Class Notes
1/22/26
World → distal stimulus
Retinal Image → proximal stimulus
What is the function of vision? Is to establish internal representations of the external world such that we can successfully interact with it (the world).
The function of any sensory system is to establish internal representations of the external world, based on some physical source of information that reflects some aspects of the world so that we can successfully interact with it.
Psychometric function is different from person to person (threshold)
1/29/26
We tend to use rods for night vision.
The rod system has higher sensitivity
Works better in low light
Acuity → Ability to discriminate fine detail
Ability to distinguish fine detail, depending on how small it is
In bright light, cones are more sensitive than rods
Cones adapt pretty quickly and then bottom out
Oguchi’s disease (congenital) → No (functional) rods
Receptive Field → a property of the cell, but it is defined by location within the visual field
Every visual sensory neuron has a receptive field
part of the visual field
That part of the visual field to which a given neuron is sensitive
High acuity; low sensitivity
Small receptive fields so there is no ambiguity with regard to A alone, B alone, or A plus B (high acuity)
But any given ganglion cell is likely to get activated under low-light conditions (low sensitivity)
Ganglion cells are good at receiving edges
RGCs with center-surround RFs are edge detectors
02/03/26
Neurofibers leave the back of the eye → that is where the blind spot is
The primary visual pathway (geniculostriate) and secondary visual pathway (retinotectal) both start at the retina
PVP
Evolutionarily newer
underlies conscious perception
SVP
Evolutionarily older
mainly unconscious processing
Primary visual cortex (V1)
Retinotopic representation
The spatial relations are maintained. Establishing a spatial map of the cortex
Better defined in the earlier processing fields than the later processing fields.
Cortical magnification
The cortical map is the tissue dedicated to the region
Multiple maps & Increasing receptive field size
Taking the cortex and making it flat.
Each one of the V’s is a separate map of the visual field. (Multiple maps of the visual field slide)
The receptive field size gets larger as it goes on up from V1.
Functional selectivity
When neurons respond more strongly to some visual feature or property than to others, that cell effectively codes for the presence of that visual attribute at that particular location in the visual field
Fusiform Face Area (FFA) → is activated during face perception because it contains lots of individual neurons that are selective for configurations of stimuli corresponding to faces ( like RGCs are selective for edges)
(Rough) Functional selectivity
V1 → basic features
V4 → color, curvatures, and simple shapes
IT/TE and LOC → complex form
FEF/LIP → spatial attention, saccade control
V1 selectivity
Retinal ganglion cells are selective for edges
Firing rate changes when there is an edge in their RF, and does not change when there is not
The tuning curve describes selectivity for a given neuron
The tuning function describes the characteristics of that one cell
V1 cells have orientation selectivity
Information processing through selective convergence
A specific subset of RGCs converging onto a common V1 cell can create an orientation-specific V1 cell
Selective adaptation
Increased threshold for adapted orientation and NOT other orientations
Means there are mechanisms selective for that orientation
Humans adapt selectively to specific spatial frequencies as well as specific orientations.
Human Contrast Sensitivity Function (CSF)
The yellow region shows the part of that space where we can see edges and light information over space.
It is determined by underlying (measurable) spatial-frequency channels → these are essentially filters.
It tells us about
Acuity → the smallest spatial detail that can be resolved (depends on contrast)
Sensitivity → the lowest contrast that can be perceived (depends on spatial frequency)
2/5/26
Human Contrast Sensitivity Function (CSF) → a space of stimulation that the visual system can deal with.
The shape of it is telling the lowest amount depends on the frequency, and the acuity depends on the contrast
Can be defined without reference to each other
Spatial Frequency and Orientation
defined by orientation, spatial frequency, and contrast
Square-wave gratings → set of superimposed spatial frequencies at increasing spatial frequency and decreasing contrast
More complex than sine waves
To the visual system, it is very complex
Single sine waves are filtered by a single frequency channel
Fourier analysis → can decompose any 2D image into a sum of component sine waves (spatial frequency, contrast, orientation)
Bandpass-filters → only a range of spatial frequencies is passed through
Internal representations of the retinal image (related to the external world) in V1 is the pattern of activity across spatial-frequency and orientation
High contrast and low contrast produce the same image, but produce different spikes/sec
A low-contrast edge at the preferred orientation elicited the same response as a high-contrast edge at a less-preferred orientation. [Ambiguity in single-cell activity]
Edges at very different non-preferred orientations can produce the same response. [Ambiguity in single-cell activity]
Population Coding → representation in terms of patterns of activity across multiple cells (populations) with different selectivities reduces ambiguity
High contrast and low contrast can depend on how the cell responds to the stimuli
2/10/26
V2
Each visual field is retinotopically mapped
They are coding for different types of visual attributes
Needs edge information in the receptive field
V4
Individual V4 neurons are selective for curvature
If it gets curvature at the right amount, it will change its firing rate to the highest amount on the curve
Inner part is the on part and the outer part is the off part
it is receiving connections from a set of V1 cells (neural signals in image (purple bells)).
they connect within the area to other cells and begin to form other shapes
shape defined by population coding across curvature-selective cells
can help see more complex shapes
shapes are made up by a bunch of curves (A,b,c,d,e,f in Hershey kiss looking image)
IT/ITE
Faces
Complex-form selectivity
far in the visual processing hierarchy
Kobatake and Tanaka (1994) monkey
coding for configural representations
they can show each of the three features but misconfigured
found to code for complex things
population coding
MT/MST
motion selectivity
MT is the critical one
MT is coding for motion without the need for edges
“Pure” motion, no orientation edge needed
displays the motion without the need for an edge in its receptive field
MT/MT+
compared when having a moving stimulus, no edge, vs a stationary stimulus
Frontal Eye Fields (FEF) and Lateral Intraparietal Area (LIP) → Visually Guided Eye Movements and Attention
Functionally Distinct Pathways
Dorsal stream → V1 to parietal cortex
Extension of rod system (and magnocellular pathway of LGN)
Ventral stream → V1 to temporal cortex
Extension of rod system (and parvocellular pathway of the LGN)
Early What vs Where Evidence
Ungerleider & Mishkin (1982)
Double dissociation → one of two functions is damaged without harm to the other, and vice versa
Object discrimination → “what” task
Landmark discrimination → “where” task
Monkey with the ventral lesion was impaired with the what task but not impaired with the where task
Monkey with the dorsal lesion was impaired with the where task but not impaired with the what task
Later What vs How evidence
Milner & Goodale (1991)
Two tasks
Perceptual matching (What)
Posting (How)
Two patients
Ventral Damage (DF)
Dorsal Damage (RV)
Two Tasks
Reaching (How)
Same/different (What)
Same/Different Task (What)
DF was worse than RV who was equal to control
Reaching Task (How)
RV was worse than DF who was equal to control
The patient with dorsal damage (RV) performed poorly
The patient with ventral damage (DF) performs as well as controls
Specific Selectivities Reflect Ventral/Dorsal Functions
Retina → edges (cones, rods)
LGN (parvocellular, magnocellular)
V1 (parvo, magno) → basic visual features
V2 (parvo, magno) → basic visual features in context
V4 → color, curvature
Temporal areas (IT/TE) → complex shapes, faces/configurations
Ventral stream → What (object recognition)
MT → motion
LIP/FEF → eye movements. Visually guided grasping
Dorsal Stream → How? (visually guided action)
2/17/26
Object Perception
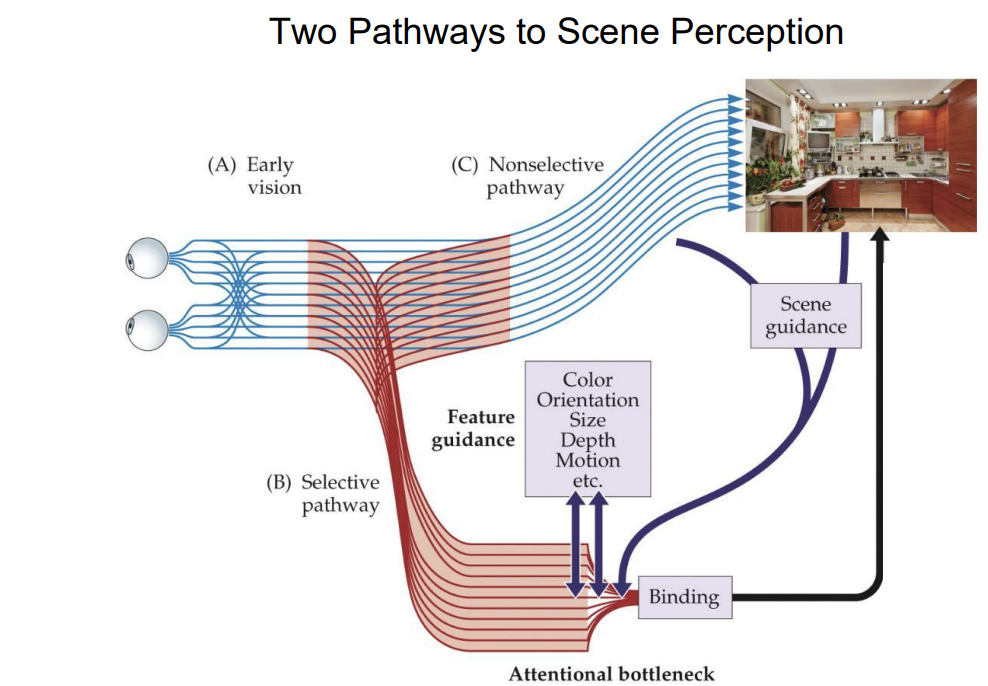
Perceptual Organization → Processes by which representations of image-based information (proximal stimulus) are transformed into representations that reflect scene structure (distal stimulus)
proximity, similarity, enclosure, symmetry, closure, continuity, connection, figure & ground
Components of Perceptual Organization:
Represent edges (image information)
Represent uniform regions bounded by edges (image information)
Different luminance levels reach the eye from different parts of the scene because of light reflecting off of surfaces with different reflectances
Mosaic → still an image-level representation
Border ownership/ figure vs. ground/ relative depths (beyond the image)
Edges separate regions
Not explicit, it has to be inferred
V2 has cells that are selective for specific border ownerships1
Function of selectivity for border ownership
Distinguish figure from (back)ground/ Assign relative depth
Completion- representing “inferred” parts of the scene (beyond the image)
group similar lines together
continue aligned edges (even if dissimilar)
enclose edges to define contiguous regions
relatable edges are completed; unrelatable edges are not
X-junction → transparency and different depths
T-junction → occlusion and different depths
L-junction → adjacent at same depth
Object Recognition → processes by which visual representations are matched to amodal semantic representations in memory
Scene Processing → understanding objects and their relations in context
Interdependence of components → completion depends on assigned border ownership
[Input] Image-based representations (e.g., luminance over space) → Perceptual Organization → [Output] Scene-based representations (e.g., surfaces and their spatial relations)
2/19/26
Recall:
Perceptual Organization → Processes by which representations of image-based information (proximal stimulus) are transformed into representations that reflect scene structure (distal stimulus)
Object Recognition → processes by which visual representations are matched to amodal semantic representations in memory
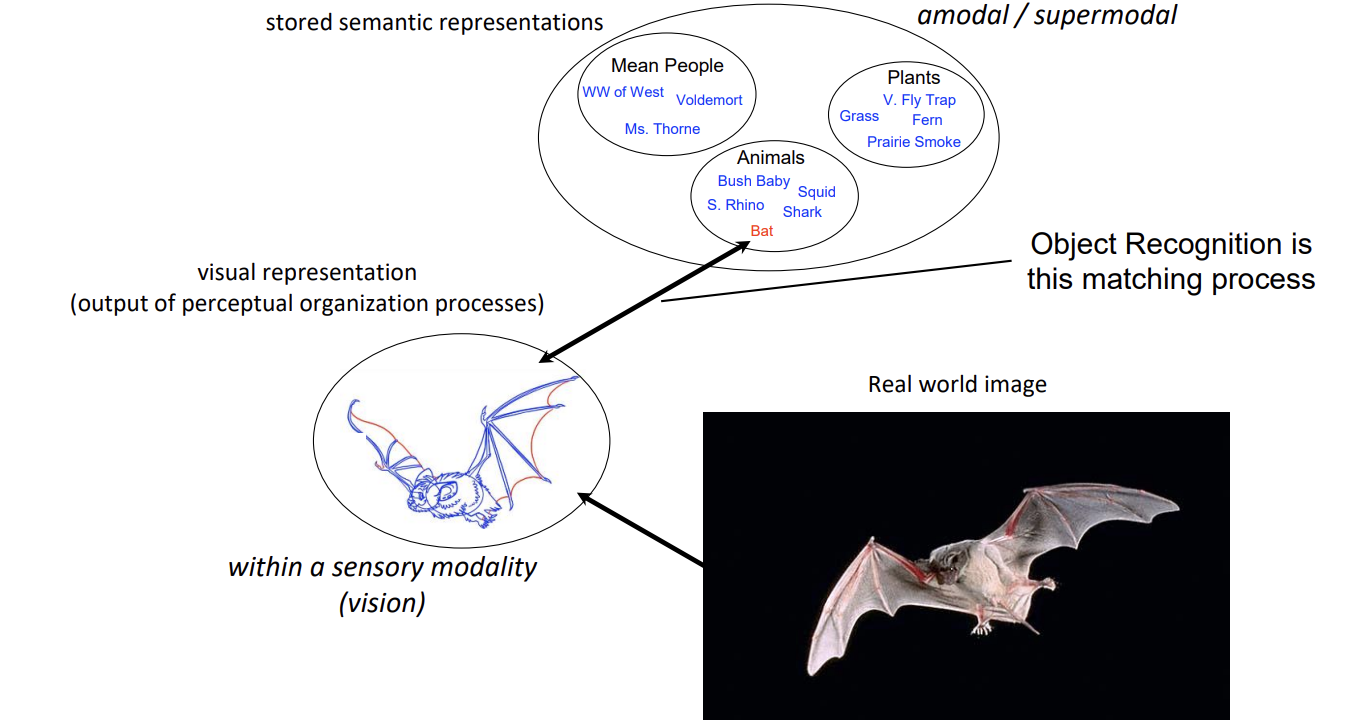
Theories of object recognition try to explain how that matching process occurs
Template theories are intuitive
Template Models
Point-for-point matching of input against stored representation (“lock and key”)
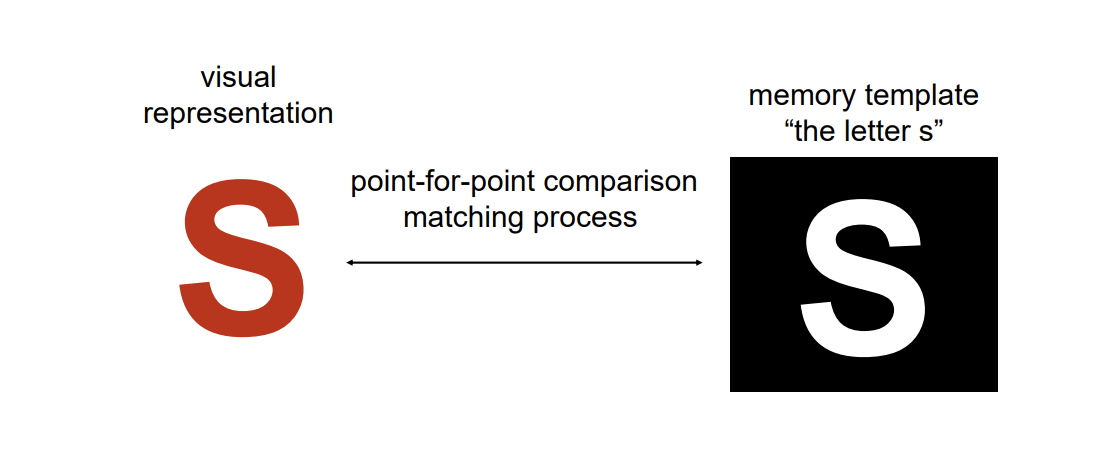
Problems with this simple template theory? → We would need an infinite number of templates in memory to account for human object recognition capabilities.
The problem of Invariance
A successful object recognition system must be able to recognize on object across different points of views (and other variability in context)
Template-Matching processes are used for a lot of applications where viewpoint can be controlled, and the number of to-be-identified “objects” is limited.
Computer-vision systems (self-driving cars) are increasingly sophisticated template-matching systems…but still template matching.
Template models with extensive image-normalization processes and exposure to massive image sets (for defining the templates) are working for increasingly complex and dynamic applications
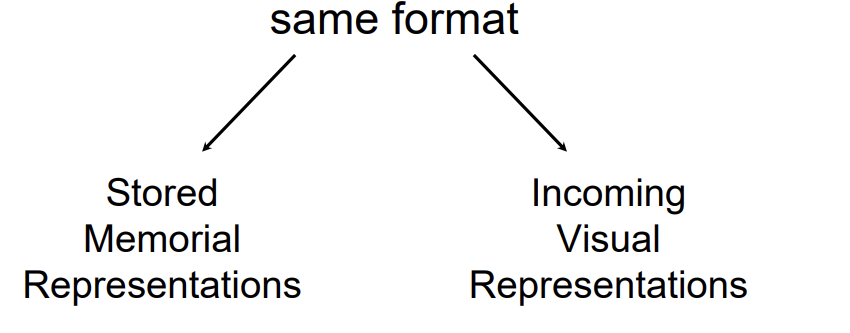
Point-for-point matching works (logically) because the visual representation and the memorial representation are the same format and can be compared…point-for-point
Characteristics of Human Vision that are not Well Explained by Template Theories
Viewpoint invariance
Robust against image degradation
Memory representations cannot depend on sensory modality (templates do)
Recognition is vast and fast
Incredibly reliable…we don’t do this (as much)
Scene Processing → understanding objects and their relations in context
[Input] Image-based representations (e.g., luminance over space) → Perceptual Organization → [Output] Scene-based representations (e.g., surfaces and their spatial relations)
Components of Perceptual Organization:
Represent edges (image information)
Represent uniform regions bounded by edges (image information)
Border ownership/ figure vs. ground/ relative depths (beyond the image)
Completion- representing “inferred” parts of the scene (beyond the image)
Ambiguity and Best Guesses about Organization
It is more likely that two lines cross than that two angles happen to abut, but it’s not impossible that two angles abut.
So, perceptual inference based on likelihood is separate from cognitive inference.
Structural Description Models (alternative to template models)
Object representations are descriptions in terms of the nature of constituent parts and the spatial relations between those parts
Hands are represented as a specific set of parts and their spatial relations
Structural Description Models do three important things:
1. Provide efficiency of representation (like alphabet to words) allowing us to represent many distinct objects
2. Solve the comparison of representation problem (apples-to-apples instead of apples-to-oranges)
3. Solve the problem of viewpoint invariance by defining parts on the basis of viewpoint invariant properties (this needs more explanation)
Parsing Image into Parts
The structural description process has to unfold based on image formation
It cannot depend on knowing what the object parts are (4 fingers and a thumb)
This visual system uses matched concavities in the image to parse it (break it apart) and represent it as a set of component parts
Notice that parsing is perceptual organization
Why concavities?
When multiple 3D components join together, they often create concave boundaries in their 2D projection
Concavities in 2D images are therefore useful cues to 3D part boundaries
Parsing at concavities…Image-based process → does not depend on knowing what the parts are → allows us to establish structural descriptions of novel objects
Identifying the Parts
A relatively small set of parts provides efficiency of representation and recognition. Like letters in an alphabet.
26 letters
More than 1,000,000 words
Infinite number of sentences
What are the parts?
Recognition by Components (RBC). A specific structural description model
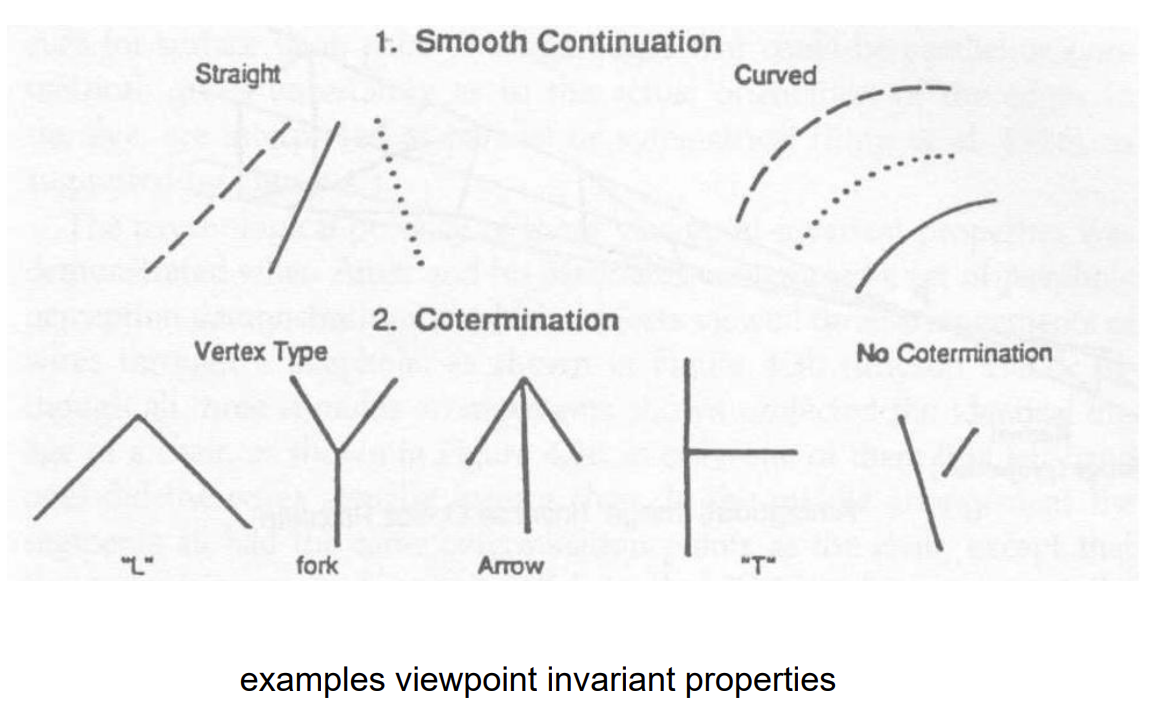
Parts are represented based on viewpoint invariant properties
Visual properties that remain constant in the 2D retinal image across (most) viewpoints of the 3D object
A solution to the challenge of viewpoint invariance in object recognition
3D curvature projects 2D curvature (except for a single accidental point of view). 3D straight projects 2D straight
So if the image is curved, the visual system infers that the object is curved. If the image is straight, the visual system infers that the object is straight
Cotermination (a viewpoint invariant property) on the image is perceived as co-termination in the world (even though sometimes it’s not)
The default assumption is that things are being viewed from a non-accidental viewpoint
2/24/26
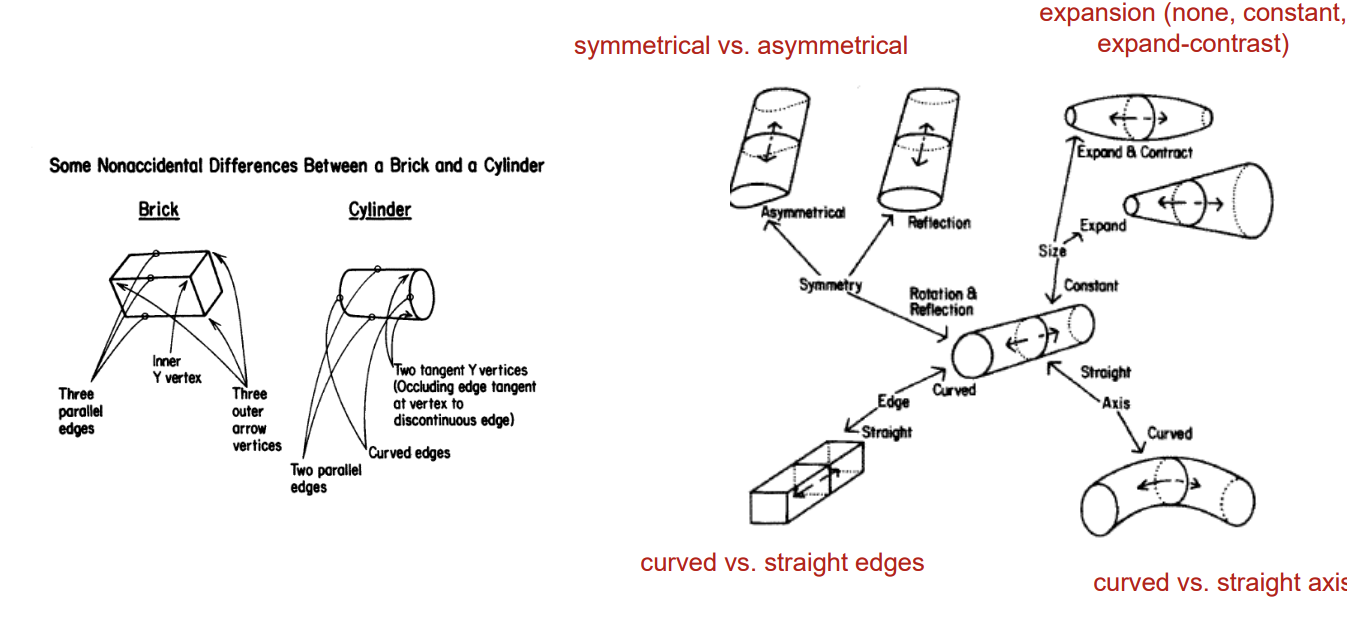
Recognition by Components (RBC) → A specific structural description model
Objects are represented as sets of parts and their spatial relations
Addresses the perceptual ←→ memorial representation problem
Parts are defined based on viewpoint invariant properties
Addresses the challenge of viewpoint invariance
Each of these are examples of different parts that can be used to create different representations.
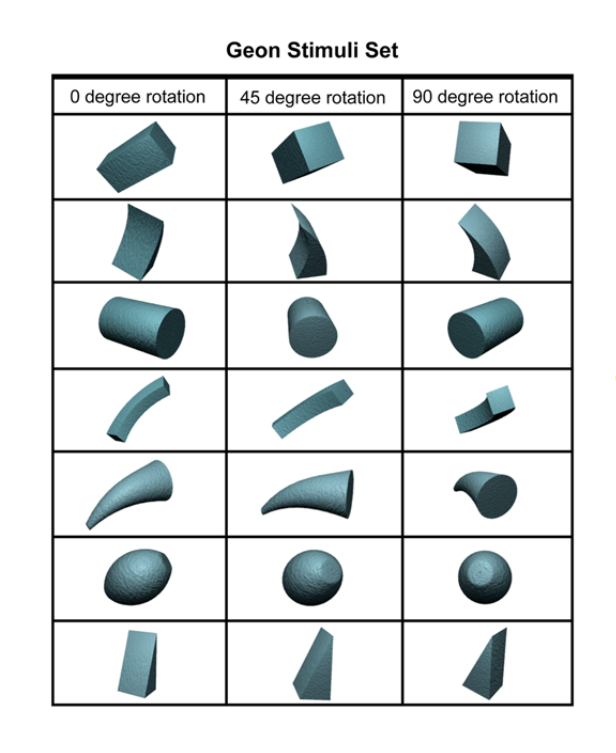
These different geons are reliably distinguishable from each other from different points of view.
Object representations consist of combinations of geons with specific spatial relations. (like words are combinations of letters in specific orders).
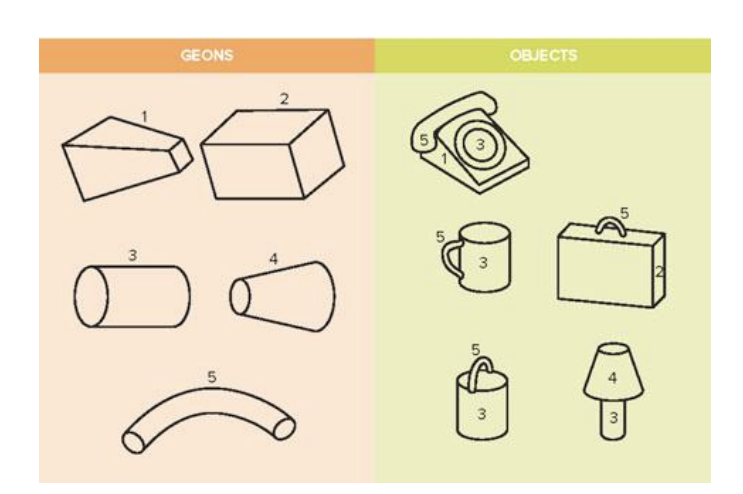
Cup → parts: {5, 3}. spatial relations: 5 is on the side of 3
Bucket → parts: {5, 3}. spatial relations: 5 is on top of 3
Structural descriptions (list of parts and their spatial relations) serves as a common representational format for perception and memory
apples to apples
Structural Description Models
do three important things
Provides efficiency of representation allowing us to represent many distinct objects (like alphabet to words)
Solve the comparison of representation problem (apples-to-apples instead of apples-to-oranges)
Solve the problem of viewpoint invariance by defining parts on the basis of viewpoint invariant properties (e.g., in RBC)
Facial Recognition
Visual Agnosia → can’t identify non-face objects but can recognize faces
Prosopagnosia → can identify non-face objects but can’t recognize faces
Structural descriptions of faces do not help identify between individuals
Thatcher Effect → Why does the altered one look so much weirder when it is right-side up?
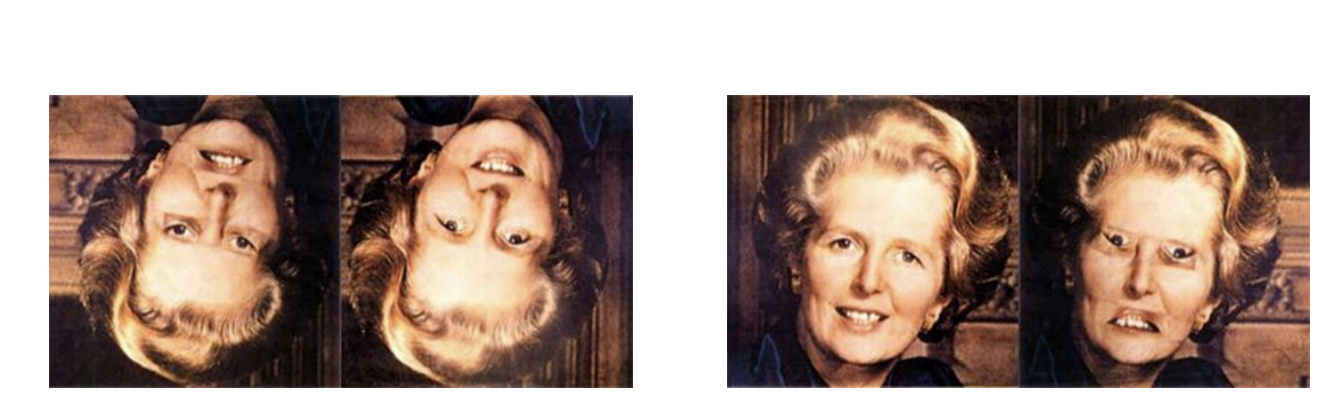
Faces are processed (more) holistically (than non-face objects).
“Holistically” means that recognition depends more on the representation of relations between parts or configurations than on parts.
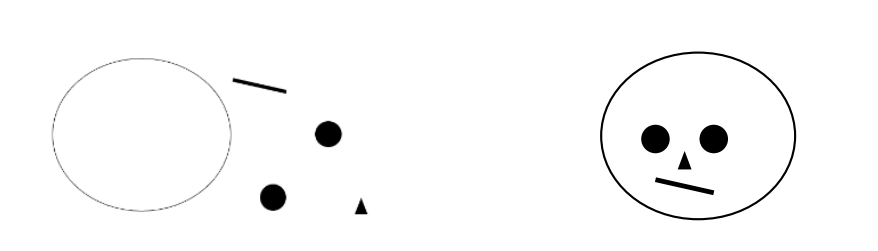
Whole-object advantage for detecting difference (Tanaka & Farah 1993)
only holds for faces. houses won't engage normal face-recognition processes, but faces will.
Upside-down faces should not engage normal face-recognition processes to the same extent that upright faces do
The whole-object advantage occurs only for upright faces - upside-down faces are not faces to the visual system
Inversion Effect → Evidence that faces are processed differently
Face recognition is impaired more by inversion than non-face object recognition is impaired.
Fusiform Face Area Parahippocampal Place Area
PPA → area that is selectively activated by images of places
FFA → area that is selectively activated by images of faces
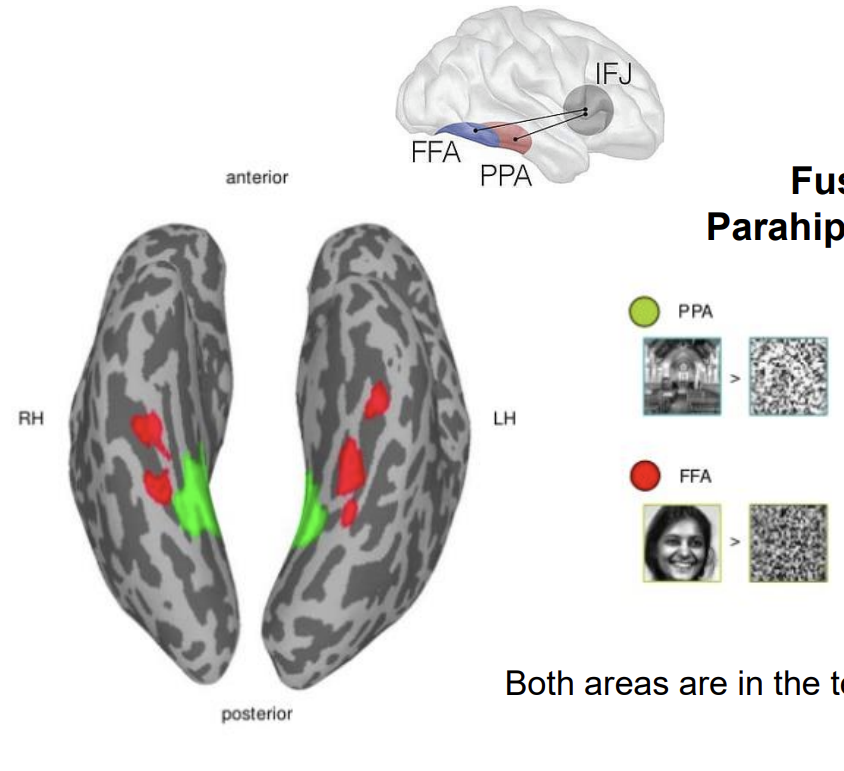
Both areas are in the temporal cortex (ventral stream)
These areas reflect different types of processing (part-based versus holistic) rather than different categorical functionality (places versus faces)
The processing of upside-down faces is dominated by part-based processing
An inverted face is not treated by the visual system as a “face”… so “regular object” part-based processes dominate …each part is essentially fine here
The processing of right-side up faces is dominated by holistic processing
A right-side up face is processed as a face …so holistic processes dominate … the relations between parts are incongruous.
The “face” is detected when it is at the orientation of normal faces

Alignment supports the perceptual completion of the two halves into a single object. The single object is a face and therefore processed holistically …making the individual component faces difficult to represented separately. For this (albeit weird) task, holistic processing is a problem.
The difference in difficulty between aligned and misaligned stimuli should be significantly reduced because turning them upside down makes them less likely to engage holistic processing and it is holistic processing that is causing the greater difficulty for aligned faces
Are faces special?
Sort of. Experts tend to showed increased FFA activity when looking at examples of the category for which they are expert. (Fusiform Expertise Area)
Perceptual expertise often involves shifting from more part-based processing to holistic processing
Own-Race Effect is Real
It’s about experience
The inversion effect is greater for own-race faces than other-race faces
Differential experience leads to differential engagement of holistic processing (expertise)
Scene processing → understanding objects and their relations in context
We extract the “gist” of scenes extremely quickly (the “clap when you see water” example)
We do this by using global image (proximal stimulus) properties to coarsely categorize scenes (representation of distal stimulus) of different types.

All of this involves inference.
Depth and Size
The function of vision → is to establish internal representations of the external world, such that we can successfully interact with it.
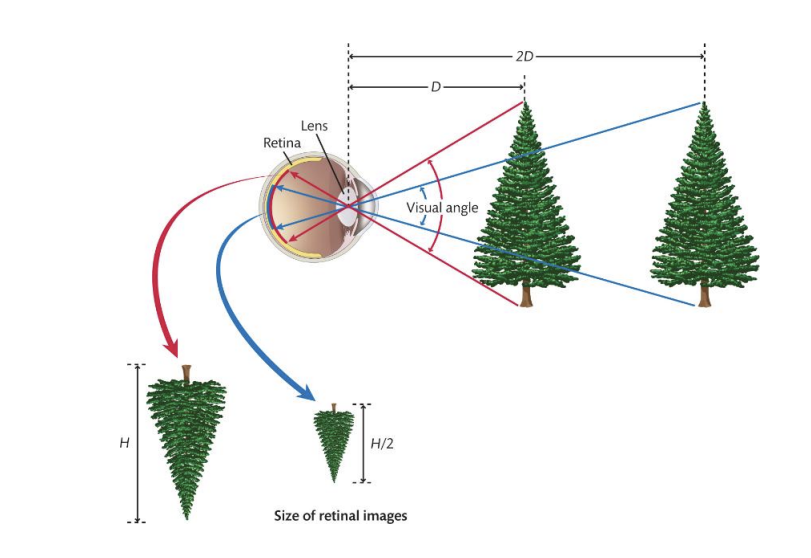
Retinal images are ambiguous with regard to size and depth
Retinal images are measured in terms visual angle.
The same object projects a smaller retinal image at further distances.
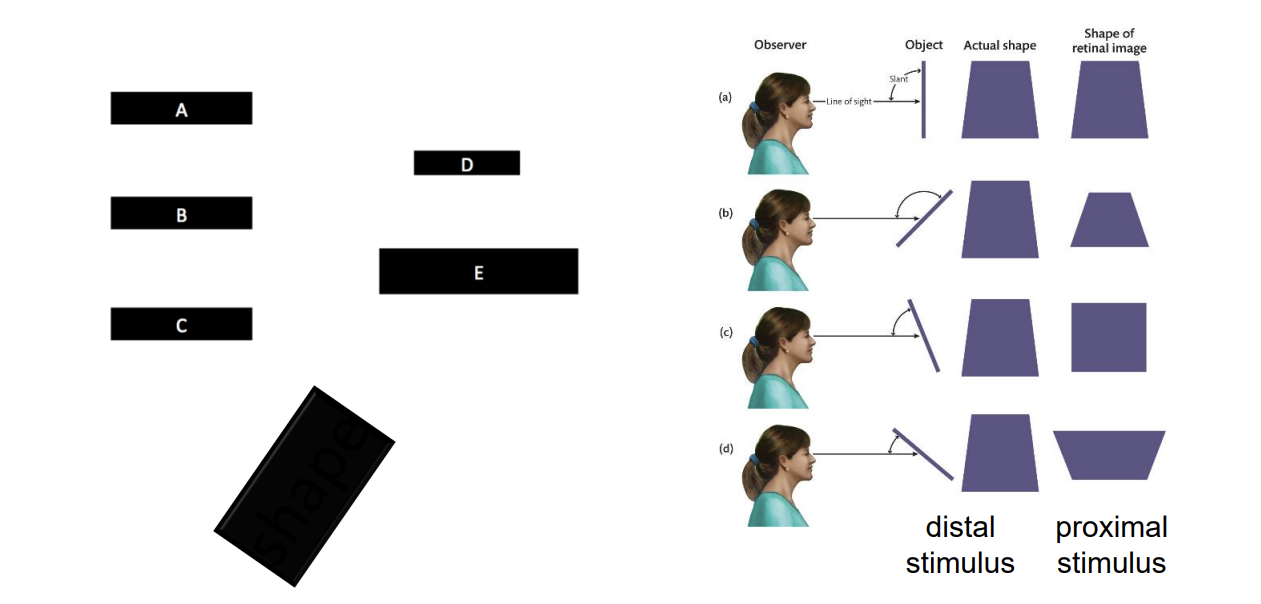
Notice that retinal images are ambiguous with regard to shape too because of orientation in depth.
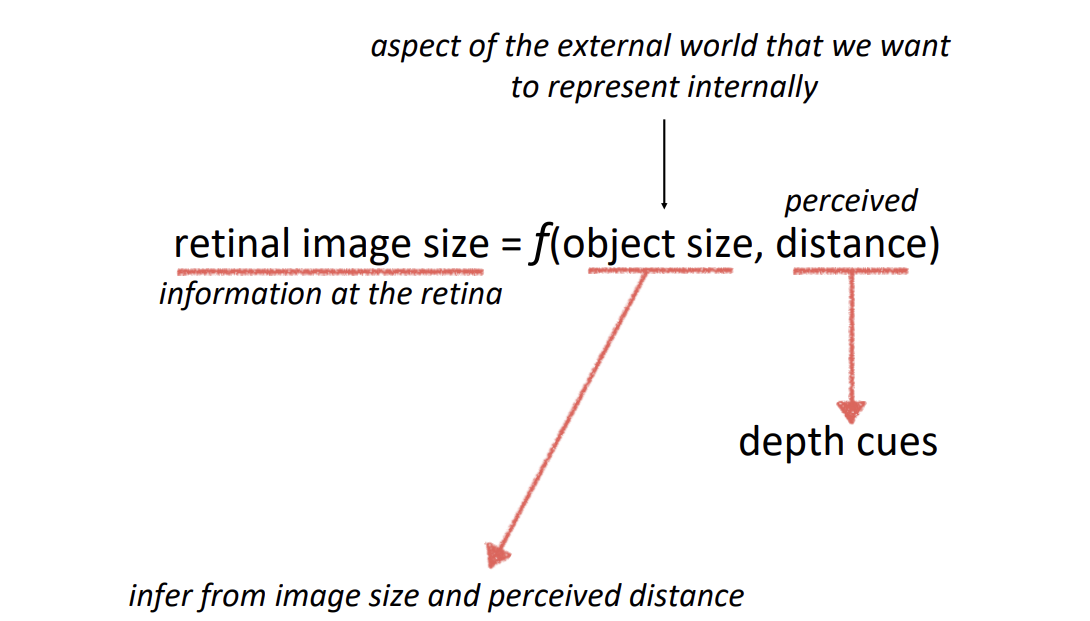
2/26/26
Perceiving size
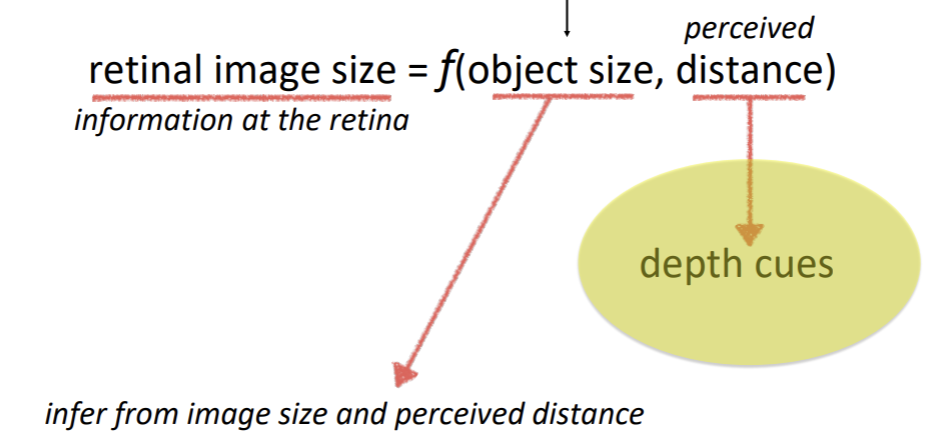
Oculomotor cues
Accomodation
The depth cue is that the brain can register the state of the muscles that control lens thickness.
Convergence
The depth cue is that the brain can register the state of the muscles that control the angle of the eyes.
Cues based on retinal imagae aka stereovision.
Monocular vision, you don’t need information from both eyes. One is sufficient enough.
Static cues:
Position-Based Cues
Partial occlusion:
When one thing is infront of another and blocks the object behind it (occlusion) it sends a cue that the thing that is occluded is farther away than the thing that is not occluded.
Relative height:
Natural images have multiple cues that the system must integrate in some way.
Relative height in image. Depth information.
Size-Based Cues
Relative size

Familiar size

You are familiar with the size of the coins so you know their sizes are different but in this image they are the same size
Texture gradients
Linear perspective
Lighting-Based Cues
Atmospheric perspective
Shading
You can convince yourself of a different lighting direction, and it will change the depth/shape perception
Cast Shadows
Many aspects of cast shadows carry information about depth
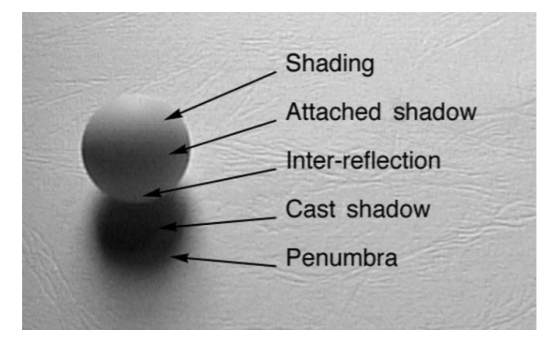
Dynamic Cues
Motion parallax
The magnitude of speed difference between two objects is metrically related to the distance between them.
Optic flow
Is the change in the optic array over time (We use it a lot for guiding our action)
The dynamic (changing) optic array
Image that is projected to the retina
Optic flow is separate from object perception
Deletion and accretion
Cues can work together motion and cast shadows
Binocular cues
Binocular disparity
Corresponding points are defined relative to the fovea
Horopter: The set of locations in the world that project to the corresponding points. It defines a surface of zero disparity.
Only exists in the relationship between the images in the two eyes
Direcetion of disparity indicates direction of from the horopter
Uncrossed disparity: perceived as farther than horopter
Images move away from the fovea nasally (toward the nose)
You would have to uncross (diverge) your eyes to fixate the object
Crossed disparity: perceived as closer than the horopter
Images move away from the fovea temporally (toward the ear)
You would have to cross (converge) your eyes to fixate the object
Binocular disparity
The difference in the relative position of the image of a single object (or edge) on the two retinae
Stereopsis
Perceiving depth from binocular disparity
About 7% of the population are stereoblind
3/3/26
Binocular cue
Only exists in the relationship between the images in the two eyes
Binocular disparity
The difference in the relative position of the image of a single object (or edge) on the two retinae
Stereopsis
Perceiving depth from binocular disparity
Corresponding points are defined relative to the fovea
Horopter
The set of locations in the world that project to corresponding points on the two retinae. It defines a surface of zero disparity.
Direction of disparity indicates direction from the horopter.
Uncrossed disparity
Perceived as farther than horopter
Crossed disparity
Perceived as closer than the horopter
Binocular Disparity → Neurophysiology
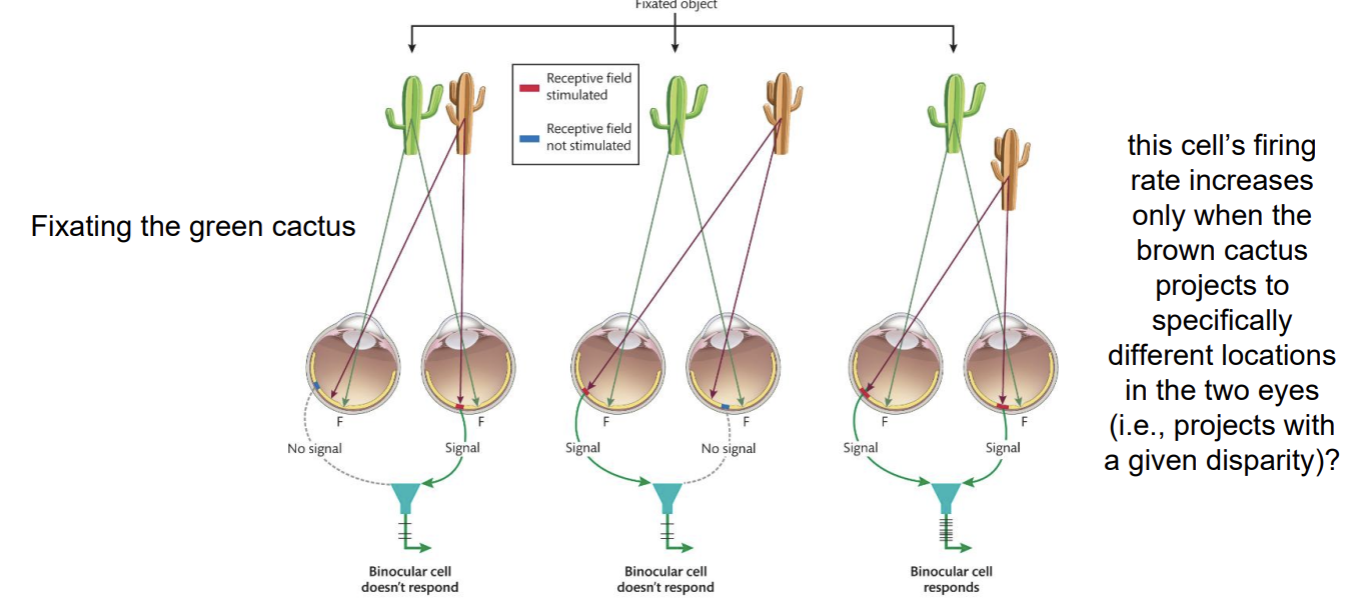
The Correspondence Problem → How does the visual system “know” which image in the right eye corresponds to which item in the left eye?
Feature (color, shape, and image size) matches?
Image features are definitely used, but cannot be the whole story
The Wallpaper illusion (“magic eye”)
Occurs when the correspondence problem is solved “incorrectly”.

Inference-like process: In order for an object to project the same size image as another object from a greater distance, it must be a larger object.

Selective (Visual) Attention
Processing one source of visual information while ignoring others.
Compare identical stimulus conditions under different task conditions.
Visual attention is selective visual processing
Selection in space and time
What happens to selected information?
Neural basis of selective processing
Scene perception and the fate of the unattended
3/5/26
Attention can be captured
Initial eye-movements often go to the non-target additional singleton, but capture depends on control settings. If searching for a singleton is not the optimal strategy, singletons don’t capture attention.
Attentional guidance is determined by more than bottom-up (stimulus driven) and top-down (goal driven) factors.
Humans are social animals. Attention is guided by others’ (overt) attention.
Attentional guidance is understood in terms of an internal map that prioritizes locations for selection based on multiple sources of input.
Priority map integrates information based on salience (bottom-up), task relevance (top-down), and other attributes (e.g., search history and value).
Then the attention is guided to peaks in order of activation level (highest to lowest)
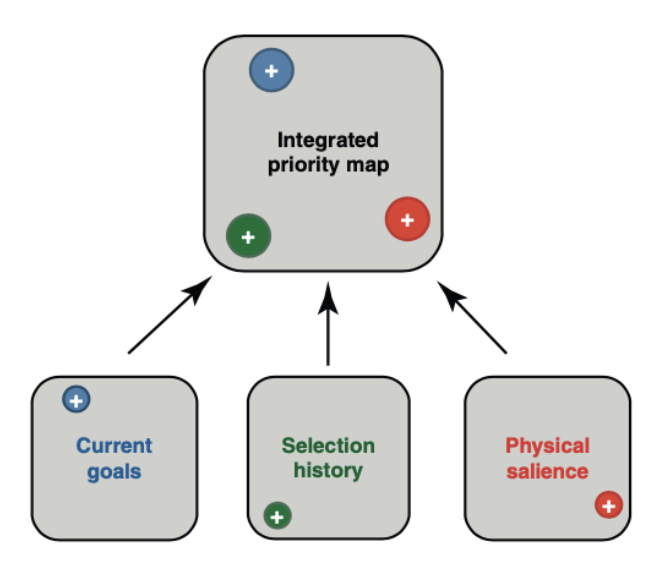
Selection in Time → Metaphor for understanding limitations of temporal selection.
Experience can improve temporal selection
Emotional stimuli (especially negative ones) capture our attention and induce an attentional blink
Enhanced activity (basically gain control)
Retinotopically organized enhanced activity in V1 corresponding to cued locations.
Cells with receptive fields at cued locations respond more strongly than cells with receptive fields at uncued locations.
Identical input yet different neural response under different cueing conditions.
You can see retinotopic response changes in visual cortex (V1) (attending to spatial locations).
Enhanced activity of specific types of processing
Recall that functional selectivity is an attribute of cortical processing.
Functionally-specific (objects not locations) changes in visual cortex.
Biased Competition → A theory of selection at a neural level
Stimuli compete for (neural) representation, and attention biases that competition in favor of one thing or another.
Attention changes (biases) population activity. MT/MST (human fMRI)
3/10/26
We have mechanisms to support selective processing because the processing capacity of the visual and cognitive system is limited.
Inattentional Blindness
Knowing that we are susceptible to missing things doesn’t prevent us from missing things.
This is because missing things is a consequence of selective processing… and selective processing is a necessary state of the system given limited processing capacity.
Global Image Information
Axes are defined by image features
Spatial frequency (openness) and edge orientation (expansion)
Scenes cluster by semantic type
Ensemble Perception (perceiving summary image-statistics)
We establish examples of summary statistics from natural images that people can reliably report.
Gaze direction, family resemblance, size, orientation, hue,
motion direction and speed, heading direction, face expression
Visual Attention
Visual processing has to be selective because processing capacity is limited
Attentional guidance is influenced by both bottom-up (stimulus-driven) and top-down (goal-based) factors, as well as by aspects of an individual’s own selection history → we understand guidance through the construct of a priority map.
Different lab-based tasks that are used to study selective processing (e.g., cueing, RSVP, visual search) have revealed what selected information is processed differently from unselected information
The fate of unattended stimuli is significant… we miss more information than we think we do
There are many ways in which selective processing is embodied at a neural level
Some aspects of scene perception are “unselective” and contribute to guidance of selective processing
Part 3
3/24/26
The study of color vision is a microcosm of vision science
The function of vision
To establish internal representations of the external world, such that we can successfully interact with it.
Reflectance and spectral reflectance
Lightness = perceived reflectance (psychological) → shades of gray
Is a (perceptual) conclusion
Color = perceived spectral reflectance
Surface Reflectance = the proportion of light that a surface reflects (physical)
The inverse optics problem for lightness
Luminance → intensity of incident light (physical) → intensity of light at the eye - retinal input (physical)
Reflectance → proportion of incident light that a surface reflects (physical)
It depends on the luminance at the eye and the perceived luminance of incident light
Simultaneous Contrast
Lateral inhibition explanation of simultaneous contrast: Higher luminance surround suppresses more than lower luminance surround
What matters is to which regions/surfaces the gray squares seem to belong - lightness depends on perceptual organization
More perceptual organization
Edge types are important cues about the illumination conditions
Different edges come from different things
Scene cues about edge type provide information about the illumination conditions
Lightness difference is stronger when the edge is perceived as an illumination edge than when it is perceived as a reflectance edge
The lightness difference increases as the cues about edge type lean increasingly toward them being illumination edges (rather than reflectance edges)
Inference about the structure of the scene
Color → perceived spectral reflectance
The visual system’s conclusion as to what proportion of light a surface reflects as a function of wavelength
The nature of specific light (from a source or at the eye) can be described in terms of its power spectrum intensity as a function of wavelength
White light (such as from the sun) is light that contains all wavelengths in more-or-less equal proportions (Flat power spectrum)
Flat Power Spectrum → describing white light
Measurements of intensity of specific wavelengths produced by different light sources (their power spectra)
Surfaces have different reflectance profiles
The proportion of light that a surface reflects as a function of wavelength
Spectral reflectance
When reflectance profiles are flat, we talk about lightness (perceived reflectance because it’s constant across wavelength)
When reflectance profiles are not flat, we talk about color (perceived spectral reflectance)
(Light at source): Power spectrum → intensity of incident light as a function of wavelength (physical)
(Surface reflectance): Spectral reflectance → proportion of incident light that a surface reflects as a function of wavelength (physical)
(Light at eye): Power spectrum → intensity of light at the eye as a function of wavelength at the eye - retinal input (physical)
Changes to the illuminant vs changes to the (surface) reflectance
Additive color mixing
mixing lights
changes the power
spectrum of the light
Subtractive color mixing
mixing pigments
changes the spectral
reflectance of the surface
Additive color mixing (lights) Red + Green = Yellow
Pigment absorbs more of the wavelengths, subtracting from the signal that reaches the eye
More wavelengths are added to the signal that reaches the eye
Additive - it relies on mixing of different wavelengths as they reflect off of different points of pigment
3/26/26
Light → Power Spectrum (Spectral Power Function)
Surface → Spectral Reflectance Function
Light (with a given power spectrum) shines on surfaces (with a given spectral reflectance function) → Describes the light (power spectrum) that reaches the eye.
First Step to Perceiving Color
Encoding the wavelength information at the eye
Spectral content of light & Spectral reflectance of surfaces both determine the light at the eye
Law of Three Primaries (psychophysics)
Given control over the intensities of three different primary light sources, any visible spectral color can be matched
Led to the hypothesis of 3 classes of photoreceptors, each with a different peak sensitivity.
Trichromacy (physiology)
Population coding → the pattern of activity across a population of cells.
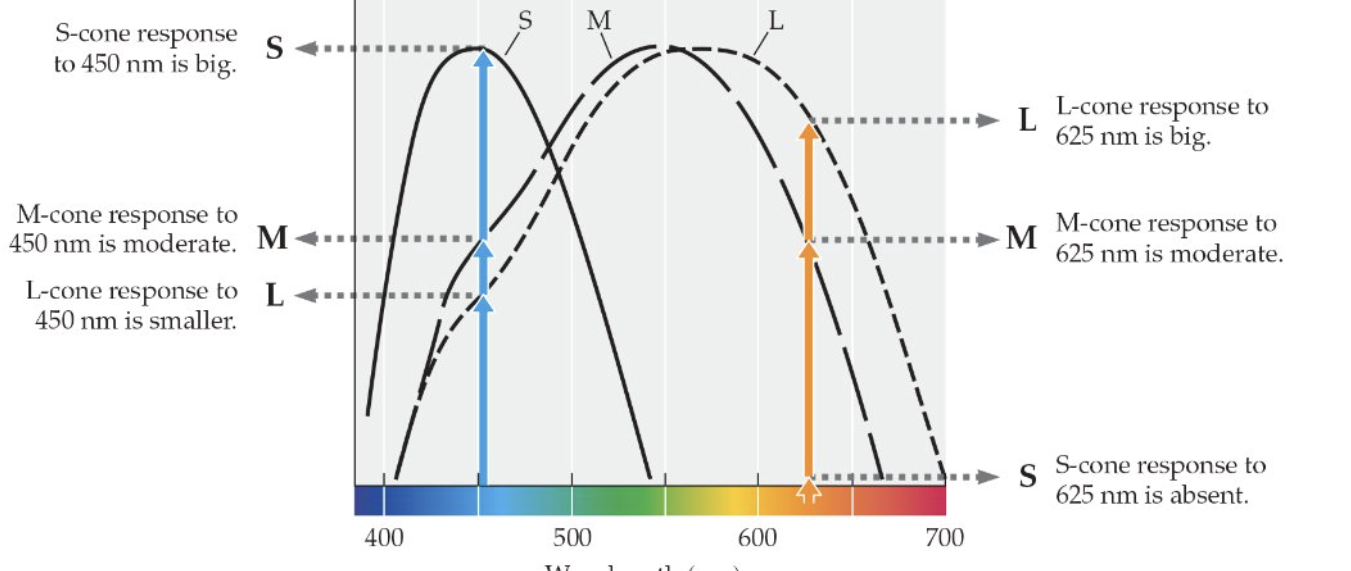
Still ambiguity
Imagine a system with two classes of receptors with different spectral sensitivities
This system cannot tell the difference
Metamers
Pairs of stimuli that are perceptually identical but are physically different (have different power spectra)
530 + 680 light does not create 580 light
This system just can’t represent the difference between 530 + 680 and 580
The set of discriminable colors is determined by the number of cone types and their specific spectral sensitivities
Color blindness is an inability to discriminate between colors that “normal” (trichromatic) folks can because of fewer distinct cone classes
Color blind individuals simply have more metamers
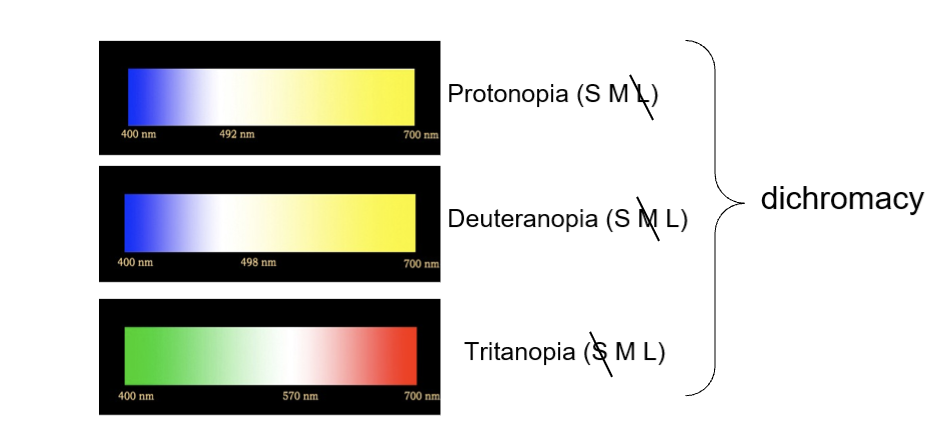
Red-green colorblindness is often caused by the M and L cones having peak sensitivities that are too close
Blue-yellow colorblindness is much less prevalent
Mantis shrimp have 16 classes of photoreceptors!
Wavelength is physical
Color is psychological
Does not exist in the external world
Is the interaction between wavelength and our particular visual system
Color Space (versus spectrum)
electromagnetic spectrum is linear
380 vs 780 nm are maximally different stimuli
Color space is circular
Color space is a perceptual (physiological) space, not a physical space
The color spindle - three dimensions
The Law of Complementarity (psychophysics)
For any spectral color there is a complementary spectral color such that when the two are combined, the result is white/gray
Worked out by Hering around the same time of the Law of Three Primaries
Hering hypothesized 3 classes of photoreceptor, each with an opponency relationship
Trichromacy (neurophysiology) → photoreceptors
Three cone types were confirmed definitively by the 1960s
Later (1970s or so), color-opponent cells were discovered
Opponency → ganglion cells and beyond
Trichromacy at the level of photoreceptors and opponency in higher-order cells
3/31/36
The Law of Three Primaries (psychophysics)
Given control over the intensities of three different primary light sources (e.g., 450, 550, 700), any visible spectral color can be matched
Hypothesized Trichromacy
3 receptor classes with different peak sensitivities
The Law of Complementarity (psychophysics)
For any spectral color there is a complementary spectral color such that when the two are combined, the result is white/gray
hypothesized opponency
3 receptor classes with different opponent relationships
Trichromacy
population coding
the pattern of activity across a population of cells
None of us can know how any of us experience different colors, but we can measure which wavelengths can and cannot be discriminated.
Many cells (starting at retinal ganglion cells) exhibit opponency
“B-Y” RGCs tend to be non-articulated, which has implications for color-specific acuity differences
Trichromacy and Opponency reflect “color” vision at different levels of the system.
These neural mechanisms were hypothesized based on psychophysics before we had methods to confirm them.
Color Constancy
Discounting the Illuminant
Will be on the exam
We also use cues to infer spectral properties of the incident light and then discount it when interpreting the light at the eye.
Color Constancy
Discounting differences in stimuli due to differences in illumination conditions.
What color you perceive depends on your perception of the illumination source (we discount the perceived illuminant_
If the cues are especially ambiguous, then different people can perceive the nature of the illumination differently, and in turn will perceive the color of
Color Wrap up
Lightness is perceived reflectance, and color is perceived spectral reflectance. Lightness and color are psychological (they do not exist outside of our perceptual system). Reflectance and spectral reflectance are physical properties of surfaces.
The physical information that the visual system uses to infer lightness/color is luminance/spectral power. Luminance is the intensity of light as a function of wavelength; it can be measured with a spectrophotometer (power spectra).
To use spectral power to infer color, the visual system has to encode it - trichromacy (photoreceptors) and opponency (ganglion cells and beyond)
Color space (spindle) is very different from wavelength (linear), it reflects the way wavelength information is coded through trichromacy (hue categories) and opponency (saturation)
Trichromacy and opponency establish internal representations of the proximal stimulus (light at the eye) NOT the distal stimulus (surface reflectance) - there is a backwards optics problem
Inference-like process of lightness/color perception:
The nature of the light that is reflected from a surface (intensity/power spectrum) - A
The light that is shining on that surface appears to be (intensity/of the illuminant) - B
Given A and B, the surface must have this spectral reflectance function - C - color
The function of vision
Is to establish internal representations of the external world, such that we can successfully interact with it… and the external world is in motion… including ourselves.
Our sensory systems evolved in a dynamic world
Motion parallax (depth cue)
Objects at different depths move at different speeds on the retina
Optic flow
is the change in the optic array over time
It carries information about heading (self motion) and relative positions of objects in space relative to the observer
Many Functions of Motion in Vision
Identify where things are relative to other things (including ourselves), and where they are headed, including ourselves (optic flow) - talked about this in the depth, size, shape section of the course
4/7/26
The function of vision
Is to establish internal representations of the external world, such that we can successfully interact with it
and the external world is in motion, including ourselves
Motion (from a visual point of view) is systematic change in retinal location over time
Problems to solve:
Frame of reference → need to distinguish between change in retinal location due to object motion versus eye/head motion versus both
Motion detection → need neural mechanisms that register delayed (t2 - t1) activation of neurons with receptive fields at x1 and x2.
Correspondence → need to know that retinal stimulation at x2-t2 was caused by the same object (in the world) as the stimulation at x1-t1
Corollary discharge allows system to discount the changes in information on the retina that are caused by eye movements.
Reichardt Mechanisms
Neural mechanisms that are selective for specific spatiotemporal relationships (distance, direction, and delay/speed)
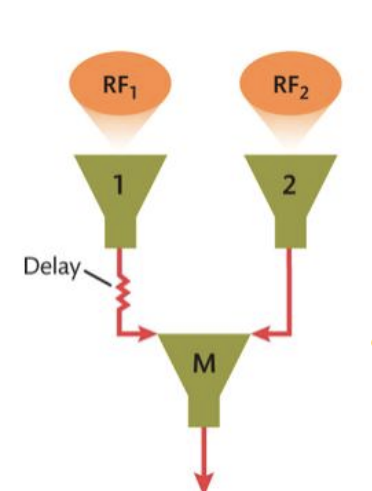
What 2 parameters determine the direction of motion that a RM is selective for?
1. Which lower-order cell is “cell 1” (i.e., has the delay)
2. The relative positions of the receptive fields of the two lower-order cells
What 2 parameters determine the speed of motion that a RM is selective for?
1. The specific delay of signal from cell 1 to M
2. The distance between the receptive fields of the two lower-order cells
Population coding for motion
Motion is represented by patterns of activity across sets of Reichardt mechanisms that are selective to different orientations and speeds
Reichardt mechanisms can’t tell the difference between apparent motion and real motion
M’s response to two sequentially flashed stimuli will be identical to its response to actual motion of an object in the world
“apparent motion” - motion metamers
Aperture problem (ambiguity)
Different directions of motion produce identical stimulation with an aperture. Notice that receptive fields are apertures!
The shape of the aperture determines the perceived direction of motion. - Barber pole illusion
4/9/26
Reichardt Mechanisms (higher-order cell) (Motion detection)
Lower-order cells → RF1 & RF2
Only works if it goes at the correct speed and correct direction and the same delay.
Reichardt Mechanisms and the Motion After Effect
two oppositely tuned Reichardt mechansims
connected to a single higher-order unit (one excitatory and one inhibitory)
Oppenency in motion
above baseline → leftward motion
below baseline → rightward motion
baseline → no motion
Where might Reichardt mechanisms be within the visual system?
If you close one eye and adapt, you won’t get a color after image in the unadapted eye
If you close one eye and adapt, the other eye will gett a motion after effect in the unadaptted eye
Motion Aftereffect (MAE) results from fatguing opponent-motion-selective cells in area MT.
Correspondence problem
need to know that retinal stimulation at x2-t2 was caused by the same object (in the world) as the stimulation at x1-t1?
The problem of knowing what went where when
if you change how you resolve correspondence, you change what motion you perceive.
Ternus Motion (1926)
Interstimulus interval (ISI)
Short ISI → “element motion”
Long ISI → “group motion”
Which motion is perceived implies a different resolution to the correspondence problem. Therefore, perceived motion provides a measure of the correspondence process.
The dependence of perceived motion on ISI, confirms that spatiotemporal cues are used to resolve correspondence.
Feature cues are used to resolve correspondence. Notice that feature cues can completely dominate (override) spatiotemporal cues.
The correspondence problem for motion is solved on the basis of spatiotemporal continuity (space/time proximity) and features.
and global variables as well (which are neurally more mysterious)
The wagon wheel illusion (wheels appear to be moving backwards) - incorrect resolution of the correspondence problem
Motion Wrap up
The external world is dynamic, and so are we
So, motion is part of what we seek to represent internally and use to guide our action
As a (proximal) stimulus, motion is systematic change in retinal location over time
Must distinguish between change in retinal location due to object motion versus eye/head motion?
Corollary discharge - extra-retinal information factored into our visual perception!
Need neural mechanisms that code for stimulation at a specific locations at specific delays
Reichardt mechanisms
Correspondence problem - need to know that retinal stimulation at a given location at an earlier time was caused by the same object (in the world) as the stimulation at this new location now?
Solved through use of cues about spatiotemporal coherence and feature matching, including global shape.
4/16/26
The function of any sensory system
is to establish internal representations of the external work such that we can successfully interact with it.
The starting point of all sensation is some source of the energy that carries information about the external world
EM energy (waves/oscillations)
lawful light-surface interactions
The starting point for hearing is waves too
pressure waves
Sound consists of (air) pressure waves
high concentration → compression
low concentration → rarefaction
Sound waves
Like all waves, sound waves are defined by their wavelength and amplitude
Frequency = cycles/second (Hertz, Hz)
There are physical and perceptual dimensions of sound
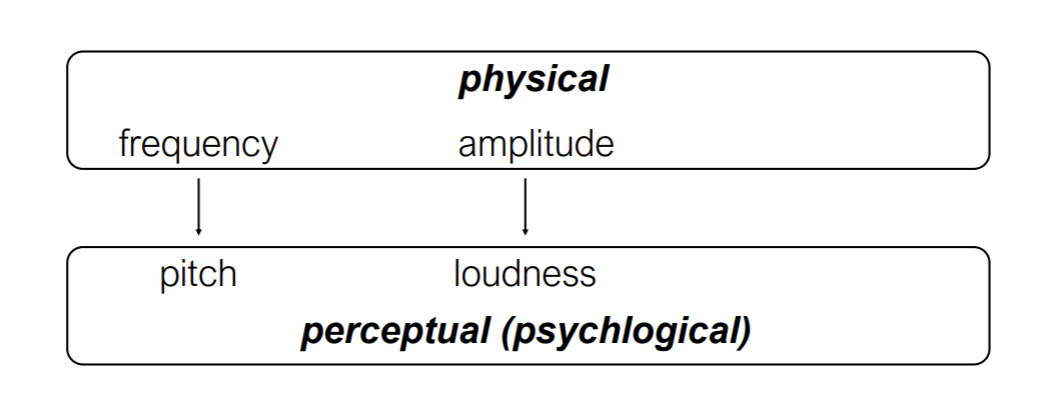
Amplitude is measured in decibels (relative pressure units)
Alexander Graham Bell
Every 20 dB is a log unit of intensity change.
Notice that dBs are on a logarithmic scale
So 90 to 100 is much more of a change than 10 to 20
Prolonged exposure above 90 dB can cause permanent hearing loss.
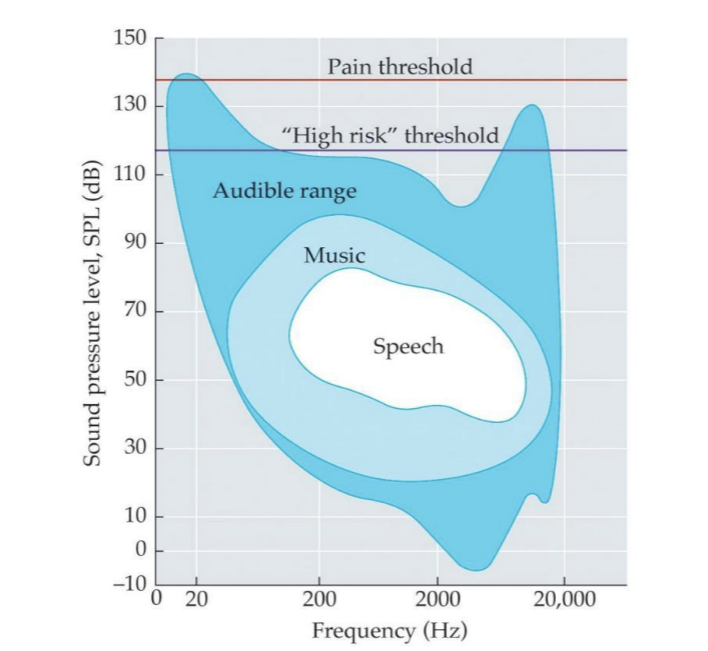
Remember the Contrast Sensitivity Function in Vision?
Visibility depends on (spatial) frequency
Human hearing uses a limited range of frequencies and sound pressure levels
All natural sounds are complex and have multiple frequencies embedded in them.
Fourier analysis
A mathematical theorem by which any complex waveform can be divided into a set of sine waves (pure tones)
Recombining the composite sine waves will reproduce the original sound
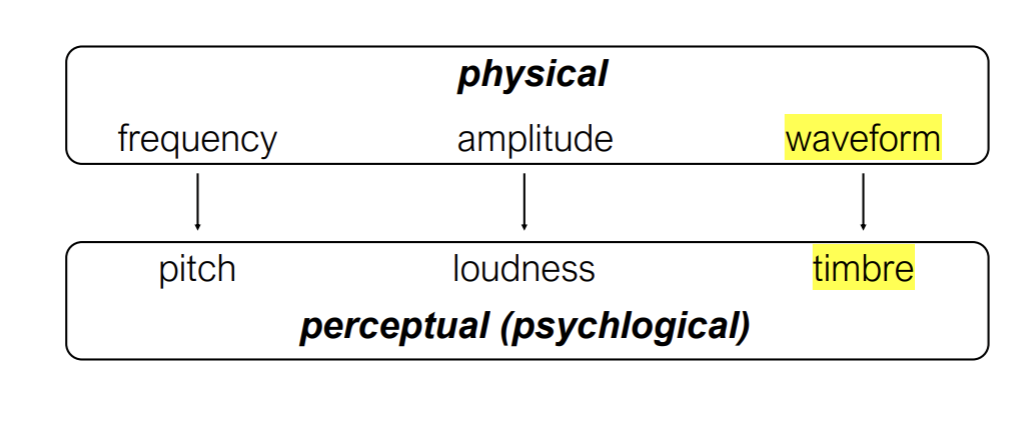
A musical instrument plays a note that is defined (to our hearing) by its fundamental.
Different instruments can play a note with the same fundamental, but with different patterns of harmonics (overtones)
The particular pattern of harmonics determines the timbre of a sound.
Musical instruments are classified by what part vibrates and creates compression waves.
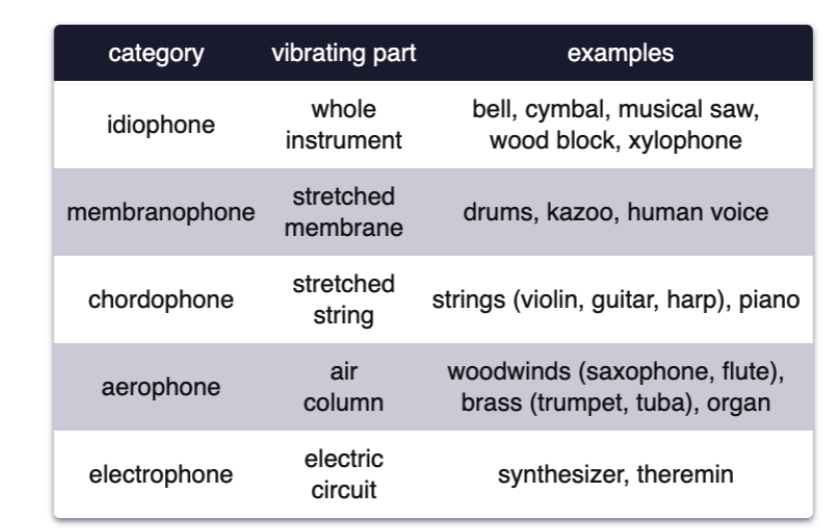
The spectrum (power at different frequencies) changes over time.
Compare:
Recall that visual images can also be described in terms of a sum of sine wave components, each defined by (spatial) frequency, contrast (amplitude) and orientation.
The auditory system decomposes natural sounds into sine-wave components over time.
The visual system decomposes natural images into sine-wave components over space.
Just as the retinal image carries information about the external world because it is determined by lawful light-surface interactions… sound carries information about the external world.
Sound waves interact (lawfully) with surfaces and materials (location, action, type of material).
Different things produce reliably different sounds (bird, car, frog, human voice).
Speech and other communication
Music
As with light, information carried in sound can be useful for representing the external world internally only if there is a system that is sensitive to it.
The first step is “presenting” the information (stimulus) to the system and encoding the pattern as neural code.
The outer ear guides sound waves toward the cochlea and interacts with them.
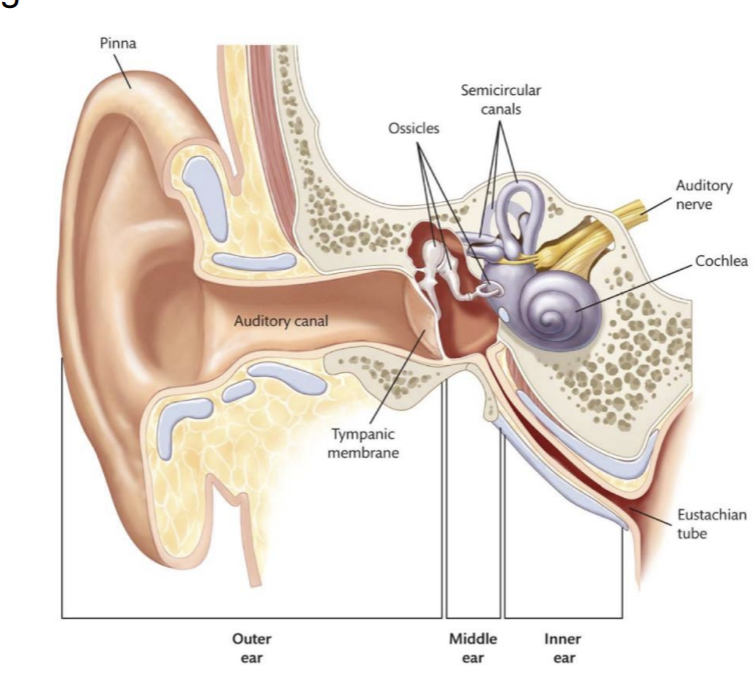
The middle ear amplifies sound waves and transmits the energy from air to fluid within the inner ear.
Amplification occurs through two mechanisms
the lever system of the ossicles
the transmission of sound waves from the (large) tympanic membrane to the (15-20 times smaller) oval window.
The inner ear
The cochlea is functionally analogous to the retina
is equivalent to the retina where transduction occurs
4/21/26
Made a transition from vision to hearing, and the general function is the same
Establish an internal representation of the external world such that we can successfully interact with it.
Based on sound instead of light
The higher the amplitude → louder the sound
The middle ear amplifies sound waves and transmits the energy from air to fluid within the inner ear.
Amplification occurs through two mechanisms
the lever system of the ossicles
the transmission of sound waves from the (large) tympanic membrane to the (15-20 times smaller) oval window.
Organ of Corti gets pushed up by hair cells
As the Basilar membrane displaces up, the hair cells on top of it get pressed against the Tectorial membrane, triggering transduction.
The Basilar membrane is like a tube man in your inner ear.
The peak of the wave determines the peak of the force.
The greater the force, the higher the firing rate.
Frequency → tonotopy
high frequency sound is coded toward base of the cochlea and higher frequency toward the apex.
Place Code for frequency
Tonotopy (frequency-time) is like Retinotopy (space)
Therefore, which hair cells are activated - and thier relative activation levels - is systematically related to the frequency content of the sound (i.e., its an internal representation of the external world)
Outer hair cells act to amplify and sharpen the tuning functions of auditory nerve fibers
Selectivity for ~8000 Hz is enhanced by outer hair cell activity
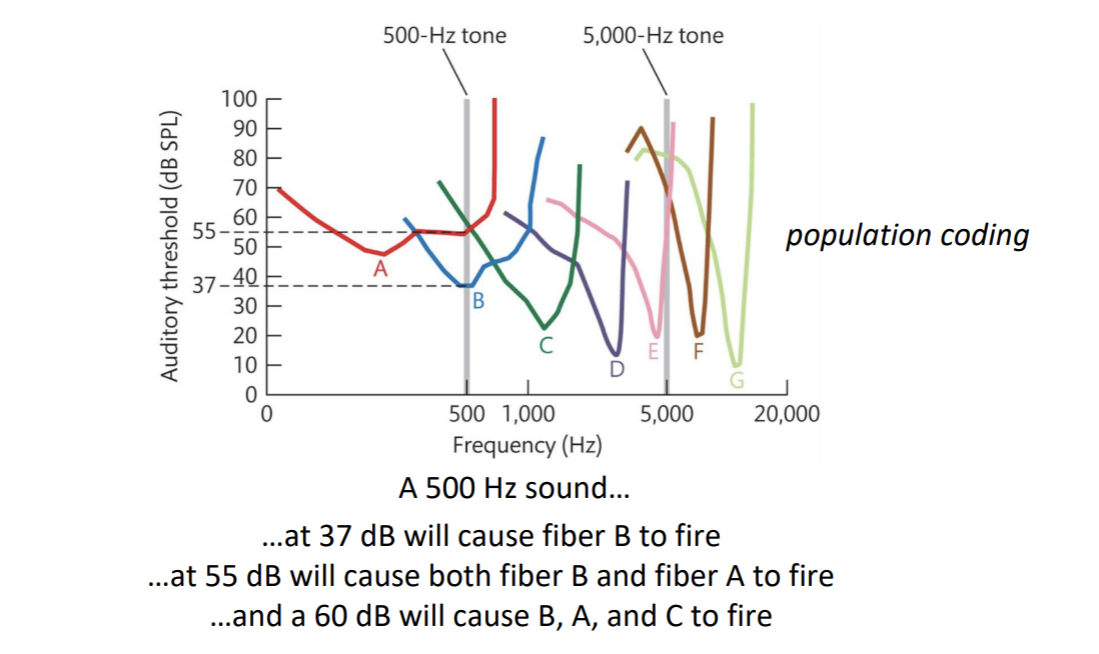
Auditory nerve fibers are selective for different frequencies (allows for population coding of complex sounds)
They tend to be sharper (and more sensitive) for higher frequencies compared to lower frequencies.
Frequency information is also coded on the basis of the temporal pattern across a set of auditory nerve fibers.
This is a form of population coding known as the volley principle.
Generally, the more hair cells that are bent, the higher the firing rate.
But the range of amplitudes that we can hear is much greater than the range of firing rates of individual auditory nerve fibers
Auditory nerve fibers with similar characteristic frequencies but different dynamic range profiles also carry information about amplitude.
Amplitude information is given by an increase in the number of nerve fibers that respond to a given frequency as amplitude increases.
Waveform is represented through effective Fourier analysis.
The cochlea is essentially a Fourier analysis machine.
Auditory Disorders
Things can go wrong in a variety of ways
Conduction problems (outer and middle ear)
getting a good quality sound to the appropriate part of the ear
Basilar membrane wear (aging)
As we age, we lose high frequency information…think about the fatigue of the basilar membrane and its corresponding hair cells.
Hair cell loss (inner or outer)
Dislodging of Basilar membrane anchor
Tinitus
Cochlear Implants
sensorineuro deafness
There are retinal implants…but they are complicated
Hearing Aids for Conductive Impairments Have Different Issues.
They have to compress the range of sounds - and different compression functions optimize different needs (speech, speech in noise, music, etc.)
Vestibular Disorders
Things can go wrong in a variety of ways
Abnormalities with calcium crystals (“ear rocks”)
Meniere’s disease → too much fluid in the inner ear
Inner-ear infection
Structural - tear between middle ear and inner ear (disrupts fluid volume and flow)
A1 tonotopically organized as V1 is retinotopically organized
There are also separated “what” and “where” pathways in audition, like vision
Hearing What and Where
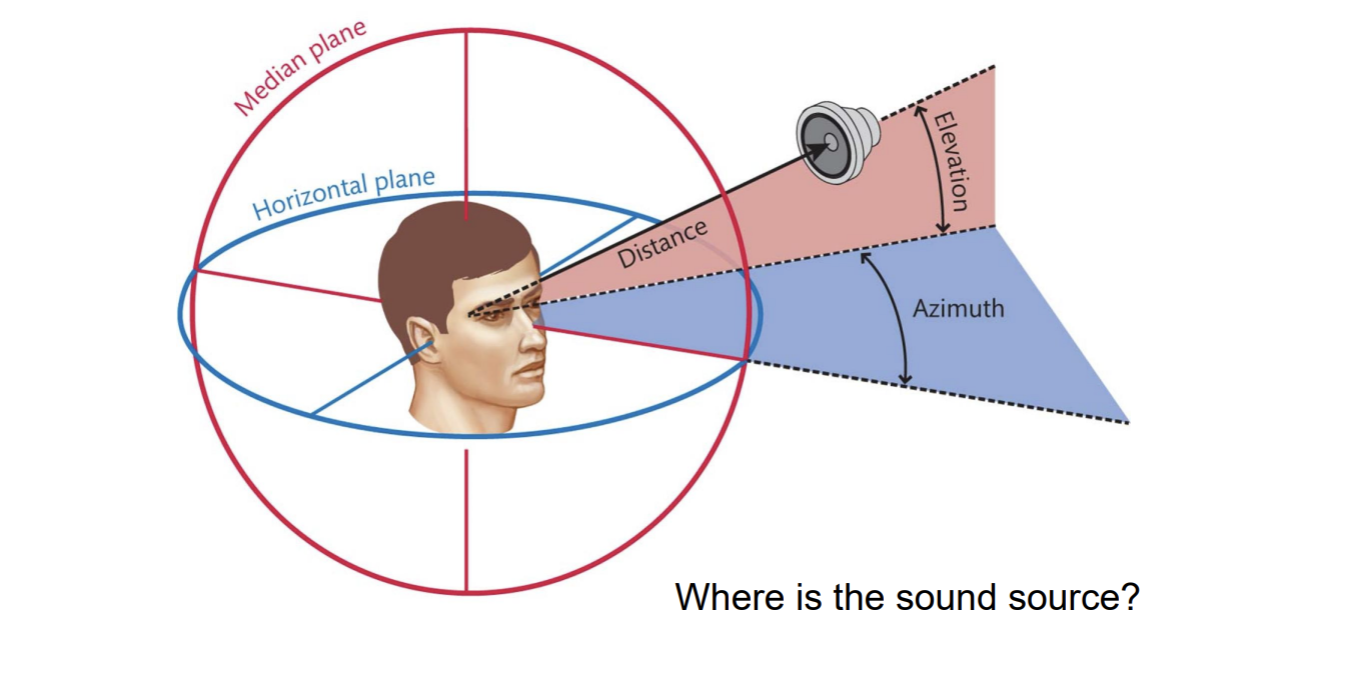
People are pretty good at localizing sound…both azimuth and elevation
Sound reaches the two ears at different times and intensities, similar to how images project to the two eyes at different retinal locations.
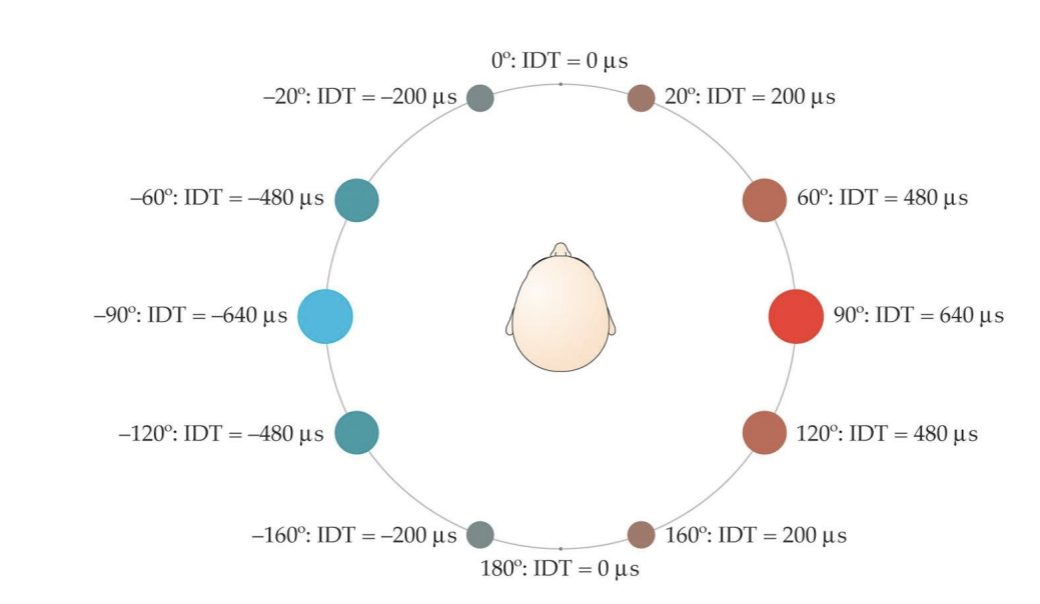
Interaural time difference (ITD) carries information about location (along the azimuth) of the sound of the source.
People can detect ITDs as small as 10 microseconds, meaning 1 degree of spatial angle here.
Your head creates a sound “shadow” that reduces the intensity of the sound at the ear that is in the shadow…which creates an intensity difference between the two ears that depends on where the sound source is relative to the two ears.
There is more interference for high-frequency sounds than low-frequency sounds.
Interaural level (intensity) difference (ILD) carries information about location (along the azimuth) of the sound source.
Higher frequencies are disrupted more, causing them to have larger ILD differences as a function of location
Higher-order cells in the brain stem (medial superior olive) respond selectively to different ITDs
Note similarly to Reichardt Mechanisms and binocular neurons)
Ambiguity in ITDs and ILDs for sound localization.
Cones of confusion → Regions of positions in space where all sounds produce the same time and level (intensity) differences (ITDs and ILDs).
4/23/26
People are pretty good at localizing sound - both azimuth and elevation.
Sound reaches the two ears at different times, creating interaural time differences (ITDs).
Interaural time difference (ITD) carries information about location (along the azimuth) of the sound source.
Your head creates a sound “shadow” that reduces the intensity of the sound at the ear that is in the shadow creating interaural intensity (level) differences (IILD).
There is more interference for high-frequency sounds that low-frequency sounds.
Interaural level (intensity) difference (ILD) carries information about location (along the azimuth) of the sounds source.
Higher frequencies are disrupted more, causing them to have larger ILD differences as a function of location.
Ambiguity in ITDs and ILDs for sound localization.
Experiment by Hans Wallach
subject sits with head unmoving
creates the (illusory) sense of self motion of rotation - vection
tone played directly in front (0 azimuth, 0 elevation)
rotating drum (the door closes), head position is fixed.
they hear the tone directly above or directly below (weird)
Why?
Those are the only two locations
Notice the inference-like process that resolves the ambiguity of ITDs/ILDs analogous to those we saw in vision.
the information that I have at my ears is a constant 0 ITD and ILD
the position of my ears is changing over time
In order for both of those to be true, the sound must be coming from a location where the ITD and ILD is constant relative to my ears (directly above OR directly below)
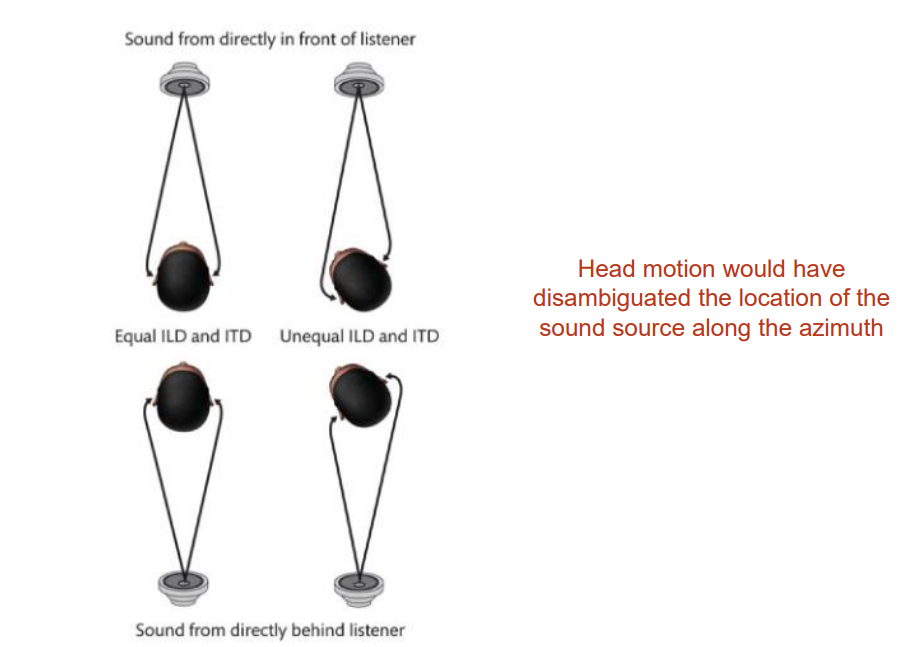
ITD and ILD, combined with strategic head positioning, provides good information about positioning along the azimuth.
Elevation… not so much
Remember talking about how ears (pinnae) are so weird?
They do more than just funnel sound down the tympanic membrane.
Everyone has a unique head-related transform function. (the way in which sound is changed by interacting with the folds of your pinna)
It also depends on (i.e., carries information about!) about elevation.
Measurement of localization ability with subject’s own pinnae
Insert prosthetic pinnae with different folds (and therefore head-related transform function)
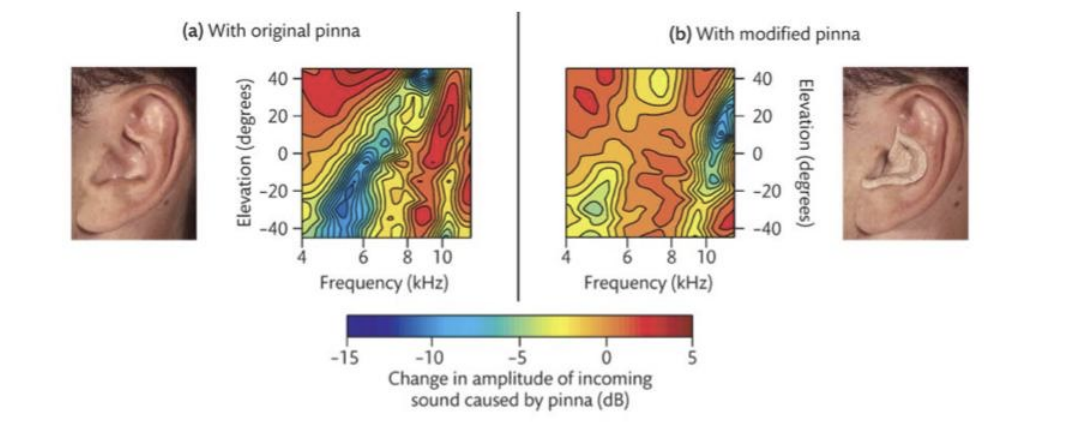
Subjects learned to use the new head-related transform function over time.
Distance
Auditory Distance Perception
Relative intensity → provides some information
Works best when sound source is moving
Ambiguous! (farther away or less intense?)
Moreover, its usefulness is limited in range because of the Inverse-square law
Inverse-square law → intensity decreases with the square of a source’s distance.
Doppler Effect (sound) ←→ Redshift (Light)
Reverberation (echo) provides information about distance.
And, if you have the sensory apparatus to encode and interpret it, echos provide exquisitely rich information about the external world. Echolocation.
Visual cortex is recruited for echolocation in blind individuals.
Contrast with Vision
We cannot produce the stimulus of vision (light)
Though way back when (starting in 400 BC and continuing through ~ 200 AD), extromission theories of vision were popular
Glowing eyes were interpreted as light sources
Lidar - is like “echolocation” with light
Hearing What auditory scene analysis (perceptual organization in hearing)
All sounds (from separate sources) reach the ear as a single complex wave form.
Fourier analysis decomposes complex waveforms into component sine waves…not into component sound sources.
Fourier analysis is good for encoding the physical attributes of the stimulus, not identifying what in the world produced the stimulus.
Perceptual Organization in Audition
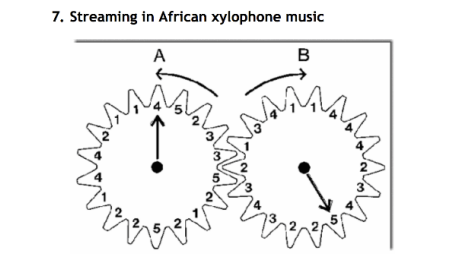
Auditory streaming (perceptual groups)
Grouping based on frequency and temporal proximity
Stream segregation in a cycle of six tones
Pattern recognition, within and across perceptual streams
De-camouflaging based on frequency
Segregation of a melody from interfering tones
4/28/26
Auditory Perceptual Organization
Perceptual organization in Audition
Auditory streaming (perceptual groups)
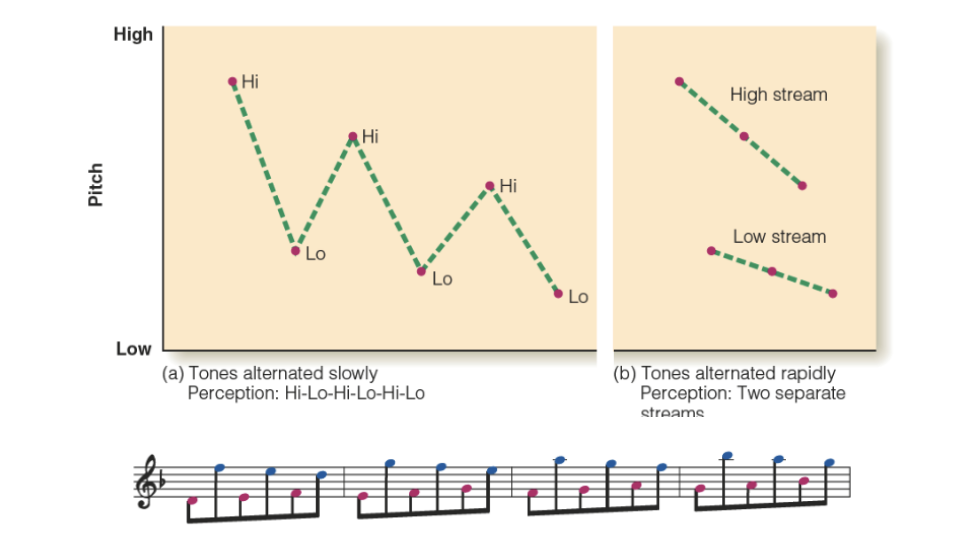
De-camouflaging based on frequency
Grouping based on frequency
Each time, increasing the pitch range of the melody
Segmentation/grouping based on spectral content
Like common-fate grouping cue in vision
Grouping/Parsing by Timbre
Same timbre asynchronous melodies form a whole
A plays alone
B is added so that both are playing (lose A can’t isolate B)
A drops out (can now hear B for the first time)
A rejoins (both A and B are lost)
Example of “the whole is greater than the sum of the parts” in audition
Continuity and Restoration Effects
Perceptual completion (filling in of inaudible information)
Notice the analogousness across sensory modalities perceptual completion (representing the invisible/inaudible)
Phonemic Restoration Effect
Gap in the speech signal
Difficulty recognizing the word
Still gap in the speech signal… but a noise burst “explains” the gap
No difficulty recognizing the word; in fact, we hear (perceive) the whole word.
Hearing What is more than parsing and organization.
Not simply organization, but information about what is making the sound.
Dynamic components (onset/offset and change in frequency content)
Discriminate different instrumental sounds
Discriminate different speech sounds
Speech Production: respiration (lungs), phonation (vocal folds), articulation (vocal tract)
Harmonic spectrum: Base sound is produced (lungs and larynx - Buzzzz)
Filter function: Filtered (vocal folds and vocal tract)
Vowel output: Speech sounds
A phoneme is the smallest unit of sound in speech.
Voicing → whether or not you are using those vocal folds to make the sound
Frequency content (perceived as timbre)
distinguishing speech patterns
Music Perception
The function of music perception is different
It does more/something different than other modes of perception
Notes, rhythm, and melody
Entrainment, emotion, memory
Health and healing
Octave → doubling frequency
Many different scales are used across cultures
Heptatonic scale versus pentatonic (seven versus five notes to the octave)
The fewer the notes, the more loosely tuned the scale is (wider ranges of pitches qualify as a given note)
Chords → 3 or more notes (can be played at different heights) we think of them as we play them together. Can be played over time and that is called broken chords.
4/30/26
Consonance vs Dissonance
Consonant → simple ratios (1:1, 2:1)
Dissonant → complex ratios. Defined by the stimulus.
Rhythm
Patterns of stress/unstress
We feel it and we create it
We perceive patterns of stress/unstress even when the stimulus is continuous.

Syncopation
Breaking expected patterns of rhythm
Need both expectation AND violation of expectations
Humans looovee it
Syncopated Polyrhythms
We sync them up
Beats are happening, and out of sync with each other, and over time, we psychologically sync them together. We shift where we hear the beats so they form a unified pole.
Melody
A psychological entity
An agreeable succession of sounds defined psychologically
Twinkle twinkle little star, abc’s, ba ba black sheep all have the same melody
Music perception functions differently from other modes of perception
It is more than audition
It is more than multisensory
It is multisystemic
Audition (yes)
Motor
Emotion
Memory
Neural entrainment and synchrony
Neural entrainment and synchrony
The stimulus entrains neural activity and synchronizes neural activity across systems
Why do we respond to music the way that we do?
The function of music perception is NOT (simply) to establish an internal representation.
Audition wrap-up
Frequency and amplitude are the core codes for audition; the cochlea is effectively a Fourier Analysis system; the brain interprets the frequency content.
Where processing: Interaural time/level differences serve as cues for localization along the azimuth; systematic distortions of sounds by the ear serve as cues to elevation; changes in intensity serve as cues to distance; these are all analogous to depth cues in vision.
Ambiguities must be resolved - we see the same kind of inference-like processes in audition as we saw in vision (Wallach spinning-drum experiment)
What processing: The auditory “image” (single pressure wave at the ear) must be parsed, identified, and understood in context, just like the visual image (pattern of light at the eye) - perceptual organization and recognition.
The function of music perception is different. It’s good to be human!
5/5/26
The function of any sensory system (except music perception)
is to establish internal representations of the external world such that we can successfully interact with it… and as usual to start, we need information about the external world that can be converted into internal representations.
Smell and taste are different from other senses because the part of the external world that is represented is taken into the body
The stimuli are chemicalss
Odorants
chemical compounds that are volatile (float through the air) and are hydrophobic/lippophylic
Tastants
chemical compounds more generally
The chemical senses are the phylogenetically oldest of the senses
Highly adaptable (across species, within species, and within individual)
Genes coding for receptors tend to be at locations where recombination is most rapid
Receptors regenerate frequently
Humans have ~900 receptor genes only 400 expressed; which can vary with group and individual (even varying within individual over time)
Chemicals carry information about important aspects of the external world
Predators
Mates
Food
Navigation
Nutritional Content
Poison
Smell and taste are sometimes referred to as gatekeeper senses
They reinforce the ingestion of “good” things and punish (reject) the ingestion of “bad” things
Olfaction
Olfactory System
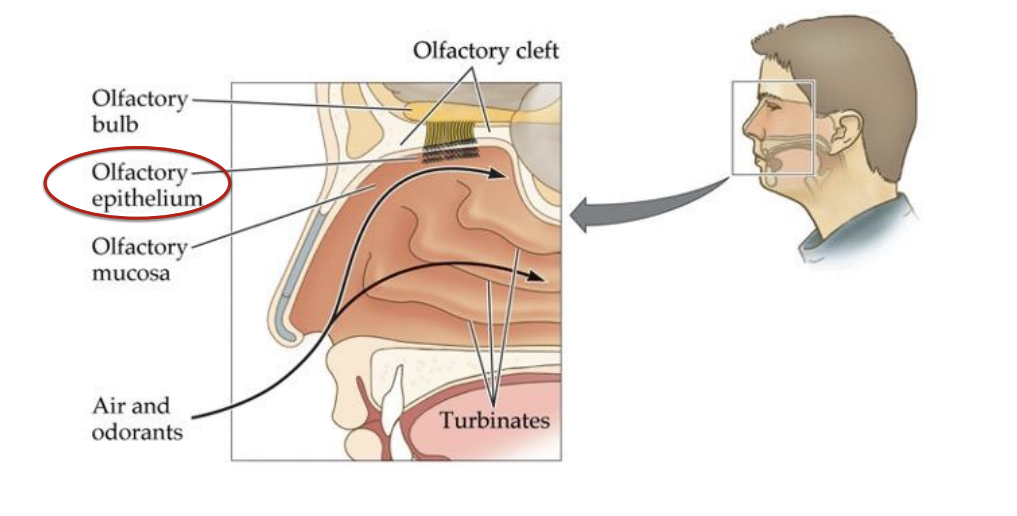
Analogous to the retina in vision and the cochlea in audition
Retronasal olfaction (mouth to olfactory epithelium)
Orthonasal olfaction (nose to olfactory epithelium)
Olfactory bulb → to primary olfactory cortex and other brain structures → Mitral cell → Glomerulus → Cribiform plate → Olfactory nerve → Olfactory sensory neuron → Olfactory cilia → receptor → odorant molecules
Coding Oderants
Olfactory Receptors (ORs) respond based on molecular shape - the closer the match the stronger the response.
1:1:1 rule
Each OR* is selective for 1 odorant
Each olfactory sensory neuron has only 1 type of OR
Each mitral cell carries information from 1 type of olfactory sensory neuron to the brain
OR* = Odorant receptor
Remember how wavelength content is coded by patterns of firing across the three types of photoreceptor?
Olfaction is analogous to color vision in that odors are coded as a pattern of responses across OR types however…
Recall: Color space (psychological) reflects the nature of the stimulus (wavelength) interacting with our particular system (trichromacy and opponency)
A difference between color vision and olfaction
Whereas there are 3 types of cones, humans have ~400 (functional) ORs.
So, whereas humans can (in principle) discriminate among about 75 million different colors
We (in principle) have the potential of discriminating about 1 trillion different odorants… but we can’t really.
We actually have ~900 genetically distinct ORs but only about ~400 become functional… which ones are functional varies across groups of individuals, individuals within a group. and within individuals across time.
Dogs have twice as many active OR types and about 100 times as many units as humans
Elephants have nearly 2,000 active OR types and 1-2 billion units
But it’s not as straightforward as the numbers would suggest
Acuity depends on brain processing as well as the potential number of unique patterns
Abilities are odorant-specific (humans are more sensitive to some odorants than dogs are)
Differences in sampling behavior.
It’s kind of a myth that humans are not good with smell.
Humans were able to follow a 10-meter-long scent track of chocolate aroma while on all fours in an open grass field… and did it very similarly to a dog tracking pheasant.
Pheromones (different from odorants)
Pheromones are chemicals that are emitted by one member of a species that trigger a physiological or behavioral response in another member of the species.
They can, but do not always activate ORs (i.e., they may or may not have an odor - perceptually detectable)
They mostly function through a separate system
Vomeronasal Organ → Accessory Olfactory Bulb
There is no compelling evidence that humans respond to pheromones
We do not have an accessory olfactory bulb
We also do not have vomeronasal organs
McClintock’s report that women who live together begin cycling together proved to be an artifact; and no new evidence has been found to support the claim.
Associative learning, however, DOES occur strongly with olfactory stimuli in humans
Coding Odorants as Tactile Stimuli
Some ORs are polymodal nocioceptors that project to somatosensory areas (via the Trigeminal nerve) as well as olfactory areas
Plug your nose when you cut onions because it sends signals to the trigeminal nerve and makes the eyes water/sting. There is no juice going in the eyes.
Olfactory Adaptation (decreasing sensitivity)
Olfactory adaptation is rapid
Sensitivitty can drop by 50% within seconds, and insensitivity can occur within minutes.
Speed varies across individuals and odorant (type and concentration)
Mechanism
Receptor recycling can’t keep up
Cognitive habituation (e.g., to your home)
Functional Benefit - olfaction is all about detection of change
Oddly, sniffing through cotton fabric can reset things - perfumer’s trick
There is clear chemotopic (or odortopic) organization in the olfactory bulb (e.g., longer chains are represented in more leftward areas)
This is like retinotopic and tonotopic representation in vision and audition.
Similarly selective ORs converge on common glomeruli and mitral cells
Remember the 1:1:1 rule
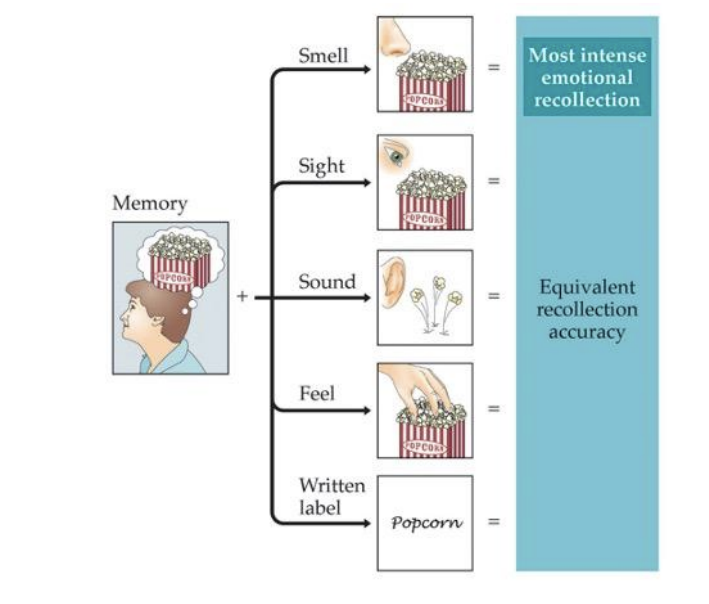
Olfaction and Memory
“The smell and taste of things remain poised a long time, like soulds, ready to remind us…” - Marcel Proust
Olfactory Hedonics
The extent to which we like or dislike the smell of a given chemical depends on the chemical itself and the intensity
Given the gatekeeper role of the chemical senses, people looked for molecular bases for preferences that might be common to all members of the species.
Ex: It was found that the more oxygen atoms there were in a chemical, the more pleasant it was perceived across multiple cultures.
Nature not nurture
Associative Learning and Emotion/Hedonics
In two large-scale studies in 1960’s and 70’s - one in the U.S. and one in the U.K. - individuals provided hedonic ratings for a set of common odors
Both studies included wintergreen as an item
It was one of the lowest rated odors in the British study and the top-rated odor (of the set) in the U.S. study.
Nurture not nature
5/7/26
Gustation
Smell and taste are sometimes referred to as gatekeeper senses
They reinforce the ingestion of “good” things and punish (reject) the ingestion of “bad” things.
Four Basic Tastes
Sweet (sugars)
Salty (sodium)
Sour (acids)
Bitter (various poisons)
What makes something a “basic taste”
Dedicated receptors
Specific biochemical physiological reaction
Produces a discrete sensation that is not confusable with any other basic taste
Has meaning ecologically with respect to the environment that it represents
Basic tastes are in place from birth
A proposed 5th basic taste has been proposed
“deliciousness”
savory or “meaty” taste
Proposed as a signal for amino acids to regulate protein intake
Problems:
Amino acids are too big to be detected by selective receptors
Sensation is often confused with other basic tastes (typically salty)
Does not connect to any one thing that is good (or bad) for us (protein doesn’t work because mushrooms and bread are strongly associated with the umami experience).
NO!
It was not actually Häning, the German physiologist, who was at fault for propagating this map. It was E.G. Boring, the American Psychologist, who tried to translate the work and totally booted it.
Taste Papillae → map of the tongue
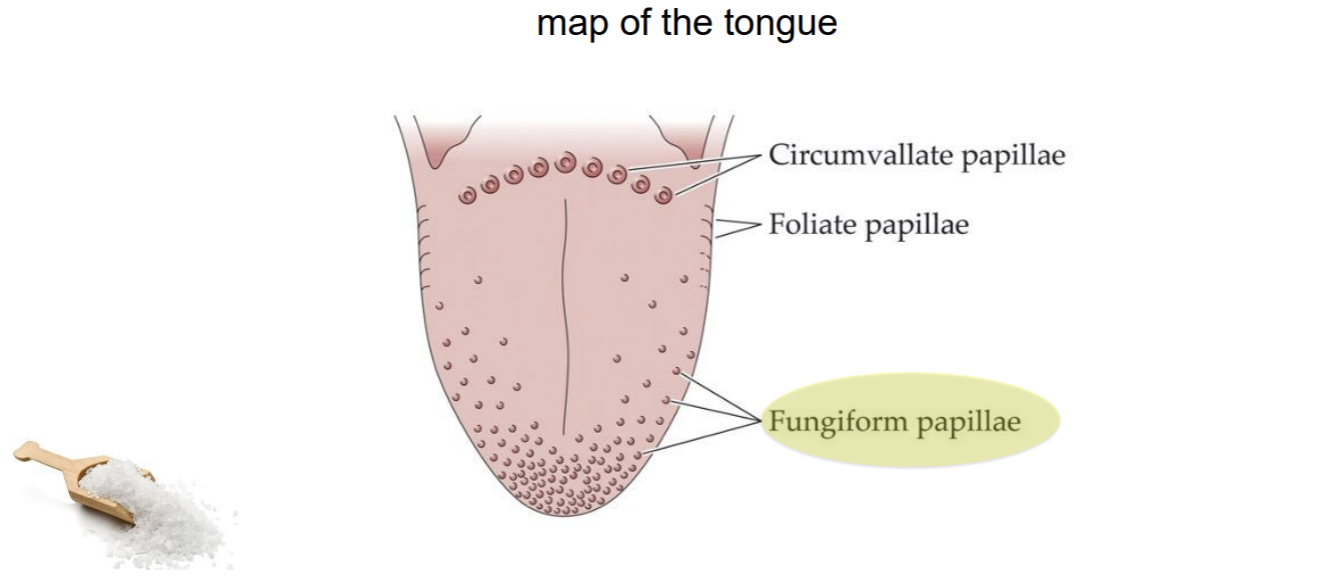
There are also some taste buds on the roof of your mouth way in the book
Gustatory System
Taste buds are tucked inside the papilla
Different cells (within a bud) are selective for sweet, bitter, salt, and acid (sour)
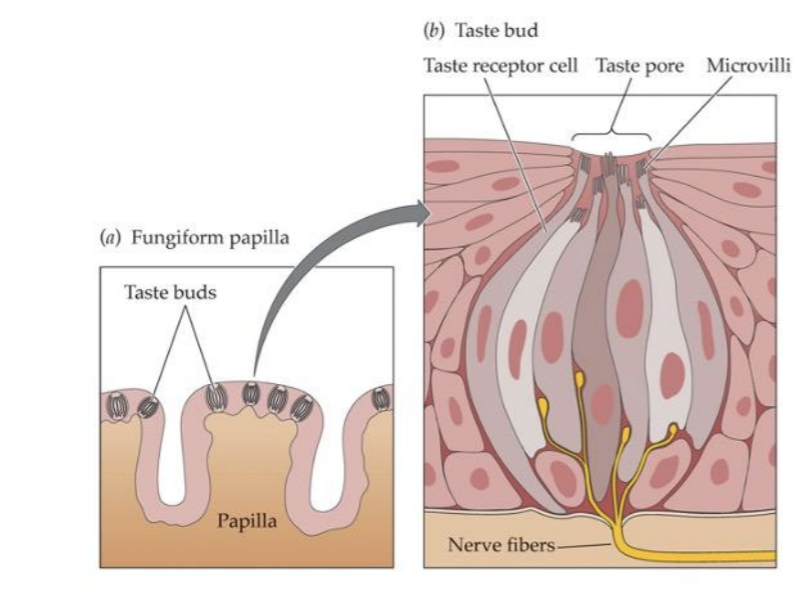
The density of fungiform papillae varies across individuals
Genetically determined
Related to ability to taste certain compounds (as bitter)
Related to sensitivity to capsaicin
Remember magnitude estimation?
Using cross-modal magnitude estimation, it was possible to quantify experienced intensity?
There are not just tasters and non-tasters; there are SUPERtasters.
Its Genetics (super taster/taster/non-taster)
Super Tasters (~25% of population)
Tend to be picky eaters
tend to avoid leafy greens
tend to dislike beer and other alcohol
less likely to smoke
put lots of salt on bitter foods (salt blocks bitter receptors)
lower BMI
NonTasters (~25% of population)
Tend to like/tolerate super spicy food
tend to use a lot of salt
more likely to smoke
more likely to become an alcholic
lower rates of some cancers
higher BMI
So, the process…
Chewing breaks down food substances into molecules, which are dissolved in saliva
Saliva-borne food molecules flow into taste pores that lead to the taste buds
Molecules bond with receptors specific to four basic tastes
Signals are sent from taste receptors via three cranial nerves to the thalamus and on to (primary gustatory) cortex, and eventually the orbitofrontal cortex (as with olfaction)
Notice: Much less direct pathway to the brain for taste than for smell where receptors in the olfactory epithelium project directly to the olfactory bulb, which projects directly to the amygdala/hippocampal complex and the primary olfactory cortex in parallel.
Taste is not flavor
Flavor is what we really mean when we say something tastes good (or bad)
We actually rarely experience taste
Flavor - Taste + Olfaction
Oderants coming in through the mouth are processed along a different pathway to the brain (along with that processing tastants) than odorants coming in through the nose.
This contributes to the complexity of flavor but it also reflects a functional role…the importance of (say, bad) odors in the environment and detected at the nose versus ingested into the body is different.
So the difference in signaling (nose versus mouth) codes for that important differences in the world
Sweetness can be enhanced through volatiles (odorants)
“sweet” with less sugars
Chemical senses wrap up
Chemical senses are critical to survival
They are unusual (among the sensory modalities) in the way they “represent” the external world… they take the external world in.
They serve gate-keeping functions, and such are “change detectors”
Individual experience is particularly individual (compared to other senses)
Olfactory space is unfathomably complex
Taste space is (relatively) simple (four basic tastes and their combinations…umami is probably not a basic taste)
Flavor is altogether a different thing
Taste + Olfaction = Flavor