DAT566: Module 6 Machine Learning and Neural Networks
1/34
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
35 Terms

Which of these are supervised? Which are unsupervised?
Supervised: Regression and Classification. Unsupervised: Clustering

What methods can we use for solving these tasks?
Regression: Linear regression, neural nets
Classification: Logistic regression, k-NN, decision trees
Clustering: k-means, hierarchical clustering
All 3: Neural nets
What is a decision tree?
A tree shaped diagram used to determine a course of action
It can be used for decision making and classification
What is measures of impurity?
A way to measure how well a question splits the data
How does one select the best split for data?
Gini Impurity of Sets: The lower the score the better
What are pros and cons of decision trees?
Advantage: Easy to build, use, and implement
Disadvantage: Shallow trees are inaccurate, deeper trees tend to overfit on training data
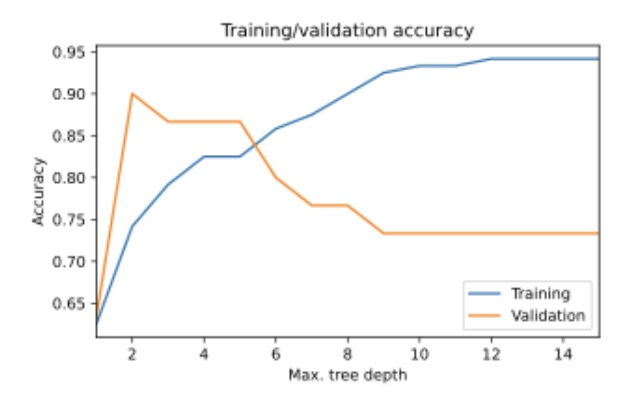
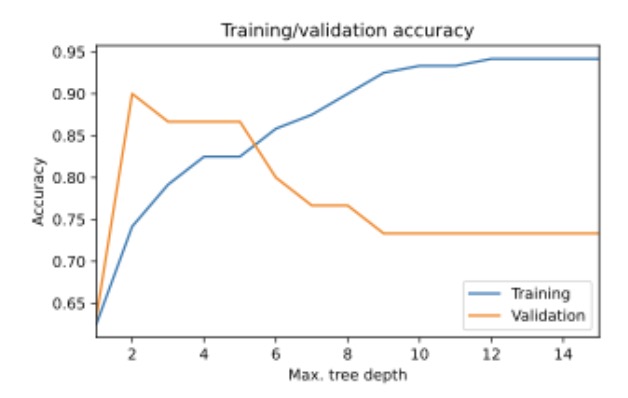
Which statement about decision trees is supported by the following plot?
The shallower a decision tree, the better it predicts the data
Deeper decision trees risk overfitting on the training set
Deeper decision trees tend to generalize better to unseen data
Deeper decision trees risk overfitting on the training set
What is a Random Forrest?
When one builds many small, independent trees and decides via majority voting. “Wisdom of the crowd” effect
What is a bagging in Random Forrests?
Idea: to prevent overfitting, aggregate the results from tens or hundreds of decision trees.
Each tree is trained on a random subset of features and data points (“bagging”).
What are pros and cons of random forests?
Advantages: accurate and robust ensemble method, prevents overfitting
Disadvantages: generating predictions is slow (for many trees), models are harder to interpret
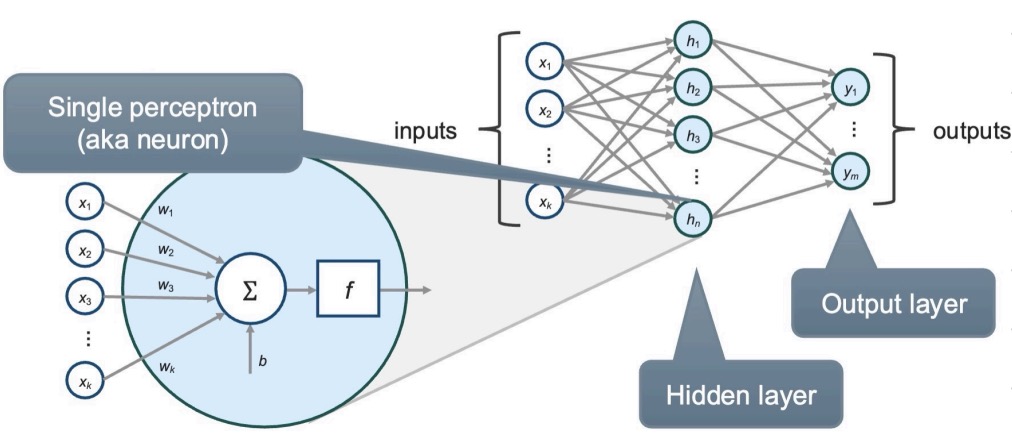
What is a perception?
A perceptron is a simple (binary) linear classifier
Can a single perceptron compute a logical XOR operation?
No, a single perception can only compute boolean functions (AND, OR, NOT, …)
What is a neural net?
The stacking of single perceptions to create more expressive functions. They are know as multi-layer perceptions (MLPs) or deep neural networks (> 1 layer)
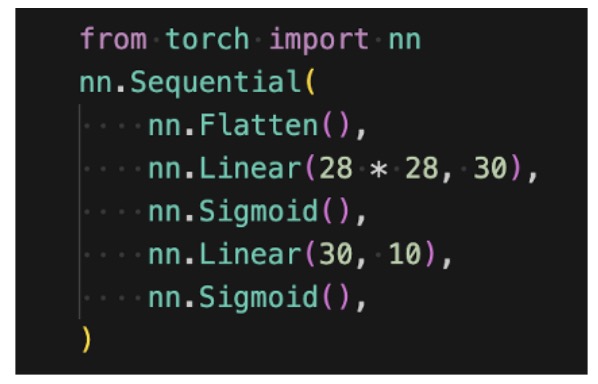
How many weights does the following neural net have?
28×28×30 + 30×10 = 23820
How is a neural network (NN) trained?
Pick a suitable loss function L(wi,bi)
Find the weights/biases wi,bi that minimize the loss/prediction error
What is an epoch in training?
One complete pass through the entire training dataset by the learning algorithm
How is prediction error minimized using gradient descent?
Weights and biases are initialized randomly
GD gradually adjusts the weights and biases in the direction that reduces the loss (i.e. moving against the gradient until a local minimum is met)
What are some caveats about training a NN with GD?
The loss function of a NN is not convex in general
GD is not guaranteed to find a global maximum or even to converge
What is dropout while training NN’s and its purpose?
During training, a random subset of neurons is dropped from the network by setting their weights to zero
A NN should not be sensitive to small changes in its input
In which situations do decision trees offer conceptual advantages over neural networks, and why?
They partition the feature space using simple decision rules that are easy for humans to interpret.
They make predictions using feature-wise comparisons rather than gradient-based optimization.
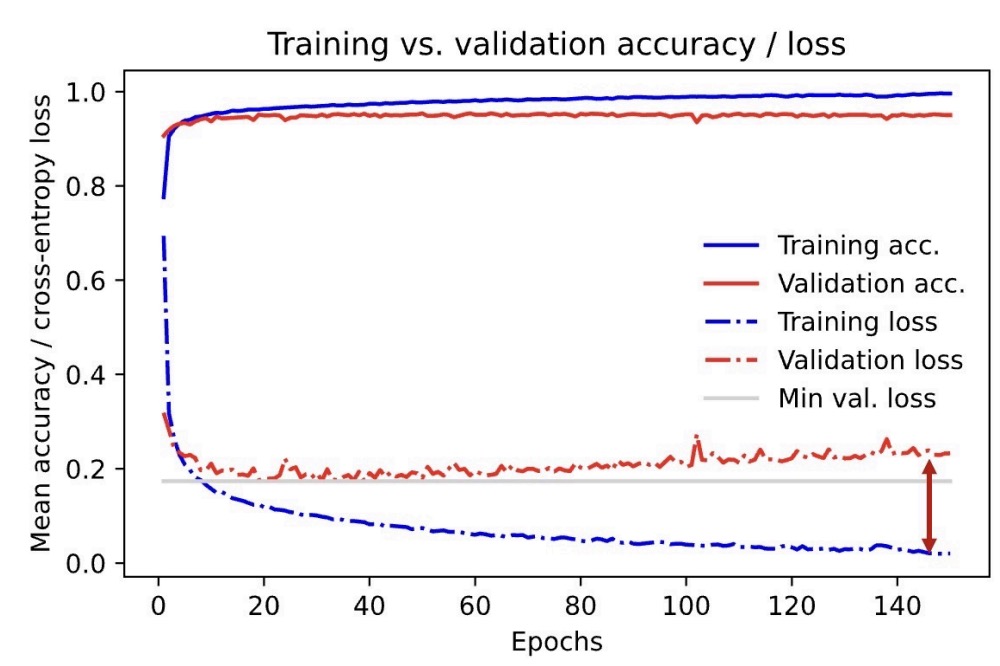
Is this model overfitting or underfitting?
Overfitting: The training accuracy is higher than the validation accuracy
The generalization gap is also large
What are some strategies against overfitting?
Early stopping
Dropout
Weight decay (regularization): L2 / ridge, L1 / LASSO
Removing redundant features
What is the difference between test and validation datasets?
Validation data can be used for early stopping during training.
Validation data can be used to tune hyperparameters during training.
Test data must only be used to evaluate the model performance once training is complete.
What are examples of machine learning methods and their function?
Naïve classification: Estimate probabilities from training data
Convolutional neural networks (CNNs): Automatically learn feature representations from raw data
Random forests using hand-crafted features
What is naïve image classification using NN and how many weights are needed?
Each neuron "looks" at the whole picture at once
For a small 28 × 28 pixel image, each neuron needs 784 (= 28 × 28) weights
For a colored image 28 × 28 × 3 = 2352 inputs (2352 weights per neuron) are needed
What are Convolutional neural networks (CNNs)?
Instead of learning to classify a whole image, learn small kernels/filters that can be used to detect features in the image.
Convolution: use a sliding window to apply kernels and find features
What is a feature map?
The output of a convolution filter (kernel) applied to an image → Shows where a specific pattern in an image appears
Each feature detects one pattern (colors, texture, shapes) and the resulting image detection is the feature map
A feature map has three dimensions: height x width x channels (# of filters)
What is the structure of a CNN?
Several convolutional layers (features) followed by a few fully-connected layers (classifiers)
Early layers:
Convolution → Apply several small kernels resulting in multiple channels (feature maps)
Pooling → Aggregate/reduce information in a feature map
Late layers:
Use resulting high-level features to preform final classification
True or False? In deep learning, more layers = higher accuracy
False: As networks get deeper they encounter a problem called the vanishing/exploding gradient problem and they are harder to train
What are Residual Networks (Res Nets)?
Res Net introduces the concept of residual (skip) connections. It makes it possible to train networks with hundreds of layers. Used in Deep NN architectures including transformers.
Why do residual (skip) connections enable effective training of very deep neural networks?
They allow layers to learn residual functions relative to their inputs rather than full transformations
They provide shorter paths for gradient flow during backpropagation
What is an Autoencoder?
A small layer in the middle of an encoder (bottleneck) that forces the NN to learn a compressed intermediate representation of data
Injecting noise in input data helps the NN learn to deconstruct denoised data
What is word embeddings?
Words that are semantically similar map to vectors that are close to each other
man to woman = king to queen
What is a token in machine learning?
Sub-word text chucks that can be embedded as inputs to downstream tasks like translation and next word prediction
What is reinforcement learning?
A framework for learning to make optimal decisions through trial and error