Comprehensive Notes on Amino Acids, Peptides, and Proteins
Overview of Protein Functions and Diversity
Proteins include catalysts (enzymes), structural fibers (keratin, collagen), transporters (hemoglobin), antibodies, hormones, light-harvesting complexes, toxins, etc.
A single cell may contain thousands of distinct proteins; diversity arises from different linear sequences of 20 common α-amino acids.
Example functions

Firefly luciferin–luciferase light production (ATP-dependent).
Oxygen transport by erythrocyte hemoglobin.
Keratin in hair, nails, wool, rhinoceros horn.
Four Organizing Principles
All living organisms build proteins from the same 20 amino acids.
Each amino acid has a side chain (R group) with distinctive chemistry.
Amino acids join via peptide bonds → linear sequence = primary structure.
Individual proteins can be purified because unique sequences confer unique chemical/functional properties; sequences also trace evolutionary relationships.
3.1 Amino Acids
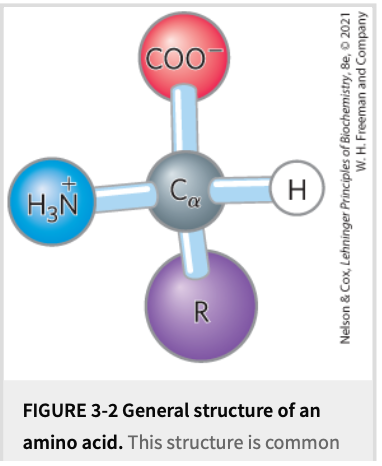
Common Structural Features (Fig. 3-2)
General formula: \text{H}_3\text N^{+}–\text{CH}(\text R)–\text{COO}^{-} at pH 7.
All are α-amino acids ➜ amino & carboxyl on same carbon (α-carbon).
"Residue" = amino acid minus elements of \text H_2\text O after peptide bond.
Chirality & Stereoisomerism (Fig. 3-3, 3-4)
Except glycine (where the R group is hydrogen, making two identical groups attached to the {\alpha} -carbon), the {\alpha} -carbon in amino acids is chiral. chiral carbon: carbon atom bonded to four different groups.
This chirality leads to the existence of two non-superimposable mirror-image forms called D & L enantiomers.
Biological proteins almost exclusively use L-amino acids (comprising more than 99% of amino acids found in proteins).
While chiral compounds do rotate plane-polarized light (a property known as optical activity), the D/L designation refers to the absolute configuration of the molecule's atoms in space, specifically relative to the stereochemistry of L-glyceraldehyde, and not directly to the direction or magnitude of optical rotation.
Carbon Nomenclatures
Side-chain carbons: β, γ, δ … outward from α.
Alternative numeric system (C-1 as carboxyl C) used when Greek ambiguous.
Classification by R Groups (Table 3-1, Fig. 3-5)
Non-polar, Aliphatic
Gly, Ala, Val, Leu, Ile, Met, Pro.
Hydrophobic clustering stabilizes protein core.
Gly provides flexibility; Pro imposes rigidity (cyclic secondary amino).
Aromatic
Phe, Tyr, Trp ➜ relatively hydrophobic.
Tyr OH can H-bond & undergo phosphorylation.
UV absorbance peaks near 280\,\text{nm} (Tyr & Trp > Phe) ➜ used to estimate protein concentration (Lambert–Beer law A = \varepsilon c l).
Polar, Uncharged
Ser, Thr (OH), Cys (SH), Asn, Gln (amide).
Cys can oxidize → disulfide bond (cystine) strengthening protein structure.
Positively Charged (Basic)
Lys (\text{p}K_R \approx 10.53), Arg (12.48), His (6.00 ‑ near neutrality ➜ enzymatic acid–base catalyst).
Negatively Charged (Acidic)
Asp (\text{p}K_R = 3.65), Glu (4.25) – deprotonated at pH 7.
Uncommon & Post-translationally Modified Amino Acids (Fig. 3-8)
Examples: 4-Hydroxyproline (collagen), γ-Carboxyglutamate (prothrombin), desmosine (elastin cross-link).
Selenocysteine & pyrrolysine inserted co-translationally via recoded stop codons.
Reversible modifications regulate activity (phosphorylation, methylation, acetylation, ADP-ribosylation, etc.).
Ornithine & citrulline: urea cycle intermediates, not protein residues.
Acid–Base Properties & Titration
In water, amino acids exist mainly as zwitterions.
Diprotic acids (for simple aa): \mathrm{p}K1(\alpha\text{–COOH}) \approx 2.0; \mathrm{p}K2(\alpha\text{–NH}_3^+) \approx 9.5.
Henderson–Hasselbalch: \text{pH}=\text{p}K_a+\log\dfrac{[A^-]}{[HA]}.
Titration of glycine (Fig. 3-10):
Buffering at \text{p}K1=2.34 & \text{p}K2=9.60.
Isoelectric point \text{pI}=\dfrac{2.34+9.60}{2}=5.97 ➜ net charge 0.
Amino acids with ionizable R groups display three stages & three \text pK values (examples: glutamate, histidine; Fig. 3-12). \text{pI}{\text{acidic}} \approx \frac{\text{p}K1+\text{p}KR}{2}; \text{pI}{\text{basic}} \approx \frac{\text{p}K2+\text{p}KR}{2}.
Summary Highlights
20 common L-α-amino acids are the “alphabet” of proteins.
R-group chemistry dictates solubility, reactivity, charge.
Knowledge of structures, abbreviations, pKa and classification is foundational for biochemistry.
3.2 Peptides and Proteins
Peptide Bond Formation (Fig. 3-13)
Condensation reaction: \text{COO}^- + \text{NH}3^+ \;\xrightarrow{\;\Delta H2O\;}\; peptide bond \text{–CO–NH–} + \text H_2\text O.
Thermodynamically favors hydrolysis; biosynthesis uses activated carboxyl (tRNA) + ribosomal catalysis.
Di-, tri-, oligo- (< ~20), poly- (> ~20–50) peptides.
Directionality & Terminology (Fig. 3-14)
Sequence written N-terminal → C-terminal.
Example pentapeptide: Ser-Gly-Tyr-Ala-Leu (SGYAL).
Stability & Ionization of Peptides (Fig. 3-15)
Peptide bonds have t_{1/2} \approx 7\,\text{yr} in cells (high activation barrier to hydrolysis).
Only terminal \alpha-NH$_3^+$ & \alpha-COO$^- ionize; internal groups engaged in peptide bonds.
Net charge ↔ pH ➜ exploited in separations.
Size Range & Biological Examples (Tables 3-2, 3-3)
Small peptides with potent activity: oxytocin (9 aa), thyrotropin-releasing factor (3 aa), amanitin toxin.
Proteins: cytochrome c (104 aa), chymotrypsinogen (245), hemoglobin (574 in 4 subunits), titin (~ 27,000 aa, M_r \approx 3\times10^6).
Average residue mass ≈ 110\,\text{Da} ➜ \text{No. residues} \approx \dfrac{M_r}{110}.
Quaternary & Conjugated Proteins
Multisubunit proteins held non-covalently; identical subunits → oligomeric, minimal repeating unit = protomer.
Conjugated proteins possess non-aa prosthetic groups (Table 3-4): lipids, carbohydrates, phosphate, heme, flavin, metals (Fe, Zn, Ca, Cu, Mo).
Summary Points
Peptide bond defines primary structure; N→C orientation mandatory.
Proteins vary from few to > 10⁴ residues; may have covalent or non-covalent prosthetic groups.
3.3 Working with Proteins
General Strategy
Source: cells/tissues → disrupt to crude extract.
Fractionation exploiting solubility, size, charge, binding.
Progressive purification monitored by assay & specific activity.
Early Steps
Salting out with \text{(NH}4)2\text{SO}_4; different proteins precipitate at different ionic strengths.
Dialysis removes small solutes through semipermeable membrane.
Column Chromatography (Fig. 3-16, 3-17)
Stationary phase (matrix) vs mobile phase (buffer).
Ion-exchange: cation exchangers (negatively charged resin) bind + proteins; elute by salt or pH gradient.
Size-exclusion (gel-filtration): porous beads; large proteins elute first.
Affinity: matrix-bound ligand specifically binds target protein; elute by free ligand or salt. Engineered tags (His₆, GST, etc.) facilitate single-step purification.
HPLC: high pressure + fine matrix ➜ high resolution, fast.
Monitoring Purification
Electrophoresis in polyacrylamide gels:
With SDS ➜ uniform q/m, separation by size; visualize with Coomassie blue (Fig. 3-18, 3-19).
Molecular weight from log (M_r) vs mobility plot.
Isoelectric focusing: separation by pI in pH gradient (Fig. 3-20).
2-D electrophoresis = IEF (1st) + SDS-PAGE (2nd) ➜ resolves thousands of proteins (Fig. 3-21).
Enzyme Assays & Purification Table (Table 3-5)
Activity: μmol substrate converted · min⁻¹.
Specific activity: units · mg⁻¹ – increases with purity.
Purification factor = \dfrac{\text{final specific activity}}{\text{initial}}; yield = \dfrac{\text{final total activity}}{\text{initial}}.
Summary
Combine inexpensive bulk methods first, high-resolution methods later.
SDS-PAGE & specific activity benchmarks guide purification.
3.4 Protein Structure – Primary Structure
Hierarchy (Fig. 3-23)
Primary (sequence) → Secondary (α-helix, β-sheet) → Tertiary (3-D fold) → Quaternary (subunit assembly).
Functional Importance of Sequence
Unique sequence → unique 3-D structure → unique function.
Mutations (single residue to deletions) underlie many diseases (e.g., sickle cell anemia, dystrophin in muscular dystrophy).
Proteins are often polymorphic; conserved regions denote functional/structural importance.
Classical Sequencing Tools
Edman degradation: stepwise N-terminal PITC labeling & cleavage.
N-terminal labeling reagents: FDNB, dansyl, dabsyl chlorides (Fig. 3-25).
Disulfide cleavage: performic acid oxidation; reduction with dithiothreitol or β-mercaptoethanol + alkylation (Fig. 3-26).
Protease/chemical cleavage specificities (Table 3-6):
Trypsin: Lys/Arg (C-side); Chymotrypsin: Phe/Tyr/Trp (C);
CNBr: Met (C); V8 protease: Asp/Glu (C), etc.
Synthetic Peptide Chemistry (Merrifield, Fig. 3-30)
Solid-phase synthesis using Fmoc strategy.
Repetitive cycle: deprotect → activate incoming aa → couple → wash.
Direction: C-terminus anchored to resin; synthesis proceeds C→N (reverse of biosynthesis).
Practical length ≤ ~100 residues; peptides can be ligated for larger proteins.
Mass Spectrometry & Proteomics
MALDI-MS & ESI-MS move macromolecules to gas phase with minimal fragmentation.
m/z measurement via TOF or Orbitrap ➜ accurate M_r$$ (Fig. 3-28).
Tandem MS (MS/MS): protease digest → select one peptide → collide & fragment → deduce sequence from mass differences (Fig. 3-29).
LC-MS/MS enables whole-proteome identification & quantification within ~1 h.
Bioinformatics & Evolution
Consensus sequence: most frequent residue per position (Box 3-2); sequence logos visualize conservation.
Homologous proteins: paralogs (within species), orthologs (between species).
Horizontal gene transfer complicates trees.
Signature sequences identify clades (e.g., 12-aa insertion in EF-1α/EF-Tu of Archaea/Eukarya; Fig. 3-32).
Multiple conserved proteins (e.g., 120 bacterial proteins) produce calibrated phylogenetic trees (Fig. 3-33).
Summary Bullets
Primary structure can be obtained from DNA or MS; informs folding, function, regulation, location, and evolutionary history.
Chemical & enzymatic tools allow manipulation, modification, synthesis of peptides for research & therapeutics.