1b
Sorting
Briefly describe Bubble sort giving details about.
The main idea of Bubble Sort.
Answer: Start by comparing the first pair of elements and swap them if the first element is greater than the second (assuming ascending order). Repeat for all pairs in the list. Repeat this whole iteration n-1 times (or until the whole list is sorted by checking if no swaps were done in the current iteration (optimisation 1)). There is no need to check the elements that were already sorted in subsequent iterations so reduce the range by 1 in each iteration (optimisation 2). |
What is the largest number of swaps performed by Bubble Sort per item in the list?
Answer: It is n-1 swaps! 🙂 Feedback: Would be good to define what n actually is Alternate Answer: Yeap this is correct |
What is the best case and worst case complexity?
Answer: The overall complexity of Bubble sort 1 in both best and worst cases is O(n^2) The overall best-case complexity of Bubble sort 2 is O(n) and its worst case complexity is O(n^2) where n is the length of list. Feedback: Would be good to define what n actually is for Bubble Sort 1: The overall complexity of Bubble sort 1 in both best and worst cases is O(n^2), where n is the number of elements in the list |
Explain why the best and worst case are as stated. No explanation no marks.
Answer: Bubble sort 1 has two loops. The outer loop runs n-1 times and so does the inner loop (n is the length of the list). So the overall complexity in all cases comes out to be (n-1)^2 which is O(n^2). Bubble sort 2 also has two loops but there is a conditional break. If none of the numbers are swapped during a traversal, then the loop is stopped. The best case of O(n) occurs when the list is already sorted and it takes one traversal to make sure that the list is sorted. The worst case is when the list is sorted in the reverse order (both inner and outer loop will run n-1 times). So the worst case complexity is O(n^2). Alternative Answer #1 (more in depth)
|
What is the result of applying one iteration (list traversal) of Bubble Sort if one wants to sort the list in increasing order and starts from the left?
Example: [5, 20, -5, 10, 3]
Answer: [5,-5,10,3,20] |
Example: [-5, -20, -5, -10, 3]
Answer: [-20,-5,-10,-5,3] |
When does Bubble Sort stop? Describe at least one way to improve Bubble Sort.
Answer: Bubble sort 1 stops after n-1 iterations of the outer loop. Bubble sort 2 stops when none of the elements have been swapped in the last. Bubble sort 2 is the optimised version of bubble sort 1 where there is a conditional break if the list becomes sorted before n-1 traversals are over. |
What does it mean for a sorting algorithm to be incremental? Is BubbleSort incremental? Why and when?
Answer: An algorithm is said to be incremental if it does not need to recompute everything after a small change. For example: adding an element to a sorted list and sorting it again. If it only takes a few iterations, it would be called incremental. Bubble sort is incremental when the element is added to the front of the list because it will reach its correct position in the list in the first iteration. But if you add it to the end of the list, the number of iterations required would depend on the position of the element. (Include an example) Adding onto this ^^: This is because of the invariant that mentions that in each traversal, the largest unsorted element will get to its final position. Eg: Original sorted list: [3, 6, 10, 14, 18, 20] After appending 13 at the end: [3, 6, 10, 14, 18, 20, 13] Note that 14, 18 and 20 are not in their final positions and require 3 traversals of the list in order to sort the list. However, if we append to the front: [13, 3, 6, 10, 14, 18, 20], only one traversal of the list is required (refer back to the invariant) |
What does it mean for a sorting algorithm to be stable? Why? Is Bubble Sort stable?
Answer: A sorting algorithm is said to be stable if the relative order is maintained after the list has been sorted. For example: [1,,,2]->[1,2,,] this is stable. Bubble sort is stable because of the strict < comparison in the code (elements are only swapped if they are less than the other element, so equal elements are not swapped and the relative order is maintained). Using <= would make it unstable. |
Briefly describe Selection sort giving details about.
The main idea of Selection Sort.
Answer: Selection Sort finds the minimum value for each index of the array and successively does this until the end of the array is reached. To add on: Once it “selects” the minimum value in the unsorted portion of the list it then swaps it into the end of the sorted portion of the list, which will be its final position. |
Explain what one iteration does.
Answer: For each iteration of Selection Sort we find the minimum value starting at the 0th index and traverse the list. We store the minimum value in a variable and note the index it was found. We then place the current value of the array at the current index in a temp variable. We replace the current value with the minimum and the value at which minimum value was found with the temp variables value. |
What is the best case and worst case complexity?
Answer: O(n^2) for both, where n is the length of the list |
Explain why the best and worst case are as stated. No explanation no marks.
Answer: Regardless of whether or not a list is sorted, the amount of times we iterate through the list is the same as the selection sort algorithm does not know if all the elements have been sorted without checking. It will still go through itself to find the smallest element and swap it with itself. The algorithm hence takes O(N^2) comparisons, so it has an O(N) complexity. |
What is the result of applying one iteration of SelectionSort if one wants to sort the list in increasing order and starts from the left?
Example: [5, 20, -5, 10, 3]
Answer: [-5, 20, 5, 10, 3] |
Example: [6, 5, 4, 3, 2, 1]
Answer: [1, 5, 4, 3, 2, 6] |
What does it mean for a sorting algorithm to be stable? Why? Is Selection Sort stable?
Answer: A sorting algorithm is considered stable if it preserves the relative order of items with equal values. This means that if two elements in the list are equal, their order relative to each other remains the same after sorting. For. e.g. in a list of tuples [(Earl,80), (David,90), (Charlie,70), (Sebastian, 80)] is going to be sorted by the grades of students. Two people in the grades have the same grade 80 - Sebastian and Earl. Earl is at index 0 while Sebastian is at index 3 in the unsorted list - Earl has a lower Index than Sebastian. If the list is sorted by a stable sorting algorithm, to maintain the relative order of all items, Earl would have a lower index than Sebastian in the sorted list. The expected sorted list under a stable sorting algorithm would be: [(David,90), (Earl,80), (Sebastian,80), (Charlie,70)] However, in selection sort, as non-adjacent elements are swapped, the relative order of all items in the output may be disrupted. As such, the expected output from the selection sort algorithm would be: v [(David,90), (Sebastian,80), (Earl,80), (Charlie,70)] As the relative order under the selection sort algorithm is not preserved, it is not a stable sorting algorithm. |
What does it mean for a sorting algorithm to be incremental? Why? Is Selection Sort incremental?
Answer:incremental An algorithm is said to be incremental if it does not need to recompute everything after a small change/if the algorithm can return a sorted list with the new element within one or few iterations. Selection sort is not incremental. The algorithm is written in such a way that it will always repeatedly select the smallest element from the unsorted portion of the list and swap it with the first unsorted element. Regardless of whether the new element is placed in the front or back, in each (outer) iteration, selection sort will examine all the remaining unsorted elements to find the minimum (will always perform full scans of the unsorted portion). Hence, to return a sorted list with the new element, it will require (a lot) more than one or few iterations of the algorithm |
Briefly describe Insertion sort giving details about.
The main idea of Insertion Sort.
Answer: Consider the first element as “sorted” (might not necessarily be true) Create temp variable for first unsorted number Check over each number in the sorted partition (decrementing right to left) If the decremented element is greater than temp, shift it to the right by 1 spot. Once the decremented element is less than or equal to temp, overwrite the number after the decremented element with temp, thus “inserting” it. |
Explain what one iteration does.
Answer: Each iteration will increase the number of elements in the sorted partition by 1 |
What is the best case and worst case complexity?
Answer: Best case O(n) Worst case O(n2) |
Explain why the best and worst case are as stated. No explanation no marks.
Answer: Best: O(n) where n is the number of elements in the array occurs if the array is already sorted. The algorithm will store temp, then compare with the element to the left of it in the sorted partition. Since temp is greater than the element in the sorted partition, it will essentially do nothing because it’s already in correct order. It will repeat this for n elements in the array. Worst: O(n2) where n is the number of elements in the array. Worst case occurs if the array is sorted in reverse order. For every unsorted element, the algorithm will then have to traverse the entire sorted partition from right to left until it finds the correct position for temp (which is at the beginning). If the program has to traverse the entire sorted partition (O(n)) for n elements, we get O(n2) |
What is the result of applying one iteration of Insertion Sort if one wants to sort the list in increasing order and starts from the left?
Example: [5, 20, -5, 10, 3]
Answer: [-5,5,20,10,3] [incorrect] Alternative answer (pls check): [5, 20, -5, 10, 3] because in the first iteration, it compares 5 and 20, and since 20 is greater than 5 it stays in the same position. Yeye this is correct. The one up there is wrong, and no swaps should be performed! |
Example: [-7,-1,-4,4,5,6]
Answer: [-7,-1,-4,4,5,6] -> List remains unchanged as -7 at index 0 is smaller than index 1. |
What does it mean for a sorting algorithm to be incremental? Why? Is Insertion Sort incremental? Why and when?
Answer:
|
What does it mean for a sorting algorithm to be stable? Why? Is InsertionSort stable?
Answer: For a sorting algorithm to be stable, it is expected that the relative order of items will remain the same, i.e. when 2 or more items have the same value in an unsorted list, the one which had a lower index in the unsorted list is first. During the insertion process, when an element (pivot) is being compared to the sorted elements of the list, it will only move past elements which are greater than it, not elements which are less than or equal to it. Hence, insertion sort is stable because when 2 or more items have the same value, the relative order of items remains unchanged. |
Algorithms and Complexity
What is expected of an algorithm in general? Following the definitions given in class, can it happen that two algorithms solving the same problem produce non-equivalent outputs? Why?
Answer: In general for an algorithm, it is expected that it will do a finite set of instructions. (Feedback: Answer correct but incomplete) Alternative Answer #1: An algorithm should have:
It can happen that two algorithms solving the same problem can produce non equivalent outputs, because an algorithm can be non deterministic which would produce a different output even if the input is the same each time we run an algorithm usually because the algorithm is probabilistic or contains randomness, An example would be probabilistic algorithms whose behaviours depend on random number generators. Credit to the Malaysian PASS leader for this answer |
With respect to the definitions given in class, can it happen that an algorithm does not stop for some of the problem instances? Why?
Answer: No, an algorithm has to halt for any problem instance according to the definition in class, therefore the algorithm would have already been designed in a way that it will always halt for any problem instance. Alternative answer: No, Algorithm has to halt for any problem instance because algorithms are considered correct if they produce the correct output for every valid input. Therefore algorithms should stop for every problem instances. |
What is normally meant to be an input size if the algorithm’s input is an integer, collection of elements or a graph/tree? What do we count when calculating the time complexity of an algorithm?
Answer: If the algorithm’s input is an integer, it means it is the number of bits or digits needed to represent the integer where for an integer in general the size is equal to log2n where n is the input size. If the algorithm’s input is the collection of elements, the input size is the number of elements in the collection. If the algorithm’s input is a graph/tree, the input size can be measured in multiple ways, for example, the number of vertices, edges or both. When we calculate the time complexity of an algorithm we want to know how much time does an algorithm take solving the problem, so we usually measure the number of elementary operations performed in the algorithm. |
Should algorithmic time complexity be measured with respect to something specific? If yes, what? What does it mean mathematically that f(n)=O(g(n)), in your own words?
Answer: Algorithmic time complexity should be measured with respect to the input size of the algorithm. An example of an input size would be the number of elements in a collection. When f(n) = O(g(n)) it means mathematically that f(n) is less than some constant multiple of g(n), for all sufficiently large values of n. g(n) is an asymptotic upper bound for f(n) meaning when n becomes very big and it is approaching infinity g(n) provides the tightest upper bound for the runtime of our algorithm. |
Which function grows faster: f(n) or g(n)? Why?
Example: f(n)= and g(n)=
Example: f(n)= and g(n)=
Example: f(n)= and g(n)=
Answer:
|
Is it true that f(n)=O(g(n))? Why?
Example: f(n)=+ and g(n)=
Example: f(n)= and g(n) =
Answer: 1.No, f(n) simplifies to O(n^2) given that the dominating component of the function f(n) is 1000^2. (feedback: dominating component should be 1000n^2?) (feedback: not sure if this is right but should you say the dominating component is n^2 because the constant is irrelevant in an asymptotic context?) As, n^2 not equals g(n) = n log n, the statement that f(n) = O(g(n)) is not true. 2.No as they simplify to f(n) = O(3^n) and g(n) = O(2^n), this means that 3^n grows faster than 2^n thus they are not equivalent. |
Assume that given a collection of n elements, our function iterates n times and does a constant number of other elementary operations. What is its complexity? Why?
Answer: Its complexity is O(n), as the number of traversals of the function is related to the total amount of elements by a factor of n Feedback (Correct): Alternate Answer more i n depth below:
|
Assume that given a collection of n elements, our function iterates 50 times and does a constant number of other elementary operations. What is its complexity? Why?
Answer:O(50*n) which can be simplified to O(n) where n is the size of the collection. This is because our algorithm will perform a constant number of elementary operations 50 times on each element in the collection. As these operations are elementary they have constant time so our complexity would be O(1*50*n) which we saw can be simplified to O(n) Feedback (Correct): Alternate Answer more in depth below:
|
Assume that given a collection of n elements, our function iterates times and does a constant number of other elementary operations. What is its complexity? Why?
Answer:
|
Assume that given a number n, our function iterates n times. What is its complexity with respect to the input size assuming all the other operations are constant-time? Why?
Answer:
|
Assume that given a number n, our function iterates times. What is its complexity with respect to the input size assuming all the other operations are constant-time? Why?
Answer:
|
How is the constant-time complexity denoted?
Answer: Constant-time complexity is simply donated as O(1). |
Answer: f1(n) + f2(n) will be O(max(f1(n),f2(n)) where n is ____ (not given) The time complexity of f1(n) + f2(n) will be whichever has a faster growing Big O time. In this case, f1(n) + f2(n) will be f`1(n) = O(n2) because n2 is larger than n*log(n). This can be seen: n2 = n*n > n*log(n) since n > log(n) |
Answer: Since they are multiplying each other, we multiply the big O complexities. f1(n)*f2(n) will be O(n3*log(n)) where n is …. (not given to us) |
What is the difference between worst-case and best-case complexity? Explain in your own words.
Answer: Time complexity refers to the amount of times an algorithm will traverse through the algorithm relative to an input of a specific size. The worst-case complexity is measured when we are given when an input of specific size for which the traversals are maximum, the best-case complexity is when we are given an input of a specific size for which the traversals are minimal.
|
20. What is the worst-case complexity of a given function? With respect to what should it be analysed?
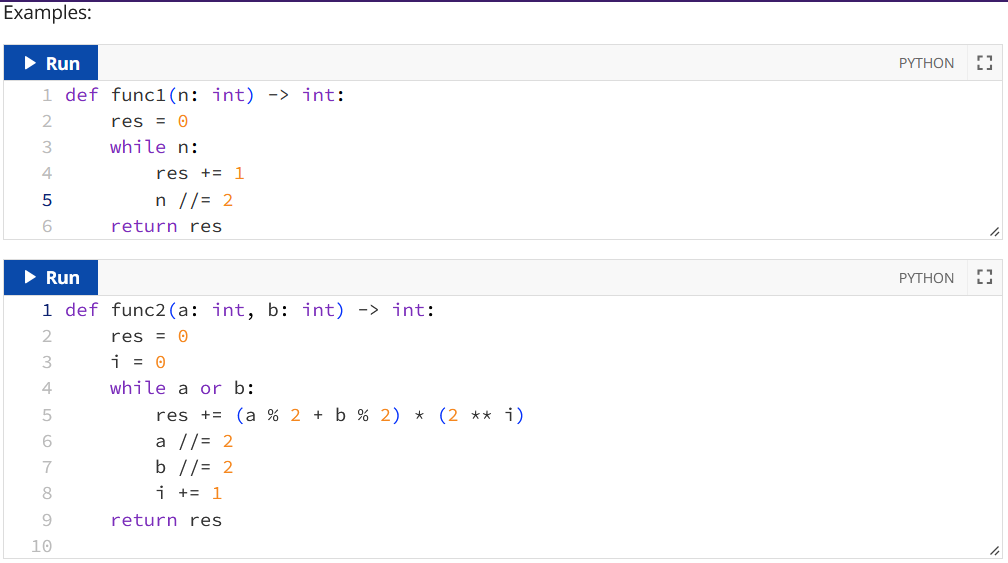

Answer: func1: O(log(n)) where n is the value of the integer n func2: O(max(log(a,b)) where a, b are their integer values func3: O(n2) where n is the number of elements in the list: l |
21. What is the best-case complexity of a given function? With respect to what should it be analysed?
Answer: The best case complexity of a given function is found when an input is picked such that it may have a lowered amount of operations. (Feedback: Please give according to the examples listed in 20.) |
ADT, Stack ADT (array-based), Set ADT
What is an abstract data type and how does it differ from data type? Give examples for abstract data type and also data type in Python.
Answer: An Abstract Data Type (ADT) defines the possible values of the type and their meaning, the operations that can be done on them, but not its implementation, i.e. how the values are stored, how the operations are implemented. Users interact with the data only through the provided operations. Eg. Stack ADT, Queue ADT, List ADT. Data Types are like ADTs except they have implementation and information on how they’re stored. The possible values for that type, the meaning of those values, the operations that can be done on them, and how those values are implemented are all provided. Eg. int, str etc. |
In your own words, what is the key idea behind abstract data types? Why are they used?
Answer: The idea behind an abstract data structure is to display the information regarding possible values of a particular type and the operations which can be done on them, without showing the code for them. This is done for the sake of simplification and maintenance - the algorithm for a particular data structure may change, yet it may not impact the usability for one’s code. |
Is there a difference between capacity and length for an ADT implemented with an array?
Answer: The capacity is the maximum amount of elements that can be in a data structure, while the length states the amount of elements that actually are in a data structure. |
Briefly describe Stack ADT giving details about
Main property of a Stack ADT
Key operations of the Stack ADT
Name a few applications where stacks are of use.
Answer:
Key operations of Stacks are the constructor, push() and pop() Other common operations include: peek(), is_empty(), is_full(), clear()
|
What is the best-case and worst-case complexity of operations push() and pop() for a Stack ADT, if implemented with an array? No explanation no marks.
Answer: Best and worst cases for both are O(1). Does anyone know to explain the reasoning behind this other than saying that the operations in the methods are all constant, or is that enough explanation? Alternative Answer #1 (Revised post feedback below): Given that the amount of operations for the items to be popped remain constant throughout all valid scenarios, both the best-case and the worst-case for pop() is O(1). Push(): O(1) best case, O(n) worst case Pop(): O(1) best case, O(1) worst case Feedback to Alt Ans #1: It is possible for push to be O(n), where n is the capacity of the array, due to resizing? Feedback to Feedback #1: I think it depends on how push() is implemented I think… |
Briefly describe Set ADT, giving details about
How one can implement the Set ADT
The main properties of the Set ADT
The key operations on the Set ADT
Answer: A set is unordered and does not allow for duplicates. Key operations are the constructor, add(), remove(), member(), union(), difference(), intersection() |
Briefly describe a bit-vector, giving details about
How a bit-vector can represent a set of elements
What kind of elements can be represented this way
Explain how bitvector-based sets operate
Give an example
Answer: A bit-vector refers to how the bits 1 and 0 respectively can be used to represent whether or not certain elements are within a particular set. If Item i belongs to the set if the vector has value 1 in the position i - 1, Otherwise, the item is not in the set! For example:
The set represented by the bit-vectors above has elements {A,B,E,F}. We handle bit vector-based sets by doing bitwise operations. Bit-vectors can only be utilised to represent numbers |
What are the main advantages and disadvantages of an array-based implementation of the Set ADT compared to a bitvector-based implementation? State the advantages and disadvantages as separate sections for each.
Answer:
Advantages: Array
Bitvector
Disadvantages: Array
Bitvector
|
What is the best-case and worst-case complexity of the below operations for a Set ADT, if implemented with an array? Explain the reason for the best and worst case. No explanation no marks.
add()
remove()
__len__()
union()
intersection()
Answer:
|
What is the best-case and worst-case complexity of the below operations for the Set ADT, if implemented with a bit-vector? Explain the reason for the best and worst case. No explanation no marks.
add()
remove()
__len__()
union()
intersection()
Answer:
|
Does Python have primitive data types? Explain.
Answer: Yes! Python has integers, booleans, floats, strings as primitive data types. They are primitive in the sense that they are the building blocks which all other data types are constructed from. (from PASS slides) |
Queue ADT (arrays based), List ADT (arrays based)
Briefly describe Queue ADT giving details about
Main property of a Queue ADT;
Key operations of the Queue ADT;
Name a few applications where Queues are of use.
Answer:
11 Alternative Answer: (Feedback: Above answer is correct, but some more details)
|
Distinguish between a linear queue and a circular queue, providing at least 2 points of difference? Which one is better? Why?
Answer:
Alternative Answer: (Feedback: Above answer is correct, but some more details)
|
What is the best-case and worst-case complexity of the below operations for a Circular Queue ADT, if implemented with an array? Explain the reason for the best and worst case. No explanation no marks.
append()
serve()
is_full()
Answer:
Alternative Answer append() & serve(): (Feedback: Above answer is correct, but some more details)
Alternative Answer is_full() (Feedback: Above answer is slightly incorrect, I think).
|
Briefly describe List ADT giving details about
Main property of a List ADT;
Key operations of the List ADT;
Name a few applications where Lists are of use.
Answer:
|
What is the best-case and worst-case complexity of the below operations for a List ADT, if implemented with an array? Explain the reason for the best and worst case. No explanation no marks.
insert()
index()
delete_at_index()
Answer:
|
Sorted List ADT (array based), List ADT (linked nodes based)
Briefly describe Sorted List ADT giving details about
Main property of a Sorted List ADT;
Key operations of the Sorted List ADT;
When (in practice) can sorted lists be preferred to normal (unsorted) lists? When is it better to use unsorted lists?
Answer: The main property of a sorted list is that whenever items are added in and removed to the list, they will be sorted in ascending order. The key operations of the sorted list ADT are:
Sorted lists would be preferred to normal lists when one needs to find a large amount of data from a particular data set - if the list is sorted, binary search instead of linear search to find elements, reducing the complexity of the index(item) method to O(logn). |
What is the best-case and worst-case complexity of the below operations for a Sorted List ADT, if implemented with an array? Assume that item search is done with either linear search (or binary search). Explain the reason for the best and worst case. No explanation no marks.
index()
add()
Answer: add() - Best case would be O(log(n)), where n is the length of the list. Occurs when an item is added to the end of the list. Worst case, on the other hand, would be O(n), where n is the length of the list. This occurs either when we have to resize the list when it is full OR when we add to the first element, as every item needs to be shuffled right by one. index()
Feedback: (added case for Binary Search) For Best Case for index():
Linear Search: O(1), when the item is in the beginning of the list, as it checks the start first Binary Search: O(1), when the item is in the middle of the list, as it checks the middle first. |
For a sorted list of elements, what is the difference between linear search and binary search applied to the list? Give the best-case and worst-case complexity of both.
Answer: The best case of both searches is O(1), as we can get the desired result 1st try. This occurs when the item is in the middle of the list for binary search, and the start for linear search. However, as binary search reduces the search size for the sorted list by a half each iteration - we know that the worst-case time complexity is thus O(log(n)), where n is the size of the list. This occurs when the item is either at the start or the end of the list. The worst case for linear search on the other hand would be O(n), where n is the length of the list. This is because we need to iterate through every element to find the last item. |
State three advantages and disadvantages of Linked Nodes data structures?
Answer: Advantages:
Disadvantages:
ADDITION TO ANS ABOVE: Another Disadvantage is:
Feedback: |
What is the best-case and worst-case complexity of the below operations for a List ADT, if implemented with an linked nodes? Explain the reason for the best and worst case. No explanation no marks.
insert()
index()
delete_at_index()
__get_node_at_index()
Answer: Assuming that the linked list is a singly linked list:
Feedback (Incorrect): I’m pretty sure Best Case reasoning for insert(index, item) is incorrect, and Worst Case is wrong (should be O(n), where n is the index), and also Best Case reasoning and Worst Case in general is incorrect for delete_at_index() see slides for Linked List ADT page 66. I also provided an alternate answer considering the cost of comparison just in case the question asks for it. And also, for the alternate answer for insert(index, item) and delete_an_index, can anyone explain why the lecture slides says that the worst case for insert is O(index), not O(len(self))? Alternate Answer: insert(index, item) Best Case O(1) - occurs if we insert the item at the beginning, then we only need to update the head element and add the previous head as the link to the current head. Worst case O(index) - this is because everything is constant except for __get_node_at_index (which is O(index)), as we need to traverse through the nodes to find the previous node index() Everything is constant except for the cost of comparison and the loop runs until the item is found Best Case: O(comp) - if the item is at the front of the list as the loop only has to run once Worst Case: O(comp * len(self)) - if the element is at the rear of the list as the loop have to iterate len(self) times until we reach the end of the list delete_at_index() Everything is constant except for __get_node_at_index, which the worst case is O(n), where n is the length of the list. Best Case: O(1) - occurs if we delete the item at the beginning, then we only need to update self.head to the next head in the list and traversing through the entire nodes is not required Worst Case: O(n), where n is the length of the list - occurs when the item to delete is at the very end, meaning that we have to traverse the nodes n times, and then updating the previous node’s link. __get_node_at_index(index) The loops always executes index times, and all other operations are constant |