Viruses
Overview of Viruses
A virus consists only of nucleic acid, proteins, and sometimes a membranous envelope. After infecting a host cell, it uses the host cell's molecules to make new viruses.
A virus consists of a nucleic acid surrounded by a protein coat.
Compared with eukaryotic and even prokaryotic cells, most viruses are much smaller and simpler in structure. Lacking the structures and metabolic machinery found in a cell, a virus is an infectious particle consisting of little more than genes packaged in a protein coat.
Are Viruses Living or Nonliving?
Early on, they were considered biological chemicals; the Latin root for virus means “poison.”
Viruses can cause a wide variety of diseases, so researchers in the late 1800s saw a parallel with bacteria and proposed that viruses were the simplest of living forms. However, viruses cannot reproduce or carry out metabolic activities outside of a host cell.
Most biologists would probably agree that viruses are not alive but instead exist in a shady area between life-forms and chemicals. The simple phrase used by two researchers describes them aptly: Viruses lead “a kind of borrowed life.”
The Discovery of Viruses: Scientific Inquiry
Scientists detected viruses indirectly long before they were able to see them. The story of how viruses were discovered begins in 1883. A German scientist named Adolf Mayer was studying tobacco mosaic disease, which stunts the growth of tobacco plants and gives their leaves a mottled, or mosaic, coloration.
Mayer discovered that he could transmit the disease from plant to plant by rubbing sap extracted from diseased leaves onto healthy plants.
After an unsuccessful search for an infectious microorganism in the sap, he suggested that the disease was caused by unusually small bacteria that were invisible under a microscope.
This hypothesis was tested a decade later by Dmitri Ivanowsky, a Russian biologist who passed sap from infected tobacco leaves through a filter designed to remove bacteria. After filtration, the sap still produced mosaic disease.
But Ivanowsky reasoned that perhaps the bacteria were small enough to pass through the filter or made a toxin that could do so.
The second possibility was ruled out when the Dutch botanist Martinus Beijerinck carried out a classic series of experiments that showed that the infectious agent in the filtered sap could replicate.

In fact, the pathogen replicated only within the host it infected. In further experiments, Beijerinck showed that unlike bacteria used in the lab at that time, the mysterious agent of mosaic disease could not be cultivated on nutrient media in test tubes or petri dishes.
Beijerinck imagined a replicating particle much smaller and simpler than a bacterium, and he is generally credited with being the first scientist to voice the concept of a virus.
His suspicions were confirmed in 1935 when the American scientist Wendell Stanley crystallized the infectious particle, now known as tobacco mosaic virus (TMV). Subsequently, TMV and many other viruses were actually seen with the help of the electron microscope.
CONCEPT 19.1 Structure of Viruses
The tiniest viruses are only 20 nm in diameter—smaller than a ribosome. Millions could easily fit on a pinhead.
Even the largest known virus, which has a diameter of 1,500 nanometers (1.5 μm), is barely visible under the light microscope.
Stanley’s discovery that some viruses could be crystallized was exciting and puzzling news. Not even the simplest of cells can aggregate into regular crystals. But if viruses are not cells, then what are they?
Examining the structure of a virus more closely reveals that it is an infectious particle consisting of one or more molecules of a nucleic acid enclosed in a protein coat and, for some viruses, surrounded by a membranous envelope.
The simple structure of viruses makes them a useful biological system: To a large extent, molecular biology was born in the laboratories of biologists studying viruses that infect bacteria.
Experiments using these viruses provided evidence that genes are made of nucleic acids, and they were critical in working out the molecular mechanisms of the fundamental processes of DNA replication, transcription, and translation.
Viral Genomes
We usually think of genes as being made of double-stranded DNA, but many viruses defy this convention. Their genomes may consist of double-stranded DNA, single-stranded DNA, double-stranded RNA, or single-stranded RNA, depending on the type of virus.
A virus is called a DNA virus or an RNA virus based on the kind of nucleic acid that makes up its genome.
In either case, the genome is usually organized as a single linear or circular molecule of nucleic acid, although the genomes of some viruses consist of multiple molecules of nucleic acid.
The smallest viruses known have only three genes in their genome, while the largest have several hundred to 2,000. For comparison, bacterial genomes contain about 200 to a few thousand genes.
Capsids and Envelopes
The protein shell enclosing the viral genome is called a capsid. Depending on the type of virus, the capsid may be rod-shaped, polyhedral, or more complex in shape.
Capsids are built from a large number of protein subunits called capsomeres, but the number of different kinds of proteins in a capsid is usually small.
Tobacco mosaic virus has a rigid, rod-shaped capsid made from over 1,000 molecules of a single type of protein arranged in a helix; rod-shaped viruses are commonly called helical viruses for this reason.
Adenoviruses, which infect the respiratory tracts of animals, have 252 identical protein molecules arranged in a polyhedral capsid with 20 triangular facets—an icosahedron; thus, these and other similarly shaped viruses are referred to as icosahedral viruses.
Some viruses have accessory structures that help them infect their hosts. For instance, a membranous envelope surrounds the capsids of influenza viruses and many other viruses found in animals.
These viral envelopes, which are derived from the membranes of the host cell, contain host cell phospholipids and membrane proteins. They also contain proteins and glycoproteins of viral origin. (Glycoproteins are proteins with carbohydrates covalently attached.) Some viruses carry a few viral enzymes, such as viral polymerase, within their capsids.
Many of the most complex capsids are found among the viruses that infect bacteria, called bacteriophages, or simply phages.
The first phages studied included seven that infect Escherichia coli (E. coli). These seven phages were named type 1 (T1), type 2 (T2), and so forth, in the order of their discovery. (The T2 phage was used in the experiment that established DNA as the genetic material;)
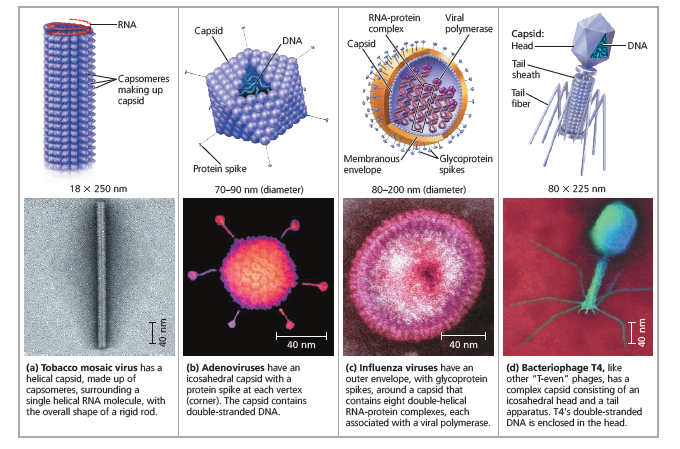
The three “T-even” phages (T2, T4, and T6) turned out to be very similar in structure. Their capsids have elongated icosahedral heads enclosing their DNA. Attached to the head is a protein tail piece with fibers by which the phages attach to a bacterial cell. In the next section, we’ll examine how these few viral parts function together with cellular components to produce large numbers of viral progeny.
Viruses Replicate Only in Host Cells
Viruses lack metabolic enzymes and equipment for making proteins, such as ribosomes. They are obligate intracellular parasites; in other words, they can replicate only within a host cell.
It is fair to say that viruses in isolation are merely packaged sets of genes in transit from one host cell to another.
Each particular virus can infect cells of only a limited number of host species, called the host range of the virus.
This host specificity results from the evolution of recognition systems by the virus.
Viruses usually identify host cells by a “handshake” fit between viral surface proteins and specific receptor molecules on the outside of cells.
Such receptor molecules are most often proteins that carry out necessary functions for the host cell and have been adopted by viruses as portals of entry.
Some viruses have broad host ranges. For example, West Nile virus and equine encephalitis virus are distinctly different viruses that can each infect mosquitoes, birds, horses, and humans.
Other viruses have host ranges so narrow that they infect only a single species. Measles virus, for instance, can infect only humans.
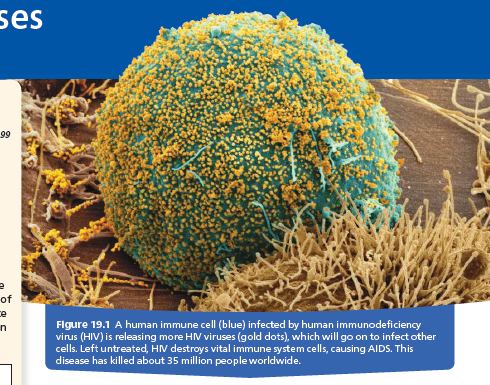
Furthermore, viral infection of multicellular eukaryotes is usually limited to particular tissues. Human cold viruses infect only the cells lining the upper respiratory tract, and the HIV seen in Figure 19.1 binds to receptors present only on certain types of immune cells.
General Features of Viral Replicative Cycles
A viral infection begins when a virus binds to a host cell and the viral genome makes its way inside.
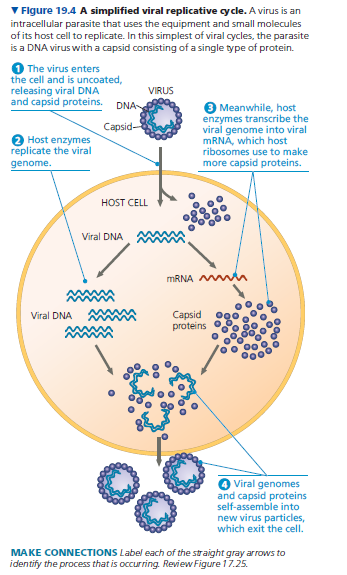
The mechanism of genome entry depends on the type of virus and the type of host cell. For example, T-even phages use their elaborate tail apparatus to inject DNA into a bacterium.
Other viruses are taken up by endocytosis or, in the case of enveloped viruses, by fusion of the viral envelope with the host’s plasma membrane.
Once the viral genome is inside, the proteins it encodes can commandeer the host, reprogramming the cell to copy the viral genome and manufacture viral proteins.
The host provides the nucleotides for making viral nucleic acids, as well as enzymes, ribosomes, tRNAs, amino acids, ATP, and other components needed for making the viral proteins.
Many DNA viruses use the DNA polymerases of the host cell to synthesize new genomes along the templates provided by the viral DNA.
In contrast, to replicate their genomes, RNA viruses use virally encoded RNA polymerases that can use RNA as a template. (Uninfected cells generally make no enzymes for carrying out this process.)
After the viral nucleic acid molecules and capsomeres are produced, they spontaneously self-assemble into new viruses.
In fact, researchers can separate the RNA and capsomeres of TMV and then reassemble complete viruses simply by mixing the components together under the right conditions.
The simplest type of viral replicative cycle ends with the exit of hundreds or thousands of viruses from the infected host cell, a process that often damages or destroys the cell. Such cellular damage and death, as well as the body’s responses to this destruction, cause many of the symptoms associated with viral infections.
The viral progeny that exit a cell have the potential to infect additional cells, spreading the viral infection.
There are many variations on the simplified viral replicative cycle we have just described. We will now take a look at some of these variations in bacterial viruses (phages) and animal viruses; later in the chapter, we will consider plant viruses.
Replicative Cycles of Phages
Phages are the best understood of all viruses, although some of them are also among the most complex.
Research on phages led to the discovery that some double-stranded DNA viruses can replicate by two alternative mechanisms: the lytic cycle and the lysogenic cycle.
The Lytic Cycle
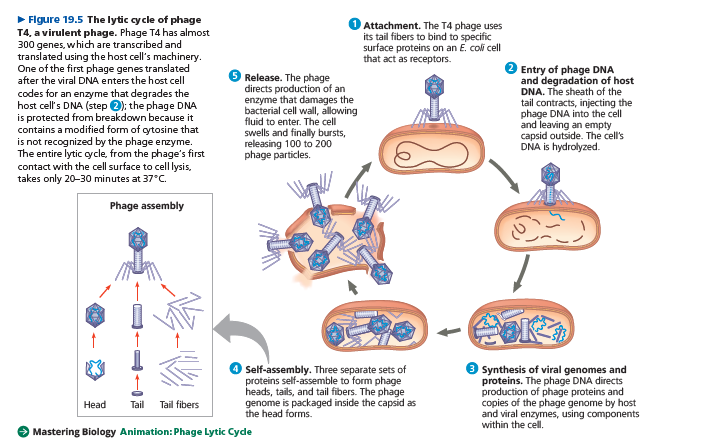
A phage replicative cycle that culminates in death of the host cell is known as a lytic cycle.
The term lytic refers to the last stage of infection, during which the bacterium lyses (breaks open) and releases the phages that were produced within the cell.
Each of these phages can then infect a healthy cell, and a few successive lytic cycles can destroy an entire bacterial population in just a few hours.
A phage that replicates only by a lytic cycle is a virulent phage.
The Lysogenic Cycle
Instead of lysing their host cells, many phages coexist with them in a state called lysogeny.
In contrast to the lytic cycle, which kills the host cell, the lysogenic cycle allows replication of the phage genome without destroying the host.
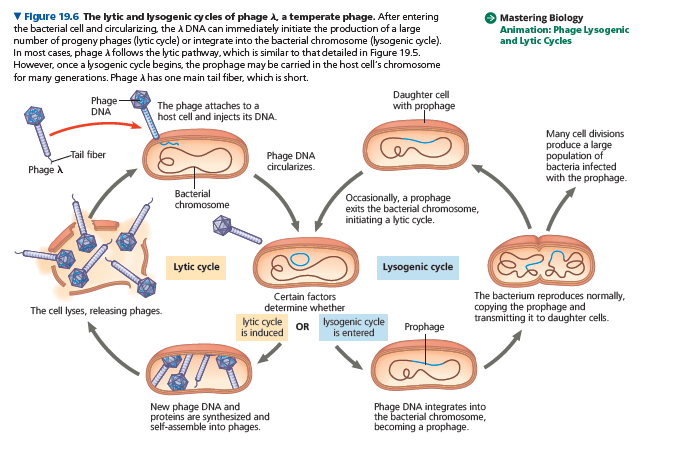
Phages capable of using both modes of replicating within a bacterium are called temperate phages. A temperate phage called lambda, written with the Greek letter l, has been widely used in biological research.
Phage λ resembles T4, but its tail has only one short tail fiber.
Infection of an E. coli cell by phage λ begins when the phage binds to the surface of the cell and injects its linear DNA genome .
Within the host, the λ DNA molecule forms a circle. What happens next depends on the replicative mode: lytic cycle or lysogenic cycle.
During a lytic cycle, the viral genes immediately turn the host cell into a l-producing factory, and the cell soon lyses and releases its virus progeny.
During a lysogenic cycle, however, the λ DNA molecule is incorporated into a specific site on the E. coli chromosome by viral proteins that break both circular DNA molecules and join them to each other.
When integrated into the bacterial chromosome in this way, the viral DNA is known as a prophage.
One prophage gene codes for a protein that prevents transcription of most of the other prophage genes. Thus, the phage genome is mostly silent within the bacterium.
Every time the E. coli cell prepares to divide, it replicates the phage DNA along with its own chromosome such that each daughter cell inherits a prophage. A single infected cell can quickly give rise to a large population of bacteria carrying the virus in prophage form.
This mechanism enables viruses to propagate without killing the host cells on which they depend.
The term lysogenic signifies that prophages are capable of generating active phages that lyse their host cells.
This occurs when the λ genome (or that of another temperate phage) is induced to exit the bacterial chromosome and initiate a lytic cycle.
An environmental signal, such as a certain chemical or high-energy radiation, usually triggers the switchover from the lysogenic to the lytic mode.
In addition to the gene for the viral protein that prevents transcription, a few other prophage genes may be expressed during lysogeny.
Expression of these genes may alter the host’s phenotype, a phenomenon that can have important medical significance.
For example, the three species of bacteria that cause the human diseases diphtheria, botulism, and scarlet fever would not be so harmful to humans without certain prophage genes that cause the host bacteria to make toxins.
And the difference between the E. coli strain in our intestines and the O157:H7 strain that has caused several deaths by food poisoning appears to be the presence of toxin genes of prophages in the O157:H7 strain.
Bacterial Defenses Against Phages
After reading about the lytic cycle, you may have wondered why phages haven’t exterminated all bacteria.
Lysogeny is one major reason why bacteria have been spared from extinction caused by phages.
Bacteria also have their own defenses against phages.
First, natural selection favors bacterial mutants with surface proteins that are no longer recognized as receptors by a particular type of phage.
Second, when phage DNA does enter a bacterium, the DNA often is identified as foreign and cut up by cellular enzymes called restriction enzymes, which are so named because they restrict a phage’s ability to replicate within the bacterium. (Restriction enzymes are used in molecular biology and DNA cloning techniques; see Concept 20.1.)
The bacterium’s own DNA is methylated in a way that prevents attack by its own restriction enzymes.
A third defense is a system present in both bacteria and archaea called the CRISPR-Cas system, which you learned about in Concept 17.5.
The CRISPR-Cas system was discovered during a study of repetitive DNA sequences present in the genomes of many prokaryotes.
These sequences, which puzzled scientists, were named clustered regularly interspaced short palindromic repeats (CRISPRs) because each sequence reads the same forward and backward (a palindrome), with different stretches of “spacer DNA” in between the repeats.
At first, scientists assumed the spacer DNA sequences were random and meaningless, but analysis by several research groups showed that each spacer sequence corresponded to DNA from a particular phage that had infected the cell.
Further studies revealed that particular nuclease proteins interact with the CRISPR region. These nucleases, called Cas (CRISPR-associated) proteins, can identify and cut phage DNA, thereby defending the bacterium against phage infection.
When a phage infects a bacterial cell that has the CRISPR-Cas system, the DNA of the invading phage is stored, integrated into the genome between two repeat sequences.
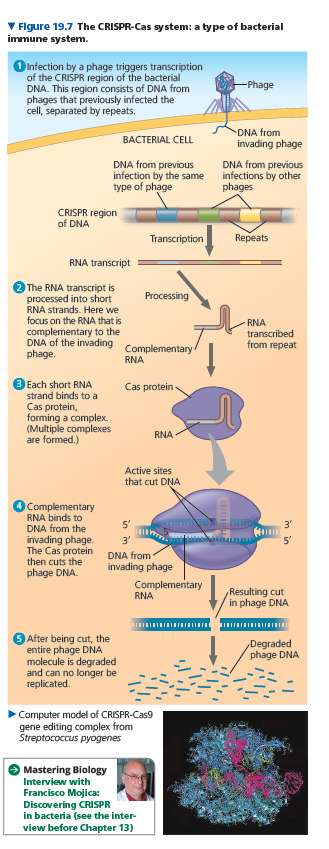
If the cell survives the infection, any further attempt by the same type of phage to infect this cell (or its offspring) triggers transcription of the CRISPR region into RNA molecules.
These RNAs are cut into pieces and then bound by Cas proteins, such as the Cas9 protein.
The Cas protein uses a portion of the phage-related RNA as a homing device to identify the invading phage DNA and cut it, leading to its destruction.
Just as natural selection favors bacteria that have receptors altered by mutation or that have enzymes that cut phage DNA, it also favors phage mutants that can bind to altered receptors or that are resistant to enzymes.
Thus, the bacterium-phage relationship is in constant evolutionary flux.
Replicative Cycles of Animal Viruses
Everyone has suffered from viral infections, whether cold sores, influenza, or the common cold.
Like all viruses, those that cause illness in humans and other animals can replicate only inside host cells.
Many variations on the basic scheme of viral infection and replication are represented among the animal viruses.
Key variables are the nature of the viral genome (double- or single-stranded DNA or RNA) and the presence or absence of an envelope.
Whereas there are only a few bacteriophages that have an envelope or RNA genome, many animal viruses have both.
In fact, nearly all animal viruses with RNA genomes have an envelope, as do some with DNA genomes.
Rather than consider all the mechanisms of viral infection and replication, we will focus first on the roles of viral envelopes and then on the functioning of RNA as the genetic material of many animal viruses.
Viral Envelopes
An animal virus equipped with an envelope—that is, a membranous outer layer—uses it to enter the host cell.
Protruding from the outer surface of this envelope are viral glycoproteins that bind to specific receptor molecules on the surface of a host cell.
Figure 19.8 outlines the events in the replicative cycle of an enveloped virus with an RNA genome.
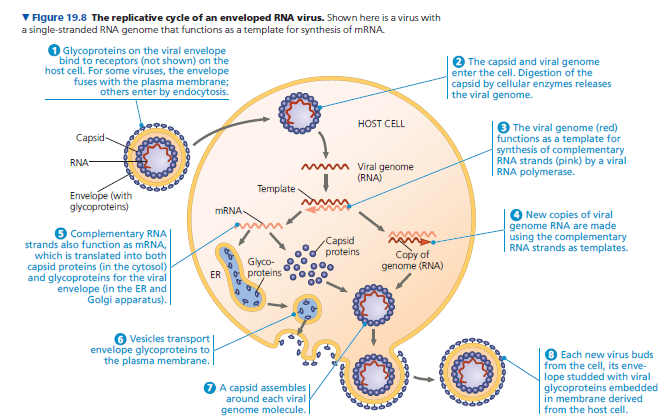
Ribosomes bound to the endoplasmic reticulum (ER) of the host cell make the protein parts of the envelope glycoproteins; cellular enzymes in the ER and Golgi apparatus then add the sugars.
The resulting viral glycoproteins, embedded in membrane derived from the host cell, are transported to the cell surface.
In a process much like exocytosis, new viral capsids are wrapped in membrane as they bud from the cell.
In other words, the viral envelope is usually derived from the host cell’s plasma membrane, although all or most of the molecules of this membrane are specified by viral genes.
The enveloped viruses are now free to infect other cells.
This replicative cycle does not necessarily kill the host cell, in contrast to the lytic cycles of phages.
Some viruses have envelopes that are not derived from plasma membrane. Herpesviruses, for example, are temporarily cloaked in membrane derived from the nuclear envelope of the host; they then shed this membrane in the cytoplasm and acquire a new envelope made from the membrane of the Golgi apparatus.
These viruses have a double-stranded DNA genome and replicate within the host cell nucleus, using a combination of viral and cellular enzymes to replicate and transcribe their DNA.
In the case of herpesviruses, copies of the viral DNA can remain behind as mini-chromosomes in the nuclei of certain nerve cells. There they remain latent until some sort of physical or emotional stress triggers a new round of active virus production.
The infection of other cells by these new viruses causes the blisters characteristic of herpes, such as cold sores or genital sores. Once someone acquires a herpesvirus infection, flare-ups may recur throughout the person’s life.
Classes of Animal Viruses
Animal viruses (classes IV–VI in Table 19.1).
The genome of class IV viruses can directly serve as mRNA and thus can be translated into viral protein immediately after infection.
Figure 19.8 shows a virus of class V, in which the RNA genome serves instead as a template for mRNA synthesis.
The RNA genome is transcribed into complementary RNA strands, which function both as mRNA and as templates for the synthesis of additional copies of genomic RNA.
All viruses that use an RNA genome as a template for mRNA transcription require RNA S RNA synthesis.
These viruses use a viral enzyme capable of carrying out this process; there are no such enzymes in most cells.
The enzyme used in this process is encoded by the viral genome.
After the protein is synthesized, it is packaged during viral self-assembly with the genome inside the viral capsid.

Retroviruses
The RNA animal viruses with the most complicated replicative cycles are the retroviruses (class VI).
These viruses have an enzyme called reverse transcriptase that transcribes an RNA template into a DNA copy, an RNA ➔ DNA information flow that is the opposite of the usual direction.
This unusual phenomenon is the source of the name retroviruses (retro means “backward”).
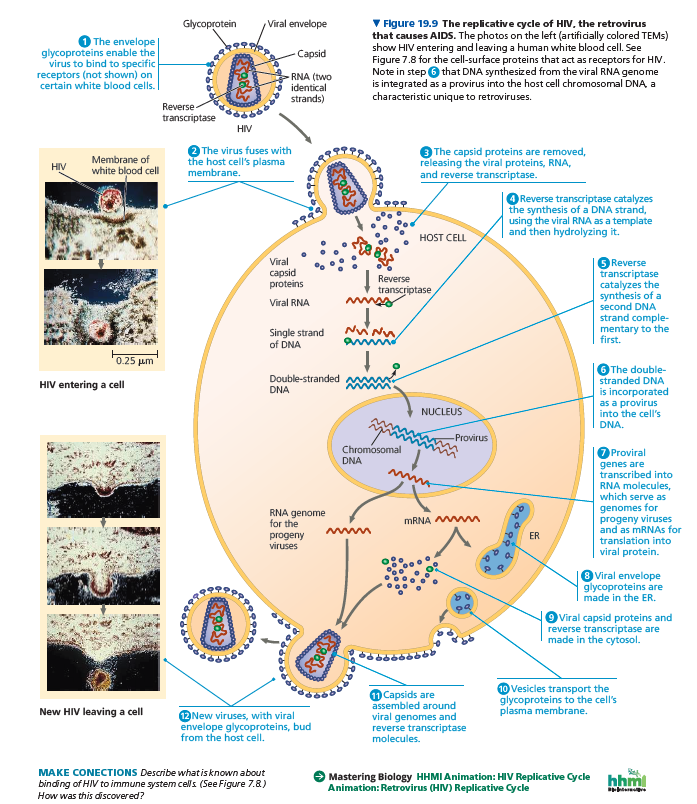
Of particular medical importance is HIV (human immunodeficiency virus), the retrovirus shown in Figure 19.1 that causes AIDS (acquired immunodeficiency syndrome).
HIV and other retroviruses are enveloped viruses that contain two identical molecules of single-stranded RNA and two molecules of reverse transcriptase.
The HIV replicative cycle (illustrated in Figure 19.9) is typical of a retrovirus. After HIV enters a host cell, its reverse transcriptase molecules are released into the cytoplasm, where they catalyze synthesis of viral DNA.
The newly made viral DNA then enters the cell’s nucleus and integrates into the DNA of a chromosome.
The integrated viral DNA, called a provirus, never leaves the host’s genome, remaining a permanent resident of the cell.
(Recall that a prophage, in contrast, leaves the host’s genome at the start of a lytic cycle.)
The RNA polymerase of the host transcribes the proviral DNA into RNA molecules, which can function both as mRNA for the synthesis of viral proteins and as genomes for the new viruses that will be assembled and released from the cell.
In Concept 43.4, we describe how HIV causes the deterioration of the immune system that occurs in AIDS.
Evolution of Viruses
We began this chapter by asking whether or not viruses are alive. Viruses do not really fit our definition of living organisms.
An isolated virus is biologically inert, unable to replicate its genes or regenerate its own ATP. Yet it has a genetic program written in the universal language of life.
Do we think of viruses as nature’s most complex associations of molecules or as the simplest forms of life? Either way, we must bend our definitions.
Although viruses cannot replicate or carry out metabolic activities independently, their use of the genetic code makes it hard to deny their evolutionary connection to the living world.
How did viruses originate?
Viruses have been found that infect every form of life—not only bacteria, animals, and plants, but also archaea, fungi, and algae and other protists.
Researchers estimate that each milliliter (one-fifth of a teaspoon) of seawater contains between one and 100 million viruses, ten times the number of microorganisms!
Because viruses depend on cells for their own propagation, it seems likely that viruses are not the descendants of precellular forms of life but evolved—possibly multiple times—after the first cells appeared.
Most molecular biologists favor the hypothesis that viruses originated from naked bits of cellular nucleic acids that moved from one cell to another, perhaps via injured cell surfaces.
The evolution of genes coding for capsid proteins may have allowed viruses to bind cell membranes, thus facilitating the infection of uninjured cells.
Candidates for the original sources of viral genomes include plasmids and transposons.
Plasmids are small, circular DNA molecules found in bacteria and in the unicellular fungi called yeasts.
Plasmids exist apart from the genome, can replicate independently of the genome, and are occasionally transferred between cells.
Transposons are DNA segments that can move from one location to another within a cell’s genome.
Thus, plasmids, transposons, and viruses all share an important feature: They are mobile genetic elements.
Consistent with this notion of pieces of DNA shuttling from cell to cell is the observation that a viral genome can have more in common with the genome of its host than with the genomes of viruses that infect other hosts.
Indeed, some viral genes are essentially identical to genes of the host.
Debate about the origin of viruses was reinvigorated about 20 years ago when an extremely large virus was discovered: Mimivirus is a double-stranded DNA (dsDNA) virus with an icosahedral capsid that is 400 nm in diameter, the size of a small bacterium.
Its genome contains 1.2 million bases (Mb)—about 100 times as many as the influenza virus genome—and an estimated 1,000 genes.
Perhaps the most surprising aspect of mimivirus, however, was that its genome included genes previously found only in cellular genomes. Some of these genes code for proteins involved in translation, DNA repair, protein folding, and polysaccharide synthesis.
Whether mimivirus evolved before the first cells and then developed an exploitative relationship with them or evolved more recently and simply scavenged genes from its hosts is not yet settled.
In the past decade, several even larger viruses have been discovered that cannot be classified with any existing known virus.
One such virus is 1 μm (1,000 nm) in diameter, with a dsDNA genome of around 2–2.5 Mb, larger than that of some small eukaryotes.
What’s more, over 90% of its 2,000 or so genes are unrelated to cellular genes, inspiring the name it was given, pandoravirus.
The number of genes in pandoraviruses varies from 1,500 to 2,500 genes.
A second virus, called Pithovirus sibericum, with a diameter of 1.5 μm and 500 genes, was discovered in permanently frozen soil in Siberia.
This virus, once thawed, was able to infect an amoeba after being frozen for 30,000 years!
How these and all other viruses fit in the tree of life is an intriguing, unresolved question.
The ongoing evolutionary relationship between viruses and the genomes of their host cells is an association that continues to make viruses very useful experimental systems in molecular biology.
Knowledge about viruses also allows many practical applications since viruses have a tremendous impact on all organisms through their ability to cause disease.
Viral Diseases in Animals
Diseases caused by viral infections afflict humans, agricultural crops, and livestock worldwide.
A viral infection can produce symptoms by a number of different mechanisms.
Viruses may damage or kill cells by causing the release of hydrolytic enzymes from lysosomes.
Some viruses cause infected cells to produce toxins that lead to disease symptoms, and some have molecular components that are toxic, such as envelope proteins.
How much damage a virus causes depends partly on the ability of the infected tissue to regenerate by cell division.
People usually recover completely from colds because the epithelium of the respiratory tract, which the viruses infect, can efficiently repair itself.
In contrast, damage inflicted by poliovirus to mature nerve cells is permanent because these cells do not divide and usually cannot be replaced.
Many of the temporary symptoms associated with viral infections, such as fever and body aches, actually result from the body’s own efforts to defend itself against infection rather than from cell death caused by the virus.
The immune system is a critical part of the body’s natural defenses. It is also the basis for the major medical tool used to prevent viral infections—vaccines.
A vaccine is a harmless derivative of a pathogen that stimulates the immune system to mount defenses against the harmful pathogen.
Smallpox, a viral disease that was once a devastating scourge in many parts of the world, was eradicated by 1980 due to a vaccination program carried out by the World Health Organization (WHO).
The very narrow host range of the smallpox virus—it infects only humans—was a critical factor in the success of this program.
Similar worldwide vaccination campaigns are underway to eradicate polio, the incidence of which has dropped by 99%, and measles.
Although an effective vaccine exists for measles, a large outbreak occurred in the Pacific Northwest in 2019, correlated with lower vaccination rates in that region.
Effective vaccines are also available to protect against rubella, mumps, hepatitis B, and a number of other viral diseases.
Treatments for Viral Infections
Although vaccines can prevent some viral illnesses, medical care can do little, at present, to cure most viral infections once they occur.
The antibiotics that help us recover from bacterial infections are powerless against viruses.
Antibiotics kill bacteria by inhibiting enzymes specific to bacteria but have little or no effect on eukaryotic or virally encoded enzymes.
However, the few enzymes that are encoded only by viruses have provided targets for other drugs.
Most antiviral drugs resemble nucleosides and thus interfere with viral nucleic acid synthesis.
One such drug is acyclovir, which impedes herpesvirus replication by inhibiting the viral polymerase that synthesizes viral DNA but not the eukaryotic one.
Similarly, azidothymidine (AZT) curbs HIV replication by interfering with the synthesis of DNA by reverse transcriptase.
In the past 30 years, much effort has gone into developing drugs to treat HIV.
Currently, multidrug treatments, sometimes called “cocktails,” are considered to be most effective.
Such treatments commonly include a combination of two nucleoside mimics and a protease inhibitor, which interferes with an enzyme required for the assembly of the viruses.
Multidrug treatments originally involved taking up to 20 pills multiple times per day but now usually consist of a single daily tablet.
Another effective treatment involves a drug called maraviroc, which blocks a protein on the surface of human immune cells that helps bind the HIV virus.
This drug has also been used successfully to prevent infection in individuals who either have been exposed to, or are at risk of exposure to, HIV.
Emerging Viral Diseases
Viruses that suddenly become apparent are often referred to as emerging viruses.
HIV, the AIDS virus, is a classic example: It appeared in San Francisco in the early 1980s, seemingly out of nowhere, although later studies uncovered a case in the Belgian Congo in 1959.
Some other dangerous emerging viruses cause encephalitis, inflammation of the brain. One example is the West Nile virus, which appeared in North America in 1999 and has spread to 49 U.S. states, resulting in over 50,000 cases and about 2,000 deaths by 2019.
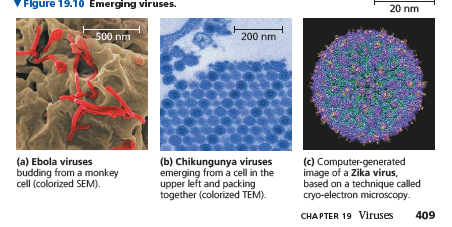
The deadly Ebola virus (Figure 19.10a), recognized initially in 1976 in central Africa, is one of several emerging viruses that cause hemorrhagic fever, an often fatal illness characterized by fever, vomiting, massive bleeding, and circulatory system collapse.
In 2014, a widespread outbreak, or epidemic, of Ebola virus occurred. By 2016, it had resulted in over 11,000 deaths.
In 2017, 2018, and 2019, smaller outbreaks occurred in the Democratic Republic of the Congo.
The mosquito-borne chikungunya virus (Figure 19.10b) causes an acute illness with fever, rashes, and persistent joint pain.
Chikungunya has long been considered a tropical virus, but it has now appeared in Italy, France, and Spain.
The Zika virus (Figure 19.10c) was first observed in Uganda in 1947, but for decades only a few cases occurred per year.
In the spring of 2015, however, it became an emerging virus when it caused a large outbreak in Brazil.
Although symptoms of Zika are often mild, the infection of pregnant women was correlated with a striking increase in the number of babies born with abnormally small brains, a condition called microcephaly.
Zika is a mosquito-borne flavivirus (like West Nile virus) that infects neural cells, posing a particular danger to fetal brain development.
Causes of Emerging Viral Strains
Where do these new strains of virus come from? One cause of rapidly emerging viral diseases in humans is mutation of existing viruses into new viruses that can spread more easily.
RNA viruses have a high rate of mutation because viral RNA polymerases do not proofread and correct errors in replicating their RNA genomes.
Some mutations change existing viruses into new viral strains that can cause disease, even in people immune to the original virus.
A well-known related example is how three or four mutations causing changes in a surface protein of a cat virus (feline panleukopenia virus) resulted in the emergence in 1978 of canine parvovirus, a very contagious deadly virus infecting dogs.
A second cause of the emergence of viral diseases is the spread of a viral disease from a small, isolated human population.
HIV, the virus that causes AIDS, went unnamed and virtually unnoticed for decades before spreading around the world.
In this case, technological and social factors, including affordable international travel, blood transfusions, unprotected sexual intercourse, and reuse of needles to inject intravenous drugs, allowed a previously rare human disease to become a global scourge.
A third cause of new viral diseases in humans is the spread of existing viruses from other animals.
Scientists estimate that about three-quarters of new human diseases originate in this way.
Animals infected with a virus that can be transmitted to humans are said to be a natural reservoir for that virus.
HIV is an example, as scientists believe that it originated from a version of the virus found in chimpanzees in central Africa, after people ate chimpanzee meat for food and were infected by exposure to chimpanzee blood.
Example of Influenza Epidemics
In general, flu epidemics provide an instructive example of these three causes of emerging viruses.
There are three types of influenza virus: types B and C, which infect only humans and have never caused an epidemic, and type A, which infects a wide range of animals, including birds, pigs, horses, and humans.
The influenza type A viruses present in pigs and wild and domestic birds are potential emerging viruses that represent a long-term threat to human health.
A case in point is the H5N1 strain of avian influenza virus, which is highly contagious and deadly in birds.
The first transmission from birds to humans was documented in Hong Kong in 1997. Since then, about 700 people have been infected, with an alarming mortality rate of greater than 50%.
The high mortality rate is partly because H5N1 is very different from strains of influenza that have circulated among humans for a long time.
Individuals are therefore not able to mount a strong immune response against viruses like H5N1.
Different strains of influenza A are given standardized names; for example, the name H5N1 identifies which forms of two viral surface proteins are present—hemagglutinin and neuraminidase (HA and NA, respectively; see the glycoprotein spikes in Figure 19.3c).
These two proteins together help determine the host range and severity of disease caused by each virus.
As of 2017, 18 types of hemagglutinin, a protein that helps the flu virus attach to host cells, and 11 types of neuraminidase, an enzyme that helps release new virus particles from infected cells, have been identified.
All possible combinations of HA and NA have been found in some waterbirds.
In 2018, researchers using advanced microscopy techniques reported that the HA protein is quite dynamic, stretching toward the target host cell, retracting, then refolding to a new shape and re-approaching the target cell.
Although deadly, the H5N1 strain has not yet caused an epidemic because nearly all cases have been the result of transmission from birds to people, rather than person-to-person.
Epidemics occur when genetic changes allow a new viral strain to be easily transmitted between humans.
An event like this occurred in 2009, when a strain of influenza virus (H1N1) appeared that was very different from the virus that causes the seasonal flu.
The H1N1 influenza virus spread rapidly, prompting WHO to declare a global epidemic, or pandemic.
Within half a year, the disease had reached 207 countries, infecting over 600,000 people and killing almost 8,000.
In addition to the 2009 H1N1 pandemic, influenza A strains have caused three other major flu epidemics among humans in the last 100 years.
The most notable of these was the “Spanish flu” pandemic of 1918–1919, which killed 40–50 million people worldwide.
In the Scientific Skills Exercise, you’ll analyze genetic changes in variants of the 2009 H1N1 influenza virus and correlate them with the spread of the disease.
The disease caused by H1N1 was originally called “swine flu” because parts of the viral genome were very similar to strains of influenza in pigs.
However, studies revealed that the virus was not transmitted from pigs to humans. Instead, the story was more complex: H1N1 was a unique combination of swine, avian, and human influenza genes that allowed it to spread among humans.
Influenza viruses can change quickly because they have a genome made up of nine segments of RNA rather than a single RNA molecule.
When an animal like a pig or a bird is infected with multiple strains of influenza virus, the RNA molecules making up the viral genomes can mix and match (reassort) during viral assembly, resulting in new genetic combinations.
If a flu virus from pigs recombines with viruses that circulate widely among humans, it may acquire the ability to spread easily from person to person, dramatically increasing the potential for a major human outbreak.
Pigs are believed to have been the main hosts for recombination that led to the 2009 H1N1 flu virus.
Influenza viruses also have a high rate of mutation, for reasons mentioned earlier.
Coupled with reassortments, these mutations can lead to the emergence of a viral strain from animals that can infect human cells.
Scientists are worried that the H5N1 strain will evolve in a way that enables it to spread as easily as the H1N1 strain.
This would represent a major global health threat like that of the 1918 pandemic.
How easily could this capability evolve in the H5N1 strain?
In 2011, scientists working with ferrets, small mammals used as model organisms for the human flu, found that only a few mutations of the avian flu virus were sufficient to allow infection of cells in the human nasal cavity and windpipe.
Furthermore, when the scientists transferred nasal swabs serially from ferret to ferret, the virus became transmissible through the air.
Reports of this startling discovery ignited a firestorm of debate about whether to publish the results.
Ultimately, the scientific community decided the benefits of preventing pandemics outweighed the risks of the information being used for harmful purposes, and the work was published in 2012.
Normal seasonal flu viruses (including influenza types A and B) are not considered emerging viruses because variations of seasonal flu viruses have been circulating among humans for long enough that most components are recognized by the immune system.
However, these viruses still undergo mutation and reassortment of genome segments, and variations of the HA protein are used each year to generate vaccines against the strains predicted most likely to occur the following year.
As we have seen, emerging viruses are usually existing viruses that mutate, spread more widely in the current host species, or spread to new host species.
Changes in host behavior or environmental changes can increase the viral traffic responsible for emerging diseases.
For instance, new roads built through remote areas can allow viruses to spread between previously isolated human populations.
Also, the destruction of forests to expand cropland can bring humans into contact with animals that host infectious viruses.
Finally, genetic mutations and changes in host ranges can allow viruses to jump between species.
Many viruses are transmitted by mosquitoes.
A dramatic expansion of the disease caused by the chikungunya virus occurred in the mid-2000s when a mutation allowed it to infect not only the mosquito species Aedes aegypti but also the related Aedes albopictus.
Insecticides and mosquito netting over beds are crucial tools in public health attempts to prevent diseases carried by mosquitoes.

Viral Diseases in Plants
More than 2,000 types of viral diseases of plants are known, accounting for an annual loss of over $30 billion worldwide due to destruction of crops.
Common signs of viral infection include bleached or brown spots on leaves and fruits, stunted growth, and damaged flowers or roots, all of which can diminish the yield and quality of crops.

Plant viruses have the same basic structure and mode of replication as animal viruses.
Most known plant viruses, including tobacco mosaic virus (TMV), have an RNA genome.
Many have a helical capsid, like TMV, while others have an icosahedral capsid.
Viral diseases of plants spread by two major routes.
In the first route, horizontal transmission, an external source infects the plant. Because the invading virus must get past the plant’s outer protective layer of cells (the epidermis), a plant becomes more susceptible to viral infections if it has been damaged by wind, injury, or herbivores.
Herbivores, especially insects, pose a double threat because they can also carry viruses, transmitting disease from plant to plant.
Moreover, gardeners may transmit plant viruses inadvertently on pruning shears and other tools.
The other route of viral infection is vertical transmission, in which a plant inherits a viral infection from a parent.
Vertical transmission can occur in asexual propagation (for example, through cuttings) or in sexual reproduction via infected seeds.
Once a virus enters a plant cell and begins replicating, viral genomes and associated proteins can spread throughout the plant through plasmodesmata, the cytoplasmic connections that penetrate the walls between adjacent plant cells.
The passage of viral macromolecules from cell to cell is facilitated by virally encoded proteins that cause enlargement of plasmodesmata.
Scientists have not yet devised cures for most viral plant diseases, so research efforts are focused largely on reducing disease transmission and on breeding resistant varieties of crop plants.
Prions: Proteins as Infectious Agents
The viruses discussed in this chapter are infectious agents that spread diseases, and their genetic material is composed of nucleic acids, whose ability to be replicated is well known.
Surprisingly, there are also proteins that are infectious. Proteins called prions appear to cause degenerative brain diseases in various animal species.
These diseases include scrapie in sheep; mad cow disease, which plagued the European beef industry about 20 years ago; and Creutzfeldt-Jakob disease in humans, which has caused the death of some 175 people in the United Kingdom since 1996.
Prions can be transmitted in food, as may occur when people eat beef from cattle with mad cow disease.
Kuru, another human disease caused by prions, was identified in the early 1900s among the South Fore indigenous people of New Guinea.
When a kuru epidemic peaked there in the 1960s, scientists at first thought the disease had a genetic basis because family members also often contracted the disease.
Eventually, however, investigations revealed a different story: After a death, family members practiced ritual cannibalism, eating organs of the deceased, and prions were transmitted primarily in brain tissue.
Women got kuru more often than men because men ate the more “prestigious” organs, like the heart, while women and children ate the brains.
Two characteristics of prions are especially alarming.
First, prions act very slowly, with an incubation period of at least ten years before symptoms develop.
The lengthy incubation period prevents sources of infection from being identified until long after the first cases appear, allowing many more infections to occur.
Second, prions are not destroyed or deactivated by heating to normal cooking temperatures.
To date, there is no known cure for prion diseases, and the only hope for developing effective treatments lies in understanding the process of infection.
How can a protein, which cannot replicate itself, be a transmissible pathogen?
According to the leading model, a prion is a misfolded form of a protein normally present in brain cells.
When the prion gets into a cell containing the normal form of the protein, the prion somehow converts normal protein molecules to the misfolded prion versions.
Several prions then aggregate into a complex that can convert other normal proteins to prions, which join the chain.
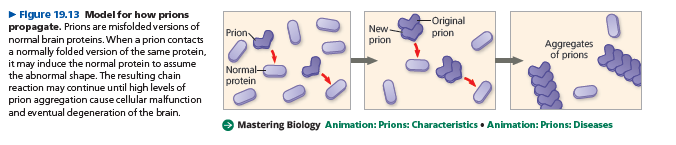
Prion aggregation interferes with normal cellular functions and causes disease symptoms.
This model was greeted with much skepticism when it was first proposed by Stanley Prusiner in the early 1980s, but it is now widely accepted.
Prusiner was awarded the Nobel Prize in 1997 for his work on prions.
He has also proposed that prions are involved in neurodegenerative diseases such as Alzheimer’s and Parkinson’s disease.
There are many outstanding questions about these small infectious agents.