Lecture 2 : time series analysis
What is time series data?
Time series data are observations collected from the same unit repeatedly over time (e.g., daily, monthly, yearly).
analyze patterns and dynamics over time
forecast future values
Yt,t=1,2,…,T
Y = wat je meet (het onderwerp / de variabele)
t = het tijdstip van de meting
T = het laatste tijdstip / totaal aantal metingen
For example, an inflation rate model has the form:
𝜋𝑡 = 𝛼 + 𝛽1𝜋𝑡−1 + ⋯ + 𝛽𝑝𝜋𝑡−𝑝 + 𝜖t

What makes time series different?
1. Observaties zijn ordered (time matters)
Je ziet maar één timepath:
{\left\lbrace Y1,Y2,...,YT\right\rbrace}
Bijv: GDP door de jaren heen.
Je kan de volgorde niet mixen → tijd bevat info.
2. Waarden beïnvloeden elkaar (dependence)
Het verleden beïnvloedt de toekomst:
Corr(Yt,Yt-1)\ne0
Wat vandaag gebeurt hangt samen met gisteren.
This violates classical Ordinary Least Square (OLS) independence assumption:
OLS gaat uit van onafhankelijke fouten:
E(\varepsilon t\varepsilon s)=0(t\ne s)
Maar in time series zijn fouten vaak wel afhankelijk → assumptie stuk.
Waarom is OLS niet genoeg in time series?
1⃣ Probleem: Serial correlation
Corr(\varepsilon t,\varepsilon t-1)\ne0
Dit betekent:
De fout van vandaag hangt samen met de fout van gisteren.
In gewone taal:
Fouten “clusteren” in de tijd.
Bijvoorbeeld:
Vandaag beurscrash → morgen nog steeds hoge volatiliteit.
Vandaag onverwacht hoge inflatie → morgen vaak ook hoger.
Dus errors zijn niet onafhankelijk.
2⃣ Wat OLS aanneemt
OLS veronderstelt:
Errors zijn independent
Geen serial correlation
Dus OLS denkt:
Elke fout is puur random en heeft niets met vorige fouten te maken.
Maar in time series klopt dat meestal niet ❌
3⃣ Wat gebeurt er dan?
🔴 Gevolg 1: Biased standard errors
Coëfficiënten kunnen nog ok zijn
Maar standaardfouten zijn fout
t-statistieken en p-values zijn onbetrouwbaar
Je denkt dat iets significant is, terwijl dat misschien niet zo is.
🔴 Gevolg 2: Spurious regression
Je vindt een sterke relatie die eigenlijk niet echt bestaat.
Twee variabelen met trend kunnen “significant” lijken,
maar het is gewoon gedeelde tijdsdynamiek.
📌 Wat is stationarity?
Een tijdreeks {Yt}\{Y_t\}{Yt} is (weakly) stationary als haar gedrag niet verandert over de tijd.
Dat betekent 3 dingen 👇
1⃣ Het gemiddelde verandert niet
E(Yt)=μ
Dit betekent:
Het gemiddelde is constant door de tijd.
Dus geen stijgende trend of dalende trend.
Bijvoorbeeld:
Inflatie die altijd rond 2% schommelt → kan stationary zijn.
Inflatie die elk jaar stijgt → niet stationary.
2⃣ De variantie verandert niet
Var(Yt)=\sigma2
Dit betekent:
De spreiding blijft constant.
Dus geen toenemende volatiliteit.
Bijvoorbeeld:
Als schommelingen steeds groter worden → niet stationary.
3⃣ De autocovariantie hangt alleen af van afstand (lag)
Cov(Yt,Yt−k)=ρk
Dit betekent:
De relatie tussen vandaag en k periodes geleden hangt alleen af van k, niet van t.
Dus:
Correlatie tussen 2024 en 2023 = correlatie tussen 2010 en 2009 (als k=1)
🎯 In gewone taal
Een tijdreeks is stationary als:
Het gemiddelde niet verschuift
De variatie niet verandert
De afhankelijkheid niet verandert (covariance)
📌 Stationarity vs. Non-stationarity
✅ Stationary
Een tijdreeks is stationary als:
Gemiddelde constant blijft
Variantie constant blijft
Covariance niet verandert door de tijd
👉 De statistische eigenschappen blijven stabiel.
Waarom belangrijk?
Omdat de meeste time-series modellen dit veronderstellen.
Dan kloppen je standaardfouten en t-statistieken.
❌ Non-stationary (wat te doen)
❖ Step 1: Diagnose the type of non-stationarity
Een reeks is non-stationary als:
Er een trend in zit (deterministic trend)
Er een unit root is
Structural break
❖ Step 2: Transform to stationary series
📈 Case 1 : Derterminisic Wat betekent de formule?
Yt=β0+β1t+ut,ut∼stationary
Dit betekent:
De tijdreeks bestaat uit een trend + ruis (noise).
Opsplitsen:

Dus:
👉 Data stijgt door de tijd op een voorspelbare manier.
Voorbeeld:
CO₂-uitstoot
GDP
bevolking
🔴 Waarom is dit non-stationary?
Omdat het gemiddelde stijgt door de tijd:
E(Yt)=β0+β1t
Het gemiddelde hangt dus af van t → niet constant → niet stationair.
Belangrijk:
Variantie blijft constant ✔
Maar gemiddelde verandert ❌
Dus: non-stationary.
⭐ Deterministic trend = voorspelbare trend
De trend is deterministisch omdat hij volledig bepaald wordt door tijd (t).
Geen random groei — gewoon een rechte lijn.
🛠 Oplossing: detrending
Hoe maak je de reeks stationair?
1⃣ Regress (Yt) op tijd (t)
2⃣ Neem de residuals (ut)
Die residuals zijn stationair 🎉
🎯 In één zin
Deterministic trend = een tijdreeks die non-stationary is omdat het gemiddelde lineair stijgt in de tijd; maak hem stationair door de trend te verwijderen.
Case 2 : unit root Wat betekent de formule?
Yt=Yt−1+εt
Dit zegt:
De waarde vandaag = waarde gisteren + random shock.
Dus de reeks stapt elke periode random verder → random walk.
Voorbeeld:
aandelenprijzen
wisselkoersen
crypto
🔴 Waarom is dit non-stationary?
1⃣ Gemiddelde hangt af van startpunt
De reeks “drijft” weg afhankelijk van waar je begon.
Geen vast gemiddelde ❌
2⃣ Variantie groeit door de tijd
De onzekerheid stapelt zich op.
Hoe langer in de toekomst → hoe onvoorspelbaarder.
Dus spreiding wordt groter ❌
3⃣ Shocks zijn permanent 💥
Dit is het belangrijkste verschil met trend!
Bij random walk:
Een schok verdwijnt nooit.
Als aandelen vandaag +5% onverwacht stijgen, blijft dat effect voor altijd in het niveau zitten.
Deterministic trend | Random walk |
|---|---|
Trend is voorspelbaar | Pad is random |
Shock tijdelijk | Shock permanent |
Detrending helpt | Differencing nodig |
🛠 Oplossing: First difference
We nemen verandering i.p.v. niveau:
ΔYt=Yt−Yt−1
Invullen in model:
ΔYt=εt
In één zin
Random walk is non-stationary omdat shocks permanent zijn; maak de reeks stationair door first differencing.
Case 3: Structural break
Wat zegt de formule?
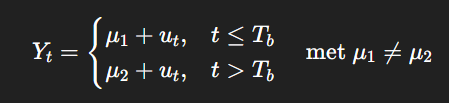
Dit betekent:
De tijdreeks verandert plots op één moment TbT_bTb.
Voor en na dat moment heeft de reeks een ander gemiddelde.
Voorbeeld:
COVID → economie verandert plots
Nieuwe wetgeving
Financiële crisis
Oorlog
De wereld verandert → de data ook.
📉 Waarom is dit non-stationary?
Omdat het gemiddelde niet constant is door de tijd:
Voor Tb: gemiddelde = μ1
Na Tb: gemiddelde = μ2
Er zit dus een sprong (break) in de reeks.
Dit noemen we:
👉 Regime shift
🛠 Oplossing: Break dummy
We voegen een dummy variabele toe:
Yt=β0+β1Dt+ut
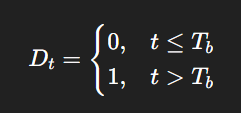
De dummy “zet” het model op een nieuw niveau na de breuk.
🎯 In één zin
Structural break = de tijdreeks krijgt plots een ander gemiddelde; maak het stationair door een break dummy toe te voegen
3. ARMA models
Zelfs nadat je de reeks stationair hebt gemaakt…
➡ Betekent dat niet dat observaties onafhankelijk zijn.
We hebben nog steeds:
Corr(Yt,Yt-1)niet0
Dus:
De reeks heeft nog geheugen
Het verleden beïnvloedt de toekomst
Voorbeelden:
Inflatie
Aandelenrendementen
GDP-groei
Allemaal stationair, maar nog steeds afhankelijk door de tijd.
Waarom hebben we een model nodig?
Omdat we de dynamiek in de tijd willen beschrijven.
We willen wiskundig modelleren:
Hoe sterk beïnvloedt het verleden de toekomst?
Oplossing: AR/MA modellen
Deze modellen beschrijven de autocorrelatie in de data.
AR (AutoRegressive) → afhankelijk van eigen verleden
MA (Moving Average) → afhankelijk van vroegere shocks
Dit gaat over de intuïtie van een AR(1) model — de simpelste dynamische time-series 😊
De formule:
Yt=ϕYt−1+εt
betekent:
De waarde vandaag hangt af van de waarde gisteren + een shock.
Dus de reeks heeft geheugen.
🔎 Wat betekent φ (phi)?
φ meet hoe sterk het verleden blijft doorwerken.
🔹 φ = 0.1 → weak persistence
Kleine invloed van gisteren.
Effect van een shock verdwijnt snel.
Reeks “vergeet” het verleden snel.
👉 korte geheugen.
🔹 φ = 0.8 → strong persistence
Grote invloed van gisteren.
Shock werkt lang door.
Reeks beweegt langzaam terug naar gemiddelde.
👉 lang geheugen.
🔹 φ = 1 → random walk (unit root)
Yt=Yt−1+εt
Nu verandert alles:
Shock verdwijnt nooit ❌
Effect blijft permanent.
Reeks is niet stationair.
👉 geen terugkeer naar gemiddelde.
🎯 In één zin
In AR(1) bepaalt φ hoe lang het verleden blijft doorwerken: klein φ = snel vergeten, φ dicht bij 1 = zeer persistent, φ = 1 = random walk.

Wat is een MA(q) model?
Formule:
Yt=μ+εt+θ1εt−1+⋯+θqεt−q
Betekenis:
De waarde vandaag hangt af van huidige en vorige shocks (fouten).
Dus niet van vorige Y’s, maar van vorige ε’s.
⭐ MA(1) voorbeeld
Yt=μ+εt+θεt−1
Vandaag =
gemiddelde +
shock vandaag +
deel van shock gisteren
💡 Intuïtie
Een schok heeft tijdelijk effect.
Bijv:
Slecht economisch nieuws vandaag → effect morgen nog voelbaar
Maar na een tijdje verdwijnt het effect
Dit heet:
👉 finite memory
Na q periodes is het effect weg.
📌 Belangrijke eigenschappen
MA(q) is altijd stationair ✅
Shock effect verdwijnt na q periodes
Voor MA(1): ∣𝜃∣<1
⚖ Verschil AR vs MA (super belangrijk)
AR(p) | MA(q) |
|---|---|
Afhankelijk van vorige waarden Yt−1 | Afhankelijk van vorige shocks εt−1 |
Oneindig geheugen | Eindig geheugen |
Stationarity hangt af van φ | Altijd stationair |
🎯 In één zin
MA(q): vandaag hangt af van huidige en vorige shocks; schokken verdwijnen na q periodes.
Wat is ARMA(p,q)?
Yt=α+i=1∑pϕiYt−i+εt+j=1∑qθjεt−j
In woorden:
ARMA combineert AR + MA.
Dus vandaag hangt af van:
vorige waarden (AR-deel)
vorige shocks (MA-deel)
🧠 Intuïtie
AR(p) → geheugen van vorige Y’s
MA(q) → geheugen van vorige shocks
ARMA gebruikt beide soorten geheugen tegelijk.
❓ Wat vraagt de slide nu?
Nu de reeks stationair is en we weten dat ARMA nodig is, komen de praktische vragen:
1⃣ Hoe kies je p en q?
Gebruik ACF & PACF:
PACF → helpt AR-orde (p) kiezen
ACF → helpt MA-orde (q) kiezen
2⃣ Hoe schatten?
Gebruik Maximum Likelihood (software doet dit).
We schatten:
φ-coëfficiënten
θ-coëfficiënten
α
3⃣ Hoe check je residuals?
Heel belangrijk 🔍
Residuals moeten white noise zijn:
geen serial correlation
constant variance
geen patroon
Als niet → model aanpassen.
4⃣ Hoe forecasten?
Als residuals white noise zijn → model is goed.
Dan kan je:
Y^{^{^1}}+Y^{^{t+2}}+\cdots
voorspellen.
🎯 In één zin
ARMA combineert AR en MA om stationaire tijdreeksen te modelleren; daarna kies je p en q, schat je het model, controleer je residuals en maak je forecasts.
📌 MA(q) – Moving Average model
🔎 Definitie
Yt=μ+εt+θ1εt−1+⋯+θqεt−q
Betekenis:
Vandaag hangt af van huidige en vorige shocks (errors).
Dus:
Niet van vorige YYY’s
Maar van vorige ε’s
⭐ MA(1) voorbeeld
Yt=μ+εt+θεt−1
Vandaag =
gemiddelde
shock vandaag
deel van shock gisteren
Een schok werkt dus nog 1 periode door.
🔑 Belangrijkste eigenschappen
✅ Altijd stationair
MA(q) is automatisch stationair.
Geen unit root probleem.🧠 Finite memory
Een shock werkt maar q periodes door.
Na q periodes:
Effect = 0
Dus:
MA heeft eindig geheugen
Schokken verdwijnen volledig
🔒 Invertibility (voor MA(1))
∣θ∣<1
Anders kan het model niet uniek worden geschat.
(Technisch punt, vooral belangrijk voor theorie/examen.)
⚖ Verschil met AR
AR(p) | MA(q) |
|---|---|
Afhankelijk van vorige Y’s | Afhankelijk van vorige shocks |
Oneindig geheugen | Eindig geheugen |
Stationair als φ goed is | Altijd stationair |
🎯 Intuïtie in één zin
MA(q): Vandaag is een combinatie van recente shocks; schokken verdwijnen na q periodes.
📊 ACF vs PACF
🔹 ACF (Autocorrelation Function)
ρk=Corr(Yt,Yt−k)
Meet:
Totale correlatie met het verleden.
Dus: hoeveel hangt vandaag samen met lag 1, lag 2, lag 3, …
🔹 PACF (Partial ACF)
Meet:
Directe correlatie met lag k
na verwijderen van tussenliggende lags.

📌 Wanneer is een spike significant?
In ACF/PACF plot:
\pm\frac{2}{\sqrt{T}}
Spikes buiten deze band = significant.
🎯 Hoe herken je AR vs MA?
Dit moet je echt onthouden 👇
Model | ACF | PACF |
|---|---|---|
AR(1) | Exponential decay | Cuts off after lag 1 |
MA(1) | Cuts off after lag 1 | Exponential decay |
AR(p) | Gradual decay | Cuts off after p |
MA(q) | Cuts off after q | Gradual decay |
🧠 Intuïtie truc (exam hack)
PACF → AR kiezen
ACF → MA kiezen
Dus:
👉 PACF cutoff → AR model
👉 ACF cutoff → MA model
⭐ In één zin
ACF en PACF helpen de orde van AR en MA te kiezen: PACF bepaalt p, ACF bepaalt q.
📌 Waarom hebben we dit nodig?
Met ACF/PACF krijg je een idee van p en q,
maar vaak zijn er meerdere mogelijke modellen.
Dus we moeten modellen objectief vergelijken.
📊 Information Criteria
AIC
AIC=−2logL+2k
BIC
BIC=−2logL+klogT
🔎 Wat betekenen de symbolen?
L = likelihood → hoe goed model data fit
k= aantal parameters → modelcomplexiteit
T = sample size
Dus beide criteria:
Belonen goede fit
Straffen te complexe modellen
⚖ Verschil AIC vs BIC
AIC → minder strenge penalty → kiest vaker groter model
BIC → strengere penalty → kiest simpeler model
Maar regel blijft:
Lager AIC/BIC = beter model
🧠 Hoe gebruik je dit praktisch?
1⃣ Schat meerdere modellen
AR(1), AR(2), MA(1), ARMA(1,1), …
2⃣ Vergelijk AIC/BIC
3⃣ Kies model met laagste waarde
Software doet dit automatisch.
🎯 In één zin
Kies p en q door modellen te vergelijken met AIC/BIC en neem het model met de laagste waarde.
📌 Model diagnostics (controle van je model)
Na het schatten van een ARMA-model kijk je naar de residuals (fouten).
👉 Die moeten zich gedragen als white noise.
Waarom?
Omdat een goed model alle structuur al heeft uitgelegd.
Wat overblijft = pure random noise.
🎯 Wat moeten residuals hebben?
Een goed model ⇒ residuals hebben:
1⃣ Gemiddelde ≈ 0
2⃣ Constante variantie
3⃣ Geen serial correlation
Kort: residuals = white noise.
🔎 Tool 1: Residual ACF
We plotten de ACF van residuals.
Wat wil je zien?
👉 Alle spikes binnen de confidence bands.
Als er spikes buiten zitten →
er zit nog structuur in data → model niet goed.
🧪 Tool 2: Ljung–Box test
Hypothese:
H0: H0: No serial correlation
Dus:
H₀ = residuals zijn white noise (goed model)
Interpretatie p-value
p-value | Conclusie |
|---|---|
> 0.05 | Model ok ✅ |
< 0.05 | Model fout ❌ |
Als H₀ wordt verworpen → model is mis-specified.
🧠 Intuïtie
Na modelleren vragen we:
Zit er nog patroon in de fouten?
Ja → model verbeteren
Nee → model klaar 🎉
🟢 In één zin
Een goed model heeft residuals die white noise zijn; check dit met residual ACF en de Ljung–Box test.
📌 Belangrijk inzicht
ACF/PACF en AIC/BIC helpen je,
maar geven geen perfect antwoord.
Echte macrodata (zoals inflatie) zijn complex → je moet iteratief werken.
🔁 Model selectie is een cyclus
Je herhaalt steeds:
Identification → Estimation → Diagnostics → Refinement
1⃣ Kies model (ACF/PACF, AIC/BIC)
2⃣ Schat model
3⃣ Check residuals
4⃣ Verbeter model
→ en opnieuw 🔁
Dit gebeurt vaak meerdere keren.
⚠ Veelgemaakte fouten
1⃣ Overfitting
Te hoge p en q kiezen.
Probleem:
Model past verleden perfect
Slechte voorspellingen in toekomst
2⃣ Structural breaks negeren
Economie verandert:
crises
pandemie
beleid
Als je dit negeert → model fout.
3⃣ Non-stationarity negeren
Niet-stationaire data → spurious regression.
Altijd eerst stationair maken!
🎯 Waar gaan we nu heen?
Nu je een goed model hebt:
👉 Hoe gebruiken we het om de toekomst te voorspellen?
Dat is de volgende stap: forecasting 📈
🧠 In één zin
ARMA modelleren is een iteratief proces; vermijd overfitting en non-stationarity, en gebruik het uiteindelijke model voor forecasting.
Wat is een forecast?
Y^{T}+h\vert T=E(YT+h\vert FT)
Dit ziet er moeilijk uit maar betekent gewoon:
Een forecast is de beste verwachting van de toekomst gegeven alle info die we nu hebben.
Wat betekenen de symbolen?
T = vandaag (laatste observatie)
h= hoeveel stappen vooruit (horizon)
FT= alle info die we nu kennen
E(⋅)= verwachting (gemiddelde)
Dus:
Y^{T}+1\vert T
= voorspelling voor morgen op basis van info vandaag.
🎯 Twee doelen van forecasting
1⃣ Point forecast
Één getal voorspellen.
Bijv:
Inflatie volgende maand = 2.3%
2⃣ Prediction interval
Een range geven met onzekerheid.
Bijv:
Inflatie volgende maand ligt waarschijnlijk tussen 1.8% en 2.8%
Omdat de toekomst onzeker is.
🧠 In één zin
Forecasting = de beste voorspelling van de toekomst gegeven alle info vandaag, met een puntvoorspelling en een onzekerheidsinterval.
Dit is de intuïtie van forecasting met AR(1) 😊 en eigenlijk heel logisch.
📌 AR(1) model
Yt=α+ϕYt−1+εt
🔮 1-step ahead forecast
Voorspelling voor morgen:
Y^T+1∣T=α+ϕYT
Wat doen we?
👉 Gewoon de laatste observatie invullen.
🔮 h-step ahead forecast (verder in toekomst)
Y^{T}+h\vert T=\mu+\phi h(YT-\mu)
met
\mu=\frac{\alpha}{1-\phi}
Dit is de lange-termijn gemiddelde waarde.
🧠 Intuïtie (super belangrijk!)
Als Als\vert𝜙\vert<1
ϕh→0als h→∞
Dus:
Y^T+h∣T→μ
👉 Op lange termijn keert de forecast terug naar het gemiddelde.
Dit heet mean reversion.
📈 Onzekerheid groeit
Hoe verder je voorspelt:
👉 Hoe groter de onzekerheid.
Prediction interval:
Y^T+h∣T±1.96SE
Verder in toekomst → grotere SE → bredere interval.
🎯 In één zin
In AR(1) gebruikt de forecast de laatste observatie; op lange termijn keert de voorspelling terug naar het gemiddelde en onzekerheid groeit met de horizon.
Dit is de laatste stap: checken hoe goed je voorspellingen zijn 📈
📌 Evaluating Forecast Performance
🔹 Twee manieren
1⃣ In-sample
Je test het model op dezelfde data waarop je het hebt geschat.
👉 makkelijk, maar kan misleidend zijn (overfitting).
2⃣ Out-of-sample (belangrijk!)
Data opsplitsen:
Train set → model schatten
Test set → voorspellen en vergelijken
Dit heet rolling forecast.
👉 Dit lijkt op echte forecasting in de praktijk.
🔎 Forecast error
eT+h=YT+h−Y^T+h∣T
= echte waarde − voorspelling.
📏 Hoe meten we accuracy?
RMSE (Root Mean Squared Error)
RMSE=\sqrt{\frac{1}{N}}∑e^2t
Straft grote fouten extra zwaar.
MAE (Mean Absolute Error)
MAE=MAE=\frac{1}{n}∑\vert et\vert
Gemiddelde foutgrootte.
🎯 Regel
Lagere RMSE / MAE = betere forecast
🧠 In één zin
Evalueer forecasts met out-of-sample fouten en kies het model met de laagste RMSE/MAE.
Dit is de praktische manier om forecasts te testen 😊
📌 Rolling window forecast
Dit bootst echte forecasting na.
🔁 Procedure (stap voor stap)
1⃣ Schat model op eerste deel van data
[1,…,T0]
2⃣ Maak voorspelling voor volgende periode
T0+1
3⃣ Voeg nieuwe observatie toe
→ schuif het venster vooruit (roll the window)
4⃣ Herhaal dit steeds opnieuw 🔁
Je maakt dus elke keer een nieuwe forecast alsof je in real time leeft.
⭐ Waarom doen we dit?
✔ Mimics real-time forecasting
In werkelijkheid ken je de toekomst niet.
Rolling window simuleert dat perfect.
✔ Vermijdt look-ahead bias
Je gebruikt nooit toekomstige info bij voorspellen.
Dus:
eerlijkere evaluatie van model.
🎯 In één zin
Rolling window forecasting maakt telkens nieuwe voorspellingen terwijl het model stap voor stap wordt geüpdatet, net zoals in de echte wereld.
Dit is de brug tussen time series en regressie voor forecasting 😊
📌 Predictive regression framework
Formule:
Rt+1=α+βXt+εt+1
Dit betekent:
We voorspellen rendement morgen met informatie van vandaag.
🔎 Wat betekenen de variabelen?
Rt+1 = return in de volgende periode
Xt = predictor vandaag (bv. dividend-price ratio)
β= voorspellende kracht van Xt
Dus:
Kan info vandaag toekomstige returns voorspellen?
⚠ Waarom zijn OLS t-statistieken problematisch?
1⃣ Overlapping observations → serial correlation
In finance overlappen returns vaak.
Gevolg:
Corr\left(\varepsilon t,\varepsilon t-1\right)\ne0
Errors zijn dus afhankelijk.
2⃣ Heteroskedasticity
Variantie van fouten verandert over tijd.
Bijv:
rustige periodes vs crisis periodes.
💥 Gevolg
OLS standaardfouten worden biased.
Dus:
t-statistieken onbetrouwbaar
significantie kan fout zijn
🎯 In één zin
Predictive regressions gebruiken OLS om returns te voorspellen, maar serial correlation en heteroskedasticity maken de standaard t-tests onbetrouwbaar.
Dit is hoe we het probleem van onbetrouwbare t-statistieken oplossen 👇
📌 Correction for t-statistics
🔧 Probleem recap
In predictive regressions hebben we:
Serial correlation
Heteroskedasticity
→ OLS standaardfouten kloppen niet.
🛠 Oplossing: Newey–West standaardfouten
Newey-West (1987) corrigeert de standaardfouten zodat ze robuust zijn voor:
veranderende variantie
serial correlation
Dus:
Betrouwbare t-statistieken ondanks time-series problemen.
🔁 Waarom ontstaat serial correlation hier?
Bij multi-year returns overlappen observaties.
Voorbeeld: 5-year returns
Return op tijd t gebruikt data:
t+1 tot t+5
Volgende observatie gebruikt:
t+2 tot t+6
👉 Ze delen dus data → errors worden automatisch gecorreleerd.
Dit heet overlapping observations.
💡 Belangrijk inzicht
Deze serial correlation ontstaat mechanisch
zelfs als het model perfect is!
Daarom moeten we standaardfouten corrigeren.
Hodrick (1992) bevestigt dit.
🎯 In één zin
Gebruik Newey-West standaardfouten om t-statistieken betrouwbaar te maken bij serial correlation en heteroskedasticity.
Dit is een heel belangrijke maatstaf in forecasting van returns 📈
📌 Out-of-sample R2R^2R2
We willen weten:
Voorspelt ons model beter dan gewoon het historische gemiddelde?
Het gemiddelde is namelijk een sterke benchmark in finance.
🔎 Formule (idee)
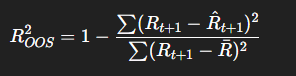
Vergelijking van twee modellen:
Teller → fouten van jouw model
Noemer → fouten van simpel gemiddelde model
🎯 Interpretatie
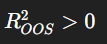
Model is beter dan gemiddelde ✅
👉 Je model voegt voorspellende waarde toe.
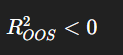
Model is slechter dan gemiddelde ❌
👉 Gewoon het gemiddelde gebruiken is beter.
Dit gebeurt vaak in finance 😅
⚠ Belangrijk inzicht
Statistische significantie ≠ goede forecast.
Een predictor kan:
significante t-stat hebben
maar toch nauwelijks beter voorspellen
In finance telt vaak de economische grootte.
🧠 In één zin
Out-of-sample R2R^2R2 meet of je model beter voorspelt dan het historische gemiddelde.