Power, Type 1/2 errors and understanding biases and limitations of studies
Power
Parametric tests are said to have more power
Power: the likelihood of the test detecting a significant difference when the null hypothesis is false
Several things affect the power of tests:
- Type of test - parametrics are more sensitive
- Making more accurate measurements - tight procedure and clearly defined and measured dependent variable
- having a one-tailed hypothesis - lowers the critical value required for equivalent levels of significance
Probability and Significance
probability of events occurring is measured on a scale of 0 to 1
logical probability: ratio of the number of ways our predicted outcome can happen divided by the number of possible outcomes
empirical probability: ratio of the number of relevants which have happened divided by the total number of relevant events
differences/correlations needed to be submitted to a test of significance in order for a decision to be made concerning whether the differences are to be counted as showing a genuine effect or dismissed as likely to represent chance fluctuation
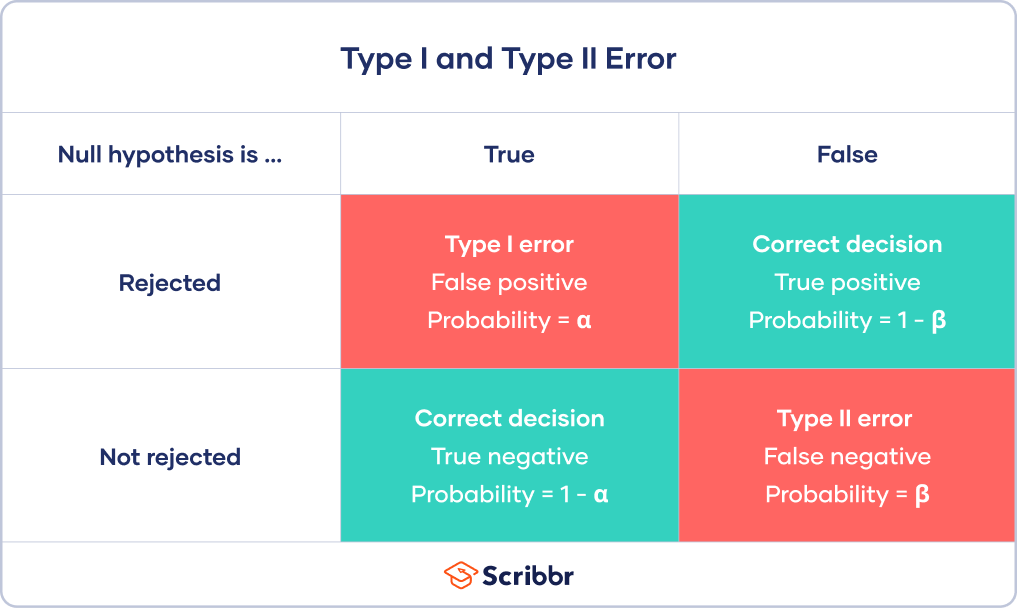
reject the null when the probability of being true drops below 0.05: 5% significance level
Type 1 error = false positive: null hypothesis is true but has been rejected because p<0.05
Type 2 error = false negative: null hypothesis has been retained because p>0.05 but there is a real underlying effect
Directional hypothesis = one-tailed test of probability
Non-directional hypothesis = two-tailed test of probability
results tested with a one-tailed test are more likely to reach significance but if the direction is opposite to that predicted, even past critical value, the null hypothesis must be retained
probability distribution: histogram with columns measuring the likelihood of occurrence of the event they represent.
\
Understanding biases and limitations of Studies
- reliability: a measures consistency in producing similar results on different but comparable occasions
- validity: whether a measure is really measuring what it was intended to measure
- internal validity: whether an effect was genuine or the result of incorrectly applied statistics, sampling biases or extraneous variables unconnected with the IV
- external validity: whether an effect generalises from the specific people, place and measures of variables tested to the population, other populations, other places and other measures of variables tested.
- population validity: can it be generalised to all other people in that population/other populations
- ecological validity: can it be generalised to other settings
- construct validity: does your measure of a concept really reflect the breadth of that concept?
- standardised procedures reduce variance in people’s performances, exclude bias from different treatment of groups and make replication possible
- meta-analysis: statistical review of many tests of the same hypothesis in order to establish the extent of valid replication and to produce objective reviews of results in topic areas
Threats to internal validity
- using a low power statistical test: different tests have varying sensitvity to detect difference
- violating assumpttions of statistical test used: tests should not be used if the data dont fit the assumptions
- capitalising on chance: multiple testinng of same data gives a higher chance of gettign a fluke significant result
- reliabilitty of measures
- reliability of procedures
- random errors in the research setting
- participant variance
- history: events which happen to participants during the research which affect results but arent linked to the IV
- maturation: participants mature durinng the study (eg child development studies)
- testing: practise or recallign mistakes
- selection bias
- drop out
- imitation of treatment: control participants may knnow what teh treatment groups are doing
- rivalry of control group: control participants may resent the treatment or want to do as well as the treatment group
Threats to external validity
- construct validity
- inadequate variable definition: to what extent are the measures used adequately defined
- mono-method bias: construct validity is improved by taking a variety of measures of the same concept
- hypothesis guessing: treatment participants guess what is required of them during the study
- evaluation apprehension: hypothesis guessinng may lead to tryinnng to please the experimenter
- experimenter expectancy
- level of independent variable: may not be far enough apart (30+40s vs 30s+1m)
- ecological validity
\
Relative Values of Quantitative vs Qualitative Studies
| Quantitative | Qualitative |
|---|---|
| Information is objective and narrow | Information is subjective and rich |
| high internal validity | low internal validity |
| artificial setting | realistic/naturalistic setting |
| structured design | unstructured design |
| low realism | high realism |
| low construct validity | high construct validity |
| high reliability | low reliability |
Sampling
Types of Groups
control group: group which is used as a baseline measure against which the performance of the intervention group is assessed
experiment/treatment group: group who recieves values of the IV in ann experiment or quasi-experiment
placebo group: group who dont recieve treatment but everything else the experimental group recieve and who are sometimes lef to believe their treatment will have an effect
Types of Sampling
cluster sampling: sample selected from a specific area as beinng representative of a population
opportunity sampling: sample selected because they are easily available for testing
systematic sampling: sample selected by taking every nth case
quota sampling: sample selected so that specified group[s will appear in numbers proportional to their size in the target population
random sampling: sample selected in which every member of the target population has an equal chance of being selected
self-selecting sampling: sample selected for study on the basis of their own action in arriving at the sampling point
snowball sampling: sample selected for study by asking key figures for people they think will be important or useful to include
stratified sampling: samples are selected so that specified groups will appear in numbers proportional to their size in the target population, within each subgroup cases are selected on a random basis
\