Testkonstruktion
Vorgehensweise
Itemsatz generieren (nach den Konstruktionsprinzipien: rationale Konstruktion, externale Konstruktion, induktive Konstruktion oder Prototypenansatz)
→ Itempool
an einer Stichprobe erproben (Datenerhebung 1)
Itemanalyse und Itemauswahl (Datenanalyse 1) - Eigenschaften: Schwierigkeit, Trennschärfe, Homogenität
→ vorläufige Testform
nochmal an einer anderen Stichprobe erproben (Datenerhebung 2)
Testbewertung (Datenanalyse 2) - Gütekriterien: Objektivität, Reliabilität, Validität
→ Testendform
Testeichung (Datenerhebung & Datenanalyse 3) - hier werden Normwerte gewonnen
Konstruktionsprinzipien
die rationale Konstruktion (++ökonomisch in Herstellung und leicht kommunizierbar):
auch genannt rationale/deduktive Methode
Ausgangspunkt: Eigenschaftstheorie (bspw. über Intelligenz, Kreativität, Ängstlichkeit, Leistungsmotivation)
Theorie beinhaltet Konstrukte, die theoriegeleitet definiert, spezifiziert und differenziert werden (z.B. Leistungsmotivation = Leistungsmotiv * Situation)
→ Ableitung von indikativen Verhaltensweisen (also Verhalten = Indikator des Konstrukts)
→ Validierung der Skalen erforderlich (z.B. durch Korreation mit Schulnoten)
die externale Konstruktion (++geringe Verfälschbarkeit; - - inhaltliche Itemheterogenität → niedrige Reliabilität?):
auch genannt exernale/kriteriumsbezogene Skalenentwicklung
Ausgangspunkt: Vorliegen verschiedener Personengruppen (der Test soll für deren Klassifikation/Diskriminierung entwickelt werden; bspw. Hauptschüler von Sonderschülern oder schizophrene von manisch-depressiven Menschen unterscheiden)
hierbei ist die theoretische Reflexion der Merkmalsausprägung überflüssig (da es ja nur darum geht zwischen den Gruppen zu trennen, und nicht darum was wirklich dahinter steckt)
→ Itempool soll möglichst groß und inhaltlich breit gefächert sein, es werden Items aufgenommen die besonders gut zwischen den Gruppen trennen können (Iteminhalt egal)
die induktive Konstruktion:
Ausgangspunkt: eine spezifische Methode, nämlich die Korrelationsrechnung
umfangreiche Stichproben von Items und Personen werden erhoben
Items werde “blindanalytisch” zu Skalen zusammengefasst, die miteinander hoch korrelieren (es wird also nur auf die Zahlen geschaut)
Anforderungen an Items und Skalen: interne Konsistenz/Homogenität = hohe Korrelation zwischen Items innerhalb einer Skale + Einfachstruktur = niedrige Korrelationen mit den Items anderer Skalen
Methode: Faktorenanalyse (Faktoren müssen dann anhand der auf ihnen hoch ladenden Items durch Interpretation erschlossen werden)
—> alle ähnlich zielführend
—> Konstruktionsprinzipen ergänzen sich: Generierung Itempool durch rationale Methode, Bereinigung Itempool durch induktive Methode, Validierung Skalen durch externale Methode
Itemselektion
Schwierigkeitsindex (P): gibt an, wie viel % der Probanden einer Stichprobe ein Item im Sinne einer höheren Merkmalsausprägung (bei Leistungstests = richtig; bei Persönlichkeitstests = im Sinne des Merkmals zustimmend) beantwortet haben
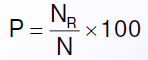
NR = Anzahl der Vpn, die im Sinne des Merkmals antworteten
N = Anzahl aller Vpn
P=0 oder P=100 ist nicht gut weil man dann nicht zwischen Probanden hoher/niedriger Ausprägung differenzieren kann, alle antworten gleich
P=50 maximale Differenzierung zwischen Probanden mit mittlerer Ausprägung
Items mit extremer Schwierigkeit (P = 5 – 10 oder 90-95) ermöglichen eine Differenzierung zwischen den Probanden im oberen oder unteren Bereich der Merkmalsausprägung.
!! Problem bei extremen Schwierigkeiten: fast alle antworten gleich also eingeschränkte Varianz, wodurch Korrelationen zwischen solchen Items mit anderen Items/Testwerten behindert werden
→ man möchte eine breite Streuung der Schwierigkeit (zwischen 5 und 95)
Trennschärfe (rit): Korrelation zwischen Itemvariable (Itemscores/-werte) und Testvariable (Summenscores/-werte) einer Skala → Kennwert für das Ausmaß der Übereinstimmung zwischen Item und Skala (“Wie repräsentativ ist das Item für den Test/die Skala?”)
also: je höher die Trennschärfe, desto mehr trägt ein Item zur Messung dessen bei, was durch den gesamten Test gemessen wird
Gütekriterien
Objektivität = Ausmaß in dem die Ergebnisse eines Tests unabhängig von der Person des Untersuchungsleiters sind
kann in Durchführung, Auswertung und Interpretation beeinträchtigt/gefährdet sein → Formen: Durchführungsobjektivität, Auswertungsobjektivität, Interpretationsobjektivität
→ Sicherung durch Standartisierung der drei Phasen (Bestimmung der Objektivität: rational)
Reliabilität = technische Genauigkeit, mit der ein Test misst was er misst
Reliabilitätskoeffizient = Anteil der Truescorevarianz an der gemessenen Varianz [Wertebereich 0 - 1]
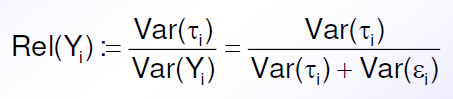
Interpretation:
unter .80 niedrig
zwischen .80 und .90 mittel
über .90 hoch
Messung des Reliabilitätskoeffizienten setzt eine mehrfache (also mindestens doppelte) Messung und ein Messmodell voraus
→ Reliabilität von Y1 und Y2 kann durch ihre Korrelation geschätzt werden (beide haben dabei dieselber Reliabilität)
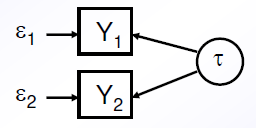
Annahmen:
tau-Equivalenz also hinter beiden Messung steckt der gleiche tau Wert
unkorrelierte Fehler also Cov(\epsilon1,\epsilon2)=0
gleiche Fehlervarianzen also Var(\epsilon1)=Var(\epsilon2)=:Var(\epsilon)
!!! Problem: Annahmen im Rahmen der KTT nicht überprüfbar
—> LÖSUNG: Strukturgleichungsmodelle
Wie kann die “doppelte Messung” praktisch umgesetzt werden?
Retest-Methode
Paralleltest-Methode
Testhalbierungs-Methode
→ dann Schätzung der Reliabilität durch Retest-/Paralleltest-/Testhälfte-Korrelation (bei letzterem mit Spearman-Brown-Formel), oder Cronbachs alpha (bei mehr als 2 Testteilen)
Validität = Ausmaß, mit dem ein Test tatsächlich das Konstrukt misst, dass er messen soll/vorgibt zu messen (Inhaltliche, Kriteriumsbezogene, Konstruktvalidität)
Validitätskoeffizient rtc = Korrelation zwischen Test und Kriterium (dann gibt es noch echte Kriterien vs Quasi-Kriterium; ultimative vs. aktuelle Kriteren; konkurrente vs. prädiktive Validität)
Konstruktvalidität = Einbettung des mit einem Test erfassten Konstruktes in das nomologische Netzwerk anderer (un)ähnlicher Konstrukte (konvergente vs diskriminante Validität)
!!! Probleme:
Kriteriumsvalidität: Messwerte sind mit Messfehlern kontaminiert, die jeden systematischen Zusammenhang mindern
Konstruktvalidität: Interpretation von Multitrait-Multimethod-Matrizen ist mühsam und oft uneindeutig, Validität von State-Trait-Skalen wird nur indirekt erschlossen, Veränderungsmessungen sind besonders anfällig für Messfehler
Faktorielle Validität (=strukturelle/interne Validität): Entscheidungskriterien zur Bestimmung der Faktorzahl bei explorativen Faktorenanalysen sind nur heuristisch
—> LÖSUNG: Strukturgleichungsmodelle
Normierung: liefert ein Bezugssystem, um Porbanden anhand ihrer Testwerrte in Relation zu Personen einer repräsentativen Stichprobe einzuordnen (= statistische Interpretation der Scores)
es gibt Äquivalenz-/Abweichungs-/Prozentrangnormen