Summary_Psychodiagnostics_GGZ2030.docx
Summary Psychodiagnostics GGZ2030
Psychological test = a standardised measure of a sample of behaviour that establishes norms and uses important test items that correspond to what the test is to discover about the test-taker. Is also based on uniformity of procedures in administering and scoring tests.
The standardised measure of a sample of behaviour = an established reference point that a test scorer can use to evaluate, judge, measure against, and compare.
- We get to this reference point by establishing norms 🡪 rely on the number of test-takers who take a given test, to establish what is normal in the group.
- Then scorers can determine where an individual falls within that group 🡪 that is why the larger the sample the better.
- Norms: to compare and give meaning to results.
Test items = the questions that a test-taker is asked on any given test.
- They must be relevant to what the test is trying to measure.
- They must have large sets to establish a proper measurement 🡪 it needs to have a lot of questions. More questions equal more chances of establishing what a test-taker knows and does not know to find their norm.
Uniformity of procedures in administering and scoring of tests = refers to administrators presenting the test in the same way, test-takers taking the test in the same way, and scorers scoring the test the same way every given time that this test is given, taken, and scored 🡪 this helps with:
- Validity = testing exactly what one is trying to discover.
- Reliability = being able to recreate the same or similar outcome every time the test is taken. There could have been emotional stress or other factors that may have made the individual score slightly lower or higher, but in general the score remains in the same scoring range 🡪 that establishes what the norm is, namely in the middle of this scoring range.
Reliability | Validity | |
|---|---|---|
What does it tell you? | The extent to which the results can be reproduced when the research is repeated under the same conditions. | The extent to which the results really measure what they are supposed to measure. |
How is it assessed? | By checking the consistency of results across time, across different observers, and across parts of the test itself. | By checking how well the results correspond to established theories and other measures of the same concept. |
How do they relate? | A reliable measurement is not always valid: the results might be reproducible but they’re not necessarily correct. | A valid measurement is generally reliable: if a test produces accurate results, they should be reproducible. |
Some of the primary purposes of psychological assessment are to:
- Describe current functioning, including cognitive abilities, severity of
disturbance, and capacity for independent living.
- Confirm, refute, or modify the impressions formed by clinicians through their less structured interactions with patients.
- Identify therapeutic needs, highlight issues likely to emerge in treatment,
recommend forms of intervention and offer guidance about likely outcomes.
- Aid in the differential diagnosis of emotional, behavioural, and cognitive disorders.
- Monitor treatment over time to evaluate the success of interventions or to
identify new issues that may require attention as original concerns are
resolved.
- Manage risk, including minimization of potential legal liabilities and
identification of untoward treatment reactions.
- Provide skilled, empathic assessment feedback as a therapeutic intervention
in itself.
Although specific rules cannot be developed, provisional guidelines for when assessments are likely to have the greatest utility in general clinical practice can be offered.
- In pre-treatment evaluation:
- Goal: to describe current functioning, confirm or refute clinical impressions, identify treatment needs, suggest appropriate interventions, or aid in differential diagnosis.
- Assessment is then likely to yield the greatest overall utility when:
- The treating clinician or patient has salient questions.
- There are a variety of treatment approaches from which to choose and a body of knowledge linking treatment methods to patient characteristics.
- The patient has had little success in prior treatment.
- The patient has complex problems and treatment goals must be prioritised.
3 readily accessible but inappropriate benchmarks can lead to unrealistically high expectations about effect magnitudes:
- It is easy to recall a perfect association. However, perfect associations are never encountered in applied psychological research.
- It is easy to implicitly compare validity correlations with reliability coefficients because the latter are frequently reported in the literature. However, reliability coefficients evaluate only the correspondence between a variable and itself, so they cannot provide a reasonable standard for evaluating the association between 2 distinct real-world variables.
- Monomethod validity coefficients are presented everywhere in the psychological literature (e.g., self-reports are compared with self-reports). Because the systematic error of method variance is aligned in such studies, the results are inflated and do not provide a reasonable benchmark for considering the real-world associations between 2 independently measured variables.
Instead of relying on unrealistic benchmarks to evaluate findings 🡪 psychologists should be satisfied when they can identify replicated univariate correlations among independently measured constructs.
Therapeutic impact is likely to be greatest when:
- Initial treatment efforts have failed
- Clients are curious about themselves and motivated to participate
- Collaborative procedures are used to engage the client
- Family and allied health service providers are invited to furnish input
- Patients and relevant others are given detailed feedback about results
Monomethod validity coefficients = are obtained whenever numerical values on a predictor and criterion are completely or largely derived from the same source of information.
- E.g., a self-report scale that is validated by correlating it with a conceptually similar scale that is also derived from self-report.
Distinctions between psychological testing and psychological assessment:
- Psychological testing = a relatively straightforward process wherein a particular scale is administered to obtain a specific score 🡪 the score has 1 meaning.
- Psychological assessment = concerned with the clinician who takes a variety of test scores, generally obtained from multiple test methods, and considers the data in the context of history, referral information, and observed behaviour to understand the person being evaluated, to answer the referral questions, and then to communicate findings to the patient, his or her significant others, and referral sources.
- Scores can have different meanings 🡪 after considering all relevant information
- Assessment uses test-derived sources of information in combination with historical data, presenting complaints, observations, interview results, and information from 3rd parties to disentangle the competing possibilities.
Distinctions between formal assessment and other sources of clinical information:
- Psychological assessments generally measure many personality, cognitive, or neuropsychological characteristics simultaneously 🡪 they are inclusive and often cover a range of functional domains, many of which might be overlooked during less formal evaluation procedures.
- Psychological tests provide empirically quantified information, allowing for more precise measurement of patient characteristics than is usually obtained from interviews.
- Psychological tests have standardised administration and scoring procedures 🡪 in less formal assessments, standardisation is lacking.
- Psychological tests are normed 🡪 permitting each client to be compared with a relevant group of peers 🡪 allows the clinician to formulate refined inferences about strengths and limitations.
- Research on the reliability and validity of individual test scales sets formal assessment apart from other sources of clinical information. Without this, practitioners have little ability to measure the accuracy of the data they process when making judgments.
- The use of test batteries in psychological assessment 🡪 in a battery, psychologists generally employ a range of methods to obtain information and cross-check hypotheses. These methods include self-reports, performance tasks, observations, and information derived from behavioural or functional assessment strategies.
Assessment methods:
- Unstructured interviews
- Elicit information relevant to thematic life narratives, though they are constrained by the range of topics considered and ambiguities inherent when interpreting this information.
- Structured interviews and self-report instruments
- Elicit details concerning patients’ conscious understanding of themselves and overtly experienced symptomatology, though they are limited by the patient’s motivation to communicate frankly and their ability to make accurate judgements.
- Performance-based personality tests
- Elicit data about behaviour in unstructured settings or implicit dynamics and underlying templates of perception and motivation, though they are constrained by task engagement and the nature of the stimulus materials.
- Performance-based cognitive tasks
- Elicit findings about problem solving and functional capacities, though they are limited by motivation, task engagement, and setting.
- Observer rating scales
- Elicit an informant’s perception of the patient, though they are constrained by the parameters of a particular type of relationship and the setting in which the observations transpire.
Clinicians and researchers should recognize the unique strengths and limitations of various assessment methods and harness these qualities to select methods that help them more fully understand the complexity of the individual being evaluated.
Low cross-method correspondence can indicate problems with one or both methods. Cross-method correlations cannot reveal what makes a test distinctive or unique, and they also cannot reveal how good a test is in any specific sense.
Clinicians must not rely on 1 method.
One cannot derive unequivocal clinical conclusions from test scores considered in isolation.
Because most research studies do not use the same type of data that clinicians do when performing an individualised assessment, the validity coefficients from testing research may underestimate the validity of test findings when they are integrated into a systematic and individualised psychological assessment.
Contextual factors play a very large role in determining the final scores obtained on psychological tests, so contextual factors must therefore be considered 🡪 contribute to method variance. However, trying to document the validity of individualised, contextually included conclusions is very complex.
The validity of psychological tests is comparable to the validity of medical tests.
Distinct assessment methods provide unique sources of data 🡪 sole reliance on a clinical interview often leads to an incomplete understanding of patients.
It is argued that optimal knowledge in clinical practice/research is obtained from the sophisticated integration of information derived from a multimethod assessment battery.
Clinical diagnostics is based on 3 elements:
- Theory development of the problems/complaints and problematic behaviour
- Operationalization and its subsequent measurement
- The application of relevant diagnostic methods
Testing a diagnostic theory requires 5 diagnostic measures:
- Converting the provisional theory into the concrete hypotheses
- Selecting a specific set of research tools, which can either support or reject the
formulated hypotheses
- Making predictions about the results or outcomes from this set of tools, in
order to give a clear indication as to when the hypotheses should be accepted
or rejected
- Applying and processing instruments
- Based on the results that have been obtained, giving reasons for why
the hypotheses have either been accepted or rejected
This results in the diagnostic conclusion.
5 basic questions in clinical psychodiagnostics – classification of requests:
- Recognition = what are the problems? What works and what does not?
- Explanation = why do certain problems exist and what perpetuates them?
- Prediction = how will the client’s problems subsequently develop in the future?
- Indication = how can the problems be resolved?
- Evaluation = have the problems been adequately resolved because of the intervention?
The quantity and type of basic questions to be addressed depends on the questions that were discussed during the application phase. Most requests contain 3 basic questions: recognition, explanation, and indication. In practice, all the basic questions chosen are often examined simultaneously.
Recognition:
- Identifying both the complaints and adequate behaviour of the client and/or his environment to obtain a better understanding of the client’s problem.
- Recognition may occur because of:
- Comparison to a predefined standard = criterion-oriented measurement
- Comparison to a representative comparison group = normative measurement
- Comparison to the individual him-/herself = ipsative measurement
- Classification (“labelling”) 🡪 the clinical picture is assigned to a class of problems.
- All-or-nothing principle = DSM-categories
- More-or-less principle = dimensions of a test or questionnaire
- Diagnostic formulation = focuses on the individual and his/her own unique clinical picture 🡪 holistic theory.
- Allows for the uniqueness of the individual, based on a description of the client and its context 🡪 helps the therapy planning, but there is an occasional lack of empirical support.
- Diagnostic formulation usually involves simultaneous recognition and explanation.
Explanation:
- Answers the question of why there is a problem or a behavioural problem.
- It includes:
- The main problem or problem component
- The conditions that explain the problem’s occurrence
- The causal relationship between points 1 and 2.
- Explanations may be classified according to:
- The locus = the person or the situation
- Person-oriented = explanatory factor lies in the person him-/herself; the behaviour is viewed separately from the context.
- Situation-oriented = explanatory factor lies in the event of a well-known context. Explanatory events may precede the behaviour that it is to be explained or follow it.
- The nature of control
- Cause = determines behaviour by previous conditions
- Reason = explanatory factor determined by a voluntary or intentional choice
- Causes explain behaviour while reasons make behaviour understandable.
- Synchronous and diachronous explanatory conditions
- Synchronous = coincide with the behaviour that is to be explained at the time
- Diachronous = precede this behaviour (prior to the behaviour)
- Induced and persistent conditions
- Induced = give rise to a behaviour problem (produce)
- Persistent = perpetuate the behavioural problem (maintain)
- When treating a problem, it is best to search for factors in the current situation that perpetuate the problem, because we can exert an influence on these.
- The locus = the person or the situation
Prediction:
- Involves making a statement about the problem behaviour in the future.
- It is a chance statement 🡪 this chance plays a part in determining the treatment proposal (e.g., long- versus short-term, admission or ambulant treatment, etc.).
- Prediction pertains to a relation between a predictor and a criterion:
- The predictor is the present behaviour
- The criterion is the future behaviour.
- We can only determine the chance that behaviours will collectively occur in a particular population (and not in a certain client) = risk assessment.
Indication:
- Focuses on the question of whether the client requires treatment and, if so, which caregiver and assistance are the most suitable for this client and problem.
- The indication is a search process, carried out by a therapist.
- Before the indication can start, the steps for explanation and prediction must be completed.
- There are 3 additional elements:
- Knowledge of treatments and therapists
- Knowledge of the relative usefulness of treatments
- Knowledge of the client’s acceptance of the indication 🡪 e.g., do not want to follow the treatment
- Indication strategy which takes the client’s preference into account:
- The client’s perspective is examined and explicated
- The diagnostician provides the client with information about the courses of treatment, processes, and therapists.
- The client’s expectations and preferences are compared to those that the diagnostician deems to be suitable and useful, and during a mutual consultation, several possible treatments, which are acceptable to both parties, are formulated.
- The client selects a therapist and a treatment.
Evaluation:
- Evaluation of the assertions about diagnosis and/or intervention takes place based on both the progress of the therapeutic process and the results of the treatment.
- This establishes:
- Whether the therapy took account of the diagnosis and treatment proposal 🡪 if this was not the case, the diagnostic process was unnecessary
- Whether the process and the treatment have brought about change in the client’s behaviour and experience
Diagnostic cycle = a model for answering questions in a scientifically justified manner:
- Observation = collecting and classifying empirical materials, which provide the basis for forming thoughts about the creation and persistence of problem behaviour.
- Induction = the formulation of theory and hypotheses about the behaviour.
- Deduction = testable predictions are derived from these hypotheses.
- Testing = new materials are used to determine whether the predictions are correct or incorrect.
- Evaluation
The diagnostic cycle is a basic diagram for scientific research, not for psychodiagnostic practice.
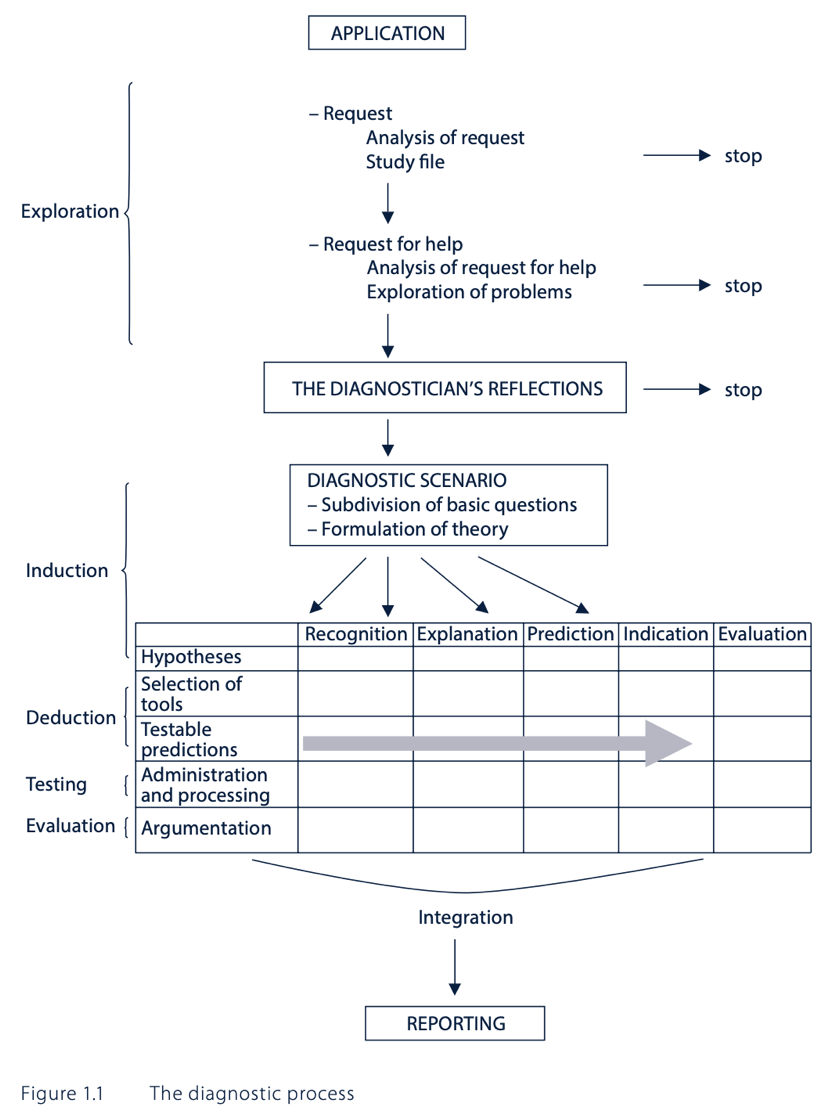
The diagnostic process:
- Application:
- The diagnostician’s first task is to analyse the request for help, results in:
- Information about the referrer:
- It is important to understand the referrer’s frame of reference.
- The analysis of the request results in clarification of the relationship between the diagnostician and the referrer.
- It is important to make a distinction between the referrer in name (🡪 requires the examination to be carried out) and the actual referrer (🡪 initiative taker).
- Referrers differ from each other in terms of nature and extent of the powers which are available to them, e.g., psychiatrist versus in-taker.
- Details about the type and content of the request:
- Open-ended format = the referrer will not formulate any hypotheses about the problem.
- Closed format = the referrer formulates hypotheses about the problem.
- The content of a request is partially connected to the setting from which the request originates.
- Information about the referrer:
- Analysis of the request includes exploration of the client’s mindset.
- The diagnostician’s first task is to analyse the request for help, results in:
- The diagnostician’s reflections:
- Due weight is given to each of the carious pieces of information.
- This reflection phase requires insight into the diagnostician’s position and professional and task-oriented practices.
- The diagnostician should be aware of his potential biases in both general clinical judgement and towards clients.
- The diagnostic scenario:
- The diagnostician organises all the requester’s and client’s questions from the application phase, all the questions that have occurred to him and his knowledge of the problem.
- Based on this information, he proposes an initial, tentative theory about the client’s problematic behaviour.
- The basic questions are asked.
- The diagnostic examination:
- Hypothesis formulation
- The diagnostician formulates several hypotheses based on the diagnostic scenario.
- In the context of the recognition question, the hypotheses centre on the presence of psychopathology or a differential diagnosis.
- In the context of the explanation question, the hypotheses require a list of explanatory factors and their predisposing or perpetuating roles.
- In the context of the prediction question hypotheses are based on empirical knowledge of successful predictors.
- In the context of the indication question, hypotheses are assumptions about which treatment and which therapist(s) are best suited to a client with a specific problem.
- These hypotheses are founded on the conclusions that have been drawn from recognition, explanation, and prediction, but are also based on:
- Theory of illness = how the client formulates his/her problem, how he/she views his/her complaints and what the disease attributes are.
- Theory of healing = which type of help he/she expects to receive and the way he/she expects to receive it.
- Theory of health = what he/she hopes to achieve with the treatment.
- Selection of examination tools
- Formulation of testable predictions
- Administration and scoring
- Argumentation
- Report
- Hypothesis formulation
Critical comments on DTCs:
- Many patients have more than 1 complaint/problem 🡪 difficult to choose a department.
- Some clients do not have clearly defined complaints/problems
- Within departments that address certain complaints/problems, there is a strong focus on the reported complaints/problems. Due to this, there is a danger that other, even more important existing disorders may be overlooked.
- DTCs assume an interaction between a specific diagnosis and a type of treatment.
- When working with DTCs, there is often insufficient time to carry out a comprehensive diagnostic examination of the causes of the complaint(s)/problem(s).
BDI-II:
- You can only use this for screening not for classification.
- It is not a diagnostic tool 🡪 it is for finding out the severity of depression.
- Cut points are used to classify patients (versus non-patients):
- A score of 13 or higher indicates depression in healthy (and somatic/primary care) populations.
- A score of 19 or higher indicates depression in psychiatric settings.
- Cut points that are optimal within a specific sample do not necessarily emerge as optimal in other samples from the same population or generalise well to the population at large.
- 1 explanation for the need for higher cut points in psychiatric patients is that many symptoms which are assessed as part of the BDI-II (sleeplessness, trouble with concentration) are also affected by other psychiatric diseases or side effects of psychopharmaceuticals, rather than specific symptoms of depression.
Sensitivity = the number of individuals we can correctly diagnose with depression 🡪 from the 100 people receiving a diagnosis, 86 would be diagnosed with depression correctly 🡪 the other 14 individuals are false negatives.
Specificity = the number of individuals we can correctly diagnose as healthy 🡪 from the 100 people receiving a diagnosis, 78 would be diagnosed healthy correctly 🡪 the other 22 individuals are false positives.
The Youden criterion (= sensitivity + specificity) is not always correct 🡪 it may give counterintuitive results in some circumstances.
- The depression cut point should be higher than the non-depression cut point.
- But if the non-depression cut point is 21 (in total of 40) the optimal cut point of depression (according to Youden criterion) would be 19.
- However, the results show an optimal cut point of 28 for depressed patients.
Based on BDI-II scores alone:
- Misses between 15-20% of persons with depression 🡪 false negatives
- Wrongfully classify 20-25% as having depression even though they don’t 🡪 false positives
The Narcissistic Personality Inventory is the same as the Self Confidence Test. Narcissists could underreport on psychological tests as they want to do good and won’t show they are suffering from a disease.
- Do not rely on 1 test but use different tests to get a differential diagnosis.
- It is generally useful to use BDI-II in this case.
Kohut’s self-psychology approach offers the deficit model of narcissism, which asserts that pathological narcissism originates in childhood because of the failure of parents to empathise with their child.
Kernberg’s object relations approach emphasises aggression and conflict in the psychological development of narcissism, focusing on the patient’s aggression towards and envy of others 🡪 conflict model.
Social critical theory (Wolfe) 🡪 narcissism was a result of the collective ego’s defensive response to industrialisation and the changing economic and social structure of society.
Narcissistic personality disorder (NPD), DSM-V criteria:
- Grandiosity and self-importance
- Persistent fantasies of success, power, attractiveness, intellectual superiority
or ideal love
- Sense of superiority and specialness
- Wish to be admired
- Strong sense of entitlement
- Manipulates and exploits others
- Lack of empathy
- Believes others are envious of him/her and envy of others
- Arrogant and contemptuous attitudes and behaviours
DSM-IV mainly focused on the disorder’s grandiose features and did not adequately capture the underlying vulnerability that is evident in many narcissistic individuals.
At least 2 subtypes or phenotypic presentations of pathological narcissism can be differentiated:
- Grandiose or overt narcissism = may appear arrogant, pretentious, dominant, self-assured, exhibitionist or aggressive 🡪 thick-skinned
- Vulnerable or covert narcissism = may appear overly sensitive, insecure,
defensive and anxious about an underlying sense of shame and inadequacy 🡪 thin-skinned
The former defending the latter: grandiosity conceals underlying vulnerabilities
Both individuals with grandiose and those with vulnerable narcissism share a preoccupation with satisfying their own needs at the expense of the consideration of others.
Pathological narcissism is defined by a fragility in self-regulation, self-esteem, and sense of agency, accompanied by self-protective reactivity and emotional dysregulation.
Grandiose and self-serving behaviours may be understood as enhancing an underlying depleted sense of self and are part of a self-regulatory spectrum of narcissistic personality functioning.
Psychodynamic approaches:
- Psychodynamic psychotherapy is grounded in psychoanalytic principles, but it is based on a broader theoretical framework capturing relational, interpersonal, intersubjective, and embodied experiences of both the social world and the internal world.
- Transference-focused psychotherapy = based on the principles of psychoanalytic object relations theory, originally for borderline patients. It’s aimed at the active exploration of the patient’s aggression, envy, grandiosity, and defensiveness. Interpretations are targeted towards uncovering the negative transference, challenging the patient’s pathological grandiose defences, and exploring their sensitivity to shame and humiliation.
- Mentalisation-based treatment = this group and individual therapy is based on attachment theory, and it integrates psychodynamic, cognitive, and relational components, originally for borderline patients. It focuses on enhancing mentalisation = the ability to reflect on one’s own and others’ states of mind and link these to actions and behaviour.
Cognitive-behavioural approaches:
- In the cognitive-behavioural framework therapists and researchers have adapted Beck’s cognitive therapy model to treat narcissistic thoughts and behaviours. Cognitive techniques such as cognitive reframing, problem-solving and altering dysfunctional thoughts, coupled with behavioural modification techniques such as impulse control, maintaining eye contact, and reducing grandiosity, have been demonstrated in narcissistic patients to strengthen the therapeutic alliance and increase adherence to therapy and therapeutic goals.
- Schema-focused therapy = an integrative psychotherapy that expands strategies from cognitive-behavioural therapy, but also includes elements from object relations, psychodynamic and gestalt therapeutic models. No clinical trials of schema-focused therapy have been conducted for NPD, but clinical reports suggest that it may be effective for the disorder. It focuses on challenging early maladaptive schemas regarding relationships to self and others and on promoting a healthier “adult mode” of functioning. The therapist uses a process of “re-parenting”, encouraging the patient to better regulate narcissistic fluctuations in emotional reactivity and to develop empathy for and achieve emotional intimacy with others.
- Dialectical behaviour therapy = combines individual and group therapy sessions and incorporates cognitive-behavioural principles with acceptance and mindfulness-based skills. Group skills-training sessions are used to promote mindfulness, emotion regulation, distress tolerance and interpersonal effectiveness. It reduces the feelings of shame and self-criticism.
- Meta-cognitive interpersonal therapy = manualized step-by-step treatment particularly focusing on perfectionism. It is aimed at dismantling narcissistic processes, with shared understanding of the patient’s problems in their autobiographical context, progressing to recognition of maladaptive schemas and interpersonal functioning, and finally to promoting change through identification of grandiosity, distancing from old behaviour, reality- and perspective-taking and building more healthy schemas.
Treatment challenges:
- If the diagnosis is made, patients often reject it as it challenges their sense of
specialness and/or may accentuate feelings of low self-worth, shame and
humiliation.
- Patients may feel criticised or unfairly treated by the clinician.
- Patients may resent the perceived power or expertise of the clinician and reject any treatment offered.
- Patients may also wish to please the therapist and be their favourite patient.
- People with NPD may report being particularly sensitive to the side-effects of medication, particularly those that affect their sexual function or intellectual capacity.
- Patients may also resent the idea that they might be dependent on
pharmacological interventions.
The mainstay of treatment for NPD is psychological therapy.
Cronbach’s Alpha = a psychometric statistic
- Introduced by Cronbach in 1952
Before Cronbach’s Alpha:
- Split-half reliability 🡪 was actually very similar to Cronbach’s Alpha but was limited in that you had to choose what split-half 🡪 different split-halves give different estimates of internal consistency.
- Kuder-Richardson 🡪 it was used exclusively for items that were scored dichotomously
Cronbach’s Alpha is much more general than these two 🡪 it represents the average of all possible split-halves. In addition, it can be used for both dichotomous and continuously scored data/variables.
Coefficient Alpha = Cronbach' Alpha
What is it?:
- It is an estimate of reliability 🡪 an estimate of internal consistency reliability.
- Cronbach’s alpha is an indicator of consistency, just like all the other reliability estimates.
- It’s not a measure of homogeneity and it’s not a measure of unidimensionality 🡪 scale.
- Consistency in measurement is good.
Cronbach’s Alpha is a coefficient, and it can range from 0.00 to 1.00.
- Technically you can have a negative reliability estimate in the context of Cronbach’s Alpha, but this doesn’t happen often 🡪 it is a very bad sign.
- 0.00 = no consistency in measurement
- 1.00 = perfect consistency in measurement
- 0.70 means that 70% of the variance in the scores is reliable variance.
- Therefore, 30% is error variance 🡪 we want this to be low.
Internal consistency reliability is relevant to composite scores = the sum (or average) of 2 or more scores.
- E.g., items in a test: item 1 + item 2 + item 3, etc.
- Internal consistency is not relevant to the individual item scores.
Cronbach’s Alpha measures internal consistency between items on a scale.
- Internal means that we are looking at how a participant is responding across all items 🡪 so if a participant is responding on the upper end of the scale like neutral, agree or strongly agree, we would expect them to be responding that way for each item in the scale.
- We don’t want to see that they are responding like strongly agree for some items and then strongly disagree for other items 🡪 that is inconsistent.
- If you have a mix of positive and negatively worded questions 🡪 your Cronbach’s Alpha will be negative 🡪 you need to make sure to reverse code your variables first 🡪 they all need to go in the same direction (does not matter if this is positive or negative).
- You do not do Cronbach’s Alpha for your entire questionnaire because people are going to be answering differently across scales and across items 🡪 it is just a Cronbach’s Alpha for each scale.
The steps needed to generate the relevant output in SPSS:
- Analyze
- Scale
- Reliability analysis
- Select the items and move them over with the arrow 🡪 you must do the Cronbach’s Alpha for each scale separately 🡪 you cannot do it for your whole questionnaire at once 🡪 people answer differently across scales and items
- Select “Alpha” in model
- Label your scale to name the output (not compulsory, but helpful)
- Statistics tab: choose:
- Descriptives for 🡪 “item”, “scale”, and “scale if item deleted”
- Summaries 🡪 “means” and “correlations”
- Inter-item 🡪 “correlation”
- Continue
- OK
Interpreting Cronbach’s Alpha output from SPSS: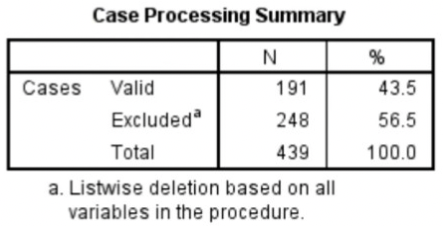
- Case processing summary
- Listwise deletion = if a participant had one missing value, that participant was omitted from the Cronbach’s Alpha calculation 🡪 excluded for all items when one item was missing.
- Listwise deletion = if a participant had one missing value, that participant was omitted from the Cronbach’s Alpha calculation 🡪 excluded for all items when one item was missing.
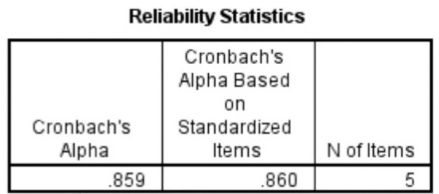
- Reliability statistics
- Cronbach’s Alpha should be .70 or higher
- If less than 10 items, it should be higher than .50 🡪 hard to get a high Cronbach’s Alpha with few items.
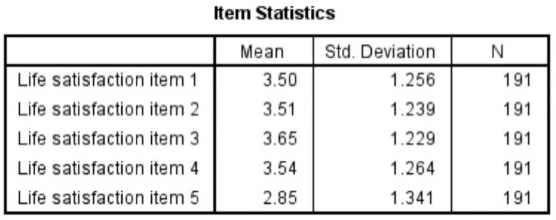
- Item statistics
- Mean, standard deviation, and sample size for each of the items on the scale.
- Inter-item correlation matrix
- The correlation of every item in the scale with every other item.
- You would expect all these correlations to be positive because all your questions should be worded in the same way 🡪 all in the same direction.
- The larger the value is closer to one, the stronger the relationship between the responses.
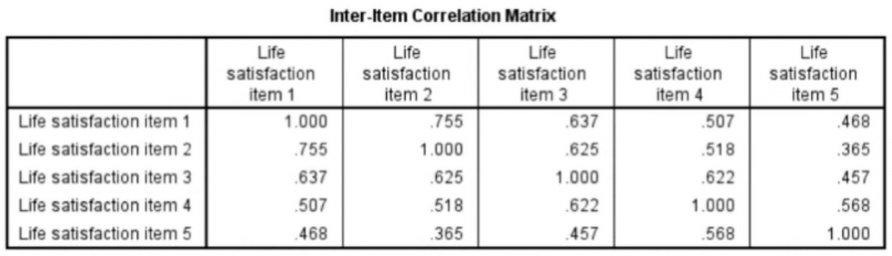
- 1.000 in the table when an item is correlated with itself 🡪 perfect correlation.
- It is symmetric: values are mentioned twice
- Summary item statistics
- Item means and inter-item correlations
- Range = maximum value – minimum value
- If you have a low Cronbach’s Alpha because you have few items in your scale, report the inter-item correlation (mean).
- If you have a high Cronbach’s Alpha, you do not need to worry about it.

- Item-total statistics:
- Corrected item-total correlation = the correlation of each item with all other items combined.
- Should be higher than .40
- Cronbach’s Alpha if item deleted = if item is deleted from the scale
- You can look at this when you have a low Cronbach’s Alpha 🡪 you can see what happens when you delete a particular item 🡪 will it increase?
- Corrected item-total correlation = the correlation of each item with all other items combined.
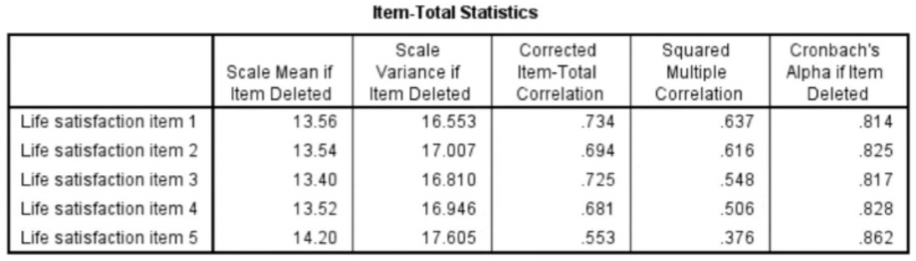
- Scale statistics
High Cronbach’s Alpha: suggests that a questionnaire might contain unnecessary duplication of content.
Reliability = how consistently a method measures something.
- When you apply the same method to the same sample under the same conditions, you should get the same results 🡪 if not, the method of measurement may be unreliable.
There are 4 main types of reliability 🡪 each can be estimated by comparing different sets of results produced by the same method.
Test-retest reliability:
- Measures the consistency of results when you repeat the same test on the same sample at a different point in time.
- You use it when you are measuring something that you expect to stay constant in your sample.
- Why it’s important:
- Many factors can influence your results at different points in time 🡪 e.g., respondents might experience different moods, or external conditions might affect their ability to respond adequately.
- Test-retest reliability can be used to assess how well a method resists these factors over time 🡪 the smaller the difference between the 2 sets of results, the higher the test-retest reliability.
- How to measure it:
- To measure test-retest reliability, you conduct the same test on the same group of people at 2 different points in time.
- Then you calculate the correlation between the 2 sets of results.
- Improving test-retest reliability:
- When designing tests or questionnaires, try to formulate questions, statements and tasks in a way that won’t be influenced by the mood or concentration of participants.
- When planning your methods of data collection, try to minimise the influence of external factors, and make sure all samples are tested under the same conditions.
- Remember that changes can be expected to occur in the participants over time and take these into account.
Interrater reliability/interobserver reliability:
- Measures the degree of agreement between different people observing or assessing the same thing.
- You use it when data is collected by researchers assigning ratings, scores, or categories to one or more variables.
- Why it’s important:
- People are subjective, so different observers’ perceptions of situations and phenomena naturally differ 🡪 reliable research aims to minimise subjectivity as much as possible 🡪 so that a different researcher could replicate the same results.
- When designing the scale and criteria for data collection, it’s important to make sure that different people will rate the same variable consistently with minimal bias 🡪 this is especially important when there are multiple researchers involved in data collection or analysis.
- How to measure it:
- To measure interrater reliability, different researchers conduct the same measurement or observation on the same sample.
- Then you calculate the correlation between their different sets of results.
- If all the researchers give similar ratings, the test has high interrater reliability.
- Improving interrater reliability:
- Clearly define your variables and the methods that will be used to measure them.
- Develop detailed, objective criteria for how the variables will be rated, counted, or categorised.
- If multiple researchers are involved, ensure that they all have the same information and training.
Parallel forms reliability:
- Measures the correlation between 2 equivalent versions of a test.
- You use it when you have 2 different assessment tools or sets of questions designed to measure the same thing.
- Why it’s important:
- If you want to use multiple different versions of a test (e.g., to avoid respondents repeating the same answers from memory), you first need to make sure that all the sets of questions or measurements give reliable results.
- How to measure it:
- The most common way to measure parallel forms reliability is to produce a large set of questions to evaluate the same thing, then divide these randomly into 2 question sets.
- The same group of respondents answers both sets, and you calculate the correlation between the results 🡪 high correlation between the 2 sets indicates high parallel forms reliability.
- Improving parallel forms reliability:
- Ensure that all questions or test items are based on the same theory and formulated to measure the same thing.
Internal consistency:
- Assesses the correlation between multiple items in a test that are intended to measure the same construct.
- You can calculate internal consistency without repeating the test or involving other researchers 🡪 so it’s a good way of assessing reliability when you only have one data set.
- Why it’s important:
- When you devise a set of questions or ratings that will be combined into an overall score, you must make sure that all of the items really do reflect the same thing 🡪 if responses to different items contradict one another, the test might be unreliable.
- E.g., internal consistency tells you whether the statements are all reliable indicators of customer satisfaction.
- How to measure it:
- 2 common methods are used to measure internal consistency:
- Average inter-item correlation = for a set of measures designed to assess the same construct, you calculate the correlation between the results of all possible pairs of items and then calculate the average.
- Split-half method = you randomly split a set of measures into 2 sets. After testing the entire set on the respondents, you calculate the correlation between the 2 sets of responses.
- E.g., the correlation is calculated between all the responses to the “optimistic” statements, but the correlation is very weak. This suggests that the test has low internal consistency.
- 2 common methods are used to measure internal consistency:
- Improving internal consistency:
- Take care when devising questions or measures: those intended to reflect the same concept should be based on the same theory and carefully formulated.
Which type of reliability applies to my research?:
- It’s important to consider reliability when planning your research design, collecting, and analysing your data, and writing up your research.
- The type of reliability you should calculate depends on the type of research and your methodology.
- If possible and relevant, you should statistically calculate reliability and state this alongside your results.
Summary types of reliability:
Test-retest reliability The same test over time Measuring a property that you expect to stay the same over time | You devise a questionnaire to measure the IQ of a group of participants (a property that is unlikely to change significantly over time). You administer the test 2 months apart to the same group of people, but the results are significantly different, so the test-retest reliability of the IQ questionnaire is low. |
|---|---|
Interrater reliability/interobserver reliability The same test conducted by different people Multiple researchers making observations or ratings about the same topic | A team of researchers observe the progress of wound healing in patients. To record the stages of healing, rating scales are used, with a set of criteria to assess various aspects of wounds. The results of different researchers assessing the same set of patients are compared, and there is a strong correlation between all sets of results, so the test has high interrater reliability. |
Parallel forms reliability Different versions of a test which are designed to be equivalent Using 2 different tests to measure the same thing | A set of questions is formulated to measure financial risk aversion in a group of respondents. The questions are randomly divided into 2 sets, and the respondents are randomly divided into 2 groups. Both groups take both tests: group A takes test A first, and group B takes test B first. The results of the 2 tests are compared, and the results are almost identical, indicating high parallel forms reliability. |
Internal consistency The individual items of a test Using a multi-item test where all the items are intended to measure the same variable | A group of respondents are presented with a set of statements designed to measure optimistic and pessimistic mindsets. They must rate their agreement with each statement on a scale from 1 to 5. If the test is internally consistent, an optimistic respondent should generally give high ratings to optimism indicators and low ratings to pessimism indicators. The correlation is calculated between all the responses to the “optimistic” statements, but the correlation is very weak. This suggests that the test has low internal consistency. |
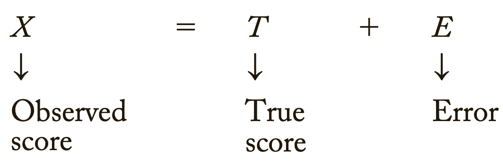
Errors of measurement = discrepancies between true ability and measurement of ability
- Error implies that there will always be some inaccuracy in our measurements 🡪 we need to minimise errors
Tests that are relatively free of measurement error: reliable
Tests that have “too much” measurement error: unreliable
Classical test score theory = assumes that each person has a true score that would be obtained if there were no errors in measurement.
- Because measuring instruments are imperfect, the score observed for each person almost always differs from the person’s true ability or characteristic.
- Measurement error = the difference between the true score and the observed score
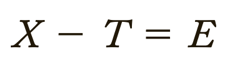
3 different distributions shown:
- Far left distribution: great dispersion around the true score 🡪 you might not want to depend on a single observation because it might fall far from the true score.
- Far right distribution: tiny dispersion around the true score 🡪 most of the observations are extremely close to the true score 🡪 drawing conclusions based on fewer observations will likely produce fewer errors than it will for the far-left curve.
- In the middle
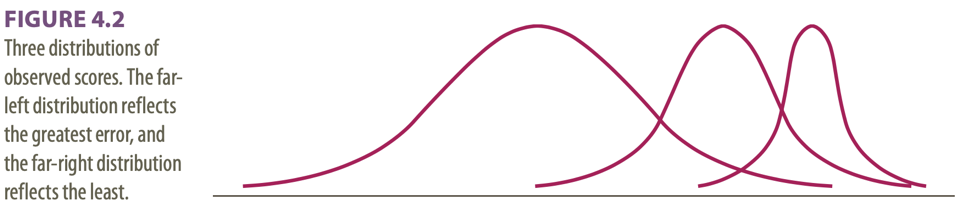
Dispersions around the true score: tell us how much error there is in the measure
- A major assumption in classical test theory = errors of measurement are random
- If errors of measurement are not random 🡪 scores will not have a normal distribution
Classical test theory assumes that the true score for an individual will not change with repeated applications of the same test 🡪 because of random error, repeated applications of the same test can produce different scores 🡪 random error is responsible for the distribution of scores.
The standard deviation of the distribution of errors for each person tells us about the magnitude of measurement error.
- We usually assume that the distribution of random errors will be the same for all people 🡪 classical test theory uses the standard deviation of errors as the basic measure of error = standard error of measurement (σmeas)
- Tells us, on the average, how much a score varies from the true score.
- In practice, the standard deviation of the observed score and the reliability of the test are used to estimate the standard error of measurement.
Domain sampling model = considers the problems created by using a limited number of items to represent a larger and more complicated construct 🡪 another central concept in classical test theory.
- Conceptualizes reliability as the ratio of the variance of the observed score on the shorter test and the variance of the long-run true score.
- The measurement considered in the domain sampling model is the error introduced by using a sample of items rather than the entire domain.
- Sample = shorter test 🡪 e.g., with measuring spelling ability
- The task in reliability analysis is to estimate how much error we would make by using the score from the shorter test as an estimate of true ability.
As the sample gets larger, it represents the domain more and more accurately 🡪 the greater the number of items 🡪 the higher the reliability
Because of sampling error, different random samples of items might give different estimates of the true score: true scores are not available so need to be estimated.
- The distribution of these estimates should be random and normally distributed.
Turning away from classical test theory because it requires that the same test items be administered to each person 🡪 low reliability when few items.

Item response theory (IRT) = the computer is used to focus on the range of item difficulty that helps assess an individual’s ability level.
- E.g., if the person gets several easy items correct, the computer might quickly move to more difficult items 🡪 then this level of ability is tensely sampled.
- The overall result: a more reliable estimate of ability is obtained using a shorter test with fewer items.
Difficulties of IRT: requires a bank of items that have been systematically evaluated for level of difficulty 🡪 complex computer software is required and much effort in test development.
Reliability coefficient = the ratio of the variance of the true scores on a test to the variance of the observed scores.

σ2 = describes theoretical values in a population
S2 = values obtained from a sample
If r = .40: 40% of the variation or difference among the people will be explained by real differences among people, and 60% must be ascribed to random or chance factors.
An observed score may differ from a true score for many reasons.
Test reliability is usually estimated in 1 of 3 ways:
- Test-retest method = we consider the consistency of the test results when the test is administered on different occasions.
- Parallel forms = we evaluate the test across different forms of the test.
- Internal consistency = we examine how people perform on similar subsets of items selected from the same form of the measure.
Test-retest method:
- Time sampling
- Evaluation of the error associated with administering the test at 2 different times
- Only when we measure “traits” or characteristics that do not change over time
- Easy to evaluate: find the correlation between scores from the 2 administrations
- Carryover effect = occurs when the first testing session influences scores from the second session 🡪 e.g., remembering answers
- Due to this, the test-retest correlation usually overestimates the true reliability
- One type of carryover effect = practice effects = some skills improve with practice
- Systematic carryover does not harm the reliability 🡪 when everyone’s score improves 5 points 🡪 no new/low reliability
- Random carryover effects 🡪 when something affects some but not all takers of the test 🡪 new reliability/low reliability
- The time interval between testing sessions must be selected and evaluated carefully
- Too close in time: high risk of carryover (and practice) effects
- Too far apart: many other factors can intervene to affect scores, e.g., change of a characteristic
Parallel forms:
- Item sampling
- To determine the error variance that is attributable to the selection of 1 set of items
- Compares 2 equivalent forms of a test that measure the same attribute
- The 2 forms use different items 🡪 however, the rules used to select items of a particular difficulty level are the same
- Equivalent forms reliability = when 2 forms of the test are available, one can compare performance on one form versus the other
Internal consistency:
- All the measures of internal consistency evaluate the extent to which the different items on a test measure the same ability or trait 🡪 low estimates of reliability if the test is designed to measure several traits
- Split-half method
- A test is given and divided into halves that are scored separately
- The results of one half of the test are then compared with the results of the other half
- If a test is long: best method is to divide the items randomly into 2 halves
- Some people prefer to calculate a score for the first half of the items and another score for the second half = easier
- However, can cause problems: if the second half of the items is more difficult than the first half
- If the items get progressively more difficult, then you might be better advised to use the odd-even system = one sub score for the odd-numbered items of the test and one for the even-numbered items
- However, can cause problems: if the second half of the items is more difficult than the first half
- Half-length of the test: has a lower reliability value than the complete test 🡪 test scores gain reliability as the number of items increases
- To correct for this: Spear-Brown formula = allows you to estimate what the correlation between the 2 halves would have been if each half had been the length of the whole test
- Increases the estimate of reliability 🡪 estimate of reliability based on 2 half-tests would be deflated because each half would be less reliable than the whole test
- To correct for this: Spear-Brown formula = allows you to estimate what the correlation between the 2 halves would have been if each half had been the length of the whole test
- No Spear-Brown formula when: 2 halves have unequal variances 🡪 Cronbach’s Alpha
- Provides the lowest estimate of reliability that one can expect
- If alpha is high, then you might assume that the reliability of the test is acceptable because the lowest boundary of reliability is still high 🡪 the reliability will not drop below alpha
- A low alpha level gives you less information 🡪 the actual reliability may still be high
- Can confirm that a test has substantial reliability, but cannot tell you that a test is unreliable
- Kuder-Richardson technique
- Addition to split-half technique: also estimating internal consistency
- No problems with unequal variances
- Considers simultaneously all possible ways of splitting the items
- Formula is for calculating the reliability of a test in which the items are dichotomous 🡪 scored 0 or 1 (usually right or wrong)
- Kuder-Richardson 20, KR20 or KR20

- pq = variance for an individual item/Σpq = the sum of the individual item variances
- Adjustment for the number of items in the test 🡪 will allow an adjustment for the greater error associated withs shorter tests
- Because the Kuder-Richardson procedure is general, it is usually more valuable than a split-half estimate of internal consistency 🡪 it evaluates reliability within a single test administration
- Covariance = occurs when the items are correlated with each other 🡪 they can be assumed to measure the same general trait, and the reliability of the test will be high
- Only situation that will make the sum of the item variance less than the total test score variance
- Difficulty = the percentage of test takers who pass the item
- Coefficient/Cronbach’s Alpha
- Kuder-Richardson technique requires that you find the proportion of people who got each item “correct” 🡪 many types of tests have no right or wrong answers, e.g., when Likert scales are used
- A more general reliability estimate: estimates the internal consistency of tests in which the items are not scored as 0 or 1 (right or wrong)
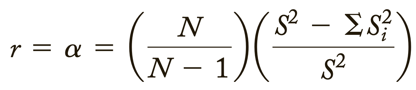
- Only difference with above is that Σpq has been replaced by ΣSi2
- = is for the variance of the individual items (i)
- Si2 can describe the variance of items whether or not they are in a right-wrong format
- Thus, Coefficient Alpha is the most general method of finding estimates of reliability through internal consistency
Factor analysis = popular method for dealing with the situation in which a test apparently measures several different characteristics.
- Can be used to divide the items into subgroups: each internally consistent
- The subgroups of items will not be related to one another
- Is of great value in the process of test construction: can help a test constructor build a test that has sub measures for several different traits 🡪 these subsets will then be internally consistent
Difference score = created by subtracting one test from another
- The difference between performances at 2 points in time
- The difference between measures of 2 different abilities (standardized units needed, Z-scores)
- In a difference score, the error (E) is expected to be larger than either the observed score (X) or the true score (T) 🡪 E absorbs error from both scores used to create the difference score
- Furthermore, T might be expected to be smaller than E because whatever is common to both measures is cancelled out when the difference score is created.
- As a result, the reliability of a difference score is expected to be lower than the reliability of either score on which it is based.
Psychologists with behavioural orientations usually prefer not to use psychological tests 🡪 direct observation of behaviour.
- Psychologists cannot always monitor behaviour continuously 🡪 they often take samples of behaviours at certain time intervals
- In practice, behavioural observation systems are frequently unreliable because of discrepancies between true scores and the scores recorded by the observer.
- Interrater-/interscorer-/interobserver-/interjudge reliability = estimating the reliability of the observers = assessing the problem of error associated with different observers
- Consider the consistency among different judges who are evaluating the same behaviour
2 of 3 ways of measuring this type of reliability:
- Record the percentage of items that 2 or more observers agree upon 🡪 most common, but not good, e.g., not considering chance
- Kappa statistic = measure of agreement between judges who use nominal scales to rate
- Indicates the actual agreement as a proportion of the potential agreement following correction for chance agreement 🡪 best method
- Values of Kappa:
- 1 = perfect agreement
- -1 = less agreement than can be expected based on chance alone
- Higher than .75 = excellent agreement
- .4-.75 = fair to good/satisfactory agreement
- Less than .4 = poor agreement
Standard reliability of a test depends on the situation in which the test will be used:
- Sometimes bringing a test up to an exceptionally high level of reliability may not be worth the extra time and money.
- On the other hand, strict standards for reliability are required for a test used to make decisions that will affect people’s lives.
When a test has an unacceptable low reliability 2 approaches are:
- Increase the length of the test 🡪 the number of items/questions
- The larger the sample, the more likely that the test will represent the true characteristic 🡪 according to the domain sampling model: each item in a test is an independent sample of the trait or ability being measured.
- The reliability of a test increases as the number of items increases.
- By using the Spearman-Brown formula, one can estimate how many items will have to be added to bring a test to an acceptable level of reliability 🡪 so the test will not be too long or costly 🡪 = prophecy formula
- The larger the sample, the more likely that the test will represent the true characteristic 🡪 according to the domain sampling model: each item in a test is an independent sample of the trait or ability being measured.
- Throw out items that run down the reliability
2 approaches to ensure that items measure the same thing:
- Perform factor analysis
- Tests are most reliable if they are unidimensional = one factor should account for considerably more of the variance than any other factor 🡪 items that do not load on this factor might be best omitted.
- To divide the test into homogeneous subgroups of items.
- Discriminability analysis = examine the correlation between each item and the total score of the test
- When the correlation between the performance on a single item and the total test score is low, this item is probably measuring something different from the other items on the test.
- It also might mean that the item is so easy or so hard that people do not differ in their response to it.
- In either case: the low correlation indicates that the item drags down the estimate of reliability and should be excluded.
Low reliability 🡪 findings/correlation not significant 🡪 potential correlations are attenuated, or diminished, by measurement error 🡪 obtained information has no value
- Correction for attenuation = dealing with the problem of low reliability by estimating what the correlation between tests would have been if there had been no measurement error 🡪 “correct” for the attenuation in the correlations caused by the measurement error.
- For this, one needs to know only the reliability of 2 tests and the correlation between them.
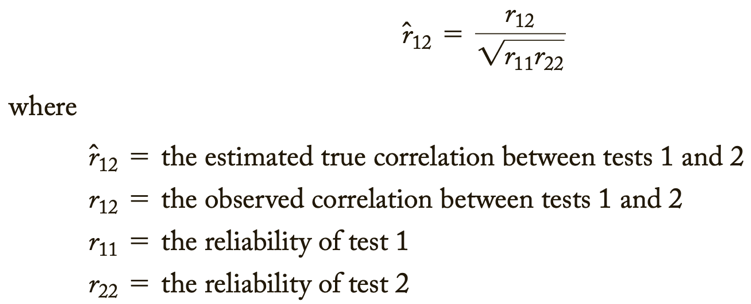
Adding more questions to heighten the reliability can be dangerous: it can impact the validity and it takes more time to take the test.
Too high reliability 🡪 remove redundant items/items that do not add anything 🡪 we want some error
Great instruction goes together with a high reliability.
For research rules are less strict than for individual assessment.
The Dutch Committee on Testing (COTAN) of the Dutch Psychological Association (NIP) publishes a book containing ratings of the quality of psychological tests.
- As a result of the growing awareness of the importance “to promote the better use of better tests” the NIP founded the COTAN.
The COTAN adopts the information approach, which entails the policy of improving test use and test quality by informing test constructors, test users, and test publishers about the availability, the content, and the quality of tests.
2 key instruments used are:
- Documentation of Tests and Test Research
- Contains a description of all tests available in The Netherlands (650+)
- Contains excerpts of research conducted with these tests
- A criterion for being listed in the book is that at least some research in Dutch samples on norms, reliability, or validity has been published.
- The descriptions have a fixed format and concern 8 characteristics:
- Target group(s)
- Construct(s) to be measured
- Availability/publisher
- Administration procedure
- Time needed for administration
- Content (e.g., number and type of items)
- Scoring (way of scoring, available norm groups, type of norms)
- References
- Dutch Rating System for Test Quality
- Evaluates the quality of a test on 7 criteria
- Rating each criterion: insufficient, sufficient, or good
- The 2009 revision:
- Similarities: the general structure and the assessment criteria
- Changes:
- Texts of all criteria were adapted to apply to both paper-and-pencil tests and computer-based tests
- For each criterion the items and recommendations were extended to include new developments (or revived old techniques)
The 7 criteria of the Dutch Rating System for Test Quality:
- Theoretical basis of the test
- Should enable the prospective test user to judge whether the test is suitable for his/her purposes.
- 3 items that deal with the theoretical basis and the logic of the test development procedure.
- Key item:
- Asks whether the manual clarifies the construct that the test purports to measure, the groups for which the test is meant, and the application of the test.
- Quality of the test materials
- The new rating system contains separate items for paper-and-pencil tests and computer-based tests.
- Both sets contain 8 items of which 3 are key items.
- Key items:
- The standardization of the test content
- The objectivity of the scoring system
- The presence of unnecessary culture-bound words or content that may be offensive to specific ethnic, gender, or other groups.
- Comprehensiveness of the manual
- Evaluates the comprehensiveness of the information the manual provides to the test user to enable the well-founded and responsible use of the test.
- Contains 7 items of which 1 is a key item.
- Key item:
- Ask whether there is a manual at all.
- For computer-based tests 3 extra items are available 🡪 about installation of the software, etc.
- Norms
- Scoring a test usually results in a raw score 🡪 partly determined by characteristics of the test, such as number of items, time limits, item difficulty, and test conditions 🡪 raw scores are difficult to interpret and unsuited for practical use.
- To give meaning to a raw score 2 ways of scaling or categorizing raw scores can be distinguished:
- Norm-referenced interpretation = a set of scaled scores or norms may be derived from the distribution of raw scores of a reference group.
- Domain-referenced interpretation = standards may be derived from a domain of skills or subject matter to be mastered, or criterion-referenced interpretation = cut scores may be derived from the results of empirical validity research.
- Raw scores will be categorized in 2 (e.g., “pass” or “fail) or more different score ranges.
- The provision of norms, standards, or cut scores is a basic requirement for the practical use of most tests, but there are exceptions.
- Criterion is assessed using 2 key items and 3 separate sections on norm-referenced, domain-referenced, and criterion-referenced interpretation.
- Key items:
- Checks whether norms, standards, or cut scores are provided
- Asks in which year or period the data were collected
- Reliability
- Reliability results should be evaluated from the perspective of the test’s application 🡪 different estimation methods may produce different reliability estimates, and in different groups the test score may have different reliabilities.
- The objective of the reliability analysis is to estimate the degree to which test-score variance is due to true-score variance.
- 3 items, of which 1 is a key item.
- Key item:
- Checks whether any reliability results are provided at all.
- Construct validity
- Validity = extent to which a test fulfils its purpose
- When the purpose is description, other validity information is required than whether the purpose is prediction of classification.
- Construct validity is required for almost all tests, whatever the purpose of test use.
- Construct-related evidence should support the claim that the test measures the intended trait or ability.
- The structure of the items with respect to construct validity is the same as for reliability.
- First, the provision of results is ascertained by means of a key item.
- Criterion validity
- Will not be required for tests that are not intended for prediction.
- Demonstrates that a test score is a good predictor of non-test behaviour or outcome criteria.
- Prediction can focus on:
- Past = retrospective validity
- Same moment in time = concurrent validity
- Future = predictive validity
- The structure of the items with respect to criterion validity is the same as for construct validity.
Quality of Dutch tests:
- For 5 of the 7 criteria, the quality of a considerable majority of the test (about 2/3 or more) is at least “sufficient”.
- However, for 2 criteria (norms and criterion validity) the quality of most tests is “insufficient”.
Overall picture is positive showing that the quality of the test repertory is gradually improving.
Standards for educational and psychological testing; 3 sections:
- Foundations = focuses on basic psychometric concepts such as validity and reliability
- Operations = considers how tests are designed and built and how they are administered, scored, and reported. It also reviews standards for test manuals and other documentation.
- Application = takes on a wide range of issues, ranging from training required to administer and interpret tests.
Validity = does the test measure what it is supposed to measure?
- Evidence of validity of a test establishes the meaning of a test.
- The agreement between a test score or measure and the quality it is believed to measure.
Validity is the evidence for inferences made about a test score.
3 types of evidence:
- Construct related
- Criterion related
- Content related
Every time we claim that a test score means something different from before, we need a new validity study 🡪 ongoing process.
- Validity really refers to evidence supporting what can be said on the basis of the test scores and not to the tests themselves.
Subtypes of validity:
- Face validity
- Measures whether a test looks like it tests what it is supposed to test.
- Face validity if the items seem to be reasonably related to the perceived purpose of the test.
- Not technically a form of validity
- Can motivate test takers 🡪 the test appears relevant
- Content validity
- Considers the adequacy of representation of the conceptual domain the test is designed to cover.
- Based on the correspondence between the item content and the domain the items represent 🡪 items are rated in terms of relevance to the content.
- Of greatest concern in educational testing
- Logical rather than statistical
- Threats to content validity:
- Construct underrepresentation = the failure to capture important components of a construct 🡪 the assessment is “too small”
- Construct-irrelevant variance = occurs when scores are influenced by factors irrelevant to the construct 🡪 the assessment is “too big”
- Criterion validity
- Tells us how well a test corresponds with a particular criterion = the standard against which the test is compared.
- Evidence is provided by high correlations between a test and a well-defined criterion measure.
- Types of criterion validity: past present or future
- Retrospective validity = the extent to which an instrument that purports to measure a particular behaviour can be shown to correlate with past occurrences that demonstrate this behaviour. Not used very often past (you already know what the diagnosis contains so there is bias with answering)
- Predictive validity = evidence that a test score or other measurement correlates with a variable that can only be assessed at some point after the test had been administered or the measurement made. future (take a test to see if therapy will work then you give therapy and see if the test predicted the outcome)
- Comes from studies that use a test to forecast performance on a criterion that is measured at some point in the future.
- The test itself is the predictor variable and the outcome is the criterion.
- Many tests do not have exceptional predictive validity.
- Concurrent validity = the degree to which the measures gathered from one tool agree with the measures gathered from other assessment techniques. present (test and clinician gives diagnosis and you see if they give the same answer)
- Obtained from correlations between the test and a criterion when both are measured at the same point in time.
- Another use: when a person does not know how he or she will respond to the criterion measure.
- Criterion-referenced tests = participants are evaluated against the specific criterion instead of how they performed relative to other participants. These tests have items that are designed to match certain specific instructional objectives.
- A style of test which uses test scores to generate a statement about the behaviour that can be expected of a person with that score.
- Construct validity
- Construct = something built by mental synthesis (e.g., intelligence).
- Is used when a specific criterion is not well-defined.
- Is used to determine how well a test measures what it is supposed to measure.
- Is established through a series of activities in which a researcher simultaneously defines some construct and develops the instrumentation to measure it.
- Required when: “no criterion or universe of content is accepted as entirely adequate to define the quality to be measured”
- It involves assembling evidence about what a test means. Done by showing the relationship between a test and other tests and measures.
- Types of construct validity:
- Convergent validity = when a measure correlates well with other tests believed to measure the same construct. Obtained in one of 2 ways:
- We show that a test measures the same things as other tests used for the same purpose.
- We demonstrate specific relationships that we can expect if the test is really doing its job.
- Discriminant validity = proof that the test measures something unique/distinct from other tests.
- Indicates that the measure does not represent a construct other than the one for which it was devised.
- To demonstrate this, a test should have low correlations with measures of unrelated constructs or with what the test does not measure.
- By providing evidence that a test measures something different from other tests, we also provide evidence that we are measuring a unique construct.
- Convergent validity = when a measure correlates well with other tests believed to measure the same construct. Obtained in one of 2 ways:
Examples of the subtypes of validity:
Face validity Does the content of the test appear to be suitable to its aims? | You create a survey to measure the regularity of people’s dietary habits. You review the survey items, which ask questions about every meal of the day and snacks eaten in between for every day of the week. On its surface, the survey seems like a good representation of what you want to test, so you consider it to have high face validity. |
|---|---|
Content validity Is the test fully representative of what it aims to measure? | A mathematics teacher develops an end-of-semester algebra test for her class. The test should cover every form of algebra that was taught in the class. If some types of algebra are left out, then the results may not be an accurate indication of student’s understanding of the subject. Similarly, if she includes questions that are not related to algebra, the results are no longer a valid measure of algebra knowledge. |
Criterion validity Do the results accurately measure the concrete outcome that they are designed to measure? | A university professor creates a new test to measure applicants’ English writing ability. To assess how well the test really does measure students’ writing ability, she finds an existing test that is considered a valid measurement of English writing ability and compares the results when the same group of students take both tests. If the outcomes are very similar, the new test has high criterion validity. |
Construct validity Does the test measure the concept that it’s intended to measure? | There is no objective, observable entity called “depression” that we can measure directly. But based on existing psychological research and theory, we can measure depression based on a collection of symptoms and indicators, such as low self-confidence and low energy levels. |
Validity coefficient = correlation that describes the relationship between a test and a criterion 🡪 tells the extent to which the test is valid for making statements about the criterion.
- Between .30-.40 are commonly considered adequate.
- Larger than .60 rarely found in practice.
- Is statistically significant if the chances of obtaining its value by chance alone are quite small 🡪 usually less than 5 in 100.
- A score tells us more than we would know by chance.
- The validity coefficient squared = the percentage of variation in the criterion that we can expect to know in advance because of our knowledge of the test scores.
- E.g., we will know .40 squared, or 16%, of the variation in college performance because of the information we have from the SAT test.
- In many circumstances, using a test is not worth the effort because it contributes only a few percentage points to the understanding of variation in a criterion.
- However, low validity coefficients (.30 to .40) can sometimes be especially useful even though they may explain only 10% of the variation in the criterion.
- In some circumstances, though, a validity coefficient of .30 or .40 means almost nothing.
Because not all validity coefficients of .40 have the same meaning, you should watch for several things in evaluating such information 🡪 evaluating validity coefficients:
- Look for changes in the cause of relationships (between test and criterion)
- Be aware that the conditions of a validity study are never exactly reproduced.
- What does the criterion mean?
- Criterion-related studies mean nothing at all unless the criterion is valid and reliable.
- Some test constructors attempt to correlate their tests with other tests that have unknown validity 🡪 a meaningless group of items that correlates well with another meaningless group of items remains meaningless.
- The criterion should relate specifically to the use of the test.
- E.g., because the SAT attempts to predict performance in college, the appropriate criterion is GPA (a measure of college performance). Any other inferences made based on the SAT require additional evidence.
- Review the subject population in the validity study
- The validity study might have been done on a population that does not represent the group to which inferences will be made.
- Be sure the sample size was adequate
- Sometimes a proper validity study cannot be done because there are too few people to study 🡪 misleading.
- The smaller the sample, the more likely chance variation in the data will affect the correlation.
- A validity coefficient based on a small sample tends to be artificially inflated.
- A good validity study: presents cross validation = assesses how well the test forecasts performance for an independent group of subjects:
- The initial validity study assesses the relationship between the test and the criterion, whereas the cross validation study checks how well this relationship holds for an independent group of subjects.
- The larger the sample size in the initial study, the better the likelihood that the relationship will cross validate.
- Never confuse the criterion with the predictor
- It is important to have no confusion between predictor (e.g., GRE exam) and criterion (e.g., success in the program).
- Check for restricted range on both predictor and criterion
- A variable has a “restricted range” if all scores for that variable fall very close together 🡪 within a limited range.
- The problem: correlation depends on variability 🡪 requires that there be variability in both the predictor and the criterion.
- Review evidence for validity generalization
- Criterion-related validity evidence obtained in 1 situation may not be generalized to other similar situations 🡪 generalizability = applied to other situations.
- You need to prove that the results obtained in a validity study are not specific to this original situation. We cannot always be certain that the validity coefficient reported by a test developer will be the same for our situation.
- Generalizations from the original validity study to other situations should be made only based on new evidence.
- There are many reasons why results may not be generalized.
- Consider differential prediction
- Predictive relationships may not be the same for all demographic groups 🡪 the validity for men could differ in some circumstances from the validity for women. Or native versus non-native speakers.
- Under these circumstances, separate validity studies for different groups may be necessary.
Relationship between reliability and validity:
- Reliability and validity are related because it is difficult to obtain evidence for validity unless a measure has reasonable reliability.
- On the other hand, a measure can have high reliability without supporting evidence for its validity.
- Defining the validity of a test will not be possible/futile of the test is not reliable.
- Unreliable and valid: cannot exist
- We can have reliability without validity:
- Reliable and invalid: you get a reliable outcome but for a different measure/construct/concept 🡪 it did not measure what it was supposed to measure
- Sometimes we cannot demonstrate that a reliable test has a meaning
The total variation of a test score into different parts:
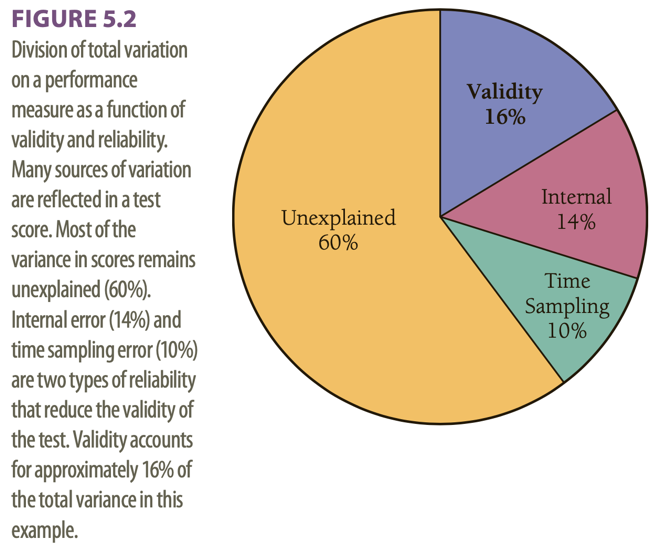
This example has a validity coefficient of .40.
Assessment of personality relies heavily on self-report measures.
- Response biases (e.g., socially desirable answers)
- The reliability and validity of self-ratings can be questioned because of distorted self-perceptions due to:
- Memory failure
- Consistency seeking
- Self-enhancement
- Self-interests 🡪 such as having the secondary benefits of being ill or the reduction of sanctions of criminal acts
- It is also possible that because of (personality) pathology, self-knowledge is limited.
Can people be trusted in what they say about themselves? 🡪 it is preferable to maximize the validity by combining self-report approach with other methods, such as informant reports and observational measures.
Hofstee’s definition of personality: in terms of intersubjective agreement.
- As judgement is subjective by definition 🡪 whether provided by the target persons themselves or by someone else 🡪 objectivity is not within reach.
- The best point of reference for the assessment of personality: the averaged judgements of multiple informants. Because:
- Response tendencies and interpretation and measurement errors will have been averaged out 🡪 more reliable and valid.
- His recommendation: those who know the target person best
- Self-reports add to the reliability of assessments to the extent that they agree with the assessments by others.
- He argues that to the extent that subjective personality deviates systematically from the consensus of others, such deviations may be found clinically relevant.
Preconceptions: informant methods for personality assessment are time-consuming, expensive, ineffective, and vulnerable to faking or invalid responses.
- Vazire does not agree 🡪 according to her, informant reports can be cheap, fast, and easy.
Still, in daily clinical practice, systematically collecting information from others than the client is not common use. Clinicians generally use interview and observation techniques to determine personality and psychopathology.
Multiple informant information on client personality and psychopathology is not embraced by clinicians.
Level of self-other (dis)agreement:
- Self-other agreement tends to be moderate
- Self-informant agreement appeared to be roughly equivalent for questionnaires and interviews
- Informants report more personality pathology than subjects themselves
- A decrease of disagreement was mainly due to changes in clients’ self-judgements
Moderators of self-other agreement:
- Length of acquaintanceship between subject and informant supposed to enhance the accuracy of ratings.
- Individuals with temporally stable response patterns have higher self-other agreement.
Self-assessment in clinical research has most validity.
Most reliable information yielded from assessment of others.
Other studies are based on the assumptions that each of the 2 sources of information yields unique information.
Aggregate ratings by multiple informants correlated higher with observed behaviour than did self-ratings, thus, yielding more accurate information.
Information from others added value when it came to predicting limitations and interpersonal problems, or depressive symptoms and personality characteristics.
We need to examine the content of disagreement.
Reasons for substantial disagreements between couples:
- Idiosyncratic understanding of items
- Reference to different time frames or roles
- Unavailability for the spouse of covert experience of the subject
2 hypotheses:
- The larger the discrepancy between self-report and (averaged) informants’ reports on personality, the more (personality) pathology in terms of symptoms and DSM-IV diagnoses is found.
- The larger the discrepancy between self-report and (averaged) informants’ reports, the more a positive therapy outcome, defined as reduction in symptoms and an improvement in functioning will be limited. treatment characteristics (number of no shows, cancelled appointments)
Results:
- Vazire’s claim: feasibility
- Support for the feasibility of the use of multiple informant reports by means of personality questionnaires in clinical practice was found.
- In the authors’ opinion, symptoms, interpersonal context, and personality are inextricably related and should all be considered in assessing a client.
- Hofstee’s claim: clinical relevance
- Self-other disagreement was found to be a relatively independent constant in terms of the personality characteristics determined with the instrument.
- Individuals found themselves less extraverted and more emotionally stable than their proxies 🡪 these results seemed not random.
- Self-other disagreement occurred predominantly in introverted, shy, hostile, and depressed persons, who tended to have more personality problems.
- Self-other disagreement does not appear to reflect current pathological state but rather to represent a more structural characteristic of either the client’s personality or his/her interpersonal relationships 🡪 on average, symptoms decreased and functioning increased but self-other disagreement did not significantly change between t1 and t2.
- Results confirm the first hypothesis 🡪 self-other disagreement on personality reflects psychopathology.
- Prediction of therapy outcome
- Less convincing support on the fact that self-other disagreement on personality would reduce therapy effects.
- Although, it strongly predicts dropout.
- A decrease in depression, hostility, and shyness goes together with a decrease in the overall self-other discrepancy on the client’s personality profile.
- A decrease in disagreement on autonomy appeared to play a key role in these changes.
- Disagreement on conscientiousness was the main predictor of dropout.
- Less convincing support on the fact that self-other disagreement on personality would reduce therapy effects.
2 conclusions:
- Information on the amount of disagreement might supplement the diagnostic process.
- Greater self-other discrepancies can signal the presence of personality pathology as well as a greater risk of dropout.
- Information on the amount of self-other disagreement might supplement the therapy process.
- The therapist could discuss the validity of the client’s view considering this client’s average informant’s view to improve specific therapy results.
Larger disagreement between self-evaluation and evaluation by someone else: can signal presence of personality pathology as well as a greater risk of dropout.
SCID-5-S: Het gestructureerd klinisch interview voor DSM-5 Syndroomstoornissen
- Het SCID-5-S (voorheen SCID-I) leidt de clinicus stap voor stap door het diagnostisch proces waarmee alle belangrijke DSM-5-syndroomstoornissen kunnen worden vastgesteld. Van depressieve stoornis tot schizofrenie, ADHD en psychotrauma gerelateerde stoornissen.
- Het SCID-5-S Interview bestaat uit 461 vragen en wordt geleverd met handleiding.
- Extra modules en stoornissen voor de Nederlandse situatie
- In aanvulling op het interview kan de SCID-5-S Vragenlijst (SCID-5-SV) als screeningsinstrument gebruikt worden 🡪 bespaart tijd.
- Doel: categorisering
- Doelgroep: volwassenen (vanaf 18 jaar) en met een minimale aanpassing van de bewoording kan de SCID-5-S ook bij adolescenten worden gebruikt.
- Afname en interpretatie door zorgprofessionals die classificeren met de DSM-5: psychiaters, psychologen, (ortho)pedagogen, professionals in de GGZ, (huis)artsen, verpleegkundigen, psychosociaal werkenden.
- SCID-5-S is not a psychological instrument 🡪 it is just counting symptoms = more of a statistical method.
CES-D: Center for Epidemiologic Studies Depression scale
- Ontwikkeld met het doel om depressieve gevoelens/symptomen bij bevolkingsgroepen te kunnen vaststellen.
- Zelfbeoordelingslijst en meet de omvang van depressieve symptomen, waarbij niet alleen milde symptomen maar ook ernstige symptomen gemeten kunnen worden.
- Het voorkomen van depressieve symptomen in de week voorafgaande aan de afname van de vragenlijst wordt gemeten.
- Meet geen chronische depressie, maar registreert de depressieve gevoelens die als gevolg van een bepaalde gebeurtenis kunnen ontstaan (reactieve depressie).
- De vragenlijst bevat de volgende componenten:
- Depressieve stemming
- Schuldgevoelens en gevoelens van inferioriteit
- Gevoelens van hulpeloosheid en wanhoop
- Verlies van eetlust
- Slaapstoornissen
- Psychomotorische retardatie
- Doelgroepen: kinderen, ouderen en volwassenen
- Soort meetinstrument: vragenlijst
- Functies: mentale functies
- Aandoeningen: geestelijk welbevinden, psychische stoornissen
Task 4 – Andrew’s problems become clear
Caldwell: anecdotal interpretation, selectively relating his experiences, without scientific data 🡪 referring to clinical experience to validate his use of a test.
- Disadvantage: a psychologist’s prediction of test scores will sometimes be correct by chance, not because the psychologist’s overall impression of the client is accurate 🡪 use of the test is then not valid.
2 traditional reactions on this/him in clinical psychology:
- Romantic reactions = learning from experiences/informal observations 🡪 likely to be greatly impressed and inspired by Caldwell
- Empiricist reactions = insist that grand claims are scientifically tested 🡪 a more sceptical attitude towards Caldwell
2 extremes 🡪 most of the time it is a mix.
Both empiricists and romanticists base their judgments on a combination of scientific findings, informal observations, and clinical lore 🡪 empiricists place a greater emphasis on scientific findings.
- Key distinction: those in the romantic tradition are likely to accept findings based on clinical validation, whereas those in the empiricist tradition are likely to maintain a sceptical attitude.
- Clinical validation = the act of acquiring evidence to support the utility of specific procedures for diagnosis or treatment.

Research supports the empiricist tradition 🡪 it can be surprisingly difficult to learn from informal observations, both because clinicians’ cognitive processes are fallible and because accurate feedback on the validity of judgements is frequently not available in clinical practice. Furthermore, when clinical lore is studied, it is often found to be invalid.
2 new approaches to evaluating the validity of descriptions of personality and psychopathology:
- Have clients make self-ratings every day to indicate whether they had performed a particular behaviour on a given day. Advantages: they do not have to rely on memory + by making ratings for specific behaviours they do not have to make judgements that require more than a low degree of inference. It would be of value to compare psychologist’s judgements to results from this behaviour record, because we can then see whether psychologists can report certain behaviours correctly.
- Improvements in research design and statistical analysis 🡪 psychologists should routinely collect information from more than 1 source (self-ratings, parents, teachers, peers, etc.) 🡪 removing variance due to context and perspective using statistical analysis.
Cognitive heuristics and biases: used to describe how clinical psychologists and other people make judgements.
- Affect heuristic = reliance on feelings of affective responses
- Affective responses are rapidly and automatically
- Affect is likely to guide clinical judgement and decision-making
- Positive effects: are related to clinical intuition and the setting of meaningful treatment goals
- Negative effects: are related to biases, e.g., race and gender bias
In conclusion: psychologists should reduce their reliance on informal observations and clinical validation when:
- Choosing an assessment instrument or treatment intervention
- Revising diagnostic criteria
- Making clinical judgements or test interpretations
Anchoring = the tendency to fixate on specific features of a presentation too early in the diagnostic process, and to base the likelihood of a particular event on information available at the outset.
Anchoring is closely related to:
- Premature closure = the tendency to accept a diagnosis before it is fully verified.
- Confirmation bias = the tendency to look for confirming evidence to support a hypothesis, rather than look for disconfirming evidence to refute it.
Diagnoses can be biased, e.g., by patient (race) and task (dynamic stimuli lacking predictability) characteristics.
Diagnostic anchor = diagnoses suggested in referral letters
- Moderately experienced clinicians use the suggested diagnosis as anchor 🡪 when they received a referral letter suggesting depressive complaints, they were more inclined to classify the client with a depressive disorder when real symptoms match.
- To conclude: the diagnoses in referral letters influence the diagnostic decisions made by moderately experienced clinicians.
- The correctness of the diagnoses made by very experienced clinicians are unaffected by the referral diagnoses.
In conclusion: referral diagnoses/anchors do seem to influence the correctness of the diagnoses of intermediate but not very experienced clinicians.
- Bright side: very experienced clinicians may be unaffected by information presented early on in their decision-making process.
- Downside: very experienced clinicians may not benefit from correct diagnosis referral information.
Intermediate/moderately experienced clinicians tend to process information distinctively differently 🡪 and perform differently.
- In some tasks they outperform their less and more experienced colleagues, e.g., in recall of clinical case information.
- They tend to perform worse when it comes to accuracy of psychodiagnostic classification due to the poor organization of their extending knowledge.
Experience brings about a shift: from more deliberate, logical, step-by-step processing to more automatic, intuitive processing 🡪 increased experience = increased tendency to conclude in favour of first impressions.
The present study indicates that the quality of referral information is important, certainly for clinicians with a moderate amount of experience 🡪 when uncertain about the diagnosis it is best to omit a diagnosis instead of giving a wrong “anchor”
Diagnostic errors 🡪 diagnosis with x while disease y 🡪 death
Daniel Kahneman:
- System 1 thinking:
- What is 1+1?
- Fast
- Snap decision
- Often correct
- Needs to be self-monitored 🡪 it can make snap errors as quickly as it makes correct diagnoses
- System 2 thinking:
- What is 17x24?
- Slow
- Analytical
- Requires conscious effort
- Can help to avoid mistakes made by system 1
We fluidly switch back and forth between these.
Not 2 physically separate systems but represent a model that can help us better understand different ways the brain operates.
When making a diagnosis: system 1 automatically kicks in when we recognize a pattern in a clinical presentation. System 2 requires deliberate thinking 🡪 when not used 🡪 diagnostic errors.
System 1 thinking becomes more accurate as clinicians move through their careers (become more experienced) and it can recognize (more easily) atypical/variant presentations.
Types of cognitive mistakes that can lead to diagnostic errors:
- Premature closure = occurs when the initial diagnosis is heavily focused on, and the mind becomes closed to other possibilities.
- Representative bias = the diagnostician/clinician is looking for the classic presentation of a disease and the client presents with an atypical or variant pattern.
- Experienced clinicians know variants of common diagnoses are frequent and they happen more often than we immediately think.
Bayes’ theorem/Bayes’ rule = a formula used to determine the conditional probability of events.
- Describes the probability of an event based on prior knowledge of the conditions that might be relevant to the event.
- Conditional probability = a measure of the probability of an event occurring, given that another event has already occurred.
Bayes’ rule is designed to help calculate the posterior probability/post-test probability of an individual’s condition = the probability after the test has been taken and given the outcome of the test.
Based on 3 elements:
- The prevalence/prior probability/pre-test probability/base rate of that condition in the population of that individual
- The outcome of a test
- The psychometric characteristics of that test 🡪 its sensitivity and specificity
Sensitivity = number of individuals correctly diagnosed, the rest are false negatives
Specificity = number of individuals correctly seen as healthy, the rest are false positives
To use Bayes’ rule, it is essential to know: the prevalence of the condition in the population of which the individual is a member 🡪 leads to incorrect conclusions when skipped.
If in a given population a condition is rare (= low prevalence), the probability that the individual has the condition can never be high, even though it is higher with a positive test result than before the test outcome was known.
Different population 🡪 different prevalence of the condition 🡪 same test result leads to a different probability of the same condition
Not following Bayes’ rule properly 🡪 overdiagnosis 🡪 overtreatment
Prev = prevalence/base rate/pre-test probability in the GP’s population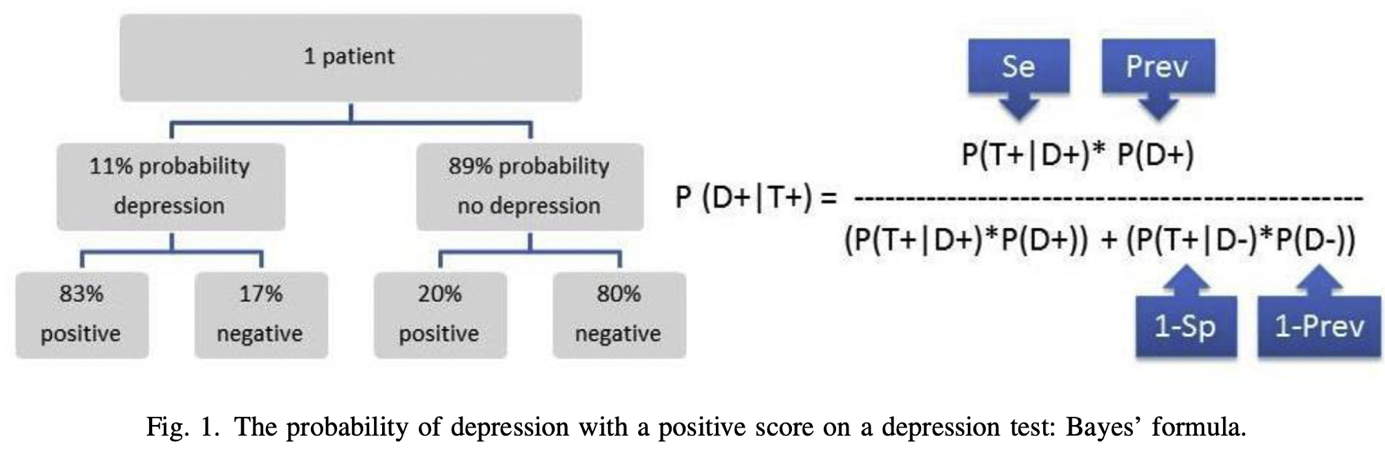
P = probability/likelihood
| = under the condition that/given
D+ = having depression
T+ = positive test result
So, P(D+|T+) means: the probability (P) that the client has a depression (D+) given (|) a positive test result (T+) on a depression questionnaire 🡪 in this case the BDI. 
- This is the probability we want to know.
Thus, P(D+|T+) for this client from this GP population is about one third (34%) 🡪 posterior probability/post-test probability
34% is a low probability 🡪 too low for treatment indication
This test (the BDI) cannot be used to establish the presence of depression 🡪 if a clinician is aware of Bayes’ rule, extra diagnostics are needed in addition to administering the BDI.
- The BDI could justifiably be used to exclude depression, but not to establish its presence.
- A negative test result, on the other hand, gives a relatively high level of certainty about the absence of depression, indeed a probability that is higher than the specificity.
The calculation is also easy to do with absolute numbers 🡪 steps summarized below. 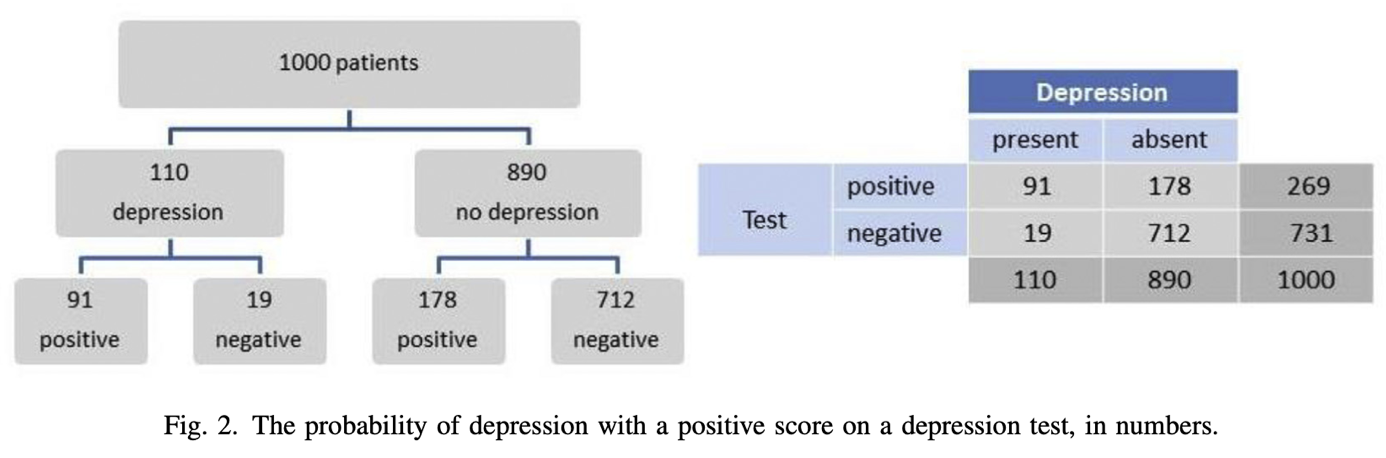

Positive score: 91/(91+178) = 0,34
Negative score: 712/(19+712). = 0,97 (probability of no depression with a negative score)
Clinicians often forget to include the pre-test probability in their interpretation. If they do look further than the test result, they tend to only consider the sensitivity of a test. Typically, a positive test score is interpreted as the presence of the condition.
Clinicians that are aware of Bayes’ rule 🡪 when interpreting a test, they will take into consideration the setting in which the test was taken and the population to which the tested person belongs 🡪 they will establish the prevalence of the condition in that setting and population.
Sometimes general population, sometimes prevalence in clinicians’ practice or institute is more relevant.
It is recommended to use the information of your own institute or organization about prevalence of a certain disorder or disease.
Ignoring Bayes’ rule = overdiagnosis of conditions with a low pre-test probability (= not prevalent) 🡪 with low prevalence the “no disorder or disorder” group is very large, the post-test probability will remain low even with very high specificity, despite the large numbers of people who have a depression and who tested positive.
Making the error of omitting to take prevalence into account 🡪 major consequences for treatment policy 🡪 and thus for the course of a client’s symptoms.
- Remember: given a positive test result, the probability of a condition depends on the population and setting of the client, on the prior probability of them having the condition.
You should not simply rely on the score of a test. Neither can we rely on the sensitivity and specificity only. Prevalence is also important.
Base rate problem:
- E.g., tropical diseases or fat versus skinny people
- Risk of low base rate 🡪 it is never diagnosed
- Minimalize generalization 🡪 father with bipolar disorder example
- Psychologists work up from highest to lowest base rate when diagnosing
12 common biases in forensic neuropsychology 🡪 encountered in evaluation or provision of expert opinions and testimony.
- The first 4 are logistical and administrative: pertaining to how the neuropsychologist has set up the evaluation and the source of information relied upon
- The next 2 are statistical in nature
- The final 6 might be best described as a subgroup of cognitive, personal, and attributional biases
- Role bias: conflating clinical and forensic roles
- Clear distinctions between clinical and forensic roles with precautions not to mix these.
- The treating neuropsychologist frequently attempts to develop a therapeutic alliance with the patient 🡪 emphasizing trust and empathy. May view him-/herself as an advocate for the patient to promote health, well-being, and recovery.
- The retained expert (hired by an attorney) wants primary to help the legal process, but also has to corroborate self-report and remain objective and impartial.
- Role conflict/irreconcilable conflict 🡪 health professionals who serve as the retained expert of a former patient 🡪 double agents/dual agents 🡪 can result in impairments in objectivity and/or exploitation.
- Solution: fact witness/treating expert (neuropsychologist) 🡪 not providing forensic opinions.
- It is permissible for this clinician to testify under oath regarding facts about his/her patient such as start, duration, and completion of care, methods of treatment employed, outcome, etc. However, the treating neuropsychologist has not performed forensic evaluation 🡪 cannot provide certain expert opinions or formulate conclusions from the reports of others.
- It is when the neuropsychologist “changes hats” and provides forensic opinions regarding causality, permanency of a condition, and other psycho-legal matters that potential role conflict and/or ethical issues arise.
Tackling point: do not take 2 roles at once.
- Financial/payment bias
- Eventual payment of your final bill is 100% dependent on the outcome of the case 🡪 a lot of tests, treatments, etc.
Tackling point: be very careful with getting paid and make clear for what you are being paid.
- Referral source bias (and retaining attorney pressure)
- It is important that the neuropsychologist guards against automatically offering favourable opinions for the side that hired him/her.
- Some people only work for defense 🡪 careful not just saying anything because you are defense.
- When the attorney starts the referral, he/she will tell the neuropsychologist what he/she wants to get out of it 🡪 the attorney wants the neuropsychologist to affiliate with them and to accept their point of view. It is encouraged to resist this before reviewing all the records and conducting your own evaluation. Information received at the start of a case should raise awareness on primacy bias or anchoring.
- 50-50 referral pattern does not exist.
Tackling point: be critical with forming a professional opinion about the case, do not just say something because you always handle defense cases.
- Self-report bias (need for corroborative data)
- Examinee self-report in forensic settings can be notoriously unreliable, with problems that bring into question the accuracy of one’s subjective history.
- Self-report is not a reliable basis for estimation of pre-injury cognitive status.
Tackling point: make use of supporting data to form an opinion.
- Under-utilization of base rates
- Neuropsychologists under-utilize or are unaware of base rates.
- Base rate = the frequency or prevalence of e.g., a diagnosis or disorder within a given population.
- Base rates are especially important in calculation of positive predictive probability and negative predictive probability.
- Base rates help inform the decision-making process and address the significance of a particular test finding.
- Knowing the base rates of the condition and symptoms in question will only increase the forensic practitioner’s diagnostic and predictive accuracy.
Tackling point: know the prevalence.
- Ignoring normal variance in test scores
- It is a mistake that all abnormal scores reflect brain dysfunction 🡪 may be explained through unusual, unexpected, or special findings.
- It is equally incorrect to say that all abnormal scores are acquired 🡪 average performance may result from a variety of factors, including the psychometrics of a given test (e.g., low ceiling).
Tackling point: know when test scores are abnormal.
- Conformation bias
- An individual preferentially favours information that supports an original hypothesis and ignores or dismisses data that may disconfirm the favoured hypothesis.
- It is the process of seeking information based on a desired outcome.
Tackling point: treat the diagnostic process with care and always have 2 hypotheses.
- Personal and political bias
- Neuropsychologists and their family and friends can be the victim of various adverse life experiences that can shape attitudes and contribute to unconscious stereotyping or frank bias.
- Careful self-examination is required here to ensure the expert is not biased by such an event or trying to champion a cause.
- The forensic neuropsychologist has to be aware of countertransference issues = examinee characteristics (e.g., age, gender, attractiveness, SES, ethnicity) that could elicit an emotion or reaction in the neuropsychologist that would affect attitudes and expert opinions.
Tackling point: be alert for personal and political bias.
- Group attribution error
- Belief that an individual’s traits are representative of a whole group.
- The understanding of group attribution error has been at the core of the social psychology research on racism and stereotype persistence for many years.
Tackling point: analyse interviews to see if there aren’t symptoms that are being missed just because someone is presenting in a certain way.
- Diagnosis momentum
- Tendency for an opinion or working diagnosis to become almost certain as it is passed from person to person, thereby suppressing further evaluation.
- Clinicians may prematurely and/or inaccurately assign a diagnosis early, and then this diagnosis gains momentum when subsequent clinicians accept the initial diagnosis, with no consideration of differential diagnoses.
Tackling point: critically review diagnosis and if possible, conduct your own investigation.
- Good old days bias
- Tendency to view oneself as healthier or higher functioning in the past, or to underestimate symptoms in the past, prior to an injury.
- Clients/patients tend to report fewer pre-injury symptoms than the base rate of symptoms in healthy samples.
- These clients/patients tend to overestimate the actual degree of change from pre-injury.
Tackling point: use complete data from the past and after the accident to have a good overview if capabilities were really that impaired.
- Overconfidence
- Tendency to hold a false and misleading assessment of our skills, intellect, or talent.
- In short, it is an egotistical belief that we are better than we actually are.
- Neuropsychologists who are 100% certain that they know the truth, perhaps because of the confirmatory bias or diagnosis momentum problems.
- It can lead to diagnostic errors because of an inability to consider competing hypotheses.
Tackling point: same as with confirmation bias; make use of the concurrent hypothesis.
Bias will always exist, no matter what. Bias is also unaffected by years of experience in practice.
The diagnosis of mental disorders has 4 major goals:
- By giving someone a diagnosis 🡪 professional attempts to identify the problems
- Professional tries to recognize the factors contributing to and maintaining the identified problems
- Diagnosis 🡪 professional can choose and carry out the most appropriate course of treatment
- Professional can change the treatment to meet the needs of the client if necessary
Giving an accurate diagnosis is important for the correct identification of the problems and the best choice of intervention.
Essential problem in assessment and clinical diagnosis: the neglect of the role of cultural differences on psychopathology.
One way to conceptualize this problem is to use the ethnic validity model in psychotherapy 🡪 the recognition, acceptance, and respect for the presence of communalities and differences in psychosocial development and experiences among people with different ethnic or cultural heritages.
Useful to broaden this to cultural validity = the effectiveness of a measure or the accuracy of a clinical diagnosis to address the existence and importance of essential cultural factors, e.g., values, beliefs, communication patterns.
- An exploration of inaccuracies in evaluation and diagnosis due to differences in race, ethnicity, nationality, or culture.
Problems because of the lack of cultural validity in clinical diagnosis:
- Clinically: an incorrect diagnosis and ineffective treatment of culturally different populations
- Socially: individuals may be unnecessarily stigmatized and institutionalized because of diagnostic errors
Universalist perspective = assumes that all people, regardless of race, ethnicity, or culture develop along uniform psychological dimensions.
- This is a cultural uniformity assumption 🡪 prevents clinicians from recognizing cultural differences that may affect the assessment and diagnosis of culturally diverse clients.
- Has consistently been used in assessment and diagnosis
Threats to cultural validity are due to a failure to recognize or a tendency to minimize cultural factors in clinical assessment and diagnosis.
Sources of threats to cultural validity:
- Pathoplasticity of psychological disorders
- Refers to the variability in symptoms, course, outcome, and distribution of mental disorders among various cultural groups.
- 2 major examples of it among Asian Americans 🡪 the severity of psychiatric symptoms, and the distribution and prevalence/rates of mental disorders.
- 3 possible causes for the observed higher severity among Asian Americans:
- Higher rates of mental health problems
- Underutilization of mental health services
- Misdiagnosis because of miscommunication or lack of cultural knowledge
- Threat results from a failure to recognize cultural plasticity often associated with various forms of psychopathology.
- Cultural factors influencing symptom expression
- The influence of the client’s cultural background on their symptom expression/manifestation.
- E.g., in hospitalization, somatization
- Inappropriateness of and stigma attached to expressing psychological symptoms 🡪 Asian Americans = somatise psychological symptoms
- Psychologization of depression = Westerners overemphasize the affective or psychological aspects of depression compared with other cultures (more somatization).
- Behaviours that may be considered indicative of psychological disorders are actually the norm in a different culture.
- The influence of the client’s cultural background on their symptom expression/manifestation.
- Therapist bias in clinical judgement
- Therapist bias = culture-based countertransference = the client’s racial, ethnic, and cultural characteristics are likely to elicit therapist reactions, which may in turn affect the services provided.
- Racial or ethnic differences may affect therapist clinical judgement and assessment 🡪 over-pathologizing a culturally different client.
- There is a subjective nature of assessment, data interpretation and clinical diagnosis 🡪 therapists judge clients from another culture to be more severely disturbed.
- Language capability of the client
- Language may serve as a barrier to effective therapeutic communication:
- It may interfere with the effective exchange of information 🡪 misunderstandings
- It may stimulate bias in the therapist performing the evaluation.
- The use of interpreters 🡪 may result in distortions that may negatively influence diagnostic evaluations 🡪 under-/overestimation of symptoms = interpreter effect
- Words can have different meanings or connotations in diagnosing one’s problems
- Clinicians and interpreters who may lack flexibility, openness (to learning), and knowledge of the client’s culture may not be able to provide best clinical care to clients with limited English proficiency.
- Language may serve as a barrier to effective therapeutic communication:
- Inappropriate use of clinical and personality tests
- = generalization
- Clinical and personality test results have tended to show that Asian Americans have more severe symptoms and profiles than do Whites. The results of these tests need to be interpreted with a great deal of caution for several reasons:
- Most of these measures were developed and normed on White samples 🡪 their predictive validity for other ethnic and cultural groups needs to be independently established.
- Only a few of the clinical diagnostic instruments have been translated into Asian languages.
- Although Western models of personality structure may provide a valid picture of intraindividual aspects of personality, they need to be complemented with indigenous models of personality that focus on the social and relational aspects of personality.
- One of the fundamental problems: relates to measurement equivalence of tests and measures = the same construct being measured across some specified groups.
- Using personality and diagnostic tests in Asian Americans 🡪 differences in definitions of mental illness and health, and there are indeed “many ways of being human”.
- Using existing tests to diagnose 🡪 may formulate culturally invalid diagnoses.
In conclusion, cultural factors are important to clinical diagnosis and assessment of psychopathology.
Recommendations to reduce sources of threats to cultural validity:
- Therapists should conduct culturally relevant interventions
- Therapists should be aware of communication and language differences
- Counsellors must be careful not to misinterpret cultural effects
- Informal support sources, such as churches, ethnic clubs, family associations, and community leaders, be called upon for assistance in understanding cultural traditions and systems when working with Asian American clients
- Ensure the measurement equivalence of the assessment instruments used by therapists 🡪 otherwise interpret with caution
- Be aware of within-group differences as well as between-group differences 🡪 society in which a client lives influences his/her perceptions and how these may vary by region 🡪 e.g., Chinese Americans living in Chinatowns in large cities may be facing different problems than do those living in rural areas.
Bias = nuisance factors in cross-cultural score comparisons
Equivalence = more associated with measurement level issues in cross-cultural score comparisons
Thus, both are associated with different aspects of cross-cultural score comparisons of an instrument 🡪 they do not refer to intrinsic properties of an instrument.
Bias occurs if score differences on the indicators of a particular construct do not correspond to differences in the underlying trait or ability 🡪 e.g., percentage of students knowing that Warsaw is Poland’s capital – geography knowledge.
Inferences based on biased scores are invalid and often do not generalize to other instruments measuring the same underlying trait or ability.
Statements about bias always refer to applications of an instrument in a particular cross-cultural comparison 🡪 an instrument that reveals bias in a comparison of German and Japanese individuals may not show bias in a comparison of German and Danish subjects.
3 types of bias:
- Construct bias
- Bias caused by/because of the theoretical construct
- Occurs if the construct measured is not identical across cultural groups 🡪 e.g., 2 aspects of intelligence: reasoning versus social when measuring it.
- Solution: specify the theoretical conceptualization underlying the measure
- Method bias
- Bias caused by/because of the method (e.g., form of test administration)
- Can have devastating consequences on the validity of cross-cultural comparisons 🡪 will often lead to a shift in average scores.
- 3 types:
- Sample bias = incomparability of samples on aspects other than the target variable
- Cultural groups often differ in educational background and, when dealing with mental tests, these differences can confound real population differences on a target variable.
- Instrument bias = problems deriving from instrument characteristics
- E.g., stimulus familiarity = e.g., making models with iron wire is a popular pastime among Zambian boys 🡪 scoring higher when using iron wires than British children. Reversed when working with paper and pencil.
- Administration bias = communication problems between interviewers and interviewees can easily occur, especially when they have different first languages and cultural backgrounds.
- Sample bias = incomparability of samples on aspects other than the target variable
- Item bias/differential item functioning
- Bias caused by/because of the item content
- Refers to distortions at item level, unlike construct and method bias
- For persons from different cultural groups with equal total scores (i.e., who are equally intelligent, anxious or whatever is measured), an unbiased item should be equally difficult (or attractive).
- Items should have equal mean scores across the cultural groups 🡪 different means on that item point to item bias.
- Detecting item bias: Mantel-Haenszel statistic = analysing bias in dichotomously scored items which are common in mental tests.

The likelihood of a certain type of bias will depend on:
- The type of research question and the type of equivalence aimed at:
- Structure-oriented studies = identity of psychological constructs is addressed 🡪 e.g., whether the Big Five constitute an adequate description of personality in various cultural groups.
- Level-oriented studies = examine differences in averages across cultural groups 🡪 e.g., are Chinese more introvert than British?
- The cultural distance of the groups involved = all aspects in which the groups differ, and which are relevant to the target variable.
Equivalence = measurement level at which scores can be compared across cultures.
Equivalence of measures (or lack of bias) is a prerequisite for valid comparisons across cultural populations 🡪 can be defined as the opposite of bias.
Hierarchically linked types of equivalence (from small to high):
- Construct/structural/functional equivalence
- The same construct is measured in each cultural group but the functional form of the relationship between scores obtained in various groups is unknown.
- The same construct is measured across all cultural groups studied 🡪 regardless of whether or not the measurement of the construct is based on identical instruments across all cultures.
- Implies the universal (i.e., culture-independent) validity of the underlying psychological construct.
- Construct equivalence is associated with an etic position = from outside/the perspective of the observer.
- Construct inequivalence is associated with an emic position = emphasizes the idiosyncrasies of each culture and, therefore, favours an indigenous approach to assessment 🡪 from within the social/cultural group/the perspective of the subject.
- A common procedure is to examine the nomological network of the measure in every culture = a representation of the concepts (constructs) of interest in a study, their observable manifestations, and the interrelationships between these.
- Convergent validity (type of construct validity) = pattern of high correlations with related measures.
- Discriminant validity (type of construct validity) = pattern of low correlations with measures of other constructs.
- E.g., of structural equivalence = COVID-19 (information is the same all over the world) 🡪 different with psychological/mental disorders 🡪 is rare in mental health.
- Measurement unit equivalence
- Obtained when 2 metric measures/scores have the same measurement unit across populations but have different origins 🡪 the scale of one measure is shifted with a constant offset as compared to the other measure.
- E.g., temperature scales Kelvin and Celsius: the 2 scales have the same unit of measurement, but their origins differ 273 degrees. Scores obtained with the 2 scales cannot be directly compared but if the difference in origin (i.e., the offset) is known, their values can be converted to make them comparable.
- Full scale/scalar equivalence
- Obtained when scores/2 metric measures have the same measurement unit and same origin in all populations.
- E.g., when temperature is measured using a Celsius scale in both groups 🡪 differences in temperature can be compared directly between the 2 groups.
- Assumes completely bias-free measurement = a distinction with measurement unit equivalence.
Bias tends to challenge and can lower the level of equivalence:
- Construct bias leads to: conceptual inequivalence. Method and item bias do not affect construct equivalence.
- Method and item bias can threaten: scalar equivalence. Such a bias will reduce scalar equivalence to measurement unit equivalence.
An appropriate translation requires: a balanced treatment of psychological, linguistic, and cultural considerations 🡪 translation of psychological instruments involves more than rewriting the text in another language.
2 common procedures to develop a translation:
- Translation-backtranslation procedure
- A text is translated from a source into a target language.
- A second interpreter (or group of interpreters) independently translates the text back into the source language.
- The accuracy of the translation is evaluated by comparing the original and backtranslated versions.
- However, a translation that is linguistically correct may still be of poor quality from a psychological point of view.
- Committee approach
- A group of people, often with different areas of expertise, prepare a translation.
- Strength: cooperative effort that can improve the quality of translations 🡪 especially when the committee members have complimentary areas of expertise.
- 2 procedures:
- Simultaneous development = a new instrument is to be developed 🡪 easier to carry out
- Successive development = an existing instrument is to be translated to be used in a multilingual context 🡪 most common
- 3 options of successive development available:
- Application = literal translation of an instrument into a target language (most common).
- Use of application can result in biased instruments 🡪 when the following assumption is not met: the underlying construct is appropriate in each cultural group and a simple, straightforward translation will suffice to get an instrument that adequately measures the same construct in the target group.
- Adaptation = literal translation of a part of the items and/or changes in other items and/or the creation of new items.
- When the use of application leads to bias.
- Makes sure that the underlying constructs are measured adequately in each language.
- Assembly = instrument must be adapted to such a degree that practically a new instrument is assembled.
- Adequate when: construct bias, caused by differential appropriateness of the item content for most of the items, threatens a direct comparison.
- Another indication: the incomplete overlap of the construct definition across cultures, e.g., aspects of the construct that are salient for some cultures but are not covered in the instrument.
- Application = literal translation of an instrument into a target language (most common).
Remedies: most strategies implicitly assume that bias is a nuisance factor that should be avoided 🡪 there are techniques that enable the reduction and/or elimination of bias.
- Recently, the idea is that bias may yield important information about cross-cultural differences and can also be seen as a phenomenon that requires explanation.
The most salient techniques for addressing each bias:

Construct bias:
- Cultural decentering eliminates concepts that are specific to 1 language or culture.
Construct and/or method bias:
- Definition of first one in table 3 is committee approach.
- Limitations of administering the test to bilingual subjects:
- Bilinguals are usually not representative of the larger population
- Carryover effects
- A combination of bilingual and monolingual samples is useful.
- Pilot study with non-standard instrument administration: the subject is encouraged to indicate how he/she interprets the stimuli and to motivate responses.
- Nomological network analysis involves other constructs besides just the target construct 🡪 any cross-cultural differences found can either be caused by the target construct or by other constructs.
- The presence of construct and method bias cannot be only based on differences in the nomological network.
Method bias:
- Use of subject and context variables: it is usually impossible to match cultural groups on all variables that are relevant to the variable under study.
- When a confounding variable has been measured, it becomes possible to statically check its influence.
- Collateral information: provides evidence about the presence or absence of method bias 🡪 the method of data collection can influence the outcome of a study.
- Test-taking attitudes may differ per culture.
- Manipulate or measure response styles:
- The number of alternatives in a Likert scale can influence the measurement outcome.
- Social desirability varies systematically with sample characteristics.
Item bias:
- Error or distractor analysis is promising for cross-cultural group comparisons of mental tests with multiple-choice items 🡪 identifies typical types of errors and, with carefully planned distracters, gives insight into the cognitive processes involved in the solution process.
- However, error analyses are hardly used in cross-cultural research.
Raven’s Progressive Matrices/Raven’s Matrices/RPM = a non-verbal test typically used to measure general human intelligence and abstract reasoning and is regarded as a non-verbal estimate of fluid intelligence = the ability to solve novel reasoning problems and is correlated with several important skills such as comprehension, problem solving, and learning.
- Administered to both groups and individuals ranging from 5-year-olds to the elderly.
- It comprises 60 multiple choice questions, listed in order of increasing difficulty.
- This format is designed to measure the test taker’s reasoning ability 🡪 the eductive (“meaning-making”) component of Spearman’s g (= general intelligence).
- In each test item, the subject is asked to identify the missing element that completes a pattern.
- Many patterns are presented in the form of a 6x6, 4x4, 3x3, or 2x2 matrix, giving the test its name.
All the questions on the Raven’s progressives consist of visual geometric design with a missing piece 🡪 the test taker is given 6 to 8 choices to pick from and fill in the missing piece.
An IQ test item in the style of a Raven’s Progressive Matrices test. Given 8 patterns, the subject must identify the missing 9th pattern.
Raven's Progressive Matrices and Vocabulary tests were originally developed for use in research into the genetic and environmental origins of cognitive ability.
- Raven thought that the tests commonly in use at that time were cumbersome to administer and the results difficult to interpret.
- Accordingly, he set about developing simple measures of the 2 main components of Spearman’s g:
- The ability to think clearly and make sense of complexity 🡪 eductive ability
- The ability to store and reproduce information 🡪 reproductive ability
- Raven's tests of both were developed with the aid of what later became known as item response theory.
The Matrices are available in 3 different forms for participants of different ability:
- Standard Progressive Matrices (RSPM)
- These were the original form of the matrices.
- The booklet comprises 5 sets (A to E) of 12 items each (e.g., A1 to A12) 🡪 with items within a set becoming increasingly complex, requiring ever greater cognitive capacity to encode and analyse information.
- All items are presented in black ink on a white background.
- Coloured Progressive Matrices (RCPM)
- Designed for children aged 5 to 11, the elderly, and mentally and physically impaired individuals.
- This test contains sets A and B from the standard matrices, with a further set of 12 items inserted between the 2, as set Ab.
- Most items are presented on a coloured background to make the test visually stimulating for participants.
- However, the last few items in set B are presented as black-on-white 🡪 if a subject exceeds the tester's expectations, transition to sets C, D, and E of the standard matrices is eased.
- Advanced Progressive Matrices (RAPM)
- The advanced form of the matrices contains 48 items, presented as one set of 12 (set I) and another of 36 (set II).
- Items are again presented in black ink on a white background and become increasingly complex as progress is made through each set.
- These items are appropriate for adults and adolescents of above-average intelligence.
In addition, "parallel" forms of the standard and coloured progressive matrices were published 🡪 to address the problem of the Raven's Matrices being too well known in the general population.
- Items in the parallel tests have been constructed so that average solution rates to each question are identical for the classic and parallel versions.
A revised version of the RSPM – the Standard Progressive Matrices Plus 🡪 based on the "parallel" version but, although the test was the same length, it had more difficult items in order to restore the test's ability to differentiate among more able adolescents and young adults than the original RSPM had when it was first published.
The tests were initially developed for research purposes.
Because of their independence of language and reading and writing skills, and the simplicity of their use and interpretation, they quickly found widespread practical application.
Flynn-effect = intergenerational increase/gains in IQ-scores around the world.
- Raven preceded Flynn in finding evidence of IQ-score gains, reporting on studies with the RPM.
Individuals with ASS score high on Raven’s tests.
Therapeutic assessment (TA):
- Assessor comes in as an expert
- Assessor administers measures or conducts an interview
- Assessor provides certain information about the client to the client
The client has specific questions 🡪 therapist/assessor tries to answer these questions with test results 🡪 by planning a battery that is in line with the client’s questions.
- They go through the client’s questions and answer these by bringing in the test results 🡪 giving a summary and feedback 🡪 clients gain new insight.
3 factors that make the change:
- Putting together the knowledge that we get from testing
- The awareness that clients get from discussing their test results with the assessor
- The use of therapeutic principles that are empirically supported as effective
Clients who never improved from other treatment(s) do improve from TA.
Power of TA: the basic human need to be seen and understood
A person develops through the process of TA a more coherent, accurate, compassionate, and useful story about themselves.
Therapeutic assessment (TA) = semi-structured approach to assessment that strives to maximize the likelihood of therapeutic change for the client 🡪 an evidence-based approach to positive personal change through psychological assessment.
Development of TA:
- Fisher
- Psychologists can acknowledge that humans are purposeful and that “the professional’s understandings are not more real, valid, or influential within the client’s life than are the client’s” 🡪 instead of treating them as objects able to measure.
- Defines collaborative assessment = assessment “in which the client and professional labour together toward mutually set goals, sharing their respective background information and emerging impression”.
- Finn and colleagues
- Developed the TA approach
- Incorporating evolving insights from other areas of psychology, including the idea that emotional experience rather than logical understanding is at the heart of therapeutic change.
- Moves assessment from an intellectual exercise to an experiential one.
- Adapted the approach developed for adults to the assessment of children 🡪 introduced the idea of writing fables or stories as age-appropriate feedback for children, offering new options and outcomes through stories.
- Other/application adaptions of TA: adolescents, neuropsychological assessment, couples, etc.
Evidence for TA:
- Finn & Tonsager: study of students in 2 groups (assessment versus no assessment)
- Waiting for therapy
- Assessment group: significant drop in symptoms and significant increase in self-esteem
- No assessment group: variables above unchanged
- The 2 groups showed no differences in feelings about the therapist/assessor
- This study provided powerful evidence that assessment can be therapeutic 🡪 fueled the movement
- Newman and Greenwat: similar study with some refinements
- Both groups took the MMPI–2 (= personality test), although the control group received feedback after the outcome measures were completed.
- Their results were like those in the Finn & Tonsager study, but the effect sizes were smaller.
Growing number of research 🡪 TA is an effective therapeutic intervention
- TA was better than traditional assessment in insuring compliance with treatment recommendations.
- TA was more effective on several factors, including facilitating treatment alliance, cooperation with treatment, and satisfaction with treatment and that it also promoted lower distress and an increased sense of well-being.
Ingredients of TA that explain the powerful therapeutic effects:
- Changing a client’s self-narrative
- Effectively changing how people view themselves in the world opens new possibilities in their lives.
- Walking the line between self-verification and disintegration
- Self-verification = the powerful human tendency to seek and attend to information that supports established ways one understands oneself.
- Even when this view is negative and self-limiting.
- If these established patterns of understanding oneself in the world are changed too abruptly 🡪 feelings of disintegration = an experience of emotional distress, disorientation, and fear that can result when an individual is unable to refute evidence that some central and tightly held belief about the self is wrong.
- Balance is central in promoting change 🡪 TA techniques enable the assessor to facilitate change without overwhelming the client.
- Self-verification = the powerful human tendency to seek and attend to information that supports established ways one understands oneself.
- Using psychological tests as “empathy magnifiers”
- The client is changed by the experience of being deeply seen and understood.
- Psychological tests are excellent “empathy magnifiers” and, thus, perfectly suited to maximize the empathy experience.
- Involving the entire system with children and families
- TA is a family-systems intervention = caretakers observe or participate in each step in the assessment process and are included in discussions during or after each assessment session.
- The parents are led by the data and their interactions to see their child more accurately and understand what the child needs.
- Assessor also helps parents deal with their own pain and limitations.
- Thus, TA addresses the child’s most important interpersonal environment to create opportunity for growth and therapeutic change.
- TA is a family-systems intervention = caretakers observe or participate in each step in the assessment process and are included in discussions during or after each assessment session.
- Undoing projective identification with couples
- Exposing and diminishing the relationship patterns rooted in childhood that guide expectations, reactions, and behaviour with one’s spouse or partner 🡪 often deeply entrenched and completely ego-syntonic
- TA in couples:
- First assessing the partners independently to gain an understanding of each person’s underlying dynamics that influence the couple’s relationship.
- Second, move the couple to relate more from accurate, present-day reality than from projection of past relationship patterns.
Steps in the TA process by Finn (and Tonsager):
- Initial contact
- Initial contact with the referring professional and later with the client.
- Question and information are sought from the referring professional, and he or she is encouraged to share the questions with the client.
- Initial phone contact conveys a wealth of information about the client 🡪 how they present themselves, what concerns they might have, their tone of voice, and how open they are to the assessment.
- Collaborative assessor–client relationship is begun in the initial phone contact by asking clients to think of questions they would like the assessment to answer.
- The assessor also answers practical questions and schedules the first meeting.
- Initial contact with the referring professional and later with the client.
- Initial session
- Very important as it sets the frame in which the assessment will occur.
- Assessor tries to convey authentic warmth, respect, compassion, and curiosity, and to engage the client as a collaborator.
- Assessor can encourage them to talk about the problems they are having in life and then listen carefully for potential questions to bring to the client’s attention.
- The assessor gathers relevant background for each central question.
- It is also helpful to inquire about past assessments and any hurts they might have caused.
- Assessor also asks clients if they have questions about the assessor 🡪 relationship is open both ways.
- The assessor and client review the client’s questions and the plan of work and agree on fees and the schedule for future sessions.
- Standardized testing sessions
- Test are administered in standardized ways to gather information that will inform the answers to the questions.
- To begin, the assessor often chooses tests that are more clearly related to the client’s questions.
- Technique that is increasingly valued in TA: extended inquiry = assessor asking about the client’s experience of a test or the client’s thoughts about certain test responses.
- Assessment intervention session
- Most innovative step in TA: assessor uses the information gathered up to that point to elicit an analogue of the client’s main difficulties in vivo.
- If successful, the assessor invites the client to observe the problem behaviour, understand it, and then solve it in the assessment session.
- They relate their discussions to the client’s daily life.
- Summary/discussion session
- Provides the opportunity for the client and assessor to collaboratively discuss the findings of the assessment.
- The assessor first contacts the referring professional to discuss the findings and plan the summary/discussion session together 🡪 when possible, the referring therapist attends the session.
- The assessor takes each of the client’s questions and proposes tentative answers based on the testing and previous discussions with the client 🡪 after each point, the assessor asks how the client understands the finding.
- The session ends with the client and therapist discussing viable next steps that the client can take to address the problems focused on in the assessment and talking about what it was like to do the assessment together.
- Written feedback
- The assessor writes a letter to the client that outlines the findings from the assessment that were discussed in the last session.
- Typically, in the form of a personal letter, which restates each question and summarizes the answer.
- This letter is an enduring documentation of the assessment findings and of the client’s connection with the assessor.
- Follow-up session
- Typically, scheduled 3 to 6 months after the summary/discussion session.
- Offers the opportunity for assessor and client to check in with each other and clarify or deepen what the assessment results indicate and how they might bear on recent questions and concerns.
- Serves as a mechanism to keep the client on track with the important results of the assessment.
Traditionally: assessment has focused on gathering accurate data to use in clarifying diagnoses and developing treatment plans.
New approaches: also emphasize the therapeutic effect assessment can have on clients and important others in their lives.
Steps that are not conducted in the traditional psychological assessment: first step, fourth step, seventh step.
Therapeutic assessment (TA) = a collaborative semi-structured approach to individualized clinical (personality) assessment.
- Humanistic approach to clients
- Related to collaborative assessment
- TA-procedures are extensively documented
- Well for transfer and empirical testing
- Pre-treatment TA has the potential to improve outcomes with specific
psychiatric populations
The therapist and assessor were/are not the same person 🡪 indicating that the techniques practiced by TA providers to foster a therapeutic alliance model transfer to subsequent providers and might aid in treatment readiness and success.
TA can be effective in reducing distress, increasing self-esteem, fostering the therapeutic alliance, and, to a lesser extent, improving indicators of treatment readiness.
On the other hand, symptomatic and functional improvement has yet to be definitively demonstrated with adults.
In children, emerging evidence suggests that TA was associated with symptomatic improvement, but these studies suffer from small samples and nonrandomized designs.
TA has not yet been empirically tested in patients formally diagnosed with personality disorders (PDs) 🡪 present study is a conduction of a pre-treatment RCT among patients with severe personality pathology awaiting an already assigned course of treatment.
- Useful because: patients with PDs have pronounced needs for sustained empathy, require special attention in terms of building and maintaining alliance, and tend to be ambivalent about change.
- Emphasis on emotional containment, empathic connection and close collaboration, and recognition of dilemmas of change are all key aspects of TA.
- Emphasis on emotional containment, empathic connection and close collaboration, and recognition of dilemmas of change are all key aspects of TA.
- Evidence of treatment utility was expected on outcomes indicating general treatment readiness, motivation, and psychotherapy process variables, rather than on short-term symptomatic relief.
2 conditions in the study:
- Therapeutic assessment (TA)
- Distinguishing feature of TA: primary assessment goals are formulated in collaboration with the client as questions to be answered by the assessment.
- Test selection is guided by the client’s and referring clinician’s questions.
- Subsequent administration and scoring are conducted according to standardized techniques.
- Individualized feedback is another key element and is characterized by its question-driven, patient-centred, and collaborative nature 🡪 normative data are transformed into the idiographic context of the client’s everyday life.
- 4 face-to-face sessions in the present study:
- 1: collecting questions and taking the MMPI-2 (= personality test)
- 2: taking performance-based tests
- 3: assessment intervention session
- Designed to elicit and subsequently experiment with key, but inadequately understood, personal dynamics 🡪 use of non-standardized techniques.
- 4: discussion of the assessment feedback
- Goal-focused pre-treatment intervention (GFPTI)
- Protocol-guided comparison condition
- Based on the five sessions model = standard for good quality first-line care in Dutch mental health care
- Had a specific session-by-session agenda that emphasized goal setting and motivation for the subsequent treatment.
- Also 4 face-to-face sessions + clients received a workbook that included homework assignments and a written explanation of the goal of each session.
- 1: focus on attacking demoralization and promoting hope by providing psychoeducation on dynamics of maladaptive behaviours and their potential for change.
- 2: aimed at the main problem on which treatment will focus
- 3: involved examining the dilemma of change
- 4: focuses on achieving a shared re-appraisal of problems and included goal setting for remaining period prior to treatment.
- Throughout the intervention, clients were actively encouraged to think about the most central problem they need to address in pre-treatment.
- They were asked to reflect on the question: “If your treatment were successful, what problems would it help to solve?”
Conclusions:
- Patients in the TA condition compared to the GFPTI condition:
- Higher outcome expectations for their subsequent treatment
- Felt more on track in terms of their focus for treatment
- Indicated a moderately stronger alliance to the therapist than those who received GFPTI
- Higher satisfaction with the intervention received (the quality of it)
- TA exerted medium to large effects in these measures 🡪 even when compared with a highly credible control condition – GFPTI
- Across interventions, however, no statistically significant differences in
symptoms and demoralization improvements were observed.
Treatment utility is often defined as improving treatment outcome, typically in terms of short-term symptomatic improvement.
- By this measure, TA did not outperform the 4 sessions of a motivational pre-treatment.
From the more inclusive view of treatment utility however, TA demonstrated stronger ability to prepare, motivate, and inspire the patient for the tasks of therapy, and to provide focus and goals for therapy.
- Such effects seem to be of major value from a patient’s perspective, particularly in the context of patients with treatment-resistant personality pathology.
The Netherlands Institute of Psychologists (NIP) is a national professional association promoting the interests of all psychologists. It has its own Code of Ethics = describes the ethical principles and rules that psychologists must observe in practicing their profession.
The objective of the NIP is to ensure psychologists work in accordance with high professional standards, and it guides and support psychologists’ decisions in difficult and challenging situations that they may face.
The Code of Ethics is based on 4 basic principles: responsibility, integrity, respect, and expertise. These basic principles have been elaborated into more specific guidelines.
- These guidelines serve as a tool for a psychologist’s ethical decision-making in a specific situation 🡪 this Code offers them a guideline in practising their profession and is an important quality instrument of the NIP.
- Some guidelines are related to several principles.
Psychologists registered with NIP or members need to follow the principles/are obliged to.
It is a good tradition of the NIP to regularly examine the Code of Ethics 🡪 professional ethics are dynamic, so the information is updated regularly.
A Code of Ethics serves several purposes:
- For psychologists: an important tool in making ethical decisions in their work 🡪 reinforces and increases professionalism.
- For the public who make use of a psychologist’s services: clarify what they may expect of a psychologist.
- Serves as an assessment standard when psychologists must account for their activities in a complaints procedure.
Basic principles:
- Responsibility = psychologists must recognise their professional and scientific responsibility in relation to the persons involved, their environment and society. Psychologists are responsible for their professional conduct. As far as they are able, they must ensure that their services and the results of their activities are not abused.
- The quality of the professional activities
- Continuity of professional activities
- Preventing and limiting harm
- Preventing abuse
- Psychologists and their working environment
- Accountability
- Integrity = psychologists must aim for integrity in the practice of their science, education, and the application of psychology. In practising their profession, psychologists must demonstrate honesty, equal treatment and openness towards the persons involved. They must provide clarity for all the persons involved regarding the roles that they play and must act accordingly.
- Reliability
- Honesty
- Role integrity
- Respect = psychologists must respect the fundamental rights and dignity of the persons involved. They must respect the right to privacy and confidentiality of the persons involved. They must respect and promote their self-determination and autonomy, insofar as that is in keeping with the psychologists’ other professional duties and with the law.
- General
- Autonomy and self-determination
- Confidentiality
- Provision of data
- Reports
- Expertise = psychologists must aim to acquire and maintain a high level of expertise in the practice of their profession. They must consider the limits of their expertise as well as the limitations of their experience. They may only provide services for which they are qualified by their education, training, and experience. The same applies to the methods and techniques that they use.
- Ethical awareness
- Professional competence
- The limits of professional activities
The Dutch Association of Psychologists (NIP) has made a Code of Ethics for Psychologists and the new Guidelines for the Use of Tests 2017.
- The Guidelines for the Use of Tests 2017 is an elaboration and specification of the Code of Ethics and contains guidelines and information for making a responsible choice of instruments and the proper use of psychodiagnostic instruments in the context of psychodiagnostics and/or psychological interventions.
- It contains extensive explanations on topics such as:
- The principles when choosing a test
- The benefits and limitations of using tests in the psychodiagnostic process
- The use of tests with special groups
- The test-taking requirements
- The assessment procedure
- The reporting of test results
- The rights of the client during test use.
- Attention is also paid to the test reviews carried out by the Dutch Committee on Tests and Testing (COTAN) and how these reviews can be used by the psychologist as an aid in making a responsible choice for an instrument.
- It contains extensive explanations on topics such as:
Psychodiagnostic instruments = instruments for determining someone’s characteristics with a view to making determinations about that person, in the context of advice to that person themselves, or to others about them, in the framework of treatment, development, placement, or selection.
2 problems may come up when psychodiagnostic instruments are used:
- The instruments may not satisfy the necessary criteria, including scientific criteria
- Psychodiagnostic instruments are used inappropriately
2.2.1 – invitation to the client
2.2.3 – raw data 🡪 the client has the right to access the entire file
2.2.8 – use of psychodiagnostic instruments
- Test-taking procedure: responsibility
- Test-taking procedure: monitoring
- Test-taking procedure: testing space
- Test-taking procedure: quality of the test material
2.3.1 – parts of the psychological test report
- Date of the assessment, and the client’s name, sex, and date of birth
- The origin and description of the question (the assignment)
- Progress of the research
- Psychodiagnostic instruments used
- Intake and anamnestic data
- Results of the assessment, including observations and the degree of uncertainty surrounding the results
- Summary
- Conclusion, and findings and recommendations
- The period of validity for the various components of the report, including the test results
- The name of the psychologist under whose responsibility the psychodiagnostic assessment took place 🡪 itis advisable to have the report signed by the person responsible for it
- The length of the period for which the test data and the psychological report can be kept on file
2.3.4 – rights of the client
- Get a debriefing on the assessment
- Inspect the report prior to its release
- Block the report, if applicable
- Make improvements or additions to data, or to delete data
- Get a copy of the report after its release
- Get guided access to the raw test data