Nucleic Acids
History:
In the mid-twentieth century, scientists were still unsure as to whether DNA or protein was the genetic material of the cell
It was known that some viruses consisted solely of DNA and a protein coat and could transfer their genetic material into hosts
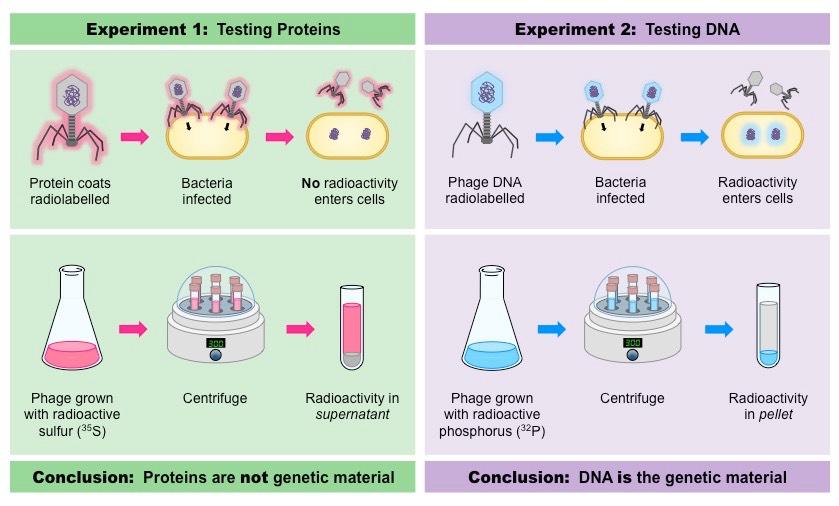
In 1952, Alfred Hershey and Martha Chase conducted a series of experiments to prove that DNA was the genetic material
Viruses (T2 bacteriophage) were grown in one of two isotopic mediums in order to radioactively label a specific viral component
Viruses grown in radioactive sulfur (35S) had radiolabelled proteins (sulfur is present in proteins but not DNA)
Viruses grown in radioactive phosphorus (32P) had radiolabeled DNA (phosphorus is present in DNA but not proteins)
The viruses were then allowed to infect a bacterium (E. coli) and then the virus and bacteria were separated via centrifugation
The larger bacteria formed a solid pellet while the smaller viruses remained in the supernatant
The bacterial pellet was found to be radioactive when infected by the 32P–viruses (DNA) but not the 35S–viruses (protein)
This demonstrated that DNA, not protein, was the genetic material because DNA was transferred to the bacteria
Summary of the Hershey-Chase Experiment
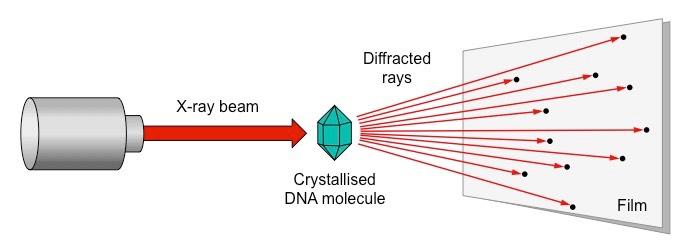
Rosalind Franklin and Maurice Wilkins used a method of X-ray diffraction to investigate the structure of DNA
DNA was purified and then fibres were stretched in a thin glass tube (to make most of the strands parallel)
The DNA was targeted by a X-ray beam, which was diffracted when it contacted an atom
The scattering pattern of the X-ray was recorded on a film and used to elucidate details of molecular structure
Summary of the Process of X-Ray Crystallography
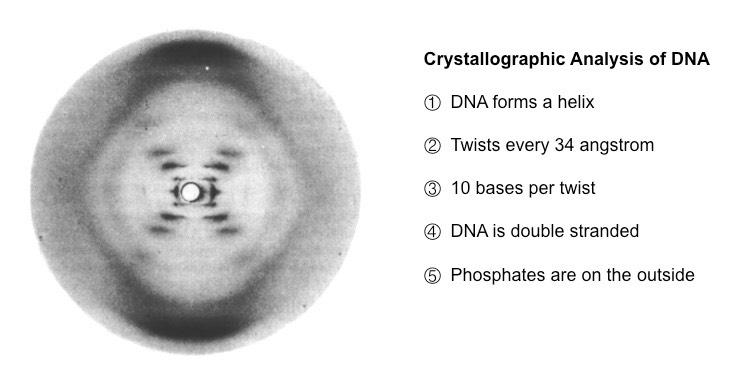
From the scattering pattern produced by a DNA molecule, certain inferences could be made about its structure
Composition: DNA is a double stranded molecule
Orientation: Nitrogenous bases are closely packed together on the inside and phosphates form an outer backbone
Shape: The DNA molecule twists at regular intervals (every 34 Angstrom) to form a helix (two strands = double helix)
Photo 51 – Evidence for the Structure of DNA via X-Ray Diffraction
Franklin’s data was shared by Wilkins with James Watson (without Franklin’s permission) who, with the help of Francis Crick, used the information to create a molecular model of the basic structure of DNA
In 1962, Watson, Crick and Wilkins (but not Franklin) were awarded the Nobel prize for their contributions to DNA structure identification
Franklin’s x-ray diffraction experiments demonstrated that the DNA helix is both tightly packed and regular in structure
Phosphates (and sugars) form an outer backbone and nitrogenous bases are packaged within the interior
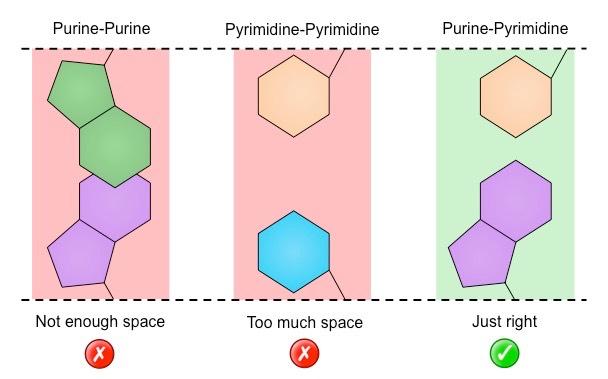
Chargaff had also demonstrated that DNA is composed of an equal number of purines (A + G) and pyrimidines (C + T)
This indicates that these nitrogenous bases are paired (purine + pyrimidine) within the double helix
In order for this pairing between purines and pyrimidines to occur, the two strands must run in antiparallel directions
When Watson & Crick were developing their DNA model, they discovered that an A–T bond was the same length as a G–C bond
Adenine and thymine paired via two hydrogen bonds, whereas guanine and cytosine paired via three hydrogen bonds
If the bases were always paired this way, then this would describe the regular structure of the DNA helix (shown by Franklin)
Replication
Consequently, DNA structure suggests two mechanisms for DNA replication:
Replication occurs via complementary base pairing (adenine pairs with thymine, guanine pairs with cytosine)
Replication is bi-directional (proceeds in opposite directions on the two strands) due to the antiparallel nature of the strands
Complementary Base Pairing as a Mechanism for DNA Replication
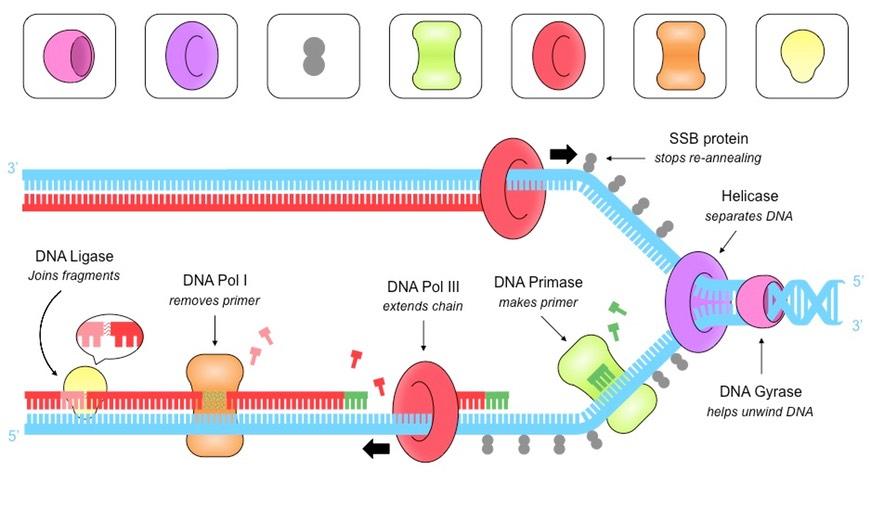
DNA replication is a semi-conservative process that is carried out by a complex system of enzymes:
Helicase
Helicase unwinds and separates the double-stranded DNA by breaking the hydrogen bonds between base pairs
This occurs at specific regions (origins of replication), creating a replication fork of two strands running in antiparallel directions
DNA Gyrase
DNA gyrase reduces the torsional strain created by the unwinding of DNA by helicase
It does this by relaxing positive supercoils (via negative supercoiling) that would otherwise form during the unwinding of DNA
Single Stranded Binding (SSB) Proteins
SSB proteins bind to the DNA strands after they have been separated and prevent the strands from re-annealing
These proteins also help to prevent the single stranded DNA from being digested by nucleases
SSB proteins will be dislodged from the strand when a new complementary strand is synthesised by DNA polymerase III
DNA Primase
DNA primase generates a short RNA primer (~10–15 nucleotides) on each of the template strands
The RNA primer provides an initiation point for DNA polymerase III, which can extend a nucleotide chain but not start one
DNA Polymerase III
Free nucleotides align opposite their complementary base partners (A = T ; G = C)
DNA pol III attaches to the 3’-end of the primer and covalently joins the free nucleotides together in a 5’ → 3’ direction
As DNA strands are antiparallel, DNA pol III moves in opposite directions on the two strands
On the leading strand, DNA pol III is moving towards the replication fork and can synthesise continuously
On the lagging strand, DNA pol III is moving away from the replication fork and synthesises in pieces (Okazaki fragments)
DNA Polymerase I
As the lagging strand is synthesised in a series of short fragments, it has multiple RNA primers along its length
DNA pol I removes the RNA primers from the lagging strand and replaces them with DNA nucleotides
DNA Ligase
DNA ligase joins the Okazaki fragments together to form a continuous strand
It does this by covalently joining the sugar-phosphate backbones together with a phosphodiester bond
Summary of DNA Replication
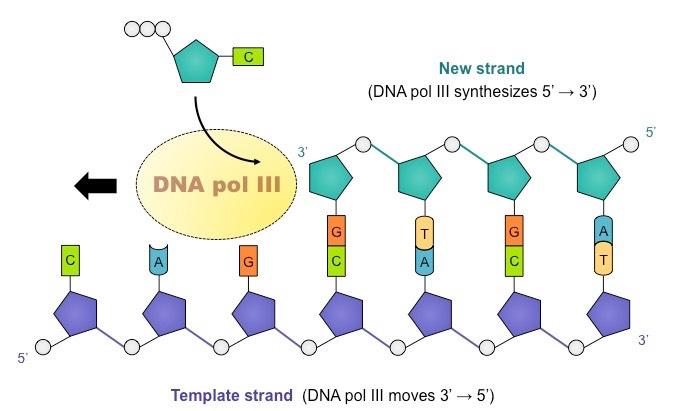
DNA polymerase cannot initiate replication, it can only add new nucleotides to an existing strand
For DNA replication to occur, an RNA primer must first be synthesized to provide an attachment point for DNA polymerase
DNA polymerase adds nucleotides to the 3’ end of a primer, extending the new chain in a 5’ → 3’ direction
Free nucleotides exist as deoxynucleoside triphosphates (dNTPs) – they have 3 phosphate groups
DNA polymerase cleaves the two additional phosphates and uses the energy released to form a phosphodiester bond with the 3’ end of a nucleotide chain
Direction of DNA Synthesis
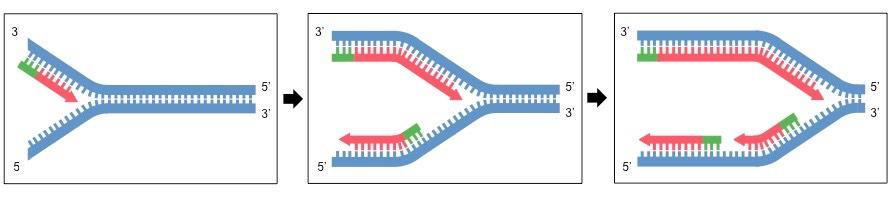
Leading versus Lagging Strands
Because double-stranded DNA is antiparallel, DNA polymerase must move in opposite directions on the two strands
On the leading strand, DNA polymerase is moving towards the replication fork and so can copy continuously
On the lagging strand, DNA polymerase is moving away from the replication fork, meaning copying is discontinuous
As DNA polymerase is moving away from helicase, it must constantly return to copy newly separated stretches of DNA
This means the lagging strand is copied as a series of short fragments (Okazaki fragments), each preceded by a primer
The primers are replaced with DNA bases and the fragments joined together by a combination of DNA pol I and DNA ligase
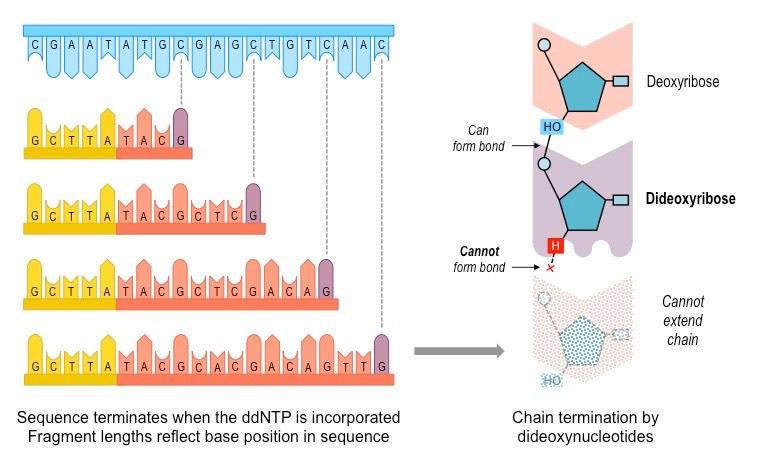
DNA sequencing refers to the process by which the base order of a nucleotide sequence is elucidated
The most widely used method for DNA sequencing involves the use of chain-terminating dideoxynucleotides
Dideoxynucleotides (ddNTPs) lack the 3’-hydroxyl group necessary for forming a phosphodiester bond
Consequently, ddNTPs prevent further elongation of a nucleotide chain and effectively terminate replication
The resulting length of a DNA sequence will reflect the specific nucleotide position at which the ddNTP was incorporated
For example, if a ddGTP terminates a sequence after 8 nucleotides, then the 8th nucleotide in the sequence is a cytosine
The Sanger method:
Four PCR mixes are set up, each containing stocks of normal nucleotides plus one dideoxynucleotide (ddA, ddT, ddC or ddG)
As a typical PCR will generate over 1 billion DNA molecules, each PCR mix should generate all the possible terminating fragments for that particular base
When the fragments are separated using gel electrophoresis, the base sequence can be determined by ordering fragments according to length
If a distinct radioactive or fluorescently labelled primer is included in each mix, the fragments can be detected by automated sequencing machines
If the Sanger method is conducted on the coding strand (non-template strand), the resulting sequence elucidated will be identical to the template strand
DNA sequencing
DNA sequencing refers to the process by which the base order of a nucleotide sequence is elucidated
The most widely used method for DNA sequencing involves the use of chain-terminating dideoxynucleotides
Dideoxynucleotides
Dideoxynucleotides (ddNTPs) lack the 3’-hydroxyl group necessary for forming a phosphodiester bond
Consequently, ddNTPs prevent further elongation of a nucleotide chain and effectively terminate replication
The resulting length of a DNA sequence will reflect the specific nucleotide position at which the ddNTP was incorporated
For example, if a ddGTP terminates a sequence after 8 nucleotides, then the 8th nucleotide in the sequence is a cytosine
Determining Nucleotide Positions Using Dideoxynucleotides
Sequencing
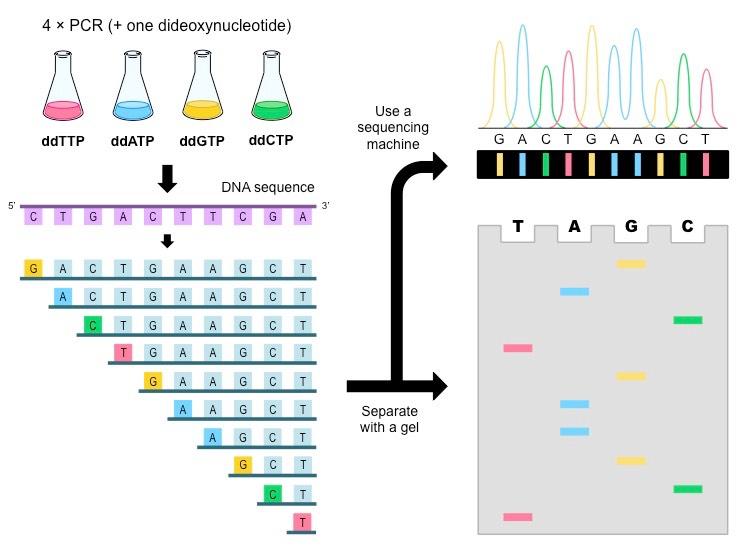
Dideoxynucleotides can be used to determine DNA sequence using the Sanger method
Four PCR mixes are set up, each containing stocks of normal nucleotides plus one dideoxynucleotide (ddA, ddT, ddC or ddG)
As a typical PCR will generate over 1 billion DNA molecules, each PCR mix should generate all the possible terminating fragments for that particular base
When the fragments are separated using gel electrophoresis, the base sequence can be determined by ordering fragments according to length
If a distinct radioactive or fluorescently labelled primer is included in each mix, the fragments can be detected by automated sequencing machines
If the Sanger method is conducted on the coding strand (non-template strand), the resulting sequence elucidated will be identical to the template strand
DNA Sequencing via the Sanger Method
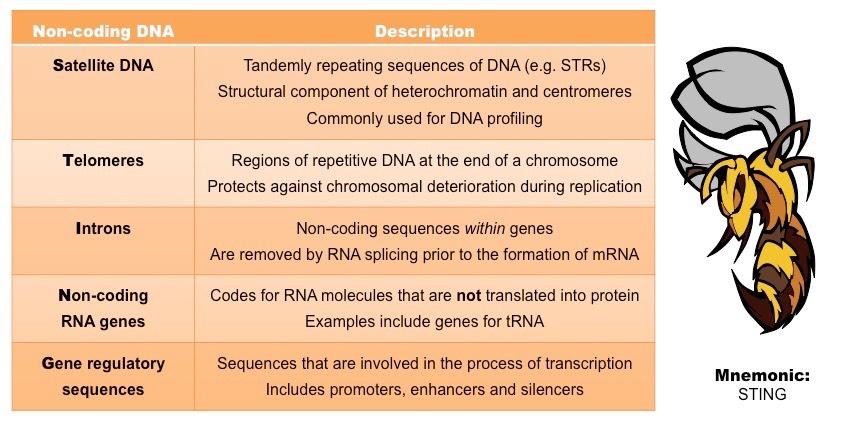
The vast majority of the human genome is comprised of non-coding DNA (genes only account for ~ 1.5% of the total sequence)
Historically referred to as ‘junk DNA’, these non-coding regions are now recognised to serve other important functions
Examples include satellite DNA, telomeres, introns, ncRNA genes and gene regulatory sequences
Types of Non-Coding DNA
DNA profiling is a technique by which individuals can be identified and compared via their respective DNA profiles
Within the non-coding regions of an individual’s genome there exists satellite DNA – long stretches of DNA made up of repeating elements called short tandem repeats (STRs)
Tandem repeats can be excised using restriction enzymes and then separated with gel electrophoresis for comparison
As individuals will likely have different numbers of repeats at a given satellite DNA locus, they will generate unique DNA profiles
Longer repeats will generate larger fragments, while shorter repeats will generate smaller fragments
Comparative STR Lengths at Two Specific Loci

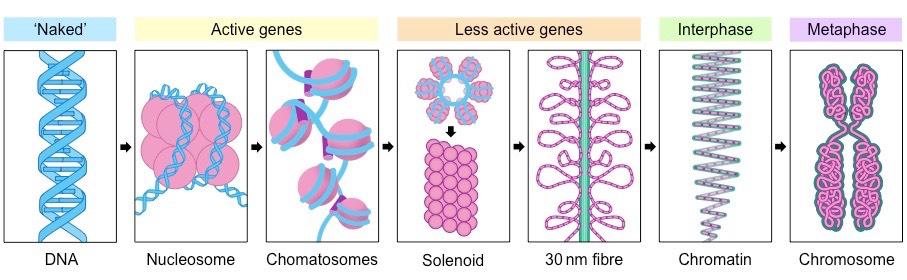
In eukaryotic organisms, the DNA is packaged with histone proteins to create a compacted structure called a nucleosome
Nucleosomes help to supercoil the DNA, resulting in a greatly compacted structure that allows for more efficient storage
Supercoiling helps to protect the DNA from damage and also allows chromosomes to be mobile during mitosis and meiosis
Organisation of Eukaryotic DNA
The DNA is complexed with eight histone proteins (an octamer) to form a complex called a nucleosome
Nucleosomes are linked by an additional histone protein (H1 histone) to form a string of chromatosomes
These then coil to form a solenoid structure (~6 chromatosomes per turn) which is condensed to form a 30 nm fibre
These fibres then form loops, which are compressed and folded around a protein scaffold to form chromatin
Chromatin will then supercoil during cell division to form chromosomes that are visible (when stained) under microscope
A nucleosome consists of a molecule of DNA wrapped around a core of eight histone proteins (an octamer)
The negatively charged DNA associates with positively charged amino acids on the surface of the histone proteins
The histone proteins have N-terminal tails which extrude outwards from the nucleosome
During chromosomal condensation, tails from adjacent histone octamers link up and draw the nucleosomes closer together
To view the structure of a nucleosome via an interactive pop-up, click on the name of the structure below:
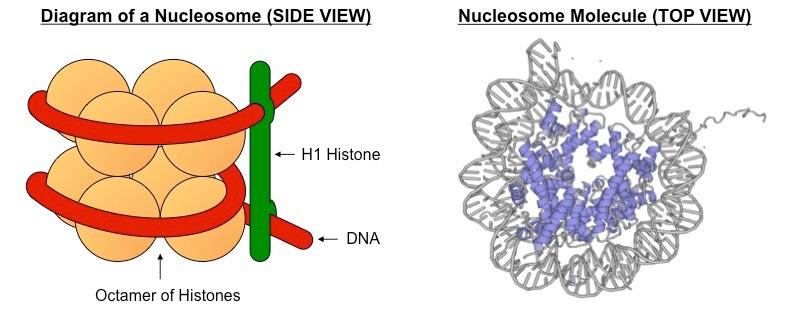
A gene is a sequence of DNA which is transcribed into RNA and contains three main parts:
Promoter
The non-coding sequence responsible for the initiation of transcription
The core promoter is typically located immediately upstream of the gene’s coding sequence
The promoter functions as a binding site for RNA polymerase (the enzyme responsible for transcription)
The binding of RNA polymerase to the promoter is mediated and controlled by an array of transcription factors in eukaryotes
These transcription factors bind to either proximal control elements (near the promoter) or distal control elements (at a distance)
Coding Sequence
After RNA polymerase has bound to the promoter, it causes the DNA strands to unwind and separate
The region of DNA that is transcribed by RNA polymerase is called the coding sequence
Terminator
RNA polymerase will continue to transcribe the DNA until it reaches a terminator sequence
The mechanism for transcriptional termination differs between prokaryotes and eukaryotes
Sections of a Gene
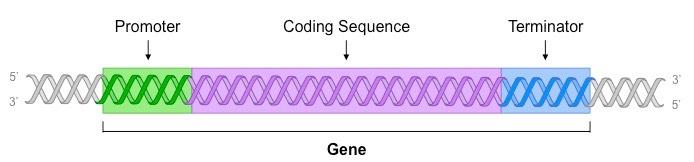
Antisense vs Sense
A gene (DNA) consists of two polynucleotide strands, but only one is transcribed into RNA
The antisense strand is the strand that is transcribed into RNA
Its sequence is complementary to the RNA sequence and will be the "DNA version” of the tRNA anticodon sequence
The antisense strand is also referred to as the template strand
The sense strand is the strand that is not transcribed into RNA
Its sequence will be the “DNA version” of the RNA sequence (i.e. identical except for T instead of U)
The sense strand is also referred to as the coding strand (because it is a DNA copy of the RNA sequence)
Either of the 2 polynucleotide strands may contain a gene, and hence the determination of sense and antisense is gene specific
Antisense vs Sense Strands
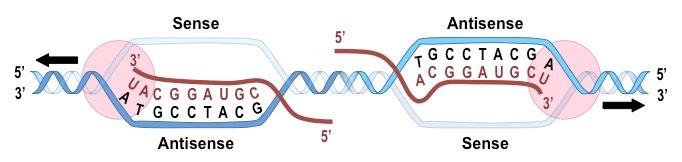
Transcription is the process by which a DNA sequence (gene) is copied into a complementary RNA sequence by RNA polymerase
Free nucleotides exist in the cell as nucleoside triphosphates (NTPs), which line up opposite their complementary base partner
RNA polymerase covalently binds the NTPs together in a reaction that involves the release of the two additional phosphates
The 5’-phosphate is linked to the 3’-end of the growing mRNA strand, hence transcription occurs in a 5’ → 3’ direction
Overview of Transcription
The process of transcription can be divided into three main steps: initiation, elongation and termination
In initiation, RNA polymerase binds to the promoter and causes the unwinding and separating of the DNA strands
Elongation occurs as the RNA polymerase moves along the coding sequence, synthesising RNA in a 5’ → 3’ direction
When RNA polymerase reaches the terminator, both the enzyme and nascent RNA strand detach and the DNA rewinds
Many RNA polymerase enzymes can transcribe a DNA sequence sequentially, producing a large number of transcripts
In eukaryotes, post-transcriptional modification of the RNA sequence is necessary to form mature mRNA
Summary of Transcription
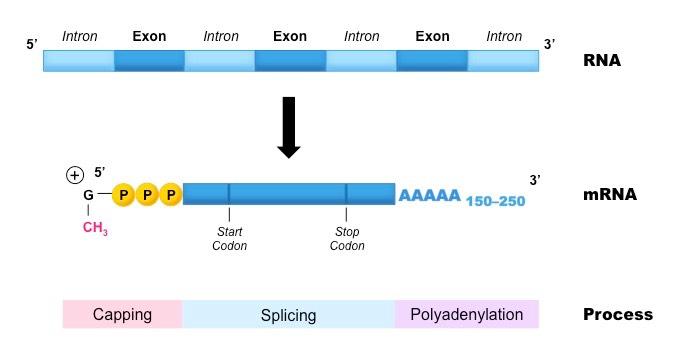
In eukaryotes, there are three post-transcriptional events that must occur in order to form mature messenger RNA:
Capping
Capping involves the addition of a methyl group to the 5’-end of the transcribed RNA
The methylated cap provides protection against degradation by exonucleases
It also allows the transcript to be recognised by the cell’s translational machinery (e.g. nuclear export proteins and ribosome)
Polyadenylation
Polyadenylation describes the addition of a long chain of adenine nucleotides (a poly-A tail) to the 3’-end of the transcript
The poly-A tail improves the stability of the RNA transcript and facilitates its export from the nucleus
Splicing
Within eukaryotic genes are non-coding sequences called introns, which must be removed prior to forming mature mRNA
The coding regions are called exons and these are fused together when introns are removed to form a continuous sequence
Introns are intruding sequences whereas exons are expressing sequences
The process by which introns are removed is called splicing
Post-Transcriptional Modifications
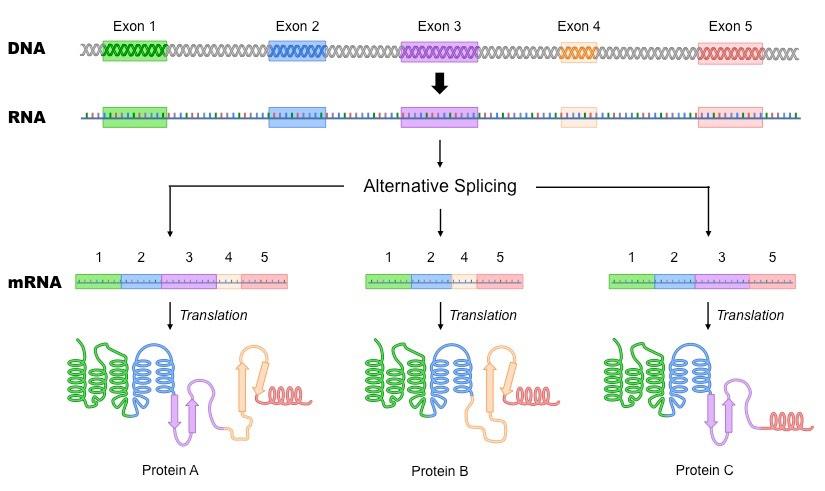
Splicing can also result in the removal of exons – a process known as alternative splicing
The selective removal of specific exons will result in the formation of different polypeptides from a single gene sequence
For example, a particular protein may be membrane-bound or cytosolic depending on the presence of an anchoring motif
Alternative Splicing
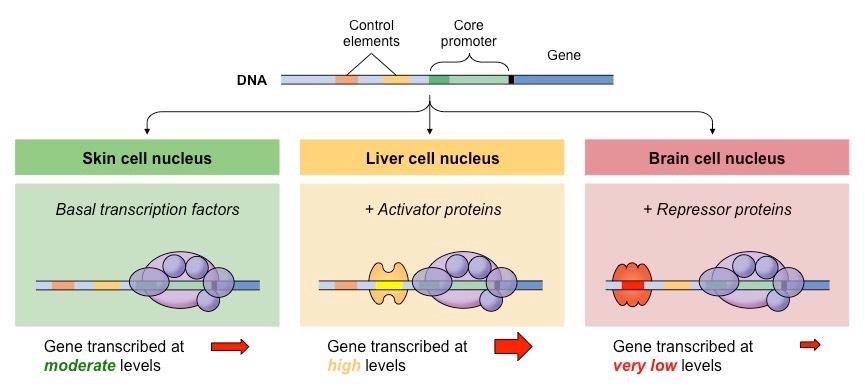
Transcriptional activity is regulated by two groups of proteins that mediate binding of RNA polymerase to the promoter
Transcription factors form a complex with RNA polymerase at the promoter
RNA polymerase cannot initiate transcription without these factors and hence their levels regulate gene expression
Regulatory proteins bind to DNA sequences outside of the promoter and interact with the transcription factors
Activator proteins bind to enhancer sites and increase the rate of transcription (by mediating complex formation)
Repressor proteins bind to silencer sequences and decrease the rate of transcription (by preventing complex formation)
The presence of certain transcription factors or regulatory proteins may be tissue-specific
Additionally, chemical signals (e.g. hormones) can moderate protein levels and hence mediate a change in gene expression
Differential Gene Expression
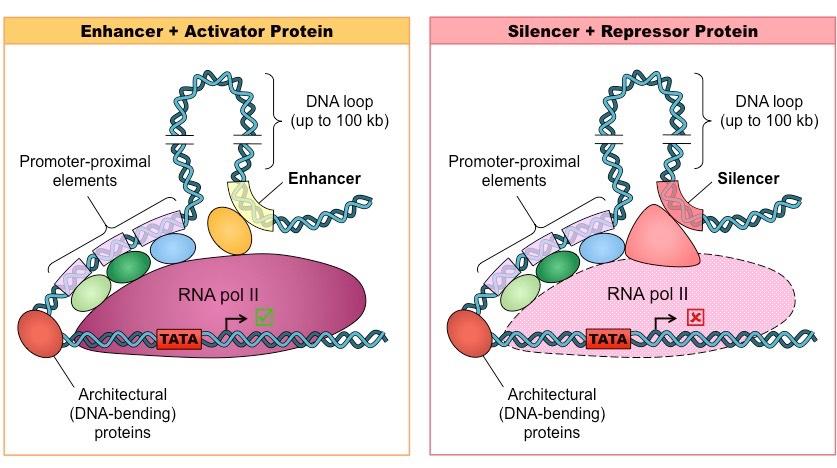
Control Elements
The DNA sequences that regulatory proteins bind to are called control elements
Some control elements are located close to the promoter (proximal elements) while others are more distant (distal elements)
Regulatory proteins typically bind to distal control elements, whereas transcription factors usually bind to proximal elements
Most genes have multiple control elements and hence gene expression is a tightly controlled and coordinated process
Enhancers and Silencers
Changes in the external or internal environment can result in changes to gene expression patterns
Chemical signals within the cell can trigger changes in levels of regulatory proteins or transcription factors in response to stimuli
This allows gene expression to change in response to alterations in intracellular and extracellular conditions
There are a number of examples of organisms changing their gene expression patterns in response to environmental changes:
Hydrangeas change colour depending on the pH of the soil (acidic soil = blue flower ; alkaline soil = pink flower)
The Himalayan rabbit produces a different fur pigment depending on the temperature (>35ºC = white fur ; <30ºC = black fur)
Humans produce different amounts of melanin (skin pigment) depending on light exposure
Certain species of fish, reptile and amphibian can even change gender in response to social cues (e.g. mate availability)
The Role of Soil pH in the Determination of Hydrangea Flower Colour
Eukaryotic DNA is wrapped around histone proteins to form compact nucleosomes
These histone proteins have protruding tails that determine how tightly the DNA is packaged
Modification of Histone Tails
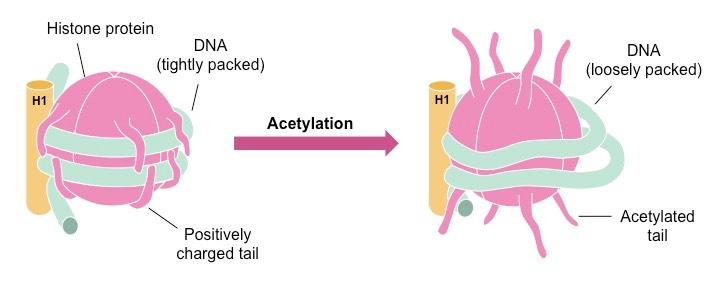
Typically the histone tails have a positive charge and hence associate tightly with the negatively charged DNA
Adding an acetyl group to the tail (acetylation) neutralises the charge, making DNA less tightly coiled and increasing transcription
Adding a methyl group to the tail (methylation) maintains the positive charge, making DNA more coiled and reducing transcription
Acetylation of Nucleosomes
Types of Chromatin
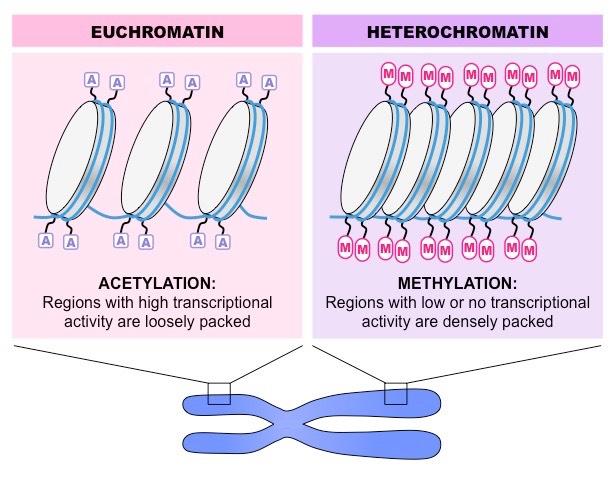
When DNA is supercoiled and not accessible for transcription, it exists as condensed heterochromatin
When the DNA is loosely packed and therefore accessible to the transcription machinery, it exists as euchromatin
Different cell types will have varying segments of DNA packaged as heterochromatin and euchromatin
Some segments of DNA may be permanently supercoiled, while other segments may change over the life cycle of the cell
Nucleosome Packaging in Euchromatin and Heterochromatin
Direct methylation of DNA (as opposed to the histone tails) can also affect gene expression patterns
Increased methylation of DNA decreases gene expression (by preventing the binding of transcription factors)
Consequently, genes that are not transcribed tend to exhibit more DNA methylation than genes that are actively transcribed
Factors Contributing to DNA Methylation Patterns
Epigenetics
Epigenetics is the study of changes in phenotype as a result of variations in gene expression levels
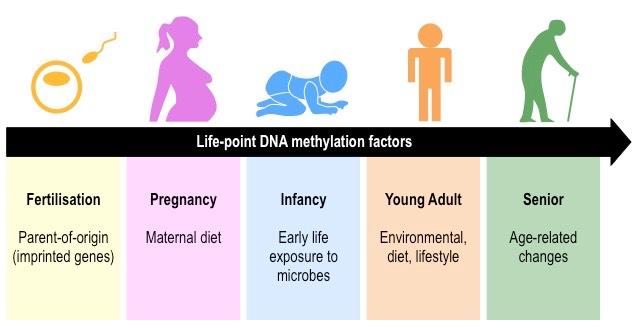
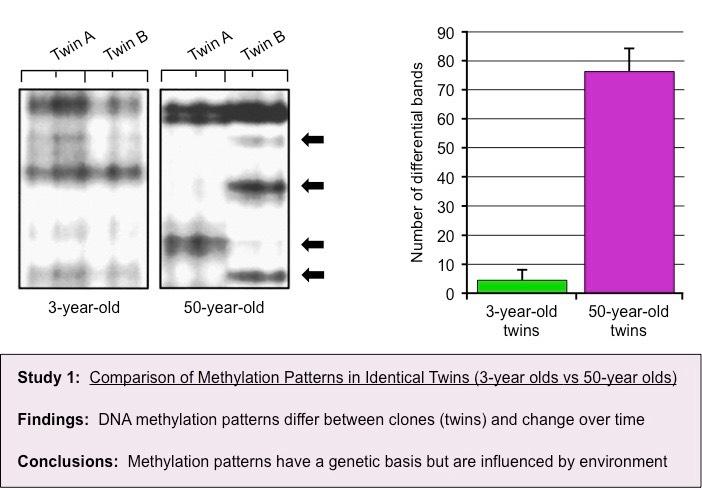
Epigenetic analysis shows that DNA methylation patterns may change over the course of a lifetime
It is influenced by heritability but is not genetically pre-determined (identical twins may have different DNA methylation patterns)
Different cell types in the same organism may have markedly different DNA methylation patterns
Environmental factors (e.g. diet, pathogen exposure, etc.) may influence the level of DNA methylation within cells
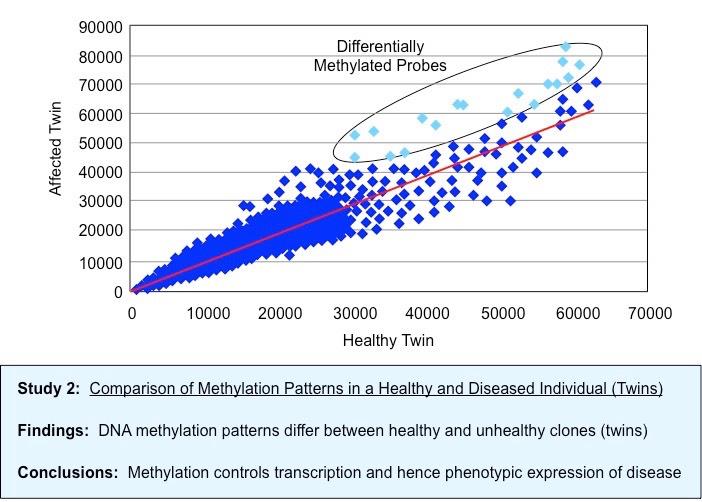
Comparative DNA Methylation Patterns in Twins of Different Ages
Comparative Methylation Patterns in Twins of Differing Health Status (Healthy vs Diseased)
Ribosomes
Ribosomes are made of protein (for stability) and ribosomal RNA (for catalytic activity)
They consist of a large and small subunit:
The small subunit contains an mRNA binding site
The large subunit contains three tRNA binding sites – an aminoacyl (A) site, a peptidyl (P) site and an exit (E) site
Ribosomes can be found either freely floating in the cytosol or bound to the rough ER (in eukaryotes)
Ribosomes differ in size in prokaryotes and eukaryotes (prokaryotes = 70S ; eukaryotes = 80S)
Structure of a Ribosome
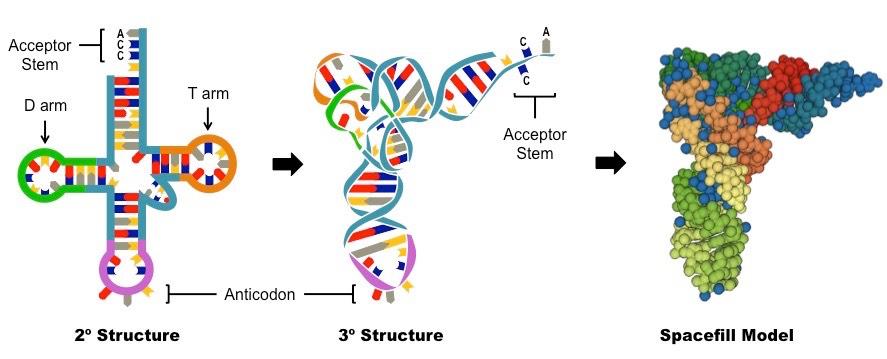
Transfer RNA (tRNA)
tRNA molecules fold into a cloverleaf structure with four key regions:
The acceptor stem (3’-CCA) carries an amino acid
The anticodon associates with the mRNA codon (via complementary base pairing)
The T arm associates with the ribosome (via the E, P and A binding sites)
The D arm associates with the tRNA activating enzyme (responsible for adding the amino acid to the acceptor stem)
Structure of tRNA
Ribosome and tRNA Molecules
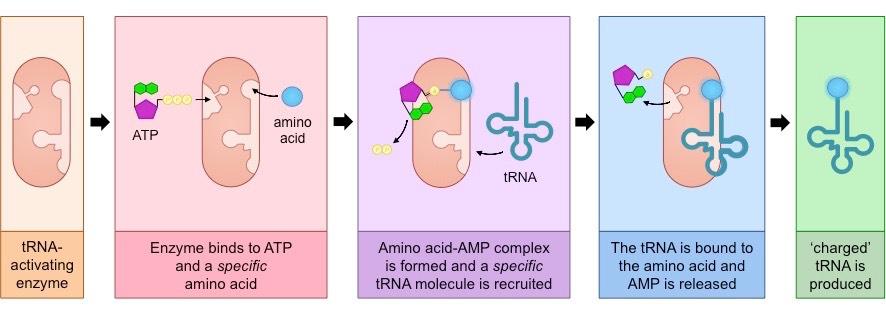
Each tRNA molecule binds with a specific amino acid in the cytoplasm in a reaction catalysed by a tRNA-activating enzyme
Each amino acid is recognised by a specific enzyme (the enzyme may recognise multiple tRNA molecules due to degeneracy)
The binding of an amino acid to the tRNA acceptor stem occurs as a result of a two-step process:
The enzyme binds ATP to the amino acid to form an amino acid–AMP complex linked by a high energy bond (PP released)
The amino acid is then coupled to tRNA and the AMP is released – the tRNA molecule is now “charged” and ready for use
The function of the ATP (phosphorylation) is to create a high energy bond that is transferred to the tRNA molecule
This stored energy will provide the majority of the energy required for peptide bond formation during translation
tRNA Activation
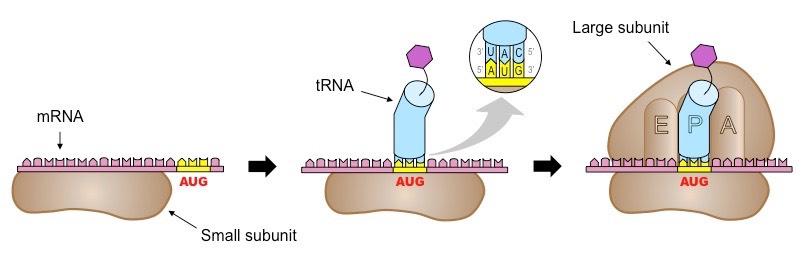
Initiation
The first stage of translation involves the assembly of the three components that carry out the process (mRNA, tRNA, ribosome)
The small ribosomal subunit binds to the 5’-end of the mRNA and moves along it until it reaches the start codon (AUG)
Next, the appropriate tRNA molecule bind to the codon via its anticodon (according to complementary base pairing)
Finally, the large ribosomal subunit aligns itself to the tRNA molecule at the P site and forms a complex with the small subunit
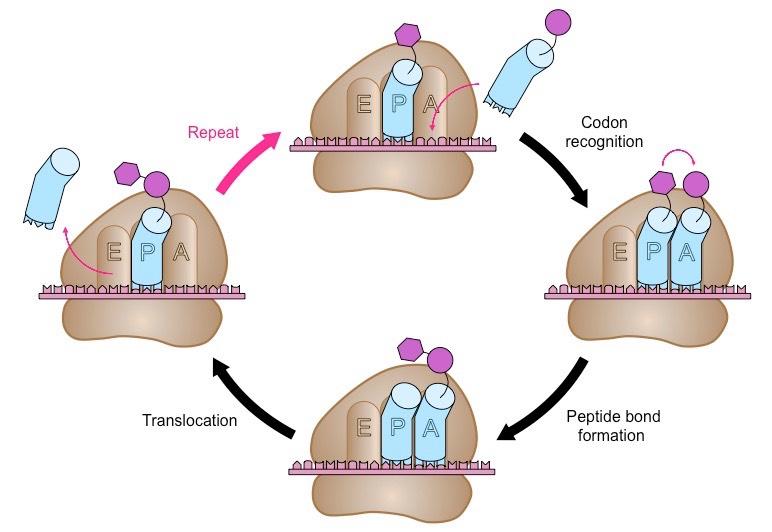
Elongation
A second tRNA molecule pairs with the next codon in the ribosomal A site
The amino acid in the P site is covalently attached via a peptide bond (condensation reaction) to the amino acid in the A site
The tRNA in the P site is now deacylated (no amino acid), while the tRNA in the A site carries the peptide chain
Translocation
The ribosome moves along the mRNA strand by one codon position (in a 5’ → 3’ direction)
The deacylated tRNA moves into the E site and is released, while the tRNA carrying the peptide chain moves to the P site
Another tRNA molecules attaches to the next codon in the now unoccupied A site and the process is repeated
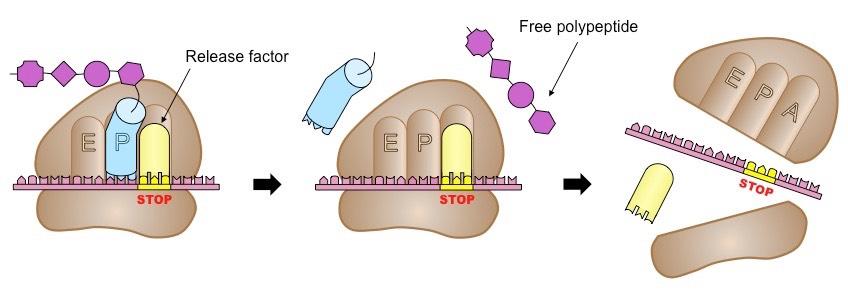
Termination
The final stage of translation involves the disassembly of the components and the release of a polypeptide chain
Elongation and translocation continue in a repeating cycle until the ribosome reaches a stop codon
These codons do not recruit a tRNA molecule, but instead recruit a release factor that signals for translation to stop
The polypeptide is released and the ribosome disassembles back into its two independent subunits
In eukaryotes, the ribosomes are separated from the genetic material (DNA and RNA) by the nucleus
After transcription, the mRNA must be transported from the nucleus (via nuclear pores) prior to translation by the ribosome
This transport requires modification to the RNA construct (e.g. 5’-methyl capping and 3’-polyadenylation)
Prokaryotes lack compartmentalised structures (like the nucleus) and so transcription and translation need not be separated
Ribosomes may begin translating the mRNA molecule while it is still being transcribed from the DNA template
This is possible because both transcription and translation occur in a 5’ → 3’ direction
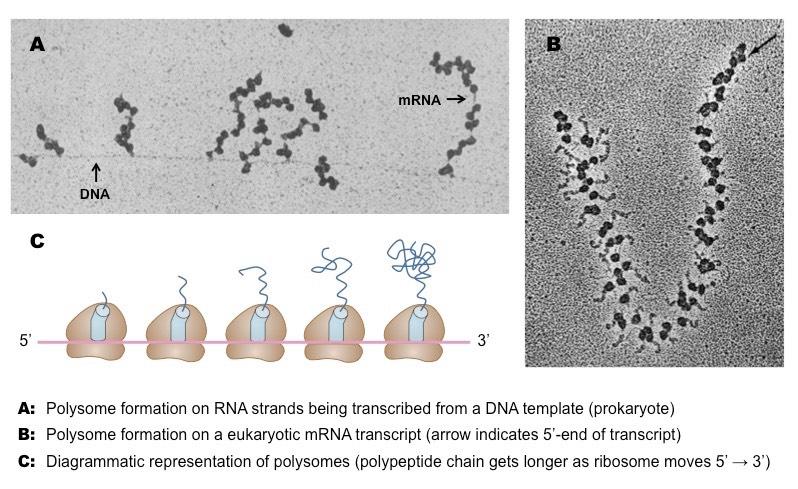
A polysome (or a polyribosome) is a group of two or more ribosomes translating an mRNA sequence simultaneously
The polysomes will appear as beads on a string (each 'bead' represents a ribosome ; the ‘string’ is the mRNA strand)
In prokaryotes, the polysomes may form while the mRNA is still being transcribed from the DNA template
Ribosomes located at the 3’-end of the polysome cluster will have longer polypeptide chains that those at the 5’-end
Polysomes
All proteins produced by eukaryotic cells are initially synthesised by ribosomes found freely circulating within the cytosol
If the protein is targeted for intracellular use within the cytosol, the ribosome remains free and unattached
If the protein is targeted for secretion, membrane fixation or use in lysosomes, the ribosome becomes bound to the ER
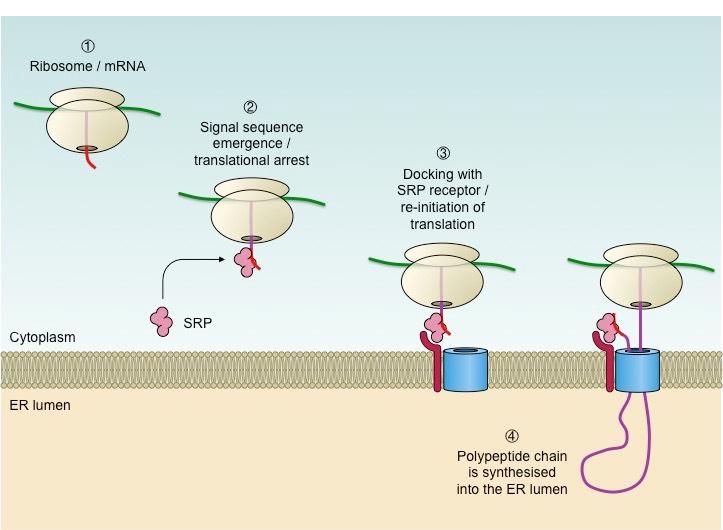
Protein destination is determined by the presence or absence of an initial signal sequence on a nascent polypeptide chain
The presence of this signal sequence results in the recruitment of a signal recognition particle (SRP), which halts translation
The SRP-ribosome complex then docks at a receptor located on the ER membrane (forming rough ER)
Translation is re-initiated and the polypeptide chain continues to grow via a transport channel into the lumen of the ER
The synthesised protein will then be transported via a vesicle to the Golgi complex (for secretion) or the lysosome
Proteins targeted for membrane fixation (e.g. integral proteins) get embedded into the ER membrane
The signal sequence is cleaved and the SRP recycled once the polypeptide is completely synthesised within the ER
The Role of the Signal Recognition Particle in Protein Destination
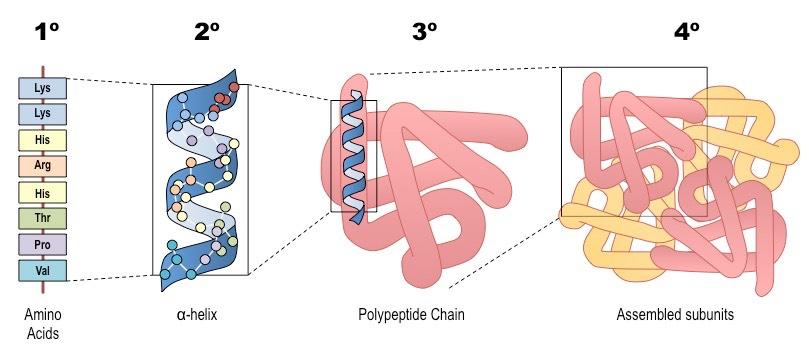
Primary (1º) Structure
The first level of structural organisation in a protein is the order / sequence of amino acids which comprise the polypeptide chain
The primary structure is formed by covalent peptide bonds between the amine and carboxyl groups of adjacent amino acids
Primary structure controls all subsequent levels of protein organisation because it determines the nature of the interactions between R groups of different amino acids
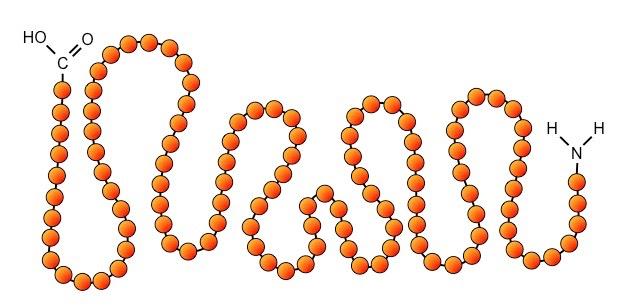
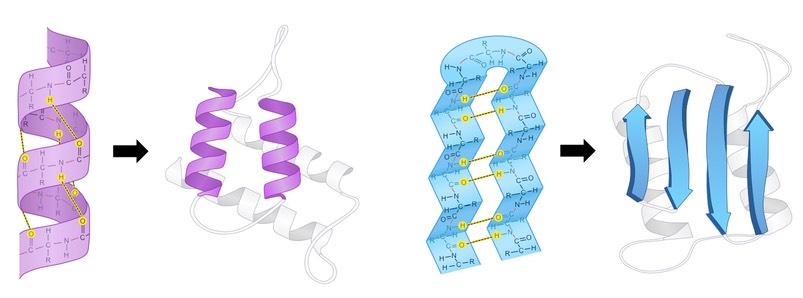
Secondary (2º) Structure
The secondary structure is the way a polypeptide folds in a repeating arrangement to form α-helices and β-pleated sheets
This folding is a result of hydrogen bonding between the amine and carboxyl groups of non-adjacent amino acids
Sequences that do not form either an alpha helix or beta-pleated sheet will exist as a random coil
Secondary structure provides the polypeptide chain with a level of mechanical stability (due to the presence of hydrogen bonds)
In pictures, alpha helices are represented as spirals (purple ; left) and beta-pleated sheets as arrows (blue ; right)
Tertiary (3º) Structure
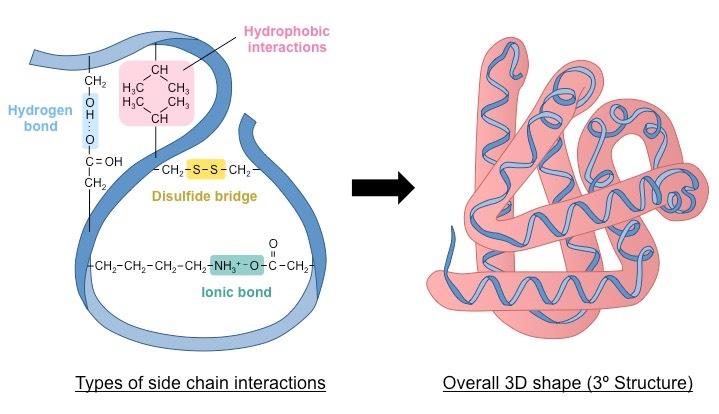
The tertiary structure is the way the polypeptide chain coils and turns to form a complex molecular shape (i.e. the 3D shape)
It is caused by interactions between R groups; including H-bonds, disulfide bridges, ionic bonds and hydrophobic interactions
Relative amino acid positions are important (e.g. non-polar amino acids usually avoid exposure to aqueous solutions)
Tertiary structure may be important for the function of the protein (e.g. specificity of active site in enzymes)
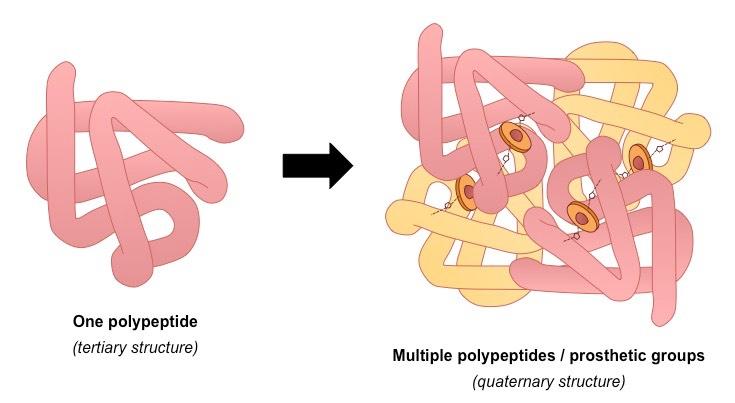
Quaternary (4º) Structure
Multiple polypeptides or prosthetic groups may interact to form a single, larger, biologically active protein (quaternary structure)
A prosthetic group is an inorganic compound involved in protein structure or function (e.g. the heme group in haemoglobin)
A protein containing a prosthetic group is called a conjugated protein
Quaternary structures may be held together by a variety of bonds (similar to tertiary structure)
Summary of the Four Levels of Protein Structure