ch17 ; gene expression: from gene to protein
Overview: The Flow of Genetic Information
The information content of DNA is in the form of specific sequences of nucleotides
The DNA inherited by an organism leads to specific traits by dictating the synthesis of proteins. Proteins are the links between genotype and phenotype.
Gene expression, the process by which DNA directs protein synthesis, includes two stages: transcription and translation
One gene— one protein or one gene— one polypeptide hypothesis.
Basic Principles of Transcription and Translation
RNA is the bridge between genes and the proteins for which they code.
Transcription is the synthesis of RNA using information in DNA. Transcription produces messenger RNA (mRNA). (DNA to RNA)
Translation is the synthesis of a polypeptide, using information in the mRNA. Ribosomes are sites of translation. (RNA to Protein)
A primary transcript is the initial RNA transcript from any gene prior to processing.
The central dogma is the concept that cells are governed by a cellular chain of command: DNA —> RNA —> Protein.
In prokaryotes, translation of mRNA can begin before transcription has finished. It happens more simultaneously.
In eukaryotic cell, the nuclear envelope separates transcription from translation.
Codons: Triplets of Nucleotides
The flow of information from gene to protein is based on a triplet code: a series of nonoverlapping, three-nucleotide words.
The words of a gene are transcribed into complementary nonoverlapping three-nucleotide word of mRNA.
These words are then translated into a chain of amino acids, forming a polypeptide.
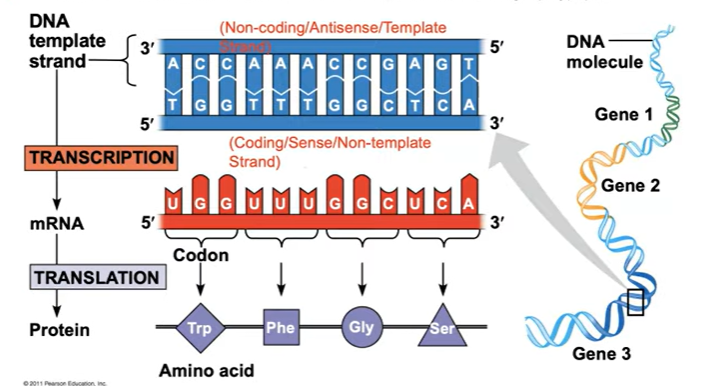 From the DNA, one of the strands is the template strand (aka non-coding/antisense)
From the DNA, one of the strands is the template strand (aka non-coding/antisense)
the other strand is called the non-template strand (aka coding/sense/non-template)
The template strand is what is read to make the mRNA, and is complementary. The mRNA is similar in terms to the non-coding strand once it is made since it uses complementary base pairing too.
mRNA has A-U, G-C pairings.
DNA is read from 3’ to 5’, but built 5’ to 3’. As you read the 3’ end of the template strand, you create the 5’ end on the mRNA.
Each triplet code is a codon.
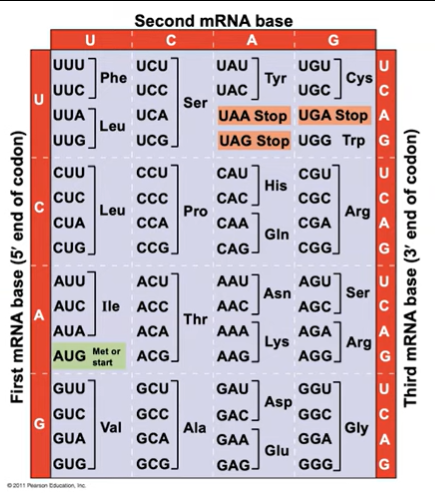 The Genetic Code
The Genetic Code
There are 64 codons. Of the 64 triplets, 61 code for amino acids; 3 triplets are “stop” signals to end translation.
The genetic code is redundant (more than one codon may specify a particular amino acid) but not ambiguous; no codon specifies more than one amino acid.
This gives leeway for mutations in DNA— even though the DNA is mutated and causes a different codon in the mRNA, it still has a chance to code for the intended amino acid. This case would be silent mutation.
Start codons gives signals to ribosomes on when to start making proteins; each polypeptide has a start codon at its beginning (AUG which codes for methianine).
mutations on the start signal would halt protein synthesis
Stop codons (3 stop signals).
Transcription is the DNA-directed synthesis of RNA
Transcription is the first stage of gene expression.
RNA synthesis is catalyzed by RNA polymerase.
The RNA is complementary to the DNA template strand.
RNA synthesis follows the same base-pairing rules as DNA, except that uracil substitutes for thymine.
The DNA sequencer where RNA polymerase attaches is called the promoter.
The stretch of DNA that is transcribed is called a transcription unit.
Three stages of transcription:
Initiation
Elongation
Termination
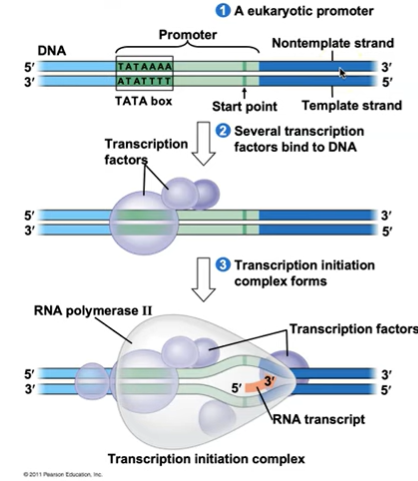
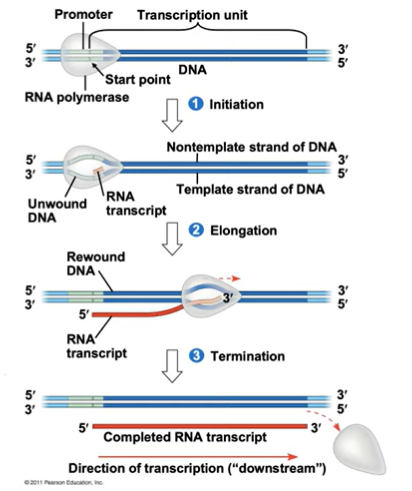 Each strand has a region called the promoter, usually in front of each gene. It signals where to begin transcription.
Each strand has a region called the promoter, usually in front of each gene. It signals where to begin transcription.
The transcription unit is the part of the DNA that is going to be read as the template.
Promoters signal the transcriptional start point and usually extend several dozen nucleotide pairs upstream of the start point.
A promoter called a TATA box is crucial in forming the initiation complex in eukaryotes. (usually filled with TATAAAA)
Transcription factors mediate the binding of RNA polymerase and the initiation of transcription.
They create a scaffold for the main enzyme to bind onto (RNA polymerase II)
The complete assembly of transcription factors and RNA polymerase II bound to a promoter is called a transcription initiation complex.
ELONGATION
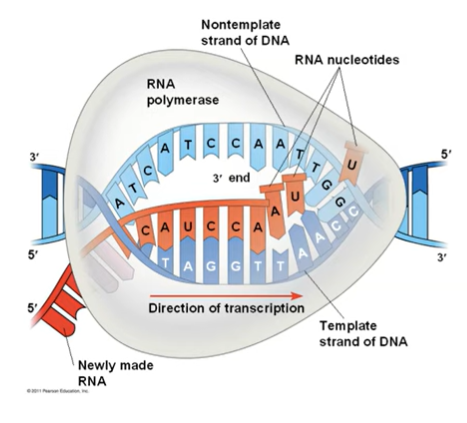 As RNA polymerase moves along the DNA, it untwists the double helix, 10 to 20 bases at a time.
As RNA polymerase moves along the DNA, it untwists the double helix, 10 to 20 bases at a time.
Transcription progresses at a rate of 40 nucleotides per second in eukaryotes (slightly slower than DNA replication).
A gene can be transcribed simultaneously by several RNA polymerase.
Nucleotides are added to the 3’ end of the growing RNA molecule. We build 5’ to 3’, so the 3’ end is always having more added to it. The direction of transcription would be 3’ to 5’ of the template strand (opposite of the RNA).
TERMINATION
In bacteria: the polymerase stops transcription at the end of the terminator and the mRNA can be translated without further modification.
In eukaryotes: RNA polymerase II transcribes the polyadenylation signal sequence; the RNA transcript is released 10-35 nucleotides past this polyadenylation sequence. It needs to be modified a bit more before it can be translated.
polyadenylation: many adenosine nucleic acids in a row.
Alteration of mRNA Ends: RNA Processing

Each end of a pre-mRNA molecule is modified in a particular way (occuring in the nucleus)
The 5’ end receives a modified nucleotide 5’ cap
made of guanosine.
The 3’ end gets a poly-A tail
made of adenosine nucleotides (not polyadenylation)
These modifications share several functions:
They seem to facilitate the export of mRNA to the cytoplasm
They protect mRNA from hydrolytic enzymes.
enzymes that would splice it/cut it.
They help ribosomes attach to the 5’ end.
The UTR (untranslated region)’s are untranslated regions where that part of the transcript won’t become a protein. Exist at 5’ and 3’.
Split Genes and RNA Splicing
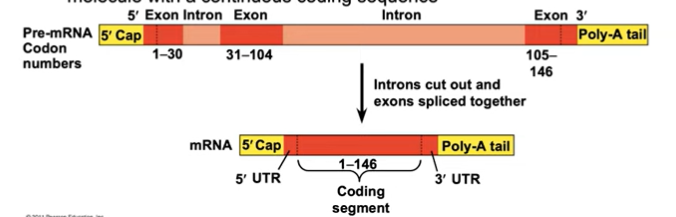
Most eukaryotic genes and their RNA transcripts have long noncoding stretches of nucleotides that lie between coding regions.
These noncoding regions are called intervening sequences, or introns.
don’t make proteins. so these parts must be removed.
introns —> interrupt >:[
The other regions are called exons because they are eventually expressed, usually translated into amino acid sequences.
exons are exciting :D
RNA splicing removes introns and joins exons, creating an mRNA molecule with a continuous coding sequence.
Once it’s sliced, it goes from pre-mRNA to mRNA! Hurray! It can now exit the nucleus.
Translation is the RNA-directed synthesis of a polypeptide
Genetic information flows from mRNA to protein through the process of translation.
A cell translates an mRNA message into a protein with the help of a transfer RNA (tRNA). tRNAs transfer amino acids to the growing polypeptide in a ribosomes.
Structure and Function of Transfer RNA
Molecules of tRNA are not identical
Each carries a specific amino acid on one end (depending on it’s anticodon!)
Each has an anticodon on the other end; an anticodon base-pairs with a complementary codon on mRNA.
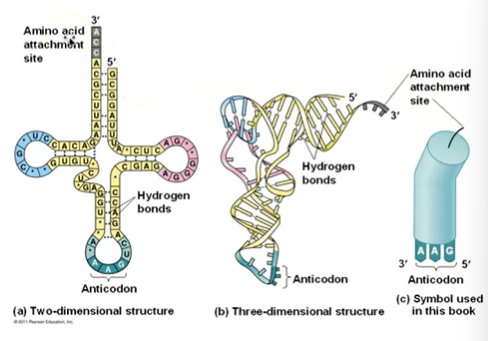 The 3’ end (with the hydroxyl group) is where the amino acids attach!
The 3’ end (with the hydroxyl group) is where the amino acids attach!
A tRNA molecule consists of a single RNA strand that is only about 80 nucleotides long.
Flattened into one plane to reveal its base pairing, a tRNA molecule looks like a cloverlead.
Flexible pairing at the third base of a codon is called wobble and allows some tRNAs to bind to more than one codon.
There is an ideal codon, but it might be able to bind to slightly different codons, very often which code for the same amino acid.
RIBOSOMES Ribomes facilitate specific coupling of tRNA anticodons with mRNA codons in protein synthesis. The two ribosomal subunits (large and small) are made of proteins and ribosomal RNA (rRNA). On top of the larger subunit, there are 3 binding sites.
Ribomes facilitate specific coupling of tRNA anticodons with mRNA codons in protein synthesis. The two ribosomal subunits (large and small) are made of proteins and ribosomal RNA (rRNA). On top of the larger subunit, there are 3 binding sites.
The P site holds the tRNA that carries the growing polypeptide chain
Peptidyl-tRNA binding site
The A site holds the tRNA that carries the next amino acid to be added to the chain
Aminoacyl-tRNA binding site
The E site is the exit site, where discharged tRNAs leave the ribosome.
Exit site.
The 5’ end of the mRNA goes in first, from A to P to E (Ape haha ooh oh ah ah)
Building a Polypeptide
Three stages:
Initiation
Elongation
Termination
All three stages require protein “factors” that aid in the translation process.
Ribosome Association and Initiation of Translation
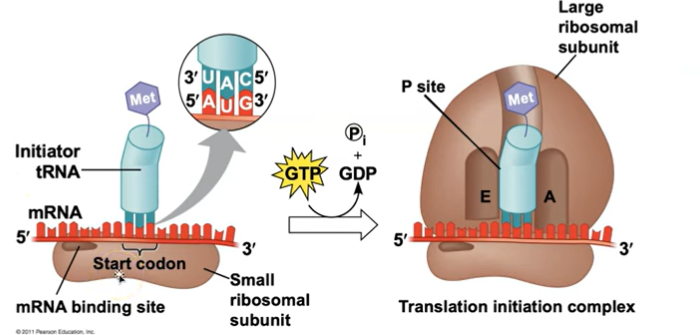
The initiation stage of translation brings together mRNA, a tRNA with the first amino acid, and the two ribosomal subunits.
A small ribosomal subunit binds with mRNA and a special inhibitor tRNA
goes through 5’ side first (the cap side)
The small subunit moves along the mRNA until it reaches the start codon
start codon: AUG, codes for Methionine.
Proteins called initiation factors bring in the large subunit that completes the translation initiation complex (uses GTP). The tRNA is in the P site!!
Elongation of the Polypeptide Chain
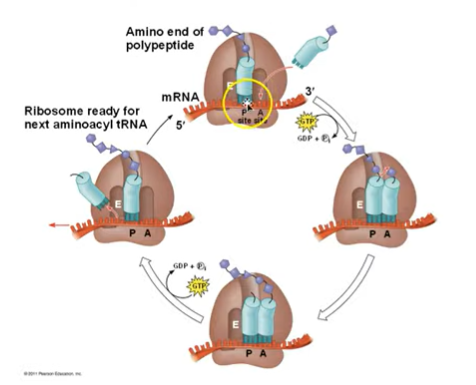
During the elongation stage, amino acids are added one by one to the proceeding amino acid at the C-terminus of the growing chain.
The A site carries a new codon that will be read by a tRNA carrying the anticodon! It will bind, and then the tRNA will carry the proper amino acid. The tRNA in the P site has the polypeptide chain we’re building. The tRNA in the P site passes the chain to the tRNA in the A site. The tRNA no longer has amino acids associated, so the ribosome clicks over, and the E site gets filled by tRNA that was in the P site, and the tRNA in the A site moves over to the P site. The empty tRNA in the E site exists, and then the ribosome is ready for the next tRNA to enter the A site. This happens until the mRNA is done coding.
Each addition involves proteins called elongation factors and occurs in three steps:
Codon recognition
Peptide bond formation
Translocation
Translation proceeds along the mRNA in a 5’ to 3’ direction.
Termination of Translation
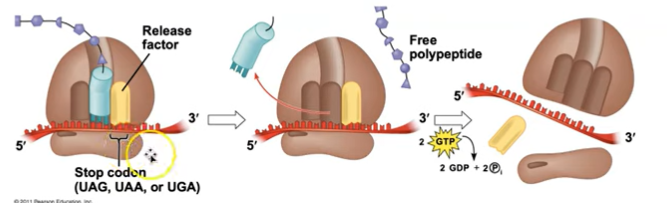
Termination occurs when a stop codon in the mRNA reaches the A site of the ribosome.
The A site accepts a protein called a release factor. The release factor causes the addition of a water molecule instead of an amino acid. This reaction releases the polypeptide, and the translation assembly then comes apart.
Proteins spontaneously coils and folds into its three dimensional shape. The protein may also require post-translational modifications before doing their job.
Transcription | Translation | |
|---|---|---|
Initiation | prepping DNA for mRNA
| |
Elongation | ||
Termination |
|
Polyribosomes
A number of ribosomes can translate a single mRNA simultaneously, forming a polyribosome (or polysome). Polyribosomes enable a cell to make many copies of a polypeptide very quickly.
they jump on at the 5’ end and move down.
the first ribosome is the one furthest from the 5’ end (since it moved forward till it got to the 3’ end).
Targeting Polypeptides to Specific Locations
Two populations of ribosomes are evident in cells: free ribosomes (in the cytosol) and bound ribosome (attached to the rough ER)
Free ribosomes mostly synthesize proteins that function in the cytosol.
Bound ribosomes make proteins of the endomembrane system and proteins that are secreted from the cell.
proteins that will be sent out of the cell.
Ribosomes are identical and can switch from free to bound.
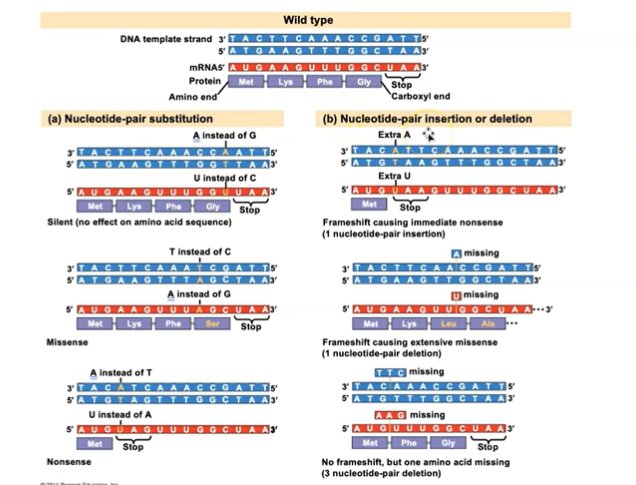
Mutations of one or a few nucleotides can affect protein structure and function
Mutations are changes in the genetic material of a cell. It results from:
Spontaneous mutations can occur during DNA replication, recombination, or repair.
Mutagens are physical or chemical agents that can cause mutations
Point mutations are chemical changes in just one base pair of a gene.
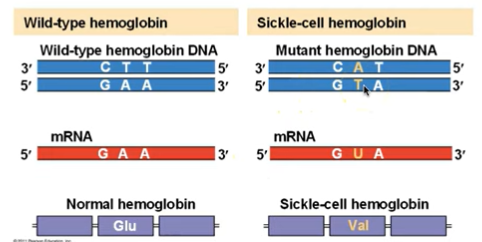
The change of a single nucleotide in a RNA template strand can lead to the production of an abnormal protein.
A nucleotide-pair substitution replaces one nucleotide and its partner with another pair of nucleotides (sickle cell hemoglobin)
Silent mutations have no effect on the amino acid produced by a codon because of redundancy in the genetic code
Missense mutations still code for an amino acid, but not the correct amino acid.
Nonsense mutations change an amino acid codon into a stop codon, nearly always leading to a nonfunctional protein.
Insertions and deletions are additions or losses of nucleotide pairs in a gene.
These mutations have a disastrous effect on the resulting protein more often than substitutions do. Insertion or deletion of nucleotides may alter the reading frame, producing a frameshift mutation.