VISUAL PERCEPTION AND ATTENTION
Chapter 2: Basic Processes in Visual Perception
1. Introduction
Visual perception is not instant; it evolves over time (Hegdé, 2008).
Visual processing starts with coarse information and moves to fine-grained details.
The human visual system is massively complex and context-dependent.
2. From Eye to Cortex
Eye Structures and Retina
Light → cornea → pupil → lens → retina
Rods (125M): motion, dim light, peripheral.
Cones (6M): color, fine detail, concentrated in fovea.
Three processing steps (Kalat, 2001):
Reception: Absorption of light by rods/cones.
Transduction: Conversion to neural signals.
Coding: Spatial layout preserved in cortex (retinotopy).
3. Visual Pathways
Main Route: Retina → LGN → V1 (Striate Cortex)
Optic chiasma: partial crossing of nerve fibers.
LGN (Thalamus): relays info to V1.
V1: Primary visual cortex in occipital lobe.
Two parallel pathways:
Pathway | Origin | Function | Main Input |
|---|---|---|---|
Parvocellular (P) | Cones | Color & fine detail | Cones |
Magnocellular (M) | Rods | Motion, depth, luminance | Rods |
4. Two Streams of Visual Processing
Ventral "What" Pathway
V1 → V2 → V4 → Inferotemporal cortex
Specializes in object identity.
Color and form processing.
Dorsal "Where/How" Pathway
V1 → V2 → MT/V5 → Posterior parietal cortex
Specializes in motion, spatial location, and visually guided actions.
5. Functional Specialisation Theory – Zeki (1992, 2005)
🧠 Core Idea:
Each visual attribute (color, motion, form) is processed in a different brain area:
Area | Specialisation |
|---|---|
V1/V2 | Early processing, color/form |
V3/V3A | Form in motion |
V4 | Color processing (with overlap) |
V5/MT | Motion perception |
🧪 Evidence:
PET (Zeki et al., 1991): V5 lights up with moving stimuli.
fMRI (Zeki & Marini, 1998): V4 active for colored objects; DLPFC active for surprising colors.
Conway et al. (2007): Cell clusters in V4 respond to both color and some shape.
⚠ Limitations:
Areas are not strictly specialized.
Other regions (e.g., V1/V2) also process color and form.
V4 is not a dedicated “color center.”
Binding problem: How does the brain integrate color, motion, and shape?
6. Visual Disorders as Evidence
Achromatopsia (Color blindness from brain damage)
Damage near V4 leads to color loss, but not completely.
Bouvier & Engel (2006): Partial color perception possible; spatial vision also affected.
Akinetopsia (Motion blindness)
Patient LM (Zihl et al., 1983): Can’t perceive motion, although vision otherwise normal.
V5/MT critical for motion.
TMS to V5 (Beckers & Zeki, 1995) disrupts motion perception.
7. Motion Perception: MT/V5 and MST
First-order vs. Second-order Motion
First-order: defined by luminance changes.
Second-order: defined by texture, contrast.
🧪 Findings:
Ashida et al. (2007): Different neurons process 1st- and 2nd-order motion.
Vaina (1998): MST damage impairs navigation despite preserved motion detection.
8. Binding Problem
How does the brain combine color, form, motion into coherent perception?
🧠 Synchrony Hypothesis:
Neurons processing the same object fire synchronously.
⚠ Problems:
Synchrony is difficult in complex or multi-object scenes.
Moutoussis & Zeki (1997): Color processed faster than motion = lack of synchrony.
9. Recurrent Processing Theory – Lamme (2006)
🧠 Idea:
Feedforward sweep (V1 → higher areas): initial unconscious processing.
Recurrent feedback (higher areas → V1): essential for consciousness.
🧪 Evidence:
Boehler et al. (2008): Visual awareness occurs with strong recurrent activity.
TMS disrupting feedback eliminates conscious perception.
10. Two Visual Systems – Milner & Goodale (1995, 1998)
🧠 Theory:
Ventral stream: Vision-for-perception.
Dorsal stream: Vision-for-action.
🧪 Evidence from Patients:
Patient DF (Visual agnosia): Can grasp objects but can't identify them.
Patient VK (Optic ataxia): Can recognize objects but fails to grasp them.
🧪 Illusion Studies:
Haart et al. (1999):
Matching (perception) = fooled by illusion.
Grasping (action) = not fooled.
Króliczak et al. (2006):
Fast flicking (action) ≠ fooled.
Slow pointing (perception-influenced) = fooled.
🧠 Dual-process model – Norman (2002):
Dorsal: fast, egocentric, action-focused.
Ventral: slower, allocentric, memory-based.
11. Integration and Summary
Key Concepts
Functional specialisation explains division of labor in visual cortex.
Ventral and dorsal streams process different "types" of visual information.
Conscious visual awareness depends on recurrent feedback, not just feedforward input.
Vision-for-action is less susceptible to illusions due to dorsal stream independence.
object and face recognition
perceptual organisation
perceptual segregation (human ability to work out accurately which parts of presented visual information being together and thus form separate objects) is a basic issue in visual perception and plays a crucial role in object recognition. This process involves distinguishing elements of a scene based on factors such as contrast, color, and spatial arrangement, enabling the brain to identify and categorize objects efficiently. Thus, we work out where the object is before deciding what it is.
the first systematic attempt to study perceptual segregation → was conducted by Gestalt psychologists in the early 20th century, who emphasized the idea that the whole is different from the sum of its parts and explored principles like proximity, similarity, good continuation, and closure that govern how we perceive distinct objects within a visual field.
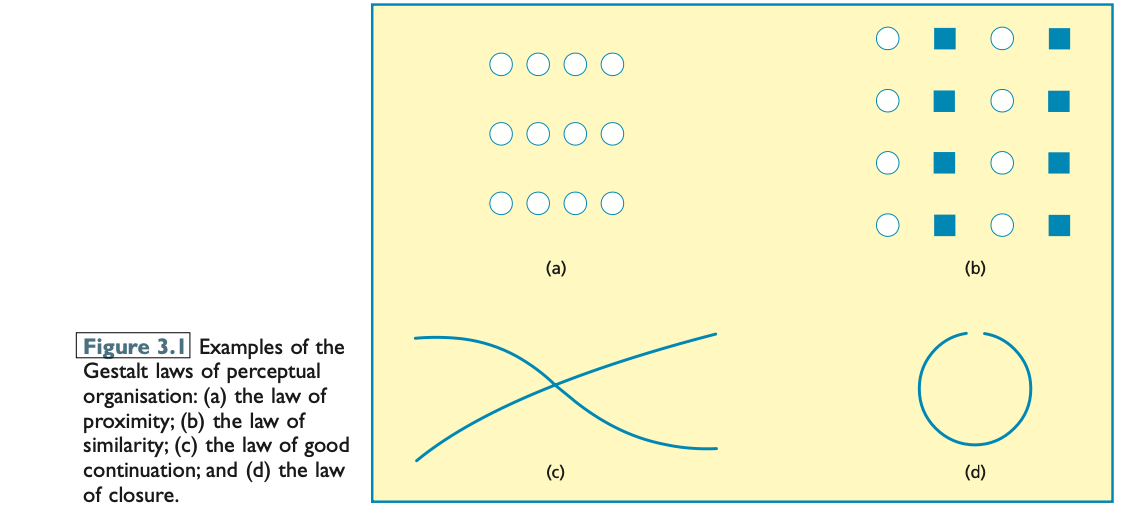
the law of proximity (Figure 3.1a) → suggests that elements that are close together are perceived as belonging to the same group, which helps our brains quickly organize visual information into coherent objects.
the law of similarity (Figure 3.1b) → posits that elements that share similar characteristics, such as color or shape, are perceived as a unified group, further aiding in our ability to distinguish and categorize objects in a complex visual environment.
the law of good continuation (Figure 3.1c) → states that lines and patterns are perceived as following the smoothest path, allowing us to infer connections between elements in a composition, which enhances our understanding of object structure and continuity in visual scenes.
the law of closure (Figure 3.1d) → suggests that our brains tend to fill in missing information or complete incomplete shapes, which enables us to recognize familiar forms even when parts of the object are not visible.
evidence supporting gestalt approach → Pomerantz (1981) found that people could more quickly identify a different item in a visual array when the array was more complex but easily organized, compared to a simpler, less organized one. This faster recognition—despite increased complexity—demonstrates the configural superiority effect, supporting the Gestalt idea that the whole is perceived more efficiently than the sum of its parts.
The Gestaltists proposed that in visual perception, we naturally distinguish a figure (the main object of focus) from the ground (the less important background). The figure is seen as having a defined shape and appears in front of the ground, with its contours belonging to it.
This idea is supported by the faces–goblet illusion, where either the goblet or the faces can be perceived as the figure, depending on how the viewer organizes the image. The figure appears in front and receives more attention than the ground.
Research by Weisstein and Wong (1986) showed that people were three times better at judging line orientation when the line appeared on the figure rather than the ground, confirming enhanced processing of the figure. Furthermore, Likova and Tyler (2008) found suppression of the ground in early visual areas (V1 and V2), supporting the notion that the brain actively prioritizes the figure while downplaying the ground.
Overall, these findings validate the Gestalt claims about figure–ground segregation, highlighting the brain's tendency to focus on organized, meaningful elements in a visual scene.
Evidence
1. Conflicting Gestalt Laws
Quinlan & Wilton (1998) examined what happens when grouping principles like proximity and similarity conflict.
They found:
Initial grouping is based on proximity.
If there's a mismatch within a group, other features like similarity can override proximity.
When mismatches exist both within and between groups, proximity is often ignored in favor of other cues like color.
2. Realistic Stimuli vs. Artificial Figures
Geisler et al. (2001) showed that contour perception in natural scenes (e.g., flowers, rivers) depends on:
Nearby contour segments having similar orientations
More distant ones having different orientations
This suggests we use real-world knowledge, not just Gestalt principles.
Elder & Goldberg (2002) still found support for Gestalt principles, especially proximity and good continuation, using natural images.
3. Uniform Connectedness
uniform connectedness: the notion that adjacent regions in the visual environment possessing uniform visual properties (e.g., colour) are perceived as a single perceptual unit.
Palmer & Rock (1994) proposed uniform connectedness (similar visual properties in connected areas) as a stronger and earlier grouping cue than Gestalt laws.
Han et al. (1999, 2003) found:
Uniform connectedness is not necessarily faster than proximity.
It becomes more useful with multiple objects, suggesting its role depends on the complexity of the visual scene.
4. Role of Experience and Attention
Kimchi & Hadad (2002) showed that past experience (e.g., knowledge of Hebrew letters) speeds up perceptual grouping, contradicting the Gestalt view of grouping as purely bottom-up.
Vecera et al. (2004) found that spatial attention can influence figure–ground assignment. When attention was directed to typically background areas, the usual figure–ground perception was reduced by 40%.
Kimchi & Peterson (2008) found that simple stimuli still triggered figure–ground processing even without attention, but complex stimuli required attention.
Conclusion
While Gestalt principles like proximity, similarity, and good continuation are still influential, more recent research shows:
Top-down processes (like experience and attention) also play a critical role.
New principles like uniform connectedness and insights from naturalistic stimuli offer a more complete view of visual perception.
Here’s a summary of the findings:
Grill-Spector & Kanwisher (2005)
Tested whether figure–ground segregation always happens before object recognition.
Participants were shown quick images (17–167 ms) followed by a mask.
Two tasks:
Object detection: Is there an object?
Object categorisation: What kind of object is it (e.g., a car)?
Results:
Reaction times and error rates were almost identical for both tasks.
When participants failed to detect an object, categorisation also failed (and vice versa).
Conclusion:
Figure–ground segregation (It refers to the brain’s ability to separate the main object of focus (the figure) from the background (the ground) in a visual scene) and object recognition likely involve the same mechanism.
Top-down processing (Top-down processing is a type of perceptual processing that is guided by prior knowledge, experience, expectations, and goals rather than just the raw sensory input.) (e.g., expectations, prior knowledge) plays a significant role.
Mack et al. (2008) — A Challenge to That Conclusion
Also compared detection and categorisation, but made the task harder (inverted or degraded images).
Findings:
Object categorisation performance dropped significantly compared to detection.
Implication:
Object categorisation may require more complex or additional processes than detection.
This suggests figure–ground segregation and object recognition might not always be identical processes.
Takeaway
While some evidence suggests that detection and recognition rely on the same underlying process, other studies show that recognition can break down while detection remains intact, hinting at distinct or layered processes in visual perception.
evaluation
Strengths of the Gestalt Approach
Laws of Grouping: The Gestalt laws (like proximity and similarity) have withstood the test of time and remain relevant in the study of perception.
Focus on Perceptual Organization: The Gestaltists emphasized the importance of understanding the processes underlying perceptual organization and how we interpret complex visual scenes.
Limitations of the Gestalt Approach
Overreliance on Line Drawings: Most evidence came from 2D line drawings, which may not fully capture real-world complexity.
Lack of Explanation: While the Gestaltists described perceptual phenomena, they didn’t always provide adequate explanations for why these phenomena occur.
Conflict Between Laws: The Gestaltists didn’t address what happens when their perceptual laws conflict, such as in cases of competing cues (e.g., proximity vs. similarity).
Incomplete Principles: The Gestaltists didn’t recognize all principles of perceptual organization, such as uniform connectedness, which later research (e.g., Han & Humphreys, 2003) highlighted.
Incorrect Emphasis on Bottom-Up Processes: The Gestaltists claimed that figure–ground segregation largely depends on bottom-up (stimulus-driven) factors. However, this view has been challenged by evidence showing that top-down processes (influenced by past experiences and attention) also play a significant role in figure–ground segregation.
Top-Down vs. Bottom-Up Processes in Perception
Bottom-Up Processing: Refers to perception driven primarily by sensory input, where the brain organizes simple visual cues based on basic principles like proximity and similarity.
Top-Down Processing: Involves prior knowledge, expectations, and attention, guiding how we perceive objects, especially in more complex, real-world scenes.
Gestaltists’ View: They believed that figure–ground segregation (distinguishing the figure from the background) was primarily a bottom-up process.
Current View:
Research now shows that both top-down and bottom-up processes work together to maximize perceptual efficiency, especially in complex scenes.
For simple shapes (used in Gestalt studies), bottom-up processes may dominate.
For natural scenes (which are more ambiguous), top-down processes (informed by object knowledge) become crucial to achieve clear figure–ground segregation.
Key Findings Challenging Gestaltists’ Claims
Kimchi & Hadad (2002): Past experiences influence figure–ground segregation, showing that top-down processes are essential.
Vecera et al. (2004): Attention can influence figure–ground assignment, again indicating top-down processes.
Grill-Spector & Kanwisher (2005): Both bottom-up and top-down processes likely work together for figure–ground segregation and object recognition.
Mack et al. (2008): Suggested that object recognition may be more complex than figure–ground segregation, involving different processes.
Conclusion
While Gestalt principles still provide a useful framework, current research suggests that both bottom-up and top-down processes are crucial in perceptual organization, especially in more realistic and complex visual scenes. The understanding of figure–ground segregation and object recognition is evolving, acknowledging the interplay of these processes.
theories of object recognition
Here’s a breakdown of the key points from your passage on object recognition, including Marr’s theory and Biederman’s recognition-by-components theory, organized for clarity and easy reference:
🔍 Why Object Recognition Matters
Object recognition is a vital part of visual processing—it’s how we identify and make sense of the world.
It’s not just a perceptual task but also a cognitive one, involving memory, reasoning, and interaction (Peissig & Tarr, 2007).
1. Marr’s Computational Theory of Object Recognition (1982)
David Marr proposed that visual perception involves creating increasingly complex and abstract representations of the visual environment. His model progresses through three main stages:
a. Primal Sketch
Description: A 2D map of changes in light intensity (edges, contours, textures).
Purpose: Identifies basic features like edges and blobs using brightness, texture, or color differences.
Nature: Viewpoint-dependent and based on raw sensory input.
b. 2.5D Sketch
Description: Incorporates information about depth, shading, motion, and texture.
Purpose: Allows the system to understand surface orientation and depth, but from the viewer’s perspective.
Nature: Still viewpoint-dependent; includes the observer’s position and orientation.
c. 3D Model Representation
Description: An abstract, three-dimensional representation that is viewpoint-invariant.
Purpose: Enables recognition of objects regardless of angle, lighting, or perspective.
Nature: Object-centered — the viewer can recognize an object from any angle.
2. Biederman’s Recognition-by-Components Theory (1987)
Irving Biederman built upon Marr’s work with a more concrete model focusing on how we parse and recognize objects based on simpler components.
Core Ideas:
Geons (Geometric Ions): The basic building blocks of object recognition (e.g., cylinders, cones, blocks, spheres).
About 36 geons are sufficient to describe most objects.
Structural Description: Objects are recognized by identifying what geons are present and how they are arranged.
Recognition Process:
Edge Extraction: Find boundaries in the visual field using changes in luminance, texture, or color.
Segmentation: Divide the image into parts, especially focusing on concave regions of contours to identify distinct geons.
Match with Stored Representations: Compare the identified geons and their spatial arrangements to known object templates.
Invariant Properties of Edges (Viewpoint-Invariant Cues):
These five edge properties help define geons reliably across viewpoints:
Curvature – Bends or arcs in the contour
Parallelism – Equidistant lines
Cotermination – Multiple edges meeting at a point
Symmetry – Balanced shapes
Collinearity – Alignment along the same line
Non-Accidental Principle:
Suggests we assume regular patterns in the image reflect actual structure in the world, not coincidence.
For example, parallel lines are assumed to indicate parallel surfaces in 3D.
Handling Partial Information:
Occlusion-resistant: Can still recognize objects even if parts are missing, as long as key geons and concavities are visible.
Redundancy: Most objects can be recognized from only a few visible geons (e.g., a giraffe from its neck alone).
Comparison Between Theories:
Marr's theory is more computational and step-wise, focusing on the transition from raw data to full 3D understanding.
Biederman's theory is component-based, focusing on how we break down and match parts of objects for recognition.
Both agree that object recognition can be viewpoint-invariant, especially when the key features or components are accessible.
evidence
Here's a detailed summary of the extended discussion on Biederman’s Recognition-by-Components (RBC) theory, highlighting both supporting and conflicting evidence:
🔍 Core Prediction of RBC Theory
Viewpoint-invariant recognition: Biederman’s theory proposes that objects are recognized equally well from different viewing angles, as long as their geons and spatial arrangements are identifiable.
✅ Evidence Supporting Viewpoint Invariance
Biederman & Gerhardstein (1993):
Design: Used familiar objects and priming tasks.
Finding: Recognition was equally effective even with a 135° angular change between object views.
Conclusion: Recognition of familiar objects was not affected by viewpoint changes, supporting the idea of viewpoint invariance.
❌ Evidence Against Viewpoint Invariance
Tarr & Bülthoff (1995):
Design: Used novel objects with extensive practice at specific viewpoints.
Finding: Recognition was viewpoint-dependent—performance was better from practiced orientations.
Implication: Novel object recognition relies more on viewpoint familiarity, challenging RBC’s core claim.
Gauthier & Tarr (2002):
Used “Greebles” (novel, complex objects from artificial “families”).
7 hours of training with multiple orientations.
Finding: Even with increasing expertise, recognition remained strongly viewpoint-dependent.
Conclusion: No evidence that practice leads to viewpoint-invariant recognition, undermining a potential shift from dependent to invariant processing.
✅ Evidence Supporting Key Aspects of RBC
Importance of Concavities:
Biederman (1987):
Recognition was harder when concave contour segments were removed from degraded line drawings.
Conclusion: Concavities are critical for segmenting objects into geons.
Geon Importance:
Cooper & Biederman (1993):
Two similar-named objects were shown in succession.
Recognition was worse when a geon changed (e.g., top hat to bowler) than when only size changed.
Vogels et al. (2001):
Single-neuron recordings in monkeys’ inferior temporal cortex.
Some neurons showed greater sensitivity to geon changes than to size changes.
Conclusion: Geons are neurally relevant units of object structure.
❌ Limitations of RBC Theory
1. Overemphasis on Edge-Based Recognition
Sanocki et al. (1998):
Compared line drawings vs. full-color photographs in both isolated and contextual conditions.
Object recognition was worse with line drawings, especially in context (multiple objects).
Conclusion: Biederman overemphasized edge-based recognition; surface features (like color and texture) also aid recognition, particularly in complex scenes.
2. Neglect of Top-Down Influences
Palmer (1975):
Participants viewed a scene (e.g., a kitchen) before a briefly presented object (e.g., loaf, mailbox, drum).
Recognition accuracy:
Best when object was contextually appropriate,
Worse with no context,
Worst when object was contextually inappropriate.
Conclusion: Context and prior knowledge influence recognition, contradicting RBC’s purely bottom-up emphasis.
Bar et al. (2006, review):
Summarized evidence that expectations, semantic context, and memory can influence early stages of object processing.
Emphasized the role of top-down processing in object recognition.
🧠 Summary of Theoretical Tensions
Aspect | Biederman’s Claim (RBC Theory) | Counter-Evidence |
|---|---|---|
Viewpoint Invariance | Object recognition is largely invariant to viewpoint. | Recognition is often viewpoint-dependent for novel or complex objects. |
Geon-Based Recognition | Geons are the core units; recognition fails when geons or concavities are obscured. | Supported by both behavioral and neural evidence. |
Edge-Based Recognition | Recognition mainly relies on contours and edges. | Performance drops in complex scenes or without surface features (color, texture). |
Bottom-Up Processing | Recognition is driven by stimulus features, not knowledge or expectations. | Context, expectations, and prior experience significantly enhance recognition. |
This means that when stimuli are ambiguous or lack distinct characteristics, the ability to identify objects or faces can suffer, leading to potential inaccuracies in perception.
Evaluation
Here's a detailed evaluation of Biederman’s (1987) Recognition-by-Components (RBC) theory, summarizing both its strengths and limitations:
🧠 Evaluation of Recognition-by-Components Theory
✅ Strengths
Addresses Invariance in Object Categories
Core puzzle: How do we recognize objects despite variation in shape, size, and orientation within categories (e.g., recognizing all types of chairs)?
RBC’s solution: Proposes that objects are made up of geons (simple 3D components like cylinders, blocks, etc.).
Implication: Because geons are structurally simple and robust to viewpoint changes, they explain how we can recognize objects in many different forms.
Evidence for Geons and Edges
Empirical studies support the importance of geon-like components and concavities in object recognition (e.g., Cooper & Biederman, 1993).
Concavities are especially useful for segmenting objects into parts, and thus crucial for identifying geons.
Simplicity and Plausibility
RBC provides a straightforward, bottom-up account of object recognition based on geometric structure.
Offers a mechanistic explanation for how complex objects can be recognized using a relatively small number of components (~36 geons).
❌ Limitations
📉 Underemphasis on Top-Down Processing
Main critique: The theory is heavily bottom-up, focusing only on stimulus-driven features.
Neglects top-down influences such as context, prior knowledge, and expectations.
Empirical challenge: Studies (e.g., Palmer, 1975; Bar, 2003) show that scene context enhances recognition, which RBC fails to explain.
Modern approaches (e.g., Lamme, Bar) incorporate both bottom-up and top-down pathways.
🔍 Limited to Coarse Discriminations
Scope issue: RBC works for broad categorization (e.g., dog vs. cat), but not fine-grained recognition (e.g., your dog vs. another dog).
Face recognition: RBC doesn't explain how we distinguish individual faces, which rely on more nuanced, configural features.
Even Biederman et al. (1999) acknowledged its inapplicability to face recognition, a domain where top-down and holistic processes dominate.
🔄 Disregards Viewpoint-Dependent Recognition
Key assumption: Recognition is viewpoint-invariant—as long as geons are visible, the object can be recognized from any angle.
Contradicted by evidence: Studies by Tarr & Bülthoff (1995) and Gauthier & Tarr (2002) show that:
Recognition is viewpoint-dependent, especially for novel or complex objects.
Even with extensive practice, people perform better from familiar viewpoints.
Conclusion: RBC oversimplifies the role of viewpoint and doesn't reflect the flexibility and adaptation in human object recognition.
🧩 Assumes Fixed, Invariant Components (Geons)
Assumes that all recognizable objects are composed of stable geon shapes.
Problem: Many objects are ambiguous, abstract, or formless (e.g., clouds, lava lamps).
Hayward & Tarr (2005) argued that almost any feature can become meaningful in the right context.
This undermines the idea that a fixed set of geons can describe the entire visual world.
⚖ Overall Assessment
Aspect | Evaluation |
|---|---|
Theoretical elegance | ✅ Simple, intuitive model of recognition through component parts |
Empirical support | ✅ Supported by evidence on geons and concavities |
Top-down influence | ❌ Ignores context, expectations, and memory |
Viewpoint dependence | ❌ Assumes invariance, but data shows dependence—especially with novel objects |
Fine-grained recognition | ❌ Fails to explain subtle within-category distinctions |
Flexibility of object features | ❌ Overly rigid—doesn’t account for vague or non-geon objects |
Viewpoint-dependent vs. viewpoint-invariant approaches
Here's a detailed summary of the comparison between viewpoint-invariant and viewpoint-dependent theories of object recognition, based on the research you provided:
🧭 Viewpoint-Invariant vs. Viewpoint-Dependent Theories of Object Recognition
🔍 Viewpoint-Invariant Theories
Key Proponent: Biederman (1987) – Recognition-by-Components theory.
Core Assumption: Object recognition is unaffected by the observer’s viewpoint.
Mechanism: Objects are recognized through geons (basic 3D components), which are resistant to transformations like rotation, scaling, or translation.
Recognition Style: Categorical – Recognizing broad object categories (e.g., "bicycle" vs. "car").
Prediction: Recognition should be equally fast and accurate across different viewpoints.
Support: Biederman & Gerhardstein (1993) showed viewpoint invariance when using familiar objects.
Limitation: Doesn’t explain within-category discriminations or novel object recognition well.
🔁 Viewpoint-Dependent Theories
Key Proponents: Tarr & Bülthoff (1995, 1998)
Core Assumption: Object recognition is slower and/or less accurate when the viewpoint changes.
Mechanism: Object representations are stored as specific views (mental snapshots).
Recognition Style: Exemplar-based – Recognition is easier when the current view matches a stored view.
Prediction: Performance declines as the angular difference from stored viewpoints increases.
Support:
Tarr & Bülthoff (1995) – Recognition of novel objects was viewpoint-dependent.
Gauthier & Tarr (2002) – Even with practice, recognition of "Greebles" remained viewpoint-sensitive.
⚖ Contextual and Task-Based Modulation
🧪 Tarr et al. (1998)
9 experiments testing 3D object recognition.
Finding: Recognition was:
Viewpoint-invariant in easy tasks (e.g., feedback given).
Viewpoint-dependent in difficult tasks (e.g., no feedback).
Conclusion: Task difficulty influences which recognition process dominates.
🧠 Vanrie et al. (2002)
Observers matched 3D block figures with either:
(1) Small tilt (10°) – Invariance condition
(2) Mirror-image rotation – Rotation condition
Finding:
Invariance condition → Viewpoint-invariant performance
Rotation condition → Viewpoint-dependent performance
Conclusion: Complex transformations lead to viewpoint dependence.
🧩 Blais et al. (2009)
Visual search study:
Some information (e.g., feature conjunctions) → Viewpoint-invariant
Other information (e.g., depth cues) → Viewpoint-dependent
Takeaway: The type of visual information determines whether recognition is affected by viewpoint.
🔄 Integrated Theories: A Combined Approach
Proposed by: Foster & Gilson (2002), Hayward (2003)
Assumption: The visual system uses both:
Viewpoint-invariant cues (e.g., number of parts, categorical structure)
Viewpoint-dependent cues (e.g., angles, part configuration)
Support:
Foster & Gilson (2002) showed that observers used both cue types simultaneously when distinguishing 3D objects made of cylinders.
Conclusion: Object recognition is flexible, and the brain integrates all available information to achieve it.
🧠 Summary Table
Approach | Assumption | Strengths | Weaknesses |
|---|---|---|---|
Viewpoint-Invariant | Recognition is unaffected by viewing angle | Efficient for familiar objects and categories | Fails for novel views or within-category differences |
Viewpoint-Dependent | Recognition relies on stored views; performance declines with rotation | Explains viewpoint sensitivity and training effects | Inefficient for rapid recognition in real-world contexts |
Integrated/Hybrid | Both invariant and dependent cues are used cooperatively | Reflects real-world flexibility of visual processing | Still under development; varies by task and stimulus type |
evaluation
Here’s a detailed summary and evaluation of the discussion on viewpoint-dependent vs. viewpoint-invariant object recognition:
🧠 Evaluation: Viewpoint-Dependent vs. Viewpoint-Invariant Recognition
🚫 Over-Simplification Warning
It is overly simplistic to claim object recognition is always either viewpoint-dependent or viewpoint-invariant.
Instead, recognition lies on a continuum, with contextual and task-related factors influencing the extent to which either mechanism dominates.
🧩 Key Moderating Factors
Type of Discrimination Required:
Between-category discriminations (e.g., dog vs. cat) → Often viewpoint-invariant
Within-category discriminations (e.g., your cat vs. someone else’s) → Often viewpoint-dependent
Task Complexity:
Simple tasks (e.g., clear feedback, well-known objects) → More viewpoint-invariant
Difficult tasks (e.g., novel objects, subtle differences) → More viewpoint-dependent
Object Familiarity and Training:
Extensive experience with objects may improve recognition from multiple angles—but evidence is mixed (e.g., Greeble studies)
🔄 Hybrid View: Parallel Use of Information
A promising theory is that both viewpoint-dependent and viewpoint-invariant cues are used in parallel.
This allows the visual system to adapt flexibly to the situation and use all available visual cues to support object recognition.
Evidence from Foster & Gilson (2002) supports this view: people use both types of features to make judgments about 3D objects.
🧪 Caution on the Evidence for Viewpoint Dependence
Much of the “evidence” for viewpoint dependence (e.g., longer reaction times for rotated objects) is indirect.
Example: Biederman & Gerhardstein (1993) found slower response times for rotated objects.
But this doesn’t necessarily mean recognition itself is viewpoint-dependent.
Alternative Explanation: The rotation might slow pre-recognition visual processing (e.g., mental alignment), which is unrelated to the actual matching process.
Blais et al. (2009) also caution that such time differences could reflect early perceptual steps, not recognition per se.
🧠 Conclusion
Viewpoint-dependence and invariance are not mutually exclusive; recognition can involve both, depending on:
Task demands
Object familiarity
Complexity of the visual scene
Future models and theories should account for this flexibility and integration of visual information.
Neuroscientific perspectives (introduced next) may help clarify how the brain coordinates these processes.
Cognitive neuroscience approach to object recognition
🌐 Understanding Complexity
Although recognizing someone like Robert De Niro feels effortless, it involves numerous complex, hierarchical processes across multiple brain regions—from the retina to higher-level cortical areas.
These processes interact across both low-level and high-level visual stages to achieve stable and flexible object recognition.
🧭 The Ventral Visual Pathway
The ventral stream (or “what” pathway) is key to object recognition.
It starts from the retina, proceeds through:
Lateral geniculate nucleus
Primary visual cortex (V1)
V2, V4
Culminates in the inferotemporal cortex (IT)
As information moves forward:
Stimuli become more complex (e.g., from edges → shapes → whole objects)
Receptive field size increases (neurons respond to larger areas of the visual field)
🔍 Note: The dorsal stream (the “where” or “how” pathway) is more involved in spatial processing and visually guided actions.
🧠 Inferotemporal Cortex (IT) and Object Recognition
The anterior inferotemporal cortex plays a crucial role in recognizing objects.
Neuronal responses in this region can be described along two key dimensions:
Selectivity:
A neuron is highly selective if it responds strongly to a specific object and weakly to others.
Invariance (or tolerance):
A neuron is invariant if it responds consistently to an object regardless of changes in orientation, size, lighting, etc.
🧩 Linking Neural Evidence to Theoretical Models
High invariance/tolerance in IT neurons supports viewpoint-invariant theories (e.g., Biederman's recognition-by-components theory).
Low invariance (i.e., neurons sensitive to viewpoint changes) supports viewpoint-dependent theories (e.g., Tarr & Bülthoff).
🧪 Methodological Considerations
Most of the evidence comes from monkey studies using invasive techniques (e.g., single-neuron recordings).
It is commonly assumed that humans and monkeys share similar basic visual processing mechanisms, though this assumption is not beyond question.
🧠 Summary of Implications
The inferotemporal cortex is a neural basis for object recognition, and the type of neuronal response it exhibits (selective vs. invariant) maps onto competing psychological theories.
Neural evidence helps bridge computational models with biological reality, though care must be taken when generalizing findings from animals to humans.
evidence
🧠 1. How Do We Know the Inferotemporal Cortex Helps with Object Recognition?
Binocular Rivalry Studies (Leopold & Logothetis, 1999):
Monkeys saw different images in each eye and had to say what they were seeing.In early brain areas like V1, only 20% of neurons' activity matched what the monkey said they saw.
In higher areas (like the inferotemporal cortex), this number was 90% — much stronger connection to perception.
✅ So, higher brain areas (especially the inferotemporal cortex) are closely linked to what we consciously see.
⚡ 2. Does This Area Cause Us to Recognize Things?
Afraz et al. (2006):
Monkeys were trained to decide if blurry images were faces or non-faces.When scientists stimulated face-sensitive neurons, the monkeys were more likely to say they saw a face, even if they didn’t.
✅ This proves that activating these neurons can change what we perceive — not just reflect it.
🧩 3. Are Specific Areas in the Brain Tuned to Different Kinds of Objects?
Brain scans show that parts of the inferotemporal cortex are tuned to different types of things — faces, animals, cars, etc.
Example: The fusiform face area (FFA) is often said to handle face recognition — but it also reacts to animals and sculptures.
✅ So, the brain isn’t perfectly organized into “one part per object type,” but there is some specialization.
👤 4. Do Individual Neurons Care About Specific Things?
Tsao et al. (2006):
In monkeys, 97% of certain neurons in the brain responded only to faces, not other things.Quiroga et al. (2005):
Found a neuron in a human brain that responded only to pictures of Jennifer Aniston (but not when she was with Brad Pitt!). Other neurons responded only to other famous people or places.
⚠ But these neurons were in memory areas of the brain, not just visual ones.
✅ Some neurons are extremely picky and respond only to one specific person or thing.
🔄 5. What About Recognizing Things from Different Angles?
Booth & Rolls (1998):
Monkeys played with new objects, then saw photos of them from different views.About half of neurons responded only to specific angles.
Only 14% worked no matter what angle — but those few were very helpful for recognition.
✅ Only some neurons recognize objects from any angle — but they may be the most important ones.
📉 6. Trade-Off: Detail vs Flexibility
Zoccolan et al. (2007):
Found that neurons that are super specific (e.g., respond to only one object) usually aren’t very flexible (e.g., across sizes/angles), and vice versa.
✅ This mix helps us both:
Identify objects exactly (like recognizing your friend’s face),
and categorize broadly (like spotting "a dog" from different breeds or poses).
🧭 7. Is Object Recognition Only in One Part of the Brain?
Traditionally:
Ventral stream = "What is it?" (object recognition)
Dorsal stream = "Where is it?" or "How do I interact with it?"
Konen & Kastner (2008):
Found that both streams help with object recognition, and higher areas (even in the dorsal stream) become more flexible over time.
✅ So, object recognition happens in both brain pathways — not just the ventral one.
🦒 8. Are Neurons Responding to Whole Objects or Just Features?
Example: A neuron that reacts to giraffes might actually just be reacting to long necks, not giraffes in general.
Sigala (2004): Some neurons react to specific features, not full objects.
✅ Some “object-selective” neurons are actually just “feature-selective.”
✅ Final Takeaways:
The inferotemporal cortex is a key part of the brain for recognizing objects, especially faces.
Some neurons are very specific, while others are more general or flexible.
Object recognition involves a mix of both brain areas and neuron types.
Both brain pathways (ventral and dorsal) help us recognize and understand what we see.
It’s important not to confuse feature recognition with full object recognition.
Top-down processes in object recognition
🧠 What Are Top-Down Processes in Object Recognition?
Most research on object recognition focuses on bottom-up processing, where information flows from the eyes to the brain (especially along the ventral visual pathway).
But top-down processes, coming from higher brain areas like the prefrontal cortex, are also important — especially when recognizing things is difficult.
🔍 Do Top-Down Processes Help Before or After Recognition?
This is a key question:
Do they help us recognize the object?
Or do they come into play after recognition to help us understand the object’s meaning?
🧪 Study 1: Bar et al. (2006)
People were shown brief, hard-to-see drawings of objects (masked so they were hard to recognize).
Researchers found that:
The orbitofrontal cortex (a part of the prefrontal cortex) became active before the visual recognition areas.
This happened about 50 milliseconds earlier than in the temporal lobe.
The earlier this brain area was activated, the more likely the person was to recognize the object.
✅ Conclusion: The brain sends top-down signals early on, helping to “guess” or predict what the object might be when the image is unclear.
🧲 Study 2: Viggiano et al. (2008)
People tried to recognize blurred photos of animals under four conditions:
rTMS to left prefrontal cortex
rTMS to right prefrontal cortex
Sham rTMS (fake stimulation)
No stimulation
🧠 rTMS (repetitive transcranial magnetic stimulation) is a way to temporarily disrupt brain activity in a specific area.
Findings:
When rTMS was applied (left or right), people were slower at recognizing the blurred images.
But rTMS had no effect when the photos were clear.
✅ Conclusion: When visual information is limited, the prefrontal cortex plays an active role in helping us recognize objects using top-down guidance.
📌 Key Takeaways
Top-down processes (from the prefrontal cortex) help with object recognition, especially when the image is unclear or degraded.
The orbitofrontal cortex may help by quickly sending predictions to the visual areas.
The dorsolateral prefrontal cortex also seems important, based on rTMS studies.
These top-down processes are less necessary when the image is clear and detailed.
Unresolved question: What exactly are the different roles of the orbitofrontal and dorsolateral prefrontal areas?
Evaluation
✅ Strengths of Research on Object Recognition
Strong evidence for the role of the inferotemporal cortex:
It plays a key role in recognizing objects.
Some neurons there are viewpoint-invariant (can recognize an object from different angles).
Others are viewpoint-dependent (respond only to specific views).
This supports the idea that object recognition can happen in multiple ways, depending on the situation.
Specialization in the brain:
Different parts of the inferotemporal cortex seem to be tuned to different object categories (e.g., faces, animals, tools).
⚠ Limitations of the Research
Generalizing from monkeys to humans:
A lot of research is done on monkeys, but the results may not fully apply to humans.
Still, some human studies (e.g., Konen & Kastner, 2008) match monkey findings, which helps support generalization.
Too much focus on the ventral stream:
Most studies focus on the ventral stream (“what” pathway).
But the dorsal stream (“where/how” pathway) might also play an important role in object recognition — more than previously thought.
Confusing object-selective with feature-selective neurons:
Some neurons thought to respond to whole objects might actually be responding to distinct features (like a giraffe’s neck, not the whole giraffe).
More careful experiments are needed to tell the difference (e.g., Sigala, 2004).
Ignoring top-down processes:
Research often assumes recognition flows bottom-up, from the eyes to the brain.
But studies (e.g., Bar et al., 2006; Viggiano et al., 2008) show top-down processes (from the prefrontal cortex) can help guide recognition, especially when the image is unclear.
🧠 Final Thought:
While the inferotemporal cortex and ventral stream are clearly important, we need a broader view that includes:
Top-down influences (expectations, memory),
Dorsal stream contributions, and
A clearer understanding of how neurons respond to features vs. whole objects.
Cognitive Neuropsychology of object recognition
🧠 Visual Agnosia: What Is It?
Visual agnosia is when someone can't recognize objects by sight, even though:
Their eyes and basic vision are fine.
They do know what the objects are — it's not a memory problem.
The issue is visual recognition, not just naming (they fail on non-verbal tasks too).
🧩 Two Classic Types of Visual Agnosia
Apperceptive Agnosia:
Problem: Early visual processing is disrupted.
They can’t accurately perceive shapes or objects.
These patients can’t copy drawings of objects.
Test: Gollin picture test (they need more complete versions to identify the object).
Associative Agnosia:
Problem: Perception is fine, but they can’t match the image to stored knowledge.
They can copy objects well but still don’t recognize them.
🔍 Important note: This apperceptive/associative split is too simplistic — many patients don’t fit neatly into either category.
📚 Beyond the Two Types: More Specific Deficits
Some people have very specific recognition problems, like:
Prosopagnosia – inability to recognize faces.
So, object recognition disorders can be highly specific, not just “general” deficits.
🧠 Riddoch & Humphreys’ Hierarchical Model of Object Recognition
They proposed a more detailed, step-by-step model to explain how object recognition breaks down at different stages:
Edge grouping by collinearity:
Early stage: combining lines and edges to form a basic outline.
Feature binding into shapes:
Combining parts (like corners, curves) into a whole shape.
View normalization (optional):
Creating a mental version of the object that’s not tied to a specific angle.
Structural description:
Matching the shape to stored knowledge of what the object looks like.
Semantic system:
Accessing what the object means (e.g., "a hammer is used to hit nails").
🔮 What This Model Predicts
Different patients might have different breakdowns at different stages.
This supports the idea that the apperceptive vs. associative distinction is not enough.
We need to consider which exact stage of the recognition process is impaired.
✅ Key Takeaways
Visual agnosia shows that object recognition is complex and multi-step.
The classic categories (apperceptive vs. associative) are helpful but too limited.
More recent models (like Riddoch & Humphreys’) give a better explanation by breaking recognition into specific stages.
Studying brain-damaged patients helps uncover how each part of the brain contributes to recognizing what we see.
Evidence
🧠 Evidence from Brain-Damaged Patients: How Object Recognition Can Break Down
Cognitive neuropsychologists have studied patients with different types of brain damage to understand how object recognition happens in the brain. These studies support the idea that recognition involves multiple stages — and damage at each stage can lead to different types of visual agnosia.
🔹 1. Problems with Edge Grouping & Form Perception
Patient DF (Milner et al., 1991):
Could recognize very few real objects, none from line drawings.
Struggled with judging patterns (e.g., grouped by shape or proximity).
Indicates a failure at the very early stage of processing edges and forms.
Patient SA (Riddoch et al., 2008):
Had form agnosia (couldn’t group contours/edges well).
Worse at early visual processing than others but better at recognizing familiar objects — possibly due to stronger top-down processes.
🔹 2. Problems with Integrating Features into a Whole
Integrative Agnosia: Can’t combine parts into a whole object.
Patient HJA (Humphreys & Riddoch, 1987):
Could draw objects from memory, but had trouble recognizing them.
Did fine when an object stood alone, but struggled when objects overlapped or were grouped.
Example: Could recognize a sausage on its own, but not when in a salad with other foods.
Did poorly when shapes were superimposed or occluded (Giersch et al., 2000).
Patient SM (Behrmann et al., 2006):
Could recognize simple parts.
Struggled when parts were rearranged, showing that identifying parts and understanding their spatial arrangement rely on separate brain mechanisms.
Comparison: SA vs. HJA (Riddoch et al., 2008)
Both had apperceptive agnosia, but with different strengths/weaknesses.
SA had better object recognition (with help from top-down processing), despite worse bottom-up visual skills.
🔹 3. Problems with Structural Descriptions and Semantic Access
Structural description = a mental blueprint of what an object looks like.
Object-decision tasks help test this:
Patients decide if an image is a real object or a made-up one.
Patient DJ (Fery & Morais, 2003):
Had associative agnosia.
Couldn’t recognize most common objects by sight (16% accuracy).
BUT: Did well when the objects were described verbally.
Did great on complex shape tasks (e.g., identifying altered animals).
Shows: DJ could see and process shapes, but couldn’t connect them to stored knowledge (semantic memory).
🔹 4. Problems with Semantic Memory
Some patients’ object recognition fails because of damaged semantic memory — their vision is fine, but they can’t access meaning.
Patient FB (Peru & Avesani, 2008):
Damaged right frontal and left posterior temporal lobes (after a skiing accident).
Couldn’t identify objects in drawings.
Verbal questions showed she couldn’t access perceptual features (what an object looks like).
But she could still describe what objects are used for.
Suggests partial semantic memory damage — not just access issues.
✅ Takeaways from the Evidence
Visual agnosia isn't just one condition — it's a collection of different disorders, each tied to a specific stage in object recognition.
Patients can struggle with:
Early edge and shape processing (like DF or SA).
Integrating parts into wholes (like HJA and SM).
Accessing object knowledge (like DJ).
Or they might have semantic memory damage itself (like FB).
These findings support Riddoch & Humphreys’ multi-stage model and show why the old apperceptive vs. associative split is too simple.
Evaluation
🧠 Evaluating the Hierarchical Model of Object Recognition
The hierarchical model by Riddoch and Humphreys (2001) is a very useful tool for understanding how object recognition can break down in people with visual agnosia. It maps out multiple stages — like grouping edges, forming shapes, and accessing meaning — and helps explain why different patients struggle at different points.
✅ Strengths of the Model
The model matches well with evidence from brain-damaged patients.
It’s a major improvement over the older, overly simple idea that agnosia is either "apperceptive" or "associative."
It helps explain specific types of deficits, like difficulty combining object parts or accessing object knowledge.
⚠ Limitations of the Model
Too Bottom-Up Focused
The model assumes object recognition mainly flows from lower to higher stages (bottom-up).
But research shows that top-down processes (like prior knowledge and expectations from the brain’s higher areas) can influence earlier processing.
Example: Bar et al. (2006) showed the orbitofrontal cortex becomes active even before recognition areas, suggesting that the brain can “guess” or predict what it’s seeing.
Too Neat and Linear
The model treats processing as a step-by-step sequence, but in reality, brain processing is often more interactive.
Later stages can feed back and affect earlier stages — it's more like a loop than a straight line.
Lacks Specific Detail
While it works well as a framework, it’s not a complete theory.
For instance, it says that each stage builds on the one before it — but how that happens, or what mechanisms are involved, isn’t clearly explained.
🧾 In Summary
The hierarchical model gives us a great starting point for understanding the different types of object-recognition problems in agnosia. But like many models in cognitive neuroscience, it needs to be updated to:
Include the role of top-down influences,
Reflect the interactive nature of brain processing,
And provide more detail on how the stages work together.
Face Recognition
👤 Face Recognition: Why It Deserves Special Attention
📌 Why study face recognition separately?
Everyday importance: Recognising faces is vital socially (e.g., avoiding awkward moments) and for survival (e.g., identifying friend or foe).
Different from object recognition: Faces are processed differently — more holistically than other objects.
Rich research base: Studies from psychology, neuroscience, and brain-damaged patients provide a deep understanding of how we recognise faces.
🧠 How Face Recognition Differs from Object Recognition
🔄 Holistic (Configural) Processing
We process faces as a whole rather than by their individual parts.
Facial features (like eyes or mouths) aren’t reliable on their own — they’re too similar between people or changeable.
📚 Key Evidence for Holistic Face Processing
1. 🔄 Inversion Effect
Faces are much harder to recognise when they’re upside-down.
This disruption is greater for faces than for other objects.
📖 Study: McKone (2004) showed accuracy drops more with inverted faces than with inverted objects.
2. 🧩 Part–Whole Effect
Face parts are remembered better when shown within a whole face.
📖 Study: Farah (1994) — People remembered facial features better in context (whole face), but this wasn’t true for houses.
Suggests faces are stored in memory holistically.
3. 🎭 Composite Effect
Two half faces are harder to recognise when aligned (vs. unaligned).
Alignment makes it harder to focus on just one half, showing automatic holistic processing.
📖 Study: Young et al. (1987)
This effect disappears with inverted faces or non-face objects.
📝 In Summary
Face recognition relies heavily on holistic processing.
There’s strong evidence that we process and store faces as unified wholes, not just as collections of parts.
These findings support the idea that face recognition is a special, distinct process, not fully explained by general object recognition theories.
Evaluation
✅ Evaluation of Evidence for Holistic Face Processing
✔ Strengths
Strong evidence from:
Part–whole effect: Better memory for face parts when seen in full-face context.
Composite effect: Difficulty in recognising aligned half-faces shows automatic holistic processing.
These effects do not occur with non-face objects — supporting the idea that face recognition is unique.
Together, these effects strongly support holistic/configural processing in face recognition.
⚠ Limitations
The inversion effect (faces are harder to recognise upside-down):
Suggests holistic processing is disrupted.
But it's indirect — doesn’t directly measure holistic processing like the other two.
❓ Is it just expertise?
Some argue that faces aren’t special — we’re just experts at processing them (Gauthier & Tarr, 2002).
Suggestion: Holistic processing could apply to any category (e.g., birds, cars) if someone has enough experience.
But most evidence does not support this view — faces still show stronger holistic effects than other expert-level objects.
Prosopagnosia
✅ Evaluation of Prosopagnosia as Evidence for Specialised Face Processing
✔ Strengths
Strong case for separate face/object systems:
Some prosopagnosics (e.g., Edward) have intact object recognition but severely impaired face recognition.
Others (e.g., CK, HH) show good face recognition but impaired object recognition.
This double dissociation supports the idea that face and object recognition rely on distinct processes and brain areas.
Holistic face processing deficit:
Edward’s inability to show an inversion effect (no difference between upright and inverted faces) implies lack of configural processing — a key part of normal face recognition.
Developmental vs. acquired forms:
Shows that face-recognition deficits can occur without brain damage (developmental), further supporting the idea that face processing is a specialised cognitive skill.
⚠ Limitations / Counterpoints
Face recognition may simply be harder:
It requires within-category discrimination (e.g., telling faces apart), while object recognition usually requires only category-level identification.
This could explain why faces are harder to recognise after brain damage — not necessarily that a distinct mechanism is involved.
Prosopagnosia is heterogeneous:
Not all cases fit neatly into the double dissociation.
Some prosopagnosics have mild object-recognition deficits as well, which can muddy the distinction.
❗ Covert Recognition
Even when conscious recognition is impaired, covert face recognition can still occur (e.g., priming studies) — suggesting some unconscious face-processing pathways are preserved.
Fusiform face area
Fusiform Face Area (FFA) and Face Specialisation in the Brain:
Key Findings on the Fusiform Face Area (FFA):
Location & Role: The FFA, located in the lateral fusiform gyrus, is a critical brain region for face processing. Studies show that this area responds more strongly to faces than to other types of objects (Kanwisher & Yovel, 2006).
Brain Imaging Evidence: Brain imaging studies (e.g., Downing et al., 2006) show that the FFA consistently activates more to faces than to objects such as tools, fruits, and even scenes. This is also observed in non-human primates (Tsao et al., 2006).
Prosopagnosia: Damage to the FFA is linked to acquired prosopagnosia, where patients have difficulty recognising faces but often retain the ability to recognise objects (Barton et al., 2002).
Critiques & Limitations of the FFA:
FFA is Not Exclusive to Faces: The FFA is involved in face processing, but it's not the only region involved. Areas like the occipital face area and the superior temporal sulcus also play roles, especially in processing dynamic or changeable features of faces, such as expressions.
Example: A prosopagnosic patient (PS) showed intact FFA but damage to the occipital face area, affecting face recognition (Rossion et al., 2003).
Complexity of the FFA: The FFA is more complex than initially thought. Grill-Spector et al. (2006) found that while FFA shows more selective activation to faces than objects like animals and cars, the differences are not dramatic. They argue that the FFA may not be a uniform, face-specific region as previously assumed.
Theoretical Debate – Expertise Hypothesis:
Gauthier and Tarr’s Expertise Hypothesis (2002) suggests that the FFA’s activation in response to faces might not be special to faces per se but due to expertise. This theory posits that any object category for which an individual has extensive expertise could engage the FFA similarly to faces.
Predictions from this theory:
Holistic processing should be observed for any category with expertise, not just faces.
The FFA should activate when experts recognise objects of their expertise, not just faces.
Prosopagnosics might also struggle with object categories for which they have expertise.
Evidence Supporting the Expertise Hypothesis:
Holistic Processing in Greebles: Gauthier and Tarr (2002) showed that with practice, participants’ expertise in recognising Greebles (artificial objects) led to a progressive increase in sensitivity to their configural features, similar to the holistic processing seen for faces.
FFA Activation with Expertise:
Studies show that the FFA is activated when experts recognise objects from their area of expertise (e.g., cars for car experts, birds for bird experts) (Gauthier et al., 2000).
However, McKone et al. (2007) found that these expertise effects on FFA activation were small and inconsistent across studies.
Challenges to the Expertise Hypothesis:
Mixed Findings: Not all studies found strong evidence for expertise-related FFA activation. Some studies reported non-significant or smaller effects of expertise on the FFA compared to other brain regions (McKone et al., 2007).
Prosopagnosics with Object Expertise: The hypothesis predicts that prosopagnosics would have impaired recognition of non-face objects they are experts in, but this isn’t always the case.
For example, RM, a prosopagnosic with expertise in cars, recognised car models better than controls (Sergent & Signoret, 1992). Similarly, WJ, another prosopagnosic, could recognise individual sheep with the same accuracy as healthy individuals despite their face-recognition deficits.
Conclusion:
The FFA is crucial for face processing, but it is not unique to faces. It is involved in expertise-related recognition of any category. The debate continues, with some researchers arguing that expertise explains FFA activation rather than face-specific processing. The relationship between expertise, the FFA, and holistic processing remains an area of active research.
Evaluation
Evaluation of the Expertise Theory in Face Recognition
The expertise theory, proposed by Gauthier and Tarr (2002), suggests that face processing is not unique but rather a product of expertise, meaning that any object category for which we have extensive experience should activate similar brain areas and processing mechanisms, such as the fusiform face area (FFA) and configural processing. However, recent evaluations of this theory have provided several challenges:
Key Issues with the Expertise Theory:
Lack of Consistent Evidence for Expertise Effects:
The hypothesis that objects for which we possess expertise would show the same effects as faces (i.e., configural processing, FFA activation, and impaired recognition in prosopagnosics) has not been consistently supported. Studies have failed to show that non-face objects of expertise demonstrate the same brain activation patterns or processing strategies that are associated with faces (McKone et al., 2007).
For example, experts on cars or birds do not consistently show the inversion effect or composite effect—hallmarks of holistic or configural processing—which are observed with faces. This suggests that expertise does not lead to the same processing style for objects as it does for faces.
Failure to Show Expertise-Based Impairment in Prosopagnosics:
According to the theory, prosopagnosics should exhibit impaired recognition of objects for which they have expertise. However, findings are mixed and often contradictory.
In cases like RM, a prosopagnosic with expertise in cars, he demonstrated superior recognition of car models compared to controls (Sergent & Signoret, 1992). Similarly, other prosopagnosics have shown intact recognition of objects within their area of expertise, such as individual sheep in the case of WJ.
These findings challenge the theory’s prediction that prosopagnosics would be impaired in recognizing objects of expertise, reinforcing the idea that face processing may be distinct from processing other objects, even when expertise is involved.
Faces as Special:
The evidence suggests that faces have unique characteristics that set them apart from other objects, regardless of expertise. Faces seem to involve distinct brain areas (e.g., the FFA) and processes (e.g., holistic processing) that are not equally applied to other objects, even when an individual has significant expertise in those objects.
Additionally, the inversion effect, part–whole effect, and composite effect are found primarily with faces, not with objects of expertise, further supporting the notion that face processing is special and distinct.
Conclusion:
While the expertise theory proposes that the processing of faces and objects is similar due to expertise, the evidence does not consistently support this claim. Faces are processed differently from other objects, showing unique processing effects, and the FFA appears to be specialized for face recognition rather than being merely a general expertise area. Therefore, it is likely that face recognition involves specialized mechanisms that are not simply a result of expertise, and faces retain unique processing characteristics that set them apart from other objects.
Models of face recognition
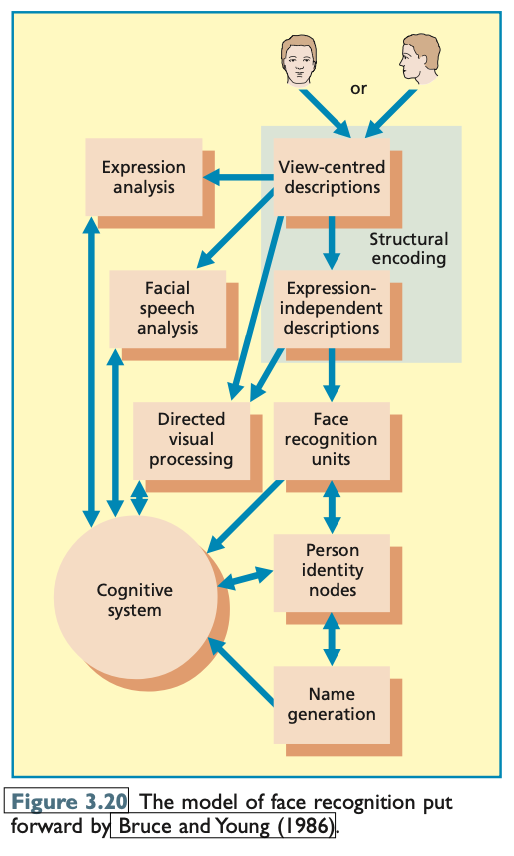
Models of Face Recognition: Bruce and Young (1986)
The Bruce and Young model (1986) is one of the most influential theories of face recognition and has contributed significantly to the development of subsequent models. It emphasizes the complexity of face processing and the variety of information we extract from faces, involving multiple distinct components that work together to recognize and interpret faces.
Key Components of the Bruce and Young Model (1986):
Structural Encoding:
This component processes basic structural features of faces, creating descriptions or representations of the face’s physical features (e.g., the distance between eyes, shape of the nose, etc.).
Expression Analysis:
This module is responsible for interpreting facial expressions, allowing us to infer emotional states (e.g., happiness, anger, surprise) from someone’s face.
Facial Speech Analysis:
This component aids in speech perception by observing lip movements, commonly known as lip-reading, which helps us understand speech in noisy environments or when auditory input is limited.
Directed Visual Processing:
This involves the selective processing of specific facial information, allowing us to focus on relevant features depending on the context (e.g., focusing on eyes to detect emotional expressions).
Face Recognition Units:
These contain structural information about known faces. When we encounter a familiar face, these units help match it to the mental representations stored in memory.
Person Identity Nodes:
This component provides personal information about the individual, such as their occupation, interests, and other details beyond facial features.
Name Generation:
This stores a person's name separately and helps retrieve the name when a familiar face is recognized.
Cognitive System:
The cognitive system contains background knowledge that influences face recognition. For example, knowing that most actors have "attractive faces" can guide processing by influencing which components of the system are attended to.
Predictions and Implications of the Model:
Differences in Processing Familiar vs. Unfamiliar Faces:
For familiar faces, recognition involves multiple stages: structural encoding, face recognition units, person identity nodes, and name generation. Familiar faces trigger a more elaborate process because they access a broader range of information.
For unfamiliar faces, recognition is less complex and mainly involves structural encoding, expression analysis, facial speech analysis, and directed visual processing.
Separate Processing Routes for Identity and Expression:
The model predicts that the recognition of facial identity (who the person is) and facial expression (what the person is feeling) are processed by separate routes. The expression analysis module is key for processing emotional expressions, while the identity route focuses on recognizing the person’s face.
Speed of Recognition:
The model suggests that recognition of familiarity (who the person is) should be faster than recognizing person identity nodes (personal details like occupation), and recognition of the person’s name should be the slowest step in the sequence. This reflects the hierarchical nature of information processing, where initial recognition happens quickly (familiarity), and deeper, more detailed information takes longer to process (identity and name).
Modifications to the Bruce and Young Model:
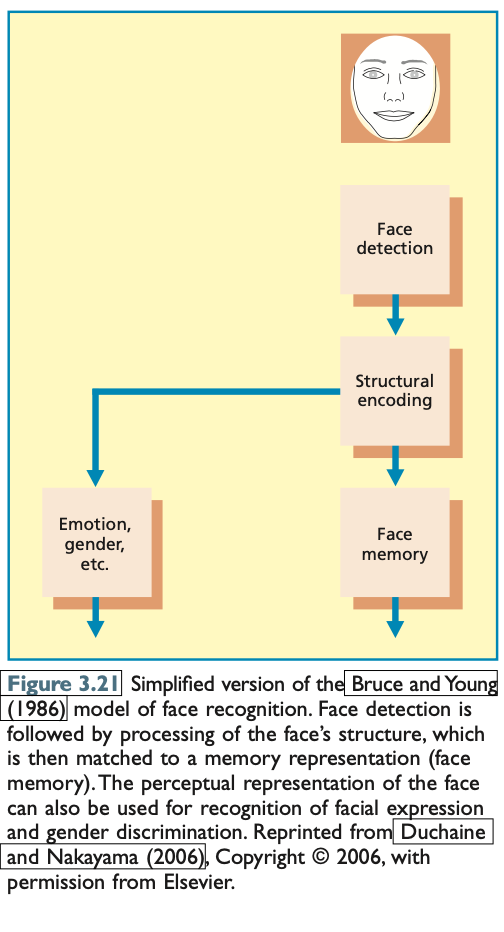
Duchaine and Nakayama (2006) proposed a modified version of the Bruce and Young model, adding a face detection stage as an initial step in face processing. This modification recognizes that, before recognizing someone’s identity or emotional state, individuals must first identify whether the stimulus is a face. This modification is important because even individuals with prosopagnosia (face blindness) can detect faces, although they may struggle with recognizing or processing their identity. Duchaine's study on a prosopagnosic patient named Edward showed that he could detect faces as quickly as healthy controls, even though his recognition of face identity was severely impaired.
Conclusion:
The Bruce and Young (1986) model remains one of the most influential and comprehensive theories in the field of face recognition. Its multi-component structure emphasizes the complexity and specialization of facial processing, considering both identity and expression recognition as distinct processes. The model has influenced many subsequent models, and the Duchaine and Nakayama modification adds an important layer by highlighting the initial step of face detection, which is essential even for individuals with face recognition impairments.
Evidence
Evidence Supporting the Bruce and Young Model (1986)
The Bruce and Young (1986) model, which posits that facial identity and expression are processed separately in the brain, has been supported by a range of findings. The model predicts distinct processing routes for recognizing familiar and unfamiliar faces, as well as for recognizing facial identity and expression. Below is a summary of key evidence that supports various aspects of the model.
1. Double Dissociation for Familiar vs. Unfamiliar Faces
The model suggests that the recognition of familiar faces (those associated with known information, like name and occupation) involves different processes from the recognition of unfamiliar faces (those that lack such information). The double dissociation between recognition of familiar and unfamiliar faces has been found in some studies:
Malone et al. (1982) observed a patient who recognized 82% of famous statesmen’s photographs but was poor at matching unfamiliar faces. In contrast, a second patient was able to match unfamiliar faces well but recognized only 23% of famous faces.
Young et al. (1993) conducted a study with 34 brain-damaged individuals and found weaker evidence for a selective impairment of either familiar or unfamiliar face recognition. While the evidence was less clear, the study did suggest some variability in the processing of these two types of faces.
These findings support the idea that separate processes might exist for familiar and unfamiliar face recognition, though further research is required to confirm this dissociation.
2. Dissociation Between Facial Identity and Expression
The model predicts that facial identity and expression are processed along separate routes in the brain. This prediction has been supported by findings of double dissociation:
Young et al. (1993) found that some patients showed good face recognition ability but struggled with identifying facial expressions, while others were good at recognizing facial expressions but had difficulty with face recognition.
Humphreys et al. (2007) reported that individuals with developmental prosopagnosia (face blindness) had poor face recognition but were able to recognize facial expressions, including subtle ones, just as well as healthy individuals. This supports the idea that face identity and expression are processed by separate mechanisms.
These studies provide compelling evidence that identity recognition and expression recognition rely on different cognitive and neural systems.
3. Brain Regions Involved in Facial Identity and Expression
The Haxby et al. (2000) model posits that facial identity is processed in the fusiform face area (FFA), whereas facial expression is processed in the superior temporal sulcus (STS). Evidence from functional imaging studies supports this distinction:
Winston et al. (2003) found that activation in the FFA increased when facial identity was repeated across different face pairs, whereas activation in the STS increased when facial expressions were repeated. This suggests that these brain areas are involved in distinct aspects of face processing, aligning with the predictions of the Bruce and Young model.
4. Effects of Facial Expression on Processing of Facial Identity
A key test of the separation of facial identity and expression processing involves the use of composite faces. Calder et al. (2000) constructed stimuli where the top and bottom halves of faces came from different individuals, varying in either facial identity or facial expression. The participants were asked to identify the facial expression or identity of the bottom half of the composite face.
The results supported the prediction that decisions about facial expression were slower when the expression differed between the top and bottom halves but were unaffected by differences in facial identity. Similarly, identity decisions were unaffected by differences in facial expression, supporting the idea that facial identity and expression are processed separately.
5. Familiarity and Name Generation
The Bruce and Young model suggests that name generation can only occur after information about the person’s identity (e.g., occupation) has been accessed, reflecting a hierarchical order of recognition processes:
Young et al. (1986) found that the decision to classify a face as familiar was made faster than decisions based on a person’s occupation, and categorizing familiar faces by occupation was faster than naming them. This supports the model's predictions about the sequence and speed of recognition processes.
Young et al. (1985) collected diary records of people’s experiences with face recognition problems, and people never reported putting a name to a face without also having additional personal information. This finding aligns with the model's assumption that name generation relies on access to person identity nodes.
6. Implications for Famous and Familiar Faces
Brédart et al. (2005) examined the speed of recognition for familiar colleagues' names versus personal information (e.g., educational level). Their findings indicated that naming close colleagues was faster than categorizing them by occupation, which contradicts the predictions for famous faces. This discrepancy is likely due to the frequency of exposure to colleagues' names and the closer familiarity, which highlights the importance of personal exposure frequency in recognition speed.
Conclusion
The Bruce and Young (1986) model remains one of the most influential and comprehensive frameworks for understanding face recognition. The evidence reviewed supports many of its key predictions, such as the separate processing routes for facial identity and expression, the hierarchical structure of face recognition processes, and the differential processing of familiar and unfamiliar faces. While some findings (e.g., with famous faces) suggest the influence of familiarity and exposure frequency, overall, the evidence strongly supports the model’s distinction between different types of face processing.
Evaluation
Evaluation of the Bruce and Young (1986) Model
The Bruce and Young (1986) model has indeed been highly influential in the field of face recognition. However, like any model, it is not without its limitations. Below is an evaluation of the model, highlighting both its strengths and areas where it may fall short.
Strengths of the Model:
Comprehensive Framework for Face Information Processing: The model identifies a wide range of information that can be extracted from faces, including both facial identity and emotional expression. It also distinguishes between the processing of familiar and unfamiliar faces, acknowledging that different cognitive systems are involved in these processes.
Empirical Support for Separate Processing Routes: The model's assumption that facial identity and facial expression are processed separately has received strong empirical backing. Research on prosopagnosics (individuals with face blindness) has shown that some individuals can recognize facial expressions without recognizing identity, and vice versa, suggesting that the two processes are not entirely dependent on each other.
Clear Differentiation of Familiar vs. Unfamiliar Faces: The model successfully predicts that the recognition of familiar faces follows a specific sequence (familiarity information → personal information → name), which is faster for familiar faces than for unfamiliar ones. This prediction aligns with experimental findings that have shown faster recognition of familiar faces compared to unfamiliar ones.
Limitations of the Model:
Omission of Initial Face Detection Stage: One of the main limitations of the Bruce and Young model is that it does not include the initial stage of face detection. Duchaine and Nakayama (2006) argue that recognizing a stimulus as a face is a crucial first step, which is not accounted for in the model. This omission makes the model overly simplified, as it jumps directly to face-specific processing without considering the initial face recognition stage.
Over-Simplification of the Separation Between Identity and Expression Processing: While the model proposes separate processing routes for facial identity and expression, this assumption may be overly simplistic. Research, including findings by Calder & Young (2005), suggests that the processing of facial identity and expression is not entirely separate. Many prosopagnosics experience difficulties with both face recognition and facial expression recognition, indicating that these routes may not be as distinct as initially thought. The distinction could be more of a continuum than a rigid separation.
Complexities in Processing Facial Expressions: The model assumes a single system for processing facial expressions, but this may not be the case. Studies have shown that individuals with impairments in facial expression recognition sometimes struggle more with certain emotional categories (e.g., fear or disgust) than with others. This suggests that facial expression processing may involve distinct systems for different emotional expressions, and that the emotional systems play a greater role in expression recognition than the model originally suggested.
Rigid Sequence of Personal Information Processing: The model assumes a rigid sequence in which the processing of personal information (e.g., occupation) and the generation of a person’s name always occurs after the recognition of facial identity. However, this assumption has been challenged by studies like Brédart et al. (2005), which show that name recognition for familiar faces can occur independently of other personal information. The model’s assumption that name generation always follows the recognition of other personal information may be too restrictive, and a more flexible approach is needed to account for cases where names can be recognized directly from faces.
Alternatives and Improvements:
Several newer models have addressed these limitations and offer more flexibility:
Duchaine & Nakayama (2006) propose a modification to the Bruce and Young model by adding a face-detection stage as the first step in face recognition, which acknowledges the importance of detecting a stimulus as a face before further processing.
Burton, Bruce, and Hancock (1999) provide a more flexible model for name generation, which does not assume a strict sequential order but instead allows for contextual flexibility in how personal information is accessed. These models highlight the importance of experience and familiarity in recognizing faces and names.
Conclusion:
The Bruce and Young (1986) model has been foundational in our understanding of face recognition, offering valuable insights into the processing of facial identity, expression, and the distinction between familiar and unfamiliar faces. However, its simplifications—such as the omission of the initial face detection stage and the rigid distinction between identity and expression processing—limit its explanatory power. More recent models have introduced modifications that allow for a more flexible and nuanced understanding of face recognition, addressing some of these shortcomings. Nonetheless, Bruce and Young's model remains a highly influential and important framework in the study of face recognition.
Visual Imagery
Visual Imagery vs. Perception
In this section, we are exploring visual imagery, which occurs when we generate mental images of objects or scenes without actually perceiving them in the external environment. The experience of “seeing with the mind’s eye” (Kosslyn & Thompson, 2003) allows us to imagine objects or situations without directly looking at them, but how closely does imagery resemble actual perception?
The Relationship Between Imagery and Perception
Visual imagery and visual perception share some similarities, but there are important distinctions that prevent confusion between the two. One reason we don't confuse mental images with actual perceptions is that we typically know when we are imagining something, whereas perception involves real-time external stimuli. Additionally, imagery tends to lack the level of detail found in perception. Harvey (1986) showed that participants rated their mental images of faces as less sharp than photographs of the same faces, highlighting this difference.
Hallucinations and Their Relation to Imagery
While most people don't confuse imagery with perception, hallucinations provide an extreme case where individuals might experience images in the absence of external stimuli. Charles Bonnet syndrome, which occurs in people with eye diseases, involves vivid and detailed visual hallucinations. These hallucinations were found to activate the same brain areas involved in perception, including regions responsible for processing color and faces, reinforcing the idea that imagery and perception can involve similar neural mechanisms. However, hallucinations are rare and typically linked to specific medical conditions.
Kosslyn’s Perceptual Anticipation Theory
Kosslyn (1994, 2005) proposed Perceptual Anticipation Theory, suggesting that mental imagery and visual perception rely on similar mechanisms. According to this theory:
Visual images are like pictures or drawings—they represent objects and their spatial relationships in the same way that perception does.
Imagery and perception both involve the brain’s early visual cortex (BA17/V1 and BA18/V2). These regions are involved in processing visual information, whether from an external stimulus or from stored memory in the form of a mental image.
Visual buffer: Kosslyn introduced the idea of a "visual buffer," where both imagery and perception are processed. In perception, this buffer is activated by external stimuli, while in imagery, it depends on non-pictorial, propositional information stored in long-term memory (e.g., shapes in the inferior temporal lobe and spatial information in the parietal cortex).
The Propositional Theory of Pylyshyn
Pylyshyn (2002, 2003) offers an alternative to Kosslyn’s theory with the propositional theory, which suggests that mental imagery does not rely on pictorial representations but instead uses tacit knowledge. According to this theory:
Tacit knowledge refers to implicit, subconscious knowledge of how objects might appear in different situations.
Imagery tasks involve accessing this knowledge rather than creating pictorial mental images. This means that early visual cortex might not play a role in visual imagery, as Pylyshyn argues that the process does not rely on a depiction of objects.
Imagery and Perception Influence Each Other
Studies suggest that visual imagery and perception are closely linked, influencing each other in certain situations:
Facilitation: In an experiment by Pearson, Clifford, and Tong (2008), participants who had previously imagined or perceived a green or red grating were more likely to perceive the same grating during binocular rivalry (when two stimuli are shown to each eye). The likelihood of perceiving the grating was higher when the orientations of the perceived/imagined and actual gratings were similar.
Interference: Baddeley and Andrade (2000) found that performing a spatial tapping task (which engages the visual buffer) while rating visual imagery vividness interfered with imagery, reducing the vividness of mental images. This suggests that both imagery and spatial processing share the same neural resources.
Differences Between Imagery and Perception
Despite the similarities, there are important differences between visual imagery and perception:
Simplified Representations: Mental images are often simplified, lacking fine details found in perception. For example, when participants imagined cutting a cube across its equator, many mistakenly believed the resulting shape would be square, when in fact it would be a hexagon. This indicates that mental images often omit structural details.
Flexibility of Use: Slezak (1991, 1995) demonstrated that participants were not able to visualize rotated images as accurately as they could perceive them. This suggests that imagery lacks the flexibility and precision of perception, particularly when it comes to manipulating objects in space.
Neural Overlap Between Imagery and Perception
While imagery and perception share some brain areas, such as the early visual cortex (BA17 and BA18), the brain's activation patterns during these processes show important differences:
Kosslyn et al. (1999) used repetitive transcranial magnetic stimulation (rTMS) to impair early visual cortex (V1) and found that this disrupted performance on imagery tasks, showing that V1 is causally involved in imagery.
Ganis, Thompson, and Kosslyn (2004) found that visual imagery and perception activated overlapping brain regions, especially in the frontal and parietal lobes, which are involved in cognitive control. However, the brain areas activated by imagery formed a subset of those activated by perception, suggesting that while imagery shares many processes with perception, it does not engage all of them.
Neuropsychological Evidence
Brain damage can affect visual perception and imagery differently:
Impaired Perception, Intact Imagery: Some patients, like JB, experience severe visual perception deficits but retain intact imagery, suggesting that the brain mechanisms for perception and imagery are not identical. Kosslyn (1994) argued that object knowledge stored in the temporal lobe is crucial for imagery, and this information is more important for imagery than for perception.
Intact Imagery, Impaired Perception: On the other hand, some patients with Anton’s syndrome (blindness denial) have impaired visual perception but can generate vivid mental images, sometimes confusing them for actual perception. This suggests that imagery can persist even when perception is impaired.
Conclusion
In sum, while visual imagery and visual perception share common neural mechanisms, such as the activation of early visual cortex, they differ in several important ways. Imagery involves the mental construction of images from stored knowledge, while perception depends on external sensory stimuli. Moreover, imagery is often less detailed and flexible than perception, and brain damage can affect these processes differently. Despite these differences, the overlap in brain activation suggests that visual imagery and perception are more closely linked than previously thought.

Evaluation
Evaluation of Visual Imagery and Perception Theories
This section assesses the progress made in understanding the relationship between visual imagery and visual perception, evaluating Kosslyn’s Perceptual Anticipation Theory and contrasting it with Pylyshyn's Propositional Theory. The evaluation highlights both supporting evidence and ongoing challenges in this area of cognitive science.
Supporting Evidence for Kosslyn’s Theory
Facilitation and Interference: One of the key predictions of Kosslyn's theory is that when the content of imagery and perception is the same, the two should facilitate each other. Conversely, when the content differs, they should interfere with each other. This prediction has been supported by multiple studies, such as the one by Pearson, Clifford, and Tong (2008), where visual imagery and perception influenced each other during binocular rivalry.
Early Visual Cortex Activation: A significant finding supporting Kosslyn's theory is the consistent activation of early visual cortex (V1 and V2) during tasks that require high-resolution details in visual imagery. This finding is crucial because it aligns with Kosslyn's claim that imagery and perception both involve similar neural mechanisms, especially in the early visual cortex, a result that Pylyshyn's theory struggles to account for.
Challenges and Limitations
Dissociations Between Perception and Imagery: One of the main challenges for Kosslyn’s theory is the existence of patients with intact visual imagery but impaired visual perception. This dissociation, such as in cases like Anton’s syndrome (where patients have blindness but vivid imagery), raises questions about the degree to which the processes involved in imagery and perception overlap. From Kosslyn's perspective, this is puzzling because if the mechanisms for both were so similar, we would not expect such a dissociation.
Theoretical Gaps: Despite the support for Kosslyn’s theory, more work is needed to fully understand why dissociations occur between visual imagery and perception. In some cases, imagery remains intact even when perception is severely impaired, suggesting that the processes might not be as integrated as Kosslyn’s theory suggests. Moreover, the nature of the tacit knowledge involved in imagery, as proposed by Pylyshyn, still remains unclear and lacks a detailed explanation, which weakens its standing.
Imagery for Different Types of Information: The brain activation patterns for object shape imagery and spatial/movement imagery differ, suggesting that different brain regions are involved in these two types of imagery. This distinction raises the question of how these different forms of imagery are coordinated when they are often used together in everyday visualizations. The lack of a clear explanation for this coordination remains a significant gap in both theories.
Conclusion
Overall, the evidence largely supports Kosslyn’s theory in terms of the shared neural mechanisms involved in imagery and perception, especially in the activation of early visual cortex. However, the existence of dissociations between perception and imagery, particularly in brain-damaged patients, poses a significant challenge to the theory. Additionally, the complexities of coordinating different types of imagery (e.g., object shape vs. spatial relationships) remain underexplored. To further advance our understanding, researchers need to focus on clarifying these dissociations and exploring the neural coordination between different types of imagery.