that the "square layer" and the "circle layer" share in common are retained, resulting in a new layer with irregular shapes.
Suppose you need to find all agricultural lands within 10 miles of a river (its floodplain). In this case, we need two layers: a river floodplain layer (which is a buffer layer containing all areas within 10 miles of rivers, referred to "buffer" in the next section), and a layer indicating all agricultural lands. You would intersect both layers to find areas that are covered by both layers.
Identity
In the Identity operation, an input layer is specified so that all of its features will be retained in the new layer. Additionally, the intersection of this layer and a second layer will be created and added to the new layer. In the second row of Figure 7, the second row, all the squares are present in the resulted layer, as well as the irregular shapes from the intersect operation (the first row).
For example, instead of getting only the intersection of the river floodplain and agricultural lands, you may want a new layer showing all floodplain areas and indicate which parts of it are agricultural lands and which are not. This is a process of identification, where you want to identify agricultural land and non-agricultural land in the floodplain. This is why this operation is called "identity."
Union
After a union operation, all of the features from both layers are combined together into a new layer. In Figure 7 (the forth row), you will find everything remains: the squares, the circles, as well as their intersections. This operation is often used to combine features from two layers.
Following the river floodplain and agricultural land example, after a union overlay operation, the new data layer will have all the features from both the floodplain and agricultural land layers. In particular, there will be three different types of features: agricultural land on floodplain, agricultural land outside floodplain, and non-agricultural land on floodplain. Think: what kind of features will you get if you use an intersection or identify operation? (You will answer this question in the self-assessment of this lecture.)
Symmetrical difference
In this operation all of the features of both layers are retained, except for the areas they have in common (the result of intersection). You can compare the third row (symmetrical difference) and the forth row (union), you will see that in symmetrical difference, only the intersected parts are left out.
Such operation would work in such case: "well, all agricultural lands within 11 miles of the rivers would be in danger in flood, therefore let's exclude them from our development plan."
2.2.2.2 Overlay for raster data
Overlay in raster is much simpler – the attributes of each cell/pixel from two or more layers are combined according to a set of rules. Within a raster dataset, each cell has a single value, and two raster layers can be overlaid in a variety of ways. The only thing to note is that in order to overlay raster data, the pixels in each layer need to be the same size.
The most common way to overlay raster data is to use a simple mathematical operator (sometimes referred to as Map Algebra), such as addition or multiplication. “Map algebra” is similar to traditional algebra where basic operations, such as addition, subtraction and exponentiation, are logically sequenced for specific variables to form equations.
Let’s look at three examples. The first one is addition, where the values of each grid cell from two different layers are added together (Figure 8).
The same thing can also be performed using multiplication. In Figure 9, both layers have values of 1 or 0. For example, the first layer could be a map of agricultural and non-agricultural land, with 1 indicating "agricultural" and 0 indicating "non-agricultural". The second layer could be a development area map, with 1 indicating "under development" and 0 indicating "will develop later". In this way, after multiplication, only cells which have value of 1 in both layers would be 1, otherwise they will be 0. In the resulting layer, 1 indicates "agricultural land under development", and 0 indicates everything else.
In the third example (Figure 10), overlay is done by determining the maximum value from two layers. Here, we want to get the maximum amount of rainfall in 1980 and 1981.
Figure 11 shows a real example of spatial overlay. Two data layers, land cover type and land slope, are overlaid to create a new layer called coincidence. The COVERTYPE layers contains three land cover types, forest (3), meadow (2), and open water (1). The SLOPE_CLASSES layers also contains three classes, which correspond to different slope levels. The new data layer simply identifies each combination of covertype and slope for each pixel. Three land cover types and three slope groups result in 9 combinations. Here we can see that a pixel with a value of 9 indicates the cover type 3 (forest) and slope class 3 (>30% slope), symbolized on the map with the color green.
2.2.3 Distance & proximity functions
Distance & proximity functions are operations that use information about the proximity, or nearness, between features. Two popular functions:
Buffer
Near operations
Buffer and Near operations can be applied to both vector and raster data. Here we mainly focus on vector data.
2.2.3.1 Buffer
A buffer creates an area within a user-defined distance of an existing entity/feature. This feature could be a point, a line, or a polygon. Buffers have many uses, for example determining areas impacted by a proposed highway, and determining the service area of a proposed hospital. Buffer can be performed on both raster and vector data. In Figure 12, we create a 60-meter buffer on the road (a line feature), and therefore we can analyze parcels that may be impacted by the road.
After buffering point data, circles are created around each point feature. If you wanted to know how many restaurants are within one mile of our current building, you would create a one-mile buffer area around the point object representing the building, and determine how many restaurants lie within the buffer. If you want to find the air pollution zone caused by the vehicle gas emission along a major interstate, you can construct a buffer zone within 100 meters of a major interstate, which is a buffer around a line. We can also buffer around an area. For example, we can create a conservation zone for all wildlife around a wetlands area.
2.2.3.2 Near operations
Near operations can be used to determine the shortest distance (within the search radius) from a feature in one layer to the nearest feature in another layer. For example, you might use "Near" to find the closest bus stops to tourist destinations or the closest stream for a set of wildlife observations.
Figure 14 shows the results of a "Near" operation performed on a point data layer and a river data layer (line features) in ArcGIS. The left figure shows some points near the river, where the points are symbolized using color gradients based on their distance to a river; they are labeled with their distance to the river. If we look at the attribute table, we find the following two fields will be added to the attribute table of the input features:
NearDistance — the nearest distance between the particular point and the river. (Note, one can draw countless lines connecting a point to any point on the river. There is one line that is the shortest representing this nearest distance).
NearAngle — the direction from the particular to the nearest place/point of the river.
Near operations (Figure 15) can be used to find the nearest distance between points, point to line, and point to polygon. The Near Features can include one or more different shape types. For instance, finding the nearest distance from points to lines and polygons, and the nearest distance from lines to polygons and points.
2.2.4 Neighborhood analysis
Neighborhood analysis evaluates the characteristics of an area surrounding a specific location. It is mainly used on raster data.
In a raster dataset, neighborhood statistics are useful to obtain information for each cell based on a specified neighborhood. For example when examining ecosystem stability, it is useful to obtain the variety of species residing in each neighborhood in order to identify locations that are lacking variability in the distribution of species.
In Figure 16, the grid cell (black) is determined by the maximum value of its neighborhood. The neighborhood of a cell is defined as the 8 cells surrounding the cell and the cell itself, which makes a 3 cell x 3 cell window. In this case the maximum value of the neighborhood for the black grid cell is 42. Therefore, in the map showing the neighborhood analysis, the cell of the same location will have the value 42. All grid cells in the dataset can calculate a new value from its neighborhood by moving this 3x3 window and determining the new "local" maximum.
The new value could also be determined by other statistics, such as mean, median, minimum, range, slope, aspect and majority. Figure 17 shows examples of these operations.
2.3 More about spatial analysis
All effective spatial analysis requires an intelligent user, not just a powerful computer. The mathematics and statistics methods used in these operations are only tools to help an analyst investigate data. Interpreting results is the most important step of spatial analysis; human knowledge and expertise is needed to detect patterns. Spatial analysis is best seen as a collaboration between the computer and the user, in which both play vital roles.
Key Terms
data query: access a database and select only the records you want from the attribute table.
Structured Query Language (SQL): a format used to query a database to find attributes that meet certain conditions.
spatial query: a tool that allows selecting features based on their location relative to other features either in the same or another layer, e.g., finding restaurants within 50 miles of your home.
spatial analysis: the process of transforming data into useful information.
map reclassification: reassigning values of an existing map based on the classes or values from a specific attribute.
overlay: when two or more layers sharing the same boundaries (but with different properties/attributes) are combined to create a new map.
intersection: results in a new layer that only contains areas that both layers have in common
identity: an input layer is specified so that all its features will be retained in the new layer, while all the features from an intersection of this layer and a second layer will also be created in the new layer
union: all features from both layers are combined into a new layer
symmetric difference: all features of both layers are retained, except for the areas they have in common (the result of intersection)
map algebra: basic operations such as addition, multiplication, and exponents are used to form equations that combine different raster layers
buffer: creates a new area within a user-defined distance of an existing point, line, or polygon feature
near operation: determines the shortest distance (within the search radius) from a feature in one layer to the nearest feature in another layer
neighborhood analysis: evaluates the characteristics of an area surrounding a specific location/cell/pixel, mostly used in raster data.
Lecture 9-2 Empower Applications with Spatial Analysis
1. Spatial Analysis for Different Data Models
Spatial analysis operations can differ between vector and raster data:
Spatial analysis for vector data
Vector data analysis typically includes buffering, overlaying, and network analysis. We covered proximity (buffer, nearness operations) and overlay functions in the last lecture. Network analysis provides spatial analysis over network-based data (i.e. road network, river network), such as routing, travel directions, closest facility, and service area.
Spatial analysis for raster data
Raster analysis is done by combining layers to create a new layer with new cell/pixel values. In addition to buffering/Proximity and reclassification (covered in the last lecture), terrain analysis (e.g., slope and hillshade calculation) and interpolation are typical raster analyses.
2. GIS Problem-Solving Process: A Practical Example
2.1 Basic GIS analysis process
a. State the problem
b. Collect and edit data
c. Analyze the problem by performing spatial analysis on the data
d. Produce maps for decision and policy makers that show the results of your analysis
2.2 Problem statement
You are a property developer in Cape Town, South Africa and you want to purchase a farm on which to build a new residential development. Your market research shows that the farm needs to satisfy the following requirements:
It needs to be in Swellendam, a small town 2.5 hours west of Cape Town
You don’t want to build any access roads longer than 500 meters. This means that the farm has to be easily accessible from main routes.
The targeted consumers will probably have children, so the farm must be within a reasonable distance (by car) from a school.
The farm must be between 100 and 150 hectares in area.
In the next sections we will solve this problem using two different data models: vector and raster.
2.3 Spatial analysis using vector data
2.3.1 Collecting data
The following data are needed to solve this problem:
DATA1 - FARM: available farms near the city of Cape Town
DATA2 - ROAD: roads that are running through these farms
DATA3 - SCHOOL: location of schools
For this example, the data has already been provided. But in reality you may need to find a provider for the datasets in question.
2.2.2 GIS workflow
First let's decide which operations should be performed and in what sequence. Typically we prepare a GIS workflow diagram to visualize the spatial analysis processes
Figure 2 shows the GIS operation workflow on the three vector datasets: road, school and farm.
We need to perform a series of attribute-based queries over those three datasets to identify:
Important roads (main roads) from all types of roads
High schools from all kinds of schools
Farms that are in Swellendam, Western Cape, South Africa (the first criteria)
To ensure that the selected farms are located within reasonable driving distance to main roads and high schools, we create buffers:
500 m buffer for the important roads data layer
10 km area for the high schools
Perform an overlay operation over the two buffer areas to find places within reasonable distance to both high schools and main roads.
Perform a spatial query using two layers: the intersected layer from step 3 and the farms data layer. This selects farms located in the intersections of school and road buffer areas.
Since we need to select farms between 100-150 hectares in size, we have to perform a geometric calculation over the selected farms to find their areas.
Finally we perform a simple attribute-based query to select farms with area greater than 100 and less than 150 hectares (which is our last criteria). This leads to the solutions to our problem.
2.2.3 GIS operations and solutions
Various GIS operations are performed during this vector data GIS workflow:
Attribute-based query helps us select important roads, high schools, and farms based only on their attribute tables.
Buffer is performed over the school and road layers to get their accessible regions.
Overlay is performed to get intersections of school and road buffer zones, and to locate areas accessible to both schools and roads.
Spatial Query is used to select farms within the intersections of school and road buffer areas.
Finally geometric calculations gives us the area of each farm, so we can choose the ones with the right size.
After performing all the operations, we can get our final farms satisfying all three criteria: polygons in the red color (Figure 3). In this final map,
Star-shaped points are high schools
The purple lines are major roads.
The big orange circles indicate the 10km buffer zone for high schools.
The long-tube shape pink polygons along some roads are the 500 meters buffer areas for roads, which are also less than 10 km away from the high schools.
The green colored polygons indicate farms that are within 500 meters of a road and within 10 km of a high school.
The red colored polygons are the final results of selected farms, which are between 100 to 150 hectares in size.
2.3 Finding the best location using raster data
2.3.1 Adding another criterion: slope
So far we have identified several farms that might be suitable based on our three criteria. Let’s add one more criterion to locate the ideal farm:
The perfect farm should be flat enough for residential houses. It needs to have areas with a slope of less than five degrees.
In order to make sure our farm meets this criterion, we need to integrate elevation data, a typical raster dataset. Based on the elevation data we can calculate slope.
2.3.2 GIS Workflow
Let’s see how to select farms that meet the slope criterion (Figure 4).
Collect the Digital Elevation Model (DEM) data representing the elevation for the whole area. A DEM shows the elevation or height of a terrain's surface in the raster format.
Perform terrain analysis over the DEM to calculate the slope for the whole area.
Reclassify the slope layer into two categories: areas with slope more than 5 degrees, and areas with slope equal to or less than 5 degrees. We choose these two categories because our criterion states that the farm must have a slope of less than 5 degrees.
As our previous solution is represented in vector polygons (Figure 3), to combine the raster analysis results we need to convert the raster slope class data to vector data. The resulting vector data layer contains polygons which fall into two categories: slope less than 5 degrees and slope greater than 5 degrees.
Now we have two vector layers: previous solutions (Figure 3) from vector analysis and suitable terrain in vector format. If we overlay our two vector layers we get final solutions that meet all criteria including the slope requirement.
2.3.3 GIS Operations (Raster Data Analysis)
The following GIS operations based on raster data are involved.
Calculate slope from the elevation data. This is know as terrain analysis, which is not covered in this course.
Reclassification of the slope map: reassign grid cells (pixels) with a slope value less than or equal to 5 degree as 1, and those with slope of more than 5 degrees as 0.
Convert raster slope class data to a vector polygon layer.
The following sections show examples of how to perform these operations in QGIS.
2.3.3.1 Calculating the slope
"Slope calculation with DEM (Terrain models)" is a common tool in GIS softwares. The result is a raster data layer with each cell value indicate the slope of the area. In Figure 5, we can see black pixels being flat terrain and white pixels indicting steep terrain.
Then, we reclassify the slope map (Figure 6a) into two categories: slope less than or equal to 5 degrees (value 1 in the result), and slope more than 5 degree (value 0 in the result). Figure 6b shows the Map Algebra used to perform this reclassification. In the raster calculator we enter "slope" <= 5 to define the first class with value equals to 1, and all the other cells would be the other class (value = 0). Figure 6c shows the final result: a two-class raster dataset. We can see that there are only two colors in the figure: black and white. The white areas (value = 1) are flat areas suitable for construction.
Then, we reclassify the slope map (Figure 6a) into two categories: slope less than or equal to 5 degrees (value 1 in the result), and slope more than 5 degree (value 0 in the result). Figure 6b shows the Map Algebra used to perform this reclassification. In the raster calculator we enter "slope" <= 5 to define the first class with value equals to 1, and all the other cells would be the other class (value = 0). Figure 6c shows the final result: a two-class raster dataset. We can see that there are only two colors in the figure: black and white. The white areas (value = 1) are flat areas suitable for construction.
Now we have two vector layers: the previous solutions from vector analysis (red polygons in Figure 3), and suitable terrain in vector format (Figure 7c). After we overlay (intersect) our two vector layers, we get our final solutions as visualized in the final map (Figure 8), with yellow polygons indicating farms that meet all criteria including the slope requirement. In the final map:
The green polygons are areas with a slope less than 5 degrees.
The white polygons with red outlines are farms that meet the first three criteria but are not flat enough for construction.
The yellow polygons with red outlines are the farms that meet all four criteria and are most suitable for residential development.
Key Terms
GIS workflow: a diagram used to illustrate the process and flow of geospatial data and spatial analysis. It is a useful framework for solving GIS problems.
Digital Elevation Model (DEM): a typical data model to represent the elevation or height of a surface at the per-pixel level.
Lecture 10 Spatial Statistics & Pattern Analysis
1. Fundamentals of Spatial Statistics
Spatial statistics uses spatial relationships (such as distance, area, height, orientation, centrality and other spatial characteristics) between features to understand distributions and analyze spatial patterns in GIS. Unlike traditional statistical methods, spatial statistics are specifically deployed on spatial or geographic data. This provides us a better understanding of geographic phenomena and causes of geographic patterns.
GIS systems provide a variety of Spatial Statistics tools. For example, Figure 1 shows the set of spatial statistics tools provided in ESRI ArcGIS.
In this lecture, we will look at two types of spatial statistics:
Tools Measuring Geographic Distributions: These identify characteristics of a distribution. They can be used to answer questions like where is the center of a set of features and how they are distributed around that center.
Tools Analyzing Patterns and Mapping Clusters: These tools can describe spatial patterns and enable us to answer questions like “Are features random, clustered, or evenly dispersed across the study area?”
Note: spatial statistics tools mainly deal with points, lines, and polygons in vector data sets.
2. Measuring Geographic Distributions
An example: we have 7 parks in a city (Figure 2). Given this map, we want to answer these questions:
Where is the center of the 7 parks?
How are these parks distributed around the center?
What's the optimal location for a fire station which allows fast access in case of an emergency in these parks?
To answer those two questions we use tools like Mean Center, Median Center, and Standard Distance.
2.1 Mean center
The easiest way to locate the fire station is to place it at the mean center of all parks. The mean center is the “average” position of the points. To get this position mathematically, we need to calculate the average x and y coordinates of all sites.
In Figure 2b, the (x,y) coordinates of all 7 parks (blue crosses) are given in the map. The average x coordinate is the sum of all x coordinates divided by the total number of points n. In this case, n = 7, since we have 7 parks total.
Average x coordinate = (580 + 380 + 480 + 400 + 500 + 550 + 300)/7 = 456
Similarly, the mean center of Y would be calculated by the sum of all y coordinates divided by the total number of points n.
Average y coordinate = (700 + 650 + 620 + 500 + 350 + 250 + 200)/7 = 467
These equations give the Mean Center coordinate of all parks: (456,467). It's shown as a green cross on the map in Figure 3.
2.2 Median center
Another way is to place the fire station at the median center of all parks. The median of a list of numbers is the middle one if these numbers are sorted from lowest to highest. To get the median center, we will sort get the medians of the x and y coordinates separately.
In the 7 parks example, the median of all x coordinates is: 480.
x coordinates (ascending order): 300 380 400 480 500 550 580
The median of the y coordinates is 500.
y coordinates (ascending order): 200 250 350 500 620 650 700
Therefore, the median center is (480, 500).
2.3 Standard distance
Both the mean center and median center are measures of the central tendency, which provides answers to the fire station locating question. To understand how these parks are distributed around the center we use Standard Distance (SD).
Standard Distance (SD) is the most common way to measure the dispersion of point distributions. It can measure the degree to which points are concentrated or dispersed around the mean center. SD is calculated using the following formula:
The left side of the numerator is the sum of the mean squares of the distance of each point to the mean center in the X direction. The right side is the sum of the mean squares of the distance of each point to the mean center in the Y direction. After adding the two sums together, dividing by the total number of points n, and taking square root, it would give us the standard distance.
Now, back to the 7 parks example, we have calculated the mean center as (456, 467). Therefore, X̄c = 456, and Ȳc = 467. The table in Figure 4 shows the process of calculating the standard distance of the 7 parks. The rows correspond to the 7 parks. The second and the fifth columns are the x and y coordinates respectively.
Subtraction: In the third column, we subtract the mean X coordinate (X̄c) from each of the X in the second column. Similarly, we also subtract the mean Y coordinate (Ȳc) from the Y coordinates.
Square: The squares of these subtractions are shown in the fourth and seventh columns.
Sum up the squares for X and we get around 59971 (the red number in the ninth row). Similarly, sum up the squares for Y and we get 244342.9.
Finally, add the two sums of squares up, divide the total by 7 ( the number of parks), and apply a final square root. This step is shown as an equation at the bottom of Figure 4.
After the above processes, we get an SD of our 7 parks of 208.5. This means the average distance between the parks and the mean center is about 208.5.
3. Analyzing Spatial Patterns
3.1 Characterizing spatial patterns
Spatial patterns of features can reveal underlying causes of distributions, which help decision making. Some common questions are:
Are the features distributed randomly?
Are some locations more likely to contain features than others?
Does the presence of one point make it more or less likely for other points to appear nearby?
There are three major ways in which features can be arranged:
Clustered: Features are concentrated in one or a few relatively small areas and form groups, and the presence of one feature may attract others.
Regular: Features are consistently spaced and regularly arranged.
Random: Features exhibit no apparent order in their arrangement. There seems to be some clustering and some regularity, but not enough to distinguish the pattern as clustered or regular.
Take Figure 6 for example: what is the pattern of the points? Note that human brains can almost always find spatial patterns, even when these patterns in the data do not exist!
These points were created using the random data generator in QGIS. So these data are completely random. But I think all of us would agree that we could see, perhaps some clusters and some empty spaces. Our brain can recognize patterns and find meanings from them, but in reality no patterns exist in these data.
We need spatial statistics methods to objectively quantify how random these data are. Are they random, or they are clustered?
A couple of quantitative methods measure the degree to which features are clustered, regularly, or randomly distributed across the study area. These include Average nearest neighbor, High/low clustering, Multi-distance spatial cluster analysis, and Spatial autocorrelation.
In this lecture, we will focus on the last one - Spatial autocorrelation (Moran’s I).
3.2 Spatial Autocorrelation
3.2.1 Positive and negative spatial autocorrelation
Spatial autocorrelation describes the similarity of a variable (such as house price) at different locations across space. It is one of the most widely used measures of the degree to which point features are clustered together (positive spatial autocorrelation) or evenly dispersed (negative spatial autocorrelation).
If there are some patterns in the spatial distribution of a variable, it is said to be spatially autocorrelated. Positive spatial autocorrelation means geographically nearby values of a variable tend to be similar: high values tend to be located near high values, medium values near medium values, and low values near low values. Demographic and socio-economic characteristics, such as population density and house price, are good examples of variables exhibiting positive spatial autocorrelation; expensive houses tend to be located near other expensive houses. Negative spatial autocorrelation describes patterns in which neighboring areas are unlike, or where dissimilar values tend to be together.
To illustrate these concepts, Figure 7 shows three synthetic examples. In the left most image, a clear separation and clustering of dark cells and white cells shows an extreme case of positive spatial autocorrelation. In the right most image, a check board pattern is a case of negative spatial autocorrelation where dissimilar values are next to each other. However, in the middle image where no clear pattern can be found, there is no spatial autocorrelation.
3.2.2 Measuring spatial autocorrelation: Moran’s I
There are a number of general measures of spatial autocorrelation, such as Moran’s I, Geary’s C, Ripley’s K, and Join Count Analysis. The most widely used one is Moran’s Index (Moran's I).
Moran's I is one of the oldest indicators of spatial autocorrelation. It is a standard for determining spatial autocorrelation based on both feature locations and feature attributes. Given a set of spatial features and an associated attribute, Moran’s I evaluates whether the pattern expressed is clustered, dispersed, or random.
Moran’s I varies from +1.0 for perfect positive correlation to –1.0 for perfect negative correlation. If Moran’s I equal to 0, it means a random pattern, indicating geographically random phenomena and chaotic landscapes (Figure 9):
A chess board (Figure 9 left) is an example of the negative spatial autocorrelation: black and white cells are intermixed, with every black cell (high value) adjacent to white cells (low value). This indicates that all the neighbors are not similar. The Moran's I statistic for the chess board is -1, giving us an almost perfect negative autocorrelation.
In the middle picture of Figure 9, black cells cluster with black cells, and white squares cluster with white squares. The Moran’s I value would be close to 1, a nearly perfect positive autocorrelation.
In the right picture of Figure 9, there are some areas negatively autocorrelated (with black and white cells intermixed) and some areas have same colored cells clustered. Therefore, in the end, Moran’s I is equal to zero. There is no spatial pattern in this map.
Key Terms
Spatial statistics: a method in GIS that uses spatial relationships (such as distance, area, height, orientation, centrality and/or other spatial characteristics of data) between different features to understand spatial distributions and analyze spatial patterns.
Geographic distribution: the arrangement of features on Earth's surface.
Mean center: a single x,y coordinate value that represents the average x-coordinate value and the average y-coordinate value of all features in a study area.
Median center: a single x,y coordinate value that represents the median x-coordinate value and the median y-coordinate value of all features in a study area.
Standard distance: a measure of the dispersion of features around their mean center.
Spatial cluster: spatial features that are concentrated in one/a few relatively small areas and form groups.
Spatial autocorrelation: describes the similarity of a variable at different locations across space.
Moran's Index (Moran's I): a standard measure of spatial autocorrelation which varies from -1 (perfect negative correlation) to 1 (perfect positive correlation).
Lecture 11 Making a Map with GIS
1. What is a Map?
1.1 Definition
A map is an essential and distinctive tool for geographers to present spatial data and phenomena. Here is a common definition of a map:
“A graphic depiction of all or part of a geographic realm in which the real-world features have been replaced by symbols in their correct spatial location at a reduced scale.”
On maps, a road in the real world is represented by a line (Figure 1). The line is a symbol which has no meaning without a legend and interpretation by the user. Mapping is more complicated than taking the final product of a GIS analysis, giving it a legend and a title, and hitting "print." There are many design considerations that should be taken into account to produce a good map.
1.2 Map elements
Map elements are the building blocks of maps. Figure 2 is a simple map showing ecological zones of Joshua Tree National Park. We can see it includes elements like a title, the source of data (credits), scale, and symbols. These are the elements that comprise a map.
Making sure that all map elements are properly applied is important; it ensures the information contained in the map is clearly conveyed to readers. Most maps have a concise title, an explanation of the map's scale, and a north arrow. Choice in map orientation (portrait versus landscape) and placement of map elements are also important to the visual appeal of the map.
1.2.1 Title/Subtitle
All maps should have a title which describes the content of the map. The title usually conveys the following information:
What is the content of the map?
Where is the geographic area?
When did the geographic phenomenon or event occur?
The title should be the biggest text on the page. Sometimes a smaller subtitle is used to provide more information.
Figure 3 is a map depicting the 2008 U.S. presidential election results. It is titled "United States Presidential Election 2008" which indicates the content. The smaller subtitle indicates that the vote results are county-level data collected on Nov 6, 2008. This text tells you what you need to know about the content of the map.
1.2.2 Projection
The projection used to create a map influences the representation of area, distance, direction, and shape. These characteristics are important to the interpretation of the map.
Including projection and coordinate system information is especially important when someone else wants to combine your map with other data in GIS. Figure 4 is a map showing unemployment rates vs. suicide incidence in the U.S., and the text in the top right says it is in the North American Equidistant Conic projection.
1.2.3 Legend
The legend tells the reader what the symbols and colors on the map represent. A symbol is a picture on the map that represents something in the real world. Maps use a legend to explain the meaning of each symbol used in the map.
The legend usually includes a small picture of each symbol used on the map along with a written description of its meaning. In Figure 4 there are two legends: the one on the right bottom corner means that the map uses different colors to show the unemployment rate of each state. The legend at the middle bottom of the map indicates that on top of each state, circles with different sizes are used to illustrate the number of suicides within each state. Another example can be found in Figure 5. The top left legend and the bottom legend show how air temperatures and precipitation levels are represented by colors. The top right is a legend for a map showing per-pupil public education expenditure.
1.2.4 Source and credits
Maps may also include some information related to the sources and credits of the map, such as:
Data sources and citations (i.e., data source: UN World Fact Book)
The map makers and the date of creation
Disclaimers and legal information
Map series information
Copyright and use issues
Unless it is absolutely clear from the context in which a map appears, readers will need to know the sources from which the map's information was derived. One must identify the sources so readers can check the original information. Often the timing, accuracy, and reliability of sources are critical to the interpretation of a map and should be noted. Sometimes it is also important to indicate how the data was processed, grouped, generalized, or categorized.
1.2.5 Direction indicator
A map's direction indicator is usually displayed as a North arrow or graticule. A directional indicator should be used 1) if the map is not oriented north, and 2) the map is of an area unfamiliar to your intended audience. Directional indicators can often be left out the map if the orientation is obvious.
If North is not a constant direction (i.e. the map covers a large area as in Figure 6), a graticule or grid can be used to indicate direction since the lines of longitude (meridians) run north to south and the lines of latitude run east to west.
Most of the time in medium to small-area maps, a single north arrow is enough to indicate direction. In Figure 4 you'll see a simple north arrow at the top left. There are many directional indicators of different styles available in a GIS software package (such as ESRI ArcGIS, Figure 7). If a north arrow is included, one should avoid making it too large or too elaborate.
1.2.6 Scale
Every map should tell the reader its scale. To represent scale on the map, we can choose from different styles such as a verbal scale, a representative fraction, or most commonly, a graphic scale. The choice of scale will influence how much information the map can contain and what symbols and features can be used to create the map. Please review "Lecture 6 - Map Scale" to review the concept of map scale.
1.2.7 Inset
Some maps have insets — smaller maps on the same sheet of paper. Inset maps can be used to show more detail or to show a larger region that isn't shown on the main map. For spatial informations that cannot fit in the same spatial context, we need an inset to either scale down or scale up.
Scale-down inset
The left figure in Figure 8 shows a map of Tennessee. However, the reader may not know where that state is. Therefore an inset map of the U.S. is shown at the bottom left corner with the same shading. This is called a scale down inset: an inset which zooms out to show the location of the main mapped area.
Scale-up inset
The scale-up inset is the opposite. For example, a map of Manhattan is quite often an inset in a map of New York City because it shows a lot more detail that we can't get from the main map. Figure 8 (right) shows a population map of California with a scale-up inset showing more detail for the San Francisco bay area.
1.2.8 Label
A label is a piece of text attached to the map’s features. GIS packages typically allow you to label map features: adding things like the names of rivers, roads or cities to the map using an automatic placement tool or allowing you to move and place individual labels.
Labels should follow a strict set of rules. Point, line, and area features have difference placement rules. For example, as shown in Figure 9, point labels should be placed above and to the right of point features. Line labels should follow the direction of the line, and curve along with the line if necessary. Area labels should be placed on a gently curved line following the shape of the feature
In summary, almost maps must include certain basic elements that provide the reader with critical information. Some elements are found on almost all maps no matter the type, while others depend heavily on the context in which the map will be read.
These are elements found on virtually every map:
Scale
Direction Indicator
Legend
Sources Of Information
Essential elements that are sensitive to context and included on most maps:
Title
Projection
Cartographer
Date Of Production
Elements that are used selectively to assist in communication:
Neatlines (a neatline is merely the boundary separating the map from the rest of the page)
Inset
2. Mapping Spatial Data in Six Steps
2.1 Choose a map type
The first step is to choose an appropriate map type. Map types are methods cartographers designed for cartographic representation.
In the 3000-year history of cartography, cartographers have designed numerous ways of showing data on a map. We have introduced reference maps and thematic maps, but these categories can be further divided into different map types. For example reference maps include a variety of map types that show the boundaries and names of geographic areas. There are different types of thematic maps, such as choropleth maps and cartograms. (We will introduce thematic maps in the lecture on thematic maps).
There is not a single GIS package/software that supports all map types. For example, if you want to create a 3 dimensional map, many GIS software would be unhelpful. Fortunately, most GIS tools do support the design of several basic map types. The same data can be mapped by different methods. Choosing the correct method requires understanding what you are mapping and your goals for the map.
2.2 Choose a layout & a template
In GIS, a map is put together by assembling all of the elements together in a layout. A good way to think of a layout is a digital version of a piece of paper with all map elements arranged on it. Choice of map layout, such as direction of the page (portrait versus landscape) and placement of map elements affects the visual results of the map.
GIS software usually includes several map templates which are pre-created designs. Just like how PowerPoint gives you presentation templates, you can select a pre-designed map template in most GIS software.
Using a template will take your GIS data and place elements like the title, legend, and north arrow at pre-determined locations and sizes on the layout. Templates are useful to create a quick printable map layout, but GIS software will also allow you to design a map from scratch.
2.3 Display attributes on the map
A layer’s attributes are usually displayed as information on the map. For example, to create a map of the 2008 U.S. presidential election results by State (Figure 10), each polygon representing that State would have an attribute designating whether Barack Obama or John McCain had a higher number of votes for that State (red states were won by McCain, blue states were won by Obama).
2.4 Classify data
More than often, the attributes are not simply two choices (as in Figure 10 where each county is marked either Obama or McCain). Attributes such as the percentage of colleges and universities per state are numerical data, having a wide range of values. In order to best display such data on a map, data classification is required.
Before we make a map we need to classify the attributes into categories. Data classification is the process of arranging data into a few classes or categories to simplify and clarify presentation. Each class can be represented with different symbols and colors. There are two purposes of classification: 1) to make the process of reading and understanding a map easier; 2) to show attributes or patterns that might not be self-evident.
Figure 11 shows a classification of the world's population density. The density figures range from 0 to more than 1,000. We thus classify them into nine categories when displaying them on the
map.
GIS software typically gives several options for data classification. However, each method classifies data differently and can result in very different representations on the map. Therefore, we need to use the optimal method based on data, desired output and goals of the maps.
There are four typical methods of data classification available: natural breaks, quantile, equal intervals, and standard deviation. Figure 12 shows four different maps which use different classification methods based on the same data to show the percentage of seasonal homes in each state. Note that the number of classes or categories is the same (four) for each map.
Natural Breaks
The Natural Breaks method takes all the values and looks at how they’re grouped together. This method identifies breakpoints between classes using a statistical formula, which minimizes the variance within each of class and maximizes the differences between classes. In this way, Natural Breaks finds groupings and patterns inherent in your data. For example, in Figure 12a, states with the lowest percentages of seasonal homes values (such as Nebraska, Oklahoma, and Texas) end up in one class, and states with the highest percentages of seasonal homes (such as Maine, Vermont, and New Hampshire) end up together in another class.
Quantile
The quantile method tries to distribute values so that each range has a similar number of features in it. For instance, with 51 states being mapped (plus the District of Columbia as a 51st area), each of the four groups will have ~13 states in each class. Since the break points between the ranges are based on the total number of items being mapped, rather than the actual data values being mapped, the Quantile method causes a relatively even distribution of values on the map.
Equal Intervals
The Equal Interval method (shown in Figure 12c) creates a number of equally sized ranges of values and then splits the data values into these ranges. In the seasonal home maps, the data is divided into four classes, and the range of values goes from the state with the lowest seasonal home percentage (0.6% of the total housing stock in Illinois) to the state with the highest seasonal home percentage (15.6% in Maine). Equal Interval takes the complete span of data values (15% = 15.6% - 0.6% in this case) and divides it by the number of classes (in this case, four), and that value (in this case, 15% / 4 = 3.75%) is used to compute the break point between classes. So the first class represents states that have a seasonal home value of 3.75% more than the class’ lowest end (for instance, the first class would have values between 0.6% and 4.35%). Note that this method simply classifies data based on the range of all values (including the highest and lowest) but does not take into account clusters of data or how the data is distributed. As such, only a few states end up in the upper class because their percentages of seasonal homes were greater than three-fourths of the total span of values.
Standard Deviation
A standard deviation is a value's average distance from the mean (average) of all values. In the standard deviation method, the breakpoints are based on these statistical values. For example, in Figure 12d, the GIS software calculated the average of all United States seasonal home values (3.9%) and the standard deviation (3.1%). These values are used to set up the breakpoints. The breakpoint of the first range is a half of the standard deviation value lower than the mean: mean minus 0.5 times the standard deviation (3.9% - 0.5 * 3.1% = 2.34%). The fourth range consists of those counties with a value greater than 1.5 times the standard deviation away from the mean. The other ranges are similarly defined by the mean and standard deviation values of the housing data.
Each method classifies data differently and can result in very different results displayed on the maps. Figure 13 shows six different maps of the percentage of foreign born Florida residents. Each of the maps was created using a different data classification technique. Note that each map has the data broken into the same number of classes (six).
Quantile method: each class contains the same number of features.
Equal interval method: divides the range of attribute values into equal sized sub-ranges. The features are then classified based on those sub-ranges.
Standard deviation method: identifies breakpoints between classes using a combination of mean and standard deviation.
Natural Breaks method: finds groupings and patterns inherent in your data. It minimizes the sum of the variance within each of the classes to make them more unique.
2.5 Symbolize the data
Symbolization is the process of choosing symbols to represent features, attribute values, or classes of attribute values. The most important requirement for map symbols is that they should be readily recognizable and suited to the scale of the map. In cartography, the ways in which a symbol can vary (which are often called visual variables) includes shape, size, and color. We can use symbols with a specific combination of shapes, sizes, and colors to represent anything on a map (Figure 14).
Shape: Map symbols with different shapes imply differences in quality or type. Sometimes map symbols are designed to reflect the characteristics of the features. For example, a map showing the location of clinics uses a cross symbol. Crosses remind us of clinics and hospitals. A map showing the location of airports uses an airplane symbol. Rivers and roads are represented by lines.
Size: We can use symbols with different sizes to intuitively suggest differences in quantity or degree. For example, a map showing the location of houses can use differently-sized circles to indicate the size of the houses; a big circle means a big house.
Color: The choice of color is important to making an attractive map, and different colors can also indicate changes in quantity. For example we can use green, yellow and red to indicate small, medium, and large (Figure 14). Just like in Figure 5, we use colors from purple to red to indicate low to high air temperature.
3.6 Export the map
Once a map has been designed and formatted, it is time to share it. There are several formats in which a map can be distributed; two common formats are JPEG (Joint Photographic Experts Group) and TIFF (Tagged Image File Format).
Images saved in JPEG format can experience some data loss due to the file compression involved. Consequently, JPEG images have smaller file sizes.
Images saved in TIFF format have a much larger file size but are a good choice for sharper, more detailed graph
Key Terms
map: a graphic depiction of all or part of a geographic realm in which the real-world features have been replaced by symbols in their correct spatial location at a reduced scale
legend: a guide to what the map's symbols represent. It usually includes a small picture of each symbol used on the map along with a written description of its meaning.
directional indicator: an element showing the direction of the map which usually comes as a north arrow or graticule
inset: smaller maps used to reveal details not shown on the larger map
label: a piece of text attached to map features
reference map: a type of map that emphasizes the geographic location of features
thematic map: a type of map designed to show a particular theme connected with a specific geographic area
map layout: a collection of map elements laid out and organized on a page
data classification (mapping attributes): the process of arranging attribute data into a few classes or categories to simplify and clarify presentation
symbolization: the process of choosing the symbols (a combination of shape, size, and color) to represent features, attribute values, or classes of attribute values
Lecture 12 Thematic Maps I - Qualitative and Quantitative Data
1. Map Types
Reference maps show the simplest properties of geographic features in a specific area, such as political boundaries, roads, water bodies, and cities. One example of a reference map is a world map, which shows the boundaries of continents, oceans, and countries, their names, as well as important water bodies (Figure 1).
One of the most commonly used reference maps is a topographic map. A topographic map shows topological features including terrain elevation, water networks, boundaries, roads, towns, cities, and labels showing the names of important features. For example, Figure 2 is a 1:62,500-scale topographic map of Madison from 1940. The brown irregular curves are contour lines that represent changes in the terrain's elevation. The blue lines and patterns shows water features such as lakes, swamps and streams. Some important features like the big lakes and towns are labeled with their names.
A thematic map is another type of map that shows one or a few themes of information for a specific area, which is often coded, colored, or grouped for convenience. These maps usually describe the physical, social, political, environmental, and cultural properties of defined area. For example, the left panel in Figure 3 shows U.S. poverty levels in 2010; it does this by coloring counties by the percent of people under the poverty line.
2. Geospatial (GIS) Data
2.1 Overview
Maps are used to display data, both spatial and non-spatial. A good map lets data speak to the reader in an attractive way. Before we go further into the art and science of map making, we need to understand data itself.
"Phenomena are all the stuff in the real world. Data are records of observations of phenomena."
Maps show us data, not phenomena. Therefore, carefully think about the data you're mapping; it is important to think about how the data relates to real world phenomena and how the interpretation of the data affects our understanding of the phenomena. There are many ways to classify data, each of which emphasizes a specific aspect of the data:
Classify based on how the data is organized in digital format (Figure 4)
Vector or raster data
Classify based on what kind of geographic phenomena the data represents:
Continuous or discrete data
Point, Line, Area, or Volume data
Classify based on how the data defines or describes the geographic phenomena:
Qualitative or quantitative data
Classify based on levels of measurement. Here a measurement level describes the nature of numerical information about geographic features.
Nominal, ordinal, interval, or ratio data
2.2 Point, Line, Area, or Volume data
Geographic data can be categorized the physical shape/dimension of geographic phenomena, such as point, line, area and volume. For example, a point phenomenon is something that occurs at a point in space defined solely by a geographic location without width or area at the scale of the map. We can use point data to depict point phenomena.
Point phenomena describes things like houses or cities, which may be too small to be represented by areas or polygons on a map for a given scale. For example, in a world map of major cities, each city is represented as a point (Figure 6).
Line phenomena describes features that follow a line without a defined width at a certain scale. A river or road map are good examples of line phenomena (Figure 7).
Area phenomena occupies an area on the map, such as houses, forests, lakes, counties, and even buildings at a large enough scale. For example, in Figure 3, counties are areas/polygons.
Volume phenomena occupies a volume in space (including length, width, and depth) at the scale of the map. Examples include mountains and ocean trenches.
Note that the classification of geographic features as point, line, area, volume only matters at a specific scale of the map. Almost everything in the real world is a volume to us; a house, a farm, or a city occupies space. However, those features could be abstracted as points, lines or areas depending on the map’s scale.
For example, a large-scale city map (such as Madison, WI) for reference purpose might show the location and dimension of all the buildings in a city block, or the location of all the churches, social organizations, and bars in an urban neighborhood. However, in a small-scale map of all cities in the U.S., each city is represented as a single point.
2.3 Discrete and continuous
Data describing the geographic phenomena could be discrete or continuous.
Discrete data represents discrete phenomena with distinct boundaries. A district, houses, towns, agricultural fields, rivers, highways are good examples of discrete phenomena. Sometimes discrete data is also called categorical data, which often represents objects. These objects usually belong to a class (for example, soil type), a category (for example, land-use type), or a group (for example, political party). Such objects (categorical objects) have known and definable boundaries. For example, Figure 8 shows a land use map for Chicago in 1950. The land use types, such as development, forest, and agriculture, are discrete phenomena represented with specific colors in bounded areas. Note that discrete phenomena change abruptly, like laws change from one jurisdiction to another. In this example, when agricultural land is converted to urban land, its value in the map changes from agriculture to development directly. There is nothing in between.
Continuous data represent continuous phenomena which have no defined borders, but a smooth transition from one value to another. Examples of continuous surfaces are elevation, aspect, slope, the radiation levels from a nuclear plant, and the salt concentration from a salt marsh as it moves inland. Continuous phenomena, such as air temperature, precipitation, and elevation vary continuously without incremental steps. For example, Figure 9 shows an air temperature map of the U.S. Note that the temperature is a value that changes continuously, i.e. from 66 to 66.01. There is always something in between two values of temperature.
2.4 Qualitative and quantitative
Data can be organized into two broad categories: qualitative (differences in kind) or quantitative (differences in amount). This is a fundamental classification of the GIS data, as each one has distinctive methods of analysis and symbolization.
Qualitative data show the categories of things expressed by means of a natural language description. Examples include land cover types, soil types, language and religion, and major in college. Figure 6 shows qualitative data: the name of major cities of the world. Figure 8 shows another example, which is the land use types across Chicago.
Quantitative data depicts the magnitude (e.g., size, importance) of things, expressed in numbers. Such data can be quantified and verified. Examples include population density and annual rainfall. Figure 3 shows the percent of population in poverty of each county in the U.S., which is expressed as a quantity. Figure 9 shows air temperature, another example of quantitative data.
In a word, qualitative data describes things, whereas quantitative data measures things.
2.5 Level of measurements
The level of measurement is a way to describe the the scaling of data in statistics. There are typically four levels of measurement. They can help us to better understand the nature of the data we are going to map and design the most suitable way of analyzing and displaying it.
Nominal (qualitative)
Ordinal (quantitative)
Interval (quantitative)
Ratio (quantitative)
The first belongs to qualitative data, and the other belong to quantitative data.
2.5.1 Nominal
Nominal data has no order and thus only gives names or labels to various categories. Nominal data consists of categories used to distinguish different types of features. Values in nominal data are used to distinguish one feature/object/phenomena from another. They may also establish the group, class, member, or category with which the object is associated. These values are qualities, not quantities. Classes for land use, soil types, or any other attribute qualify as nominal measurements.
Other familiar examples of nominal data include,
Gender
Religion
College major
Jersey numbers
The values of nominal data are NOT always descriptive. They could be stored as words or a numerical code. For example, social security numbers, zip codes, and telephone numbers are all nominal data. The difference between these numbers and values in quantitative data (such as air temperature) is that these numbers, such as zip codes, have no numerical meaning and are not measurements of anything. They serve the same function as a name.
Nominal data are descriptions for features with no order. For example, jersey numbers in basketball, though numerical, are measures at the nominal level. This number does not imply order or convey quantitative information (size or importance of each category). A player with the jersey number 30 is not more of anything than a player with the jersey number 15. Nominal scales are therefore qualitative rather than quantitative.
Figure 11 gives an example of a map of a nominal data - election results. Based on the legend, we know that there are four nominal values: McCain, Obama, No Returns yet, and Returns available. Each state is assigned to one of those categories.
2.5.2 Ordinal
Ordinal data includes values with order, which allows comparisons of the degree between two values. Examples of ordinal data include: scale of tree size (small, medium, and tall), scale of pain (ranked from 1 to 10), movie ratings (one star to five stars), scale of hotness (hot, hotter, hottest), etc..
Ordinal variables have meaningful order, but the intervals or difference between values are not necessarily equal. For example, the gap (Figure 12) between hot and hotter may be small, whereas there might be a big discrepancy between hotter and hottest. Patients are asked to express the amount of pain they are feeling in a scale of 1 to 10. A score of 7 means more pain that a score of 5, and that is more than a score of 3. But the difference between the 7 and the 5 may not be the same as that between 5 and 3. The values simply express an order. There is still no quantifiable numeric difference between the values.
Ordinal values show the position in a rank, such as first, second, and third place, but they do not establish magnitude or relative proportions. How much better, worse, healthier, or stronger something is cannot be demonstrated from ordinal numbers. For example, a runner who was first place in a race probably did not run twice as fast as the second-place runner. Knowing the winners only by ranking place does not mean you know how much faster the first-place runner was compared with the second-place runner. This explains why nominal data is qualitative.
Figure 13 is an ordinal map showing the groundwater productivity for the area around Pohang City, Korea. The ground water productivity ranges from very high to low. Here, we use different colors to indicate different ranks.
2.5.3 Interval
Interval data consists of numerical values on a magnitude scale that has an arbitrary zero point. Those numerical value can order from low to high, with a numeric difference between the classes. Land elevations are an excellent example of interval-level data, since the zero level (datum defined by geoid) is arbitrarily defined as mean sea level.
When looking at interval-level data on a map, know that the numerical intervals (differences) between values are meaningful, but ratios between two values are meaningless.
A good example of an interval scale is the Fahrenheit scale for temperature. Equal differences on this scale represent equal differences in temperature. For example, the difference between a temperature of 30 degrees and 20 degrees is the same difference as between 20 degrees and 10 degrees, where both are 10 degrees lower. However, a temperature of 30 degrees is not twice as warm as one of 15 degrees. You can not say, for example, that one day is twice as hot as another day
Here is another example. A student who scores 90% is probably a better student than someone who scores 45%. The difference between the two scores is 45%. But this doesn’t make the first student twice as smart.
Figure 14 is a map of global annual mean temperature. Temperature is an example of interval data. In addition to being ranked from low to high, temperature also includes numerical values.
2.5.4 Ratio
Ratio data also consists of numerical values on a magnitude scale. However, in contrast to interval-level data, the zero point is not arbitrary. The zero point is clearly defined and typically the zero point denotes absence of the phenomenon.
You will find many thematic maps showing ratio-level data, such as maps showing population density (or any other density), annual precipitation, crime rate, tree heights, tax rate, family income, all of which are ratio-level data. We could have zero crime rate, which denotes a total absence of crime. Therefore ratio-level data have all the properties of interval-level data, but in addition, it also has a natural zero value. When the variable equals 0.0, there is none of that variable.
While ratios are meaningless for interval data, ratios between two values are meaningful for ratio data. Good examples of ratio-level data include height, weight, or measurement of time. A weight of 4 grams is twice as much as a weight of 2 grams; therefore weight is ratio-level data.
Figure 15 shows the population in Florida by county. Since population can have a zero point that indicates a total absence of population, it is ratio-level data.
Key Terms
Reference Map: a type of map showing the simplest properties of the geographic features in a specific area, such as political boundaries, roads, water bodies and cities.
Topographic Map: a type of map showing topological features including terrain, water networks, boundaries, roads, towns, cities, as well as labels showing the names of important features.
Thematic Map: a type of map showing one or a few themes of information for a specific area, which is often coded, colored, or grouped for convenience. These maps can portray physical, social, political, cultural, economic, sociological, agricultural, or any other aspects of a specific area, such as a city, state, region, nation, or continent.
Point Phenomenon: phenomenon that occurs at a point in space defined solely by a geographic location without width or area at the scale of the map.
Line Phenomenon: phenomenon that describes a thing that follows a line without width at the scale of the map.
Area Phenomenon: phenomenon that occupies an area on the map; depending on the scale, this could include a house, a forest, a lake, a county, or even buildings.
Volume Phenomenon: phenomenon that occupies a volume in space (including length, width, and depth) at the scale of the map.
Discrete Data: data that represent discrete phenomena or an object with distinct boundaries. These phenomena/objects usually belong to a class (e.g. soil type), a category (e.g. land-use type), or a group (e.g. political party), which have definable boundaries.
Continuous Data: data that represent continuous phenomena which has no defined borders, but which has a smooth transition from one value to another.
Qualitative Data: data that shows the categories of things expressed by means of a natural language description (e.g. words) or sometimes numbers which have no numerical meaning (e.g. basketball jersey numbers).
Quantitative Data: data that portrays the magnitude (e.g., size, importance) of things, expressed in numbers.
Nominal Data: qualitative data that has no order and thus only gives names or labels to various categories.
Ordinal Data: quantitative data that includes values with order, which allows comparisons of the degree between two values.
Standard deviation cannot be calculated
Interval Data: quantitative data that consists of numerical values on a magnitude scale that has an arbitrary zero point. Those numerical values can order from low to high with a numeric difference between the classes, but with no absolute value for the numbers and an arbitrary zero point.
Ratio Data: quantitative data that consists of numerical values on a magnitude scale. However, in contrast to interval-level data, the zero point is not arbitrary: there is a clear definition of the zero point. Typically, the zero point denotes absence of the phenomenon.
Lecture 13 Thematic Maps II: Qualitative Map
1. Overview of Thematic Maps
From the last lecture, we know that mappable data can be qualitative or quantitative. Qualitative data shows the types/categories of features, while quantitative data portray the magnitude of features/attributes.
Thematic maps can also be qualitative or quantitative depending on the type of data mapped. Qualitative maps describe the location or distribution of a phenomenon and use nominal and ordinal data. Quantitative maps describe the magnitude or value of a phenomenon and use interval or ratio data.
Figure 1 is a map of the U.S. death rate by county between 1988-1992. According to the legend and title, we can see that this map is displaying ratio-level data. Therefore, this is a quantitative thematic map.
Figure 2 shows another map of the U.S.'s largest ancestry populations by county in 2000. The legend tells us that each county in the map is colored based on the ancestry type that has the largest population in that county. The data is nominal. (Do you know why?) Thus this is a qualitative thematic map.
Based on how many attributes/variables/phenomenon are displayed on a map, thematic maps can either display a single theme or multiple themes.
Single-theme maps depict only one theme (i.e. one attribute) at a time. This means only one column in the attribute table will be displayed on the map.
Multivariate maps depict the geographical relationships between two or more phenomena.
Both single-theme and multivariate maps use points, lines, and areas to display features. In this lecture, we will learn how to use point, line, and area symbols to create qualitative thematic maps.
2. Single-theme Maps
2.1 Graphic elements/visual variables for qualitative mapping
Cartographers use different symbols or graphic elements on the map to represent points, lines, and areas features. Certain graphic elements work well for qualitative data because they do not encode magnitude or quantitative information; others, such as color intensity or size, work better for displaying quantitative data.
The visual variables that effectively display qualitative differences are shape, orientation, and color hue (Figure 3).
Different shapes imply differences in type rather than differences in magnitude. A square is different from a circle, but a reader would not assume that a square is more than a circle; it's just different. For example in Figure 3, a house symbol represents a house, while a pickaxe symbol represents a mine. Different types of lines can also represent different kinds of transportation corridors. A shape can also be repeated to create a pattern.
Likewise, orientation can be used to create patterns that show qualitative differences for features. For example, a tree symbol oriented north or east can show whether the tree is dead or alive.
Color hue simply means different colors. Symbols with different hues imply differences in quality or type. For example, we can change the color hue indicate whether a tree is dead or alive; green for live, and brown for dead.
Figure 4 is an example of a single-themed map using color to differentiate forest classes in northwest Oregon. Note that color lightness is also used: the symbols for the first few classes in the legend are greens of different lightness. We usually want to represent the geographic feature in colors similar to how it would appear in the real world. Therefore, trees or forests are usually green.
2.2 Point feature maps
Point feature maps use symbols which show the location of an object. The point symbols can be geometric, mimetic, or pictographic (Figure 5).
Geometric symbols use simple shapes, such as squares, circles, and triangles to represent features. As they are simple they usually require a legend to be interpreted correctly.
Pictographic symbols are designed to look very similar to their real-world counterparts. For example, Figure 5 (D) shows a realistic symbol of a house. These detailed symbols immediately remind map readers of the real-world features they are supposed to represent.
Mimetic symbols lie between geometric and pictographic symbols. They are often created from a combination of geometric shapes, such as a square with a triangle on the top to represent a house. Sometimes, they can be more complex, like a small cartoon. These symbols can be both intuitive and simple, and are popular in mapping point features. For example in Figure 5, both B and C are adequate to indicate a house without the complicated colors and textures of D. You will find mimetic symbols on tourist maps, recreational maps, and airport maps.
2.3 Line feature maps
Line features, such as roads, streams, or boundaries can be represented with different line symbols. Appropriate visual variables such as shape, orientation, and color hue can differentiate line features of different types (Figure 8).
Shape is commonly used to distinguish categories of line features. For example administrative boundaries are often shown with dashed lines, and railroads are shown using a solid line with cross-hatches that mimic railroad ties.
Different color hues can differentiate feature categories. We can use colors to show different boundary lines: in Figure 8, a red line means a national border, and a yellow line means a state border. For example, Figure 9 shows a map of railroad line ownership where different owners get different line colors. Some hues have been standardized for certain features. For example rivers are usually shown with blue lines, administrative boundaries are displayed with red lines, roads with black lines, and contour lines in brown.
Typically, variations in both color hue and shape are used to represent a greater variety of line features.
Although line features may have no actual width in the spatial data, the real geographic features they represent usually have an actual width on the ground. For example, a river has width in reality but is usually shown with a narrow line on a map.
Figure 10 is an example of a line feature map: the streams in the Columbia River watershed. The lines do not accurately reflect stream width; the width of the lines actually shows variations in stream flow, not the actual width of the stream in real life. If you measured the width of a blue line that represents a stream and converted it to real-world ground distance using the scale, it would be much wider than the real-life stream.
2.4 Area feature maps
To create area symbols that represent different types of area features, we can use color hue and/or patterns (Figure 11).
For example we can use two colors to show the states carried by the democratic (blue) and republican (red) party presidential candidate in an election map. Alternatively, we can use donkeys as mimetic symbols to fill the Democratic states as a pattern, and elephants for the Republican ones. We might also use a combination of pattern and hue (red elephants and blue donkeys) to make it even more obvious; but most area features are differentiated simply by color.
Figure 12 shows an example of a qualitative thematic map: a map of ecoregions. Colors, such as red, green, purple, and brown, are used to distinguish different ecoregions. Within each type of ecoregion, color lightness and color intensity are used to show sub-classes.
3. Multivariate Maps
In single-theme maps, only one attribute of geographic features are depicted. Sometimes we want to show more information on the map and create associations between two or more geographic phenomena, such as population and GDP of a bunch of countries, or the spatial distribution of water bodies and human settlements. Multivariate maps simultaneously display multiple themes or feature attributes. Typically, we use a different symbol to represent each attribute/phenomena.
For example, Figure 13 shows a multivariate map showing both the location of cholera deaths and the locations of water pumps. The pumps are represented by a mimetic symbol of a circle with the letter "P" inside. Cholera deaths are represented by dots. Displaying both symbols helps a map reader find a spatial relationship between the two features.
The above example shows a common way to depict two or more attributes on the same map: use a separate symbol for each attribute/theme/phenomena. By varying the symbol’s shape, color hue, or orientation, qualitative attributes can be differentiated from one another. This is simple for point or line features, but for area features, which can overlap one another, there is more to consider than just choosing different symbols.
When overlaying two or more types of area symbols, the most common method is to display one attribute using color hue and show the other attribute using pattern shape (repeating a shape within the feature polygon).
Figure 14 shows a map of shellfish distribution in a coastal region of Oregon. The bottom layer displays the type of ocean bottom, symbolized by different colors. Another layer showing shellfish type is placed above the "Bottom Type" layer. In this layer, different area symbols are filled with different patterns. The vertical and horizontal dashed line pattern symbols show where crab or shrimp are harvested. The areas with “+” signs show where both crab and shrimp are harvested.
This map allows you to see if there's any geographical relationship between the ocean bottom type and the type of shellfish harvested. For example, we can see that crab is mostly harvested from areas with sand bottoms.
4. Qualitative Change Map
A qualitative change map is a type of map that shows the change of geographic phenomena. Mapping change is difficult because it can be hard to find symbols explicit enough to convey the correct information to the reader. Qualitative change maps display changes that are qualitative/categorical rather than quantitative. There are two types of qualitative changes:
Change in the category of features over time at the same location.
Change in the location of a feature over time.
There are a variety of ways show change on a map. Figure 15 shows locations whose attributes have changed over a certain time period. In this map, red areas represent land-cover change from non-urban to urban from 1986 to 2002 in the Minneapolis-St. Paul region of Minnesota. Note how the legend uses red to encode "change from non urban to urban"; this makes it easy to see that most of the change occurred at the edge of the core urban area.
Figure 16 shows another way to map changes in attributes. This maps displays change in Portland, Oregon building use between 1879, 1908, and 1955. Instead of marking building change with special symbols, this map shows three maps in a time series. They use the same basemap and symbols which helps the readers understand changes in the number of buildings and their use. This example shows another way to map changes: show a time series of maps side by side that 1) cover the same area and 2) use the same symbols and legend.
The maps in Figure 17 also show change using a series of maps over different times. These maps show dam construction over different time periods. Each map displays dams constructed during that time period with a dark purple color, and previously-constructed dams with a light purple color.
These maps let us study the long-term pattern of changes in a region by showing changes at each time period as well as cumulative changes before that time period.
The three examples (Figure 15-18) show attribute changes over time in the same location. What if the location of a phenomena is also changing? This falls into the second category of qualitative change maps. Figure 18 shows the location of the Mt. St. Helens volcanic ash plume at different time periods after eruption. In this map a series of red lines, which are called isochrones (lines of equal time difference), show the range of the ash at different times: 3 hours, 6 hours, and 9 hours after the eruption.
Key Terms
Qualitative Map: a map showing the location/distribution of a phenomenon using nominal data
Quantitative Map: a map showing the magnitude/value of a phenomenon using ordinal, interval or ratio data
Single-theme Map: a map that only depicts one theme or attribute at a time
Multivariate Map: a map that simultaneously displays two or more themes or feature attributes to describe geographic relationships between the phenomena
Geometric symbol: symbols that use simple shapes, such as squares, circles, and triangles to represent different features
Pictographic symbol: symbols that look similar to the real-world features they represent
Mimetic Symbol: symbols that imitate or closely resemble the thing it represents using simple designs, e.g. an icon of a picnic table to represent a picnic area
Qualitative Change Map: a map showing the qualitative change of geographic phenomena/features over time, such as a change in feature category or the change in the location of features.
Lecture 14 Thematic Maps III: Quantitative Map
1. Quantitative Maps and Visual Variables
1.1. Overview of Quantitative Maps
Quantitative thematic maps describe any numerical information about spatial features and their relationships. These maps answer questions like how many, large, wide, fast, high, or deep things are, using interval or ratio data. Figure 1 shows four quantitative thematic maps made using different mapping methods: isoline, choropleth, proportional symbol, and dot density. All of them convey magnitude information.
Different isolines in the upper left map indicate different amounts of solar radiation.
In the upper right map, different tones represents different portions of residents over 65 years old (choropleth).
In the bottom left map, circles of different sizes indicate different population levels for each county (proportional symbol).
In the bottom right map, different numbers of dots represent the potato planting area for each county in Wisconsin (dot density).
We will look at these quantitative mapping methods in detail later in this lecture.
1.2 Visual Variables in Quantitative Maps
For qualitative maps, we use the visual variables color hue, orientation, and shape. For quantitative maps, we prefer visual variables that can effectively impart the magnitude of phenomena to the reader: these include size, pattern texture, color lightness/color value, and color saturation/intensity (Figure 2).
Map symbols with different sizes imply differences in quantity. For point features, a larger circle implies greater quantity than a smaller circle. For line features, a wider line indicates a larger quantity than a narrower line. For area features, more volume indicates a greater quantity.
Pattern texture can imply quantitative differences by density. A finer, more tightly-packed grid is higher in quantity than a loose, coarse grid.
Color lightness can imply an increase in quantity using the darkness of the color. For example, dark blue indicates higher magnitudes than light blue.
Color saturation (or color intensity) is a subtle visual variable that is best used to show subtle variations.
A well-designed series of symbols uses variation in one or more of these visual variables to show differences in magnitude.
In Figure 3, the size (height) of the bars is used to show the population of each county in the state of Oregon in 2000. The higher the bar, the higher the population.
1.3 Quantitative Thematic Map Classification
Similar to qualitative maps, quantitative thematic maps can also be classified as single-theme maps or multivariate maps.
Single-theme maps for quantitative data can depict point, line, area, and continuous surface features or phenomena. For each type of features, we will introduce the most common method(s) to quantitatively display their attributes. Multivariate maps show the relationship between multiple attributes. There are several ways to overlay multiple layers of symbols to create multivariate maps. Figure 4 summarizes the common methods in each category of quantitative thematic maps. We will go through each of them in the following sections. You might want to refer to this figure while you are reading.
2. Single-theme Maps
2.1 Proportional symbol and graduated symbol map
For point features, proportional and graduated symbols are commonly used to show quantitative information.
Proportional maps use symbol size to represent the data value.
Graduated maps use symbol size to represent groups of values; this means that the quantitative values are grouped into intervals, and all the features within a class are shown with symbols of the same size.
Figure 5 shows three county level population maps in the San Francisco Bay area. These maps use the same data but different symbols. The left map uses mimetic proportional symbols (left), where human-shaped symbols are sized according to population. Here each symbol of a particular size represents an exact population value (e.g. the largest one represents 800,000 people). The middle and right maps use simple geometric symbols, but one uses proportional symbols, and the other uses graduated symbols.
The simplest way to tell the difference between proportional and graduated symbols is to look at the legend. In the right map, each symbol has a range of data values, which indicates that this is a graduated symbol map. Another difference is that in a proportional symbol map, symbols on the map could have a size not listed in the legend, but in graduated map, since data are grouped in intervals and each is associated with a certain symbol size, every symbol on the map must have a size listed in the legend. In the right map in Figure 5, there aren't any symbols whose size is between any two symbol sizes in the legend.
2.2 Flow Maps
Flow is defined as the movement things from one place to another, such as migrations of people, the spread of disease, and the shipment of goods between regions. Flow maps can show these transportations spatially using a line symbol called a flow line.
On most flow maps, the size (width) of the flow line is proportional to the magnitude of the flow. For example, Figure 6 shows jobs provided to Oregon by foreign-owned companies. The width of the line indicates the number of the jobs.
The direction of flow is also important. Sometimes, arrows are added to one end of the flow line to show flow direction. In Figure 6, all the flow lines have an arrow pointing to Oregon, which means that the jobs are provide to Oregon.
In addition to size (width) of the flow line (Figure 6), the magnitude of flow can be also shown by varying the texture, color saturation and color lightness of the lines.
Figure 7 shows a traffic flow map in Google Maps. From the legend you can see that the color of the flow lines indicates the condition of traffic. Heavy traffic is represented with red, and light traffic is in green. In addition the double lines mean that the road has two directions, while the single lines indicate one-way roads.
2.3 Choropleth Maps
Choropleth maps represent quantitative properties of area features by varying the lightness or intensity of color. Choropleth maps typically show density or rate information about area features (e.g., counties, states, countries, etc), such as population density or tax rate, rather than straightforward values such as totals. Figure 8 is a simple choropleth map showing graduation rates by state. Choropleth maps are perhaps the most common and effective thematic map.
To make a choropleth map, in addition to choosing the appropriate symbols (i.e. color hue, intensity, lightness) to represent the quantity of the area features, we also need to decide how to associate data values with symbols. One way is group data into classes; remember from Lecture 11 (Section 3.4) that data reclassification is an essential step in mapping. The same methods introduced in that lecture (equal interval, natural breaks, standard deviation, and quantile) also apply here.
Figure 9 shows a series of maps of Oregon population density using different data reclassification methods.
The first map in Figure 9 uses equal interval classes to divide the range of attribute values into equal sized groups. This means each group has the same interval. However, since equal interval does not account for data distribution, it may result in having most data values placed into one or two classes. For example in this map, we can see the population density of most counties fall into the first class (0.7 -390) represented with light brown color.
The natural breaks method used in the second map divides the data into classes according to the distribution of the values. This method minimizes the differences within classes and maximizes the differences between classes. For example, based on the distribution shown in Figure 10, the natural breaks are placed at 60, 150, 1000 persons per square mile. The data is divided into four classes (0.7- 60, 60- 150, 150 – 1000, 1000 - 1561). The choropleth map based on these intervals shows population variation in Oregon counties better than the first map. This classification method can show data that is NOT evenly distributed, and makes it easier to see patterns. It is an unbiased, scientific method to determine ranges. GIS software typically uses this classification method by default.
Instead of grouping the data values, we can also symbolize the data using continuous color intensity by assigning each data value a unique shade. We simply call this method "unclassified". To create an unclassified map, a unique shade/color is assigned to a unique data value. Therefore, each unique data value is in its own class and gets its own color. The last map in Figure 9 uses continuous brown shades ranging from white for the lowest density county to dark brown for the highest density. Since we did not categorize the data into classes, the map gives you an unbiased picture of Oregon population.
Changing the number of classes results in different map appearances and can convey different messages to readers. Figure 11 shows maps of Oregon population density using different numbers of classes.
The simplest map has only two classes: above and below the median. Clearly, less information is shown in this map, because one could not compare two counties in the same color. More information is shown if four classes (e.g. using quartiles or percentiles) are used. We can increase the amount of information by using more classes, but when more classes are used the map can become more difficult to read. When eight classes are used (Figure 11 bottom), it can get hard to differentiate between colors.
2.4 Cartograms
Rather than accurately display areas and use symbols with different colors/sizes to represent the attribute, cartograms distort areas in proportion to the magnitude of the variable (such as population). This can make it easier to see differences between areas and the distribution of the data.
For example, Figure 12 is a cartogram showing the world population at 2010. The size of each country is proportional to its population rather than its geographic area. In this way countries are scaled on the basis of population. You can see the size of each country is distorted, but it allows you to see the population distribution clearly and intuitively since the mapped size of each country is proportional to the size of its population.
Although cartograms are a little strange, they help overcome some of the problems that map readers have with point symbol and choropleth maps when there is a large range in the size of areal mapping units.
There are a couple of ways to make cartograms: 1) Non-contiguous cartograms, 2) Pseudo-contiguous cartograms, and 3) Contiguous cartograms. Let's look at their differences through an example in Figure 13, which shows three types of cartograms for the population of California counties.
A Non-contiguous cartogram looks exploded, meaning neighboring areas don't need to touch. This map preserves the shapes of area as much as possible but doesn't attempt to preserve any adjacencies from the original map. Each county is enlarged or reduced in proportion to its population.
A pseudo-contiguous cartogram typically transforms each area into a simple shape (square in this example). Therefore, the shape for each county is not preserved, but is represented by uniform squares instead. Even though mapped areas share common boundaries and looks contiguous at first glance, the boundaries are not real. This is why these maps are called “pseudo-contiguous”
Contiguous cartograms are the most common cartograms. On these cartograms the contiguity of neighbors is preserved, and shapes are maintained to some extent, while the area of each feature still represents the quantity. In this example, despite the shape distortion, you can see precisely which counties have the greatest population.
2.5 Prism Maps
A prism map shows the magnitude of a theme variable (or attribute) by varying the heights of area based on its value.
Here is an example of a prism map for California population by county (Figure 14). Each county boundary has been raised above the base level to a height proportional to its population. The map looks like a three-dimensional stepped surface.
2.6 Continuous Surface Maps
So far we have talked about mapping point, line and area features, which are all discrete features. We can also map a continuous surface. Continuous surface maps are used to show quantities that vary smoothly over space.
Temperature and elevation are examples of continuous surfaces that change gradually from place to place. Density distributions, such as population density, are also continuous surfaces. In Figure 15 the density of bike share stations (stations per square mile) is mapped as a continuous surface. This map differs from a choropleth map in that the changes are gradual rather than abrupt.
There are several ways to map a continuous surface. Many of the mapping methods were originally used to portray terrain elevation. Here we are also focusing on the mapping of other types of continuous surfaces.
The most important methods for mapping continuous surfaces:
Isoline/Isopleth Map
Dot Density Map
3D Perspective Map
2.6.1 Isoline/Isopleth Map
Isoline is a line that connects points of equal value on a map. Isolines are commonly used to show quantities that vary smoothly over the Earth's surface. For example, they are used on weather maps to connect areas of equal air pressure, and on topographic maps to connect areas of equal elevation.
In Figure 16, an isoline map is used to show average annual hours of sunshine in the Pacific Northwest region of the U.S. Each isoline is labeled with its value. For example, the line labeled "3000" means that every location on the line has an average of 3000 hours of sunshine per year. From this map, we can see a strong regional pattern: hours of sunshine decrease as you move from south to north.
There are two important rules of isoline maps. First, the intervals between isolines are equal. In this example the interval is 200, therefore the isoline values increase from 1800, to 2000, and on and on in increments of 200 until 3000. The second rule says that there is always a high and low side of a particular isoline. For example, if a isoline is 500 feet (152 m) in elevation, one side of it must be higher than 500 feet and the other side must be lower. It is impossible that both sides are higher or lower at the same time. Now, check both rules in Figure 16.
To assist map readers in understanding patterns, some maps use a progression of color lightness, color intensities, or textures added between isolines, and ranges of similar value are filled with similar colors or patterns. You can see a progression in magnitude from low to high, with the isolines outlining different magnitude zones. Figure 16 shows a progression of orange to light yellow to indicate values moving from high to low.
Sometimes isolines are not labeled (Figure 17), which encourages map readers to see the general pattern of highs and lows on the surface rather than concentrate on individual isolines. Since the lines are not labeled, numerical range information for each color or texture is be found in the map legend.
The isolines examples shown above describe values that exist at points, such as temperature or elevation values. There is another type of isoline map where the values are ratios that only exist over areas, such as population per square kilometer or crop yield per acre. This is call an isopleth.
Isopleths look identical to standard isoline maps, but they they show a density or ratio surface where the values can’t physically exist at points. Figure 18 is an example of an isopleth map - the population density of California is mapped as isopleths.
Isoline = data at a point
Isopleth = data over an area
2.6.2 Dot Density Maps
A dot density map uses dots to represent data values within a polygon. It's a useful method to show variations in density across a surface. Please note that dot density mapping is only used with polygons/areas. In dot density maps, each dot represents more than one feature, and the total number of dots represents the polygon’s data value. Dot density maps usually include a legend defining how much is represented by each dot.
Figure 19 is a dot density map showing population density across Cuyahoga County, Ohio. As indicated by the legend, each dot represents 150 people. Based on the attribute value of a polygon feature, we can calculate how many points should be included within a polygon. For example we know that the population in the city of Berea is 15,000 people. Since 1 dot represents 150 people, there should be 100 dots in the polygon for Berea.
Please note that on such map, the location of dots does not show the specific location of people; there isn't a literal concentration of 150 people at each dot. Rather, the density of dots in each area represents the population density in the county.
In dot density map, there are many ways to change how data is displayed on dot density maps, including
Dot value (which means the number of features represented by a dot)
Dot size (the size of the dot )
Dot color
Dot shape
The aim of dot density maps is to present an image of changing density across the region rather than giving precise locational information. Therefore, to make a good map, one needs to determine the appropriate dot, size, shape, color, and value, to avoid giving readers mistaken impressions of the changes in density.
2.6.3 3D Perspective Maps
A continuous surface can also be represented in a three-dimensional (3D) perspective map. If the mapmaker constructs closely spaced line profiles in two directions and in perspective view, you gain an impression not of individual lines but of a continuously varying 3D surface called a fishnet. The fishnet map uses lines to depict the continuous surface. In this map you can see undulations in the surface.
Notice how your attention is focused not on any one line or any one quadrilateral that is formed by the lines but on vertical undulations in the surface. It is actually the angle and length of sides of the quadrilateral that depict the surface. Note how differently this map shows the variability in California population density than does the prism map in Figure 14.
Your ability to see all locations on the map is determined by the viewpoint and viewing angle selected by the mapmaker. In Figure 20, the California population density surface is shown at a 30-degree angle above the horizon from both a north (Figure 20, top) and south (Figure 20, bottom) viewpoint. Different peaks and valleys in the surface are hidden from view on each map. Two or more maps are often required to see parts of the surface depending on the data distribution. Animated 3D perspective maps are ideal for viewing the details of a continuous surface.
3. Multivariate Maps
Multivariate maps are used to display more than one attributes on the same map. Here we introduce three methods of combining two or more themes on a single map: combined method, point symbols, and bar/pie chart.
3.1 Combined method
The most straightforward method to show multiple quantitative attributes on a single multivariate map is to combine two or more of the mapping methods we introduced in the previous section, where each mapping method is applied to one theme/attribute.
Figure 21 combines two different mapping methods - Choropleth and Proportional Symbol - to display two related variables (mining employment and production by region). A choropleth map shows the number of people employed in the mining industry of each region, while the proportional point symbols show mining production values in millions of dollars.
The advantage of combining mapping methods is that the map effectively displays 2-3 few variables, and is useful for inspecting individual distributions.
The limitations: 1) as the number of variables increases, readability decreases; 2) it is difficult to convey the relative importance of the themes/attributes displayed on the map.
Figure 22 shows another example. This map shows the spatial relationship between the spread of the West Nile virus and states' distance from the Mississippi River. To show the spread of the west nile virus, a prism map is used. The height of each prism is proportional to the number of confirmed cases of the virus. The top of each prism is colored according to its distance from the Mississippi River; the variable “distance from the Mississippi River” is displayed using a choropleth.
The map shows a strong relationship between the incidence of the virus and proximity to the Mississippi river.
3.2 Multivariate Point symbol
Another method to show multivariate quantitative data on a single map is by using multivariate point symbols. There are two ways to use make point symbols multivariate:
Display two or more variables in a single point symbol using different visual elements
Segment a point symbol to show the relative magnitudes of attributes for the features.
3.2.1 Single Point Symbol
Figure 23 is a multivariate map showing the United Nations World Happiness index, 2017, where seven social status factors are displayed using Chernoff faces. Chernoff faces use facial expressions to illustrate multiple attributes (refer to the legend in Figure 23):
The shape of the face shows levels overall happiness
The eyes represent expectation of health
The mouth indicates having someone to count on
The eyebrows represent trust in authority
and so on
3.2.2 Segmented Point Symbol
Segmented point symbols are divided to multiple parts, with each part indicating one variable. The total magnitude for each attribute is represented using point symbols that vary in size.
Figure 24 shows Oregon state income tax and local property tax per county. The legend says that each cube is divided into two parts: the left red part indicates the income tax, while the right yellow part indicates the property tax. While the volume of each cube shows the total taxes due in each county, the volume of each part (either left or right) indicates the amount of each type of tax due (income or property).
3.3 Pie or Bar Charts
Pie or Bar Charts are a very effective way to display multiple attributes, where each component (bar or slice) of the chart corresponds to attribute.
Figure 25 shows how to use bar and pie charts to represent three different attributes: property, income, and sale tax. Property is shown by the red bar/slice, income in blue, and sales tax in yellow. The size of each part in the chart is determined by the value of each attribute. In the bar chart, the height of each bar indicates the value of each attribute. In the pie chart, the size of the circle relates to the total tax due of an area. Each part of the pie shows you the relative proportion of each type of the tax (property, income, or sales).
Note that Pie or Bar Charts are only used with polygons.
Key Terms
Quantitative Thematic Map: a type of map that describes any magnitude/numerical information about spatial features and their relationships. Such maps answer questions like how much, many, large, wide, fast, high, or deep things are, using interval or ratio data.
Proportional Symbol Map: maps that use various symbol sizes to represent the value of the attribute mapped.
Graduated Symbol Map: maps that use symbols with various sizes to represent different groups of values, which means the quantitative values are grouped into intervals and all the features within an interval are shown with same sized symbol.
Flow Map: maps that show movement of things from one place to another using a line symbol with direction.
Choropleth Map: maps that represent quantitative properties of area features using lightness/intensity of colors.
Cartogram: a type of map that distorts area (size and geographic borders) in proportion to the magnitude of an attribute (such as population) in order to add visual contrast to the data and and show its distribution.
Prism Map: a type of map that shows the magnitude of an attribute by varying the heights of areas.
Continuous Surface Map: a type of map used to show quantitative variables that vary smoothly over a surface.
Isoline: a line that connects points of equal value on a map. Isolines are commonly used to show quantities that vary smoothly over a surface.
Isopleth: a type of isoline, in which the values are ratios that exist over areas, such as population per square kilometer or crop yield per acre.
Dot Density Map: a type of map that uses dots to represent data values associated with a polygon. It is only used with polygons/areas. In dot density maps, each dot represents more than one feature, and the total number of dots within a polygon represents the polygon’s data value.
3D Perspective Map: a type of map that uses the vertical height of each cell in a fishnet to represent quantitative variables that vary smoothly across a surface.
Fishnet: a type of 3D surface constructed by closely spaced line profiles in two directions. From a perspective view, the height of each grid varies to create an impression of 3D.
proportional symbol is not suitable for presenting the information of density