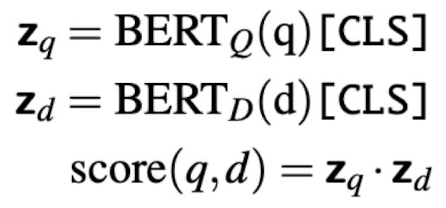Exam 2 - LIGN 167
1/88
Earn XP
Description and Tags
New material for exam 2 (text decoding, audio modeling, vision and language models, RLHF & alignment, text chain-of-thought, RAG, hallucination, training data, cognitive modeling)
Name | Mastery | Learn | Test | Matching | Spaced |
|---|
No study sessions yet.
89 Terms
How do you repurpose LMs for a specific application?
Update the model:
fine-tuning (replace LM head with a task-specific classifier and update all parameters using loss on downstream task)
domain-adaptation (fine-tune LM on next-word prediction in a target data domain)
instruction-tuning (domain adaptation to texts containing prompt/answer pairs; apply in-context learning in downstream applications to novel tasks)
RLHF (reinforcement learning from human feedback, fine-tune weights to maximize human preferences)
Interact with the model:
prompting (description of task in prompt; model learns through self-attention only (no weight updates) and generates text responses)
in-context learning (demonstration of task in prompt; model learns through self-attention only (no weight updates) and generates textual responses)
What is the pretrain-and-finetune paradigm? Why is it an efficient approach?
The pretrain-and-finetune paradigm (popularized around 2018) uses a shared pretrained model for all applications which is fine-tuned on task-specific data. This approach is a switch from custom-building all models. It helps reduce the need for large labeled datasets by leverage large unlabeled data. It also efficiently reuses parameters from pretrained models.
Define transfer learning
Transfer learning occurs when knowledge is acquired from one dataset/training objective and transfers to another.
(pre-trained weights from language models)
What are examples of repurposing LMs for a specific application?
Sequence classification:
sentiment
grammaticality
complexity
essay scoring
multiple-choice QA
Sequence pair classification:
paraphrase detection
natural language inference
Sequence tagging/labeling:
part-of-speech
named entity recognition
coreference
dependency labeling
span QA
Sequence-to-sequence:
translation
summarization
Examples of sequence classification
sentiment classification
grammatical acceptability
complexity
essay scoring
multiple-choice QA
Examples of sequence pair classification
paraphrase detection
natural language inference (NLI)
Examples of sequence tagging/labeling
part-of-speech
named entity recognition
coreference
dependency labeling
span QA
Examples of sequence-to-sequence
translation
summarization
What is out-of-domain (OOD) generalization?
OOD generalization is the ability of a model trained on one or more domains to generalize to unseen domains. Supervised models may overfit to the training domain, so OOD evaluation corrects this.
What is adversarial evaluation?
Supervised training can lead to simple heuristics that work for the bulk of training examples, but not for the long tail. Adversarial examples are designed to “trick” models that adopt these heuristics.
Example: “The doctor was paid by the actor.” —> Who paid who? - model confused by appearance order
What is named entity recognition (sequence tagging)?
Named entity recognition (NER) is a sequence tagging task in natural language processing that identifies and classifies named entities in text into predefined categories (e.g. people, organizations, locations). It works by assigning a tag to each word in a sentence.
Define Type I Error
False positive (predict true, actually negative)
Define Type II Error
False negative (predict negative, actually positive)
Define precision
Measures the reliability of a model’s positive predictions by calculating the proportion of true positives out of all positive predictions
“Of all the times the model predicted a positive outcome, how often was it correct?”
Precision = TP / (TP + FP)
High precision score indicates that the model makes very few false positive errors.
Define negative predictive value
Measures the reliability of a model’s negative predictions by calculating the proportion of true negative out of all negative predictions
“Of all the times the model predicted a negative outcome, how often was it correct?”
Negative predictive value = TN / (TN + FN)
High precision score indicates that the model makes very few false negative errors.
Define sensitivity
Measures the proportion of actual positive cases that were correctly identified by the model
Also called recall
“Of all the cases that were actually positive, what percentage did the model correctly predict as positive?”
SnNOUT: Sensitive test, Negative result = Rule Out
Sensitivity = TP / (TP + FN)
When is the sensitivity measure important?
The sensitivity metric is important when the cost of a false negative (i.e. Type II Error, missing an actual positive case) is high.
Example: medical diagnostic test for a serious disease —> highly sensitive test crucial for ensuring that very few people who have the disease are incorrectly told they are healthy
Negative result —> very effective at “ruling out” a disease (SnNOUT: Sensitive test, Negative result = Rule Out)
Define specificity
Measures the proportion of actual negative cases that are correctly identified by the model (i.e. true negative rate)
Specificity helps assess the model’s ability to avoid false positives (incorrectly predicting a positive outcome when the actual outcome was negative)
Specificity = TN / (TN + FP)
High specificity indicates that the model successfully classifies most of the true negative instances
What is Matthews Correlation?
statistical metric used to evaluate the performance of a binary classification model
balanced measure that considers all four categories of a confusion matrix (TP, TN, FP, FN)
MCC = TP × TN - FP × FN / √(TP + FP)(TP + FN)(TN + FP)(TN + FN)
*mathematically equivalent to pearson product-moment correlation coefficient applied to a 2×2 contingency (confusion) table
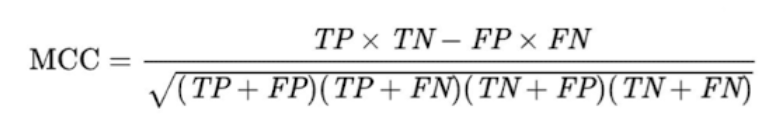
Define harmonic mean and F1 score
The F1 score is the harmonic mean of precision and recall. It provides a single, balanced score that incorporates both metrics and is particularly useful for evaluating models on datasets with imbalanced classes.
The F1 score gives a single number that is closer to the lower of the two value (precision or recall), meaning a model must perform well on both to achieve a high F1 score.
F1 = 2 / (recall-1 + precision-1) = 2TP / (2TP + FP + FN)
*Doesn’t account for true negatives —> use when true negatives are common —> bias towards positive

What is span question-answering (sequence tagging)?
A bidirectional model identifies spans in a passage that answer the question.
The answer is a continuous “span” of text extracted directly from a given context
E.g. SQuAD dataset
What are examples of sequence-to-sequence tasks and how to evaluate them?
tasks
translation
summarization
question-answering
eval
BLEU score
BERT score
Explain reference and grounding in natural language
Reference is part of language understanding. It is a relation between signifier (form) and a signified (real world thing). For humans, natural language is grounded in sensory experience.
Historically, what has been the go-to approach for image encoding?
convolutional neural networks (CNNs)
*still widely used
What challenges do you encounter trying to adapt the transformer architecture to images (pixel arrays)?
2- (or 3-) dimensional data — text sequences are 1-dimensional but images are 2-dimensional
very large number of pixels (compare to number of words passed into LMs)
How do you fix the issues associated with adapting transformer architecture to images?
vision transformer (ViT)
discrete VAE
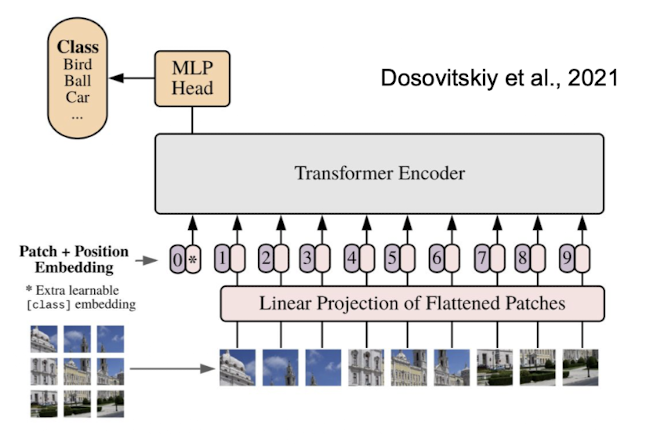
What is a vision transformer (ViT)?
A vision transformer (ViT) is a deep learning model that adapts the transformer architecture for image analysis by treating an image as a sequence of patches (similar to how NLP models process words)
Process:
break image up into patches (# patches as hyperparameter)
linearize patches (flatten out; concatenate rows; positional embedding for which patch it is)
project down to lower dimensional embeddings (map long pixel vector into more condensed, lower dimensional embedding)
train on image classification
This approach allows the model to capture both local and global relationships across the entire image simultaneously (unlike CNNs that start with local features)
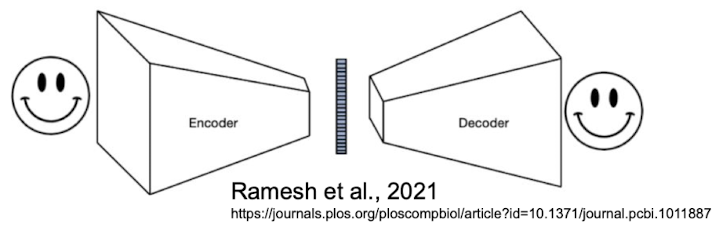
What is a discrete VAE?
Discrete VAEs (variational auto-encoders) are generative models that use categorical or binary latent spaces to capture structured and interpretable representations in domains like text, images, and graphs.
How it works:
Encode image using discrete tokens
define vocab of discrete image/token embeddings —> each image represented as list of embeddings
discrete representation for every image
Train autoencoder to reconstruct image
trying to reconstruct input
throw away decoder in the end
Summary of process: put image into encoder —> get discrete embeddings —> pass into separate decoder —> try to reconstruct original image
How was VisualBERT (2019) trained?
initialize transformer with pretrained BERT
continue training model with image and language data (example of transfer learning)
training objectives:
image-conditioned masked language modeling
sentence-image prediction
Training objectives for VisualBERT (2019) and other similar possibilities
Image-conditioned masked language modeling: given the text and image, mask out part of the text and predict
hope it becomes easier with visual image to condition on
cross modal connections
sentence-image prediction: provide two captions, model decides whether (a) both match the image or (b) only one matches
Possibilities
masked image modeling: fill in masked patches of image
masked multimodal modeling: mask both image and text, have to fill in both at the same time
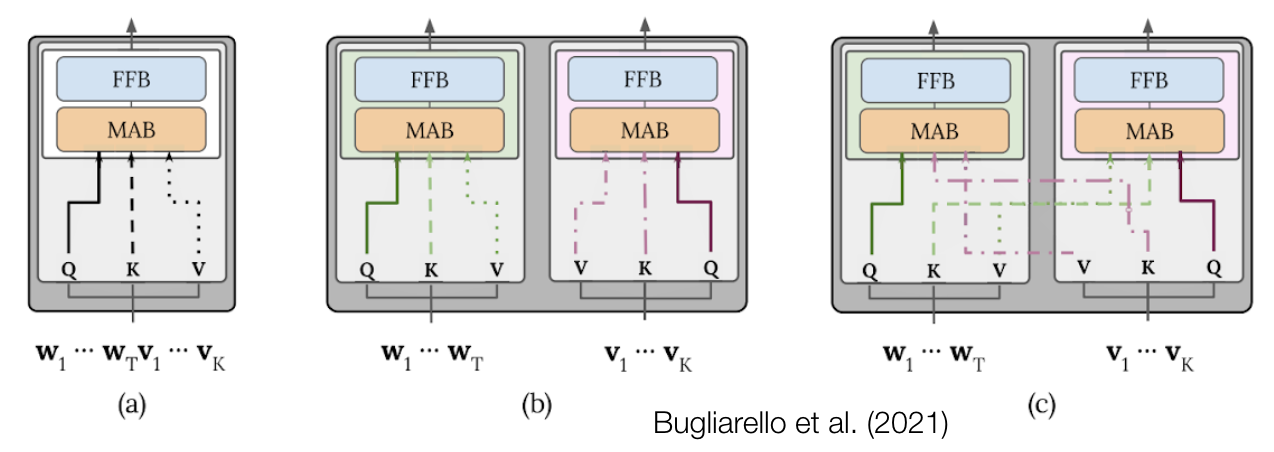
Architectural choices for vision models
single-stream: one transformer that accepts inputs from both modalities
dual-stream: two transformers, one for each modality
early vs. late fusion: how far into the model do we see multimodal transformer layers? how far into the model do we see interaction between modalities (e.g. cross-attention)
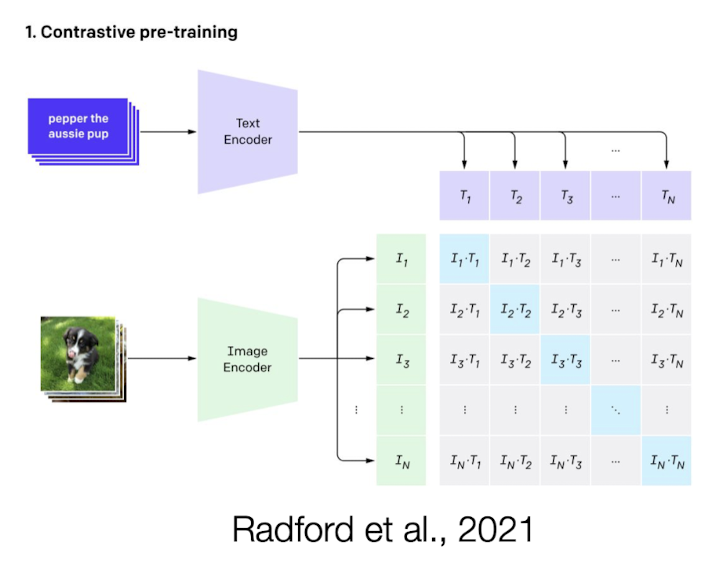
What is CLIP?
Contrastive language-image pre-training
A CLIP model is a type of neural network that learns to connect images and text by jointly training an image encoder and a text encoder.
Approach:
construct batch of N images X N texts (paired data)
labels (matching texts = positive samples, mismatching texts = negative samples)
objective: maximize similarity between positive samples and minimize similarity between negative samples
dot product from text and image encoders —> evaluate similarity
reducing loss: L(B) = Σ - (w * v) + Σ (w * v)
What is the visual question answering evaluation dataset? What is a problem with it?
Images taken from diverse sources
Human-authored questions
Problem: simple heuristics (e.g. text-only baseline - how often right without seeing image? - compare accuracy —> how important is visual component for task performance?) work well

What is the Winoground evaluation datset?
Adversarial evaluations designed to “stump” models using simple heuristics.
Inspired by “Winograd schemas” (“The trophy wouldn’t fit in the suitcase because it was too small/big. What is ‘it’?”)
Balance pairs where a language-only baseline would achieve 50% accuracy

Where does most vision-text data come from? Other possible sources?
Most vision-text data is image-caption data.
An easy source is alt text (accessibility text for vision impaired).
Other possible data sources are captions from a movie (e.g. people sitting in a cafe talking). Captions don’t always have grounding.
What are some advantages/disadvantages of caption data?
advantages
learn what’s important about images
text is grounded in important parts of image
disadvantages
relationship between text and image in real life isn’t always so direct (i.e. what you’re seeing doesn’t have anything to do with image) —> model struggles
texts are describing concrete things (e.g. physical objects, actions, colors), but linguistic data domain is specific (and small subset of how language is actually used)

How does vision-language fine-tuning affect language performance?
There is catastrophic forgetting of complex language, because captions are from a highly restricted/simple domain.
Example: VisualBERT forgets language (unrelated to captions) during fine-tuning
What kind of models typically are image generation models?
Most image generation models are diffusion models.
Models are trained to iteratively remove noise from an image (with or without cross-attention to text). Images are generated by inputting random noise and iteratively denoising.
Example: Stable Diffusion (Rombach et al., 2022)

What happens if you put a prompt into a simple pretrained LM and generate from it?
Model tries to continue texts in a way similar to what it’s seen before (e.g. trained on data scraped from internet —> doesn’t really include question-answer pairs).
It’s minimizing cross-entropy loss on token prediction.

What if you ask a pretrained LM to continue a toxic text?
It would try to continue the text as best as possible, which will likely include a toxic answer. This presents a problem for user-facing products.
What if you ask a pretrained LM a question it doesn’t know the answer to?
The LM will fall back on prior patterns/frequency in training data. This can include matching tone —> want to appear as similar as possible.
What if you ask a pretrained LM to help you do something dangerous?
The LM will try to output text that looks similar to training data. If LM is trained on data scraped from the internet, it will likely give instructions to do something dangerous when asked.
What is AI Alignment?
Alignment is the process of adapting a pretrained generative model to the needs of human users and the greater good.
What are several (common) goals of alignment?
helpfulness: AI should be able to solve problems for humans through interactions that are natural and easy for users
prompt-engineering shouldn’t be required for helpful model
handle typos, brief inputs, mistakes —> robustness
appropriate: AI should not generate texts that are rude, obscene, violent, etc.; “family-friendly” product
safety: Ai should refuse to comply with requests that are harmful to users, other people, or society
calibration: AI should be able to reflect on its level of confidence and be transparent when it is uncertain
knowledge is limited for models and humans —> don’t want LMs to make up facts because it seems helpful or resembles text
legal compliance: copyrighted material, what text do LMs have permission to share?
privacy
What is prompt-engineering?
Prompt-engineering involves designing a prompt to maximize model performance.
Why are instruction-response pairs largely out-of-domain for pretrained LMs?
*podcast
What are some methods for creating instruction-response pairs?
hand crafting
adapting labeled datasets (e.g. classification datasets - translation pairs)
use LLMs to generate examples
What is a system prompt?
The system prompt is text that is prepended to any user prompt. It supplies a persona and general instructions to the model that should apply in all interactions.
*text not code!!

What is the goal of preference learning?
The goal of preference learning is to teach models how to optimize outputs for maximizing human preferences.
*Humans share which answer they prefer

How can you acquire preference data?
present humans with several LLM outputs to a prompt
raw scores, pairwise preferences, best of n selection
use previously annotated data from stack exchange/reddit
forums with upvoting and downvoting
easy to acquire by scraping internet
What does training a reward model do?
You can train a reward head on top of LLM to predict human preferences (using labeled data).
Output z-score given candidate and prompt inputs
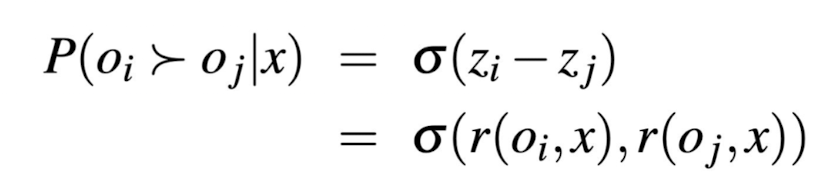
What is the optimization problem/equation in reinforcement learning?
Learn a policy π from which you can sample a sequence of actions a (i.e. generate tokens) that will optimize the expected reward model’s output r(x, o)
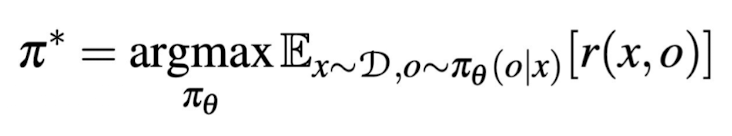
KL regularization and reinforcement learning
KL regularization limits deviations from the original pretrained model
(avoid catastrophic forgetting)
Equation note: subtracting from reward if not deviating too far from original distribution

RLHF: what do humans (actually) prefer?
good formatting/presentation: tables, bullets, clear structure, etc.
confident responses (—> hallucination)
flattery (—> sychophancy)
What happens when you instruct annotators to select responses that align with business goals?
mitigate social biases
espouse certain political viewpoints
refrain from discussing certain topics
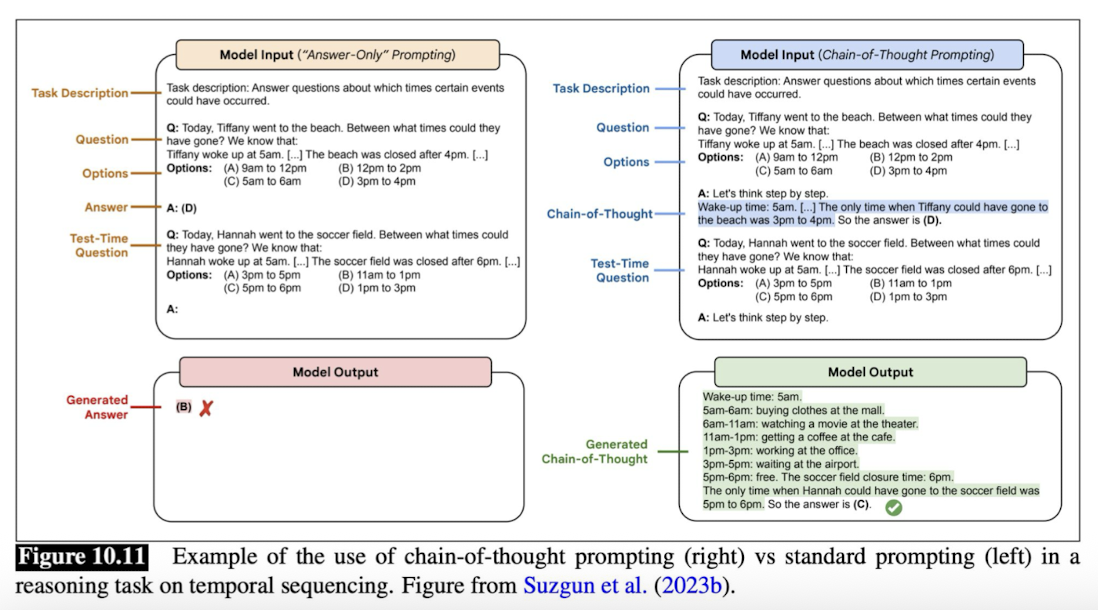
What is chain-of-thought prompting? What are reasoning models?
CoT prompting improves reasoning capabilities of models by encouraging them to break down complicated problems into steps
Reasoning models are trained specifically for chain-of-thought prompting.
Prompt-engineering —> add “think/solve step-by-step” at the end of input
What is ancestral sampling?
Ancestral sampling is one of the simplest text decoding algorithms.
Steps:
Pass in all previously generated text, or a user-specified prefix
Use the LM head to output a distribution over the next token
Sample from that distribution
Append the sampled token to the prefix
Repeat steps 1-4 until you generate the EOS token, or a predefined # of max tokens
What is maximum a posteriori decoding?
Maximum a posteriori decoding is a statistical method for estimating an unknown quantity or message based on observational data. It selects the outcome that has the highest posterior probability (which is the probability of the original message given the data that was observed)

When would you want to use maximum a posteriori decoding?
You would want to use it when you have prior knowledge or assumptions about the parameter you are trying to estimate (especially where observed data is noisy or incomplete).
Want to find most probable continuation —> on topic response
What are the problems with maximum a posteriori decoding?
can be expensive to compute
the search space is technically infinite (unless you set a max length)
the search space grows exponentially
can be degenerate
e.g. most likely continuation may just be EOS
hallucinations (problem in all text generation algorithms)
no creativity - expected, bland response based on observed data
What is greedy decoding?
At each step in greedy decoding, the model always generates the token with the highest probability.
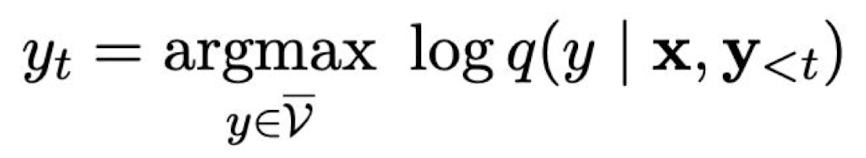
How does greedy decoding prevent issues like degenerate strings (i.e. the empty strings)?
*podcast
What is a problem with greedy decoding?
Greedy decoding can lead to highly repetitive text.
keep repeating question —> probability of repetitions increases and probability of other words goes to zero (*check podcast answer)
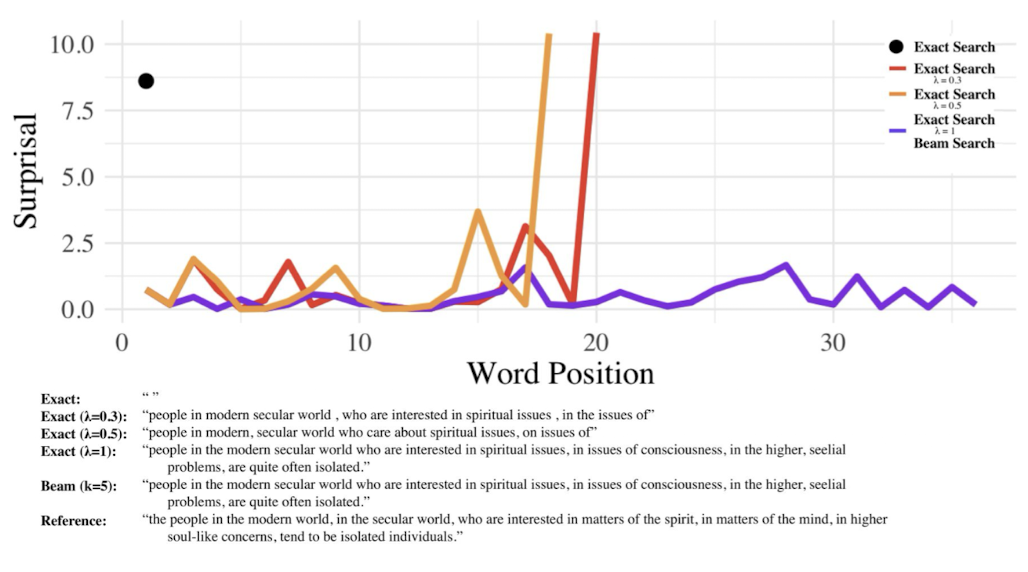
What is beam search?
Beam search is like greedy search, but at each step t, you greedily save the top k generations. k is referred to as the size of the beam.
How does beam search prevent degenerate generations?
*podcast
Beam search keeps the top k generations at each step t. By introducing more options than greedy decoding, we attempt to limit the possibility of degenerate generations (i.e. repetitions).
How does beam search prevent repetition?
In beam search, you compare all possible continuations. If a possible continuation has many repetitions, it will have a lower probability.
What else is beam search good for?
Beam search can also lead to more uniform information density (Meister et al., 2021)
What is stochastic sampling? Example?
Method for introducing randomness based on the model’s predicted probability distribution
Example: ancestral sampling
Contrasts with deterministic methods like greedy sampling
What is the problem with ancestral sampling?
Anything is possible, which can randomly lead to weird outputs.
What is the temperature parameter? What do its values mean?
Temperature is a hyperparameter set to manipulate the degree of randomness in sampling.
T —> 0: greedy decoding
T = 1: classic ancestral sampling
T —> infinity: uniform random sampling
How do we get probabilities from neural networks? (temperature)
Incorrect: normalize raw outputs
Correct: softmax function
Equation note: divide logit by some constant T (temperature)

What kind of decoding/sampling when T —> 0?
No randomness —> greedy decoding
Dividing by a small number —> amplify differences between logits —> softmax becomes sharper (more extreme values) —> model more confident/deterministic
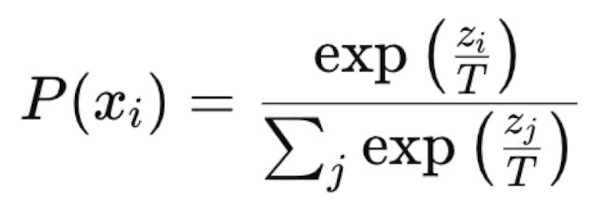
What kind of decoding/sampling when T = 1?
Default case
Logits remain unchanged —> ancestral sampling
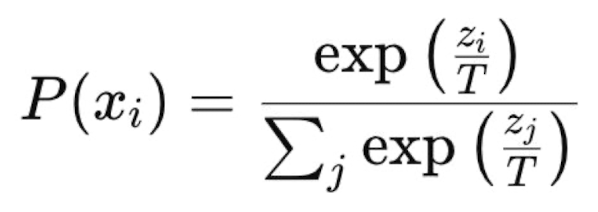
What kind of decoding/sampling when T —> infinity?
Uniform random sampling —> all tokens equally probable —> pure randomness
Dividing by a large number —> shrink differences between logits (i.e. small probability) —> softmax becomes flatter —> rare tokens more likely
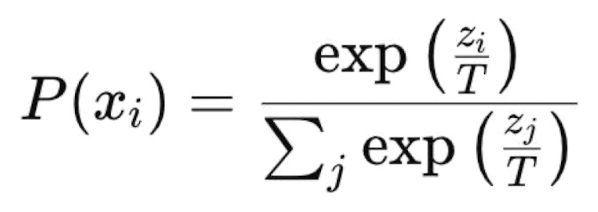
How does temperature affect softmax?
Lower temperature —> sharper softmax (more extreme highs and lows)
Higher temperature —> flatter softmax (values closer together)
When would you want a large or small temperature?
Want more creative/unexpected output (e.g. poetry) —> larger temperature
Want less creative, safer, more deterministic output (e.g. medical, legal) —> smaller temperature
What are truncated distribution methods?
For truncated distribution methods, you set some elements of the sample space (i.e. words in the vocab) to have probability 0 and renormalize. Preferably, this is excluding words that we would never want to generate (rather than just assigning them very low probability).
How would you decide what to exclude from the distribution? (truncated distribution methods)
*podcast
What is top-k sampling?
Top-k sampling involves sampling from only the k words in the vocab with the highest probability: v^(k)
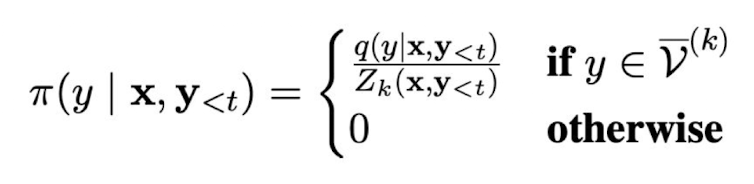
In top-k sampling, what happens when k = 1? What happens when k = |V|?
k = 1 —> picking highest probability word —> greedy sampling
k = |V| —> don’t prune anything from vocabulary —> ancestral sampling
What is nucleus sampling (top-p)?
In nucleus sampling, you select the most likely words from the vocab until the total probability mass is >= p. Then, you sample from that subset.

When does nucleus sampling method give the same result as ancestral sampling?
p = 1 —> take everything from vocabulary —> ancestral sampling
What is typical sampling?
Typical sampling is a decoding method that aims to keep the entropy of each generated step close to the typical set of the model’s distribution.
Differs from top-k/top-p sampling because it uses entropy directly

What is calibration?
LMs sound confident even when they are not correct
What are some problems with using LMs as knowledge bases to answer factual questions?
hallucination: LMs “make up” factually incorrect information in their response
calibration: LMs sound confident even when they are not correct
proprietary information: LMs aren’t trained on private data (assuming good actors), so they are less useful in internal settings
static models: knowledge is constantly changing, and training LMs continually on new data is expensive and complicated
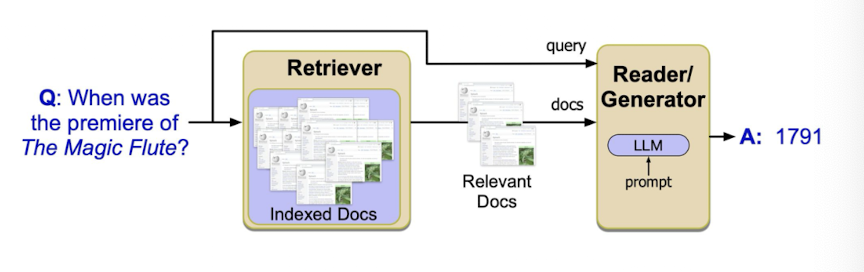
What is RAG?
RAG stands for retrieval augmented generation. It combines information retrieval (e.g. google search engine) with prompt-based LM text generation
Steps:
use information retrieval techniques to find documents that are relevant to the user’s question
prepend documents to the model prompt
additional prompt engineering (e.g. “based on these texts, answer this question: …”
generate response
What is tf-idf?
tf-idf stands for term frequency — inverse document frequency. Together, they measure how important a word is to a specific document relative to the entire corpus.
Every document/query has a tf-idf vector d/q where each entry is the tf-idf for a different term
What is an approach for information retrieval using BERT? Any problems with this approach?
Pass query and document together to BERT, and output a score indicating probability of match
Problem: highly inefficient because you need to pass every document through BERT each time you get a query
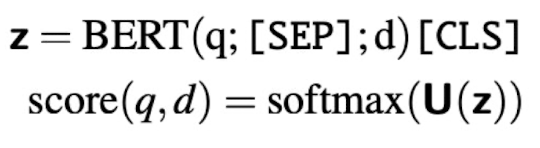
What is a second approach for information retrieval using BERT? Any problems with this approach?
Precompute document vectors and compute similarity score (dot product) with query vector on-the-fly
Problem: document vectors are not query-aware