clases
07/01/2025
La estadística y sus aplicaciones
La estadística implica información, números, gráficas visuales para resumir información y su interpretación.
La estadística descriptiva → es la parte de la estadística que estudia las técnicas y métodos que sirven para la observación, toma, organización, descripción, presentación y análisis de datos.
La estadística inferencial → es la parte de la estadística mediante la cual se intenta dar explicación, concluir o inferenciar sobre los experimentos y fenómenos observados, mediante el auxilio de la probabilidad estadística descriptiva y distribución de probabilidad, por lo que resulta una herramienta de suma utilidad para la toma de decisiones.
Se aplica en conta, finanzas, marketing, negocios y economía.
09/01/2025
Dato→ son hechos, informaciones y cifras que se recogen, analizan y resumen para su presentación e interpretación. A todos los datos reunidos para un determinado estudio se les llama conjunto de datos para el estudio.
Variable→ se considera como toda característica medida en un estudio, se realice su medición en números (edad o peso) o en categorías. Se denomina variable porque, aunque podemoste prever los valores posibles, el valor observado en un momento dado en un individuo, grupo, comunidad o población es cambiante.
escala de medición → la escala de medición es una clasificación acordada con el fin de describir la naturaleza de la información contenida dentro de los números asignados a los objetos y por lo tanto, dentro de una variable.
medida nominal → en una escala nominal es facial generar respuestas utilizando preguntas cerradas, es por eso que se pueden recopilar muchas respuestas en un corto periodo de tiempo, lo que a su vez aumenta la confiabilidad de respuesta
escala ordinaria → es uno de los niveles de medición que se otorga la clasificación y el orden de los datos sin que realmente se establezca el grado de variación entre ellos. La escala de medición ordinal permite clasificar los datos en un orden específico, pero no proporciona información sobre la magnitud de las diferencias entre los niveles, como en el caso de clasificaciones de satisfacción o rangos de preferencia.
Escala ordinal → se utiliza como parámetro para ver si las variables son mayores o menores. La tendencia central de la escala ordinal es la mediana.
escala nominal → se utiliza para categorizar datos sin un orden específico, permitiendo agrupar elementos en clases distintas sin implicar que una categoría sea superior a otra.
Escala de intervalos → se define de manera cuantitativa (numéros) en el que se mide la diferencia de dos variables. 0 = arbitraria ejemplo → NPS
Escala de razón→ en esta escala se le da también un sentido a las razones entre dos medidas, es decir las veces que una medida contiene la otra, se distingue si se obtiene un cero absoluto;.
14/01/2025
Estadística descriptiva
Distribución de frecuencia → resumen tabular de datos que muestra el numero (frecuencia) de elementos en cada una de varias clases que no se superponen. Se pueden ver varias categorías cualitativas y se puede ver como se distribuyen y con cuanta frecuencia se hacen
Sumatoria de frecuencias = muestra
Distribución defrecuencia relativa y porcentual → Lo que interesa es la proporción o porcentaje de elementos en cada clase. La frecuencia relativa de una clase es igual a la fracción o proporción de elementos que pertenecen a cada clase.
Relativa → decimal porcentual → porcentaje
frecuencia relativa de una clase = frecuencia de la clase / n
16/01/2025
Tabulaciones cruzadas y diagramas de dispersión
Se emplean para resumir datos que revelan entre dos variables.
Ejemplo:
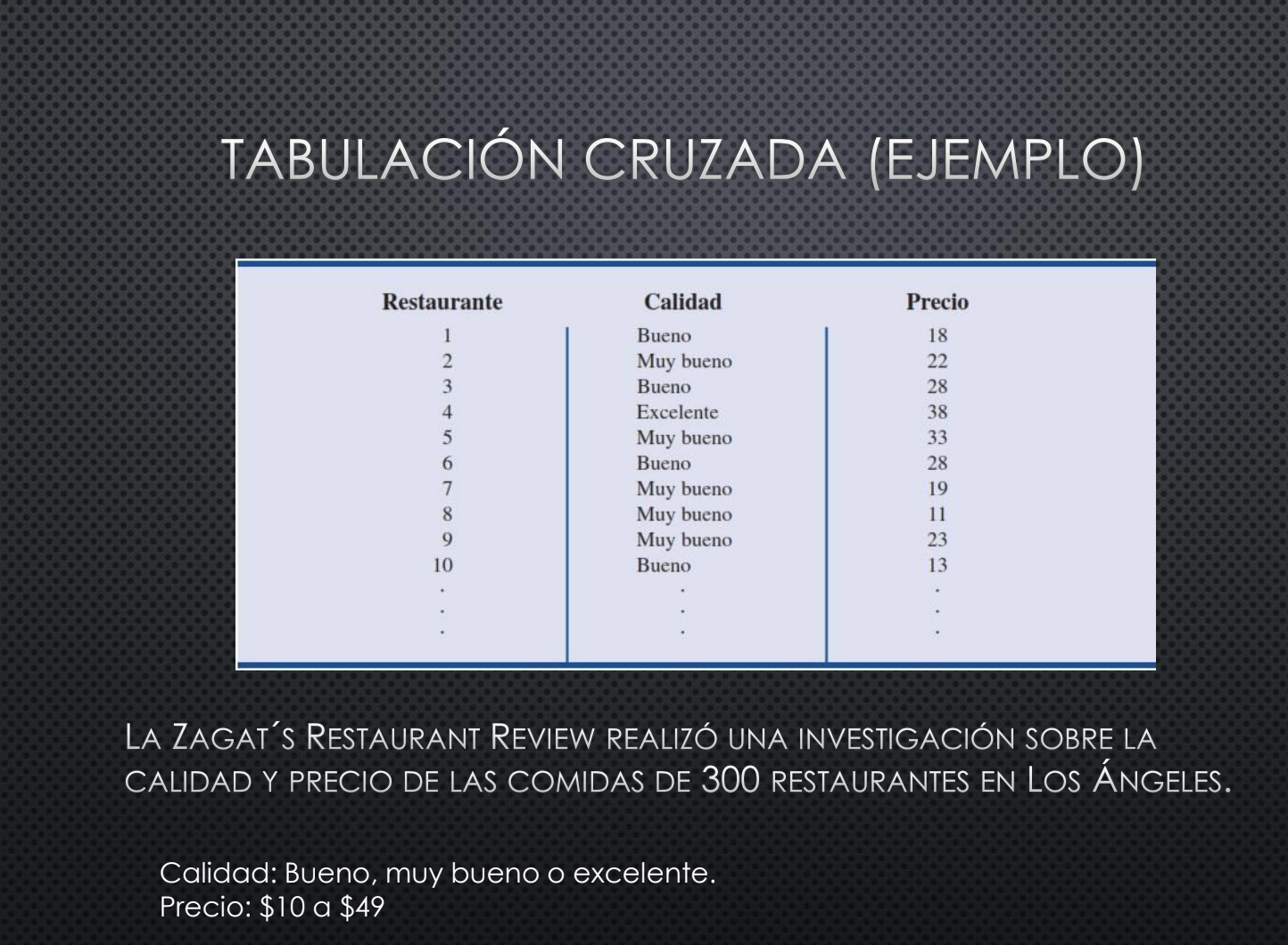
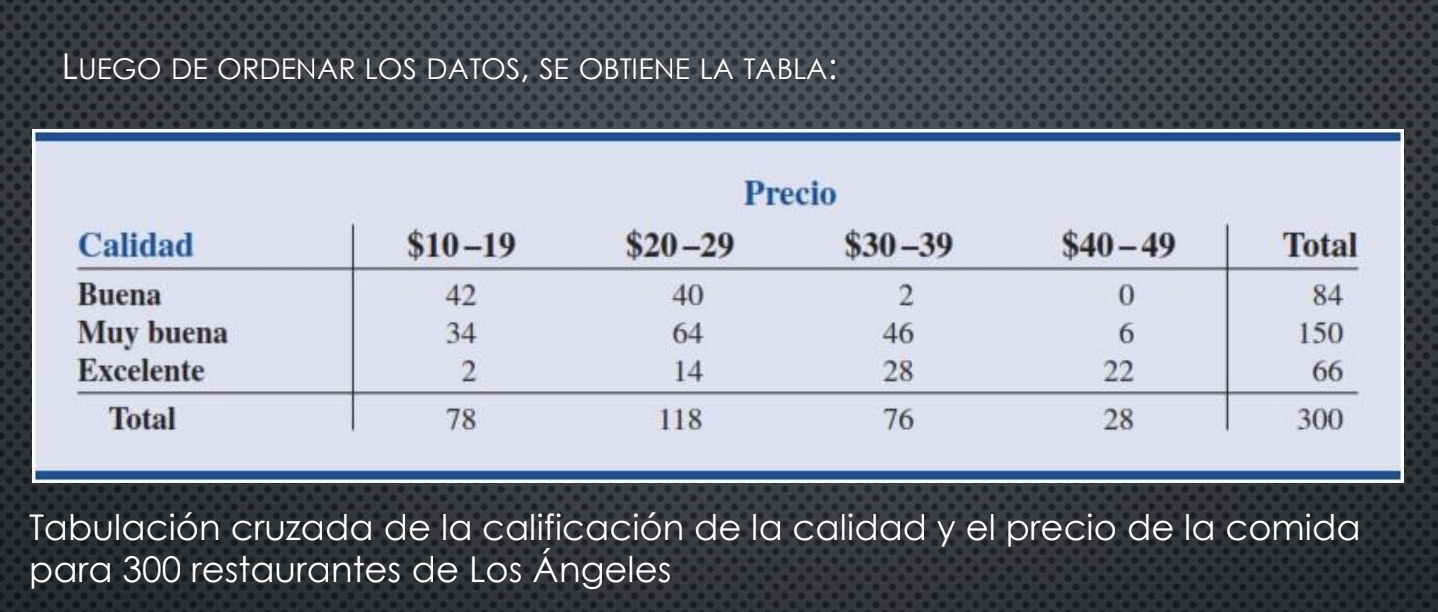
Diagrama de dispersión y línea de tendencia
Un diagrama de dispersión es la presentación gráfica de la relación entre 2 variables cuantitativas.
La línea de tendencia es aquella que proporciona una aproximación de la relación entre dos variables.
El diagrama de tallo y hoja
Es un método del análisis de datos exploratorio que permite clasificar y dar la forma de un conjunto de datos.
Medidas de la posición relativa y de la detección de observaciones atípicas
28/01/2024
Puntos Z
Ademas de las medidas de localización, variabilidad, interesa conocer también la ubicación relativa de los valores de un conjunto de datos.
Las medidas de localización relativa ayudan a determinar qué tan lejos de la media se encuentra x valor.
A partir de la media y la desviación estándar, se puede determinar la localización relativa de cualquier observación.
Punto z → z = (xi - media mostral) / desviación estándar muestral
Como se interpreta?
Punto z → valor estandarizado
El punto Z puede ser interpretado como el número de desviaciones estándar a las que xi se encuentra de la media.
Ejemplo → z1=1.2 indica que x1 está 1.2 desviaciones estándar por encima de la media.
Si z2= 0.5 indica que x2 es 0.5 menor que la media
Es simétrico
Chebyshev
Permite decir que proporción de los valores que se tienen en los datos deben de estar dentro de un determinado número de desviaciones estándar de la media.
(1-1/z²) de los valores que se tienen en los datos deben encontrarse dentro de z desviaciones estándar de la media, donde z es cualquier valor mayor que 1.
Al menos (1-1/z²) dice que tantas veces estoy alejado de la media.
z2→ 75% 2 desviaciones de la media
z3→ 89% 3 veces desviaciones de la media
z4→ 94% 4 veces desviaciones de la media
Regla empírica
cualquier conjunto de datos, distribución simétrica,
68% →
95% → no mas de dos
y casi 100%