Module 9-Adversial Search
Adversarial Search and Games
What kind of games are there?
Golf,chess,pocker
Games most commonly studied in AI are:
Determinisitc
Two-Player
Turn-taking
Perfect information
Zero-sum
Approaches to modelling adversarial
1. Consider agents together as an economy.
‣ No need to predict the action of individual agents.
‣ Can capture large characteristics of the system, such as laws of supply and demand.
2. Consider adversarial agents as part of the environment.
‣ Models the probabilistic behavior of agents as a dynamic system.
‣ Does not explicitly take into account that agents may have conflicting goals.
3. Model agents using adversarial game-tree search.
‣ Explicitly models players as adversarial agents.
‣ Only suitable for specific games.
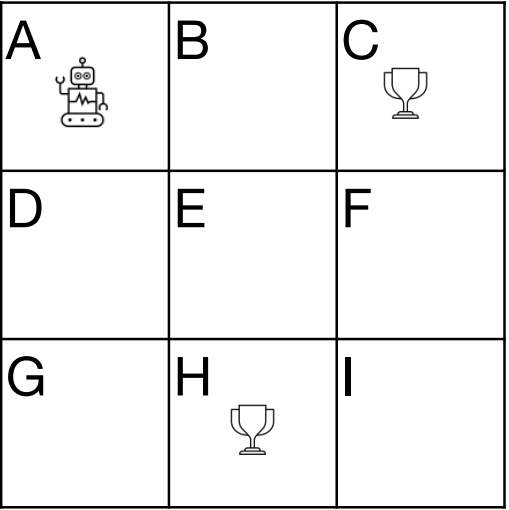
Demo: grind
Rules
‣ Two players take turn in moving the robot.
‣ Robot can only move in horizontal or vertical direction.
‣ Robot cannot move back to earlier state.
‣ First player to reach the cup wins.
‣ If there is no legal move left, the game is a draw.
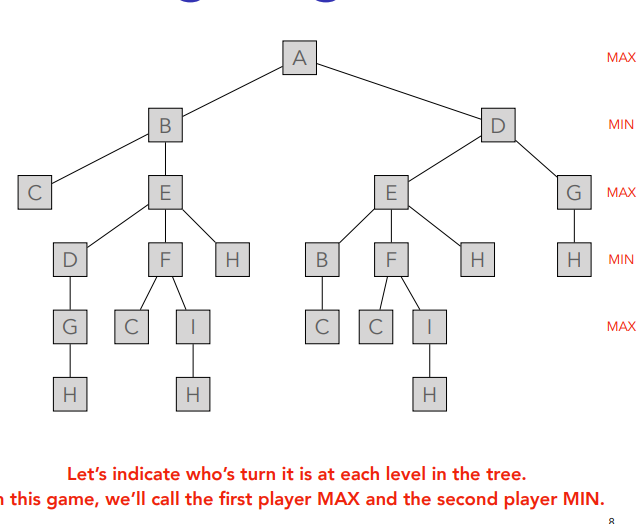
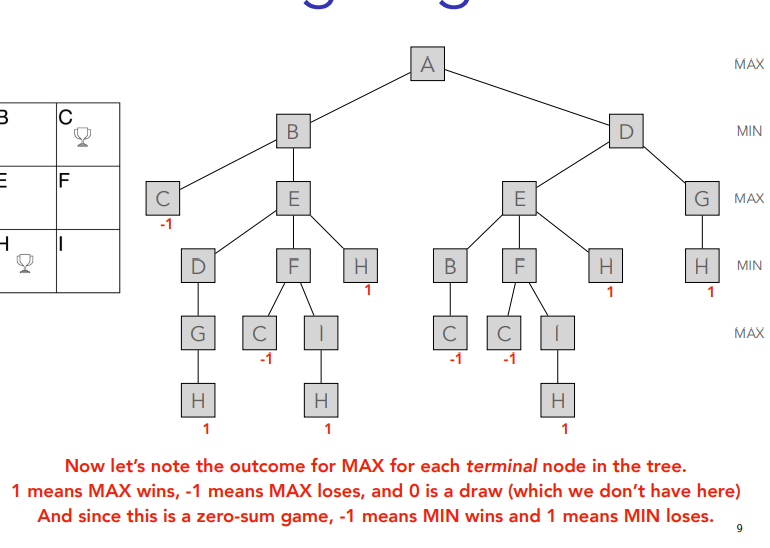
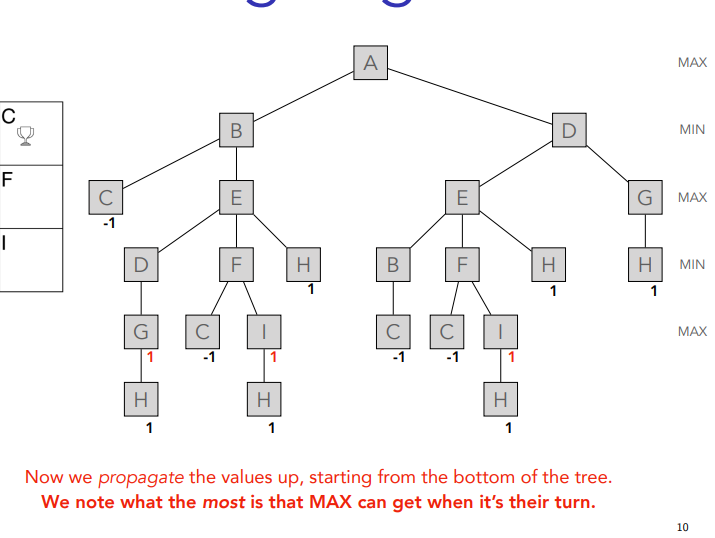
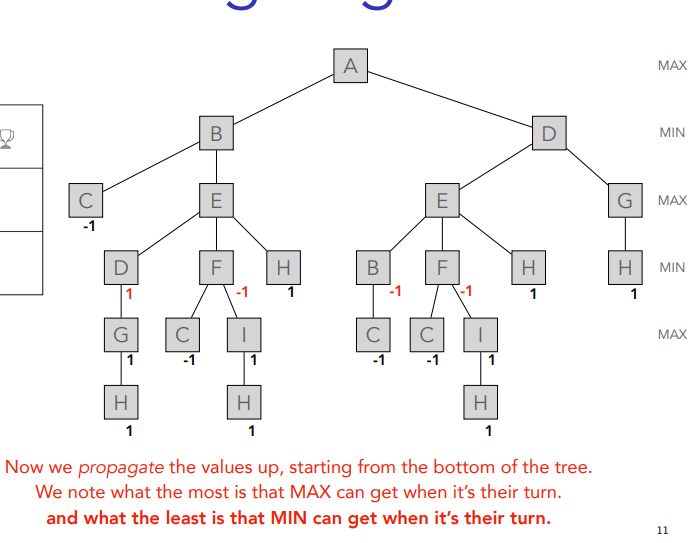
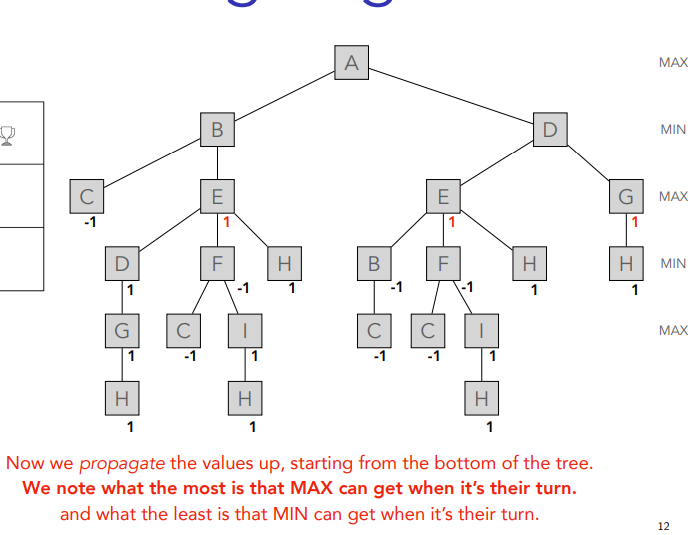
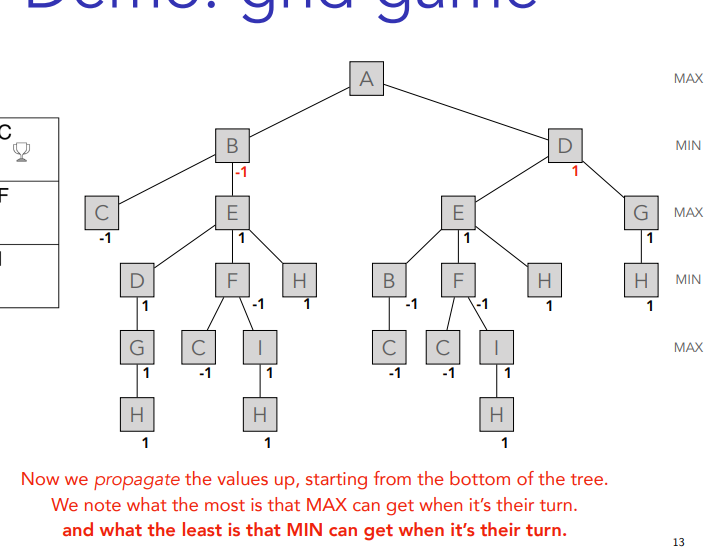
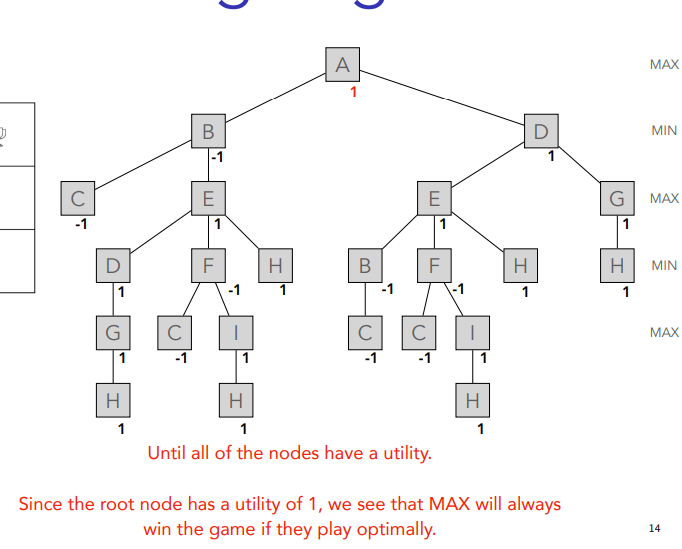
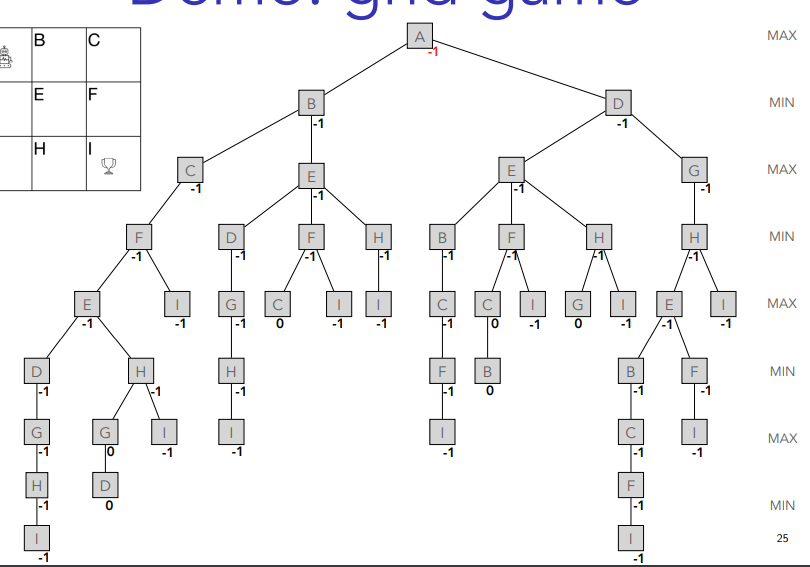
You just put ´-1 in the same line until you get to A which is last so max
Two-player zero-sum games
Formalization
‣ S0: Initial state of the game
‣ To-Move(s): player whose turn it is to move in state s
‣ Action(s): Set of legal moves in state s
‣ Result(s, a): Transition model, defining the state resulting from taking action a in state s. '
‣ Is-Terminal(s): True, when the game is over, false otherwise.
‣ Utility(s, p): numeric value to player p when the game ends in state s
State space graph
‣ Initial state + Actions + Result → state space graph
‣ Vertices are states, edges are moves.
‣ Some states may be reached by multiple paths
‣ Game Tree: Full representation of state-space graph
‣ Tree that follows every sequence of moves all the way to a terminal state.
‣ May be infinite (in case of repeatable states)
‣ Search Tree
‣ Partial representation of state-space graph
‣ Used to determine what move to make
Tic-Tac-Toe
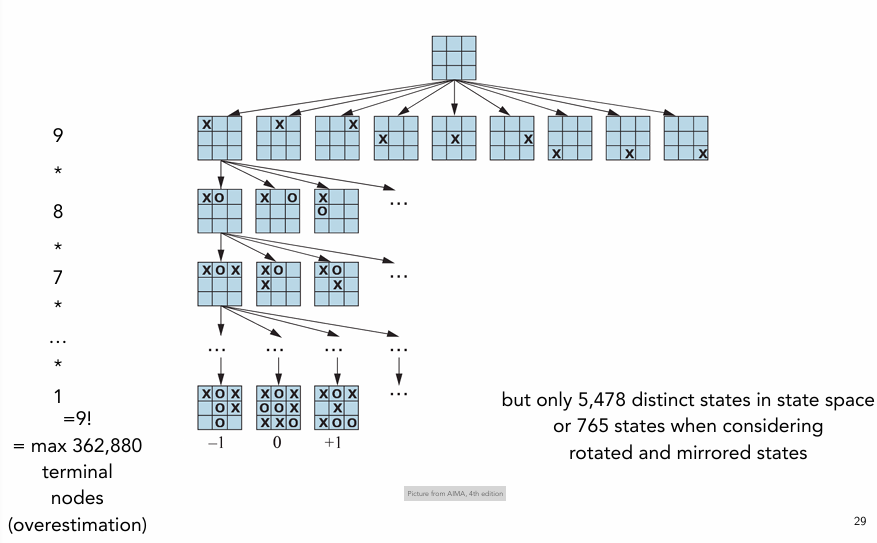
Ordinary search vs Adversarial Search
‣ In a normal search such as for the 8-puzzle, we could end the game by finding a path to a good end position.
‣ However, in adversarial search, the other player co-determines the path
Minimax search
‣ Two players, MAX and MIN, take turns in the game.
‣ MAX must plan ahead against each of MIN’s possible moves*.
* A move by a player is also called a ply.
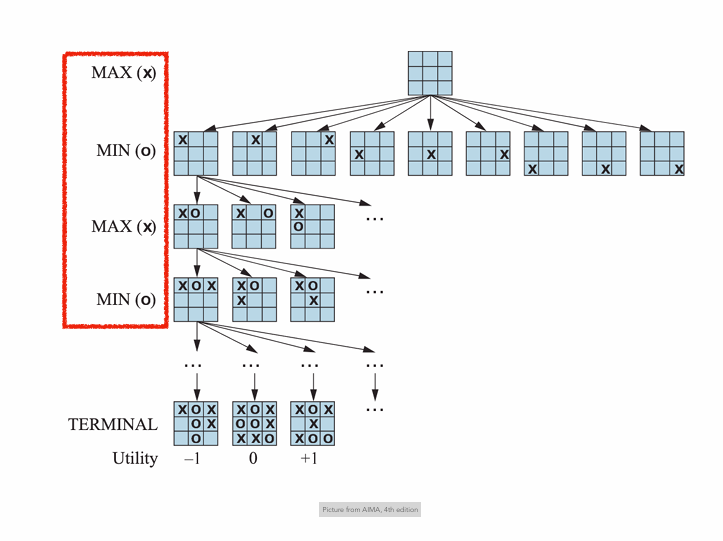
MINIMAX(S)=
‣ If we are at a terminal node → utility of terminal node
‣ If it’s MAX’s turn to move → maximum of descendant’s utilities Picture from AIMA, 4th edition
‣ If it’s MIN’s turn to move → minimum of descendant’s utitilties
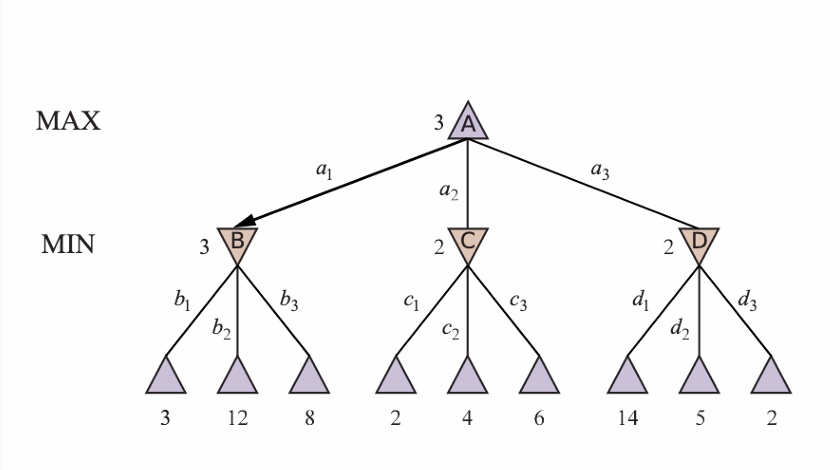
MINIMAX search Algorithm
‣ Depth-first exploration of the tree.
‣ Recursively descends each branch of the tree.
‣ Computes utility for terminal nodes. Picture from AIMA, 4th edition
‣ Goes back up, assigning minimax value to each node.
Complexity of MINIMAX
‣ Time complexity of MINIMAX is exponential: O(bm)
‣ b = (average) branching factor
‣ m = maximum depth of the tree
‣ More efficient way to search the game tree → Alpha-Beta pruning
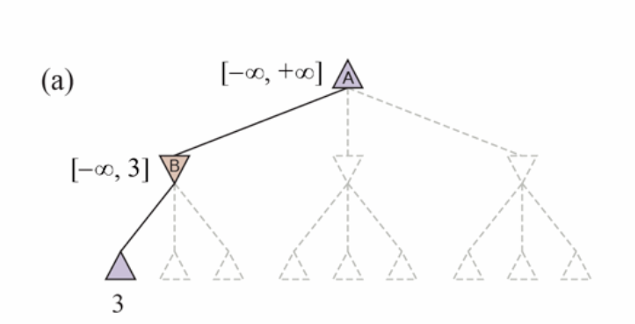
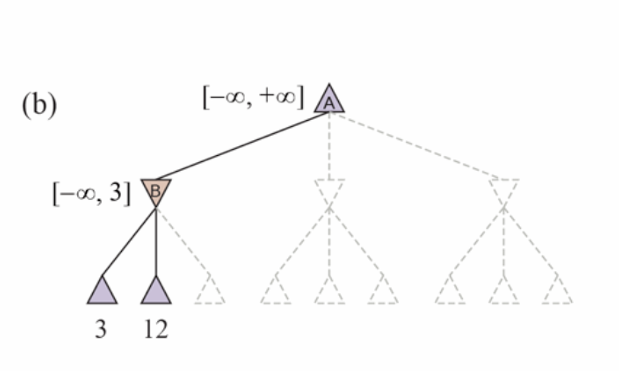
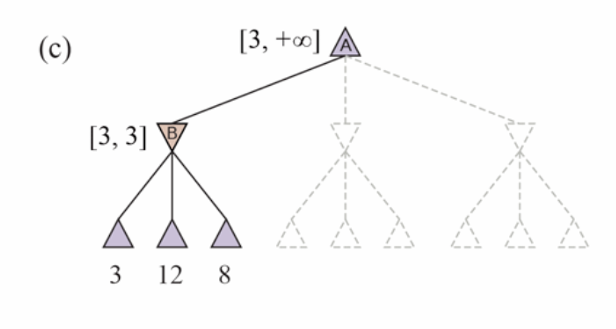
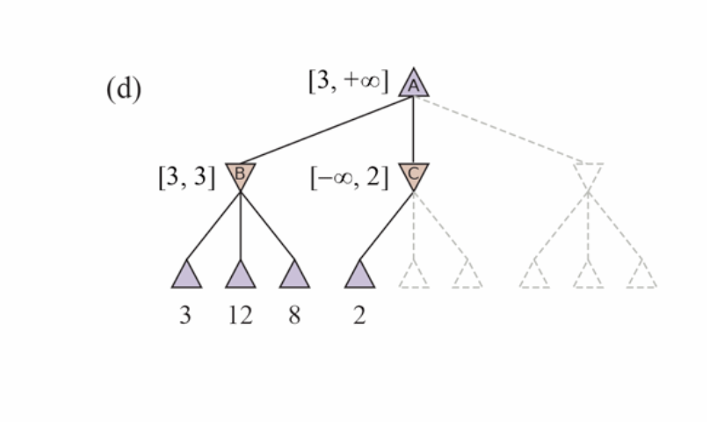
Alpha-Beta pruning
‣ α = the value of the best (i.e., highest-value) choice we have found so far at any choice point along the path for MAX. Think: α = “at least.”
/
‣ β = the value of the best (i.e., lowest-value) choice we have found so far at any choice point along the path for MIN. Think: β = “at most.”
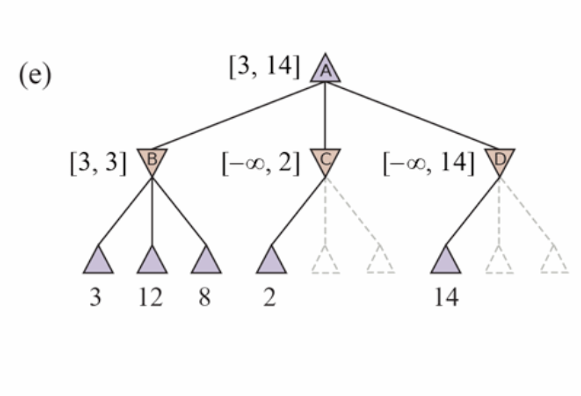
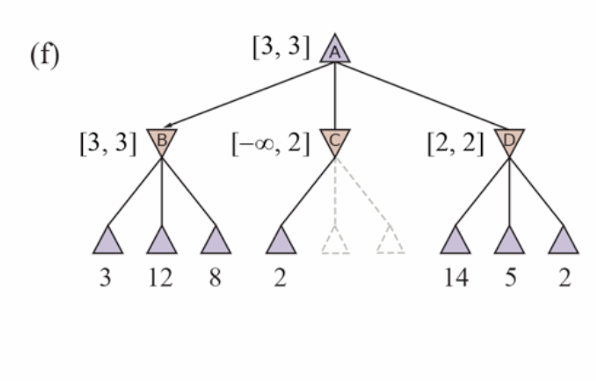
Move ordering
‣ If we have information on which moves are generally better than others, we can improve alpha-beta pruning by first evaluating the utility of nodes which are considered good moves.
‣ For instance, in chess: capture > threat > forward move > backward move
Transposition tables
In games like chess, the same positions can occur as a result of different moves → this is called a transposition
‣ Exploring the search-tree from that point again would be at least double work.
‣ Results of search for positions can be stored in a transposition table.
‣ Lookup from transposition table instead of search.
‣ Chess positions can be converted into unique indexes using special hashing techniques so that lookup has O(1) time complexity.
Heuristic strategies
Shannon (1950)
‣ Type A strategy (historically used for chess)
Consider wide but shallow part of the tree and estimate the utility at that point.
‣ Type B strategy (historically used for Go)
Consider promising parts of the tree deeply and ignore unpromising paths.
Heuristic Alpha-Beta Tree Search
‣ Can treat non-terminal nodes as if they were terminal
‣ Utility function, which is certain, is replaced by an evaluation function, which provides an estimate.
• e.g. queen=9, knight=3, bishop=3, rook=5, pawn=1, …
• Typically a weighted linear function of the values
• … but can be any function of the features
‣ H-MINIMAX (s, d)
• If cut-off reached → compute expected utility of node (=true utility for terminal nodes)
• If it’s MAX’s turn to move → maximum of descendant’s expected utilities
• If it’s MIN’s turn to move → minimum of descendant’s expected utilities
Forward Pruning
‣ Prune moves that appear to be bad (based on experience)
‣ Type B strategy
‣ PROBCUT: Forward pruning version of alpha-beta search that prunes nodes that are probably outside the α-β window.
‣ Late move reduction: reduces depth to which ordered moves are searched. Backs up to full search if higher α value is found.
Monte Carlo Tree Search
Complexity of games like Go is far greater than that of chess:
‣ Go starts with a branching factor of 361 and continues with an average branching factor of 150.
‣ Alpha-beta search is useless because it would not be possible to see far ahead.
‣ Instead, multiple simulations of complete games are played-out, starting from a given position.
‣ Expected utility of a move is percentage of play-outs with a win given that move.
‣ Usually combined with exploitation of past experiences (lookup).
‣ Combined with reinforcement learning → neural-network based game programs that learns by playing against itself (e.g.,. Alpha Zero)
Summary
‣ Games can be formalized by their initial state, the legal actions, the result of each action, a terminal test, and a utility function.
‣ The MINIMAX algorithm can determine the optimal-moves for two-player, discrete, deterministic, turn-taking, zero-sum games, with perfect information.
‣ Alpha-beta pruning can remove subtrees that are provably irrelevant.
‣ Heuristic evaluation functions must be used when the entire game-tree cannot be explored (i.e., when the utility of the terminal nodes can’t be computed).
‣ Monte-Carlo tree search is an alternative which plays-out entire games repeatedly and chooses the next move based on the proportion of winning 51 play-outs.