Parallel Final Theory
Session 13: Environmental variables and the path
Executable File Access → used by OS to locate executable files or scripts. Allows you to run a program or script from any location without specifying the full path to the executable.
Convenience → simplifies command-line usage and makes it more user-friendly. Without it you would have to navigate to the director everytime.
Efficiency →saves time and reduces navigation complexity. Useful when working with frequently used tools.
Script execution → use commands that rely on executable variables in various directories. Including these directories in the path, ou ensure that your scripts can run regardless of the location.
Customisation → path can be customised to include directories relevant to their specific needs. Allows you to extend functionality.
Environmental portability → developers can write scripts that rely on standard tools located in directories specified in the path, software can run on different systems without modification.
Environmental variable
Configuration and customization → allows user and system administrators to configure and customise behaviour of applications and the OS.
Portability → instead of hardcoding file paths, using EV allows the software to adapt to different environments and systems without modification.
Ease of Management → system wide EV allows for centralised management of critical system configurations. Simplifies the process of updating.
Consistency and Standardisation → easier to ensure that software behaves predictably across different environments.
Session 16: Parallel Computer Architecture
Method of organising all resources in order to maximise performance, programmability and the cost at any instance in time.
Unified memory access → all processors share the physical memory uniformly and have equal access time, this is called symmetric multiprocessor. When only a few can access the peripheral devices, it is called an asymmetric multiprocessor.
Non-uniform memory access → access time varies with the location of the memory word. Shared memory is physically distributed, called local memories. Collection of local memories form a global address space.
Distributed memory multicomputers consist of multiple computers known as nodes, interconnected by message passing network. Each node acts as an autonomous computer and all local memories are private.
Parallelism by pipeline
Overlapping of the execution of multiple instructions. Divided into different steps performed by dedicated hardware. The following stepare an example of division:
- Fetch → get next instruction to be executed from memory
- Decode → decode instruction from ste a
- Execute → load specific operands and execute instruction
- Write back → write result into target register.
Parallelism by multiple functional units
Number of functional units is restricted due to data dependencies.
Parallelism at process or thread level
Each core must obtain a separate flow of control. Cores of a processor chip migt access the same memory and may even share caches.memory accesses of the cores must be coordinated.
Getting parallelism in the hardware
- Instruction level parallelism
- Data parallelism → increased number of data operated at the same time
- Processor parallelism.
- Memory system parallelism → number of memory units increases and bandwidth to memory.
- Communication parallelism → increase amount of interconnections between element
Dataflow Architecture
- Computations represented as graph of dependencies
- Stored in memories until operands are ready
- Operations can be dispatched to processors
- Tokens carry tag of next
Memory consistency
C coherence implies that writes to a location are visible to all processors.
We stablish orders between a write and a read by different processors using event synchronisation.implementation of hardware protocol for cache coherency and it will be based on memory consistency model.
Constraints are specified in the order in which memory operations can appear. There are implications for the programmer and system designer (used to constraint how much access can be reordered by compiler)
Sequential Consistency
Total order achieved by interleaving accesses from different processes: maintains program in order and memory operations complete automatically with respect to others as if thy were a single memory.
Every process issues memory operations in program order. NECESITO PREGUNTAR NO ENTIENDO UNA MIERDA
ACID
Acronym that stands for:
- Atomicity – transaction happens all at once or not at all
- Consistency → database must be consistent before and after the transaction
- Isolation → multiple transactions occur independently without interference
- Durability → changes of a successful transaction occurs even if the system failure occurs.
Session 17: Distributed Memory Systems
Form of memory architecture where physically separated memories can be addressed as a single shared address space
How can we do it?
- Page-based approach using virtual memory
- Shared variable approach → routines to access shared variables (global variables)
- Object based → accessing through object oriented discipline.
Object Based Approach
Object oriented programming is a paradigm based on the concept of objects containing data (attributes) and code (methods). OOP languages are diverse, however the most commonly used are class based, where objects are instances of classes.
Session 18:Interconnection Network Design
Components
Links → cable of one or more optical fibres with a connector at each end. An analog signal is transmitted from one end to the other.
Switches → set of input and output ports, and an internal crossbar connecting al input to all output. Generally the number of input ports equals the number of output ports.
Network interfaces → behaves differently to switch nodes and may be connected via special links. Formats the packets and constructs the routing and control of information. May perform end-to-end error checking.
Interconnection Network
Composed of switching elements. Topology is the pattern to connect switches to other elements and it allows exchange of data between processors in the parallel system.
Types of Networks
Direct connection networks → point-to-point connections between neighboring nodes. Networks are static and so the connections are fixed.
Indirect connection networks → no fixed neighbours. Based on application demands, topology can be changed. Divided into three parts:
- Bus networks
- Multistage networks.
- Crossbar switches.
Routing
Determines which path acts as a route between the source and its destination . dimension order routing limits the set of legal paths so that ther is only one route.
Deterministic ROuting
Only if the route taken is determined exclusively by its source and destination and not by other traffic. It is considered minimal if only the shortest path is selected.
Domain Name System (DNS)
Phonebook of the internet. Web browsers interact through IP addresses. DNS translates domain names to IP so browsers can load the resources. Iot is important because every device connected to the internet has one unique IP.
Loading a Webpage
DNS recursor → server designed to receive queries. Recursor is then responsible for making additional requests to satisfy the previous query
Root name server → first step in the translation process. Serves as a reference to other more specific locations.
TLD nameserver → specific rack of books in the library. Holds the last portion of a hostname.
Authoritative nameserver → dictionary on a rack of books. Specific name can be translated to its own definition. It will return the IP address for the requested hostname.
Transmission control protocol is one of the main protocols. Provides reliable, ordered and error-checked delivery of a stream of octets between applications running on host communicating via an IP network
User Datagram Protocol is primarily used to establish low-latency and loss-tolerating connections between applications on the internet. Sends data before the recipient agrees to receive it.
Open Systems Interconnection (OSI) Model
Conceptual model which enables diverse communication systems to communicate using standard protocols. It can be seen as an universal language for computer networking
Session 19: Distributed Systems
A collection of interconnected computers that work together to achieve a common goal. They communicate and coordinate their actions. Designed to:
- Store data
- Perform computations
- Provide services across multiple machines
They offer solutions to challenges of scalability, fault tolerance and performance. It is key for building resilience, efficient and globally accessible applications
They are all around us: Facebook, Amazon, Netflix or google docs
Decentralisation and Distribution of Resources
- Distributed systems → resources are spread across multiple nodes or machines
- Decentralisation reduces single point failures
Heterogeneity in Hardware and Software
- Distributed systems normally have hardware and software components. They can vary in characteristics and compatibility can become a problem.
Key Characteristics of Distributed Systems
Concurrecny and Parallelism
Concurrency → multiple tasks executing in overlapping times
Parallelism → execution of tasks simultaneously
Distributed Systems leverage both.
Fault Tolerance and Redundancy
DS are designed to handle failures
Redundancy in case of failure
Fault tolerance mechanisms include data recovery techniques and replication.
Challenges and Considerations in Distributed Systems
Communication Challenges
Network latency or packet loss are examples, as information gets exchanged between nodes.
Consistency and Data Synchronisation
Distributed transactions and consensus algorithms are used to maintain data integrity.
Security and Authentication
Encryption is essential to protect data and communication. Ensuring confidentiality and integrity is also key
Scalability and Load Balancing
Increasing workloads must go hand to hand with distributing it evenly. It is complex when dealing with a large-scale.
Client-Server Architecture
Clients request services or resources from central servers. They are responsible for the interface, while servers handle data
Peer-to-Peer Architecture
Allows distributed nodes(peers)to act as both clients and servers. They share resources and services directly,reducing the need for central servers
Microservices Architecture
Application composed of small, independent services. They communicate through APIs. promotes modularity, scalability and flexibility.
Distributed Databases and Storage Systems
Distributed databases → store data across multiple nodes. For example, NoSQL or MongoDB
Advantages:
Scalability and performance improvement
- They can scale horizontally
- Applications can grow with demand
- By distributing tasks across multiple nodes, parallelism is achieved.
Fault Tolerance and High Availability
- They can withstand failures without a single point of failure
- Redundancy and data replication help with it
- High availability is achieved through load balancing and data distribution.
Applications are able to serve worldwide, and due to being geographically dispersed, they can ensure accessibility from different regions.
Session 22: Big Data, Hadoop, Spark and The Cloud
What is Big Data?
Contains greater variety arriving in increasing volumes and with ever-higher velocity.
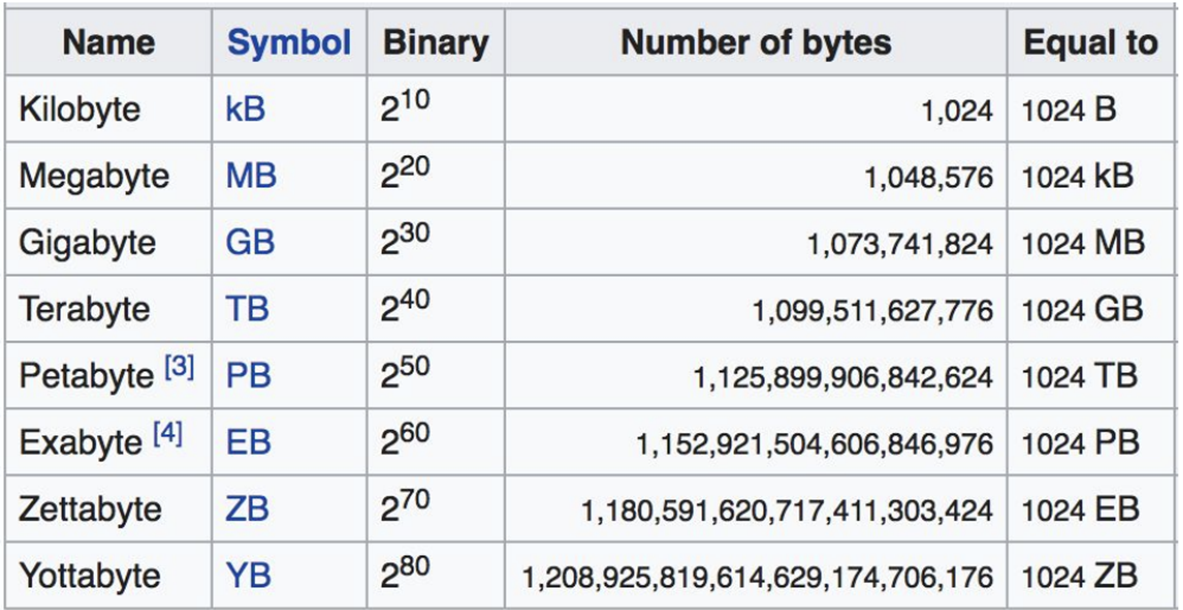
How can we trust this data?
Refers to the quality and trustworthiness of data. Due to it coming from different sources is hard to do certain actions on it.
Advanced Analytic capabilities:
- data/text mining
- ML
- Pattern matching
- Forecasting
- Semantic analysis
What is Hadoop?
Technology that gives companies the ability to store and process huge amounts of data.
HDFS is a distributed file system, files are stored in different computers. They are splitted into chunks and each block is replicated 3 times to recover in case of data loss.
Blocks are used because they store very large files and provide fault tolerance
What is Spark?
Multi-language engine for executing:
- Data engineering
- Data science
- Machine learning on single nodes
It is the evolution of Hadoop. Quickly performs tasks on very ñlarge data sets.
Apache Spark Architecture
Two main components: driver, converts users code into multiple tasks, and executors, run nodes and execute tasks given to them. Some create clusters.
Session 25: P Problems and NP Problems
Algorithm complexity refers to the efficiency of the algorithm in terms of time and space required. How performance is affected by an increase in input. It is important to have an efficient algorithm for solving real-world problems.
- Complex problems require exponential times to solve. Balancing accuracy and efficiency becomes a complex task.
Polynomial Time Class (P Problems)
Solvable in polynomial time and they have a predictable execution time in relation to the input size. For example, Merge SOrt or Quick Sort.
Non-deterministic Polynomial Time Class (NP Problems)
Verified in polynomial time. Solution might not be found quickly but validity can be checked.
Decision vs Optimisation Problems
Decision:
- Binary outcome based on input
Optimisation:
- Best solution out of a set of feasible solutions.
P vs NP Problems
Explores the boundaries of algorithmic efficiency. Poses a critical question about the inherent difficulty of certain computational tasks.
Addressing Complexity through Parallelism
Divide and Conquer → divided into smaller manageable tasks processed concurrently.
Reducing Execution → reduces overall computation time
There are certain challenges like scalability, hard to ensure efficiency, and synchronisation, coordination without causing bottlenecks.
P-Complete Class → the hardest problems in P. not know to exist in polynomial time, and if it does, there is a polynomial time solution for all problems.
NP-Complete Class → any NP problem can be reduced in polynomial time.
P-complete significance implies that P equals to NP if P-Complete has a polynomial time solution.
Challenges of solving P vs NP
- Proving P equals NP remains an open problem
- Finding polynomial time solutions for both has profound implications for the rest of the class.
Efficient algorithms for NP complete problems could impact optimisation strategies in various fields.
Parallel COmplexity Classes
Nicks Class (NC) → problems efficiently solvable in parallel. Designed to capture those problems.
P-Completeness in Parallel Computing → addresses complexity of parallel algorithms.
Problems as hard as the hardest P.
Understanding parallel complexity is key for designing efficient parallel algorithms.
Both of the previous ones explore the limits and possibilities of parallelism.
Parallelism in P | Parallelism in NP |
|
|
|
|
Challenges of Parallelising NP-Complete Problems
- Inherent Complexity
- Communication Overhead → communication occurs between parallel processors, minimising overhead and maintaining efficiency is challenging.
- Synchronisation Issues → parallel processes must not interfere with each other.
Possibilities and Approaches
- Divide and Conquer
- Heuristic Approaches → sacrifice optimality for speed
- Randomisation → monte carlo methods
- Parallelisation of special cases → tailoring algorithms to exploit the structure of specific instances can enhance parallel performance.
Session26: Map Reduce Yarn
Map reduce is a programming model used to access big data stored in HDFS. It facilitates concurrent processing by splitting data into smaller chunks and processing them in parallel. At the end it puts all the data together. The logic is executed on the server where the data already resides. Data access and storage is disk-based, input is stored as files containing structured or unstructured data and output is also stored in files
Map → data divided into smaller chunk, e3ach assigned to a mapper
Reduce → after processing is done, they are shuffled and sorted before passing to reducers. All with the same key, assigned to the same reducer, which aggregates them.
Combine → optional. Reducer that runs individually. Reduces the data on each mapper further. Makes shuffling and sorting easier
Partition → default partitioner determines the hash value. Links keys with values. As many partitions as there are reducers.
What is a YARN?
Splits the functionalities of a resource management job into separate daemons. Idea is to have a global resource manager and application master.
Components
- Container → you can find resources like a disk on a single node. CLC used to invoke containers.
- Application Master → when a single job is submitted is called an application. Monitoring certain aspects is the job of the master. All requirements of an application are done by sending the CLC.
- Node Manager → takes care of individual nodes and its containers. Primary goal is to manage each specific node container that is assigned by the resource manager. When a request is sent to the CLC, the manager creates a process container and runs it.
- Resource Manager → resource management and assignment of all the apps. It is the master daemon. Requests are forwarded tio the corresponding node manager. Resources are allocated by them.
- Scheduler → allocates resources to the various running applications subjected to familiar constraints.
- Applications Manager → responsible for accepting job submissions, negotiating the first container and providing services for restarting application manager containers on failure.
Why YARN?
It opens HADOOP allowing processes and running of data which are then stored in HDFS. this way, it helps run different types of distributed applications rather than MapReduce.
YARN Features
Multi Tenancy → allows access to multiple data processing engines.
Clusters are utilised in an optimised way because they are used dynamically.
Compatibility as it can be used with various versions of hadoop.
Scalability it allows many nodes and clusters
Steps of work for YARN
- AM is started by the allocation of the container by the RM
- RM and AM register with each other
- AM negotiations with RM regarding the container
- NM launches the container after notified by AM
- Execution of application code done in the container
- AM or PM monitors status of the application after being contacted by client
- Un-Registration of AM is done with RM after process is complete