
Cs280 stuff
Chapter 2
Zuse’s Plankalkül - Designed in 1945 but not published until 1972. It featured advanced data structures, floating-point arrays, records, and invariants.
Fortran - Developed in the 1950s, Fortran (Formula Translation) was designed for scientific computing and is notable for its use of compiled programming languages.
LISP - Developed in the late 1950s at MIT by John McCarthy, LISP (LISt Processing) is a functional programming language aimed at artificial intelligence research, using lists as its primary data structure.
COBOL - Developed in the 1960s for business data processing. It stands for Common Business Oriented Language and was designed to be readable by non-programmers.
BASIC - Developed in the 1960s for beginners, BASIC (Beginner's All-purpose Symbolic Instruction Code) was designed to be easy to use for non-science students.
PL/I - Created by IBM in the 1960s to combine features from scientific and business programming languages. PL/I stands for Programming Language One and was the first to include unit-level concurrency, exception handling, and recursion.
Prolog - A logic programming language developed in the 1970s, primarily used in artificial intelligence and computational linguistics. It allows for the expression of logic in a form of rules and facts.
Ada - A programming language developed in the 1970s by the US Department of Defense. Named after Ada Lovelace, it supports object-oriented, concurrent, and systems programming
Short Code - Developed by Mauchly in 1949 for BINAC computers, Short Code used left-to-right expression coding and was an early form of pseudocode.
Speedcoding - Developed by Backus in 1954 for the IBM 701, it featured pseudo operations for arithmetic, math functions, and conditional branching. It was slow due to limited memory for user programs.
ALGOL 60 - A refined version of ALGOL 58, it introduced block structure, two parameter passing methods, subprogram recursion, and stack-dynamic arrays. It became the standard for publishing algorithms and influenced many subsequent languages .
ALGOL 68 - An orthogonal design language that was more complex than ALGOL 60. It featured user-defined data types, flexible arrays, and a strong type system, but was less successful due to its complexity.
Pascal - Developed by Niklaus Wirth in the late 1960s, Pascal was designed for teaching programming and structured programming. It featured strong typing, extensive error checking, and was used widely in academia.
C - Developed in the early 1970s at Bell Labs by Dennis Ritchie, C is a general-purpose programming language that provides low-level access to memory. It has influenced many other languages and remains widely used today.
Smalltalk - Developed in the 1970s, Smalltalk is an object-oriented programming language that introduced the concept of classes and message passing. It significantly influenced the development of later OOP languages.
C++ - An extension of C developed by Bjarne Stroustrup in the early 1980s. C++ added object-oriented features to C, making it suitable for large-scale software development. It supports both low-level and high-level programming
Chapter 3
Syntax - The form or structure of the expressions, statements, and program units.
Semantics - The meaning of the expressions, statements, and program units.
Sentence - A string of characters over some alphabet.
Language - A set of sentences.
Lexeme - A lexeme is the smallest unit of meaning in a programming language, such as a keyword, operator, identifier, or literal. It represents a single element in the source code, like if, +, or 42.
Token - A token is a category or class of lexemes. For example, in the statement int x = 10;, int is a keyword token, x is an identifier token, = is an operator token, and 10 is a literal token. Tokens are the building blocks used by a lexical analyzer to interpret code.
Recognizer - A recognizer is a tool or component of a compiler that reads input strings of a programming language and determines whether they belong to the language. It validates syntax by checking if the input conforms to the language's grammar rules.
Generator - A generator is a tool or system that produces sentences of a language. It can be used to create valid program structures based on a set of grammar rules. This helps in understanding the syntax by generating examples of valid code.
Context-Free Grammar (CFG)
Definition: A type of formal grammar where each production rule maps a single nonterminal to a string of nonterminal and/or terminal symbols.
Characteristics: Can generate languages that include nested structures, such as parentheses in expressions.
Example: S → aSb | ε
Regular Grammar
Definition: A formal grammar where production rules are restricted to a single nonterminal on the left-hand side and a string of at most one terminal followed by at most one nonterminal on the right-hand side.
Characteristics: Suitable for defining regular languages, which do not include nested structures.
Example: A → aA | b
Difference Between CFG and Regular Grammar
Complexity: CFGs can generate more complex languages with nested structures; regular grammars cannot.
Automata: CFGs use pushdown automata; regular grammars use finite state automata.
Pushdown Automaton (PDA)
Definition: A type of automaton that includes a stack, which provides additional memory beyond the finite control.
Characteristics: Can recognize context-free languages by handling nested structures using the stack.
Example Use: Parsing nested parentheses or matching tags in HTML.
Finite State Automaton (FSA)
Definition: A computational model with a finite number of states and transitions between those states based on input symbols.
Characteristics: Can recognize regular languages by processing symbols sequentially without additional memory.
Example Use: Simple pattern matching, such as finding specific substrings in text.
Regular Grammars and Finite State Automata
Relation: Regular grammars can be directly converted into finite state automata. Each production rule corresponds to transitions between states in the automaton.
Example: The regular grammar A → aA | b can be represented by an FSA that transitions between states on input a or b.
Context-Free Grammars and Pushdown Automata
Relation: Context-free grammars can be recognized by pushdown automata, where the stack is used to keep track of nonterminals and nested structures.
Example: The CFG rule S → aSb | ε can be processed by a PDA that pushes and pops symbols on/from the stack to match a and b pairs.
Backus-Naur Form (BNF) - BNF is a notation for expressing context-free grammars. It uses production rules to define the structure of syntactic elements in a language. Each rule specifies how a nonterminal symbol can be expanded into a sequence of terminal and/or nonterminal symbols.
Nonterminal Symbols - Nonterminal symbols are placeholders or abstractions used in grammar rules to represent sets of possible sequences of symbols. They are eventually replaced by terminal symbols through a series of rule applications to form valid sentences.
Terminals - Terminal symbols are the basic, indivisible symbols of a language (such as keywords, operators, and punctuation) that appear in the final form of a sentence. They are the actual characters or tokens used in the source code.
Rule in BNF - A BNF rule consists of a left-hand side (LHS) which is a nonterminal symbol and a right-hand side (RHS) which is a sequence of terminal and/or nonterminal symbols. The rule describes how the LHS can be replaced by the RHS in the generation of sentences.
Grammar - A grammar is a collection of rules that define the syntax of a language. It includes a finite set of production rules, a start symbol, and terminal and nonterminal symbols. The grammar specifies how sentences in the language can be constructed.
Start Symbol - The start symbol is a special nonterminal in a grammar from which the derivation of sentences begins. It represents the most general form of a sentence in the language and is expanded through the application of grammar rules.
Derivation - A derivation is the process of applying grammar rules to the start symbol to produce a sentence. Each step in the derivation replaces a nonterminal symbol with the sequence specified by a rule, progressively transforming the start symbol into a complete sentence. A derivation can be left most, right most, or neither.
Sentential Form - Any intermediate string of symbols in the process of a derivation is called a sentential form. It can include both terminal and nonterminal symbols and represents a step between the start symbol and the final sentence.
Sentence (in grammar) - In the context of grammar, a sentence is a sentential form composed entirely of terminal symbols. It is the final result of a derivation process, representing a valid sequence of symbols in the language.
Leftmost Derivation - A leftmost derivation is a specific type of derivation where the leftmost nonterminal in each sentential form is always the one expanded first. This approach ensures a consistent order in the application of rules.
Parse Tree - A parse tree is a tree representation of the syntactic structure of a sentence according to a grammar. The root of the tree is the start symbol, and each internal node represents a nonterminal symbol that expands into its children, which are either terminal or nonterminal symbols.
Ambiguous Grammar - A grammar is ambiguous if there exists at least one sentence that can be generated by more than one distinct parse tree. Ambiguity in a grammar can lead to confusion in interpreting the structure and meaning of sentences.
Extended BNF (EBNF) - EBNF is an enhancement of BNF that introduces additional notation to simplify the expression of grammar rules. It includes symbols for optional elements, repetitions, and choices, making it easier to write and understand complex grammars.
Static Semantics - Static semantics defines rules that go beyond the syntactic structure to include context-sensitive aspects, such as type checking and variable declarations. These rules ensure that programs are not only syntactically correct but also make sense within the language's context.
Attribute Grammars - Attribute grammars extend context-free grammars by associating attributes with grammar symbols. These attributes can hold values computed by functions and predicates, enabling the specification of semantic rules and checks within the grammar.
Operational Semantics - Operational semantics describes the meaning of a program by simulating its execution on a machine. It focuses on how the state of the machine changes with each operation, providing an intuitive understanding of the program's behavior.
Denotational Semantics - Denotational semantics uses mathematical functions to map syntactic constructs to their meanings. It provides a formal and abstract method for defining the semantics of programming languages, facilitating proofs of program correctness.
Axiomatic Semantics - Axiomatic semantics is based on formal logic and uses axioms or inference rules to define the behavior of programs. It is used for proving the correctness of programs by showing that certain conditions hold before and after the execution of statements.
Example grammar/ BNF rules -

Derivation example -

Example of Left most grammar
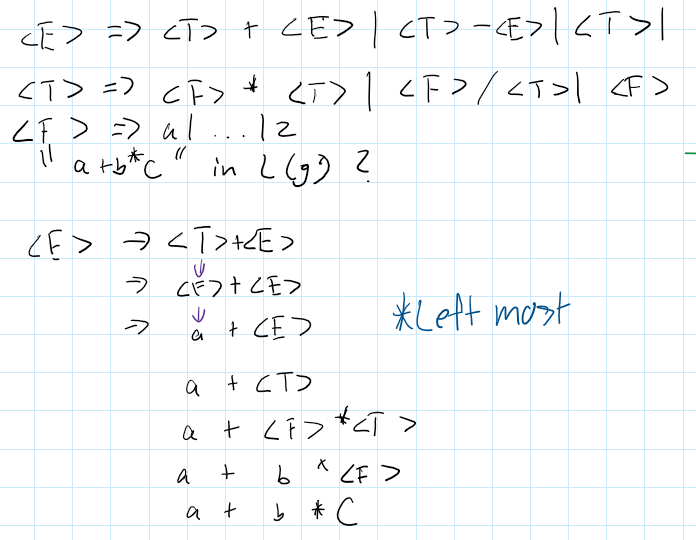
Example of Right Most derivation -
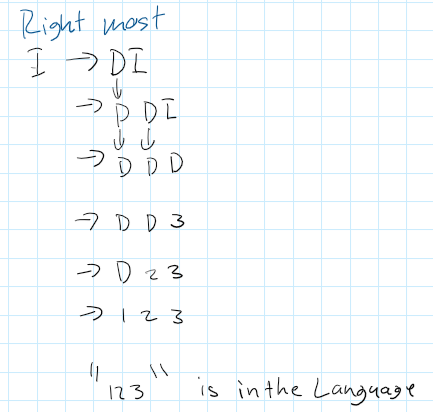
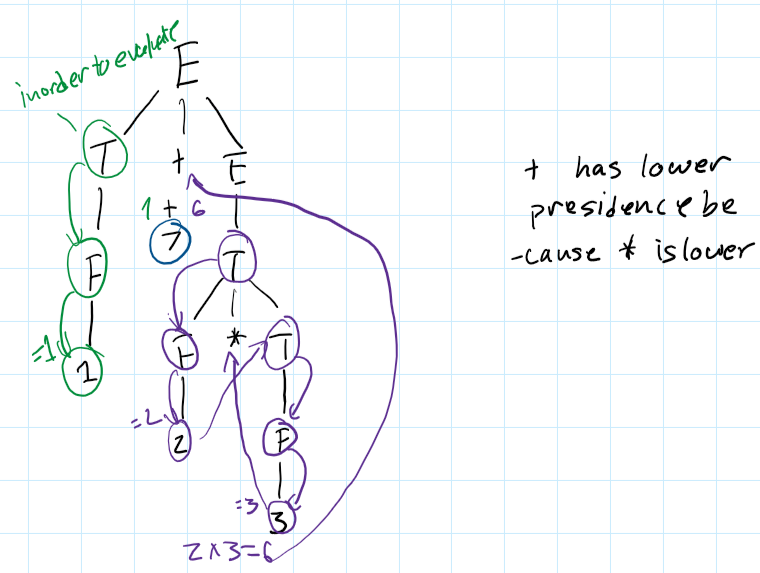
Parse Tree example:
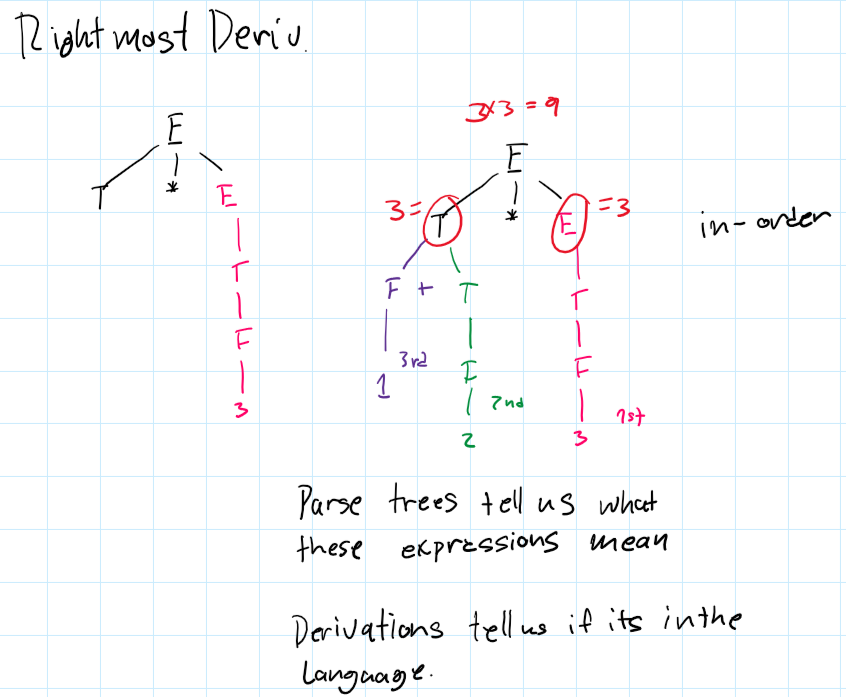
Right Most derivation parse trees
EBNF examples

Optional Parts []

Alternative parts (this or that) denoted by ()
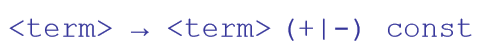
Other variations

Introduction to Syntax Analysis
Purpose: Syntax analysis, or parsing, checks the source code structure against the formal grammar of the programming language.
Implementation: Utilizes formal grammars like Backus-Naur Form (BNF) or Extended BNF (EBNF) to describe the syntax rules.
Lexical Analysis
Definition: The process of converting a sequence of characters into a sequence of tokens, which are meaningful sequences of characters identified as lexemes.
Function: Acts as the front-end of the parser, breaking down the input into manageable pieces (tokens).
Components:
Lexemes: The lowest level syntactic unit, like identifiers and keywords.
Tokens: Categories of lexemes, such as IDENT, NUMBER, KEYWORD.
Lexical Analyzer Construction
Methods:
Formal Description: Specify tokens using regular expressions and generate a lexical analyzer using tools like Lex.
State Diagram: Draw state diagrams for tokens and implement them programmatically.
Hand-constructed Table-driven Implementation: Design a table-driven lexical analyzer manually.
Reasons to Separate Lexical and Syntax Analysis
Simplicity: Simplifies the overall design by separating concerns. The lexical analyzer handles tokenization, while the syntax analyzer handles structure.
Efficiency: Optimizing the lexical analyzer can significantly improve performance as it processes the entire input.
Portability: Lexical analyzers are often platform-specific due to character encoding differences, while syntax analyzers are typically platform-independent.
Syntax Analysis
Definition: The process of analyzing strings of symbols to ensure they conform to the rules of a formal grammar.
Components:
Lexical Analyzer: Processes input into tokens.
Syntax Analyzer: Uses tokens to build a parse tree according to grammar rules.
Recursive-Descent Parsing
Definition: A top-down parsing technique where each nonterminal in the grammar has a corresponding recursive procedure.
Suitability: Works well with grammars written in EBNF.
Process: Each nonterminal symbol is parsed using a corresponding function that recursively calls other functions as necessary.
Bottom-Up Parsing
Definition: A parsing technique that builds the parse tree from the leaves (input tokens) up to the root (start symbol).
Handle: The substring matching the right-hand side of a production rule, which can be replaced by the left-hand side.
Common Algorithms: LR parsing algorithms like SLR, LALR, and canonical LR.
Finite State Automaton (FSA)
Definition: A computational model consisting of states, transitions, and an input alphabet, used to recognize regular languages.
Usage: Recognizes patterns within regular languages.
Relation to Regular Grammars: Regular grammars can be converted into FSAs, where each rule corresponds to a transition between states.
Pushdown Automaton (PDA)
Definition: A type of automaton that includes a stack to provide additional memory beyond the finite control.
Usage: Recognizes context-free languages by handling nested structures using the stack.
Relation to Context-Free Grammars: PDAs can recognize languages defined by context-free grammars, with the stack allowing for the necessary additional memory.
Regular Grammars and Finite State Automata
Relation: Regular grammars define rules that can be directly mapped to the states and transitions of a finite state automaton (FSA).
produce regular languages recognized by finite state Automata.
Example: The regular grammar rule A → aA | b corresponds to an FSA where transitions occur based on input symbols a and b.
Context-Free Grammars and Pushdown Automata
Relation: Context-free grammars can be recognized by pushdown automata (PDAs), which use a stack to manage nonterminal expansions and nested structures.
They produce Context free languages recognized by pushdown automata
Example: The CFG rule S → aSb | ε is processed by a PDA that pushes a onto the stack and pops it when encountering b.
Parsing Problem Goals
Goals:
Detect all syntax errors in the source code and provide meaningful error messages.
Construct the parse tree or produce a trace of the parsing process for valid input.
Top-Down Parsers
Types:
Recursive Descent: Hand-coded, uses recursive procedures for parsing.
LL Parsers: Table-driven, using a predictive parsing table.
Process: Start at the root and build the parse tree in a leftmost derivation order by expanding the nonterminals.
Bottom-Up Parsers
Types:
LR Parsers: Includes SLR, LALR, and canonical LR parsers.
Process: Begin with the input symbols (leaves) and construct the parse tree towards the start symbol (root), performing reductions based on grammar rules.
Efficiency: Operate in linear time for many practical context-free grammars.
Recursive-Descent Parsing Example
Grammar:
<expr> → <term> {(+ | -) <term>}
<term> → <factor> {(* | /) <factor>}
<factor> → id | int_constant | ( <expr> )
Implementation: Each production rule corresponds to a function that processes the input and calls other functions as needed to match the grammar structure.
State Diagram in Lexical Analysis
Simplification: Reduce complexity by combining transitions for similar tokens.
Character Classes: Use character classes (e.g., letters, digits) to simplify the state diagram and handle multiple characters in a single transition.
LR Parsing Table
Components:
ACTION Table: Specifies parsing actions (shift, reduce, accept, error) based on the current state and input token.
GOTO Table: Determines the next state after a reduction based on the nonterminal.
Automaton
Definition: A mathematical model for a machine with a finite number of states that processes sequences of symbols from an input alphabet.
Types:
Finite State Automaton (FSA): Processes regular languages using states and transitions.
Pushdown Automaton (PDA): Processes context-free languages using states, transitions, and a stack for additional memory.
Usage: Used in various applications including lexical analysis, parsing, and pattern recognition.
The Complexity of Parsing
- Parsers that work for any unambiguous
grammar are complex and inefficient ( O(n3),
where n is the length of the input )
- Compilers use parsers that only work for a
subset of all unambiguous grammars, but do it
in linear time ( O(n), where n is the length of the
input )
Chapter 5
Imperative Languages and von Neumann Architecture
Imperative Languages: Programming languages based on commands changing a program's state.
von Neumann Architecture: Basis for imperative languages; involves sequential execution and shared memory, reflecting the fetch-decode-execute cycle.
Variables are characterized by attributes
To design a type, must consider scope, lifetime, type checking, initialization, and type compatibility
Connotative vs. Non-Connotative Names in Programming
Connotative Meaning: Implied meaning beyond the literal.
Example: calculateSum()—clearly indicates its purpose.
Non-Connotative Meaning: Lacks descriptive clarity.
Example: x or func1()—ambiguous and unclear.
Importance:
Descriptive Names: Improve readability and maintainability.
Best Practice: Use meaningful names to convey intent and functionality.
Special Characters in Variable Naming
PHP: $ - All variable names must begin with dollar signs.
Perl: Special characters specify variable types.
Ruby: @ - Instance variables, @@ - Class variables.
Case sensitivity
Disadvantage: readability (names that look alike are different)
Names in the C-based languages are case sensitive
Names in others are not
Worse in C++, Java, and C# because predefined names are mixed case (e.g. IndexOutOfBoundsException)
Special words
Special words aid readability in programming.
They delimit or separate statement clauses.
Examples include keywords and reserved words.
Keywords
Keywords hold significance in specific contexts of a programming language.
They often denote data types or language constructs.
Examples: "Real" in Fortran, "int" in C++.
Reserved Words
Reserved words cannot be used as user-defined names.
They are reserved for language-specific purposes.
Excessive reserved words can lead to collisions and programming complexities.
Variables
A variable is an abstraction of a memory cell
Variables can be characterized as a sextuple of attributes:
Name
Address
Value
Type
Lifetime
Scope
Variable Attributes
Name - (self explanatory )not all variables have them
Address - the memory address with which it is associated
A variable may have different addresses at different times during execution and places throughout the program
If two variable names can be used to access the same memory location, they are called aliases
Aliases are created via pointers, reference variables, C and C++ unions
Aliases are harmful to readability (program readers must remember all of them
Type - determines the range of values of variables and the set of operations that are defined for values of that type; in the case of floating point, type also determines the precision
ex floats, ints, bools, etc
Value - the contents of the location with which the variable is associated
- The l-value of a variable is its address
the left side value of the = sign
- The r-value of a variable is its value
the right side value of the = sign
Explicit declaration
An explicit declaration is a program statement used for declaring the types of variables
implicit declaration
An implicit declaration is a default mechanism for specifying types of variables through default conventions, rather than declaration statements
Binding
A binding is an association between an entity and an attribute, such as between a variable and its type or value, or between an operation and a symbol
Static Binding:
A binding is static if it first occurs before run time and remains unchanged throughout program execution.
Dynamic Binding:
A binding is dynamic if it first occurs during execution or can change during execution of the program
Binding time - is the time at which a binding takes place.
Compile time -- bind a variable to a type in C or Java at the time at which the code compiles
Runtime -- bind a nonstatic local variable to a memory cell at the time at which the code runs
Scope
The scope of a variable is the range of statements over which it is visible
The local variables of a program unit are those that are declared in that unit
The nonlocal variables of a program unit are those that are visible in the unit but not declared there
Global variables are a special category of nonlocal variables
The scope rules of a language determine how references to names are associated with variables
Dynamic Scope
Based on calling sequences of program units, not their textual layout (temporal versus spatial) (basically more based on time something is called rather than where it is between the {})
References to variables are connected to declarations by searching back through the chain of subprogram calls that forced execution to this point
Static Scope
Definition:
- Static scope connects a name reference to a variable based on program text.
- It involves searching declarations locally and in enclosing scopes until finding one for the given name.
- Enclosing static scopes are termed static ancestors; the closest is the static parent.
- Languages like Ada, JavaScript, Common LISP, Scheme, Fortran 2003+, F#, and Python allow nested subprogram definitions, creating nested static scopes.
Named Constants
A named constant is a variable that is bound to a value only when it is bound to storage
Global Scope
Definition:
Global scope refers to the visibility of variables or identifiers throughout the entire program, making them accessible from any part of the codebase. Variables declared in the global scope are typically accessible from any function or block within the program.
Lifetime
The lifetime of a variable is the time during which it is bound to a particular memory cell
Difference between lifetime and scope
def foo():
x = 10
print(x)
foo()
Here, x has a lifetime starting from its declaration within the function foo() until the function exits. Within this lifetime, x is accessible and can be used. However, the scope of x is limited to the function foo(). Attempting to access x outside of foo() will result in an error, indicating that x is not defined in that scope.
def foo():
x = 10
print(x)
foo()
print(x) # Error: NameError: name 'x' is not defined
In this example, the lifetime of x is tied to the execution of foo() while its scope is confined to the function foo().
Differences between Dynamic and Static Scoping
Static Scoping:
pythonx = 10
def foo():
print(x)
def bar():
x = 20
foo()
bar() # Output: 10
In static scoping, foo() uses the x defined globally (10), as the scope is determined at compile-time.
Dynamic Scoping:
pythonx = 10
def foo():
print(x)
def bar():
global x
x = 20
foo()
bar() # Output: 20
In dynamic scoping, foo() uses the x defined in bar() (20), as the scope is determined at runtime. (Note: Python doesn't natively support dynamic scoping; this is a conceptual example.)
Compile Time:
The period when the source code is translated into executable code by a compiler.
Syntax and type checking are performed.
Errors detected during this phase are called compile-time errors.
Examples include syntax errors, type mismatches, and undeclared variables.
Runtime:
The period when the program is executing after being successfully compiled.
The program performs its tasks using CPU and memory resources.
Errors detected during this phase are called runtime errors.
Examples include division by zero, null pointer dereferences, and array out-of-bounds access.
Referencing environment
A referencing environment of a statement is the collection of all variable bindings that are accessible to that statement. It determines which variables can be used and what their current values are.
The referencing environment of a statement is the
collection of all names that are visible in the
statement
Chapter 6 - Data types
Data type
A data type defines a collection of data objects and a set of predefined operations on those objects
A descriptor is the collection of the attributes of a variable
An object represents an instance of a user-defined (abstract data) type
Primitive Data Types
Primitive data types: Those not defined in terms of other data types
integer
Almost always an exact reflection of the hardware so the mapping is trivial
Java’s signed integer sizes: byte, short, int, long
Floating point etc
Languages for scientific use support at least two floating-point types (e.g., float and double; sometimes more
Complex (contain real float and imaginary float)
Decimal
used in COBOL (business code bs)
acccurate but limited range
Boolean true or false
Character
commonly used ASCII
includes characters from most natural languages
originally used in java
Character String Types
Values are sequences of characters
Operations
Typical operations:
Assignment and copying
Comparison (=, >, etc.)
Catenation
Substring reference
Pattern matching
In languages certain
C & c++ - not primitive
SNOBOL4 primitive
Java - primitive via String class
Length
Limited Dynamic Length (c,c++)
In these languages, a special character is used to indicate the end of a string’s characters, rather than maintaining the length (null space)
Dynamic (no maximum): SNOBOL4, Perl, JavaScript
In java strings are mutable and also has string buffers which u can append shit to
Compile- and Run-Time Descriptors

User-Defined Ordinal Types
An ordinal type is one in which the range of possible values can be easily associated with the set of positive integers
Examples of primitive ordinal types in Java
int
char
boolean
Enumerations, or enums, are a data type that consists of a set of named values called elements or members. Enums are used to define variables that can hold only one of the predefined values, improving code readability and reducing errors.
Example:
javapublic enum Day {
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
}
public class Example {
public static void main(String[] args) {
Day today = Day.MONDAY;
System.out.println("Today is: " + today);
}
}
In this example, Day is an enumeration with the days of the week as its members. The variable today is assigned the value Day.MONDAY.
An ordered contiguous subsequence of an ordinal type
Example: 12 …18 is a subrange of integer type
Array Types
An array is a homogeneous aggregate of data elements in which an individual element is identified by its position in the aggregate, relative to the first element.
Indexing
Indexing (or subscripting) is a mapping from indices to elements
Array Initialization
Some language allow initialization at the time of storage allocation
C, C++, Java, C# example
int list [] = {4, 5, 7, 83}
Character strings in C and C++
char name [] = ″freddie″;
Arrays of strings in C and C++
char *names [] = {″Bob″, ″Jake″, ″Joe″];
Java initialization of String objects
String[] names = {″Bob″, ″Jake″, ″Joe″};
A heterogeneous array is one in which the elements need not be of the same type
# Example in Python
heterogeneous_array = [1, "Hello", 3.14, True]
A rectangular array is a multi-dimensioned array in which all of the rows have the same number of elements and all columns have the same number of elements
A jagged matrix/array has rows with varying number of elements
Possible when multi-dimensioned arrays actually appear as arrays of arrays
Associative Arrays
An associative array is an unordered collection of data elements that are indexed by an equal number of values called keys
Record Types
A record is a possibly heterogeneous aggregate of data elements in which the individual elements are identified by names
A record is a data structure that groups together related data of various types using named fields. It is commonly used in languages like Pascal, Ada, and modern languages such as C++ (using structs) and Rust.
#include <stdio.h>
struct Person {
char name[50];
int age;
float height;
};
int main() {
struct Person person1;
// Assigning values to fields
strcpy(person1.name, "Alice");
person1.age = 30;
person1.height = 5.5;
// Accessing fields
printf("Name: %s\n", person1.name);
printf("Age: %d\n", person1.age);
printf("Height: %.1f\n", person1.height);
return 0;
}
Tuple Types
A tuple is a data type that is similar to a record, except that the elements are not named
# Creating a tuple
person = ("Alice", 30, 5.5)
# Accessing elements by position
name = person[0]
age = person[1]
height = person[2]
print(f"Name: {name}")
print(f"Age: {age}")
print(f"Height: {height}")
List Types
different languages do different things
Lists in LISP and Scheme are delimited by parentheses and use no commas
(A B C D) and (A (B C) D)
Union Types
A union is a type whose variables are allowed to store different type values at different times during execution
Fortran, C, and C++ provide union constructs in which there is no language support for type checking; the union in these languages is called free union
Type checking of unions require that each union include a type indicator called a discriminant
Supported by Ada
Pointer and Reference Types
A pointer type variable has a range of values that consists of memory addresses and a special value, nil
Provide the power of indirect addressing
Provide a way to manage dynamic memory
A pointer can be used to access a location in the area where storage is dynamically created (usually called a heap)
Pointer operations
Two fundamental operations: assignment and dereferencing
Assignment is used to set a pointer variable’s value to some useful address
Dereferencing yields the value stored at the location represented by the pointer’s value
Dereferencing can be explicit or implicit
C++ uses an explicit operation via *
j = *ptr
sets j to the value located at ptr
Problems with pointers
Dangling pointers (dangerous)
A pointer points to a heap-dynamic variable that has been deallocated
Widows
Int *p = malloc(1000)
Int *q = p;
Free (p);
q is not freed so it’s a widow
In c and c++ pointers are S-tier pieces of shits u can do anything with em
Domain type need not be fixed (void *)
void * can point to any type and can be type checked (cannot be de-referenced)
In C++, the & symbol has two primary meanings:
Reference Operator: When used in variable declarations, it denotes a reference type.
Address-of Operator: When used in expressions, it retrieves the memory address of a variable.
Pointers and References
In C and C++, the asterisk (*) symbol is primarily used for two purposes:
Declaration of Pointers: Denotes a pointer type in variable declarations.
cppint *ptr; // 'ptr' is a pointer to an integer.
Dereferencing Operator: Accesses the value pointed to by a pointer.
cppint x = 10;
int *ptr = x; // 'ptr' points to 'x'
int value = *ptr; // 'value' is assigned the value of 'x'.
These are the main uses of the asterisk in C and C++ code.
Orphans
void createOrphan() {
int *ptr = new int; // Dynamically allocate memory
// ptr goes out of scope without deallocating memory
}
int main() {
createOrphan(); // Memory allocated in createOrphan becomes orphaned
// The dynamically allocated memory is now inaccessible and can't be deallocated
return 0;
}
Type Checking
Type checking is the activity of ensuring that the operands of an operator are of compatible types
A compatible type is one that is either legal for the operator, or is allowed under language rules to be implicitly converted, by compiler- generated code, to a legal type
This automatic conversion is called a coercion.
Strong Typing
A programming language is strongly typed if type errors are always detected
Advantage of strong typing: allows the detection of the misuses of variables that result in type errors
Ada really strongly typed
Java strongly typed
c++ kinda strongly typed
C not really strongly typed
Type Equivalence
Name type equivalence means the two variables have equivalent types if they are in either the same declaration or in declarations that use the same type name
Structure type equivalence means that two variables have equivalent types if their types have identical structures
Chapter 7
Arithmetic Expressions
Arithmetic evaluation was one of the motivations for the development of the first programming languages
Arithmetic expressions consist of operators, operands, parentheses, and function calls
A unary operator has one operand
A binary operator has two operands
A ternary operator has three operands
The operator precedence rules for expression evaluation define the order in which “adjacent” operators of different precedence levels are evaluated (think pemdas)
Typical precedence levels
parentheses
unary operators
** (if the language supports it)
*, /
+, -
The operator associativity rules for expression evaluation define the order in which adjacent operators with the same precedence level are evaluated. Think left to right if you have two addition in your function.
Conditional expressions (ternary conditional operator)
average = (count == 0)? 0 : sum / count
if true average gets set to sum to 0 if not sum/count
Functional side effects: when a function changes a two-way parameter or a non-local variablea = 10;
/* assume that fun changes its parameter */
b = a + fun(&a);
Overloaded Operators
Use of an operator for more than one purpose is called operator overloading
ex using + to add floats and ints
Type Conversions
A narrowing conversion is one that converts an object to a type that cannot include all of the values of the original type e.g., float to int
A widening conversion is one in which an object is converted to a type that can include at least approximations to all of the values of the original type e.g., int to float
A mixed-mode expression is one that has operands of different types
A coercion is an implicit type conversion
Disadvantage of coercions:
They decrease in the type error detection ability of the compiler
EX:#include <iostream>
int main() {
int intVar = 10;
double doubleVar = 5.5;
double result = intVar + doubleVar; //intVar is automatically converted to double
std::cout << "Result: " << result << std::endl; // Output: 15.5
return 0;
}
Called casting in C-based languages
Examples
C: (int)angle
F#: float(sum)
Errors in Expressions
Causes
Inherent limitations of arithmetic e.g., division by zero
Limitations of computer arithmetic e.g. overflow
Often ignored by the run-time system
Relational and Boolean Expressions
Relational Expressions
Use relational operators and operands of various types
Evaluate to some Boolean representation
Operator symbols used vary somewhat among languages (!=, /=, ~=, .NE., <>, #)
Boolean Expressions
Operands are Boolean and the result is Boolean
Example: (13 * a) * (b / 13 – 1)
If a is zero, there is no need to evaluate (b /13 - 1)
Short-Circuit Evaluation
An expression in which the result is determined without evaluating all of the operands and/or operators
C, C++, and Java: use short-circuit evaluation for the usual Boolean operators (&& and ||), but also provide bitwise Boolean operators that are not short circuit (& and |)
Assignment Statements
The general syntax
<target_var> <assign_operator> <expression>
in this example <assign_operator> can be
The assignment operator
= Fortran, BASIC, the C-based languages
:= Ada
= can be bad when it is overloaded for the relational operator for equality (that’s why the C-based languages use == as the relational operator)
Compound Assignment Operators
A shorthand method of specifying a commonly needed form of assignment
Example
a = a + b
can be written as
a += b
Unary assignment operators in C-based languages combine increment and decrement operations with assignment
sum = ++count (count incremented, then assigned to sum)
sum = count++ (count assigned to sum, then incremented
count++ (count incremented)
-count++ (count incremented then negated)
Mixed-Mode Assignment
Assignment statements can also be mixed-mode
In Fortran, C, Perl, and C++, any numeric type value can be assigned to any numeric type variable
In Java and C#, only widening assignment coercions are done
In Ada, there is no assignment coercion
Chapter 8
Control Statements
Control Structure
A control structure is a control statement and the statements whose execution it controls
Selection Statements
A selection statement provides the means of choosing between two or more paths of execution (basically if statements)
General form:
if control_expression
then clause
else clause
In many contemporary languages, the then and else clauses can be single statements or compound statements
Python uses indentation to define clauses
if x > y :
x = y
print " x was greater than y"
Nesting Selectors
Java example
if (sum == 0)
if (count == 0)
result = 0;
else result = 1;
Multiple way selection statements
Allow the selection of one of any number of statements or statement groups
#include <iostream>
int main() {
int day = 3;
switch (day) {
case 1:
std::cout << "Monday\n";
break;
case 2:
std::cout << "Tuesday\n";
break;
case 3:
std::cout << "Wednesday\n";
break;
case 4:
std::cout << "Thursday\n";
break;
case 5:
std::cout << "Friday\n";
break;
case 6:
std::cout << "Saturday\n";
break;
case 7:
std::cout << "Sunday\n";
break;
default:
std::cout << "Invalid day\n";
break;
}
return 0;
}
Basically in the example above depending on what case it is the proper response will be done.
Multiple way selectors using if
if count < 10 :
bag1 = True
elif count < 100 :
bag2 = True
elif count < 1000 :
bag3 = True
Iterative Statements
The repeated execution of a statement or compound statement is accomplished either by iteration or recursion
Counter - Controlled loops
essentially for loops
Logically controlled loops
essentially while loops
Unconditional Branching
Transfers execution control to a specified place in the program
Guarded Commands
Designed by Dijkstra
Purpose: to support a new programming methodology that supported verification (correctness) during development
Basis for two linguistic mechanisms for concurrent programming (in CSP and Ada)
Basic Idea: if the order of evaluation is not important, the program should not specify one
Chapter 9
Fundamentals of Subprograms
Each subprogram has a single entry point
The calling program is suspended during execution of the called subprogram
Control always returns to the caller when the called subprogram’s execution terminates
Kind of like polymorphism
A subprogram definition describes the interface to and the actions of the subprogram abstraction
In Python, function definitions are executable; in all other languages, they are non-executable
In Ruby, function definitions can appear either in or outside of class definitions. If outside, they are methods of Object. They can be called without an object, like a function
In Lua, all functions are anonymous
A subprogram call is an explicit request that the subprogram be executed
A subprogram header is the first part of the definition, including the name, the kind of subprogram, and the formal parameters
The parameter profile (aka signature) of a subprogram is the number, order, and types of its parameters
The protocol is a subprogram’s parameter profile and, if it is a function, its return type
Function declarations in C and C++ are often called prototypes
A subprogram declaration provides the protocol, but not the body, of the subprogram
A formal parameter is a dummy variable listed in the subprogram header and used in the subprogram
An actual parameter represents a value or address used in the subprogram call statement
Design Issues for Subprograms
Are local variables static or dynamic?
Can subprogram definitions appear in other subprogram definitions?
What parameter passing methods are provided?
Are parameter types checked?
If subprograms can be passed as parameters and subprograms can be nested, what is the referencing environment of a passed subprogram?
Can subprograms be overloaded?
Can subprogram be generic?
If the language allows nested subprograms, are closures supported?
Local Referencing Environments
Local variables can be stack-dynamic
Advantages
Support for recursion
Storage for locals is shared among some subprograms
Disadvantages
Allocation/de-allocation, initialization time
Indirect addressing
Subprograms cannot be history sensitive
Local variables can be static
Advantages and disadvantages are the opposite of those for stack-dynamic local variables
In C-based languages, locals are by default stack dynamic, but can be declared static
Difference between Static and Regular Variables:
Scope:
Regular Variables: Limited to the block or method in which they are declared.
Static Variables: Accessible across all instances of the class.
Lifetime:
Regular Variables: Exist only while the block or method is executing.
Static Variables: Exist for the entire duration of the program.
Initialization:
Regular Variables: Initialized each time the block or method is executed.
Static Variables: Initialized once when the class is loaded.
Parameter-Passing Methods
Semantic Models of Parameter Passing
In mode
Out mode
Inout mode
Pass-by-value (in mode)
The value of the actual parameter is used to initialize the corresponding formal parameter
Example of Pass by Value:
C++ Example:
```cpp
#include <iostream>
void modifyValue(int value) {
value = 20;
// This change does not affect the original variable
}
int main() {
int originalValue = 10;
std::cout << "Before function call: " << originalValue << std::endl; // Output: 10
modifyValue(originalValue);
std::cout << "After function call: " << originalValue << std::endl; // Output: 10
return 0;
}
```
Explanation:
- originalValue is passed to modifyValue.
- Inside modifyValue, the parameter value is a copy of originalValue.
- Changing value to 20 does not affect originalValue.
- originalValue remains 10 before and after the function call.
Pass by Result (inout mode)
When a parameter is passed by result, no value is transmitted to the subprogram; the corresponding formal parameter acts as a local variable; its value is transmitted to caller’s actual parameter when control is returned to the caller, by physical move
Require extra storage location and copy operation
procedure modifyValue(out result)
result = 20
main
int x
modifyValue(x)
print x // Output: 20
x is an uninitialized variable.
modifyValue(x) sets the local parameter result to 20.
When modifyValue returns, the value of result is assigned to x.
Thus, x becomes 20.
Pass By Reference (inout mode)
Pass an access path
Also called pass-by-sharing
Advantage: Passing process is efficient (no copying and no duplicated storage)
Disadvantages
Slower accesses (compared to pass-by-value) to formal parameters
Potentials for unwanted side effects (collisions)
Unwanted aliases (access broadened)
fun(total, total); fun(list[i], list[j]; fun(list[i], i);
Example:
#include <iostream>
void modifyValue(int &ref) {
ref = 20; // This change affects the original variable
}
int main() {
int originalValue = 10;
std::cout << "Before function call: "<< originalValue << std::endl; // Output: 10
modifyValue(originalValue);
std::cout << "After function call: " << originalValue << std::endl; // Output: 20
return 0;
}
originalValue is passed to modifyValue by reference.
Inside modifyValue, ref is an alias for originalValue.
Changing ref directly modifies originalValue.
originalValue is 10 before the call and 20 after the call.
C
Pass-by-value
Pass-by-reference is achieved by using pointers as parameters
C++
A special pointer type called reference type for pass-by-reference
Java
All parameters are passed are passed by value
Object parameters are passed by reference
Parameters That Are Subprograms
Basically passing functions as parameters (think of project 3 with the heap sort)
Shallow binding: The environment of the call statement that enacts the passed subprogram
- Most natural for dynamic-scoped languages
Deep binding: The environment of the definition of the passed subprogram -
Most natural for static-scoped languages
Ad hoc binding: The environment of the call statement that passed the subprogram
Calling Subprograms Indirectly
Usually when there are several possible subprograms to be called and the correct one on a particular run of the program is not know until execution (e.g., event handling and GUIs)
In C and C++, such calls are made through function pointers
Overloaded Subprograms
An overloaded subprogram is one that has the same name as another subprogram in the same referencing environment
Generic Subprograms
A generic or polymorphic subprogram takes parameters of different types on different activations
basically two different methods with different parameters that have the same name
Overloaded subprograms provide ad hoc polymorphism
Subtype polymorphism means that a variable of type T can access any object of type T or any type derived from T (OOP languages)
A subprogram that takes a generic parameter that is used in a type expression that describes the type of the parameters of the subprogram provides parametric polymorphism
- A cheap compile-time substitute for dynamic binding
Design Issues for Functions
User-Defined Overloaded Operators
Operators can be overloaded in Ada, C++, Python, and Ruby
A Python example
def __add__ (self, second) :
return Complex(self.real + second.real,
self.imag + second.imag)
Use: To compute x + y, x.__add__(y)
Closures
A closure is a subprogram and the referencing environment where it was defined
Closure example:

Coroutines
A coroutine is a subprogram that has multiple entries and controls them itself – supported directly in Lua
Chapter 11 - lots of polymorphism bs
The Concept of Abstraction
An abstraction is a view or representation of an entity that includes only the most significant attributes
Introduction to Data Abstraction
An abstract data type is a user-defined data type that satisfies the following two conditions:
The representation of objects of the type is hidden from the program units that use these objects, so the only operations possible are those provided in the type's definition (methods from the class)
The declarations of the type and the protocols of the operations on objects of the type are contained in a single syntactic unit. Other program units are allowed to create variables of the defined type.
Example
The Stack class encapsulates the stack behavior.
The user interacts with push, pop, and isEmpty methods without knowing the internal array implementation.
Design Issues for Abstract Data Types
What is the form of the container for the interface to the type?
Can abstract types be parameterized?
What access controls are provided?
Is the specification of the type physically separate from its implementation?
Language Examples
ADA
- Encapsulation:
- The encapsulation construct is called a package.
- It includes a Specification package (the interface) and a Body package (implementation).
- Information Hiding:
- The spec package has two parts: public and private.
- The name of the abstract type is in the public part, along with representations of unhidden types.
- The representation of the abstract type is in the private part, ensuring information hiding.
- Private Types:
- Private types can have built-in operations for assignment and comparison.
- Limited private types have NO built-in operations, offering a more restricted form of encapsulation.
C++
Based on C struct type and Simula 67 classes
The class is the encapsulation device
A class is a type
All of the class instances of a class share a single copy of the member functions
Each instance of a class has its own copy of the class data members
Instances can be static, stack dynamic, or heap dynamic
Structs are one of two ways u have classes in c++
Structs - naturally public
Classes - naturally private
Information Hiding
Private clause for hidden entities
Public clause for interface entities
Protected clause for inheritance (Chapter 12)
Constructors
Functions to initialize the data members of instances (they do not create the objects)
May also allocate storage if part of the object is heap-dynamic
Can include parameters to provide parameterization of the objects
Implicitly called when an instance is created
Can be explicitly called
Name is the same as the class name
In general Most restrictive to least:
Private
Package
Protected
Public
Destructors
in c++
Functions to cleanup after an instance is destroyed; usually just to reclaim heap storage
Implicitly called when the object’s lifetime ends
Can be explicitly called
Name is the class name, preceded by a tilde (~)
Example
#include <iostream>
class MyClass {
public:
MyClass() {
std::cout << "Constructor called" << std::endl;
}
~MyClass() {
std::cout << "Destructor called" << std::endl;
}
};
int main() {
MyClass obj; // Constructor called
// Destructor called when obj goes out of scope
return 0;
}
In this example, MyClass defines both a constructor and a destructor.
The constructor is called when an object of MyClass is created, and the destructor is called when the object goes out of scope.
The destructor is automatically invoked by the compiler when the object's lifetime ends, such as when the object goes out of scope or when delete is called on a dynamically allocated object.
The destructor is used to release resources acquired by the object during its lifetime, such as freeing memory or closing files.
Java doesn't have destructors
This is because memory is automatically deallocated by the garbage collector.
But it’s important in c++
If you have a constructors
Parameterized Abstract Data Types
Parameterized ADTs allow designing an ADT that can store any type elements – only an issue for static typed languages
Also known as generic classes
C++, Ada, Java 5.0, and C# 2005 provide support for parameterized ADTs
Encapsulation Constructs
Large programs have two special needs:
Some means of organization, other than simply division into subprograms
Some means of partial compilation (compilation units that are smaller than the whole program)
Obvious solution: a grouping of subprograms that are logically related into a unit that can be separately compiled (compilation units)
Such collections are called encapsulation
Nested Subprograms
Organizing programs by nesting subprogram definitions inside the logically larger subprograms that use them
Encapsulation in C++
classes structs
Friend functions allow access to private members in the class
Naming Encapsulations - basically libraries and shit u import like packages
Large programs define many global names; need a way to divide into logical groupings
A naming encapsulation is used to create a new scope for names
C++ Namespaces
Can place each library in its own namespace and qualify names used outside with the namespace
C# also includes namespaces
Java Packages
Packages can contain more than one class definition; classes in a package are partial friends
Clients of a package can use fully qualified name or use the import declaration
Midterm BS
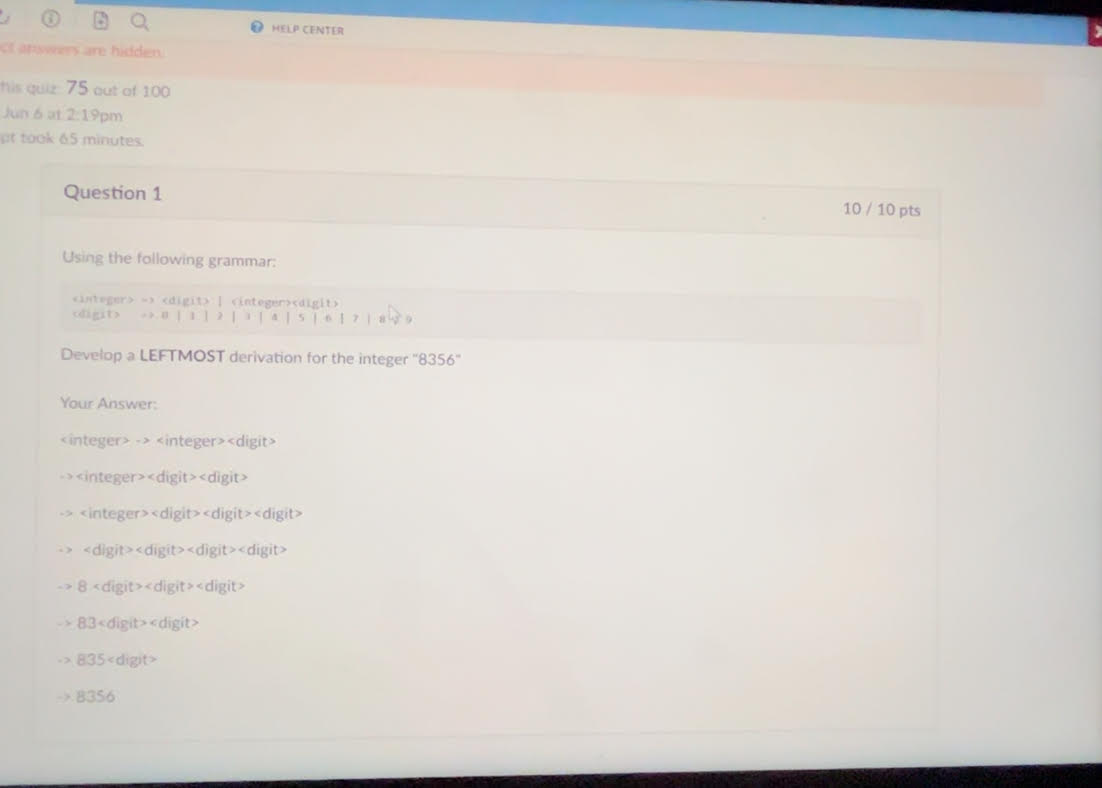
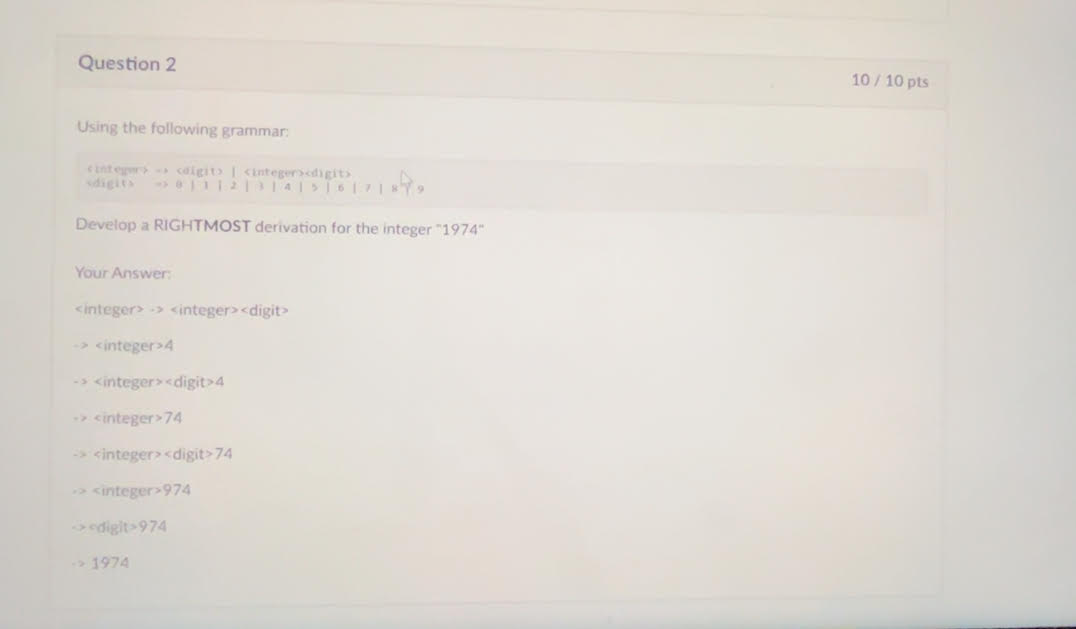
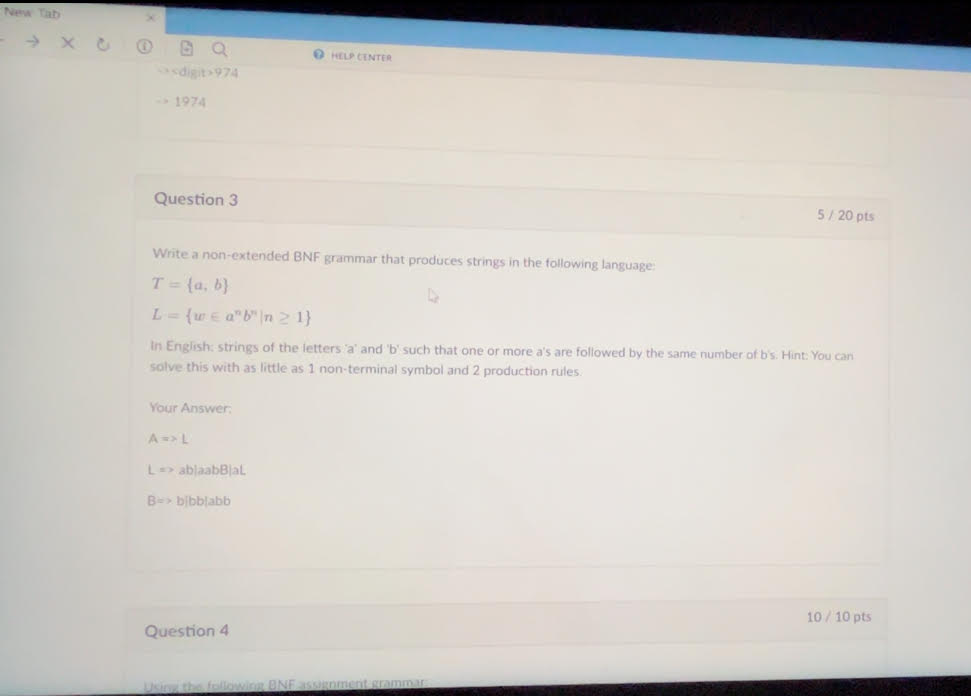 This one you got wrong cuz your DUMBASS
This one you got wrong cuz your DUMBASS
A => ab | aAb
is all it was
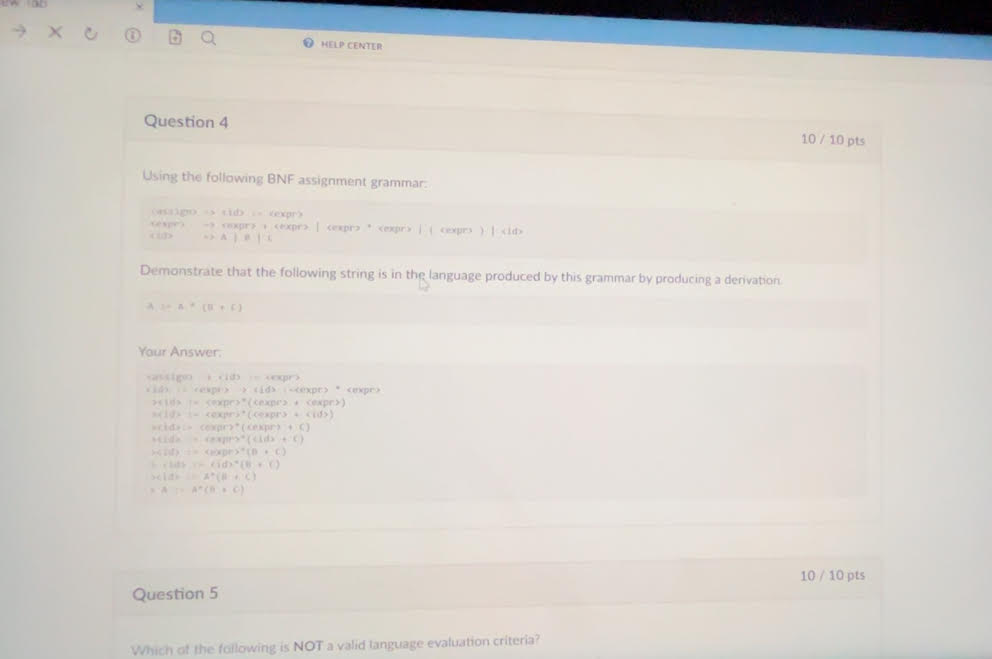 Just basically used right most derivation in this
Just basically used right most derivation in this
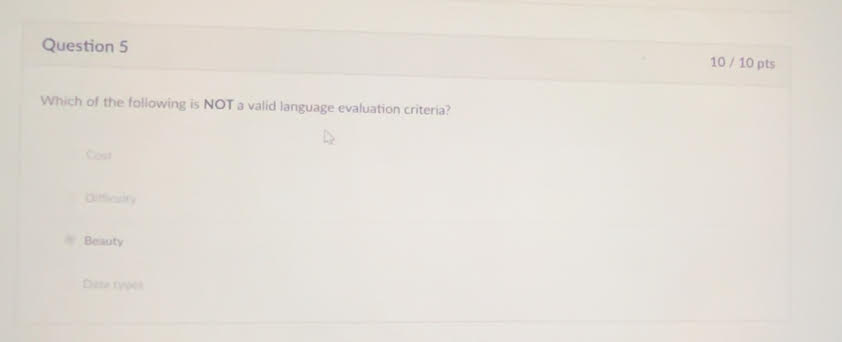 This one was obvious but pay attention do the ones that ARE evaluation criteria: Data Types, cost, difficulty
This one was obvious but pay attention do the ones that ARE evaluation criteria: Data Types, cost, difficulty
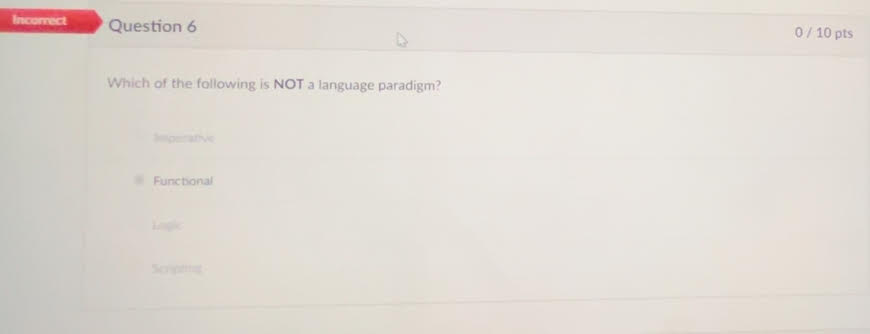 you were an idiot and didn’t know what a language paradigm was. The correct answer is scripting
you were an idiot and didn’t know what a language paradigm was. The correct answer is scripting
Scripting is not a language paradigm because it doesn't define a fundamental approach to programming. Imperative, logic, and functional programming are paradigms that prescribe specific methods for solving problems using programming languages. Scripting, on the other hand, refers to using a language to automate tasks without specifying a particular programming methodology.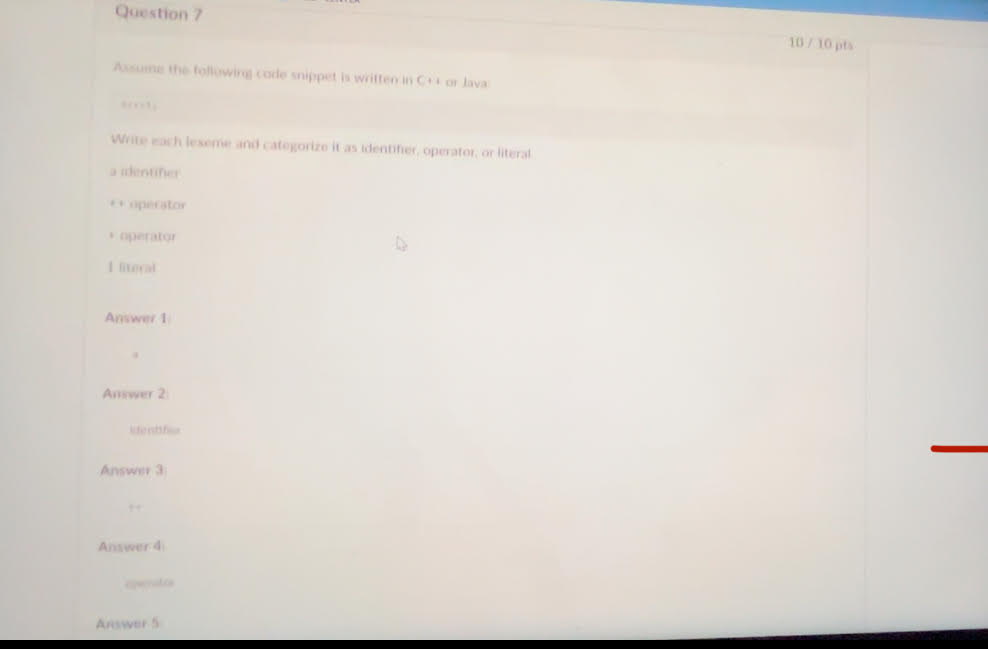

Chapter 2
Zuse’s Plankalkül - Designed in 1945 but not published until 1972. It featured advanced data structures, floating-point arrays, records, and invariants.
Fortran - Developed in the 1950s, Fortran (Formula Translation) was designed for scientific computing and is notable for its use of compiled programming languages.
LISP - Developed in the late 1950s at MIT by John McCarthy, LISP (LISt Processing) is a functional programming language aimed at artificial intelligence research, using lists as its primary data structure.
COBOL - Developed in the 1960s for business data processing. It stands for Common Business Oriented Language and was designed to be readable by non-programmers.
BASIC - Developed in the 1960s for beginners, BASIC (Beginner's All-purpose Symbolic Instruction Code) was designed to be easy to use for non-science students.
PL/I - Created by IBM in the 1960s to combine features from scientific and business programming languages. PL/I stands for Programming Language One and was the first to include unit-level concurrency, exception handling, and recursion.
Prolog - A logic programming language developed in the 1970s, primarily used in artificial intelligence and computational linguistics. It allows for the expression of logic in a form of rules and facts.
Ada - A programming language developed in the 1970s by the US Department of Defense. Named after Ada Lovelace, it supports object-oriented, concurrent, and systems programming
Short Code - Developed by Mauchly in 1949 for BINAC computers, Short Code used left-to-right expression coding and was an early form of pseudocode.
Speedcoding - Developed by Backus in 1954 for the IBM 701, it featured pseudo operations for arithmetic, math functions, and conditional branching. It was slow due to limited memory for user programs.
ALGOL 60 - A refined version of ALGOL 58, it introduced block structure, two parameter passing methods, subprogram recursion, and stack-dynamic arrays. It became the standard for publishing algorithms and influenced many subsequent languages .
ALGOL 68 - An orthogonal design language that was more complex than ALGOL 60. It featured user-defined data types, flexible arrays, and a strong type system, but was less successful due to its complexity.
Pascal - Developed by Niklaus Wirth in the late 1960s, Pascal was designed for teaching programming and structured programming. It featured strong typing, extensive error checking, and was used widely in academia.
C - Developed in the early 1970s at Bell Labs by Dennis Ritchie, C is a general-purpose programming language that provides low-level access to memory. It has influenced many other languages and remains widely used today.
Smalltalk - Developed in the 1970s, Smalltalk is an object-oriented programming language that introduced the concept of classes and message passing. It significantly influenced the development of later OOP languages.
C++ - An extension of C developed by Bjarne Stroustrup in the early 1980s. C++ added object-oriented features to C, making it suitable for large-scale software development. It supports both low-level and high-level programming
Chapter 3
Syntax - The form or structure of the expressions, statements, and program units.
Semantics - The meaning of the expressions, statements, and program units.
Sentence - A string of characters over some alphabet.
Language - A set of sentences.
Lexeme - A lexeme is the smallest unit of meaning in a programming language, such as a keyword, operator, identifier, or literal. It represents a single element in the source code, like if, +, or 42.
Token - A token is a category or class of lexemes. For example, in the statement int x = 10;, int is a keyword token, x is an identifier token, = is an operator token, and 10 is a literal token. Tokens are the building blocks used by a lexical analyzer to interpret code.
Recognizer - A recognizer is a tool or component of a compiler that reads input strings of a programming language and determines whether they belong to the language. It validates syntax by checking if the input conforms to the language's grammar rules.
Generator - A generator is a tool or system that produces sentences of a language. It can be used to create valid program structures based on a set of grammar rules. This helps in understanding the syntax by generating examples of valid code.
Context-Free Grammar (CFG)
Definition: A type of formal grammar where each production rule maps a single nonterminal to a string of nonterminal and/or terminal symbols.
Characteristics: Can generate languages that include nested structures, such as parentheses in expressions.
Example: S → aSb | ε
Regular Grammar
Definition: A formal grammar where production rules are restricted to a single nonterminal on the left-hand side and a string of at most one terminal followed by at most one nonterminal on the right-hand side.
Characteristics: Suitable for defining regular languages, which do not include nested structures.
Example: A → aA | b
Difference Between CFG and Regular Grammar
Complexity: CFGs can generate more complex languages with nested structures; regular grammars cannot.
Automata: CFGs use pushdown automata; regular grammars use finite state automata.
Pushdown Automaton (PDA)
Definition: A type of automaton that includes a stack, which provides additional memory beyond the finite control.
Characteristics: Can recognize context-free languages by handling nested structures using the stack.
Example Use: Parsing nested parentheses or matching tags in HTML.
Finite State Automaton (FSA)
Definition: A computational model with a finite number of states and transitions between those states based on input symbols.
Characteristics: Can recognize regular languages by processing symbols sequentially without additional memory.
Example Use: Simple pattern matching, such as finding specific substrings in text.
Regular Grammars and Finite State Automata
Relation: Regular grammars can be directly converted into finite state automata. Each production rule corresponds to transitions between states in the automaton.
Example: The regular grammar A → aA | b can be represented by an FSA that transitions between states on input a or b.
Context-Free Grammars and Pushdown Automata
Relation: Context-free grammars can be recognized by pushdown automata, where the stack is used to keep track of nonterminals and nested structures.
Example: The CFG rule S → aSb | ε can be processed by a PDA that pushes and pops symbols on/from the stack to match a and b pairs.
Backus-Naur Form (BNF) - BNF is a notation for expressing context-free grammars. It uses production rules to define the structure of syntactic elements in a language. Each rule specifies how a nonterminal symbol can be expanded into a sequence of terminal and/or nonterminal symbols.
Nonterminal Symbols - Nonterminal symbols are placeholders or abstractions used in grammar rules to represent sets of possible sequences of symbols. They are eventually replaced by terminal symbols through a series of rule applications to form valid sentences.
Terminals - Terminal symbols are the basic, indivisible symbols of a language (such as keywords, operators, and punctuation) that appear in the final form of a sentence. They are the actual characters or tokens used in the source code.
Rule in BNF - A BNF rule consists of a left-hand side (LHS) which is a nonterminal symbol and a right-hand side (RHS) which is a sequence of terminal and/or nonterminal symbols. The rule describes how the LHS can be replaced by the RHS in the generation of sentences.
Grammar - A grammar is a collection of rules that define the syntax of a language. It includes a finite set of production rules, a start symbol, and terminal and nonterminal symbols. The grammar specifies how sentences in the language can be constructed.
Start Symbol - The start symbol is a special nonterminal in a grammar from which the derivation of sentences begins. It represents the most general form of a sentence in the language and is expanded through the application of grammar rules.
Derivation - A derivation is the process of applying grammar rules to the start symbol to produce a sentence. Each step in the derivation replaces a nonterminal symbol with the sequence specified by a rule, progressively transforming the start symbol into a complete sentence. A derivation can be left most, right most, or neither.
Sentential Form - Any intermediate string of symbols in the process of a derivation is called a sentential form. It can include both terminal and nonterminal symbols and represents a step between the start symbol and the final sentence.
Sentence (in grammar) - In the context of grammar, a sentence is a sentential form composed entirely of terminal symbols. It is the final result of a derivation process, representing a valid sequence of symbols in the language.
Leftmost Derivation - A leftmost derivation is a specific type of derivation where the leftmost nonterminal in each sentential form is always the one expanded first. This approach ensures a consistent order in the application of rules.
Parse Tree - A parse tree is a tree representation of the syntactic structure of a sentence according to a grammar. The root of the tree is the start symbol, and each internal node represents a nonterminal symbol that expands into its children, which are either terminal or nonterminal symbols.
Ambiguous Grammar - A grammar is ambiguous if there exists at least one sentence that can be generated by more than one distinct parse tree. Ambiguity in a grammar can lead to confusion in interpreting the structure and meaning of sentences.
Extended BNF (EBNF) - EBNF is an enhancement of BNF that introduces additional notation to simplify the expression of grammar rules. It includes symbols for optional elements, repetitions, and choices, making it easier to write and understand complex grammars.
Static Semantics - Static semantics defines rules that go beyond the syntactic structure to include context-sensitive aspects, such as type checking and variable declarations. These rules ensure that programs are not only syntactically correct but also make sense within the language's context.
Attribute Grammars - Attribute grammars extend context-free grammars by associating attributes with grammar symbols. These attributes can hold values computed by functions and predicates, enabling the specification of semantic rules and checks within the grammar.
Operational Semantics - Operational semantics describes the meaning of a program by simulating its execution on a machine. It focuses on how the state of the machine changes with each operation, providing an intuitive understanding of the program's behavior.
Denotational Semantics - Denotational semantics uses mathematical functions to map syntactic constructs to their meanings. It provides a formal and abstract method for defining the semantics of programming languages, facilitating proofs of program correctness.
Axiomatic Semantics - Axiomatic semantics is based on formal logic and uses axioms or inference rules to define the behavior of programs. It is used for proving the correctness of programs by showing that certain conditions hold before and after the execution of statements.
Example grammar/ BNF rules -
Derivation example -
Example of Left most grammar
Example of Right Most derivation -
Parse Tree example:
Right Most derivation parse trees
EBNF examples
Optional Parts []
Alternative parts (this or that) denoted by ()
Other variations
Introduction to Syntax Analysis
Purpose: Syntax analysis, or parsing, checks the source code structure against the formal grammar of the programming language.
Implementation: Utilizes formal grammars like Backus-Naur Form (BNF) or Extended BNF (EBNF) to describe the syntax rules.
Lexical Analysis
Definition: The process of converting a sequence of characters into a sequence of tokens, which are meaningful sequences of characters identified as lexemes.
Function: Acts as the front-end of the parser, breaking down the input into manageable pieces (tokens).
Components:
Lexemes: The lowest level syntactic unit, like identifiers and keywords.
Tokens: Categories of lexemes, such as IDENT, NUMBER, KEYWORD.
Lexical Analyzer Construction
Methods:
Formal Description: Specify tokens using regular expressions and generate a lexical analyzer using tools like Lex.
State Diagram: Draw state diagrams for tokens and implement them programmatically.
Hand-constructed Table-driven Implementation: Design a table-driven lexical analyzer manually.
Reasons to Separate Lexical and Syntax Analysis
Simplicity: Simplifies the overall design by separating concerns. The lexical analyzer handles tokenization, while the syntax analyzer handles structure.
Efficiency: Optimizing the lexical analyzer can significantly improve performance as it processes the entire input.
Portability: Lexical analyzers are often platform-specific due to character encoding differences, while syntax analyzers are typically platform-independent.
Syntax Analysis
Definition: The process of analyzing strings of symbols to ensure they conform to the rules of a formal grammar.
Components:
Lexical Analyzer: Processes input into tokens.
Syntax Analyzer: Uses tokens to build a parse tree according to grammar rules.
Recursive-Descent Parsing
Definition: A top-down parsing technique where each nonterminal in the grammar has a corresponding recursive procedure.
Suitability: Works well with grammars written in EBNF.
Process: Each nonterminal symbol is parsed using a corresponding function that recursively calls other functions as necessary.
Bottom-Up Parsing
Definition: A parsing technique that builds the parse tree from the leaves (input tokens) up to the root (start symbol).
Handle: The substring matching the right-hand side of a production rule, which can be replaced by the left-hand side.
Common Algorithms: LR parsing algorithms like SLR, LALR, and canonical LR.
Finite State Automaton (FSA)
Definition: A computational model consisting of states, transitions, and an input alphabet, used to recognize regular languages.
Usage: Recognizes patterns within regular languages.
Relation to Regular Grammars: Regular grammars can be converted into FSAs, where each rule corresponds to a transition between states.
Pushdown Automaton (PDA)
Definition: A type of automaton that includes a stack to provide additional memory beyond the finite control.
Usage: Recognizes context-free languages by handling nested structures using the stack.
Relation to Context-Free Grammars: PDAs can recognize languages defined by context-free grammars, with the stack allowing for the necessary additional memory.
Regular Grammars and Finite State Automata
Relation: Regular grammars define rules that can be directly mapped to the states and transitions of a finite state automaton (FSA).
produce regular languages recognized by finite state Automata.
Example: The regular grammar rule A → aA | b corresponds to an FSA where transitions occur based on input symbols a and b.
Context-Free Grammars and Pushdown Automata
Relation: Context-free grammars can be recognized by pushdown automata (PDAs), which use a stack to manage nonterminal expansions and nested structures.
They produce Context free languages recognized by pushdown automata
Example: The CFG rule S → aSb | ε is processed by a PDA that pushes a onto the stack and pops it when encountering b.
Parsing Problem Goals
Goals:
Detect all syntax errors in the source code and provide meaningful error messages.
Construct the parse tree or produce a trace of the parsing process for valid input.
Top-Down Parsers
Types:
Recursive Descent: Hand-coded, uses recursive procedures for parsing.
LL Parsers: Table-driven, using a predictive parsing table.
Process: Start at the root and build the parse tree in a leftmost derivation order by expanding the nonterminals.
Bottom-Up Parsers
Types:
LR Parsers: Includes SLR, LALR, and canonical LR parsers.
Process: Begin with the input symbols (leaves) and construct the parse tree towards the start symbol (root), performing reductions based on grammar rules.
Efficiency: Operate in linear time for many practical context-free grammars.
Recursive-Descent Parsing Example
Grammar:
<expr> → <term> {(+ | -) <term>}
<term> → <factor> {(* | /) <factor>}
<factor> → id | int_constant | ( <expr> )
Implementation: Each production rule corresponds to a function that processes the input and calls other functions as needed to match the grammar structure.
State Diagram in Lexical Analysis
Simplification: Reduce complexity by combining transitions for similar tokens.
Character Classes: Use character classes (e.g., letters, digits) to simplify the state diagram and handle multiple characters in a single transition.
LR Parsing Table
Components:
ACTION Table: Specifies parsing actions (shift, reduce, accept, error) based on the current state and input token.
GOTO Table: Determines the next state after a reduction based on the nonterminal.
Automaton
Definition: A mathematical model for a machine with a finite number of states that processes sequences of symbols from an input alphabet.
Types:
Finite State Automaton (FSA): Processes regular languages using states and transitions.
Pushdown Automaton (PDA): Processes context-free languages using states, transitions, and a stack for additional memory.
Usage: Used in various applications including lexical analysis, parsing, and pattern recognition.
The Complexity of Parsing
- Parsers that work for any unambiguous
grammar are complex and inefficient ( O(n3),
where n is the length of the input )
- Compilers use parsers that only work for a
subset of all unambiguous grammars, but do it
in linear time ( O(n), where n is the length of the
input )
Chapter 5
Imperative Languages and von Neumann Architecture
Imperative Languages: Programming languages based on commands changing a program's state.
von Neumann Architecture: Basis for imperative languages; involves sequential execution and shared memory, reflecting the fetch-decode-execute cycle.
Variables are characterized by attributes
To design a type, must consider scope, lifetime, type checking, initialization, and type compatibility
Connotative vs. Non-Connotative Names in Programming
Connotative Meaning: Implied meaning beyond the literal.
Example: calculateSum()—clearly indicates its purpose.
Non-Connotative Meaning: Lacks descriptive clarity.
Example: x or func1()—ambiguous and unclear.
Importance:
Descriptive Names: Improve readability and maintainability.
Best Practice: Use meaningful names to convey intent and functionality.
Special Characters in Variable Naming
PHP: $ - All variable names must begin with dollar signs.
Perl: Special characters specify variable types.
Ruby: @ - Instance variables, @@ - Class variables.
Case sensitivity
Disadvantage: readability (names that look alike are different)
Names in the C-based languages are case sensitive
Names in others are not
Worse in C++, Java, and C# because predefined names are mixed case (e.g. IndexOutOfBoundsException)
Special words
Special words aid readability in programming.
They delimit or separate statement clauses.
Examples include keywords and reserved words.
Keywords
Keywords hold significance in specific contexts of a programming language.
They often denote data types or language constructs.
Examples: "Real" in Fortran, "int" in C++.
Reserved Words
Reserved words cannot be used as user-defined names.
They are reserved for language-specific purposes.
Excessive reserved words can lead to collisions and programming complexities.
Variables
A variable is an abstraction of a memory cell
Variables can be characterized as a sextuple of attributes:
Name
Address
Value
Type
Lifetime
Scope
Variable Attributes
Name - (self explanatory )not all variables have them
Address - the memory address with which it is associated
A variable may have different addresses at different times during execution and places throughout the program
If two variable names can be used to access the same memory location, they are called aliases
Aliases are created via pointers, reference variables, C and C++ unions
Aliases are harmful to readability (program readers must remember all of them
Type - determines the range of values of variables and the set of operations that are defined for values of that type; in the case of floating point, type also determines the precision
ex floats, ints, bools, etc
Value - the contents of the location with which the variable is associated
- The l-value of a variable is its address
the left side value of the = sign
- The r-value of a variable is its value
the right side value of the = sign
Explicit declaration
An explicit declaration is a program statement used for declaring the types of variables
implicit declaration
An implicit declaration is a default mechanism for specifying types of variables through default conventions, rather than declaration statements
Binding
A binding is an association between an entity and an attribute, such as between a variable and its type or value, or between an operation and a symbol
Static Binding:
A binding is static if it first occurs before run time and remains unchanged throughout program execution.
Dynamic Binding:
A binding is dynamic if it first occurs during execution or can change during execution of the program
Binding time - is the time at which a binding takes place.
Compile time -- bind a variable to a type in C or Java at the time at which the code compiles
Runtime -- bind a nonstatic local variable to a memory cell at the time at which the code runs
Scope
The scope of a variable is the range of statements over which it is visible
The local variables of a program unit are those that are declared in that unit
The nonlocal variables of a program unit are those that are visible in the unit but not declared there
Global variables are a special category of nonlocal variables
The scope rules of a language determine how references to names are associated with variables
Dynamic Scope
Based on calling sequences of program units, not their textual layout (temporal versus spatial) (basically more based on time something is called rather than where it is between the {})
References to variables are connected to declarations by searching back through the chain of subprogram calls that forced execution to this point
Static Scope
Definition:
- Static scope connects a name reference to a variable based on program text.
- It involves searching declarations locally and in enclosing scopes until finding one for the given name.
- Enclosing static scopes are termed static ancestors; the closest is the static parent.
- Languages like Ada, JavaScript, Common LISP, Scheme, Fortran 2003+, F#, and Python allow nested subprogram definitions, creating nested static scopes.
Named Constants
A named constant is a variable that is bound to a value only when it is bound to storage
Global Scope
Definition:
Global scope refers to the visibility of variables or identifiers throughout the entire program, making them accessible from any part of the codebase. Variables declared in the global scope are typically accessible from any function or block within the program.
Lifetime
The lifetime of a variable is the time during which it is bound to a particular memory cell
Difference between lifetime and scope
def foo():
x = 10
print(x)
foo()
Here, x has a lifetime starting from its declaration within the function foo() until the function exits. Within this lifetime, x is accessible and can be used. However, the scope of x is limited to the function foo(). Attempting to access x outside of foo() will result in an error, indicating that x is not defined in that scope.
def foo():
x = 10
print(x)
foo()
print(x) # Error: NameError: name 'x' is not defined
In this example, the lifetime of x is tied to the execution of foo() while its scope is confined to the function foo().
Differences between Dynamic and Static Scoping
Static Scoping:
pythonx = 10
def foo():
print(x)
def bar():
x = 20
foo()
bar() # Output: 10
In static scoping, foo() uses the x defined globally (10), as the scope is determined at compile-time.
Dynamic Scoping:
pythonx = 10
def foo():
print(x)
def bar():
global x
x = 20
foo()
bar() # Output: 20
In dynamic scoping, foo() uses the x defined in bar() (20), as the scope is determined at runtime. (Note: Python doesn't natively support dynamic scoping; this is a conceptual example.)
Compile Time:
The period when the source code is translated into executable code by a compiler.
Syntax and type checking are performed.
Errors detected during this phase are called compile-time errors.
Examples include syntax errors, type mismatches, and undeclared variables.
Runtime:
The period when the program is executing after being successfully compiled.
The program performs its tasks using CPU and memory resources.
Errors detected during this phase are called runtime errors.
Examples include division by zero, null pointer dereferences, and array out-of-bounds access.
Referencing environment
A referencing environment of a statement is the collection of all variable bindings that are accessible to that statement. It determines which variables can be used and what their current values are.
The referencing environment of a statement is the
collection of all names that are visible in the
statement
Chapter 6 - Data types
Data type
A data type defines a collection of data objects and a set of predefined operations on those objects
A descriptor is the collection of the attributes of a variable
An object represents an instance of a user-defined (abstract data) type
Primitive Data Types
Primitive data types: Those not defined in terms of other data types
integer
Almost always an exact reflection of the hardware so the mapping is trivial
Java’s signed integer sizes: byte, short, int, long
Floating point etc
Languages for scientific use support at least two floating-point types (e.g., float and double; sometimes more
Complex (contain real float and imaginary float)
Decimal
used in COBOL (business code bs)
acccurate but limited range
Boolean true or false
Character
commonly used ASCII
includes characters from most natural languages
originally used in java
Character String Types
Values are sequences of characters
Operations
Typical operations:
Assignment and copying
Comparison (=, >, etc.)
Catenation
Substring reference
Pattern matching
In languages certain
C & c++ - not primitive
SNOBOL4 primitive
Java - primitive via String class
Length
Limited Dynamic Length (c,c++)
In these languages, a special character is used to indicate the end of a string’s characters, rather than maintaining the length (null space)
Dynamic (no maximum): SNOBOL4, Perl, JavaScript
In java strings are mutable and also has string buffers which u can append shit to
Compile- and Run-Time Descriptors
User-Defined Ordinal Types
An ordinal type is one in which the range of possible values can be easily associated with the set of positive integers
Examples of primitive ordinal types in Java
int
char
boolean
Enumerations, or enums, are a data type that consists of a set of named values called elements or members. Enums are used to define variables that can hold only one of the predefined values, improving code readability and reducing errors.
Example:
javapublic enum Day {
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY
}
public class Example {
public static void main(String[] args) {
Day today = Day.MONDAY;
System.out.println("Today is: " + today);
}
}
In this example, Day is an enumeration with the days of the week as its members. The variable today is assigned the value Day.MONDAY.
An ordered contiguous subsequence of an ordinal type
Example: 12 …18 is a subrange of integer type
Array Types
An array is a homogeneous aggregate of data elements in which an individual element is identified by its position in the aggregate, relative to the first element.
Indexing
Indexing (or subscripting) is a mapping from indices to elements
Array Initialization
Some language allow initialization at the time of storage allocation
C, C++, Java, C# example
int list [] = {4, 5, 7, 83}
Character strings in C and C++
char name [] = ″freddie″;
Arrays of strings in C and C++
char *names [] = {″Bob″, ″Jake″, ″Joe″];
Java initialization of String objects
String[] names = {″Bob″, ″Jake″, ″Joe″};
A heterogeneous array is one in which the elements need not be of the same type
# Example in Python
heterogeneous_array = [1, "Hello", 3.14, True]
A rectangular array is a multi-dimensioned array in which all of the rows have the same number of elements and all columns have the same number of elements
A jagged matrix/array has rows with varying number of elements
Possible when multi-dimensioned arrays actually appear as arrays of arrays
Associative Arrays
An associative array is an unordered collection of data elements that are indexed by an equal number of values called keys
Record Types
A record is a possibly heterogeneous aggregate of data elements in which the individual elements are identified by names
A record is a data structure that groups together related data of various types using named fields. It is commonly used in languages like Pascal, Ada, and modern languages such as C++ (using structs) and Rust.
#include <stdio.h>
struct Person {
char name[50];
int age;
float height;
};
int main() {
struct Person person1;
// Assigning values to fields
strcpy(person1.name, "Alice");
person1.age = 30;
person1.height = 5.5;
// Accessing fields
printf("Name: %s\n", person1.name);
printf("Age: %d\n", person1.age);
printf("Height: %.1f\n", person1.height);
return 0;
}
Tuple Types
A tuple is a data type that is similar to a record, except that the elements are not named
# Creating a tuple
person = ("Alice", 30, 5.5)
# Accessing elements by position
name = person[0]
age = person[1]
height = person[2]
print(f"Name: {name}")
print(f"Age: {age}")
print(f"Height: {height}")
List Types
different languages do different things
Lists in LISP and Scheme are delimited by parentheses and use no commas
(A B C D) and (A (B C) D)
Union Types
A union is a type whose variables are allowed to store different type values at different times during execution
Fortran, C, and C++ provide union constructs in which there is no language support for type checking; the union in these languages is called free union
Type checking of unions require that each union include a type indicator called a discriminant
Supported by Ada
Pointer and Reference Types
A pointer type variable has a range of values that consists of memory addresses and a special value, nil
Provide the power of indirect addressing
Provide a way to manage dynamic memory
A pointer can be used to access a location in the area where storage is dynamically created (usually called a heap)
Pointer operations
Two fundamental operations: assignment and dereferencing
Assignment is used to set a pointer variable’s value to some useful address
Dereferencing yields the value stored at the location represented by the pointer’s value
Dereferencing can be explicit or implicit
C++ uses an explicit operation via *
j = *ptr
sets j to the value located at ptr
Problems with pointers
Dangling pointers (dangerous)
A pointer points to a heap-dynamic variable that has been deallocated
Widows
Int *p = malloc(1000)
Int *q = p;
Free (p);
q is not freed so it’s a widow
In c and c++ pointers are S-tier pieces of shits u can do anything with em
Domain type need not be fixed (void *)
void * can point to any type and can be type checked (cannot be de-referenced)
In C++, the & symbol has two primary meanings:
Reference Operator: When used in variable declarations, it denotes a reference type.
Address-of Operator: When used in expressions, it retrieves the memory address of a variable.
Pointers and References
In C and C++, the asterisk (*) symbol is primarily used for two purposes:
Declaration of Pointers: Denotes a pointer type in variable declarations.
cppint *ptr; // 'ptr' is a pointer to an integer.
Dereferencing Operator: Accesses the value pointed to by a pointer.
cppint x = 10;
int *ptr = x; // 'ptr' points to 'x'
int value = *ptr; // 'value' is assigned the value of 'x'.
These are the main uses of the asterisk in C and C++ code.
Orphans
void createOrphan() {
int *ptr = new int; // Dynamically allocate memory
// ptr goes out of scope without deallocating memory
}
int main() {
createOrphan(); // Memory allocated in createOrphan becomes orphaned
// The dynamically allocated memory is now inaccessible and can't be deallocated
return 0;
}
Type Checking
Type checking is the activity of ensuring that the operands of an operator are of compatible types
A compatible type is one that is either legal for the operator, or is allowed under language rules to be implicitly converted, by compiler- generated code, to a legal type
This automatic conversion is called a coercion.
Strong Typing
A programming language is strongly typed if type errors are always detected
Advantage of strong typing: allows the detection of the misuses of variables that result in type errors
Ada really strongly typed
Java strongly typed
c++ kinda strongly typed
C not really strongly typed
Type Equivalence
Name type equivalence means the two variables have equivalent types if they are in either the same declaration or in declarations that use the same type name
Structure type equivalence means that two variables have equivalent types if their types have identical structures
Chapter 7
Arithmetic Expressions
Arithmetic evaluation was one of the motivations for the development of the first programming languages
Arithmetic expressions consist of operators, operands, parentheses, and function calls
A unary operator has one operand
A binary operator has two operands
A ternary operator has three operands
The operator precedence rules for expression evaluation define the order in which “adjacent” operators of different precedence levels are evaluated (think pemdas)
Typical precedence levels
parentheses
unary operators
** (if the language supports it)
*, /
+, -
The operator associativity rules for expression evaluation define the order in which adjacent operators with the same precedence level are evaluated. Think left to right if you have two addition in your function.
Conditional expressions (ternary conditional operator)
average = (count == 0)? 0 : sum / count
if true average gets set to sum to 0 if not sum/count
Functional side effects: when a function changes a two-way parameter or a non-local variablea = 10;
/* assume that fun changes its parameter */
b = a + fun(&a);
Overloaded Operators
Use of an operator for more than one purpose is called operator overloading
ex using + to add floats and ints
Type Conversions
A narrowing conversion is one that converts an object to a type that cannot include all of the values of the original type e.g., float to int
A widening conversion is one in which an object is converted to a type that can include at least approximations to all of the values of the original type e.g., int to float
A mixed-mode expression is one that has operands of different types
A coercion is an implicit type conversion
Disadvantage of coercions:
They decrease in the type error detection ability of the compiler
EX:#include <iostream>
int main() {
int intVar = 10;
double doubleVar = 5.5;
double result = intVar + doubleVar; //intVar is automatically converted to double
std::cout << "Result: " << result << std::endl; // Output: 15.5
return 0;
}
Called casting in C-based languages
Examples
C: (int)angle
F#: float(sum)
Errors in Expressions
Causes
Inherent limitations of arithmetic e.g., division by zero
Limitations of computer arithmetic e.g. overflow
Often ignored by the run-time system
Relational and Boolean Expressions
Relational Expressions
Use relational operators and operands of various types
Evaluate to some Boolean representation
Operator symbols used vary somewhat among languages (!=, /=, ~=, .NE., <>, #)
Boolean Expressions
Operands are Boolean and the result is Boolean
Example: (13 * a) * (b / 13 – 1)
If a is zero, there is no need to evaluate (b /13 - 1)
Short-Circuit Evaluation
An expression in which the result is determined without evaluating all of the operands and/or operators
C, C++, and Java: use short-circuit evaluation for the usual Boolean operators (&& and ||), but also provide bitwise Boolean operators that are not short circuit (& and |)
Assignment Statements
The general syntax
<target_var> <assign_operator> <expression>
in this example <assign_operator> can be
The assignment operator
= Fortran, BASIC, the C-based languages
:= Ada
= can be bad when it is overloaded for the relational operator for equality (that’s why the C-based languages use == as the relational operator)
Compound Assignment Operators
A shorthand method of specifying a commonly needed form of assignment
Example
a = a + b
can be written as
a += b
Unary assignment operators in C-based languages combine increment and decrement operations with assignment
sum = ++count (count incremented, then assigned to sum)
sum = count++ (count assigned to sum, then incremented
count++ (count incremented)
-count++ (count incremented then negated)
Mixed-Mode Assignment
Assignment statements can also be mixed-mode
In Fortran, C, Perl, and C++, any numeric type value can be assigned to any numeric type variable
In Java and C#, only widening assignment coercions are done
In Ada, there is no assignment coercion
Chapter 8
Control Statements
Control Structure
A control structure is a control statement and the statements whose execution it controls
Selection Statements
A selection statement provides the means of choosing between two or more paths of execution (basically if statements)
General form:
if control_expression
then clause
else clause
In many contemporary languages, the then and else clauses can be single statements or compound statements
Python uses indentation to define clauses
if x > y :
x = y
print " x was greater than y"
Nesting Selectors
Java example
if (sum == 0)
if (count == 0)
result = 0;
else result = 1;
Multiple way selection statements
Allow the selection of one of any number of statements or statement groups
#include <iostream>
int main() {
int day = 3;
switch (day) {
case 1:
std::cout << "Monday\n";
break;
case 2:
std::cout << "Tuesday\n";
break;
case 3:
std::cout << "Wednesday\n";
break;
case 4:
std::cout << "Thursday\n";
break;
case 5:
std::cout << "Friday\n";
break;
case 6:
std::cout << "Saturday\n";
break;
case 7:
std::cout << "Sunday\n";
break;
default:
std::cout << "Invalid day\n";
break;
}
return 0;
}
Basically in the example above depending on what case it is the proper response will be done.
Multiple way selectors using if
if count < 10 :
bag1 = True
elif count < 100 :
bag2 = True
elif count < 1000 :
bag3 = True
Iterative Statements
The repeated execution of a statement or compound statement is accomplished either by iteration or recursion
Counter - Controlled loops
essentially for loops
Logically controlled loops
essentially while loops
Unconditional Branching
Transfers execution control to a specified place in the program
Guarded Commands
Designed by Dijkstra
Purpose: to support a new programming methodology that supported verification (correctness) during development
Basis for two linguistic mechanisms for concurrent programming (in CSP and Ada)
Basic Idea: if the order of evaluation is not important, the program should not specify one
Chapter 9
Fundamentals of Subprograms
Each subprogram has a single entry point
The calling program is suspended during execution of the called subprogram
Control always returns to the caller when the called subprogram’s execution terminates
Kind of like polymorphism
A subprogram definition describes the interface to and the actions of the subprogram abstraction
In Python, function definitions are executable; in all other languages, they are non-executable
In Ruby, function definitions can appear either in or outside of class definitions. If outside, they are methods of Object. They can be called without an object, like a function
In Lua, all functions are anonymous
A subprogram call is an explicit request that the subprogram be executed
A subprogram header is the first part of the definition, including the name, the kind of subprogram, and the formal parameters
The parameter profile (aka signature) of a subprogram is the number, order, and types of its parameters
The protocol is a subprogram’s parameter profile and, if it is a function, its return type
Function declarations in C and C++ are often called prototypes
A subprogram declaration provides the protocol, but not the body, of the subprogram
A formal parameter is a dummy variable listed in the subprogram header and used in the subprogram
An actual parameter represents a value or address used in the subprogram call statement
Design Issues for Subprograms
Are local variables static or dynamic?
Can subprogram definitions appear in other subprogram definitions?
What parameter passing methods are provided?
Are parameter types checked?
If subprograms can be passed as parameters and subprograms can be nested, what is the referencing environment of a passed subprogram?
Can subprograms be overloaded?
Can subprogram be generic?
If the language allows nested subprograms, are closures supported?
Local Referencing Environments
Local variables can be stack-dynamic
Advantages
Support for recursion
Storage for locals is shared among some subprograms
Disadvantages
Allocation/de-allocation, initialization time
Indirect addressing
Subprograms cannot be history sensitive
Local variables can be static
Advantages and disadvantages are the opposite of those for stack-dynamic local variables
In C-based languages, locals are by default stack dynamic, but can be declared static
Difference between Static and Regular Variables:
Scope:
Regular Variables: Limited to the block or method in which they are declared.
Static Variables: Accessible across all instances of the class.
Lifetime:
Regular Variables: Exist only while the block or method is executing.
Static Variables: Exist for the entire duration of the program.
Initialization:
Regular Variables: Initialized each time the block or method is executed.
Static Variables: Initialized once when the class is loaded.
Parameter-Passing Methods
Semantic Models of Parameter Passing
In mode
Out mode
Inout mode
Pass-by-value (in mode)
The value of the actual parameter is used to initialize the corresponding formal parameter
Example of Pass by Value:
C++ Example:
```cpp
#include <iostream>
void modifyValue(int value) {
value = 20;
// This change does not affect the original variable
}
int main() {
int originalValue = 10;
std::cout << "Before function call: " << originalValue << std::endl; // Output: 10
modifyValue(originalValue);
std::cout << "After function call: " << originalValue << std::endl; // Output: 10
return 0;
}
```
Explanation:
- originalValue is passed to modifyValue.
- Inside modifyValue, the parameter value is a copy of originalValue.
- Changing value to 20 does not affect originalValue.
- originalValue remains 10 before and after the function call.
Pass by Result (inout mode)
When a parameter is passed by result, no value is transmitted to the subprogram; the corresponding formal parameter acts as a local variable; its value is transmitted to caller’s actual parameter when control is returned to the caller, by physical move
Require extra storage location and copy operation
procedure modifyValue(out result)
result = 20
main
int x
modifyValue(x)
print x // Output: 20
x is an uninitialized variable.
modifyValue(x) sets the local parameter result to 20.
When modifyValue returns, the value of result is assigned to x.
Thus, x becomes 20.
Pass By Reference (inout mode)
Pass an access path
Also called pass-by-sharing
Advantage: Passing process is efficient (no copying and no duplicated storage)
Disadvantages
Slower accesses (compared to pass-by-value) to formal parameters
Potentials for unwanted side effects (collisions)
Unwanted aliases (access broadened)
fun(total, total); fun(list[i], list[j]; fun(list[i], i);
Example:
#include <iostream>
void modifyValue(int &ref) {
ref = 20; // This change affects the original variable
}
int main() {
int originalValue = 10;
std::cout << "Before function call: "<< originalValue << std::endl; // Output: 10
modifyValue(originalValue);
std::cout << "After function call: " << originalValue << std::endl; // Output: 20
return 0;
}
originalValue is passed to modifyValue by reference.
Inside modifyValue, ref is an alias for originalValue.
Changing ref directly modifies originalValue.
originalValue is 10 before the call and 20 after the call.
C
Pass-by-value
Pass-by-reference is achieved by using pointers as parameters
C++
A special pointer type called reference type for pass-by-reference
Java
All parameters are passed are passed by value
Object parameters are passed by reference
Parameters That Are Subprograms
Basically passing functions as parameters (think of project 3 with the heap sort)
Shallow binding: The environment of the call statement that enacts the passed subprogram
- Most natural for dynamic-scoped languages
Deep binding: The environment of the definition of the passed subprogram -
Most natural for static-scoped languages
Ad hoc binding: The environment of the call statement that passed the subprogram
Calling Subprograms Indirectly
Usually when there are several possible subprograms to be called and the correct one on a particular run of the program is not know until execution (e.g., event handling and GUIs)
In C and C++, such calls are made through function pointers
Overloaded Subprograms
An overloaded subprogram is one that has the same name as another subprogram in the same referencing environment
Generic Subprograms
A generic or polymorphic subprogram takes parameters of different types on different activations
basically two different methods with different parameters that have the same name
Overloaded subprograms provide ad hoc polymorphism
Subtype polymorphism means that a variable of type T can access any object of type T or any type derived from T (OOP languages)
A subprogram that takes a generic parameter that is used in a type expression that describes the type of the parameters of the subprogram provides parametric polymorphism
- A cheap compile-time substitute for dynamic binding
Design Issues for Functions
User-Defined Overloaded Operators
Operators can be overloaded in Ada, C++, Python, and Ruby
A Python example
def __add__ (self, second) :
return Complex(self.real + second.real,
self.imag + second.imag)
Use: To compute x + y, x.__add__(y)
Closures
A closure is a subprogram and the referencing environment where it was defined
Closure example:
Coroutines
A coroutine is a subprogram that has multiple entries and controls them itself – supported directly in Lua
Chapter 11 - lots of polymorphism bs
The Concept of Abstraction
An abstraction is a view or representation of an entity that includes only the most significant attributes
Introduction to Data Abstraction
An abstract data type is a user-defined data type that satisfies the following two conditions:
The representation of objects of the type is hidden from the program units that use these objects, so the only operations possible are those provided in the type's definition (methods from the class)
The declarations of the type and the protocols of the operations on objects of the type are contained in a single syntactic unit. Other program units are allowed to create variables of the defined type.
Example
The Stack class encapsulates the stack behavior.
The user interacts with push, pop, and isEmpty methods without knowing the internal array implementation.
Design Issues for Abstract Data Types
What is the form of the container for the interface to the type?
Can abstract types be parameterized?
What access controls are provided?
Is the specification of the type physically separate from its implementation?
Language Examples
ADA
- Encapsulation:
- The encapsulation construct is called a package.
- It includes a Specification package (the interface) and a Body package (implementation).
- Information Hiding:
- The spec package has two parts: public and private.
- The name of the abstract type is in the public part, along with representations of unhidden types.
- The representation of the abstract type is in the private part, ensuring information hiding.
- Private Types:
- Private types can have built-in operations for assignment and comparison.
- Limited private types have NO built-in operations, offering a more restricted form of encapsulation.
C++
Based on C struct type and Simula 67 classes
The class is the encapsulation device
A class is a type
All of the class instances of a class share a single copy of the member functions
Each instance of a class has its own copy of the class data members
Instances can be static, stack dynamic, or heap dynamic
Structs are one of two ways u have classes in c++
Structs - naturally public
Classes - naturally private
Information Hiding
Private clause for hidden entities
Public clause for interface entities
Protected clause for inheritance (Chapter 12)
Constructors
Functions to initialize the data members of instances (they do not create the objects)
May also allocate storage if part of the object is heap-dynamic
Can include parameters to provide parameterization of the objects
Implicitly called when an instance is created
Can be explicitly called
Name is the same as the class name
In general Most restrictive to least:
Private
Package
Protected
Public
Destructors
in c++
Functions to cleanup after an instance is destroyed; usually just to reclaim heap storage
Implicitly called when the object’s lifetime ends
Can be explicitly called
Name is the class name, preceded by a tilde (~)
Example
#include <iostream>
class MyClass {
public:
MyClass() {
std::cout << "Constructor called" << std::endl;
}
~MyClass() {
std::cout << "Destructor called" << std::endl;
}
};
int main() {
MyClass obj; // Constructor called
// Destructor called when obj goes out of scope
return 0;
}
In this example, MyClass defines both a constructor and a destructor.
The constructor is called when an object of MyClass is created, and the destructor is called when the object goes out of scope.
The destructor is automatically invoked by the compiler when the object's lifetime ends, such as when the object goes out of scope or when delete is called on a dynamically allocated object.
The destructor is used to release resources acquired by the object during its lifetime, such as freeing memory or closing files.
Java doesn't have destructors
This is because memory is automatically deallocated by the garbage collector.
But it’s important in c++
If you have a constructors
Parameterized Abstract Data Types
Parameterized ADTs allow designing an ADT that can store any type elements – only an issue for static typed languages
Also known as generic classes
C++, Ada, Java 5.0, and C# 2005 provide support for parameterized ADTs
Encapsulation Constructs
Large programs have two special needs:
Some means of organization, other than simply division into subprograms
Some means of partial compilation (compilation units that are smaller than the whole program)
Obvious solution: a grouping of subprograms that are logically related into a unit that can be separately compiled (compilation units)
Such collections are called encapsulation
Nested Subprograms
Organizing programs by nesting subprogram definitions inside the logically larger subprograms that use them
Encapsulation in C++
classes structs
Friend functions allow access to private members in the class
Naming Encapsulations - basically libraries and shit u import like packages
Large programs define many global names; need a way to divide into logical groupings
A naming encapsulation is used to create a new scope for names
C++ Namespaces
Can place each library in its own namespace and qualify names used outside with the namespace
C# also includes namespaces
Java Packages
Packages can contain more than one class definition; classes in a package are partial friends
Clients of a package can use fully qualified name or use the import declaration
Midterm BS
This one you got wrong cuz your DUMBASS
A => ab | aAb
is all it was
Just basically used right most derivation in this
This one was obvious but pay attention do the ones that ARE evaluation criteria: Data Types, cost, difficulty
you were an idiot and didn’t know what a language paradigm was. The correct answer is scripting
Scripting is not a language paradigm because it doesn't define a fundamental approach to programming. Imperative, logic, and functional programming are paradigms that prescribe specific methods for solving problems using programming languages. Scripting, on the other hand, refers to using a language to automate tasks without specifying a particular programming methodology.