Reinforcement Learning
Big Picture Summary
an agent will learn from the environment by interacting with it (through trial and error) and receiving rewards (negative or positive) as feedback for performing actions
Formal Definition
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
The RL Process
The agent receives the state from the environment
based on the state the agent takes an action
the environment goes to a new state
the environment gives some reward to the agent
The agent wants to maximise its cumulative reward, called the expected return
Why is the goal of the agent to maximize the expected return?
Because RL is based on the reward hypothesis, which is that all goals can be described as the maximization of the expected return (expected cumulative reward).
Markov Property
the Markov Property implies that our agent needs only the current state to decide what action to take and not the history of all the states and actions they took before.
Observation vs State
State s: is a complete description of the state of the world (there is no hidden information). In a fully observed environment
Observation o: is a partial description of the state. In a partially observed environment.
Action Space
Set of all possible actions in an environment
Discrete space: number of actions is finite (this will be our blue agent)
Continuous space: the number of actions is infinite
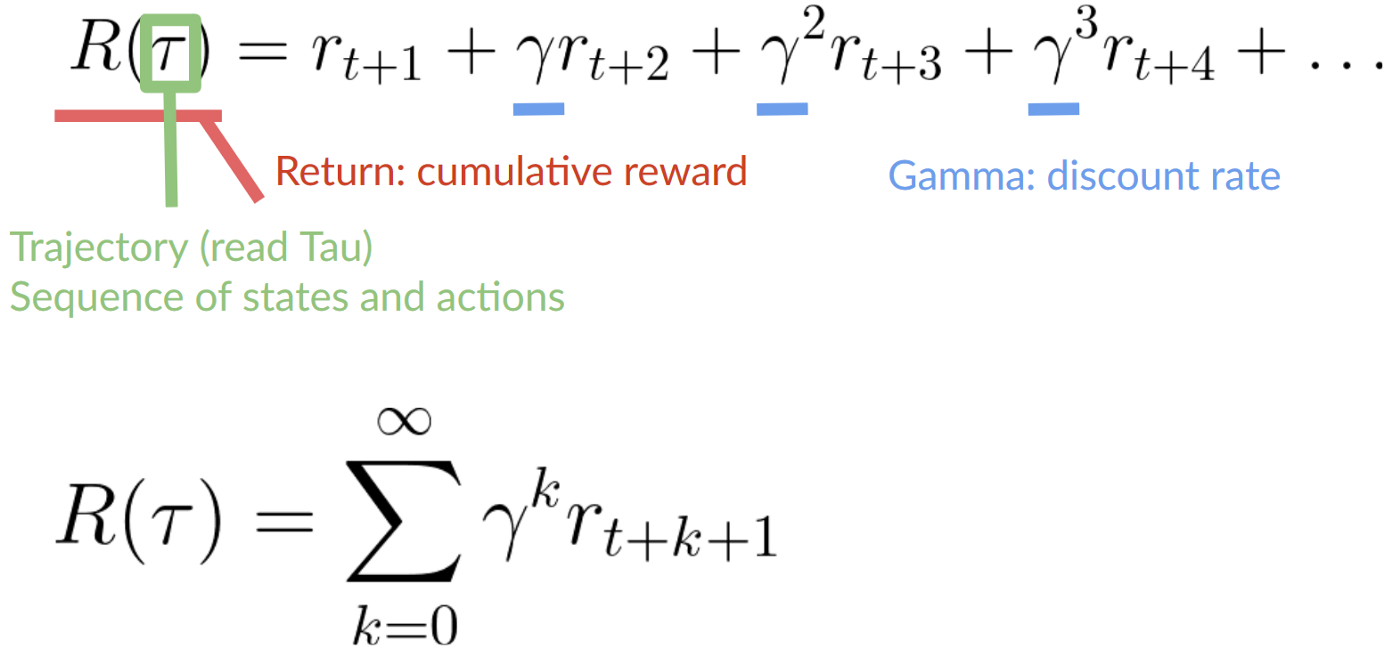
Rewards and Discounting
The rewards in the beginning are more likely to happen since it could be predictable, therefore you can discount the rewards of earlier events allowing for the agent to priortize the long-term reward
To discount the rewards the following steps must be taken:
We define a discount rate called gamma. It must be between 0 and 1. Most of the time between 0.95 and 0.99
Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, so the future reward is less and less likely to happen
Types of tasks
Episodic: starting point and an ending point (a terminal state)
Continuing: task that continue forever (no terminal state)
Exploration vs Exploitation trade-off
Exploration is exploring the environment by trying random actions in order to find more information about the environment
Exploitation is exploiting known information to maximize the reward
In other terms, the agent may only exploit a certain task as it will give a small reward, but if it were to explore further it could find a larger reward somewhere else in the environment
Two main approaches for solving RL problems
Two ways of find the optimal policy
Directly, by teaching the agent which action to take given the current state = Policy-Based Methods
Indirectly, teach the agent to learn which state is more valueable and then take the action that leads to more valuable states = Value-Based Methods
The Policy is the brain of our Agent, it’s the function that tells us what action to take given the state we are in
The given policy is to learn, so the goal is to find the optimal policy
1. Policy-Based Methods
Learn the policy function directly
define a probability distribution over the set of possible actions at that state
Two types of policies:
Deterministic: a policy at a given state will always return the same action
Stochastic: outputs a probability distribution over actions
2. Value-Based Methods
learn a value function that maps a state to the expected value of being at that state
The value of a state is the expected discounted return the agent can get if it starts in that state, and then acts by going to the state with the highest value
This is most likely the method we will choose for the CAGE challenge
The “Deep” in Reinforcement Learning
Deep Reinforcement Learning introduces deep neural networks to solve Reinforcement Learning problems