BioNinja Notes- Genetics
Transcription
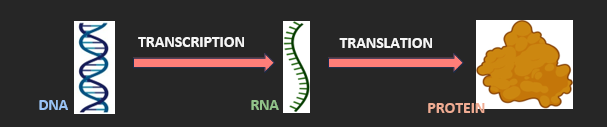
CENTRAL DOGMA
The central dogma of molecular biology describes the flow of genetic information within living organisms:
• DNA is a cell’s genetic ‘blueprint’ and is organised into instructions (or genes) that encode specific traits
• RNA is a temporary ‘photocopy’ of a gene, which is made via transcription and sent to the ribosomes
• Proteins are synthesised by the ribosomes via translation and carry out the encoded cellular functions
CENTRAL DOGMA
The central dogma of molecular biology describes the flow of genetic information within living organisms:
• DNA is a cell’s genetic ‘blueprint’ and is organised into instructions (or genes) that encode specific traits
• RNA is a temporary ‘photocopy’ of a gene, which is made via transcription and sent to the ribosomes
• Proteins are synthesised by the ribosomes via translation and carry out the encoded cellular functions

TYPES OF RNA
There are three main types of RNA that are encoded by genes and involved in the synthesis of proteins:
• Messenger RNA (mRNA) is the transcript copy of a DNA instruction (it encodes the protein sequence)
• Transfer RNA (tRNA) carries the protein subunits (amino acids) to the mRNA transcript for assembly
• Ribosomal RNA (rRNA) acts to provide the catalytic activity for combining the amino acids together

TRANSCRIPTION
Transcription is the process by which a DNA sequence (gene) is copied into complementary RNA sequences by RNA polymerase. This enzyme binds to the promoter and then separates the double-stranded DNA of the coding sequence (by breaking the hydrogen bonds between base pairs). Free RNA nucleotides then align opposite their complementary base partner and RNA polymerase joins them together with covalent bonds (between the sugar-phosphate backbone). When the enzyme reaches the terminator sequence the synthesised RNA transcript is released and the double helix reforms. Transcription occurs in the nucleus.
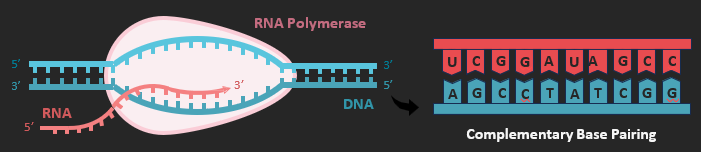
The RNA transcript has a sequence that is complementary to the DNA template. This is because the DNA bases can form hydrogen bonds with particular RNA nucleotides. Adenine always pairs with uracil via two hydrogen bonds, while guanine and cytosine always pair via three hydrogen bonds. This system of base pairing ensures that the RNA transcript is always a correct and reliable copy of the genetic instructions.
GENE EXPRESSION
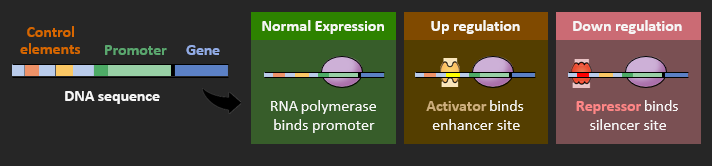
The expression of genes is coordinated by transcription factors, which are produced by regulatory genes. Transcription factors either mediate or impede the binding of RNA polymerase to the promoter, and hence function to help switch genes on and off. There are two main types of transcription factors:
• Activator proteins bind to enhancer sites and essentially function to increase transcription rates
• Repressor proteins bind to silencer sites and essentially function to decrease transcription rates
The presence of certain transcription factors may be tissue-specific, leading to the differentiation of cells and tissues. Additionally, chemical signals can moderate the activity of transcription factors and hence change gene expression (e.g. hormones may activate target tissues by altering gene expression patterns). The study of changes in organisms as a result of variations in gene expression levels is called epigenetics.
CELL DIFFERENTIATION
All cells in a multicellular organism contain the same genetic instructions. The totality of DNA sequences (both genes and non-coding DNA) within a cell or organism is called the genome. However, different genes may be activated in certain tissues, leading to the production of different proteins. The totality of proteins expressed within a cell or organism at a particular time is called the proteome. Because different cell types express different genes and produce different proteins, they may differ in both morphology and function.
Translation
TRANSLATION
Translation is the process of protein synthesis, in which genetic information encoded in mRNA is translated into a sequence of amino acids (polypeptide).
• Messenger RNA (mRNA) is transported to the ribosomes (in the cytosol)
• Ribosomes read the mRNA sequence in triplets of bases called codons
• Codons code for specific amino acids according to a genetic code
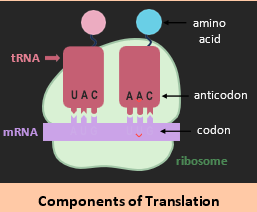
• Amino acids are brought to the ribosome by transfer RNA (tRNA)
• Transfer RNA binds to specific codons via complementary anticodons
• Anticodons cause tRNA molecules to line up according to codon order
• Peptide bonds form between amino acids (catalysed by the ribosome)
• Polypeptides are produced as the ribosome moves along the mRNA
RIBOSOMES
Hint: MR CAT APP
The ribosome is made up of two distinct subunits – each composed of protein and ribosomal RNA (rRNA):
• The small subunit binds to the messenger RNA (mRNA), which is read in triplets of bases called codons
• The large subunit contains binding sites for two tRNA molecules, which each carry a specific amino acid
The role of the ribosome is to transfer the amino acid from one tRNA molecule to the next, sequentially growing a polypeptide chain as it moves along the mRNA. Once a given tRNA molecule has transferred its amino acid to a chain, it is released in order to collect another amino acid for future use. Ribosomes initiate translation when they reach a start codon (AUG) and terminate translation when they reach a stop codon. The start codon acts to establish the appropriate reading frame in which the triplets
of mRNA bases are read (translated) by the particular ribosome. Multiple ribosomes can translate an mRNA sequence at once.
GENETIC CODE
The genetic code is the set of rules that identifies which amino acid corresponds to each mRNA codon. It is typically represented as a table. The genetic code possesses two key characteristics:
• Universality: Almost every living organism uses the same code (there are a few viral exceptions)
• Degeneracy: Some codons code for the same amino acid (there are 64 codons and only 20 amino acids)
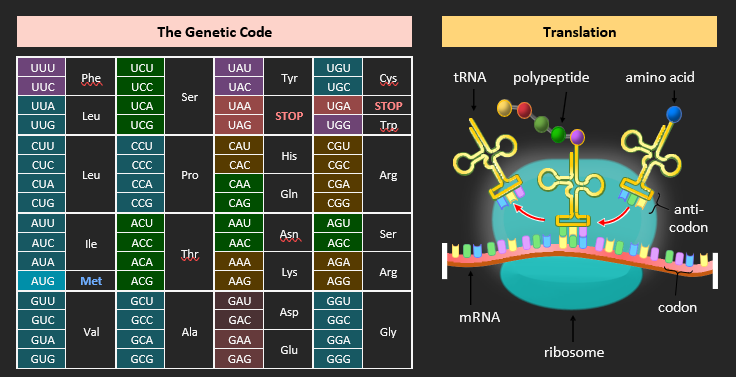
The codons are recognised by anticodons on specific tRNA molecules. The codons and the anticodons are complementary in base sequence, ensuring correct pairing. Guanine and cytosine undergo complementary pairing, while adenine partners with uracil. For instance, a codon with a sequence of AUG will correspond to anticodons with a sequence of UAC. Complementary pairing ensures sequences are correctly translated.
GENETIC DISEASES
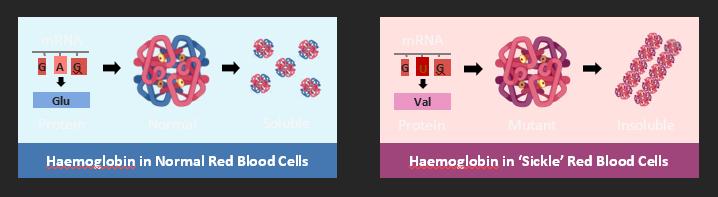
As proteins are encoded by DNA sequences (genes), a change in nucleotide sequence can alter the protein structure. If a change in protein sequence leads to the abrogation of its function, a disease condition may arise. An example of a genetic disease caused by a mutation that changes protein structure is sickle cell anaemia. Sickle cell anaemia results from a mutation to the gene coding for haemoglobin. The mRNA sequence is changed from GAG → GUG, which in turn changes the amino acid sequence from glutamic acid to valine (Glu → Val). The haemoglobin now forms insoluble fibrous strands that cannot carry oxygen as effectively (resulting in anaemia). The fibrous strands also change the shape of the red blood cell to a sickle shape, which are destroyed more rapidly than normal cells, leading to a much lower red blood cell count.
Mutations
GENE MUTATIONS
A gene mutation is a change in the nucleotide sequence of a section of DNA encoding for a specific trait. Mutations can give rise to new versions of a gene (called alleles) and hence change the observable features of an organism (creating variation). Only germ line mutations (in gametes) will produce heritable variation, somatic mutations (in body cells) cannot be passed on to offspring. There are several types of mutations.
Mutations that occur within non-coding DNA sequences will not typically change the characteristics of an organism (unless they impact gene expression levels) and hence do not usually influence genetic diversity.
SOURCES OF MUTATION
Gene mutations can be caused by proofreading errors during DNA replication. Normally, the enzyme that is responsible for copying the DNA sequence (DNA polymerase) will detect and remove any incorrectly paired nucleotides. A mutation will result if an incorrectly incorporated nucleotide is not replaced when copied.
Gene mutations can also be caused by mutagenic agents. Mutagens induce a permanent change to the genetic material of an organism (increasing the frequency of mutations above a natural background level). Physical mutagens include certain forms of radiation (including X-rays and UV light). Chemical mutagens include substances such as reactive oxygen species, certain metals (e.g. arsenic) and alkylating agent (which can be formed by grilling meat). Biological mutagens include certain viruses (HPV) and bacteria (H. pylori).
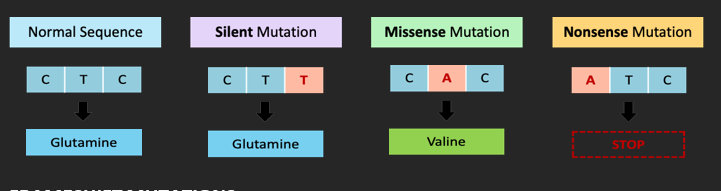
POINT MUTATIONS
Point mutations involve a change to a single base within the DNA code. This may involve base substitution (one nucleotide is replaced by another) or inversion (two adjacent nucleotides swap positions). There are three main mechanisms by which a point mutation may affect polypeptide production by a specific gene:
• Silent mutation: When a DNA change does not alter amino acid sequence (due to codon degeneracy)
• Missense mutation: When a DNA change alters a single amino acid in the polypeptide chain
• Nonsense mutation: When a DNA change creates a premature STOP codon (truncating a polypeptide)
FRAMESHIFT MUTATIONS
Frameshift mutations involve a change that alters the reading frame of the DNA code. This may involve the addition (insertion) or removal (deletion) of a nucleotide, meaning every codon after this point is changed.

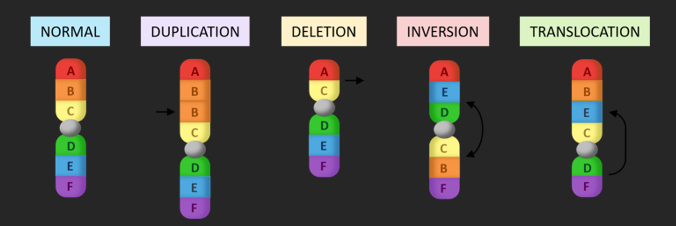
BLOCK MUTATIONS
Block mutations are changes to segments of a chromosome, leading to large scale changes to the DNA of an organism. Several different types of block mutations can occur to alter the sequence of a chromosome:
• Duplications: Part of a chromosome is copied, resulting in duplicate sections (increases expression)
• Deletions: A portion of the chromosome is removed (along with any genes contained in the segment)
• Inversions: A chromosome segment is rearranged in the reverse order of the original sequence
• Translocations: A chromosome sequence is moved to a new location (even a different chromosome)
Mutations are the only means of creating new alleles. Sexual reproduction can cause genetic reassortment (creating new combinations of alleles) and chromosomal abnormalities such as aneuploidy and polyploidy can result in more, or less, copies of a particular allele, but only via gene mutations can entirely new alleles be created within a population (but new alleles can be introduced from other populations via migration).
Transcription
GENETICS
DNA functions as the genetic blueprint for cells. DNA codes for protein – which function to manifest specific characteristics. Genes are sequences of DNA that code for particular proteins. Each gene will have a unique base sequence that is transcribed into RNA and, in turn, translated into a polypeptide in response to signals within a cell. Not all DNA sequences consist of protein-encoding genes – the majority of DNA is non-coding.
NON-CODING DNA
Non-coding DNA has been found to serve a variety of different purposes within cells:
• Satellite DNA sequences (e.g. short tandem repeats) are used for DNA profiling
• Telomeres (chromosome ends) function to prevent chromosomal deterioration
• Introns are non-coding sequences within protein-encoding genes in eukaryotes
• Non-coding genes produce RNA that does not code for proteins (tRNA and rRNA)
• Gene regulatory sequences moderate transcription (e.g. enhancers or silencers
GENES
A gene is composed of three key sections. The promoter is the site to which the enzyme RNA polymerase will bind – it is responsible for initiating transcription. The coding sequence is the region of DNA that is transcribed into RNA, while the terminator sequence functions to stop transcription by RNA polymerase. Basically, genes consist of start regions (promoter), copying regions (coding) and stop regions (terminator).
TRANSCRIPTION
Transcription is the process by which a DNA sequence (gene) is copied into complementary RNA sequences by RNA polymerase. This enzyme binds to the promoter and then separates the double-stranded DNA of the coding sequence (by breaking the hydrogen bonds between base pairs). Free RNA nucleotides then align opposite their complementary base partner and RNA polymerase joins them together with covalent bonds (between the sugar-phosphate backbone). When the enzyme reaches the terminator sequence the synthesised RNA transcript is released and the double helix reforms. Transcription occurs in the nucleus.
DIRECTIONALITY
DNA is a double-stranded molecule and genes can occur on either strand. The carbon atoms in the pentose sugar of a nucleotide are numbered. The phosphate group is always attached to the 5’-carbon and will be connected to another nucleotide via the 3’-carbon. In transcription, new strands are made in a 5’ → 3’ direction. Ribosomes also translate by reading the mRNA in a 5’ → 3’ direction.
TRANSCRIPTION FACTORS
The expression of genes is coordinated by transcription factors, which are produced by regulatory genes. Transcription factors either mediate or impede the binding of RNA polymerase to the promoter sequence:
• Activator proteins bind to enhancer sites and mediate promoter binding (gene ‘on’ – ↑ transcription)
• Repressor proteins bind to silencer sites and impede promoter binding (gene ‘off’ – ↓ transcription)
The presence of certain transcription factors may be tissue-specific or regulated by certain chemical signals. The study of changes in organisms as a result of variations in levels of gene expression is called epigenetics.
RNA PROCESSING
In eukaryotes, there are three post-transcriptional events that must occur in order to form messenger RNA.
• Capping: A methyl group is added to the 5’-end of the transcript to prevent degradation by nucleases
• Polyadenylation: A poly-A tail is added to the 3’-end in order to improve the stability of the transcript
• Splicing: Non-coding sequences are removed and the expressing sequences are then fused together Non-coding sequences within a gene are called introns, whereas the coding sequences are known as exons.

ALTERNATIVE SPLICING
Splicing typically results in the removal of introns by a complex called the spliceosome – however, exons can also be selectively removed via a process known as alternative splicing. The removal of exon segments will result in the formation of different polypeptides from a single gene sequence. This is one way a proteome can be larger than the genome, as multiple protein variants can be produced from a genetic sequence.
An example of an application for alternative splicing is the production of different versions of the same protein. For instance, an enzyme can be cytosolic or membrane-bound based on the presence or absence of an anchoring motif. Alternative splicing in fruit flies results in the production of different versions of a particular protein in females and males (contributing to morphological differences between the sexes).
Translation
TRANSLATION
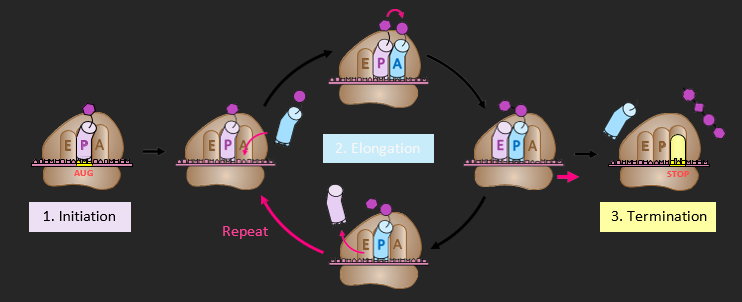
Protein synthesis (translation) occurs at the ribosome, which is composed of a large and small subunit. The small subunit binds to mRNA and moves along in a 5’ → 3’ direction until it reaches a start codon (AUG) to which an initiator tRNA has attached. A large ribosomal subunit binds to the initiator tRNA (via the P site), completing the ribosomal complex. Another tRNA molecule binds to the ribosomal A site and the tRNA in the P site transfers its amino acid to this new molecule. The ribosome moves along one codon position (in a 5’ → 3’ direction). The deacylated tRNA is now in the E site and is released. A new tRNA molecule enters the unoccupied A site and the process of amino acid transfer is repeated. This cycle continues the length of the codon sequence until a stop codon is reached. At this point, a release factor binds and causes both the ribosome and the polypeptide chain to dissociate from the mRNA – completing the process of translation.
PROTEIN DIVERSITY
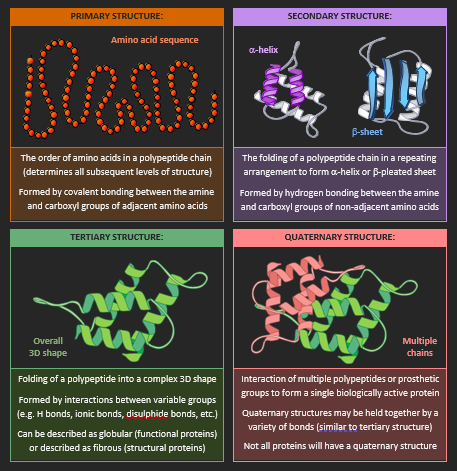
Proteins are comprised of long chains of recurring monomers called amino acids. Amino acids all share a common basic structure, with a central carbon atom bound to an amine group, a carboxyl group and a variable side chain. There are 20 different amino acids, each with a distinct side chain (i.e. R group). The different chemical properties of these side chains cause a protein to fold differently according to the sequence of amino acids (different order = altered protein structure).
PROTEIN STRUCTURE
Amino acids are joined via condensation reactions to form polypeptide chains that are linked together by peptide bonds. These polypeptide chains may be organised into four hierarchical levels of protein structure
TYPES OF PROTEINS
Proteins may be broadly categorised according to their tertiary structure organisation or core functionality. Examples of these protein categories include fibrous proteins, globular proteins and membrane proteins.
Fibrous Proteins
Fibrous proteins are typically long and narrow in shape due to a repetitive amino acid sequence. They have structural roles within organisms and are typically insoluble in water (external amino acids are non-polar). An example of a fibrous protein is collagen (prominent in the extracellular matrix and connective tissues).
Globular Proteins
Globular proteins are typically round and spherical with an irregular amino acid sequence. They will possess functional roles within an organism and are generally soluble in water (the external amino acids are polar). An example of a globular protein is insulin (hormone transported in the blood to regulate glucose levels).
PROTEIN MODIFICATIONS
Many proteins need to be modified before they can function. Insulin is a protein that requires post-translational modification. It is produced as an inactive precursor called pre-proinsulin and will undergo a two-step modification process. Pre-proinsulin is converted to proinsulin when a signal sequence is removed in the rough ER (this sequence was needed to direct the ribosome to the ER). As proinsulin folds in the Golgi body, the opposite ends of the protein (A and B chains) will become linked by disulphide bridges and the intervening segment (called the C peptide) is
removed. Functional insulin molecule is stored in the Golgi until needed.
PROTEIN TRANSPORT
All proteins produced by eukaryotic cells are initially synthesised by ribosomes found freely floating in the cytosol. If the protein is targeted for intracellular use within the cytosol, the ribosome remains unattached. However, if the protein is destined for secretion (extracellular use), the will ribosome become bound to the endoplasmic reticulum. The rough ER packages these proteins into vesicles and transfers them to the Golgi complex. These proteins can either be released by the Golgi body immediately (constitutive secretion) or can be indefinitely stored in secretory vesicles for delayed – but sustained – release (regulatory secretion).
PROTEASOMES
Maintaining a functional proteome requires the continual breakdown of superfluous proteins to enable the synthesis of new ones. Proteasomes are protein complexes that degrade polypeptides that are misfolded or no longer needed by the cell. They are used by the cell to help regulate expression levels and recycle amino acids. Proteins are targeted to the proteasome after being tagged with a short polypeptide called ubiquitin.
Epigenetics
GENE EXPRESSION
Gene expression is the process by which information encoded within genes is used to create proteins. Gene expression involves two sequential steps – transcription (DNA → mRNA) and translation (mRNA → protein). The products of gene expression collectively give rise to the genome, transcriptome and proteome of a cell.
• Genome: Totality of genetic information in a cell, tissue or organism (all genes and non-coding DNA)
• Transcriptome: All genetic instructions that have been actively transcribed to RNA (mRNA, tRNA, tRNA)
• Proteome: The complete set of proteins expressed within a cell, tissue or organism at a particular time While a genome will be identical between all of cells in an organism, transcriptomes and proteomes vary.
GENE REGULATION
Gene expression levels can be moderated at the level of the proteome, the transcriptome or the genome:
1. Expression levels can be controlled by regulating the amount of protein produced (translational control)
2. Expression can be controlled by regulating the amount or the activity of mRNA (transcriptional control)
3. Expression can be controlled by regulating the accessibility of the genes (histone or DNA modification)
By regulating gene expression, cells can become specialised and differentiate despite having shared genetic instructions – this also allows the phenotype of organisms to change while the genotype remains the same.
TRANSLATIONAL CONTROL
Gene expression may be regulated by controlling the degradation of mRNA transcripts. Within human cells, mRNA may persist for time periods from minutes up to days, before being broken down. As mRNA provides the instructions required by the ribosomes for protein assembly, the longevity of the transcripts determines the expression levels of a gene – the longer a transcript lasts before degradation, the greater the amount of protein produced. The mRNA transcripts are broken down by nucleases to form single nucleotides that can be recycled by the cell. This degradation alters the transcriptome within a cell at a particular point of time.
TRANSCRIPTION FACTORS
Gene expression may also be regulated by controlling the rate at which mRNA transcripts are produced. The process of transcription is initiated by the binding of RNA polymerase to a promoter. Certain proteins – called transcription factors – mediate this binding. Transcription factors may either bind to the promoter directly, or to DNA sequences outside of the promoter. Activator proteins bind to enhancer sites and act to increase the rate of transcription. Repressor proteins bind to silencer sites and decrease transcription rates. The presence of certain transcription factors may be tissue specific, leading to a differentiation of cell types.
TRANSCRIPTION SIGNALS
The activity of any given transcription factor can be controlled by either intracellular or extracellular signals.
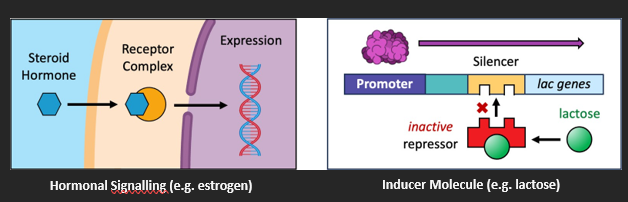
An example of an extracellular signal is a hormone – a chemical messenger transported in blood. Steroid hormones bind to receptors within the cell to form a complex that will act as a transcription factor. Peptide hormones bind to receptors on plasma membranes and act to control transcription via second messengers.
An example of an intracellular signal is an inducer molecule – such as lactose. Lactose binds to a repressor protein that supresses the transcription of genes responsible for lactose metabolism. The binding of lactose prevents the repressor from functioning – hence lactose metabolism occurs when lactose is present in cells.
EPIGENESIS
Epigenesis describes the specific development of an organism from an undifferentiated zygote to a complex multicellular organism via differential gene expression. The activation of different genes in different cells of a multicellular organism will lead to different patterns of development in these cells. This causes these cells to have different characteristics even though their base sequences are identical (their phenotype is altered but not their genotype). Epigenetic changes are triggered by specific chemical modifications to DNA (called epigenetic tags). These epigenetic tags do not alter the DNA base sequence and are potentially reversible.
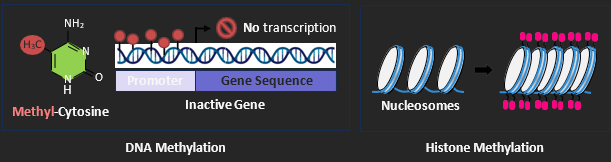
METHYLATION
One specific chemical modification that acts as an epigenetic tag is the addition of a methyl group (-CH3) to either DNA (at the promoter) or histones (within the nucleosome). In eukaryotic cells, methylation of DNA predominantly occurs at cytosine bases that are immediately adjacent to a guanine base (a CpG island). A majority of eukaryotic genes have CpG islands within their promoter sequence and the direct methylation of the promoter impedes the downstream activity of RNA polymerase. Hence DNA methylation functions to reduce transcriptional activity in eukaryotic cells by inactivating transcription (the gene is switched ‘off’).
In eukaryotic organisms, the DNA is associated with histone proteins to form a condensed complex known as a nucleosome. The histone proteins have protruding tails that are positively charged, which allows the histone to associate with the negatively charged DNA. Adding a methyl group to the histone tail maintains the positive charge, making DNA more coiled and reducing transcription. Individual nucleosomes are linked together (like beads on a string) to form chromatin. When the histones are methylated, the DNA becomes supercoiled (tightly packed) and not accessible for transcription – existing as condensed heterochromatin. The removal of methyl tags will cause the DNA to become more loosely packed and therefore accessible to the transcription machinery (euchromatin). Different cell types will have different DNA segments packaged as heterochromatin and euchromatin depending on which genes are active within the cell. Some segments of DNA may be permanently supercoiled, while other segments may change over the life cycle of the cell.
ENVIRONMENTAL TRIGGERS
Air pollutants are an example of environmental factors that can affect the methylation of DNA in a person. Several traffic-related pollutants have been associated with changes in DNA methylation – such as nitrogen oxides and polyaromatic hydrocarbons (PAH). In general, air pollution mediates a reduction in methylation across the genome, although methylation at some sites may be increased. Air pollution is specifically linked to the methylation of immunoregulatory genes, leading to increased inflammation and an altered immune profile. These methylation patterns result in the manifestation of cardiopulmonary complications – such as high blood pressure and asthma. A change in methylation is also a common cause for some types of cancer. Air pollutants may act by affecting the action of the methylating enzyme – DNA methyltransferase (DNMT).
MONOZYGOTIC TWIN STUDIES
The role of external environmental stimuli on gene expression can be demonstrated by comparing epigenetic profiles of monozygotic twins. Monozygotic twins result from the division of a fertilised egg into two distinct embryos that have an identical genome (i.e. they are clones). By comparing the methylation pattern of monozygotic twins, the role of the environment in phenotypic development can be assessed. DNA methylation patterns will differ between twins and will differ further over time as a result of exposure to unique environmental conditions. DNA methylation patterns can be used to identify genes that may be involved in the development of specific diseases (present in one twin).
EPIGENETIC INHERITANCE
Complex organisms develop from undifferentiated cells as a consequence of the programmed expression of genes via epigenetic tags. Different genes are switched ‘on’ or ‘off’ in specific cells to promote development of distinctive cell lines (tissues). As egg and sperm cells develop from differentiated germline cells, the tags that already exist in these cells must be erased to allow for epigenesis to occur upon fertilisation. Gametes must be reprogrammed via epigenetic tag removal to return them to a blank genetic slate. Reprogramming ensures that the early embryo can form every type of cell in the body by resetting an embryo’s epigenome.
IMPRINTED GENES
A small proportion of genes do not undergo reprogramming during gamete production and will retain their epigenetic tags. These sequences are called imprinted genes and allow phenotypic changes to be passed on to offspring. The presence of imprinted genes can explain the size differences seen in ligers and tigons (lion-tiger hybrids). Lions live in social groups where a single lioness may mate with many males and birth cubs from multiple fathers. A male lion is incentivised to have the largest offspring (better for cub survival) and hence will produce sperm containing imprinted genes promoting growth. But a lioness is incentivised to have small offspring (lower birth risk) and produces eggs containing imprinted genes to restrict growth. The combination of these imprinted genes will cancel each other out and result in normal-sized cubs. Tigers are solitary animals and a tigress only produces a litter with cubs from a single male. As such, imprinted genes are not needed. When a lion and tiger successfully mate, the different imprinted genes present in the parents determines offspring size. In ligers (male lion × female tiger), the male lion’s imprinted genes result in a large size. In tigons (male tiger × female lion), a lack of this imprinted gene prevents larger sizes.