Recurrance Relations and Sorting
(Like summations, but applies for Recursion only)
okay, so far, like a simple factorial one
int factorial(int n){
res = 1;
//with a while loop
while(n>0)
{
res = res * n;
n--;
}
}
// or with a for loop
or i = 1;
while)i<=n){
res = res * i;
i++;
}
factorialRec(int n)
{
if(n ==1)
return 1;
return n * factorialRec(n-1);
}
T(1) = 1;// time it takes to run
T(N) = T(N-1) + 1// how to calculate the time of N
T(N-1) = T(N-2) + 1
...//n-2
...// n-3
,
// okay, when substituted, it would result in
T(N) = T(N-4) +1 +1 +1 +1 // the amount of ones depend on what the number of N - K, then it would be K times
// previous stuff explains this
T(N) = T(N-k) + k
// N - k == 1, it is the last state, so k = N-1
//substituting k for n-1, with gets
T(N) = 1 + (N-1)
//explaining how this works, it was a proof the entire time. <!!!>
T(N) = N
Okay, the purpose of summations is to find the run time of iterative algorithms, but for Recursion, you can’t use summation rules, so you need to use Recurrance relations.
Definition of Recurrance Relations
Recurrence Relations are a tool to help find the Big-O of recursive algorithms
A simple Power example this time
int power(int x, int n) { // calculate x ^ n
res = 1;
for(i=1; i<=n; i++){// it can be n/2
res = res * x; // and this be x * x for the even case
if(n is odd)
res *= xl
}
return res;
}
int powerRec(int x, int n)
{
if(n==0) return 1;
if(n==1) return x;
if(n is even)
return powerRec(x*x, n/2);
else
return x * powerRec(x*x, n/2);
return x * powerRec(x*x, n-1);
}
T(1) = 1
T(N) = T(N/2)
...
T(N/8) = T(N/16) +2
//So it is
T(N) = T(N/2^4) + 4 * 2
T(N) = T(N / 2^k) + k * 2// if 4 is k
T(N) = T(1) + 3 logN// 3 not 2 because it is 3 operations when n is odd, * , *, and /.
= 1 + 3log N // it can be moved, but it
O(log N)
N/2^k = 1
2^k = N
k = log N
Sorting Discussion
(now, i am learning mergeSort, wow, they really split up C into two classes)
There is a O(n) runtime, Countsort, but the limitation is that it doesn’t sort negative numbers.
Without limitations, the best one is )(nlog(n)) runtime
Example runtimes and sorting algorithms
These three below, Bubble, Insertion and Selection sort have a runTime of O(n²). Although these are bad algorithms, it is important to understand how they function.
Part 1 Sorting Methods


Each iteration, it swaps between the entire array, and at the last one, it places the largest digit by swapping until the end, and then future iterations don’t touch that spot, so the amount that j checks and swaps decrease by n - i - 1, until the list is sorted.


It takes one value, and constantly checks, but it doesn’t just magically goes into position, it does a lot of comparisons and swaps until it reaches a number where it is smaller.
Correction, just not one value, it constantly compares after the swap, comparing the ones it did. Hence the while loop.
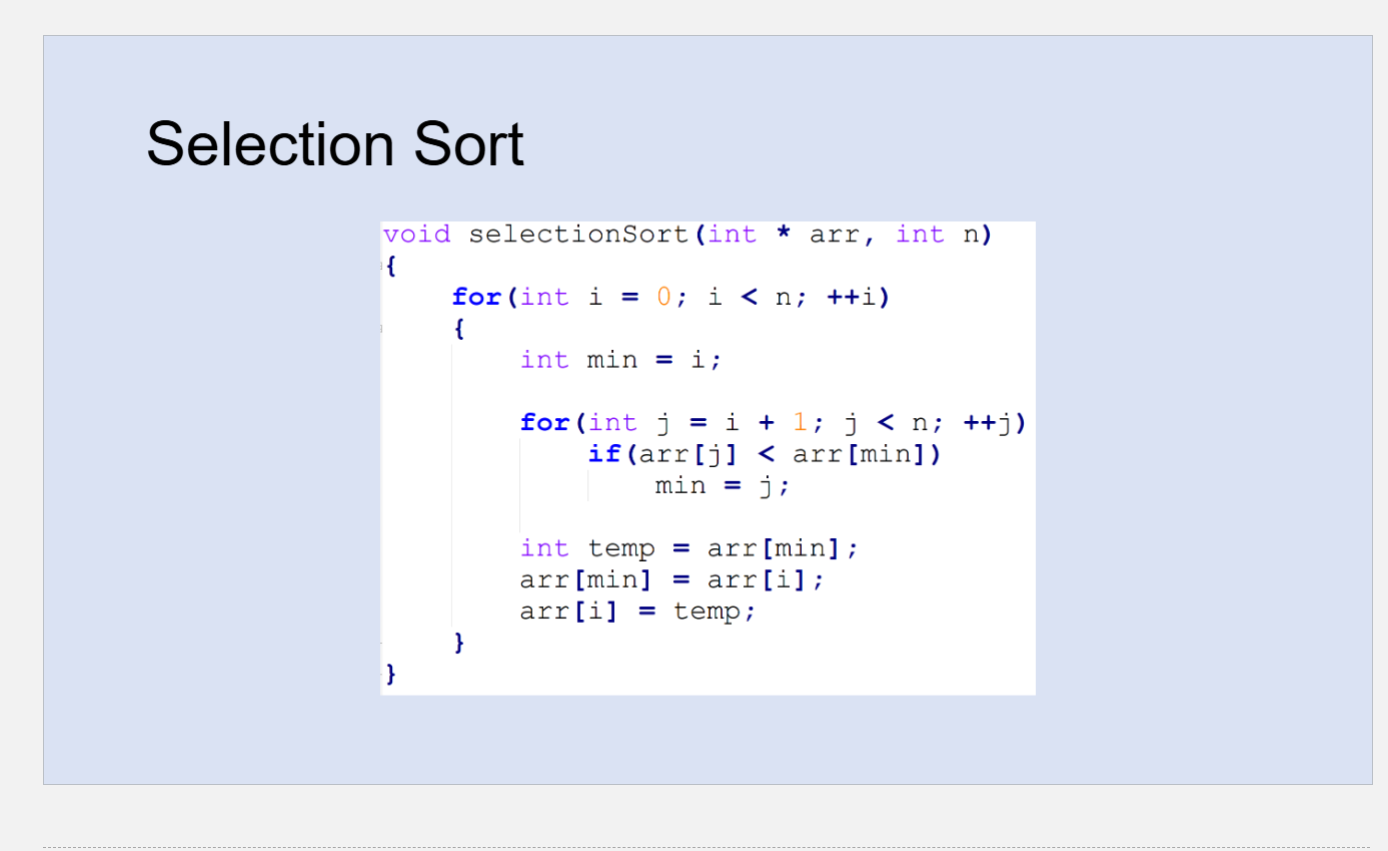

Essentially, it finds the minimum/maximum(doesn’t matter, just with maximum, you would need to reverse it and assign to the last one). After finding the minimum, it would swap it to the respective index, and places it to the first one. it would adjust by one, and constantly finds the minimum, as it starts to the next one.
Part 2 Sorting Algorithms


Code
Pay attention to Merge and MergeSort for this.
#include <stdlib.h>
void printArray(int arr[], int n);
// I believe that this merges the divided components together
//
void merge(int arr[], int left, int mid, int right){
int left_ar_sz = mid - left + 1;
int right_ar_sz = right - (mid+1) + 1;
int *L = (int *)malloc(left_ar_sz * sizeof(int));
int *R = (int *)malloc(right_ar_sz * sizeof(int));
for(int i=0;i<left_ar_sz;i++){
L[i] = arr[left + i];
}
for(int j=0;j<right_ar_sz;j++){
R[j] = arr[mid + 1 + j];
}
int i = 0; //index for left array
int j = 0; //index for right array
int k = left; //index for original array
/* okay, this part is kinda like the two-tracker approach for merging, okay! */
// It is exactly, the only thing is when it merges the two lists and one ends before the other, it would add the cut-off one at the end, while with two-tracker, it would stop comparing.
while(i < left_ar_sz && j < right_ar_sz){
if(L[i] <= R[j]){
arr[k] = L[i];
k++;
i++;
}
else{
arr[k] = R[j];
k++;
j++;
}
}
while(i < left_ar_sz){
arr[k] = L[i];
k++;
i++;
}
while(j < right_ar_sz){
arr[k] = R[j];
k++;
j++;
}
free(L);
free(R);
}
// this does the log(n) part, spliting it into different p
void mergeSort(int arr[], int left, int right){
if (left == right)
return;
int mid = (left + right) / 2;
mergeSort(arr, left, mid);
mergeSort(arr, mid+1, right);
/* handles the merging part after it got split off */
//printf("Calling Merge for left=%d, mid=%d, right=%d\n", left, mid, right);
// printArray(arr, 6);
merge(arr, left, mid, right);
// printf("After:\n");
// printArray(arr, 6);
}
void printArray(int arr[], int n){
for(int i=0;i<n;i++){
printf("%d ", arr[i]);
}
printf("\n");
}
int main(){
int arr[] = {12, 11, 13, 5, 6, 7};
int arr_size = 6;
printf("Given array:");
printArray(arr, arr_size);
mergeSort(arr, 0, arr_size-1);
printf("Sorted array:");
printArray(arr, arr_size);
return 0;
}Sorting Algorithms runTime, stability and spacing complexity
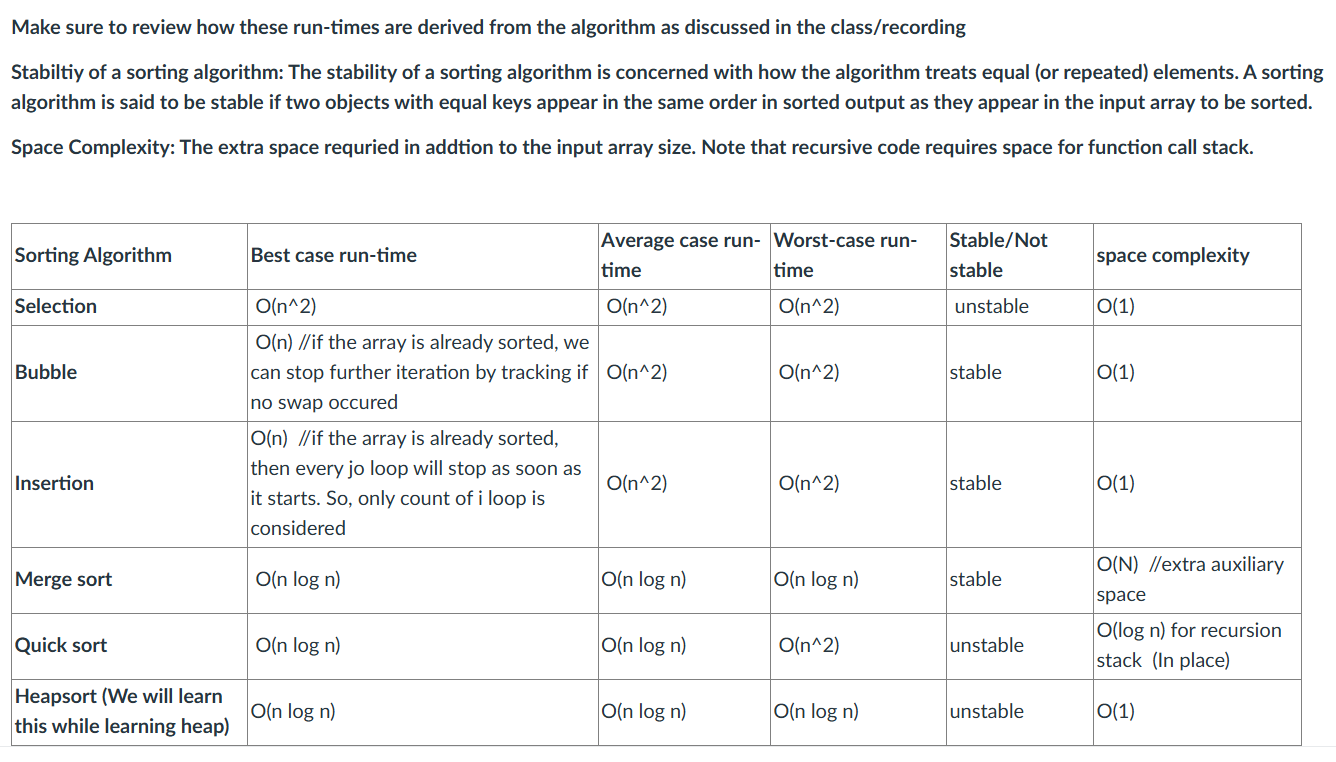
Quick Sort Algorithm (also part 3)
You are making a pivot, and the left and right would be different arrays based on if it is greater or less than the pivot
//index 0 1 2 3 4 5 6 7
//data 5 3 6 9 2 4 7 8
//explaining the partition
/*
pivot = 0
left == 1
right == 7
1 2 3 4 5 6 7
3 6 9 2 4 7 8
from here, it does two while loops that aren't nested, they are consectuitve.
the first one checks for values that are less than or equal to pivot
go forward by increasing low
the second while loop checks for values that are greater than pivot
go forward by decrasing high
after the two while loops, there is a if statement that swaps low and high
0 1 2 3 4 5 6 7
5 3 6 9 2 4 7 8
swapping now
0 1 2 3 4 5 6 7
2 3 4 5 9 6 7 8
With the pivots, in Quicksort, it will continously keep breaking until there is one element inside, which can be considered sorted
/*
For PA4:
//when there is low < high, it should check out many numbers in the current subarray, so you need to check if that subarray is <=30 elements, and if so use insertion sort.
// so check the result of (high + low), and if that is <= BASECASESIZE, use insertion sort instead. and return the result back
// DONT check in main, check in quickSort and MergeSort(that's what they are for)
//yeah that, it would i guess start the merging, you need an if statement when it is n <= BASECASESIZE, to just use insertion sort, otherwise call mergesort, then it would need to iteratevely via while loop, to check if low + high > BASECASESIZE, to keep calling it, otherwise, it would use insertion sort.
//MergesortREc is the one you ecnountered in the code
// maybe for this one, generate some inputs that are really large, like around 10,000 terms, don't know how but find out!
// also, with the sorting, it should use the compareTo, and whatever is better would be first(if first cat has better score, it comes first than the second cat, but that's already the case)
/*
*/
/*
Lab Stuff:
1. What is the runtime of MergeSort, explain why? nlogn, since it takes log(2)(7) times.
2. Why is quicksort faster?
Quicksort sorts in place, while mergesort creates subarrays , creating more memory, hence taking longer.
Quicksort is unstable because it doesn't maintain the orignal order of two duplicates, while mergesort is stable because it does that.
3. Even though QS has a worse runtime O(n^2) then MS, why is it perferred? The two cases, already sorted and the pivot having all values to the left and right smaller and bigger, respectively, doesn't happen that much.
*/