Molecular Biology
What is it?
A field of study that focuses on investigating biological activity at a molecular level
This includes elucidating the structure and function of chemical substances and determining their interactions as parts of living processes
Biological processes are tightly regulated by enzymes, whose expression is controlled by gene activation (DNA)
Changes in activity are typically determined by signalling molecules (either endogenous or exogenous in origin)
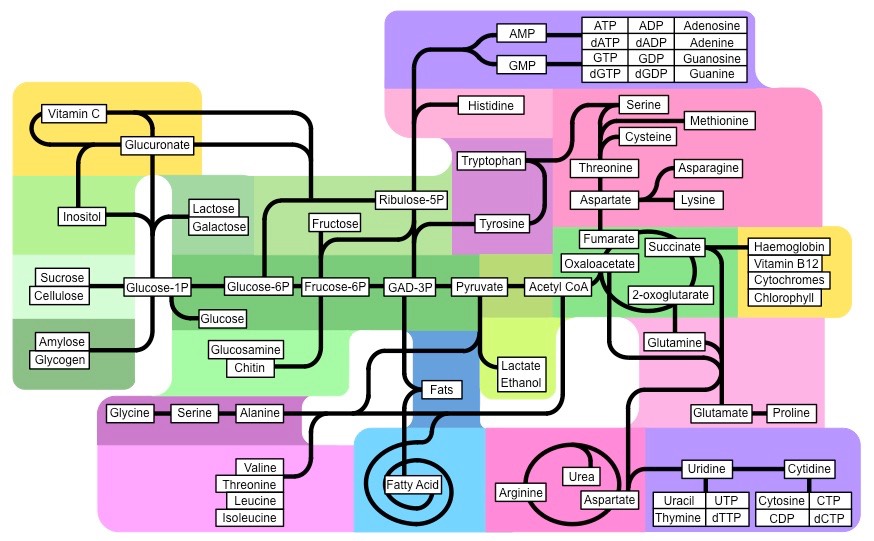
Synthesis of Key Molecules
Synthesis of Key Molecules in a Number of Biological Processes
Organic Compounds
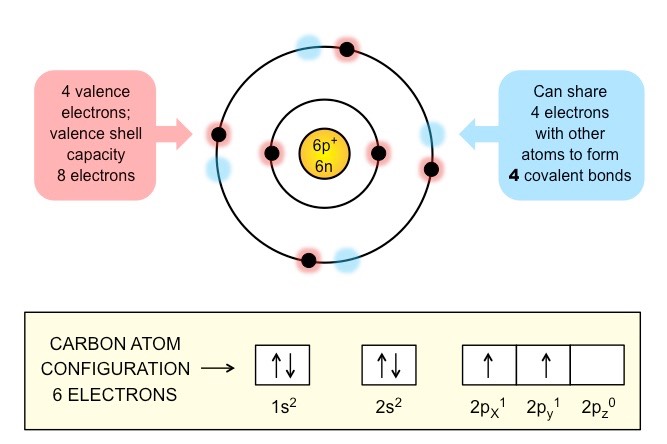
An organic compound is a compound that contains carbon and is found in living things
Exceptions include carbides (e.g. CaC2), carbonates (CO32–), oxides of carbon (CO, CO2) and cyanides (CN–)
Carbon forms the basis of organic life due to its ability to form large and complex molecules via covalent bonding
Carbon atoms can form four covalent bonds, with bonds between carbon atoms being particularly stable (catenation)
These properties allows carbon to form a wide variety of organic compounds that are chemically stable
Schematic of a Carbon Atom
Main Classes of Carbon Compounds
Four principle groups of organic compounds contribute to much of the structure and function of a cell.
Carbohydrates
Most abundant organic compound found in nature, composed primarily of C,H and O atoms in a common ratio – (CH2O)n
Principally function as a source of energy (and as a short-term energy storage option)
Also important as a recognition molecule (e.g. glycoproteins) and as a structural component (part of DNA / RNA)
Lipids
Non-polar, hydrophobic molecules which may come in a variety of forms (simple, complex or derived)
Lipids serve as a major component of cell membranes (phospholipids and cholesterol)
They may be utilised as a long-term energy storage molecule (fats and oils)
Also may function as a signalling molecule (steroids)
Nucleic Acids
Genetic material of all cells and determines the inherited features of an organism
DNA functions as a master code for protein assembly, while RNA plays an active role in the manufacturing of proteins
Proteins
Make over 50% of the dry weight of cells; are composed of C, H, O and N atoms (some may include S)
Major regulatory molecules involved in catalysis (all enzymes are proteins)
May also function as structural molecules or play a role in cellular signalling (transduction pathways)
Main Classes of Organic Compounds in Cells
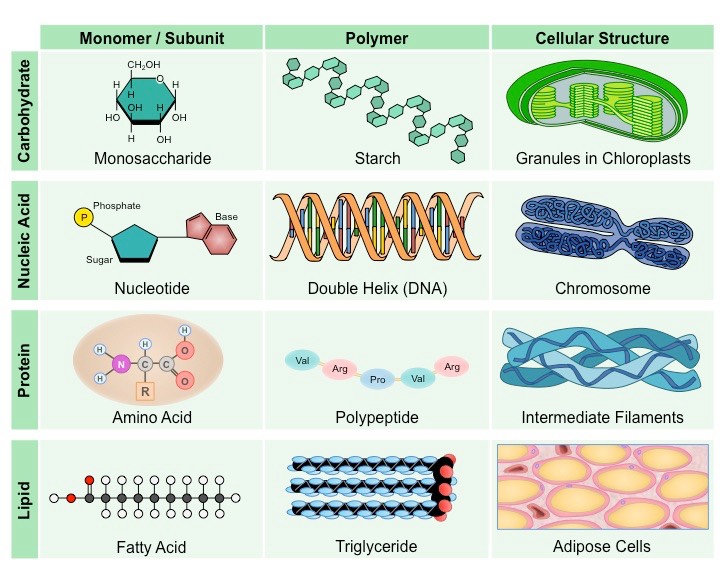
Complex macromolecules may commonly be comprised of smaller, recurring subunits called monomers
Carbohydrates, nucleic acids and proteins are all comprised of monomeric subunits that join together to form larger polymers
Lipids do not contain recurring monomers, however certain types may be composed of distinct subunits (e.g. triglycerides)
Organic Monomers / Subunits

Structure
Carbohydrates
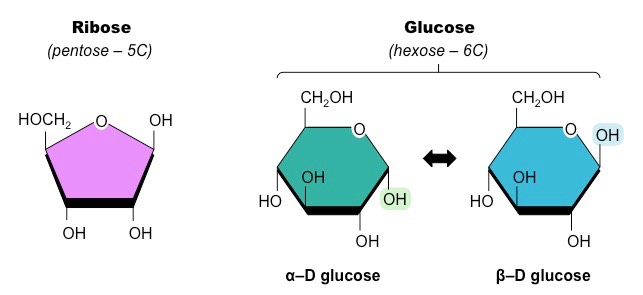
Carbohydrates are composed of monomers called monosaccharides ('single sugar unit')
Monosaccharides are the building blocks of disaccharides (two sugar units) and polysaccharides (many sugar units)
Most monosaccharides form ring structures and can exist in different 3D configurations (stereoisomers)
Examples of Common Monosaccharides
Lipids
Lipids exist as many different classes that vary in structure and hence do not contain a common recurring monomer
However several types of lipids (triglycerides, phospholipids, waxes) contain fatty acid chains as part of their overall structure
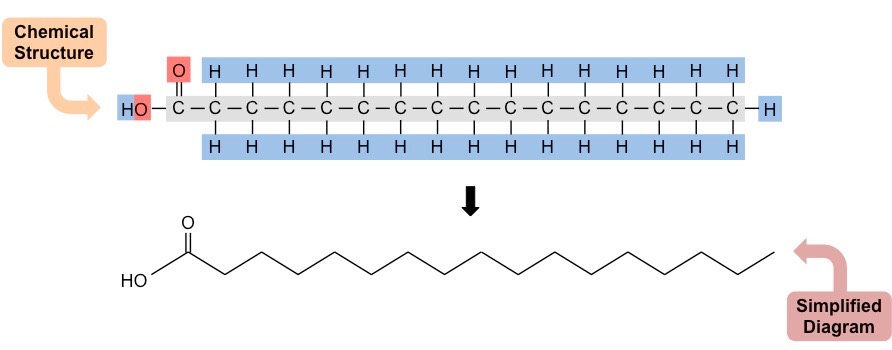
Fatty acids are long chains of hydrocarbons that may or may not contain double bonds (unsaturated vs saturated)
Structure of a Typical Fatty Acid (Saturated)
Proteins
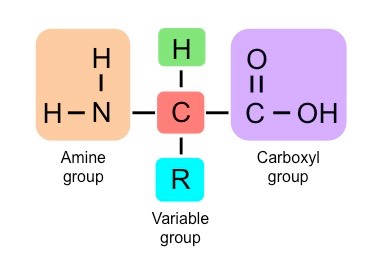
Proteins are composed of monomers called amino acids, which join together to form polypeptide chains
Each amino acid consists of a central carbon connected to an amine group (NH2) and an opposing carboxyl group (COOH)
A variable group (denoted ‘R’) gives different amino acids different properties (e.g. may be polar or non-polar, etc.)
Structure of a Generalised Amino Acid
Nucleic Acids
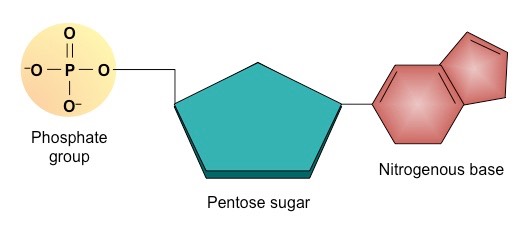
Nucleic acids are composed of monomers called nucleotides, which join together to form polynucleotide chains
Each nucleotide consists of 3 components – a pentose sugar, a phosphate group and a nitrogenous base
The type of sugar and composition of bases differs between DNA and RNA
Structure of a Generalised Nucleotide
Carbohydrates
The structure of complex carbohydrates may vary depending on the composition of monomeric subunits
Polysaccharides may differ according to the type of monosaccharide they possess and the way the subunits bond together
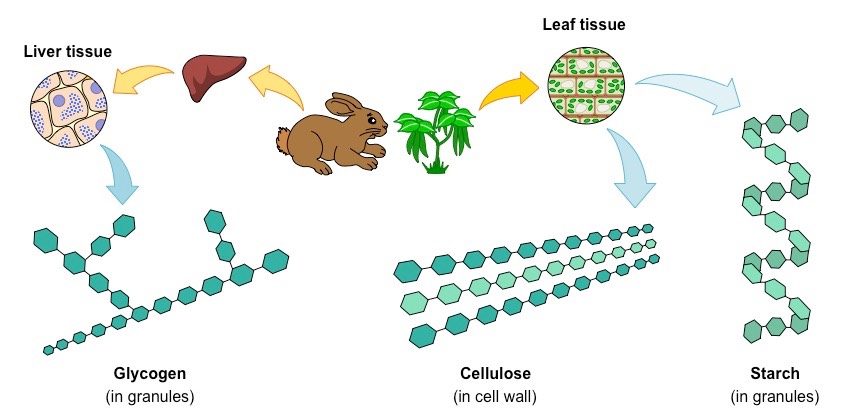
Glucose monomers can be combined to form a variety of different polymers – including glycogen, cellulose and starch
Polymers of Glucose
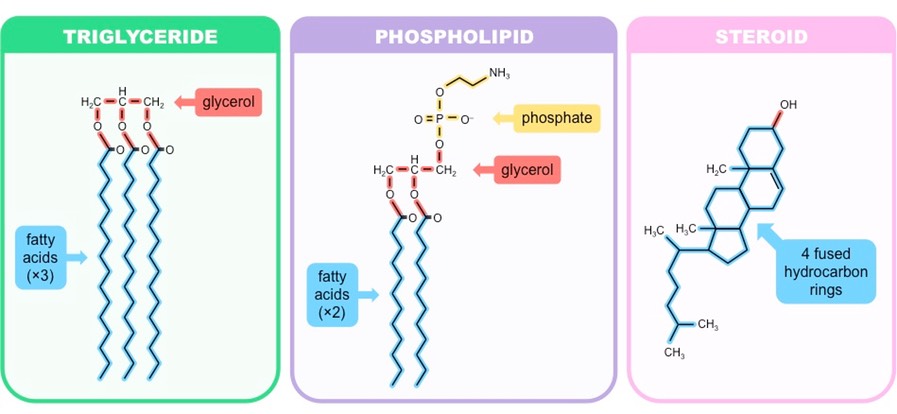
Lipids
Lipids can be roughly organised into one of three main classes:
Simple (neutral) lipids – Esters of fatty acids and alcohol (e.g. triglycerides and waxes)
Compound lipids – Esters of fatty acids, alcohol and additional groups (e.g. phospholipids and glycolipids)
Derived lipids – Substances derived from simple or compound lipids (e.g. steroids and carotenoids)
Three Main Types of Lipids
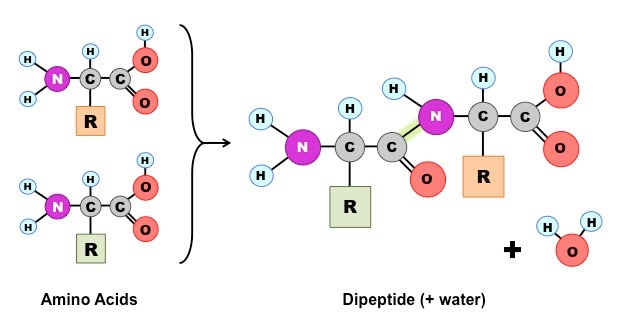
Proteins
Amino acids join together by peptide bonds which form between the amine and carboxyl groups of adjacent amino acids
The fusion of two amino acids creates a dipeptide, with further additions resulting in the formation of a polypeptide chain
The subsequent folding of the chain depends on the order of amino acids in a sequence (based on chemical properties)
Formation of a Dipeptide
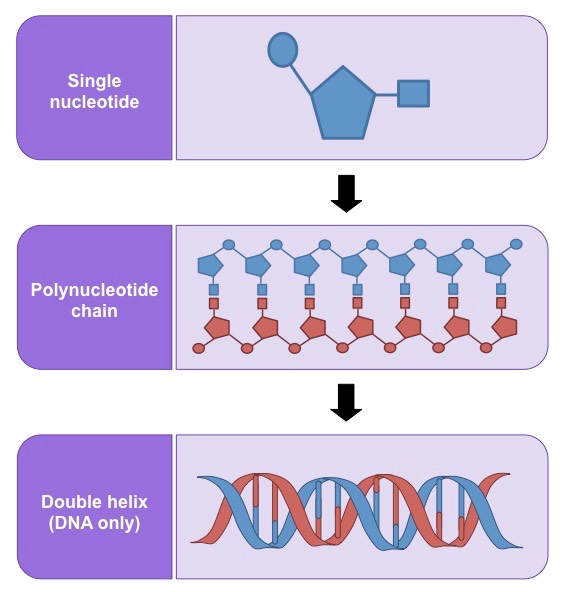
Nucleic Acids
Nucleotides form bonds between the pentose sugar and phosphate group to form long polynucleotide chains
In DNA, two complementary chains will pair up via hydrogen bonding between nitrogenous bases to form double strands
This double stranded molecule may then twist to form a double helical arrangement
Formation of a Polynucleotide Chain
Vitalism
Vitalism was a doctrine that dictated that organic molecules could only be synthesised by living systems
It was believed that living things possessed a certain “vital force” needed to make organic molecules
Hence organic compounds were thought to possess a non-physical element lacking from inorganic molecules
Vitalism as a theory has since been disproven with the discovery that organic molecules can be artificially synthesised
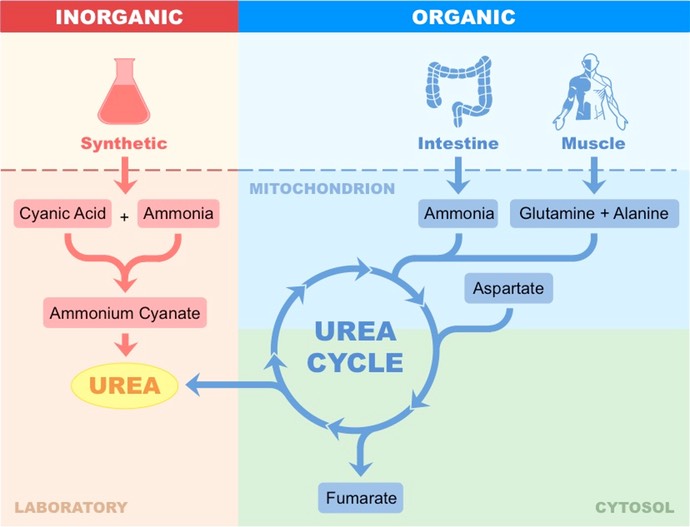
In 1828, Frederick Woehler heated an inorganic salt (ammonium cyanate) and produced urea
Urea is a waste product of nitrogen metabolism and is eliminated by the kidneys in mammals
The artificial synthesis of urea demonstrates that organic molecules are not fundamentally different to inorganic molecules
Synthesis of Urea – Artificial versus Biological
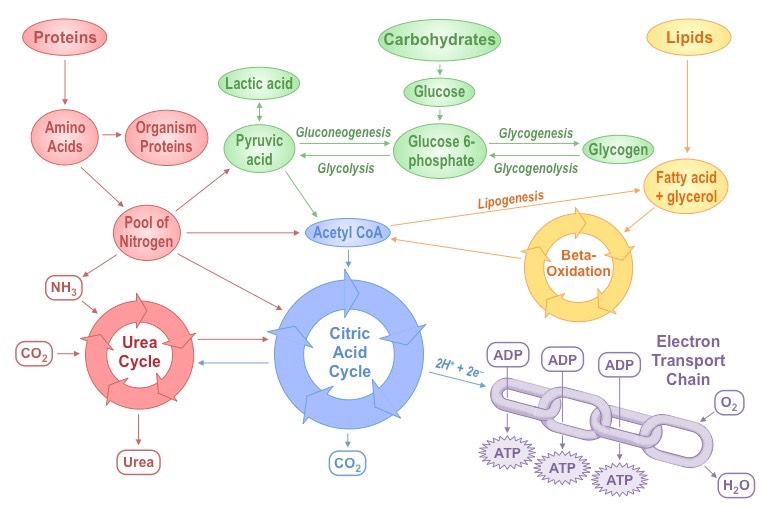
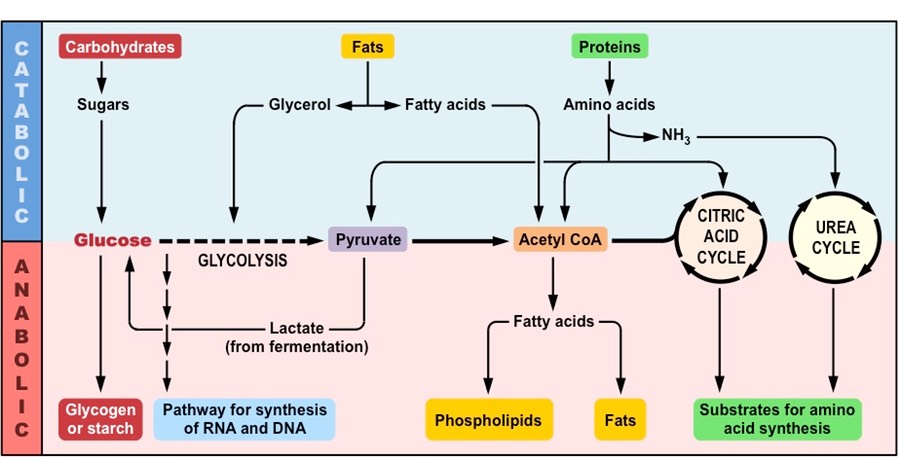
Metabolism describes the totality of chemical processes that occur within a living organism in order to maintain life
It is the web of all enzyme-catalysed reactions that occur within a cell or organism
Metabolic reactions serve two key functions:
They provide a source of energy for cellular processes (growth, reproduction, etc.)
They enable the synthesis and assimilation of new materials for use within the cell
Summary of Key Metabolic Processes
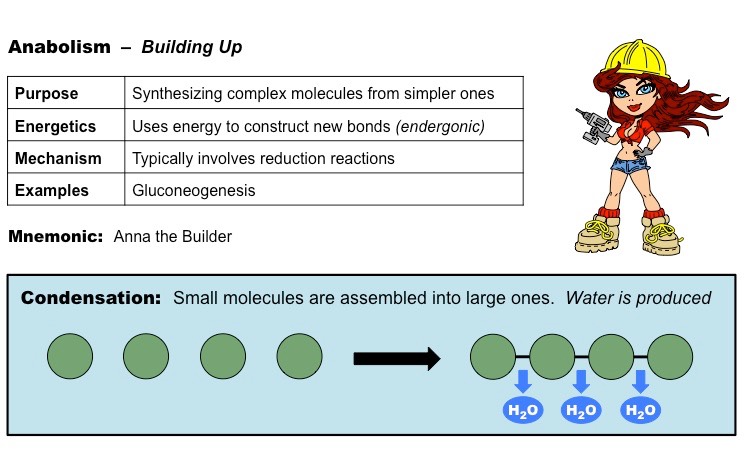
Anabolic reactions describe the set of metabolic reactions that build up complex molecules from simpler ones
The synthesis of organic molecules via anabolism typically occurs via condensation reactions
Condensation reactions occur when monomers are covalently joined and water is produced as a by-product
Monosaccharides are joined via glycosidic linkages to form disaccharides and polysaccharides
Amino acids are joined via peptide bonds to make polypeptide chains
Glycerol and fatty acids are joined via an ester linkage to create triglycerides
Nucleotides are joined by phosphodiester bonds to form polynucleotide chains
Catabolic reactions describe the set of metabolic reactions that break complex molecules down into simpler molecules
The breakdown of organic molecules via catabolism typically occurs via hydrolysis reactions
Hydrolysis reactions require the consumption of water molecules to break the bonds within the polymer
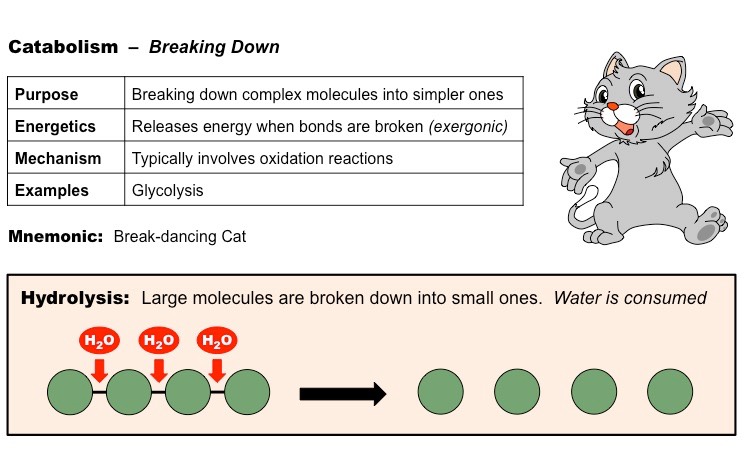
Comparison of Anabolic and Catabolic Pathways
Water is made up of two hydrogen atoms covalently bonded to an oxygen atom (molecular formula = H2O)
While this covalent bonding involves the sharing of electrons, they are not shared equally between the atoms
Oxygen (due to having a higher electronegativity) attracts the electrons more strongly
The shared electrons orbit closer to the oxygen atom than the hydrogen atoms resulting in polarity
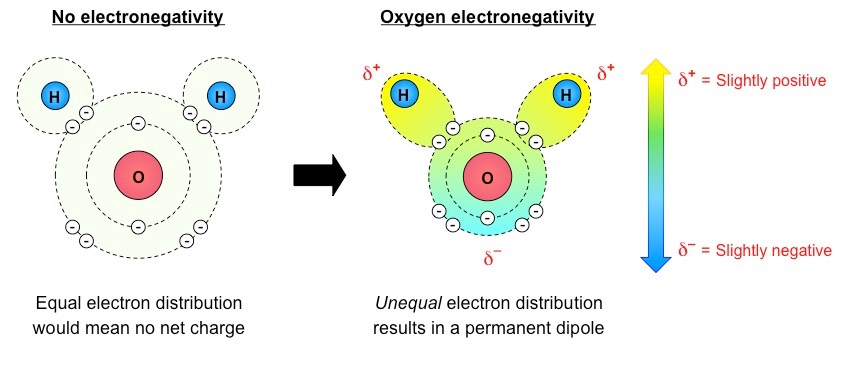
Water is described as being polar because it has a slight charge difference across the different poles of the molecule
The oxygen atom is slightly negative (δ–) while the hydrogen atoms are slightly positive (δ+)
This charge difference across the molecule (dipole) allows water to form weak associations with other polar molecules
The slightly negative poles (δ–) will attract the slightly positive poles (δ+) of other molecules, and vice versa
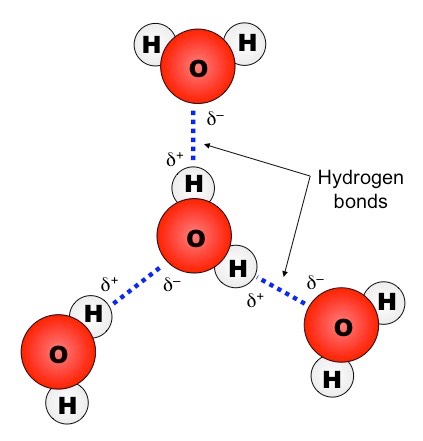
When a δ+ hydrogen atom is attracted to a δ– fluorine, oxygen or nitrogen atom of another molecule, it forms a hydrogen bond
Hydrogen bonds are relatively stronger than other polar associations due to the high electronegativity of F, O and N
The dipolarity of a water molecule enables it to form polar associations with other charged molecules (polar or ionic)
Water can form hydrogen bonds with other water molecules (between a δ+ hydrogen and a δ– oxygen of two molecules)
Hydrogen Bonding between Water Molecules
Properties of Water
This intermolecular bonding between water molecules gives water distinct properties not seen in other substances:
Thermal properties – Water can absorb much heat before changing state (requires breaking of hydrogen bonds)
Cohesive / adhesive properties – Water will ‘stick’ to other water molecules (cohesion) and charged substances (adhesion)
Solvent properties – Water dissolves polar and ionic substances (forms competing polar associations to draw materials apart)
Water has the capacity to absorb significant amounts of heat before changing state
This is due to the extensive hydrogen bonding between water molecules – the H-bonds need to be broken before a change in state can occur and this requires the absorption of energy (heat)
Consequently, water is an excellent medium for living organisms as it is relatively slow to change temperature and thus supports the maintenance of constant conditions (internal and external)
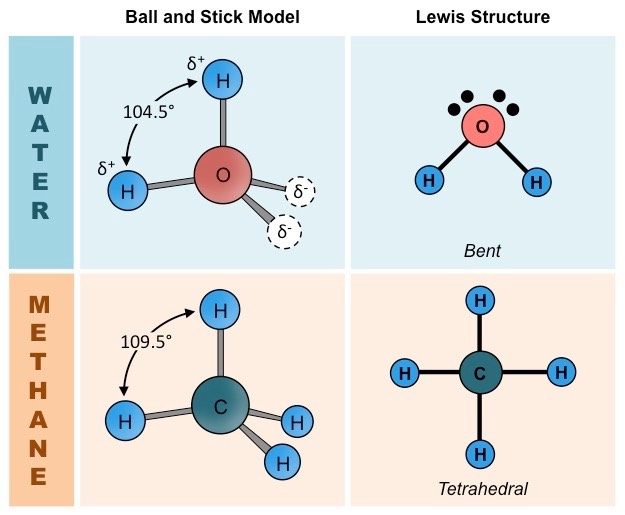
Methane (CH4) provides a good basis for comparison with water due to the many similarities between their structures:
Comparable size and weight (H2O = 18 dalton ; CH4 = 16 dalton)
Comparable valence structures (both have tetrahedral orbital formations, but water is bent due to unbonded electron pairs)
Comparison of Water and Methane Molecules
Differences between Water and Methane
The differences in thermal properties between water and methane arise from differences in polarity between the molecules:
Water is polar and can form intermolecular hydrogen bonds (due to high electronegativity of oxygen atom)
Methane is non-polar and can only form weak dispersion forces between its molecules (carbon has a lower electronegativity)
This means water absorbs more heat before changing state (each H-bond has an average energy of 20 kJ/mol)
Water has a significantly higher melting and boiling point
Water has a higher specific heat capacity (energy required to raise the temperature of 1 g of substance by 1ºC)
Water has a higher heat of vaporisation (energy absorbed per gram as it changes from a liquid to a gas / vapour)
Water as a higher heat of fusion (energy required to be lost to change 1 g of liquid to 1 g of solid at 0ºC)
Table of Key Thermal Properties(Water versus Methane)

The evaporation of water as sweat is a fundamental mechanism employed by humans as a means of cooling down
The change of water from liquid to vapour (evaporation) requires an input of energy
This energy comes from the surface of the skin when it is hot, therefore when the sweat evaporates the skin is cooled
Because water has a high specific heat capacity, it absorbs a lot of thermal energy before it evaporates
Thus water functions as a highly effective coolant, making it the principal component of sweat
Water has the capacity to form intermolecular associations with molecules that share common properties
Because water is polar it will be attracted to other molecules that are polar or have an ionic charge
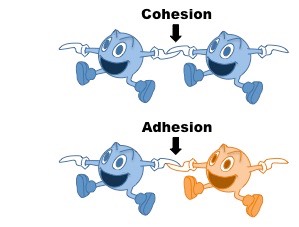
Cohesive Properties:
Cohesion is the ability of like molecules to stick together
Water is strongly cohesive (it will form hydrogen bonds)
Adhesive Properties:
Adhesion is the ability of dissimilar molecules to stick together
Water will form intermolecular associations with polar and charged molecules
Significance of Cohesive and Adhesive Properties:
The cohesive properties of water explain its surface tension
The hydrogen bonding between water molecules allows the liquid to resist low levels of external force (surface tension)
The high surface tension of water makes it sufficiently dense for certain smaller organisms to move along its surface
The adhesive properties of water explain its capillary action
Attraction to charged or polar surfaces (e.g. glass) allows water to flow in opposition of gravitational forces (capillary action)
This capillary action is necessary to allow water to be transported up plant stems via a transpiration stream
Cohesion and Adhesion by Water Molecules
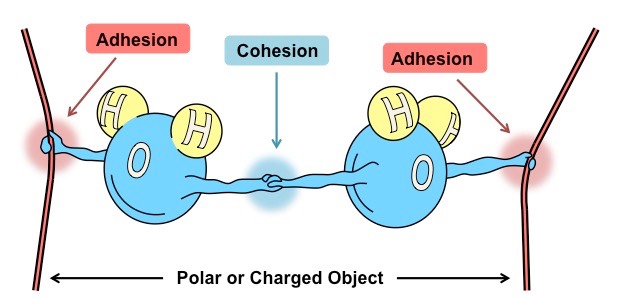
Water is commonly referred to as the universal solvent due to its capacity to dissolve a large number of substances
Water can dissolve any substance that contains charged particles (ions) or electronegative atoms (polarity)
This occurs because the polar attraction of large quantities of water molecules can sufficiently weaken intramolecular forces (such as ionic bonds) and result in the dissociation of the atoms
The slightly charged regions of the water molecule surround atoms of opposing charge, forming dispersive hydration shells
Solvent Properties of Water
- Substances that freely associate and readily dissolve in water are characterised as hydrophilic (‘water loving’)
Hydrophilic substances include all polar molecules and ions
- Substances that do not freely associate or dissolve in water are characterised as hydrophobic (‘water-hating’)
Hydrophobic substances include large, non-polar molecules (such as fats and oils)
- The transport of essential molecules within the bloodstream will depend on their solubility in water
Water soluble substances will usually be able to travel freely in the blood plasma, whereas water insoluble substances cannot
Water Soluble Substances
Sodium chloride (NaCl) is an ionic compound and its components (Na+ and Cl–) may be freely transported within the blood
Oxygen is soluble in water but in low amounts – most oxygen is transported by haemoglobin within red blood cells
Glucose contains many hydroxyl groups (–OH) which may associate with water and thus can freely travel within the blood
Amino acids will be transported in the blood in an ionized state (either the amine and/or carboxyl groups may be charged)
Water Insoluble Substances
Lipids (fats and cholesterol) are non-polar and hydrophobic and hence will not dissolve in water
They form complexes with proteins (lipoproteins) in order to move through the bloodstream
Hydrophilic portions of proteins, cholesterol and phospholipids will face outwards and shield internal hydrophobic components
Carbohydrates are made of C, H and O (‘carbo’ – contains carbon ; ‘hydrate’ – contains H and O)
Carbohydrates are composed of recurring monomers called monosaccharides (which typically form ring structures)
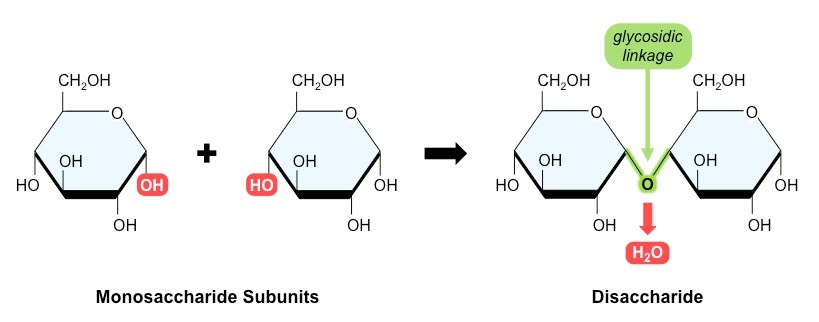
These monosaccharides may be linked together via condensation reactions (water is formed as a by-product)
Two monosaccharide monomers may be joined via a glycosidic linkage to form a disaccharide
Many monosaccharide monomers may be joined via glycosidic linkages to form polysaccharides
Formation of a Disaccharide
Examples of Carbohydrates
- Monosaccharides (one sugar unit) are typically sweet-tasting and function as an immediate energy source for cells
Examples of monosaccharides include glucose, galactose and fructose
- Disaccharides (two sugar units) are small enough to be soluble in water and commonly function as a transport form
Examples of disaccharides include lactose, maltose and sucrose
- Polysaccharides (many sugar units) may be used for energy storage or cell structure, and also play a role in cell recognition
Examples of polysaccharides include cellulose, glycogen and starch
Types of Carbohydrates
Polysaccharides are carbohydrate polymers comprised of many (hundreds to thousands) monosaccharide monomers
The type of polymer formed depends on the monosaccharide subunits involved and the bonding arrangement between them
Three key polymers can be made from glucose monosaccharides – cellulose, starch (in plants) and glycogen (in animals)
Cellulose
Cellulose is a structural polysaccharide that is found in the cell wall of plants
It is a linear molecule composed of β-glucose subunits (bound in a 1-4 arrangement)
Because it is composed of β-glucose, it is indigestible for most animals (lack the enzyme required to break it down)
Ruminants (e.g. cows) may digest cellulose due to the presence of helpful bacteria in a specialised stomach
Caecotrophs (e.g. rabbits) will re-ingest specialised faeces that contain digested cellulose (broken down in the caecum)
Starch
Starch is an energy storage polysaccharide found in plants
It is composed of α-glucose subunits (bound in a 1-4 arrangement) and exists in one of two forms – amylose or amylopectin
Amylose is a linear (helical) molecule while amylopectin is branched (contains additional 1-6 linkages)
Amylose is harder to digest and less soluble, however, as it takes up less space, is the preferred storage form in plants
Glycogen
Glycogen is an energy storage polysaccharide formed in the liver in animals
It is composed of α-glucose subunits linked together by both 1-4 linkages and 1-6 linkages (branching)
It is akin to amylopectin in plants, but is more highly branched (1-6 linkages occur every ~10 subunits as opposed to ~20)
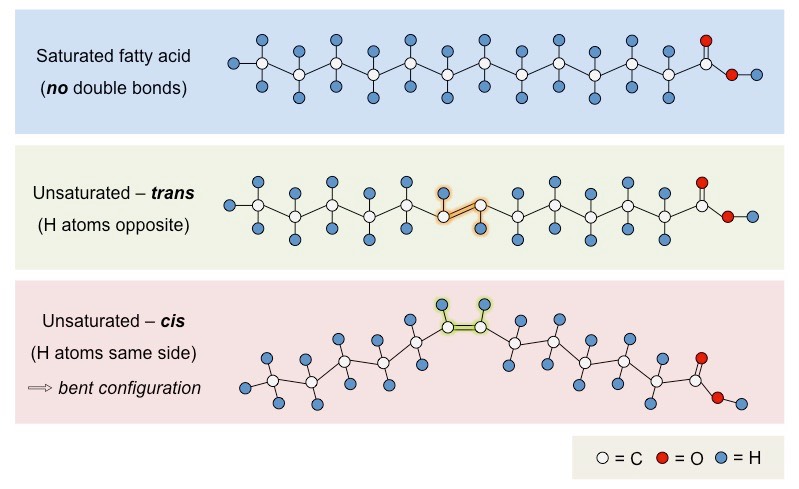
Fatty Acids
Fatty acids are long hydrocarbon chains that are found in certain types of lipids (triglycerides & phospholipids)
Fatty acids may differ in the length of the hydrocarbon chain (typically 4 – 24 carbons) and in the number of double bonds
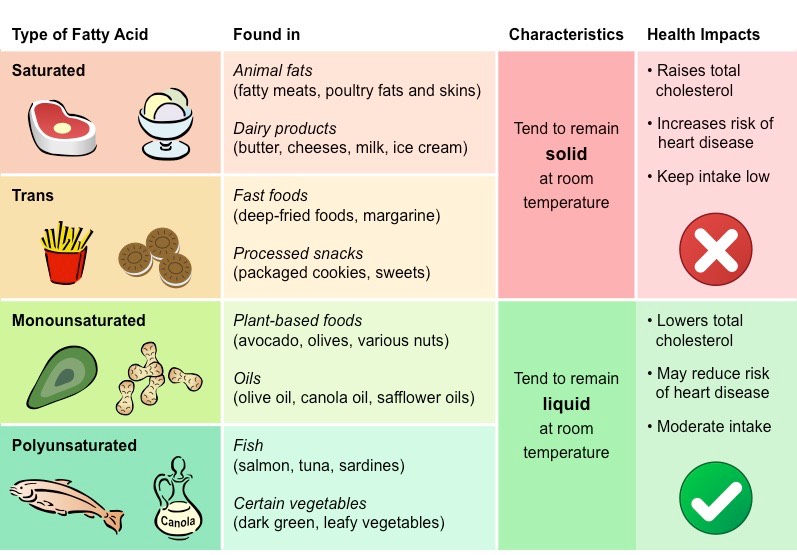
Fatty acids that possess no double bonds are saturated (have maximum number of H atoms)
Saturated fatty acids are linear in structure, originate from animal sources (i.e. fats) and are typically solid at room temperature
Fatty acids with double bonds are unsaturated – either monounsaturated (1 double bond) or polyunsaturated (>1 double bond)
Unsaturated fatty acids are bent in structure, originate from plant sources (i.e. oils) and are typically liquid at room temperatures
Unsaturated fatty acids may occur in two distinct structural configurations – cis and trans isomers
Cis: The hydrogen atoms attached to the carbon double bond are on the same side
Trans: The hydrogen atoms attached to the carbon double bond are on different sides
Trans fatty acids do not commonly occur in nature and are typically produced by an industrial process called hydrogenation
Trans fatty acids are generally linear in structure (despite being unsaturated) and are usually solid at room temperature
Types of Fatty Acid Configurations
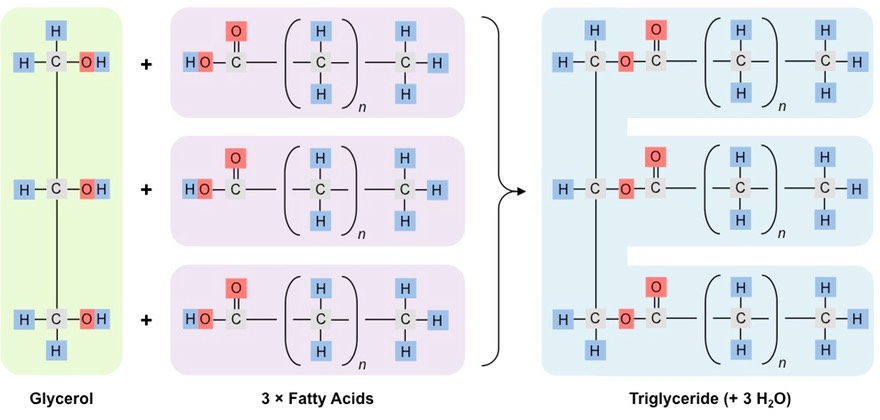
Triglycerides are the largest class of lipids and function primarily as long-term energy storage molecules
Animals tend to store triglycerides as fats (solid), while plants tend to store triglycerides as oils (liquid)
Triglycerides are formed when condensation reactions occur between one glycerol and three fatty acids
The hydroxyl groups of glycerol combine with the carboxyl groups of the fatty acids to form an ester linkage
This condensation reaction results in the formation of three molecules of water
Triglycerides can be either saturated or unsaturated, depending on the composition of the fatty acid chains
Formation of a Triglyceride
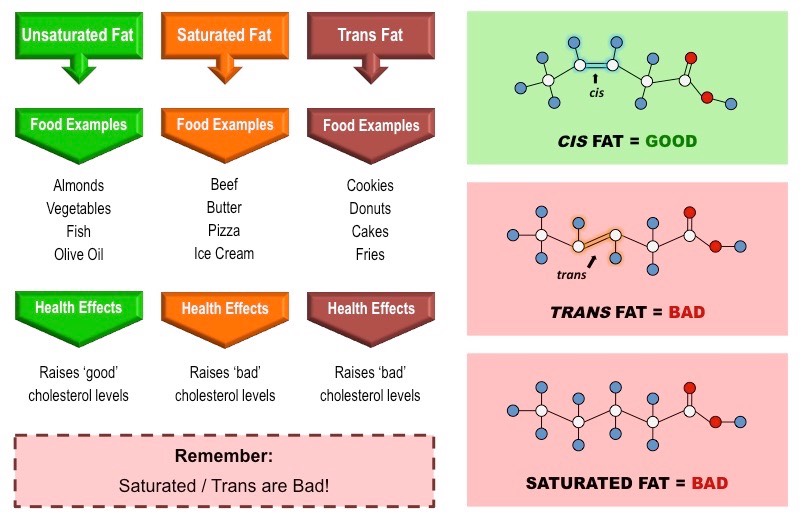
Types of Fats
Whilst all types of fats consumed as part of dietary intake will cause adverse health effects if taken in excessive amounts, some types of fats are associated with increased health risks
The mix of fats in the diet influences the level of cholesterol in the bloodstream
Saturated fats and trans fats raise blood cholesterol levels, while (cis) unsaturated fats lower blood cholesterol levels
Comparison of Main Types of Fatty Acids
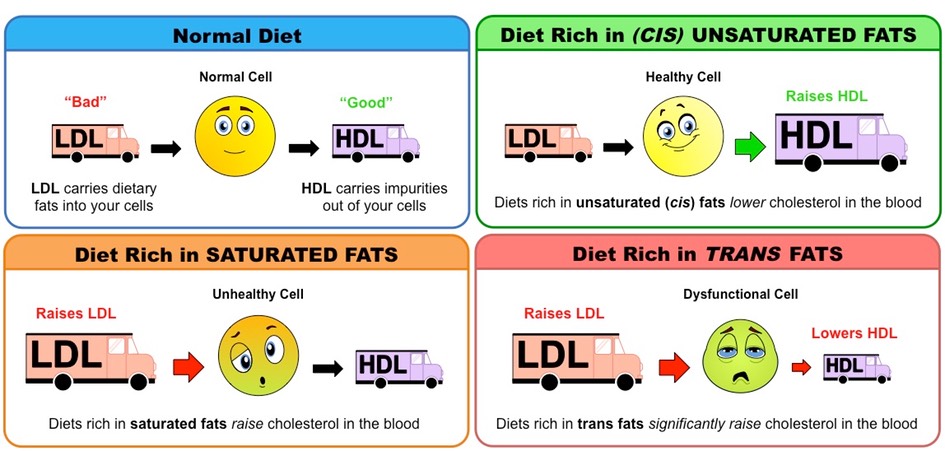
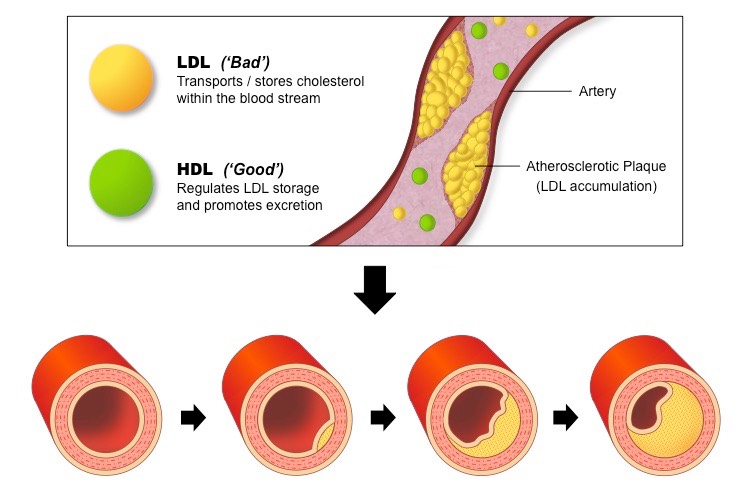
Regulating Blood Cholesterol Levels
Fats and cholesterol cannot dissolve in blood and are consequently packaged with proteins (to form lipoproteins) for transport
Low density lipoproteins (LDL) carry cholesterol from the liver to the rest of the body
High density lipoproteins (HDL) scavenge excess cholesterol and carry it back to the liver for disposal
Hence LDLs raise blood cholesterol levels (‘bad’) while HDLs lower blood cholesterol levels (‘good’)
High intakes of certain types of fats will differentially affect cholesterol levels in the blood
Saturated fats increase LDL levels within the body, raising blood cholesterol levels
Trans fats increase LDL levels and decrease HDL levels within the body, significantly raising blood cholesterol levels
Unsaturated (cis) fats increase HDL levels within the body, lowering blood cholesterol levels
Effect of Different Types of Fats on Cholesterol Levels
Health Risks of High Cholesterol
High cholesterol levels in the bloodstream lead to the hardening and narrowing of arteries (atherosclerosis)
When there are high levels of LDL in the bloodstream, the LDL particles will form deposits in the walls of the arteries
The accumulation of fat within the arterial walls lead to the development of plaques which restrict blood flow
If coronary arteries become blocked, coronary heart disease (CHD) will result – this includes heart attacks and strokes
Role of Lipoproteins in the Development of Atherosclerosis
Lipid Health Claims
There are two main health claims made about lipids in the diet:
Diets rich in saturated fats and trans fats increase the risk of CHD
Diets rich in monounsaturated and polyunsaturated (cis) fats decrease the risk of CHD
These health claims are made based on evidence collected in a number of ways:
Epidemiological studies comparing different population groups
Intervention studies that monitor cohorts following dietary modifications
Experimental designs utilising animal models or data based on autopsies
Evidence Supporting Health Claims
A positive correlation has been found between the intake of saturated fats and the incidence of CHD in human populations
Counter: Certain populations do not fit this trend (e.g. the Maasai tribe in Africa have a fat-rich diet but very low rates of CHD)
Intervention studies have shown that lowering dietary intakes of saturated fats reduces factors associated with the development of CHD (e.g. blood cholesterol levels, blood pressure, etc.)
Counter: Validity of intervention studies is dependent on size and composition of cohort, as well as the duration of the study
In patients who died from CHD, fatty deposits in diseased arteries were found to contain high concentrations of trans fats
Counter: Genetic factors may play a role (e.g. blood cholesterol levels only show a weak association to dietary levels)
Evidence Against Health Claims
Proportion of saturated and trans fats in Western diets has decreased over the last 50 years, but incidence of CHD has risen
Counter: Increased carbohydrate intake may cause detrimental health effects associated with CHD (e.g. diabetes, obesity)
Counter: Incidence of CHD dependent on a myriad of factors besides dietary intake (e.g. exercise, access to health care, etc.)
Summary of Types of Dietary Fats
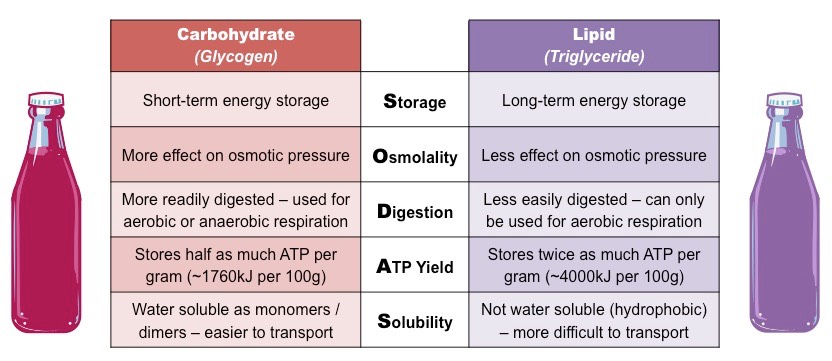
Lipids and carbohydrates both function as energy storage molecules in humans, however differ in several key aspects:
Storage (lipids are more suitable for long-term energy storage)
Osmolality (lipids have less of an effect on the osmotic pressure of a cell)
Digestion (carbohydrates are easier to digest and utilise)
ATP Yield (lipids store more energy per gram)
Solubility (carbohydrates are easier to transport in the bloodstream)
Mnemonic: SODAS
Energy Storage Comparison (Carbohydrates vs Lipids)
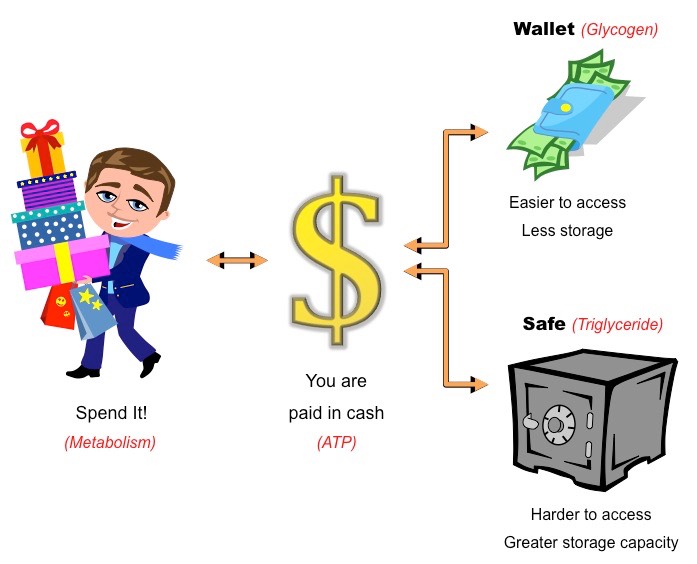
Energy Storage Analogy
ATP is the energy currency of the cell – in this respect it is akin to cash
Cash is earned when you work (cell respiration) and can be spent in a number of ways (metabolism)
Storing energy as carbohydrates (i.e. glycogen) is similar to keeping the cash in a wallet
It is easier to carry around (monosaccharides and disaccharides are water soluble)
It is readily accessible (carbohydrates are easier to digest)
You cannot carry as much (carbohydrates store less energy per gram)
Storing energy as lipids (i.e. triglycerides) is similar to keeping the cash in a safe
It is not viable to carry around (triglycerides are insoluble in water)
It is harder to access (triglycerides cannot be easily digested)
You can keep more cash in it (triglycerides store more energy per gram)
Energy Storage Analogy (Carbohydrates vs Lipids)
The body mass index (BMI) provides a measure of relative mass based on the weight and height of the individual
It is commonly used as a screening tool to identify potential weight problems in sedentary adults
Body mass index can be calculated according to the following formula:
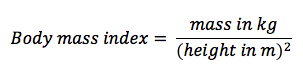
BMI ranges from underweight to obese, according to predetermined values based on an average adult population
BMI values are not a valid indicator for pregnant women or professional athletes with atypical muscle / fat ratios
BMI calculations should not be used as a diagnostic tool and should be used in conjunction with other measurements
Standard Adult BMI Categories
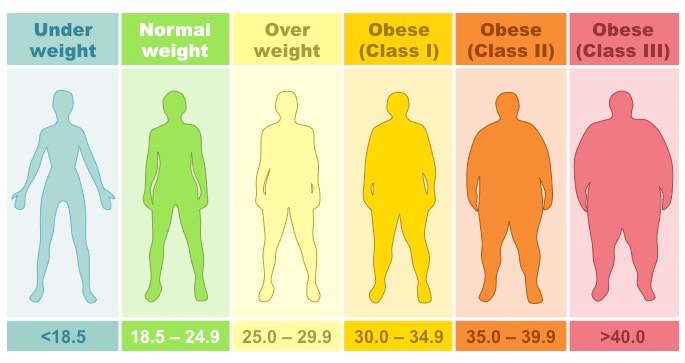
Nomograms
An alternative way of calculating body mass index is by using an alignment chart (nomogram)
Nomograms display height and weight on perpendicular axes and then assign BMI values to colour coded regions
BMI Nomogram for Typical Adult
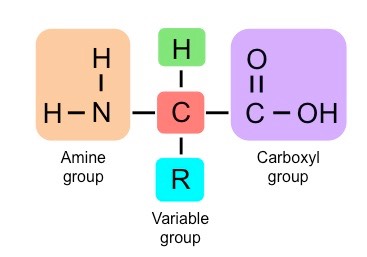
Proteins are comprised of long chains of recurring monomers called amino acids
Amino acids all share a common basic structure, with a central carbon atom bound to:
An amine group (NH2)
A carboxylic acid group (COOH)
A hydrogen atom (H)
A variable side chain (R)
Structure of a Generalised Amino Acid
There are 20 different amino acids which are universal to all living organisms
A further two – selenocysteine and pyrrolysine – are modified variants found only in certain organisms
Amino acids are joined together on the ribosome to form long chains called polypeptides, which make up proteins
Each type of amino acid differs in the composition of the variable side chain
These side chains will have distinct chemical properties (e.g. charged, non-polar, etc.) and hence cause the protein to fold and function differently according to its specific position within the polypeptide chain
As most natural polypeptide chains contain between 50 – 2000 amino acid residues, organisms are capable of producing a huge range of possible polypeptides
The 20 Universal Amino Acids
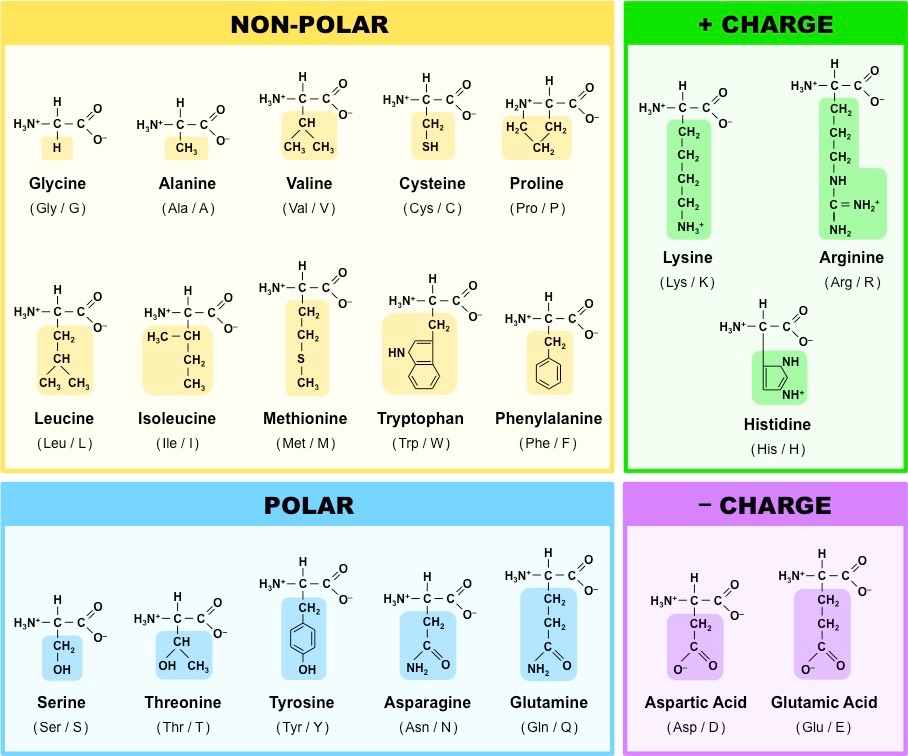
Amino acids can be covalently joined together in a condensation reaction to form a dipeptide and water
The covalent bond between the amino acids is called a peptide bond and, for this reason, long chains of covalently bonded amino acids are called polypeptides
Polypeptide chains can be broken down via hydrolysis reactions, which requires water to reverse the process
Formation of a Dipeptide
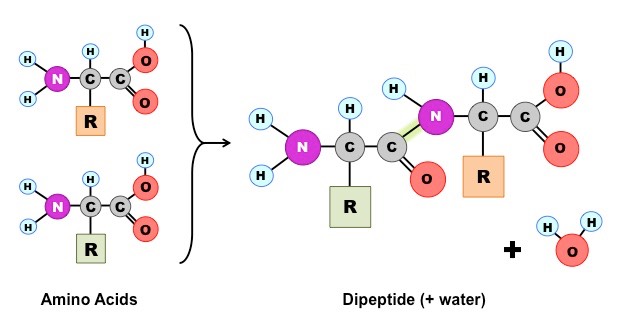
Peptide bonds are formed between the amine and carboxylic acid groups of adjacent amino acids
The amine group loses a hydrogen atom (H) and the carboxylic acid loses a hydroxyl (OH) – this forms water (H2O)
Molecular Diagram of a Peptide Bond
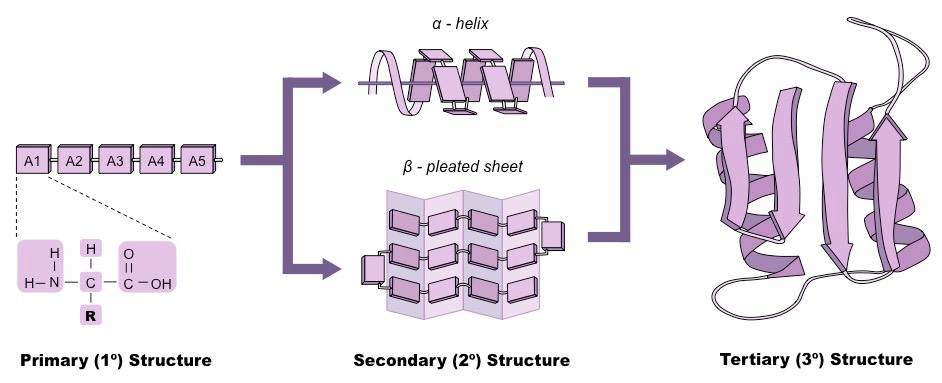
Amino acids are covalently joined via peptide bonds to form long chains called polypeptides
The order of the amino acid sequence is called the primary structure and determines the way the chain will fold
Different amino acid sequences will fold into different configurations due to the chemical properties of the variable side chains
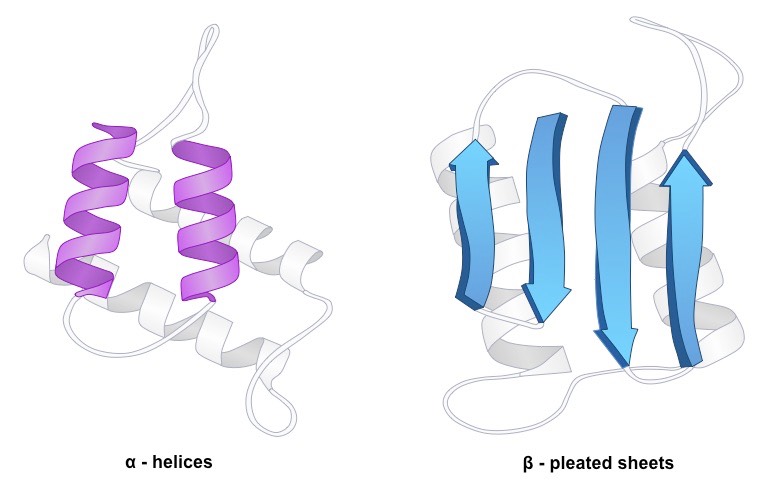
Amino acid sequences will commonly fold into two stable configurations, called secondary structures
Alpha helices occur when the amino acid sequence folds into a coil / spiral arrangement
Beta-pleated sheets occur when the amino acid sequence adopts a directionally-oriented staggered strand conformation
Both α-helices and β-pleated sheets result from hydrogen bonds forming between non-adjacent amine and carboxyl groups
Where no secondary structure exists, the polypeptide chain will form a random coil
Secondary Structure – Alpha Helices versus Beta Pleated Sheets
The overall three-dimensional configuration of the protein is referred to as the tertiary structure of the protein
The tertiary structure of a polypeptide chain will be determined by the interactions between the variable side chains
These interactions may include hydrogen bonds, disulphide bridges, ionic interactions, polar associations, etc.
The affinity or repulsion of side chains will affect the overall shape of the polypeptide chain and are determined by the position of specific amino acids within a sequence
Hence, the order of the amino acid sequence (primary structure) determines all subsequent levels of protein folding
Protein Folding: Primary → Secondary → Tertiary
Certain proteins possess a fourth level of structural organisation called a quaternary structure
Quaternary structures are found in proteins that consist of more than one polypeptide chain linked together
Alternatively, proteins may have a quaternary structure if they include inorganic prosthetic groups as part of their structure
Not all proteins will have a quaternary structure – many proteins consist of a single polypeptide chain
Quaternary Structure of a Protein
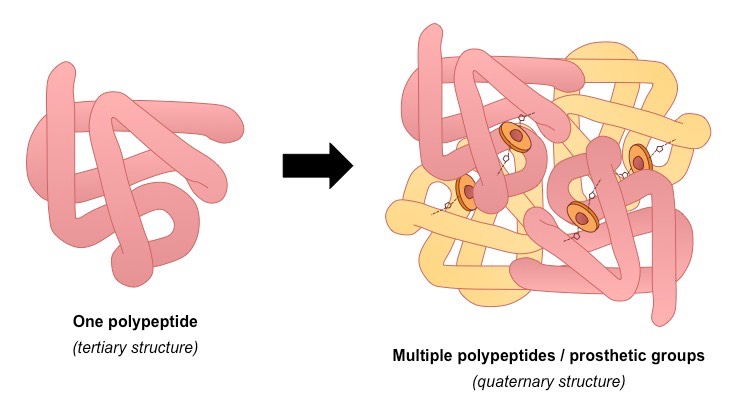
An example of a protein with a quaternary structure is haemoglobin (O2 carrying molecule in red blood cells)
Haemoglobin is composed of four polypeptide chains (two alpha chains and two beta chains)
It is also composed of iron-containing haeme groups (prosthetic groups responsible for binding oxygen)
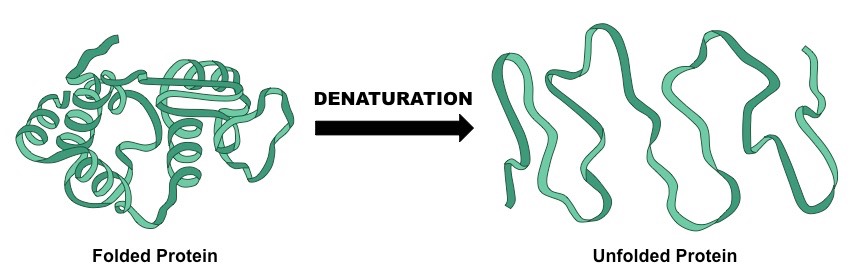
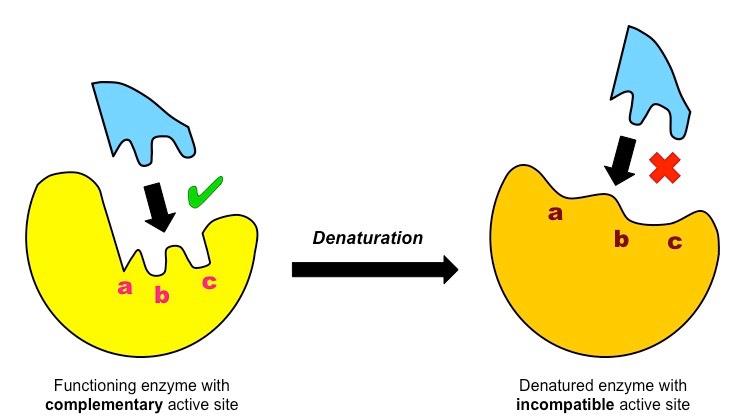
Denaturation is a structural change in a protein that results in the loss (usually permanent) of its biological properties
Because the way a protein folds determines its function, any change or abrogation of the tertiary structure will alter its activity
Denaturation of proteins can usually be caused by two key conditions – temperature and pH
Denaturation of a Protein
Temperature
High levels of thermal energy may disrupt the hydrogen bonds that hold the protein together
As these bonds are broken, the protein will begin to unfold and lose its capacity to function as intended
Temperatures at which proteins denature may vary, but most human proteins function optimally at body temperature (~37ºC)
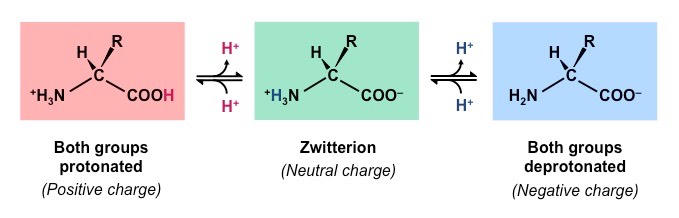
pH
Amino acids are zwitterions, neutral molecules possessing both negatively (COO–) and positively (NH3+) charged regions
Changing the pH will alter the charge of the protein, which in turn will alter protein solubility and overall shape
All proteins have an optimal pH which is dependent on the environment in which it functions (e.g. stomach proteins require an acidic environment to operate, whereas blood proteins function best at a neutral pH)
Effect of pH on Protein Structure
A gene is a sequence of DNA which encodes a polypeptide sequence
A gene sequence is converted into a polypeptide sequence via two processes:
Transcription – making an mRNA transcript based on a DNA template (occurs within the nucleus)
Translation – using the instructions of the mRNA transcript to link amino acids together (occurs at the ribosome)
Typically, one gene will code for one polypeptide – however there are exceptions to this rule:
Genes may be alternatively spliced to generate multiple polypeptide variants
Genes encoding tRNA sequences are transcribed but never translated
Genes may be mutated (their base sequence is changed) and consequently produce an alternative polypeptide sequence
The ‘One Gene – One Polypeptide’ Rule
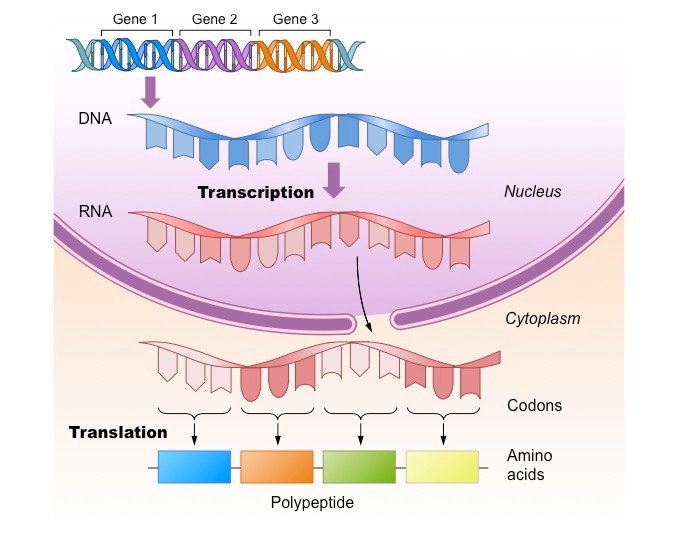
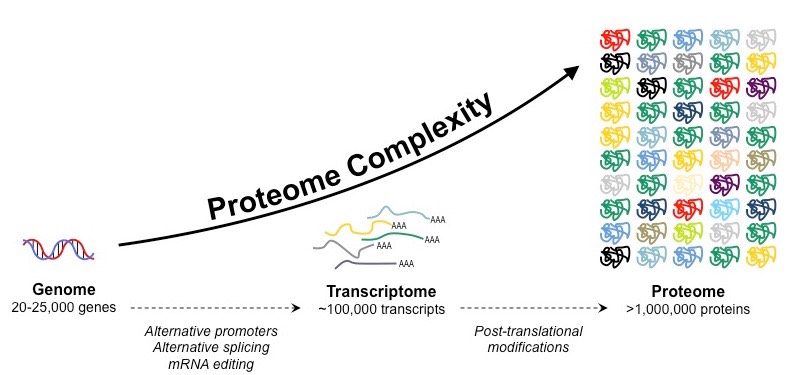
The proteome is the totality of proteins expressed within a cell, tissue or organism at a certain time
The proteome of any given individual will be unique, as protein expression patterns are determined by an individual’s genes
The proteome is always significantly larger than the number of genes in an individual due to a number of factors:
Gene sequences may be alternatively spliced following transcription to generate multiple protein variants from a single gene
Proteins may be modified (e.g. glycosylated, phosphorylated, etc.) following translation to promote further variations
Formation of the Proteome
Proteins are a very diverse class of compounds and may serve a number of different roles within a cell, including:

Structure – e.g. collagen, spider silk
Hormones – e.g. insulin, glucagon
Immunity – e.g. immunoglobulins
Transport – e.g. haemoglobin
Sensation – e.g. rhodopsin
Movement – e.g. actin, myosin
Enzymes – e.g. Rubisco, catalase
Mnemonic: SHITS ME
The following are specific examples of the different functions of proteins:
Structure
Collagen: A component of the connective tissue of animals (most abundant protein in mammals)
Spider silk: A fiber spun by spiders and used to make webs (by weight, is stronger than kevlar and steel)
Hormones
Insulin: Protein produced by the pancreas and triggers a reduction in blood glucose levels
Glucagon: Protein produced by the pancreas that triggers an increase in blood glucose levels
Immunity
Immunoglobulins: Antibodies produced by plasma cells that are capable of targeting specific antigens
Transport
Haemoglobin: A protein found in red blood cells that is responsible for the transport of oxygen
Cytochrome: A group of proteins located in the mitochondria and involved in the electron transport chain
Sensation
Rhodopsin: A pigment in the photoreceptor cells of the retina that is responsible for the detection of light
Movement
Actin: Thin filaments involved in the contraction of muscle fibres
Myosin: Thick filaments involved in the contraction of muscle fibres
Enzymes
Rubisco: An enzyme involved in the light independent stage of photosynthesis
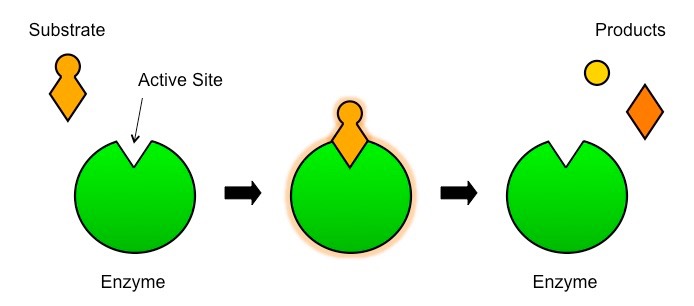
An enzyme is a globular protein which acts as a biological catalyst by speeding up the rate of a chemical reaction
Enzymes are not changed or consumed by the reactions they catalyse and thus can be reused
Enzymes are typically named after the molecules they react with (called the substrate) and end with the suffix ‘-ase’
For example, lipids are broken down by the enzyme lipase
Active Site
The active site is the region on the surface of the enzyme which binds to the substrate molecule
The active site and the substrate complement each other in terms of both shape and chemical properties
Hence only a specific substrate is capable of binding to a particular enzyme’s active site
Enzymes and Substrates
Enzyme reactions typically occur in aqueous solutions (e.g. cytoplasm, interstitial fluid, etc.)
Consequently, the substrate and enzyme are usually moving randomly within the solution (Brownian motion)
Sometimes an enzyme may be fixed in position (e.g. membrane-bound) – this serves to localise reactions to particular sites
Enzyme Catalysis
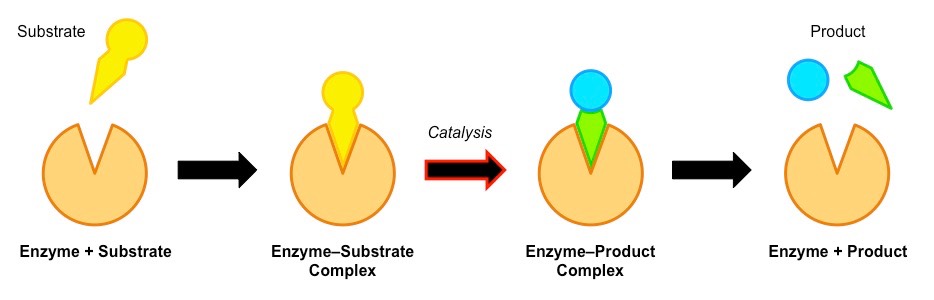
Enzyme catalysis requires that the substrate be brought into close physical proximity with the active site
When a substrate binds to the enzyme’s active site, an enzyme-substrate complex is formed
The enzyme catalyses the conversion of the substrate into product, creating an enzyme-product complex
The enzyme and product then dissociate – as the enzyme was not consumed, it can continue to catalyse further reactions
Enzyme-Substrate Interactions
Collision Frequency
The rate of enzyme catalysis can be increased by improving the frequency of collisions via:
Increasing the molecular motion of the particles (thermal energy can be introduced to increase kinetic energy)
Increasing the concentration of particles (either substrate or enzyme concentrations)
All enzymes possess an indentation or cavity to which the substrate can bind with high specificity – this is the active site
The shape and chemical properties of the active site are highly dependent on the tertiary structure of the enzyme
Like all proteins, enzyme structure can be modified by external factors such as high temperatures and extreme pH
These factors disrupt the chemical bonds which are necessary to maintain the tertiary structure of the enzyme
Any change to the structure of the active site (denaturation) will negatively affect the enzyme’s capacity to bind the substrate
Effect of Denaturation on Enzyme Activity
Various factors may affect the activity of enzymes, by either affecting the frequency of enzyme-substrate collisions or by affecting the capacity for the enzyme and substrate to interact (e.g. denaturation)
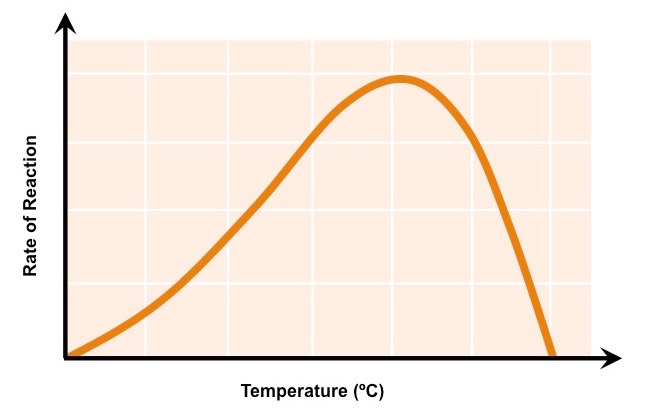
Temperature, pH and substrate concentration will all influence the rate of activity of an enzyme
Low temperatures result in insufficient thermal energy for the activation of an enzyme-catalysed reaction to proceed
Increasing the temperature will increase the speed and motion of both enzyme and substrate, resulting in higher enzyme activity
This is because a higher kinetic energy will result in more frequent collisions between the enzymes and substrates
At an optimal temperature (may vary for different enzymes), the rate of enzyme activity will be at its peak
Higher temperatures will cause enzyme stability to decrease, as the thermal energy disrupts the enzyme’s hydrogen bonds
This causes the enzyme (particularly the active site) to lose its shape, resulting in the loss of activity (denaturation)
The Effect of Temperature on Enzyme Activity
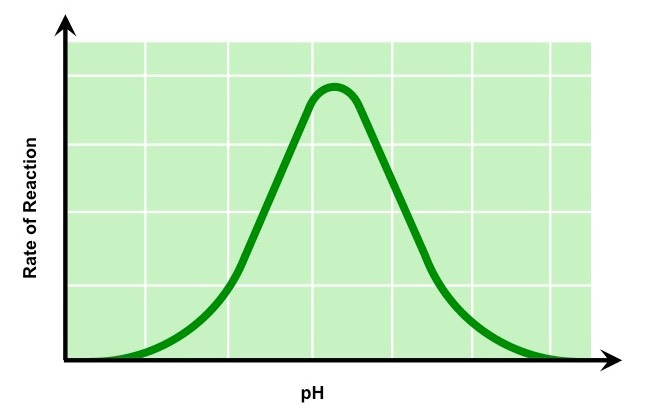
pH
Changing the pH will alter the charge of the enzyme, which in turn will alter protein solubility and overall shape
Changing the shape or charge of the active site will diminish its ability to bind the substrate, abrogating enzyme function
Enzymes have an optimal pH (may differ between enzymes) and moving outside this range diminishes enzyme activity
The Effect of pH on Enzyme Activity
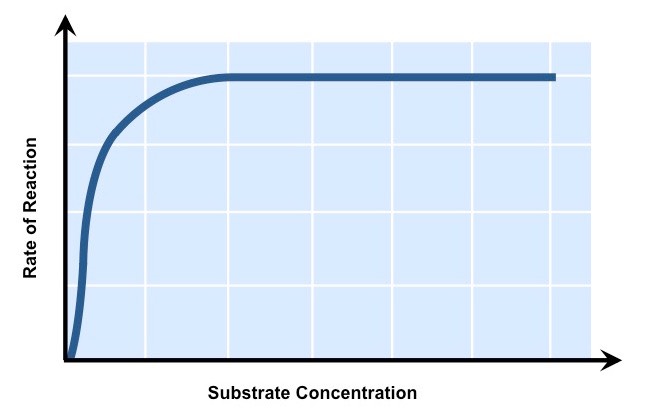
Substrate Concentration
Increasing substrate concentration will increase the activity of a corresponding enzyme
More substrates mean there is an increased chance of enzyme and substrate colliding and reacting within a given period
After a certain point, the rate of activity will cease to rise regardless of any further increases in substrate levels
This is because the environment is saturated with substrate and all enzymes are bound and reacting (Vmax)
The Effect of Substrate Concentration on Enzyme Activity
When designing an experiment to test the effect of factors affecting enzyme activity, the three key decisions to be made are:
Which factor to investigate (i.e. the independent variable)
Which enzyme / substrate reaction to use
How to measure the enzyme activity (i.e. the dependent variable)
Choosing the Independent Variable
The main factors which will affect the activity of an enzyme on a given substrate are:
Temperature (use water baths to minimise fluctuations)
pH (acidic or alkaline solutions)
Substrate concentration (choose range to avoid saturation)
Presence of inhibitor (type of inhibitor will be enzyme-specific)
Selecting an Enzyme and Substrate
Selection will depend on availability within the school, however certain enzymes can be extracted from common food sources
Examples of common enzyme-catalysed reactions include:
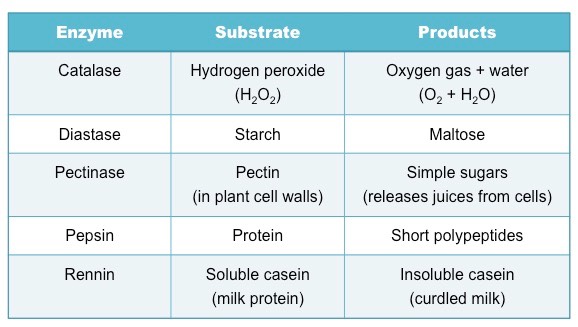
Measuring Enzyme Activity
The method of data collection will depend on the reaction occurring – typically most reactions are measured according to:
The amount / rate of substrate decomposition (e.g. breakdown of starch)
The amount / rate of product formation (e.g. formation of maltose)
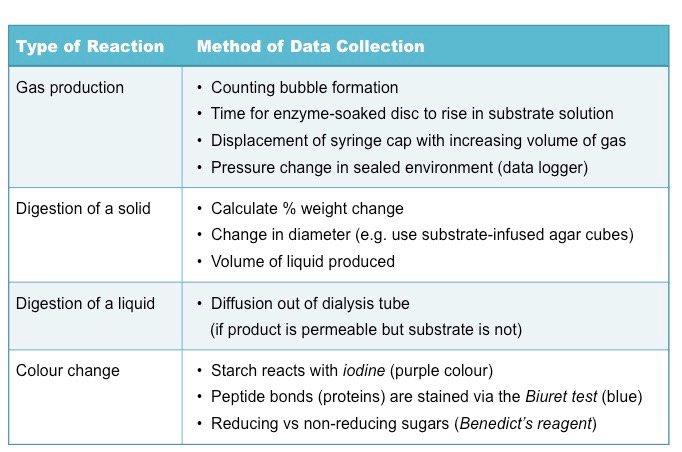
Key things to consider when conducting an experimental investigation into a factor affecting enzyme activity include:
What is an appropriate range of values to select for your independent variable?
Have you chosen a sufficient time period for the reaction to proceed?
Have you identified, and controlled, all relevant extraneous variables?
Can you include a negative control condition (no enzyme) to establish baseline readings?
Can you include a positive control condition to confirm enzyme activity?
Is it possible to treat the enzyme with the independent variable before mixing with the substrate?
Does the data collection method allow for sufficient precision in detecting changes to levels of product / substrate?
Have all appropriate safety precautions been taken when handling relevant substances?
Immobilised enzymes have been fixed to a static surface in order to improve the efficiency of the catalysed reaction
Enzyme concentrations are conserved as the enzyme is not dissolved – hence it can be retained for reuse
Separation of the product is more easily achieved as the enzyme remains attached to the static surface
Immobilised enzymes are utilised in a wide variety of industrial practices:
Biofuels – Enzymes are used to breakdown carbohydrates to produce ethanol-based fuels
Medicine – Enzymes are used to identify a range of conditions, including certain diseases and pregnancy
Biotechnology – Enzymes are involved in a number of processes, including gene splicing
Food production – Enzymes are used in the production and refinement of beers and dairy products
Textiles – Enzymes are utilised in the processing of fibres (e.g. polishing cloth)
Paper – Enzymes assist in the pulping of wood for paper production
Common Industrial Uses of Enzymes
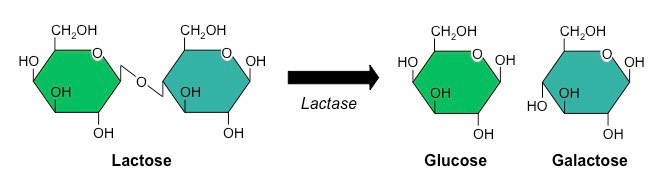
Lactose is a disaccharide of glucose and galactose which can be broken down by the enzyme lactase
Historically, mammals exhibit a marked decrease in lactase production after weaning, leading to lactose intolerance
Incidence of lactose intolerance is particularly high in Asian, African and Aboriginal populations
Incidence is lower in European populations (due to a mutation that maintains lactase production into adulthood)
Breakdown of Lactose by the Enzyme Lactase
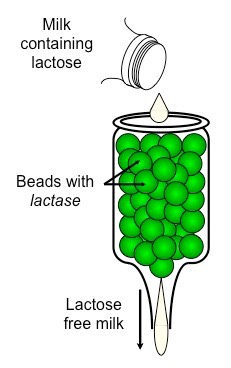
Producing Lactose-Free Milk
Lactose-free milk can be produced by treating the milk with the enzyme lactase
The lactase is purified from yeast or bacteria and then bound to an inert substance (such as alginate beads)
Milk is then repeatedly passed over this immobilised enzyme, becoming lactose-free
Scientists are currently attempting to create transgenic cows that produce lactose-free milk
This involves splicing the lactase gene into the cow’s genome so that the lactose is broken down prior to milking
Generation of Lactose-Free Milk Using Immobilised Enzymes
DNA
Advantages of Lactose-Free Dairy Products
The generation of lactose-free milk can be used in a variety of ways:
As a source of dairy for lactose-intolerant individuals
As a means of increasing sweetness in the absence of artificial sweeteners (monosaccharides are sweeter tasting)
As a way of reducing the crystallisation of ice-creams (monosaccharides are more soluble, less likely to crystalise)
As a means of reducing production time for cheeses and yogurts (bacteria ferment monosaccharides more readily)
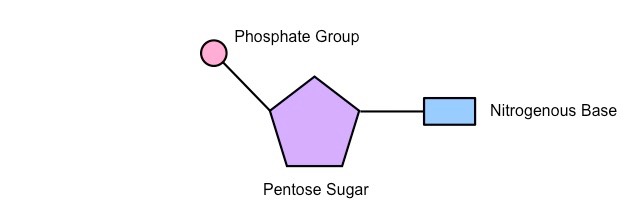
Nucleic acids are the genetic material of the cell and are composed of recurring monomeric units called nucleotides
Each nucleotide is comprised of three principal components:
5-carbon pentose sugar (pentagon)
Phosphate group (circle)
Nitrogenous base (rectangle)
Both the phosphate group and nitrogenous base are attached to the central pentose sugar
The nitrogenous base is attached to the 1’– carbon atom (right point)
The phosphate base is attached to the 5’– carbon atom (left point)
Simple Diagram of a Single Nucleotide
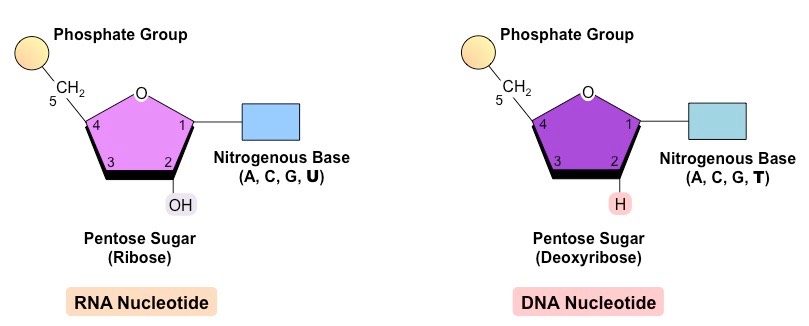
DNA (deoxyribonucleic acid) is a more stable double stranded form that stores the genetic blueprint for cells
RNA (ribonucleic acid) is a more versatile single stranded form that transfers the genetic information for decoding
Both DNA and RNA are polymers of nucleotides, however key differences exist in the composition of DNA and RNA nucleotides
Comparison of DNA and RNA Nucleotides
DNA and RNA are both polymers of nucleotides, however differ in a few key structural aspects:
Number of strands present
Composition of nitrogenous bases
Type of pentose sugar
Differences between DNA and RNA
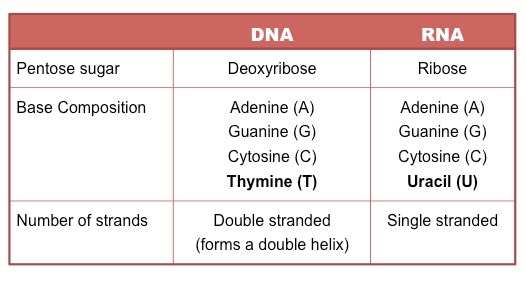
Comparison of DNA and RNA Structure
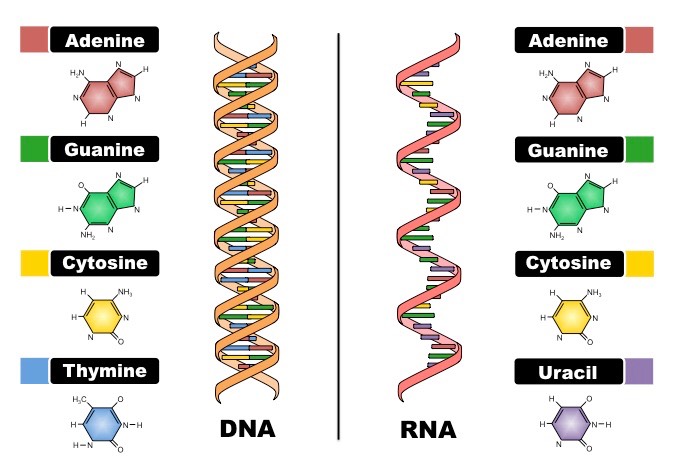
Nucleic acids are composed of nucleotide monomers which are linked into a single strand via condensation reactions
The phosphate group of one nucleotide attaches to the sugar of another nucleotide (at the 3’– hydroxyl (-OH) group)
This results in a phosphodiester bond forming between the two nucleotides (and water is produced as a by-product)
Successive condensation reactions result in the formation of long polynucleotide strands
Two polynucleotide chains of DNA are held together via hydrogen bonding between complementary nitrogenous bases
Adenine (A) pairs with Thymine (T) via two hydrogen bonds
Guanine (G) pairs with Cytosine (C) via three hydrogen bonds
In order for the bases to be facing each other and thus able to pair, the strands must be running in opposite directions
The two strands of DNA are described as being antiparallel
As the antiparallel chains lengthen, the atoms will organise themselves into the most stable energy configuration
This atomic arrangement results in the double-stranded DNA forming a double helix (~10 – 15 bases per twist)
Organisation of DNA
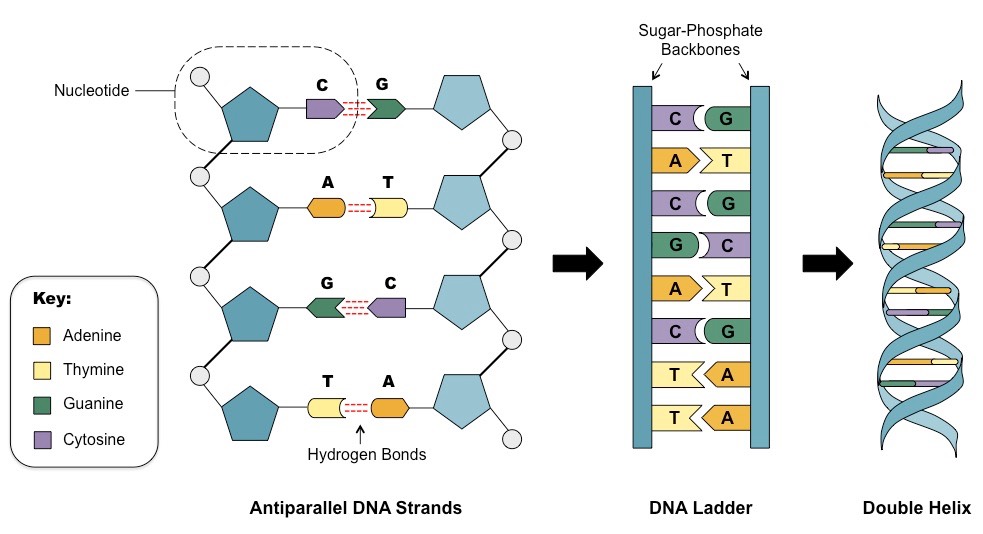
The structural organisation of the DNA molecule was correctly proposed in 1953 by James Watson and Francis Crick
These British scientists constructed models to quickly visualise and assess the viability of potential structures
Their efforts were guided by an understanding of molecular distances and bond angles developed by Linus Pauling, and were based upon some key experimental discoveries:
DNA is composed of nucleotides made up of a sugar, phosphate and base – Phoebus Levene, 1919
DNA is composed of an equal number of purines (A + G) and pyrimidines (C + T) – Erwin Chargaff, 1950
DNA is organised into a helical structure – Rosalind Franklin, 1953(data shared without permission)
Making DNA Models
Using trial and error, Watson and Crick were able to assemble a DNA model that demonstrated the following:
DNA strands are antiparallel and form a double helix
DNA strands pair via complementary base pairing (A = T ; C Ξ G)
Outer edges of bases remain exposed (allows access to replicative and transcriptional proteins)
As Watson and Crick’s model building was based on trial and error, a number of early models possessed faults:
The first model generated was a triple helix
Early models had bases on the outside and sugar-phosphate residues in the centre
Nitrogenous bases were not initially configured correctly and hence did not demonstrate complementarity
The Rosalind Franklin Controversy
The final construction of a correct DNA molecule owed heavily to the X-ray crystallography data generated by Franklin
This data confirmed the arrangement of the DNA strands into a helical structure
The data was shared without Franklin’s knowledge or permission and contributed profoundly to the final design
Hence, Franklin is now recognised as a key contributor to the elucidation of DNA structure
Watson & Crick DNA Model
(Image courtesy of Cold Spring Harbor Archives)
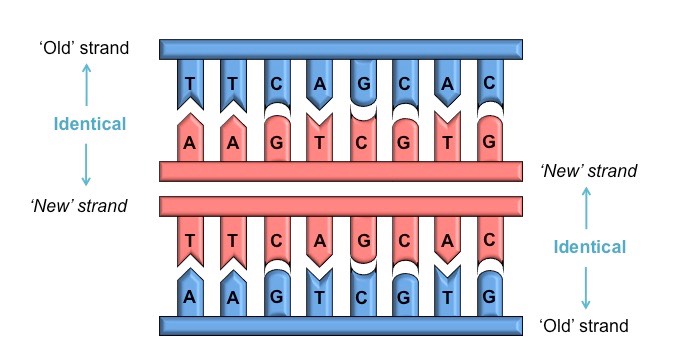
DNA replication is a semi-conservative process, because when a new double-stranded DNA molecule is formed:
One strand will be from the original template molecule
One strand will be newly synthesised
Semi-Conservative DNA Molecule

This occurs because each nitrogenous base can only pair with its complementary partner
Adenine (A) pairs with thymine (T)
Cytosine (C) pairs with guanine (G)
Consequently, when DNA is replicated by the combined action of helicase and DNA polymerase:
Each new strand formed will be identical to the original strand separated from the template
The two semi-conservative molecules formed will have an identical base sequence to the original molecule
Conservation of Sequence by Complementary Base Pairing
The theory that DNA replication was semi-conservative was confirmed by the Meselson-Stahl experiment in 1958
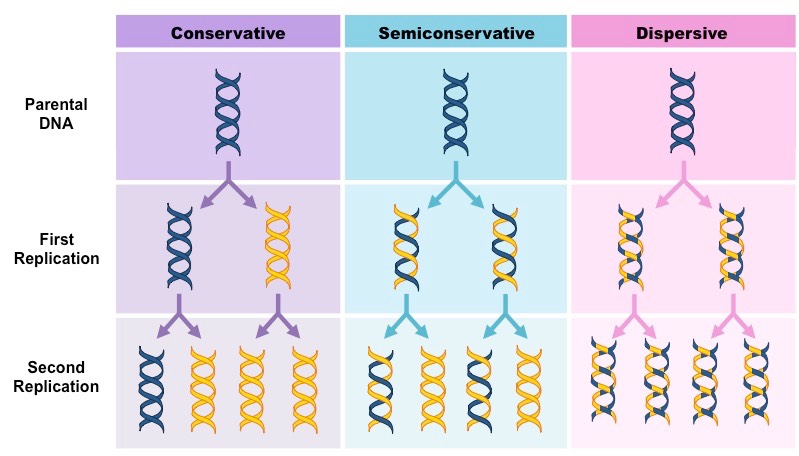
Prior to this experiment, three hypotheses had been proposed for the method of replication of DNA:
Conservative Model – An entirely new molecule is synthesised from a DNA template (which remains unaltered)
Semi-Conservative Model – Each new molecule consists of one newly synthesised strand and one template strand
Dispersive Model – New molecules are made of segments of new and old DNA
Three Proposed Models of DNA Replication
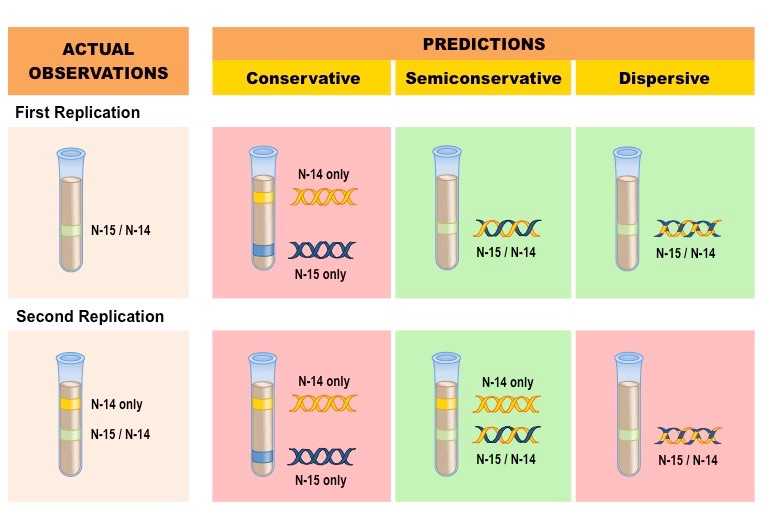
Meselson and Stahl were able to experimentally test the validity of these three models using radioactive isotopes of nitrogen
Nitrogen is a key component of DNA and can exist as a heavier 15N or a lighter 14N
DNA molecules were prepared using the heavier 15N and then induced to replicate in the presence of the lighter 14N
DNA samples were then separated via centrifugation to determine the composition of DNA in the replicated molecules
The results after two divisions supported the semi-conservative model of DNA replication
After one division, DNA molecules were found to contain a mix of 15N and 14N, disproving the conservative model
After two divisions, some molecules of DNA were found to consist solely of 14N, disproving the dispersive model
Results of the Meselson-Stahl Experiment
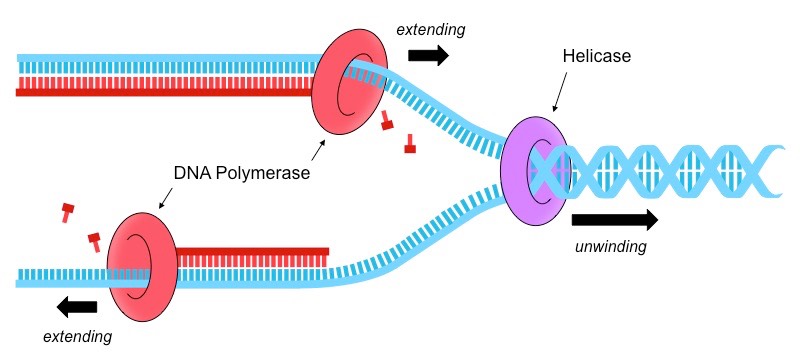
DNA replication is a semi-conservative process whereby pre-existing strands act as templates for newly synthesised strands
The process of DNA replication is coordinated by two key enzymes – helicase and DNA polymerase
Helicase
Helicase unwinds the double helix and separates the two polynucleotide strands
It does this by breaking the hydrogen bonds that exist between complementary base pairs
The two separated polynucleotide strands will act as templates for the synthesis of new complementary strands
DNA Polymerase
DNA polymerase synthesises new strands from the two parental template strands
Free deoxynucleoside triphosphates (nucleotides with 3 phosphate groups) align opposite their complementary base partner
DNA polymerase cleaves the two excess phosphates and uses the energy released to link the nucleotide to the new strand
DNA Replication Summary
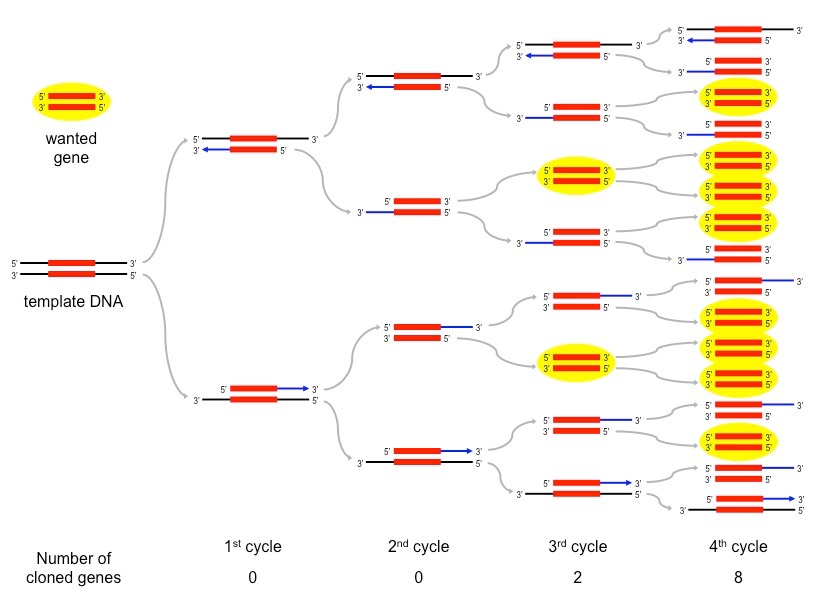
The polymerase chain reaction (PCR) is an artificial method of replicating DNA under laboratory conditions
The PCR technique is used to amplify large quantities of a specific sequence of DNA from an initial minute sample
Each reaction doubles the amount of DNA – a standard PCR sequence of 30 cycles creates over 1 billion copies (230)
The reaction occurs in a thermal cycler and uses variations in temperature to control the replication process via three steps:
Denaturation – DNA sample is heated (~90ºC) to separate the two strands
Annealing – Sample is cooled (~55ºC) to allow primers to anneal (primers designate sequence to be copied)
Elongation – Sample is heated to the optimal temperature for a heat-tolerant polymerase (Taq) to function (~75ºC)
Taq polymerase is an enzyme isolated from the thermophilic bacterium Thermus aquaticus
As this enzyme’s optimal temperature is ~75ºC, it is able to function at the high temperatures used in PCR without denaturing
Taq polymerase extends the nucleotide chain from the primers – therefore primers are used to select the sequence to be copied
Summary of a Single PCR Cycle
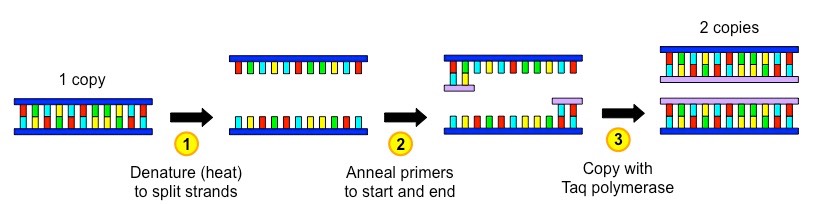
Overview of a PCR Sequence – First 4 Cycles
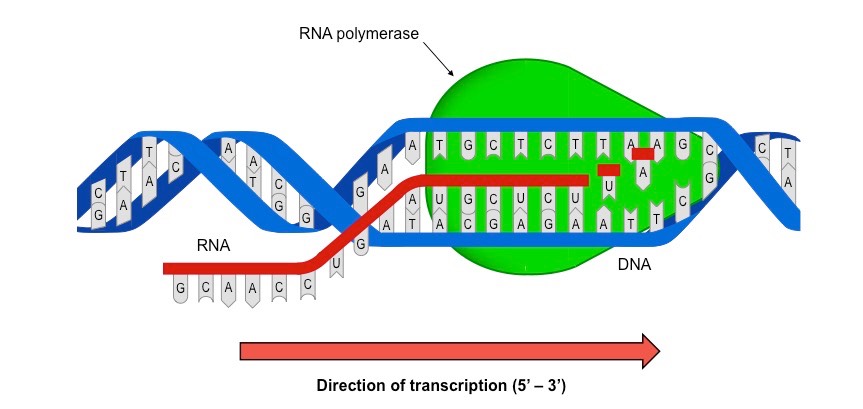
Transcription is the process by which an RNA sequence is produced from a DNA template
RNA polymerase separates the DNA strands and synthesises a complementary RNA copy from one of the DNA strands
When the DNA strands are separated, ribonucleoside triphosphates align opposite their exposed complementary base partner
RNA polymerase removes the additional phosphate groups and uses the energy from this cleavage to covalently join the nucleotide to the growing sequence
Once the RNA sequence has been synthesised, RNA polymerase detaches from the DNA molecule and the double helix reforms
The Role of RNA Polymerase in Transcription
Gene
The sequence of DNA that is transcribed into RNA is called a gene
The strand that is transcribed is called the antisensestrand and is complementary to the RNA sequence
The strand that is not transcribed is called the sensestrand and is identical to the RNA sequence (with T instead of U)
Transcription of genes occur in the nucleus (where DNA is), before the RNA moves to the cytoplasm (for translation)
Codons
The base sequence of an mRNA molecule encodes the production of a polypeptide
The mRNA sequence is read by the ribosome in triplets of bases called codons
Each codon codes for one amino acid with a polypeptide chain
The order of the codons in an mRNA sequence determines the order of amino acids in a polypeptide chain
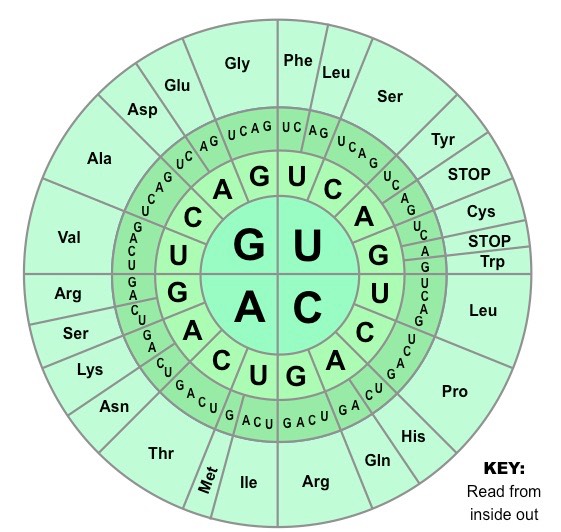
Genetic Code
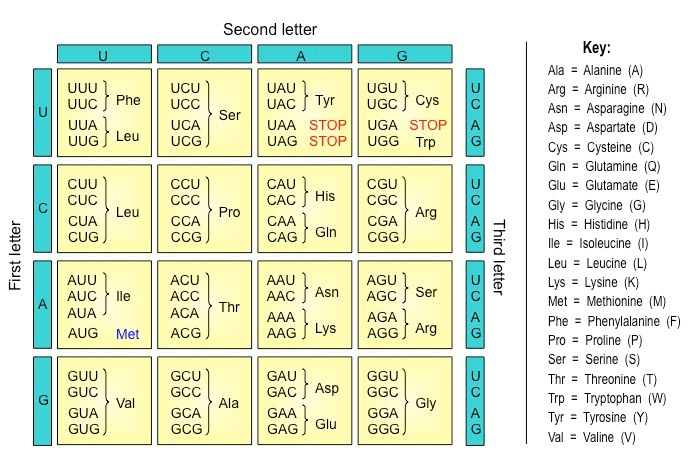
The genetic code is the set of rules by which information encoded within mRNA sequences is converted into amino acid sequences (polypeptides) by living cells
The genetic code identifies the corresponding amino acid for each codon combination
As there are four possible bases in a nucleotide sequence, and three bases per codon, there are 64 codon possibilities (43)
The coding region of an mRNA sequence always begins with a START codon (AUG) and terminates with a STOP codon
Typically the genetic code shows the codon combinations expressed on an mRNA molecule
Tables displaying the genetic code may occasionally show the sequence on the sense strand of DNA (non-coding strand)
These sequences are identical to the mRNA codons with the exception of thymine (T) being present instead of uracil (U)
The Genetic Code (Wheel)
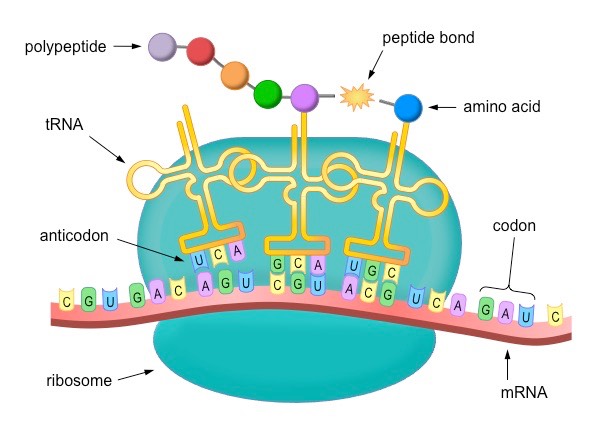
Translation is the process of protein synthesis in which the genetic information encoded in mRNA is translated into a sequence of amino acids on a polypeptide chain
Ribosomes bind to mRNA in the cytoplasm and move along the molecule in a 5’ – 3’ direction until it reaches a start codon (AUG)
Anticodons on tRNA molecules align opposite appropriate codons according to complementary base pairing (e.g. AUG = UAC)
Each tRNA molecule carries a specific amino acid (according to the genetic code)
Ribosomes catalyse the formation of peptide bonds between adjacent amino acids (via condensation reactions)
The ribosome moves along the mRNA molecule synthesising a polypeptide chain until it reaches a stop codon
At this point translation ceases and the polypeptide chain is released
Overview of Translation
Translation Mnemonic
The key components of translation are:
Messenger RNA (goes to…)
Ribosome (reads sequence in …)
Codons (recognised by …)
Anticodons (found on …)
Transfer RNA (which carries …)
Amino acids (which join via …)
Peptide bonds (to form …)
Polypeptides
The genetic code is universal – almost every living organism uses the same code (there are a few rare and minor exceptions)
As the same codons code for the same amino acids in all living things, genetic information is transferrable between species
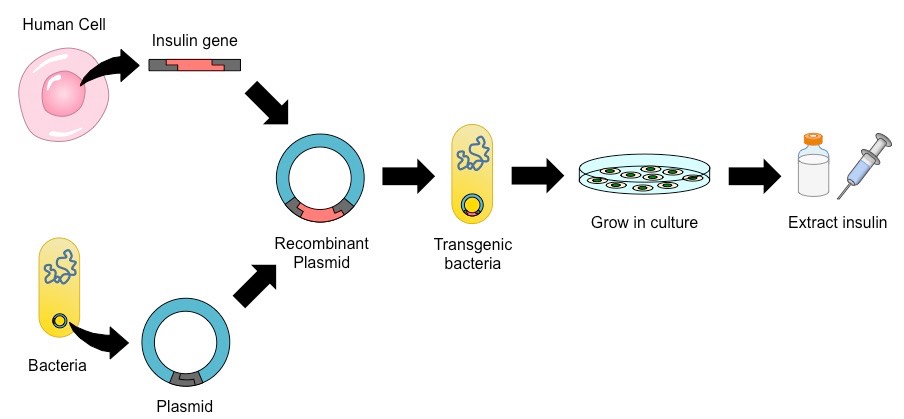
The ability to transfer genes between species has been utilised to produce human insulin in bacteria (for mass production)
The gene responsible for insulin production is extracted from a human cell
It is spliced into a plasmid vector (for autonomous replication and expression) before being inserted into a bacterial cell
The transgenic bacteria (typically E. coli) are then selected and cultured in a fermentation tank (to increase bacterial numbers)
The bacteria now produce human insulin, which is harvested, purified and packaged for human use (i.e. by diabetics)
Insulin Production via Recombinant Gene Transfer
mRNA → DNA
mRNA is a complementary copy of a DNA segment (gene) and consequently can be used to deduce the gene sequence
For converting a sequence from mRNA to the original DNA code, apply the rules of complementary base pairing:
Cytosine (C) is replaced with Guanine (G) – and vice versa
Uracil (U) is replaced by Adenine (A)
Adenine (A) is replaced by Thymine (T)
Example:(mRNA) AUG CCA GUG ACU UCA GGG ACG AAU GAC UUA
Answer:(DNA) TAC GGT CAC TGA AGT CCC TGC TTA CTG AAT
mRNA → Polypeptide
In order to translate an mRNA sequence into a polypeptide chain, it is important to establish the correct reading frame
The mRNA transcript is organised into triplets of bases called codons, and as such three different reading frames exists
An open reading frame starts with AUG and will continue in triplets to a termination codon
A blocked reading frame may be frequently interrupted by termination codons
Once the start codon (AUG) has been located and reading frame established, the corresponding amino acid sequence can be deduced using the genetic code
Example: (mRNA) GUAUGCACGUGACUUUCCUCAUGAGCUGAU
Answer:(codons) GU AUG CAC GUG ACU UUC CUC AUG AGC UGA U
Answer:(amino acid) Met His Val Thr Phe Leu Met Ser STOP
The Genetic Code (Grid)
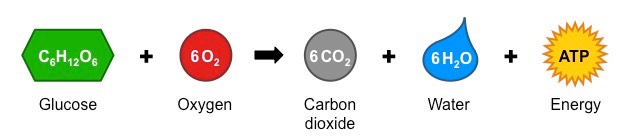
Cell respiration is the controlled release of energy from organic compounds to produce ATP
The main organic compound used for this process is carbohydrates (glucose), although lipids and proteins can also be digested
There are two main types of cell respiration:
Anaerobic respiration involves the partial breakdown of glucose in the cytosol for a small yield of ATP
Aerobic respiration utilises oxygen to completely break down glucose in the mitochondria for a larger ATP yield
Cell Respiration Equation (Complete Breakdown)
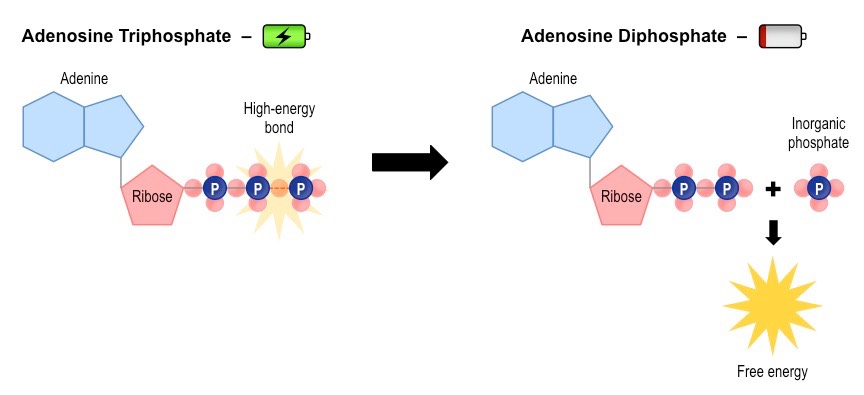
ATP (adenosine triphosphate) is a high energy molecule that functions as an immediate source of power for cell processes
One molecule of ATP contains three covalently linked phosphate groups – which store potential energy in their bonds
When ATP is hydrolysed (to form ADP + Pi) the energy stored in the phophate bond is released to be used by the cell
Cell respiration uses energy stored in organic molecules to regenerate ATP from ADP + Pi (via oxidation)
Relationship between ATP and ADP
Both anaerobic and aerobic respiration pathways begin with the anaerobic breakdown of glucose in the cytosol by glycolysis
Glycolysis breaks down glucose (6-C) into two molecules of pyruvate (3C), and also produces:
Hydrogen carriers (NADH) from an oxidised precursor (NAD+)
A small yield of ATP (net gain of 2 molecules)
Overview of Glycolysis
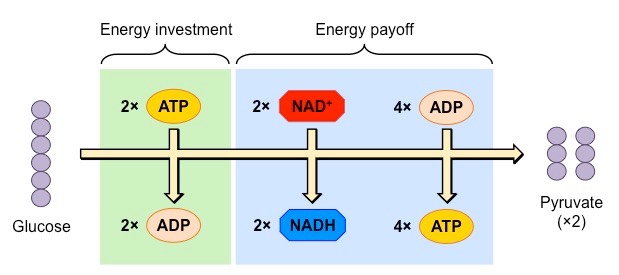
Anaerobic Respiration
Anaerobic respiration proceeds in the absence of oxygen and does not result in the production of any further ATP molecules
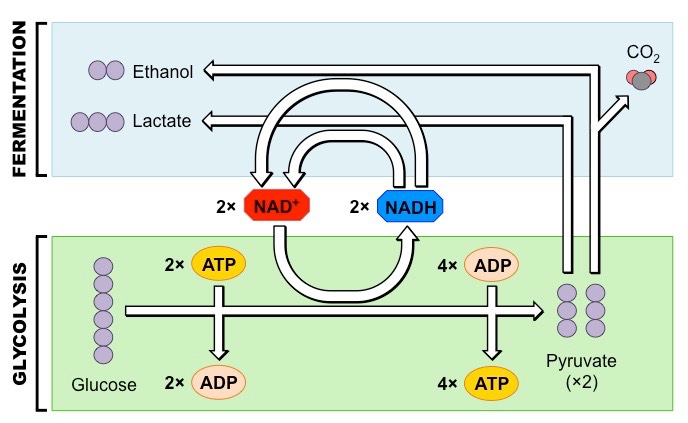
In animals, the pyruvate is converted into lactic acid (or lactate)
In plants and yeasts, the pyruvate is converted into ethanol and carbon dioxide
The purpose of anaerobic respiration is to restore stocks of NAD+ – as this molecule is needed for glycolysis
By restoring stocks of NAD+ via anaerobic pathways, the organism can continue to produce ATP via glycolysis
The conversion of pyruvate into lactic acid (animals) or ethanol and CO2 (plants / yeasts) isreversible
Hence, pyruvate levels can be restored once oxygen is present and a greater yield of ATP may be produced aerobically
Summary of Anaerobic Respiration
Muscle contractions require the expenditure of high amounts of energy and thus require high levels of ATP
When exercising at high intensity, the cells’ energy demands will exceed what the available levels of O2 can supply aerobically
Hence the body will begin breaking down glucose anaerobically to maximise ATP production
This will result in an increase in the production of lactic acid, which leads to muscle fatigue
When the individual stops exercising, oxygen levels will increase and lactate will be converted back to pyruvate
Although carbohydrates, lipids and proteins can all be consumed as energy sources, only carbohydrates will typically undergo anaerobic respiration
The Effect of Exercise Intensity on Carbohydrate Consumption (and Lactate Production)
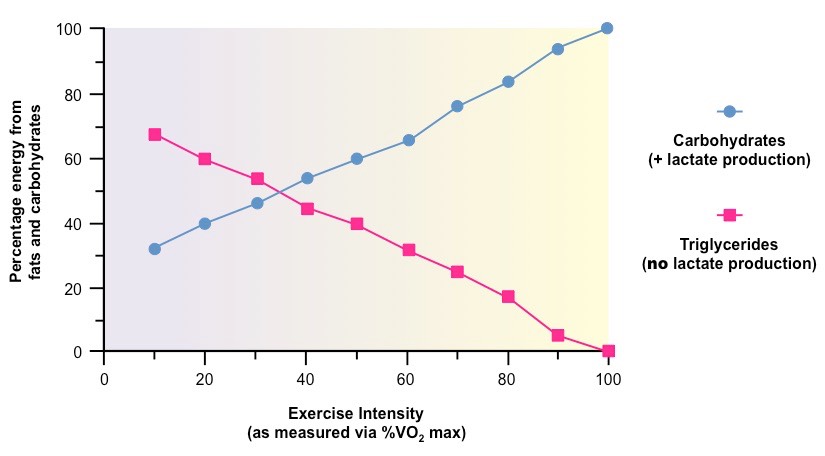
The above graph demonstrates how the conditions of cell respiration change with increasing energy demand
At high intensities, the aerobic consumption of fats is decreased while the anaerobic consumption of sugars increases
Consequently, lactate levels will increase at higher levels of exercise intensity
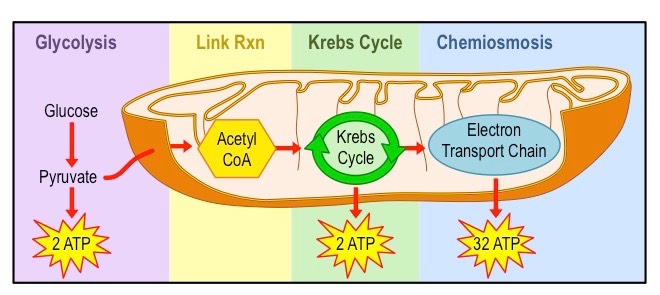
Aerobic cell respiration requires the presence of oxygen and takes place within the mitochondrion
Pyruvate is broken down into carbon dioxide and water, and a large amount of ATP is produced (~34 – 36 molecules)
Although aerobic respiration typically begins with glycolysis in carbohydrates, glycolysis itself is an anaerobic process
Aerobic respiration consists of the link reaction, citric acid cycle (or Krebs cycle) and the electron transport chain
Overview of Aerobic Respiration
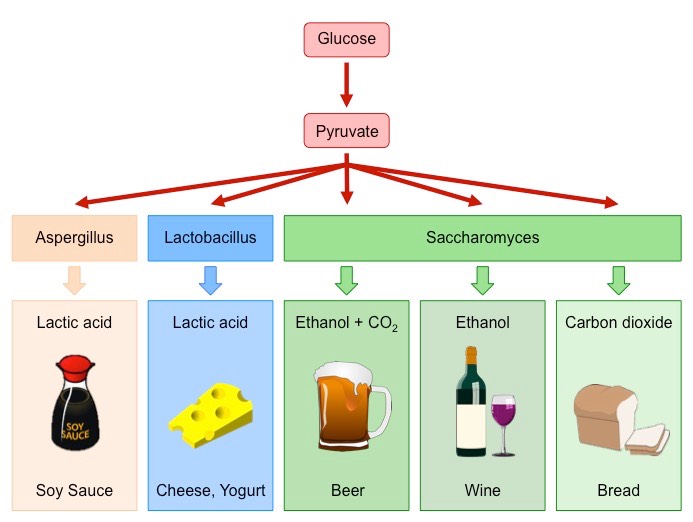
Anaerobic respiration (fermentation) involves the breakdown of carbohydrates in the absence of oxygen
In yeasts, fermentation results in the production of ethanol and carbon dioxide – which can be used in food processing:
Bread – Carbon dioxide causes dough to rise (leavening), the ethanol evaporates during baking
Alcohol – Ethanol is the intoxicating agent in alcoholic beverages (concentrations above ~14% damage the yeast)
Bacterial cultures can also undergo fermentation to produce a variety of food products
Yogurt / Cheese – Bacteria produce lactic acid anaerobically, which modifies milk proteins to generate yogurts and cheeses
Production of Fermented Foods by Bacteria and Yeast (Saccharomyces)
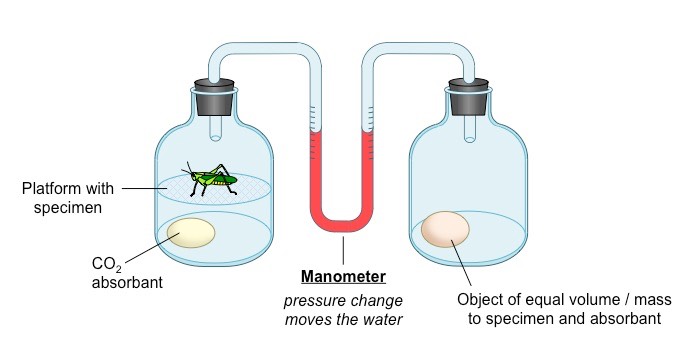
A respirometer is a device that determines an organism’s respiration rate by measuring the rate of exchange of O2 and CO2
The living specimen (e.g. germinating seeds or invertebrate organism) is enclosed in a sealed container
Carbon dioxide production can be measured with a data logger or by pH changes if the specimen is immersed in water
When an alkali is included to absorb CO2, oxygen consumption can be measured as a change in pressure within the system
The pressure change can be detected with a data logger or via use of a U-tube manometer
Factors which may affect respiration rates include temperature, hydration, light (plants), age and activity levels
An increase in carbon dioxide levels will indicate an increase in respiration (CO2 is a product of aerobic respiration)
A decrease in oxygen levels will indicate an increase in respiration (O2 is a requirement for aerobic respiration)
Schematic of a Simple Respirometer Designed to Measure Oxygen Uptake
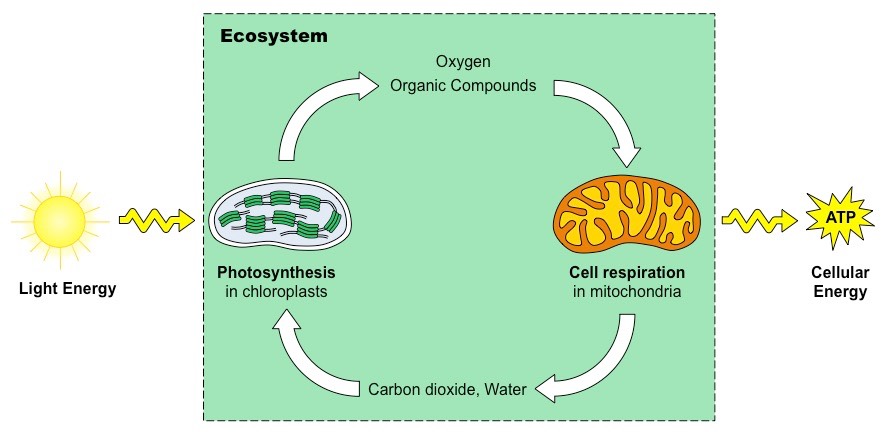
Photosynthesis is the process by which cells synthesise organic compounds (e.g. glucose) from inorganic molecules (CO2 and H2O) in the presence of sunlight
This process requires a photosynthetic pigment (chlorophyll) and can only occur in certain organisms (plants, certain bacteria)
Photosynthesis Equation

Photosynthetic organisms use the light energy from the sun to create chemical energy (ATP)
This chemical energy can either be used directly by the organism or used to synthesise organic compounds (e.g. glucose)
Animals then consume these organic compounds as food and release the stored energy via cell respiration
Photosynthesis (anabolic synthesis of organic compounds) is essentially the reverse of cell respiration (catabolic breakdown)
Relationship between Photosynthesis and Cell Respiration
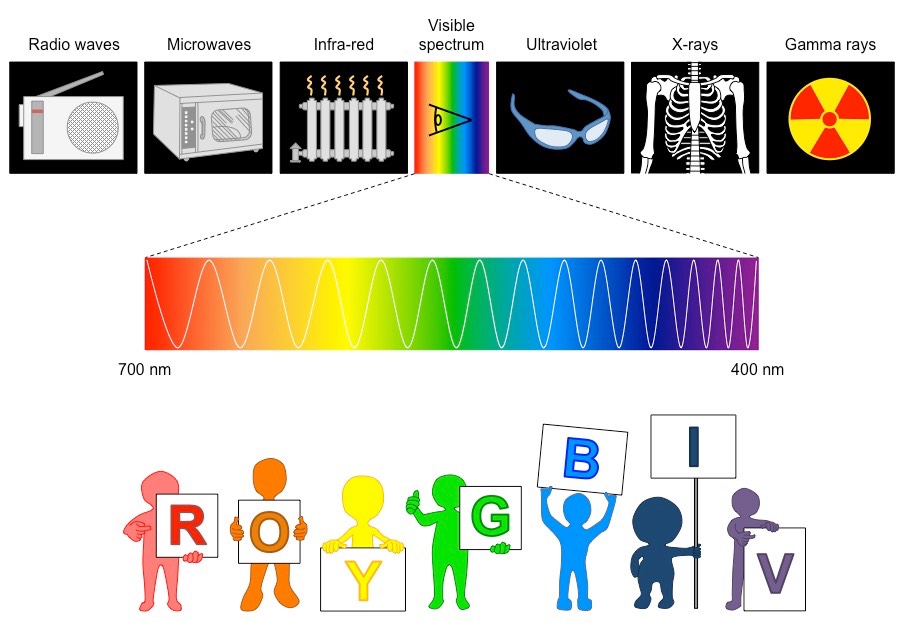
The electromagnetic spectrum is the range of all possible frequencies of electromagnetic radiation
The Sun emits its peak power in the visible region of this spectrum (white light ~ 400 – 700 nm)
Colours are different wavelengths of white light and range from red (~700 nm) to violet (~400 nm)
The colours of the visible spectrum are (from longest to shortest wavelength):
RedOrangeYellowGreenBlueIndigoViolet (Mnemonic: Roy G. Biv)
The Electromagnetic Spectrum
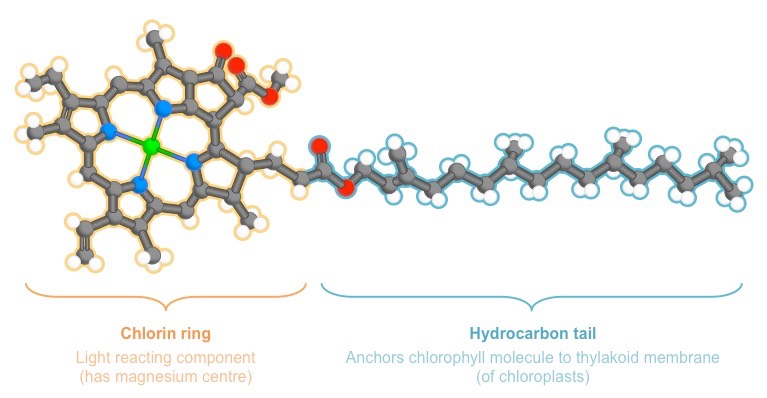
Chlorophyll is a green pigment found in photosynthetic organisms that is responsible for light absorption
When chlorophyll absorbs light, it releases electrons which are used to synthesise ATP (chemical energy)
There are a number of different chlorophyll molecules, each with their own absorption spectra, however collectively:
Chlorophyll absorbs light most strongly in the blue portion of the visible spectrum, followed by the red portion
Chlorophyll reflects light most strongly in the green portion of the visible spectrum (hence the green colour of leaves)
Diagram of a Typical Chlorophyll Molecule
Pigments absorb light as a source of energy for photosynthesis
The absorption spectrum indicates the wavelengths of light absorbed by each pigment (e.g. chlorophyll)
The action spectrum indicates the overall rate of photosynthesis at each wavelength of light
There is a strong correlation between the cumulative absorption spectra of all pigments and the action spectrum
Both display two main peaks – a larger peak at the blue region (~450 nm) and a smaller peak at the red region (~670 nm)
Both display a trough in the green / yellow portion of the visible spectra (~550 nm)
Photosynthesis
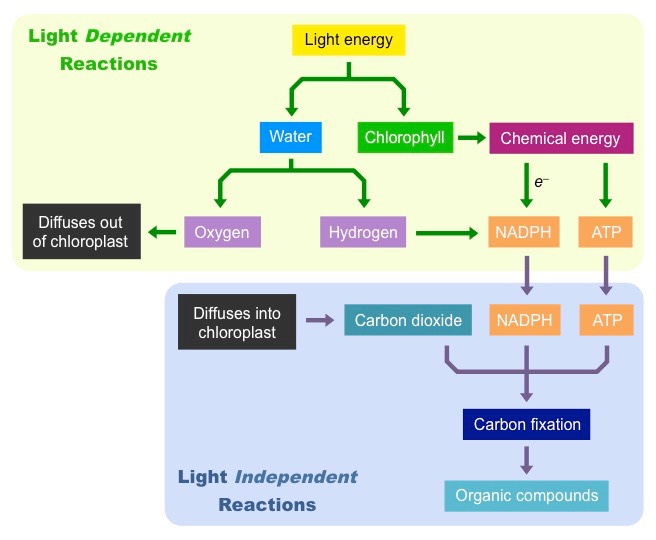
Photosynthesis is a two step process:
The light dependent reactions convert light energy from the Sun into chemical energy (ATP)
The light independent reactions use the chemical energy to synthesise organic compounds (e.g. carbohydrates)
Step 1: Light Dependent Reactions
Light is absorbed by chlorophyll, which results in the production of ATP (chemical energy)
Light is also absorbed by water, which is split (photolysis) to produce oxygen and hydrogen
The hydrogen and ATP are used in the light independent reactions, the oxygen is released from stomata as a waste product
Step 2:Light Independent Reactions
ATP and hydrogen (carried by NADPH) are transferred to the site of the light independent reactions
The hydrogen is combined with carbon dioxide to form complex organic compounds (e.g. carbohydrates, amino acids, etc.)
The ATP provides the required energy to power these anabolic reactions and fix the carbon molecules together
Summary of the Overall Process of Photosynthesis
Photosynthetic organisms do not rely on a single pigment to absorb light, but instead benefit from the combined action of many
These pigments include chlorophylls, xanthophyll and carotenes
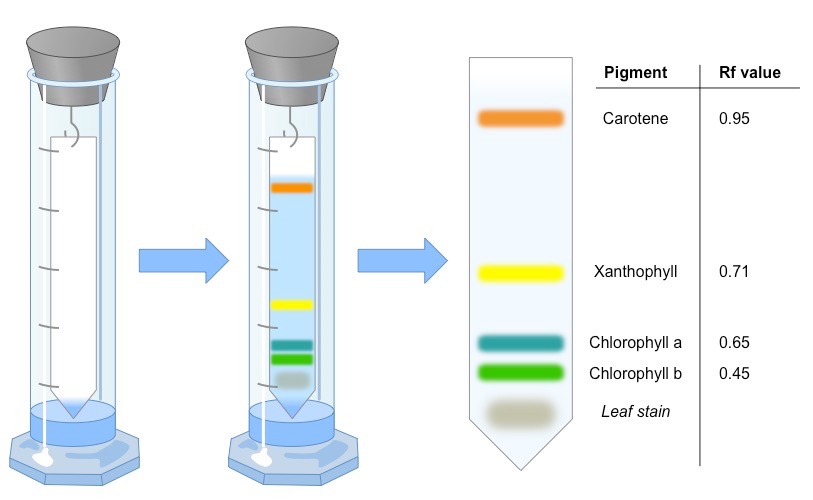
Chromatography is an experimental technique by which mixtures can be separated
A mixture is dissolved in a fluid (called the mobile phase) and passed through a static material (called the stationary phase)
The different components of the mixture travel at different speeds, causing them to separate
A retardation factor can then be calculated (Rf value = distance component travels ÷ distance solvent travels)
Two of the most common techniques for separating photosynthetic pigments are:
Paper chromatography – uses paper (cellulose) as the stationary bed
Thin layer chromatography – uses a thin layer of adsorbent (e.g. silica gel) which runs faster and has better separation
Overview of the Chromatographic Separation of Photosynthetic Pigments
The law of limiting factors states that when a chemical process depends on more than one essential condition being favourable, the rate of reaction will be limited by the factor that is nearest its minimum value
Photosynthesis is dependent on a number of favourable conditions, including:
Temperature
Light intensity
Carbon dioxide concentration
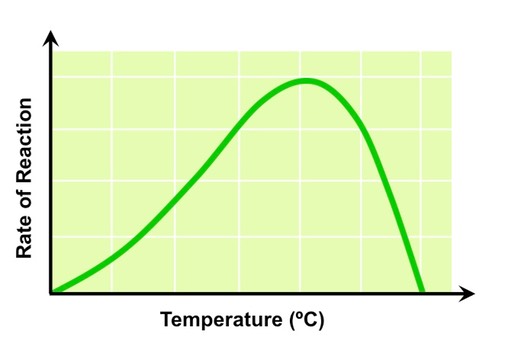
Temperature
Photosynthesis is controlled by enzymes, which are sensitive to temperature fluctuations
As temperature increases reaction rate will increase, as reactants have greater kinetic energy and more collisions result
Above a certain temperature the rate of photosynthesis will decrease as essential enzymes begin to denature
The Effect of Temperature on Photosynthetic Rate
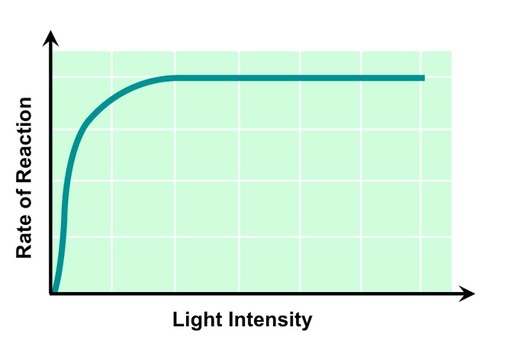
Light Intensity
Light is absorbed by chlorophyll, which convert the radiant energy into chemical energy (ATP)
As light intensity increases reaction rate will increase, as more chlorophyll are being photo-activated
At a certain light intensity photosynthetic rate will plateau, as all available chlorophyll are saturated with light
Different wavelengths of light will have different effects on the rate of photosynthesis (e.g. green light is reflected)
The Effect of Light Intensity on Photosynthetic Rate
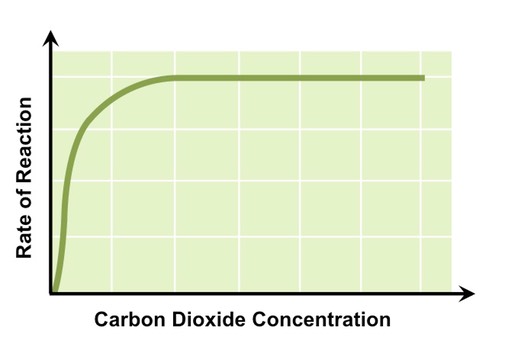
Carbon Dioxide Concentration
Carbon dioxide is involved in the fixation of carbon atoms to form organic molecules
As carbon dioxide concentration increases reaction rate will increase, as more organic molecules are being produced
At a certain concentration of CO2 photosynthetic rate will plateau, as the enzymes responsible for carbon fixation are saturated
Effect of Carbon Dioxide Concentration on Photosynthetic Rate
Photosynthesis can be measured directly via the uptake of CO2 or production of O2, or indirectly via a change in biomass
It is important to recognise that these levels may be influenced by the relative amount of cell respiration occurring in the tissue
Measuring CO2 Uptake
Carbon dioxide uptake can be measured by placing leaf tissue in an enclosed space with water
Water free of dissolved carbon dioxide can initially be produced by boiling and cooling water
Carbon dioxide interacts with the water molecules, producing bicarbonate and hydrogen ions, which changes the pH (↑ acidity)
Increased uptake of CO2 by the plant will lower the concentration in solution and increase the alkalinity (measure with probe)
Alternatively, carbon dioxide levels may be monitored via a data logger
Measuring O2 Production
Oxygen production can be measured by submerging a plant in an enclosed water-filled space attached to a sealed gas syringe
Any oxygen gas produced will bubble out of solution and can be measured by a change in meniscus level on the syringe
Alternatively, oxygen production could be measured by the time taken for submerged leaf discs to surface
Oxygen levels can also be measured with a data logger if the appropriate probe is available
Measuring Biomass (Indirect)
Glucose production can be indirectly measured by a change in the plant’s biomass (weight)
This requires the plant tissue to be completely dehydrated prior to weighing to ensure the change in biomass represents organic matter and not water content
An alternative method for measuring glucose production is to determine the change in starch levels (glucose is stored as starch)
Starch can be identified via iodine staining (turns starch solution purple) and quantitated using a colorimeter
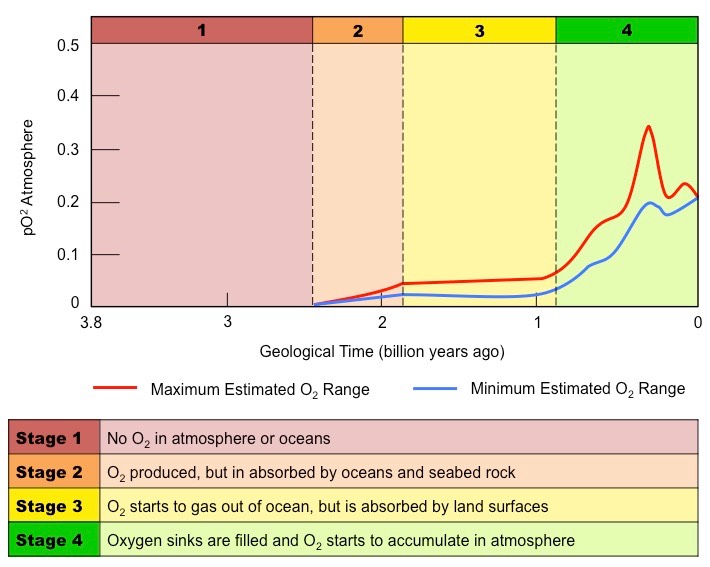
Only one significant source of oxygen gas exists in the known universe – biological photosynthesis
Before the evolution of photosynthetic organisms, any free oxygen produced was chemically captured and stored
Approximately 2.3 billion years ago, photosynthetic organisms began to saturate the environment with oxygen
This led to changes in the Earth’s atmosphere, oceans, rock deposition and biological life
Oceans
Earth’s oceans initially had high levels of dissolved iron (released from the crust by underwater volcanic vents)
When iron reacts with oxygen gas it undergoes a chemical reaction to form an insoluble precipitate (iron oxide)
When the iron in the ocean was completely consumed, oxygen gas started accumulating in the atmosphere
Atmosphere
For the first 2 billion years after the Earth was formed, its atmosphere was anoxic (oxygen-free)
The current concentration of oxygen gas within the atmosphere is approximately 20%
Rock Deposition
The reaction between dissolved iron and oxygen gas created oceanic deposits called banded iron formations (BIFs)
These deposits are not commonly found in oceanic sedimentary rock younger than 1.8 billion years old
This likely reflects the time when oxygen levels caused the near complete consumption of dissolved iron levels
As BIF deposition slowed in oceans, iron rich layers started to form on land due to the rise in atmospheric O2 levels
Biological Life
Free oxygen is toxic to obligate anaerobes and an increase in O2 levels may have wiped out many of these species
Conversely, rising O2 levels was a critical determinant to the evolution of aerobically respiring organisms
Changes to Oxygen Levels on Earth