Note
0.0(0)
Lecture 21 – DIVA model.docx
Lecture 21 – DIVA model
04.04.24
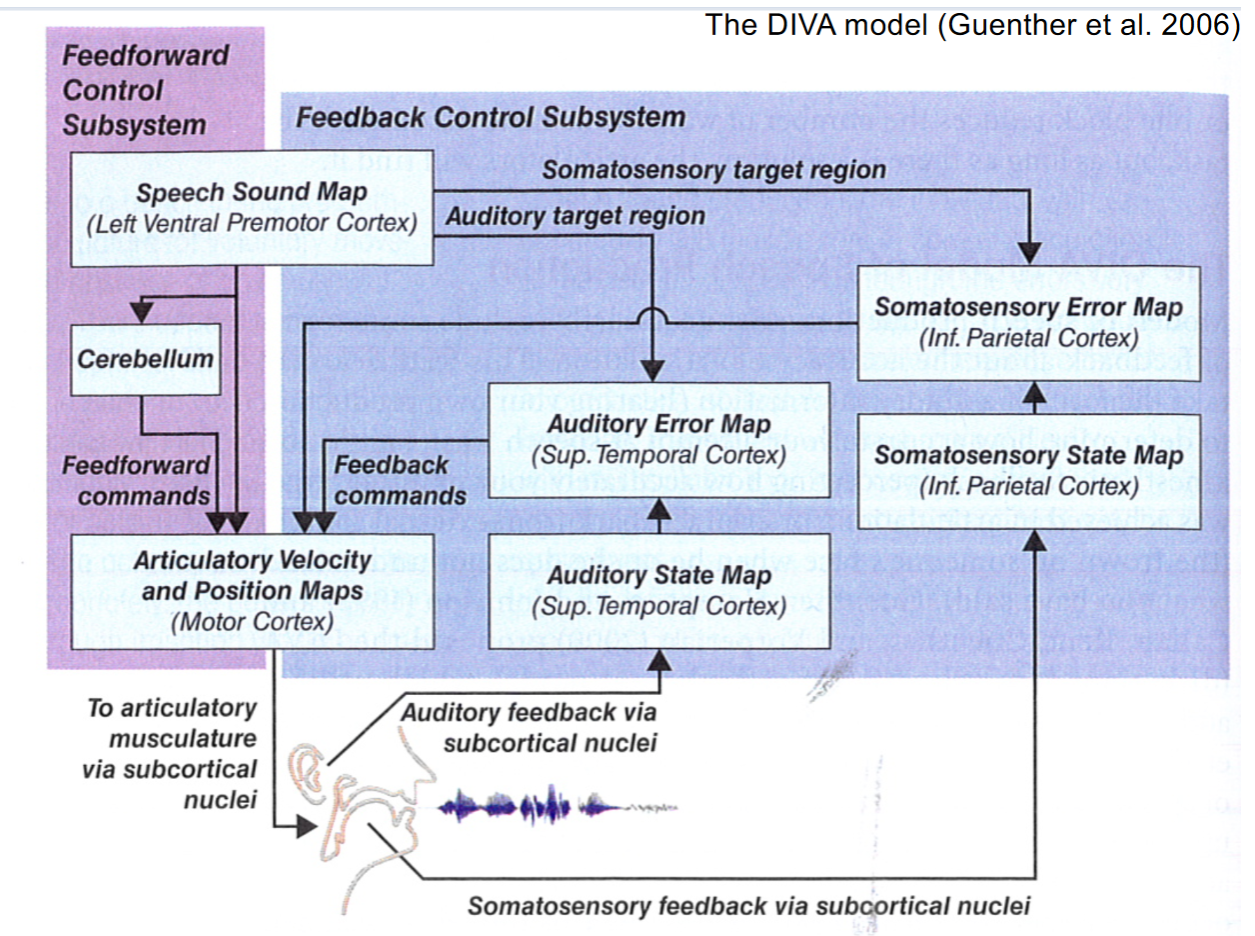
- DIVA model explained
- The speech sound map of the premotor cortex controls the articulator velocity and position maps (lower left) which, in turn, control the muscles of speech
- The output of the cortex is fed to somatosensory and auditory error-map regions responsible for monitoring the accuracy of production based on the proposed plan produced at the premotor cortex
- The error monitoring system serves as feedback control, which modifies the output over time during learning
- Eventually the feedforward control has been modified sufficiently that feedback is no longer critically essential until a perturbation occurs in the system
- That requires error correction (🡪 feedback loop)
- Such a perturbation could be
- Anesthesia from dental work
- Or inserting a tube into the mouth
- To a swollen lip or tongue
- To motor disturbance arising from neuromuscular disease
- Or simply an experiment where the auditory feedback is altered (phonetic experiments)
- For normal speech the feedback loop is turned off (otherwise speech production would be too slow) 🡪 only activated when necessary (i.e. perturbation occurs)
- General requirement for a speech model:
- Feedback:
- Auditory information (hearing your own voice and determine how exact targets have been reached)
- Tactile and kinestheic feedback (how accurately your production was achieved in articulation (e.g. collision control or precision of closure/narrow channel for plosive vs fricative)
- External sources (e.g. frown on someone’s face if they did not understand)
- Feedback:
- DIVA model contains mirror neurons model to match production to perception (a “model” of the desired speech sound is sent from the premotor cortex to the perceptual regions) 🡪 if mirror neuron “model” does not correspond to achieved acoustic output of the muscle model then muscle model is modified in the next trials 🡪 but this concept is still highly disputed
- DIVA model summary
- The DIVA model established that learning takes place due to the feedback system of error correction
- Learned accuracy carries us through task of talking (feedforward)
- Failure to turn off the feedback leads to typical pathological speech pattern (e.g. stuttering)
- Model can be used to drive speech synthesizers and thus help patients with pathological conditions (e.g. locked-in syndrome, speech motor disorders)
- DIVA model in applied sciences: stuttering
- It takes 75 to 150 ms for auditory information to reach the cerebral cortex 🡪 that is too long to produce fluent running speech (e.g. an unstressed syllable is often only 100ms long)
- So we have to disable the feedback loop for faster speech
- 🡪 that is the reason why we speak slower when learning new languages (learning process)
- 🡪dysfluency very similar to stuttering can be achieved when we do not disable the feedback part of the model and increase the speech rate -> in other words, in stuttering the feedback part of the model cannot be turned off, causing interference between the continuous auditory feedback and the motor planning for the following phonemes
- DIVA model in applied sciences: Locked-in syndrome
- Sensors have been implanted in the model-appropriate reginos of a young patients with locked-in syndrome (following a stroke after a traumatic brain injury)
- The researchers first identified the area of the atient’s brain that was active when the patient imagined himself speaking 🡪 these regions are likely to be involved in the active production of speech
- They then implemented a “neural prosthesis” that could read activity in these regions
- These activations run a speech synthesizer based on the specific phonemes that the patient is thinking of producing
- This DIVA-human combination can now successfully and consistently produce three vowels
Note
0.0(0)