Biology: Chapter 5
The Structure and Function of Large Biological Molecules
Macromolecules
Macromolecules are large molecules made from the building blocks of smaller molecules. Macromolecules include large carbohydrates, proteins, and nucleic acids.
A polymer is a large molecule consisting of many smaller similar or identical building blocks linked together by covalent bonds. These smaller building block molecules are called monomers.
Polymers
Although each class of polymers is made up of different types of monomers, the processes by which polymers are made and broken down are pretty much the same for all polymers. These processes are facilitated by enzymes. Enzymes are proteins that speed up chemical reactions.
The process that connects monomers together and builds polymers is called condensation reaction. During condensation reaction, two monomers are covalently bonded together by the loss of a small molecule, usually a water molecule. If a water molecule is lost, this process is called dehydration synthesis.
Carbohydrate and protein polymers are formed by the process of dehydration synthesis. Each reactant (monomer) contributes part of the water molecule (one contributes a hydroxyl group, OH and the other contributes a hydrogen, H) and when the monomers join, the water molecule is formed and leaves them, covalently bonding the two monomers together. This covalent bond is called a glycosidic linkage (the covalent bond that joins monosaccharides).
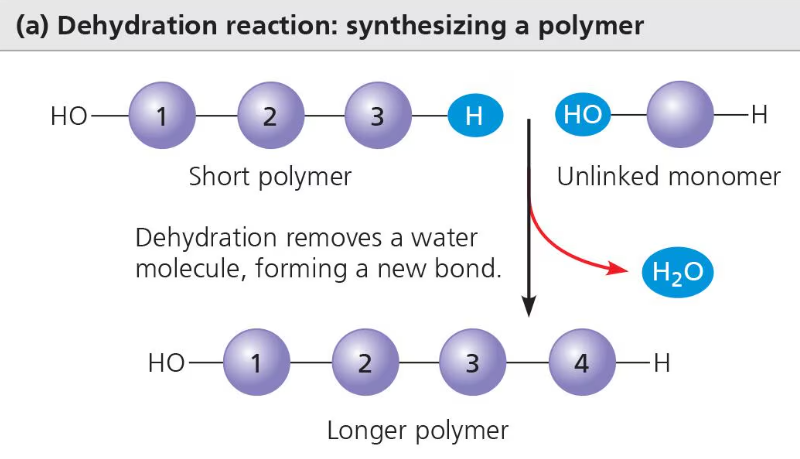
Polymers are broken down through the process of hydrolysis. It is basically the opposite of the condensation reaction or dehydration synthesis. Hydrolysis is the chemical reaction by which bonds are broken between two atoms by the addition of a water molecule. A hydrogen from the water molecule attaches to one monomer while a hydroxyl group attaches to the other, splitting the two monomers apart.
Diversity of Polymers
Most of the polymers in biology are constructed by only 40 or 50 unique monomers. However, due to the structure, these monomers can create thousands of unique and complex polymers that are important to life.
Carbohydrates
Carbohydrates include sugars and polymers of sugars. The simplest carbohydrates are monosaccharides. Monosaccharides are the monomers of carbohydrates. If two monosaccharides join together, they form a disaccharide. A polysaccharide is a polymer for carbohydrates.
Sugars
The molecular formula of monosaccharides is a multiple of the unit CH2O.
Monosaccharides have a carbonyl group and multiple hydroxyl groups. Depending on the location of the carbonyl group, the monosaccharide can either be an aldose (aldehyde sugar) or a ketose (ketone sugar).
An aldose is a sugar with a carbonyl group at the end of the sugar.
A ketose is a sugar with a carbonyl group within the carbon skeleton.

Another criterion that helps classify monosaccharides is the size of the carbon skeleton which can range from 3 to 7 carbons. Hexoses are monosaccharides with 6 sugars. These include glucose and fructose. Trioses and 3 carbon sugars and pentoses are 5 carbon sugars.
Disaccharides
A disaccharide is a carbohydrate made up of two monosaccharides joined together by a glycosidic linkage. A glycosidic linkage is a covalent bond that is formed by the process of dehydration synthesis. Examples of disaccharides:
Maltose: made up of two glucose molecules
Sucrose (table sugar): made up of glucose and fructose
Lactose: made up of glucose and galactose
Polysaccharides
Polysaccharides are are polymers with hundreds to thousands of monosaccharides joined together by glycosidic linkages. They have multiple functions in biology.
Storage Polysaccharides
Both plants and animals can store sugars for later use as storage polysaccharides. Plants store sugars in the form of starch, which is a polymer of glucose monomers. This starch represents stored energy. Sugar can be withdrawn later through the process of hydrolysis. Most of the glucose monomers in starch are joined by 1-4 linkages which are links that join the 1-carbon to the 4-carbon. The simplest form of starch, amylose is unbranched, however there are more complex branched forms of starch such as amylopectin.
Animals store a polysaccharide called glycogen. Glycogen is a extensively branched polymer of glucose. Glycogen is stored for later use in the mainly in the liver and muscle cells (in vertebrates) and broken down by cells when demand for energy increases. Th extensively branched structure of glycogen allows there to be more free branches that can be broken down. However, stored glycogen cannot fuel an animal for long.
Structure Polysaccharides
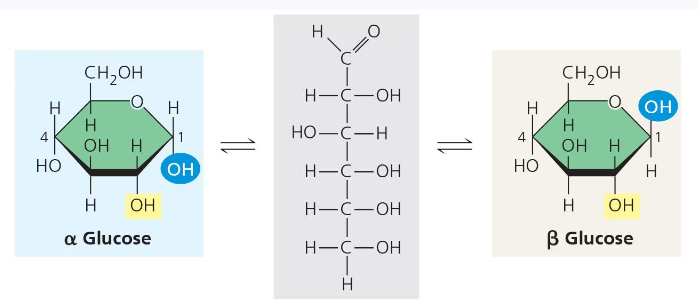
Organisms build strong materials from structural polysaccharides. For example, the polysaccharide cellulose is a major component of plant cell walls. Like starch, cellulose is a polymer of glucose that are joined by 1-4 glycosidic linkages. The difference between the two is actually in the glucose.
There are two different types of ring structures of glucose, alpha and beta. The alpha configuration which is found in starch consists of glucose monomers with the OH groups at the bottom and in the same orientation in each monomer. This same orientation between monomers makes them easier to break apart. However, the beta configuration which is what cellulose is made up of consists of monomers with opposite OH groups.
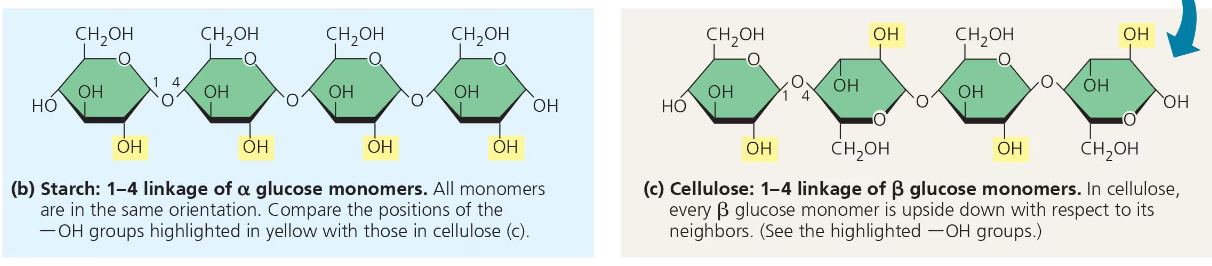
These differing structures give starch and cellulose their differing 3-D shapes. Starch has a helical shape while a cellulose molecule is straight.
Cellulose is never branched, and this feature allows it to impart strength to parts of the plant.
Enzymes that digest the alpha linkages of starch cannot also digest the beta linkages of cellulose because they have a different shape. In fact, there are few organisms that actually have enzymes that can digest cellulose.
Another important structural polysaccharide is chitin. Chitin is the carbohydrate used by arthropods (ex. spiders) to build their exoskeletons. Chitin has beta linkages, but its glucose monomers also have a nitrogen containing attachment.
Carbohydrates are also important in recognition. They are the sugars attached to blood cells as antigens that determines a person’s blood type.
Lipids
Lipids are a class of large molecules; however, they do not have large polymers and are not big enough to be considered macromolecules. The compounds called lipids are grouped together because they are all hydrophobic. This behavior is based on their function; they contain hydrocarbons with nonpolar C-H bonds. The most biologically important lipids are fats, phospholipids, and steroids.
Fats
Fats are not polymers; however, they are large molecules that are assembled from small molecules through dehydration synthesis. A fat consists of a glycerol molecule joined to three fatty acid chains.
Glycerol is an alcohol and each of its three carbons has a hydroxyl group.
A fatty acid chain has a long carbon skeleton (16 to 18 carbon atoms). One of the carbons at the end of the chain is part of a carboxyl group which contributes to the acid part of the fatty acid. The rest of the skeleton consists of a hydrocarbon chain.
Each fatty acid molecule is bonded to the glycerol molecule through dehydration synthesis resulting in the formation of an ester linkage. An ester linkage is a bond between a hydroxyl group and a carboxyl group.
A fat with three fatty acid chains (and one glycerol molecule) is called a triglyceride.
A saturated fat is a fatty acid in which there are no double bonds between the carbon atoms of the chain, so many more hydrogen atoms are bonded, making the chain “saturated” with hydrogen atoms.
Most animal fats are saturated and solid at room temperature.
A diet rich in saturated fats may lead to a cardiovascular disease known as atherosclerosis.
An unsaturated fat is a fatty acid with one or more double bonds and thus fewer hydrogen atoms. Nearly every double bond in a naturally occurring fatty acid chain is a cis double bond; this created a kink wherever the hydrocarbon chain occurs.
Most plant and fish fats are unsaturated and liquid at room temperature.
The kinks stop these fats from solidifying.
Trans fats are unsaturated fats that have been synthetically converted into saturated fats by adding hydrogen to them allowing them to solidify.
Trans fats are unhealthy and contribute to coronary heart disease.
The major function of fats is energy storage. A gram of fat stores twice as much energy as a gram of a polysaccharide. Plants are relatively immobile, so they do not need fats, but animals need fats to store energy for the future (in adipose tissue).
Fats have a lot of potential energy because they have lots of hydrocarbons.
Unlike fats, carbon dioxide has very less potential energy. This is because it is highly oxidized (has lots of oxygen).
The reason why carbohydrates have less energy than fats is because they have some oxygen. Not as much as carbon dioxide, so they do provide some energy, but they are still slightly oxidized.
Phospholipids
Phospholipids are extremely important for the structure and function of cells because they make up majority of the cell membrane.
A phospholipid molecule is similar to a fat molecule, except it only has 2 fatty acid chains attached to the glycerol instead of 3. The third hydroxyl group of the glycerol is attached to a phosphate group. Usually a small, charged or polar molecule is attached to the phosphate group.
The two ends of phospholipids show very different behaviors to water- amphipathic. The hydrocarbon tails are hydrophobic while the phosphate group and its attachments form a hydrophilic head. When added to water, phospholipids self-form into a bilayer to protect the hydrophobic tails from water.
In a cell’s membrane the phospholipids also form a phospholipid bilayer. The hydrophilic heads are on the outside of the bilayer while the hydrophobic tails are on the inside. This provides a boundary between the cell and its external environment.
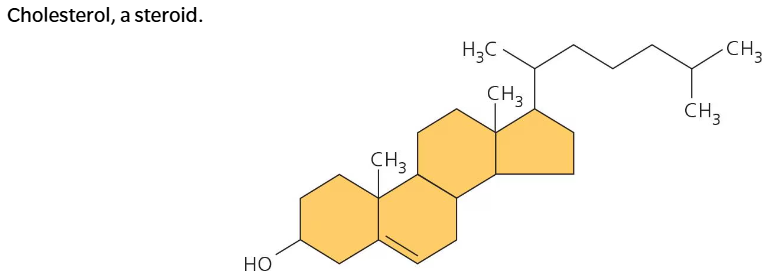
Steroids
Steroids are lipids consisting of a carbon skeleton that has four fused rings. Different steroids are distinguished by the attachments on these rings. Cholesterol, estrogen, and testosterone are all different types of steroids.
Cholesterol is an important type of steroid in living organisms and is found in animal cell membranes.
Proteins
Proteins are important in nearly every function of a living being (a cell). 50% of dry mass in most cells is made up of proteins. Proteins are the most diverse macromolecules. Proteins have several functions including speeding up chemical reactions (enzymes), storage, defense, transport, cellular communication, movement or structural support.
Most proteins are enzymes. Enzymes are catalysts because they regulate metabolism by speeding up chemical reactions without being consumed in the reaction. One enzyme can perform its function over and over again in different chemical reactions.
Every protein has a unique, three-dimensional shape that is important in allowing it to carry out its function.
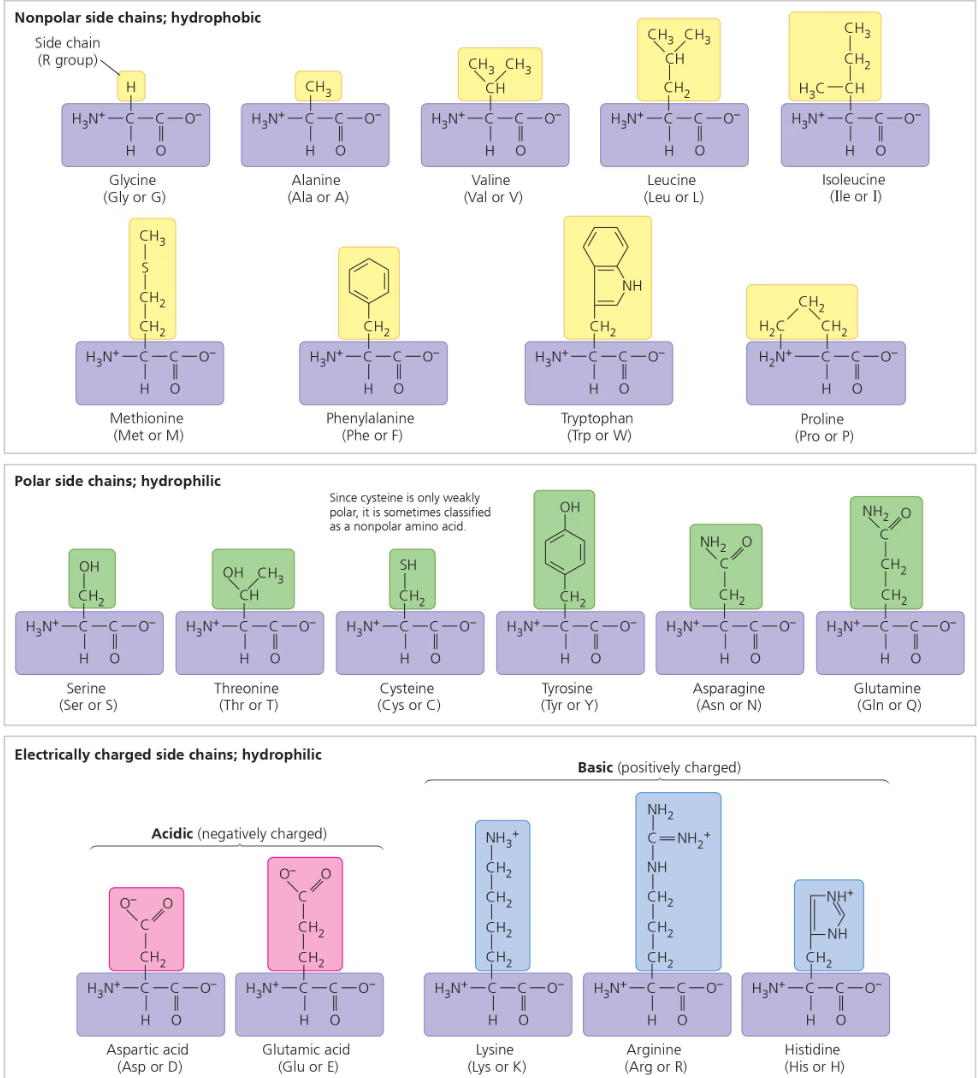
There are only 20 different amino acids, and all proteins are formed out of these 20. Amino acids are bonded together by peptide bonds, so the polymer of an amino acid (monomer) is called a polypeptide.
A protein is a biologically functional molecule that is made up of one or more polypeptide chain, folded and coiled into a unique, three-dimensional shape.
Amino Acids
All amino acids share a common structure.
All amino acids have a carbon in the middle (called the alpha carbon) that is bonded on all four sides. One side is the amino group, the opposite side is the carboxyl group, the other side is a hydrogen molecule, and the last side is an r group. The r group is different for each amino acid, and it is what makes every amino acid unique.
The R group is also known as the side chain.
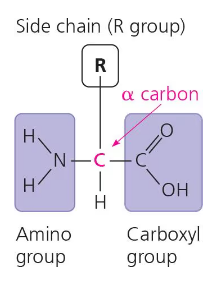
When deciding whether an amino acid is hydrophobic, hydrophilic, acidic, or basic: we need to look at the r group. Because the other parts of the amino acid are the same for every amino acid, they can be ignored when deciding the specific characteristics of a specific amino acid. Especially in the r group, the end molecule of the r group is mainly what should be considered.
Polypeptides
When two amino acids are bonding together, they are positioned so that the carboxyl group of one amino acid is next to (and bonded to) the amino group of the next amino acid. This way, they can be joined together by hydration reaction. The resulting covalent bond is called a peptide bond.
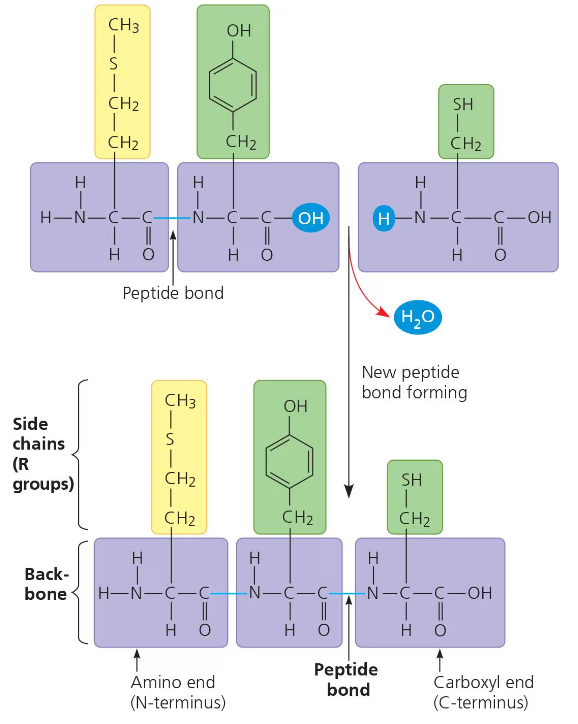
The repeating sequence of amino groups and carboxyl groups is called the polypeptide backbone.
Polypeptides may range in length from a few amino acids to thousands.
The polypeptide will have a free amine group on one side and a free carboxyl group on the other side. These characteristics will play a role in how the polypeptide folds, and thus its three-dimensional shape and chemical characteristics. The amino acid with the free amine group is called the n-terminus. The amino acid with the free carboxyl group is called the c-terminus.
Protein Structure and Function
A polypeptide is NOT the same thing as a protein. (It is sort of like the difference between yarn and a sweater that is knit from that yarn).
The amino acid sequence that makes up a polypeptide chain is what determines the specific structure of that protein under normal cellular conditions.
When a polypeptide is synthesized by a cell, the folding may occur spontaneously, becoming the functional structure for that protein. Many proteins are either shaped spherically (globular proteins) or like long fibers (fibrous proteins).
The structure of the protein determines its function. In most cases, its structure is what allows it to bind to certain molecules. For example, the antibody’s specific shape is what allows it to bind to and mark certain viruses. This characteristic of proteins is also how drugs work. Morphine, heroin, and other opiate drugs mimic the shape of endorphins and that is what allows them to bind to endorphin receptors in the brain and carry out their function. This unique shape of a protein and its binding receptor is similar to that of a lock and key.
The Four Levels of Protein Structure
There are four levels of protein structure: primary structure, secondary structure, tertiary structure, and quaternary structure.
The first three are shared by all proteins. The fourth structure (quaternary structure) is only for proteins with two or more polypeptide chains.
Primary Structure: This is the linear chain of amino acids (a polypeptide). The primary structure is not formed by random amino acids bonding together, but by genetic coding (mRNA). The primary structure in turn dictates the secondary and tertiary structures of the protein.
Secondary Structure: A polypeptide will repeatedly fold or coil itself into a structure contributing to the protein’s overall structure. This is the secondary structure. These pleats and folds are formed by hydrogen bonds between the oxygen atoms (slight negative charge) and the hydrogen atoms bonded to nitrogen (slight partial charge). Proteins (polypeptides) fold to hide the hydrophobic amino acids. There are two types of secondary structures: the alpha helix which is a coil held together by hydrogen bonding every fourth amino acid; and the beta pleated sheet in which two or more segments of a polypeptide chain lay side by side and parallel to each other (beta strands) and are connected by hydrogen bonds.
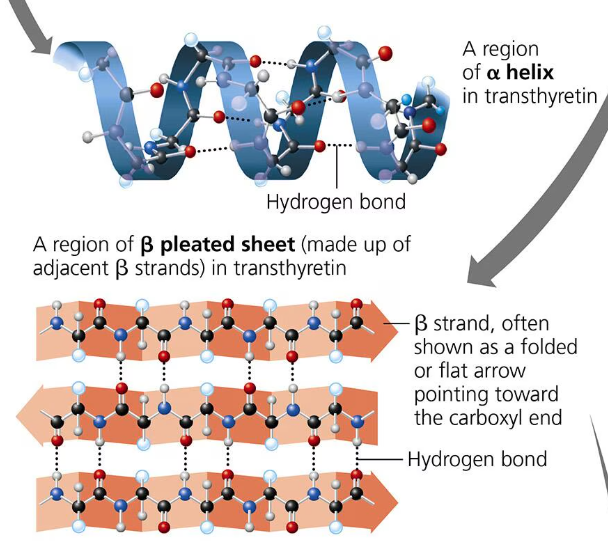
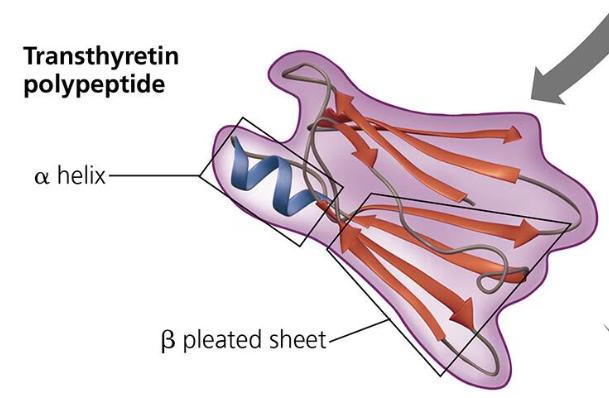
Tertiary Structure: The tertiary structure is the unique 3-d shape of a protein that results from interactions between the R groups of various amino acids in the polypeptide chain. One type of interaction that contributes to the tertiary structure is called the hydrophobic interaction. When a polypeptide folds into its tertiary shape, amino acids with hydrophobic (nonpolar) r group end up in clusters at the core of the protein away from contact of water. Van der Waals interactions hold these clusters together. Covalent bonds called disulfide bridges help further reinforce the shape of the protein. Disulfide bridges are formed when two cysteine monomers with sulfhydryl groups in their r groups are brought close to each other by the folding of the secondary structure. The sulfur of one monomer bonds to the sulfur of the other and this disulfide bridge rivets parts of the protein together.
The disulfide bond is the strongest bond contributing to the tertiary structure. Then it is ionic bond, hydrogen, and van der Waals interactions.
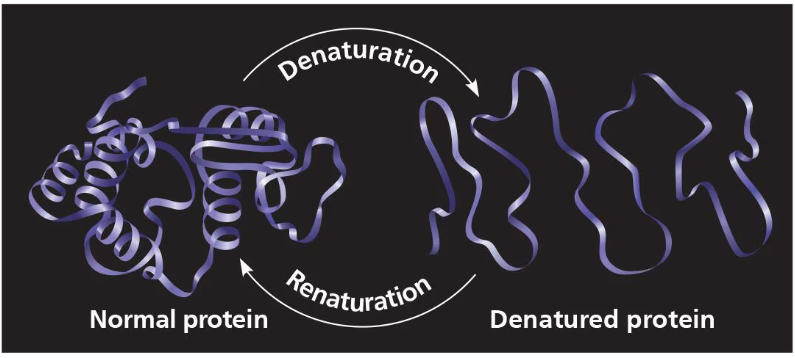
These bonds (not covalent bonds- primary structure won’t be broken) are broken in excessive heat, or pH changes. This is what leads to protein denaturation.
Quaternary Structure: The quaternary structure is the association of two or more polypeptide chains and is only found in some proteins. They are the result of the aggregation of at least two polypeptide chains. Some examples of quaternary structures are collagen, hemoglobin, and transthyretin.
The bonds of quaternary structures are ionic bonds, hydrogen bonds, and hydrophobic interactions.
Sickle Cell Disease
Even a slight change the primary structure can affect the protein’s shape and ability to function. Sickle disease is an example of this. It results when the 6th amino acid of the primary structure of hemoglobin, glutamic acid is switched for the amino acid valine. This one change in one amino acid creates abnormal hemoglobin cells that are sickle shaped and cling together creating blood clots and stopping blood flow.
What Determines Protein Structure
The polypeptide chain technically determines protein structure because it folds into the secondary structure which folds into the tertiary structure. However, the protein’s structure can be denatured if the conditions within the cell aren’t correct. pH, salt, and temperature (heat) can lead to the denaturation of a protein and at that point the protein is destroyed and will not work. Most proteins denature if they are moved from an aqueous condition to a nonpolar solvent. Heat can also denature proteins which is why fevers are so dangerous.
Protein Folding
Proteins folding incorrectly can lead to the loss of the function of the protein. This actually the main cause to several diseases such as Cystic Fibrosis, Alzheimer’s, Parkinson’s, and more.
Nucleic Acids
Nucleic acids store, transmit, and help express hereditary information. The amino acid sequence of a polypeptide is decided by a discrete unit called a gene. Genes consist of DNA which is a type of nucleic acid. Nucleic acids are polymers made up of monomers called nucleotides.
The Roles of Nucleic Acids
There are two types of nucleic acids. They are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). They enable organisms to reproduce their complex components and pass them down to future generations.
Unlike other molecules, DNA provides directions for its own replication. It also directs RNA replication and through RNA, controls RNA synthesis. This entire process is called gene expression.
DNA is the genetic material that organisms inherit from their parents. A chromosome is a package of DNA that plays a big role in mitosis when the nucleus splits. Each chromosome contains one long DNA molecule that usually carries several hundred genes. The information that programs all of the cell’s activities are encoded in the structure of its DNA. However, these actual functions are carried out by the proteins of the cell. So, the DNA codes the information to create those proteins that will carry out the functions of the cell.
RNA also has a very important role in gene expression. DNA directs the synthesis of RNA. mRNA or messenger RNA will direct the production of a polypeptide. Protein synthesis occurs on the ribosomes of a cell.
The Components of Nucleic Acids
Nucleic acids are macromolecules that exist as polymers called polynucleotides. Each polynucleotide is made up of monomers called nucleotides. A nucleotide consists of three parts: a 5-carbon sugar (pentose), a nitrogenous base, and one to three phosphate groups.
The third carbon of the pentose sugar has a hydroxyl group. The bond attaching the hydroxyl group to the third carbon is the phosphodiester linkage. Carbon number two is bonded to hydrogen in DNA, while the second carbon is attached to a hydroxyl group in RNA.
The actual monomer used to build a nucleotide has three phosphate groups, but two are lost in the polymerization process. The part of the nucleotide with no phosphate groups is called the nucleoside.
There are two groups of nitrogenous bases, pyrimidines and purines. The pyrimidines are smaller and contain one 6-carbon ring and nitrogen atoms. The members of the pyrimidine group are cytosine (C), thymine (T), and uracil (U). The purines are larger with a 6-carbon ring attached to a 5-carbon ring plus nitrogen atoms. The purines are adenine (A) and guanine (G). Pyrimidines and purines bond together with three hydrogen bonds.
Adenine, guanine, and cytosine are found in both DNA and RNA. However, thymine is only found in DNA and uracil is only found in RNA.
In DNA, the pentose sugar is deoxyribose and in RNA the pentose sugar is ribose. The only difference between the two is that deoxyribose lacks an oxygen on the second carbon of the ring.
Nucleotide Polymers
The linkages of nucleotides into a polynucleotide are by the process condensation reaction. Nucleotides are joined together by a phosphodiester linkage which consists of a phosphate group the covalently links the sugars of two nucleotides together. This bonding results in a repeating pattern of sugar-phosphate units. This is called a sugar-phosphate backbone. The nitrogenous bases are NOT a part of this backbone.
The two ends of the polymer are very different from each other. One end has a phosphate attached to a 5-carbon and the other end has a hydroxyl group attached to a 3-carbon. We refer to these as the 5’ end and the 3’ end. The polynucleotide is built directionally from the 5’ end to the 3’ end.
The sequence of bases along a polymer are unique for each gene and provides very specific information to the cell. The linear order of the bases specifies the order of the amino acids.
The Structure of DNA and RNA Molecules
A DNA molecule has two polynucleotides or strands that wind around forming a double axis. The two sugar-phosphate backbones run in opposite directions. This arrangement is referred to as antiparallel. The sugar-phosphate backbone is on the outside of each polynucleotide and the nitrogenous bases for each strand pair up on the inside. The bases are paired by hydrogen bonds.
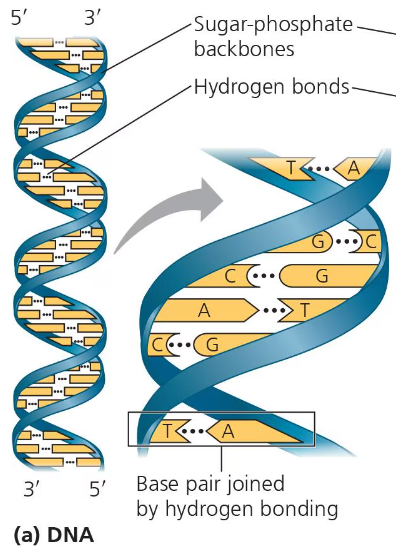
Only specific bases are paired with each other. One pyrimidine will bond with one purine. Adenine always pairs with thymine and guanine always pairs with cytosine. The two strands are complementary of each other. So, if you know the sequence of one strand, you can find the sequence of the other strand. For example, if one strand is 5’-AGTCAATCGCA-3’, then the other strand will be 3’-TCAGTTAGCGT-5’.
Unlike DNA, RNA molecules only have one strand. In RNA, adenine pairs with uracil, not thymine.
Genomics and Proteomics
Experimental work in the first half of the 20th century established DNA as the carrier of genetic material. DNA sequencing is the process of determining the sequence of nucleotides in a DNA strand. The first chemical techniques of processing DNA sequencing started in the 1970s. Since all cells of a living organism have the exact same DNA, scientists soon began to wonder how gene expression is regulated. The Human Genome Project was started to sequence the entire human genome.
Bioinformatics is the use of computer software and other computational tools that can handle and analyze these large data sets.
Biologists often look at problems by analyzing large sets of genes or even comparing entire genomes of different species, an approach called genomics. A similar analysis of large sets of proteins including their sequences is called proteomics. Genomics and proteomics can help us learn more about evolution.