
AI Course
A language model is a probabilistic model of text.
How can we affect the distribution of the vocabulary?
How do LLMs generate text using these distributions?
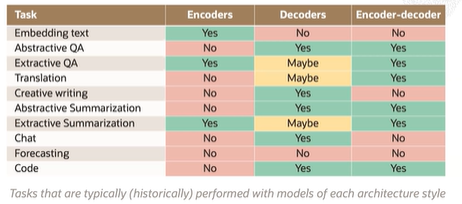
Encoders and decoders are focused on embedding and text generation. They are built on the Transformer architecture.
Embedding text means converting words into a vector, that tries to capture the meaning of it, the encoder model does this. The decoder model covers generation. Decoder models are larger than encoders because fluent generation is needed.
Semantic Search - searches for similar text from input, done by encoders.
Decoders only produce one token at a time, they need to be invoked again for more tokens.
Encoder-decoder models are used for sequence-to-sequence tasks like translation.
To control an LLM, we can affect the probability of vocabulary in 2 ways:
Very large decoder models are pre-trained, where a large amount of text is fed into the model, and given a sequence of words the model guesses what the next word is to be.
Prompt engineering: the process of iteratively refining a prompt to elicit a particular response style. Is challenging, unintuitive, and doesn’t always work. However, there are successful strategies.
In-context learning - conditioning (prompting) an LLM with instructions and or demonstrations of the task it is meant to complete.
K-shot prompting - explicitly providing k examples of the intended task in the prompt.
Doing a bit of K-shot prompting will improve results over having 0-shot prompting.
Chain-of-Thought prompting - prompts the LLM to emit intermediate reasoning steps, and helps accomplish multi-step tasks.
Least-to-most prompting - prompts the LLM to decompose the problem and solve, it easy-first.
Step-back prompting - prompts the LLM to identify high-level concepts related to a specific task.
Prompt injection (jailbreaking) - attempts to cause the LLM to ignore instructions, cause harm, or behave contrary to deployment exceptions.
Prompt injection is a concern any time an external entity is given the ability to contribute to the prompt.
Leaked prompt - shows the original prompt, can show private info.
Domain-adaptation - adapting a model to enhance its performance outside of the subject-area it was trained on.
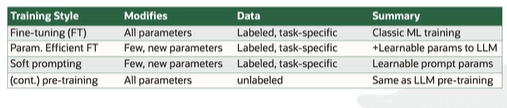
Soft prompting adds parameters to the prompt, it is learned.
Continual pre-training changes all the parameters (expensive) but does not require labeled data.
Fine Tuning - used to be the standard, trained the model for the task by changing all of the parameters (very expensive nowadays)
Parameter Efficient Fine Tuning - isolates a small set of parameters to train, LAURA (low-rank adaptation)
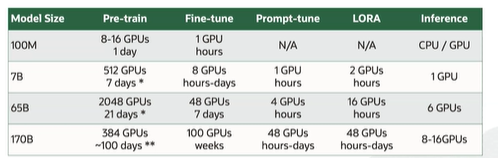
Decoding is an iterative process, one word at a time.
Greedy Decoding - picking the word with the highest probability.
Non-Deterministic Decoding - picks randomly among high-probability choices.
Temperature - a hyper parameter that modulates the distribution over vocabulary. When it is decreased, the distribution is more peaked around the most likely word. When it is increased, the distribution is flattened over all words. However the highest probability will always stay high. When temperature is increased with a non deterministic decoding, you are more likely to get rarer words. When it is decreased with the greedy decoding, there is less rare outputs.
Nucleus sampling - sampling from only the most likely tokens in the model's predicted distribution.
Bean search -generates multiple sequences and picks the best one.
Hallucination is generated text that is non-factual or ungrounded.
There are some methods that reduce hallucination such as retrieval-augmentation, no known methodology however.
Grounded- if the document supports the text of the output, embraced by research.
The TRUE model measures groundedness through NLI.
Trains the LLM to output with citations.
Retrieval augmented generation - model has access to support documents for a input, claimed to reduce hallucination. Used for a bunch of tasks, is non parametric. The model can answer without modify if the documents are good.
Code models - trained on code and comments not language. Easier than generating text. Patching bugs is harder tho.
Multi-Modal are trained on many types of info such as images. For example dalle. Diffusion models can produce a complex output at the same time rather than token by token. Difficult to apply to text.
Language agents are used in sequential decision making scenarios (chess), extension on machine learning. Take actions in response to the environment and can use tools. ReAct is a framework where LLMs emits thoughts then acts and observes. Toolformer is a technique where strings are replaced with calls to tools that get results.
Bootstrapped reasoning prompts the LLM to emit rationalization intermediate steps, used for fine-tuning data.
OCI generative AI service is a fully managed service that provides different LLMs to build AI apps
Gives you a choice of models
Allows for flexible fine-tuning with your own data set
Dedicated AI clusters which are GPU based resources that can host the fine tuning
Text input → service -> output
Generation models - Command Model from cohere, command light by cohere, and llama 2 70b meta
These are instruction tuned models, to better follow human language instructions
Summarization models (command model) summarizes text
Embedding Models creates embeddings which make it easier for computers to understand meanings of the text, are multilingual.
Fine-tuning improves model performance and improves efficiency (reducing tokens)
OCI generative ai uses the T-Few fine-tuning which only updates a portion of the model
The dedicated AI cluster uses a RDMA cluster network to connect the GPUs. The GPUS allocated for a customer are isolated from other GPUs.
LLMS understand tokens over characters
Tokens can be a word, punctuation or part of a word.
Numbers of tokens per word depends on the complexity of the text
Complex text has 2-3 tokens per word
Command Model
Command Light
Llama
Generation Model Parameters:
Cohere summarization model
Extractiveness tells how much original text to reuse
Embeddings are numerical representations of a piece of text converted to number sequences, this makes it easy for computers to understand the relationships between text
Cosine and Dot Product Similiarity can be used to compute numerical similarity
Embeddings that are numerically similar are also semanticlaly similar (same meaning)
Completion LLMs cannot give instructions to or ask questions to
HUman feedback (RLHF) is used to fine-tune LLMs to follow a broad class of written instructions
F-Strings can be used to create a multiline prompt
A language model is a probabilistic model of text.
How can we affect the distribution of the vocabulary?
How do LLMs generate text using these distributions?
Encoders and decoders are focused on embedding and text generation. They are built on the Transformer architecture.
Embedding text means converting words into a vector, that tries to capture the meaning of it, the encoder model does this. The decoder model covers generation. Decoder models are larger than encoders because fluent generation is needed.
Semantic Search - searches for similar text from input, done by encoders.
Decoders only produce one token at a time, they need to be invoked again for more tokens.
Encoder-decoder models are used for sequence-to-sequence tasks like translation.
To control an LLM, we can affect the probability of vocabulary in 2 ways:
Very large decoder models are pre-trained, where a large amount of text is fed into the model, and given a sequence of words the model guesses what the next word is to be.
Prompt engineering: the process of iteratively refining a prompt to elicit a particular response style. Is challenging, unintuitive, and doesn’t always work. However, there are successful strategies.
In-context learning - conditioning (prompting) an LLM with instructions and or demonstrations of the task it is meant to complete.
K-shot prompting - explicitly providing k examples of the intended task in the prompt.
Doing a bit of K-shot prompting will improve results over having 0-shot prompting.
Chain-of-Thought prompting - prompts the LLM to emit intermediate reasoning steps, and helps accomplish multi-step tasks.
Least-to-most prompting - prompts the LLM to decompose the problem and solve, it easy-first.
Step-back prompting - prompts the LLM to identify high-level concepts related to a specific task.
Prompt injection (jailbreaking) - attempts to cause the LLM to ignore instructions, cause harm, or behave contrary to deployment exceptions.
Prompt injection is a concern any time an external entity is given the ability to contribute to the prompt.
Leaked prompt - shows the original prompt, can show private info.
Domain-adaptation - adapting a model to enhance its performance outside of the subject-area it was trained on.
Soft prompting adds parameters to the prompt, it is learned.
Continual pre-training changes all the parameters (expensive) but does not require labeled data.
Fine Tuning - used to be the standard, trained the model for the task by changing all of the parameters (very expensive nowadays)
Parameter Efficient Fine Tuning - isolates a small set of parameters to train, LAURA (low-rank adaptation)
Decoding is an iterative process, one word at a time.
Greedy Decoding - picking the word with the highest probability.
Non-Deterministic Decoding - picks randomly among high-probability choices.
Temperature - a hyper parameter that modulates the distribution over vocabulary. When it is decreased, the distribution is more peaked around the most likely word. When it is increased, the distribution is flattened over all words. However the highest probability will always stay high. When temperature is increased with a non deterministic decoding, you are more likely to get rarer words. When it is decreased with the greedy decoding, there is less rare outputs.
Nucleus sampling - sampling from only the most likely tokens in the model's predicted distribution.
Bean search -generates multiple sequences and picks the best one.
Hallucination is generated text that is non-factual or ungrounded.
There are some methods that reduce hallucination such as retrieval-augmentation, no known methodology however.
Grounded- if the document supports the text of the output, embraced by research.
The TRUE model measures groundedness through NLI.
Trains the LLM to output with citations.
Retrieval augmented generation - model has access to support documents for a input, claimed to reduce hallucination. Used for a bunch of tasks, is non parametric. The model can answer without modify if the documents are good.
Code models - trained on code and comments not language. Easier than generating text. Patching bugs is harder tho.
Multi-Modal are trained on many types of info such as images. For example dalle. Diffusion models can produce a complex output at the same time rather than token by token. Difficult to apply to text.
Language agents are used in sequential decision making scenarios (chess), extension on machine learning. Take actions in response to the environment and can use tools. ReAct is a framework where LLMs emits thoughts then acts and observes. Toolformer is a technique where strings are replaced with calls to tools that get results.
Bootstrapped reasoning prompts the LLM to emit rationalization intermediate steps, used for fine-tuning data.
OCI generative AI service is a fully managed service that provides different LLMs to build AI apps
Gives you a choice of models
Allows for flexible fine-tuning with your own data set
Dedicated AI clusters which are GPU based resources that can host the fine tuning
Text input → service -> output
Generation models - Command Model from cohere, command light by cohere, and llama 2 70b meta
These are instruction tuned models, to better follow human language instructions
Summarization models (command model) summarizes text
Embedding Models creates embeddings which make it easier for computers to understand meanings of the text, are multilingual.
Fine-tuning improves model performance and improves efficiency (reducing tokens)
OCI generative ai uses the T-Few fine-tuning which only updates a portion of the model
The dedicated AI cluster uses a RDMA cluster network to connect the GPUs. The GPUS allocated for a customer are isolated from other GPUs.
LLMS understand tokens over characters
Tokens can be a word, punctuation or part of a word.
Numbers of tokens per word depends on the complexity of the text
Complex text has 2-3 tokens per word
Command Model
Command Light
Llama
Generation Model Parameters:
Cohere summarization model
Extractiveness tells how much original text to reuse
Embeddings are numerical representations of a piece of text converted to number sequences, this makes it easy for computers to understand the relationships between text
Cosine and Dot Product Similiarity can be used to compute numerical similarity
Embeddings that are numerically similar are also semanticlaly similar (same meaning)
Completion LLMs cannot give instructions to or ask questions to
HUman feedback (RLHF) is used to fine-tune LLMs to follow a broad class of written instructions
F-Strings can be used to create a multiline prompt