MIST 5440 - Final Exam Review Guide
1/121
There's no tags or description
Looks like no tags are added yet.
Name | Mastery | Learn | Test | Matching | Spaced | Call with Kai |
|---|
No analytics yet
Send a link to your students to track their progress
122 Terms
What do we mean by AI for not bad? What is the distinction with AI for good?
AI for NOT Bad
Avoid ethical pitfalls in one’s pursuit of one’s goals
Risk mitigation
AI for Good
To create positive social impact
What are the consequences of ethical risks (happen at scale, reputational, regulatory, and legal)?
AI scales — therefore risks affect & can harm a large number of individuals
These ethical risks create significant reputational, regulatory, and legal risks that are costly in terms of money, resources, and money to address and loss of reputation and consumer trust
Many of these arise and are realized when AI is in use
Differentiate between intended or anticipated, and unintended risks
Why are corporate codes of conduct and current regulations not adequate to cover AI ethical risks?
Corporate Codes of Conduct
Corporate codes of conduct cover employees’ behavior, but AI ethical risks are not realized because of bad behavior
They result from:
Not thinking through the consequences
Not monitoring AI “in the wild“
Not knowing what one should be on the lookout for when developing or procuring AI
Current Regulations
New regulations are needed as there are new ways to break the law
Some techniques for mitigating AI ethical risks can be:
Legally compliant but ethically risky
Ethically sound but illegal AI
What are the big three AI ethical challenges?
Contents of AI Ethics Program
Bias
Lack of Explainability
Privacy
(but other AI Ethics risks exist as well and should not be overlooked)
What is the difference between content and structure for developing AI ethics programs?
Content defines what ethical risks and values an organization cares about
Structure is the system of processes and governance used to identify, evaluate, and mitigate those risks in practice.
Be able to define content and structure and discuss their importance in AI ethics programs
Content
Reflect a deep understanding of all the ethical risks we are trying to avoid
What does the organization see as good or bad
“What are the risks we’re trying to avoid?”
Structure
Leave no stone unturned in looking for them
Formal mechanisms for identifying and mitigating ethical risks
“How do we operationalize ethical risk mitigation”
Why are misperceptions about the nature of ethics a major obstacle to organizational buy-in to developing AI ethics programs? What are these misperceptions?
Getting buy-in requires that people understand what AI ethics is, and especially what ethics is
Ethics is based on well-founded standards of right and wrong that prescribe what humans ought to do, usually in terms of rights, obligations, benefits to society, fairness, or specific virtues
Distinction between ethical right or wrong and people’s ethical beliefs
If ethics (what is right or wrong) is subjective, then there is no such thing as responsible ethical inquiry because no one can possibly be incorrect in their conclusions
What specific misperceptions are preventing genuine organizational buy-in to developing AI ethics programs?
Three reasons why ethics are misperceived as subjective:
Ethics is subjective because people disagree about what is right and wrong
Science delivers us truth. Ethics isn’t science so it doesn’t deliver us truth
Ethics requires an authority figure to say what’s right or wrong; otherwise, it is subjective
Why is it not advisable to focus on consumer ethical beliefs (perceptions) as the basis for the organization’s AI ethics program?
Consumers’ perceptions are too coarse-grained for the fine-grained problems you are facing
Your problems are ones that your consumers have not even thought about yet
Consumers are looking for ethical leadership, and a mere appeal to the sentiment of the day does not meet the bar
The approach will alienate both those who are not particularly concerned about the ethical risks of AI within your organization and those who are, leading to a lack of compliance and turnover, respectively
Key Takeaway from getting buy-in for AI ethics programs
Creating an AI ethics program requires buy-in from the top to the bottom & requires education about ethics (and AI) to genuine organizational buy-in
What is responsible AI?
A governance framework that documents how a specific organization is addressing the challenges around artificial intelligence (AI) from both an ethical and legal point of view.
Resolving ambiguity for where responsibility lies if something goes wrong is an important driver for responsible AI initiatives
Why is there a movement towards the necessity of responsible AI practices?
When not designed in a thoughtful and responsible manner, AI systems can be biased insecure, and not compliant with existing laws, even going so far as to violate human rights. AI presents a significant risk of financial and reputational harm for companies that haven't thought through their strategies and roadmaps
We saw examples of Responsible AI frameworks for many organizations. What are the common (essential) characteristics of these frameworks?
Promote AI benefits and mitigate AI harm/risks by ensuring:
Fairness
Interpretability
Privacy
Security
Reliability
Do so through creating governance structures and accountability and by translating principles to actionable guidelines and tools
What is fairness?
Impartial and just treatment or behavior without favoritism or discrimination
“Fair“ does not mean “equal“ even though equal opportunity for equal benefit is central to its meaning. Fairness means that everybody in the group has an equal opportunity to benefit
What is a major challenge to achieving fairness?
Deciding what fairness actually means
When a particular approach is the right one to use
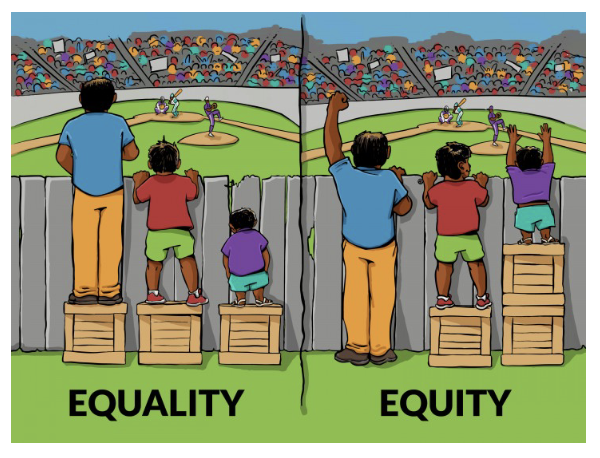
Equality v. Equity
Equality
Everybody is treated the same
Fails to take into account that not every one of us starts from the same place and that some might need different support that others do
Equity
Giving everybody equal access to the same outcomes
Adjusts for unfair disadvantages to ensure fair, just outcomes
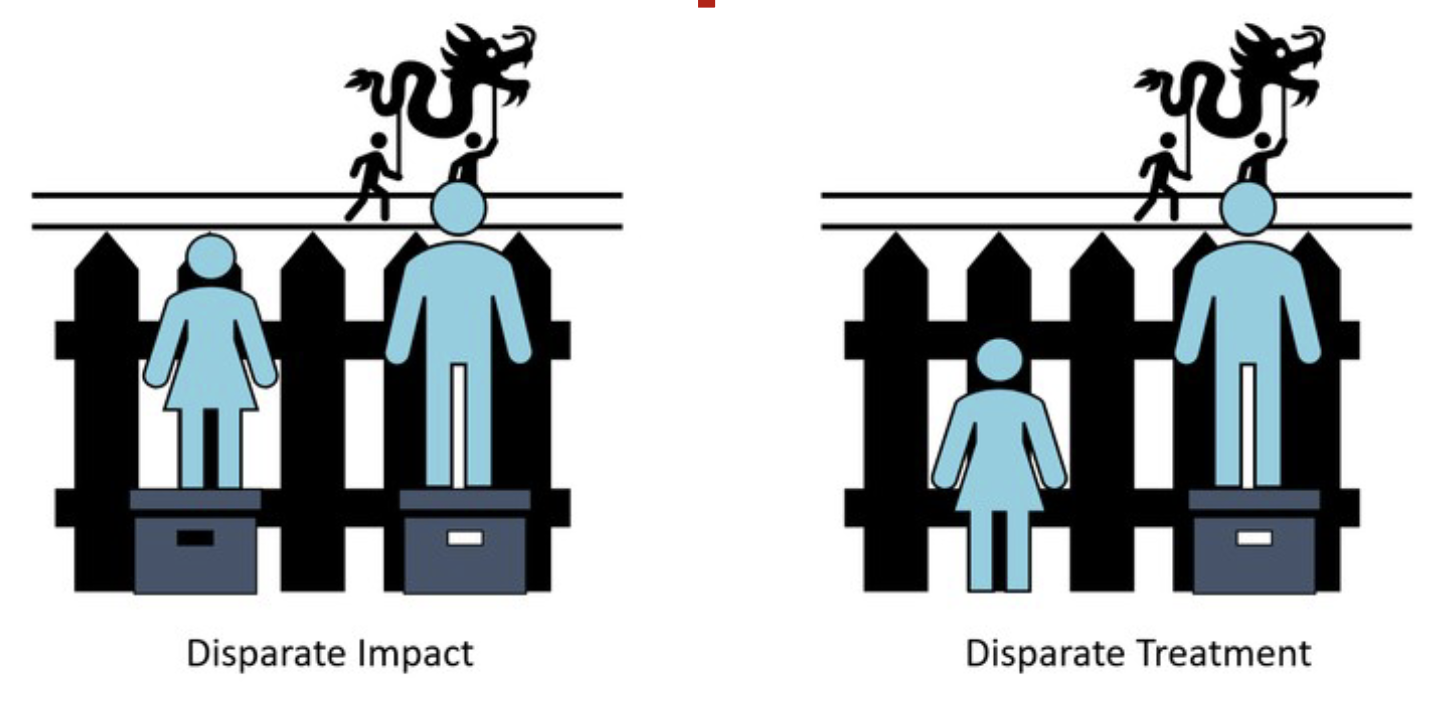
Disparate Treatment v. Disparate Impact
Disparate Treatment
Liability could be imposed if there is an explicit classification based on the protected attribute or if there was an intent/motive to discriminate
Disparate Impact
Even if the policy is neutral on its face, if there is a disproportionately adverse impact on minority groups, liability will be imposed.
What are the three steps needed to define and quantify fairness in building fair ML systems?
What is the right definition of fair outcome for the specific use case?
Who selects and defines what is a fair outcome and for whom?
What are the metrics we use?
What is the Group Fairness vs. Individual Fairness tradeoff?
Group fairness ensures equality between groups, while individual fairness ensures consistency between similar people, and optimizing one often means compromising the other.
Group Fairness Approaches
Aim to achieve the same outcomes across different demographics, or more generally, a set of protected population classes.
The population that receives a given assessment by the algorithm (let it be positive or negative) should reflect the whole population and its demographics.
The types of mistakes the model makes, and the severity of these errors, should be evenly distributed across the population.
BUT... being fair with respect to parity can seem highly unfair from a single individual’s viewpoint.
Individual Fairness
Advocates treating similar individuals similarly
Individual Fairness: The Unaware Approach
Algorithm is blinded or unaware of any identifiable factors and prohibited attributes by law such as gender, race, sexual orientation, etc. After removing the prohibited attributes, the factors with the highest correlation to the outcome are considered
The unaware approach can work only in cases where inequality is not an issue; a highly sterilized environment where the group of individuals that the algorithm classifies between is very homogenic.
Strengths & Limitations of Individual Fairness: The Unaware Approach
Strengths
Removes protected attributes (e.g., race, gender), making it legally compliant and easy to justify
Simple to implement and aligns with “merit-based” decision-making
Treats individuals consistently based on observable qualifications
Limitations
Other variables (e.g., ZIP code) can act as proxies, so bias still seeps in
Ignores structural inequalities in access to resources and opportunities
Can produce unequal outcomes across groups despite appearing “fair”
Creates a false sense of neutrality (“colorblindness” critique)
Only works well in rare, highly homogeneous or equal environments
Individual Fairness: The Awareness Approach
Two similar individuals should be treated similarly.
Individual fairness relies entirely on how you define "similarity" between applicants, and you can run the risk of introducing new fairness problems if your similarity metric misses important information. It is hard to determine what is an appropriate metric function to measure the similarity of two inputs.
Strengths & Limitations of Individual Fairness: The Awareness Approach
Strengths
Promotes consistency: similar applicants are treated similarly
Focuses on individuals rather than group averages, aligning with merit-based decisions
Intuitively fair and easy to justify in principle
Limitations
Depends heavily on how “similarity” is defined—there’s no clear or objective metric
Different reasonable metrics can lead to different (and conflicting) outcomes
Sensitive attributes complicate things—unclear whether or how they should factor into similarity
Can introduce new biases if the similarity function overlooks important context or structural inequality
Fairness Notions: Hybrid Approaches
Combine group and individual fairness.
Examples:
Learning Fair Representations approach (abstract transformations of the data points into high-dimensional numeric vectors) that could be used in downstream modeling tasks.
Individual Risk Scores approach that uses a thresholding policy to treat similarly risky individuals the same way.
Demographic (or Statistical) Parity
Scenario
AI model classifies patients as high risk (extra screening) or low risk (no action)
Two groups: Group A (80%) and Group B (20%), otherwise medically similar
Demographic (Statistical) Parity Idea
Fairness defined as matching outcomes to population proportions
~80% of “high-risk” flags should go to Group A, ~20% to Group B
Prevents over-favoring one group (e.g., giving disproportionately more screenings to Group B)
Limitation of Demographic Parity
If Group B actually has a higher cancer rate, strict parity becomes harmful
Forces fewer Group B patients to be flagged → missed diagnoses
Forces more Group A patients to be flagged → unnecessary testing
Key Takeaway
Equal proportions ≠ medically optimal outcomes; enforcing parity can reduce overall accuracy and harm patients
Limitations of Demographic (Statistical) Parity
Can create unfair outcomes: forces unnecessary testing for healthy patients and misses truly sick ones
Ignores intersectionality: fairness for one group may still disadvantage overlapping groups
Reduces model accuracy (“detunes” the algorithm), increasing costs
Doesn’t consider ground truth (actual disease status), only outcome proportions
Key Insight
Better fairness approaches account for ground truth, often by balancing error rates across groups rather than just matching proportions
Confusion Matrix
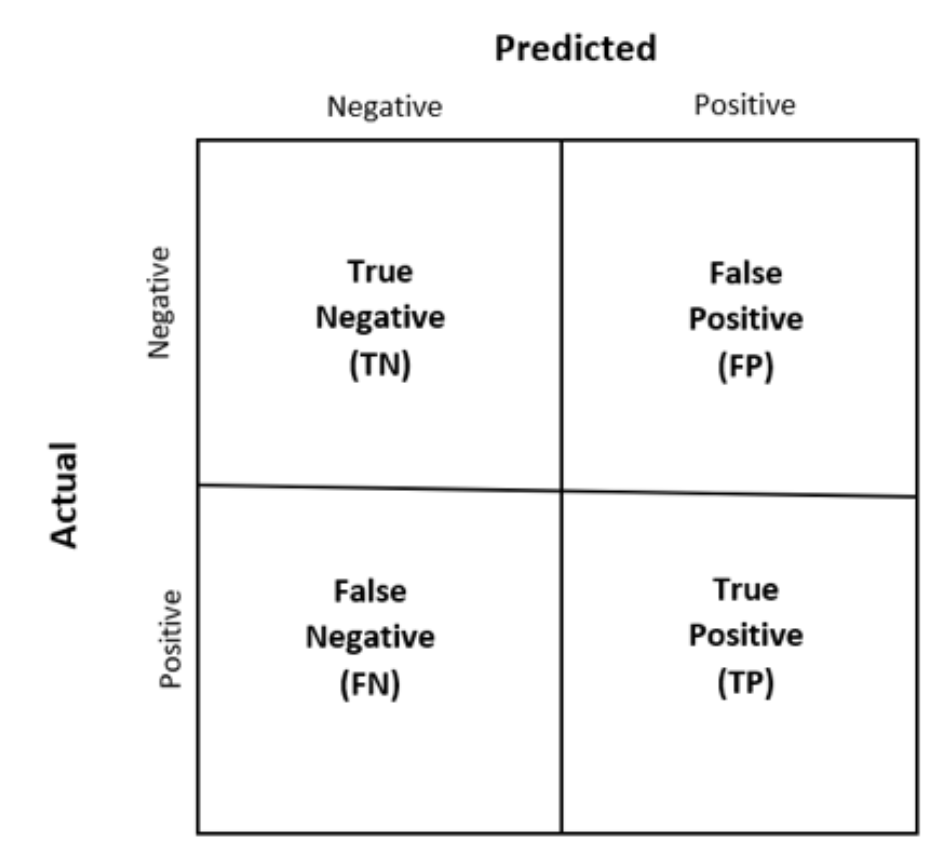
Equality of False Negatives
Enforces constant false-negative rates across groups.
This means that patients – irrespective of their group – have the same probability of being missed.
This measure aims at reducing harm from missed diagnoses.
It does not amend false positives errors
Equal Opportunity with Fairness
The group that should be favored is the group of individuals who belong to the positive class.
This means that patients – irrespective of their group – have the same probability of being correctly classified as High Risk.
This measure aims at providing equal opportunity to be identified/ selected. Fairness among those who truly need treatment.
It does not amend false negative errors
Equality as Equalized Odds
Equalized odds requires the same true-positive and false-positive rates across groups.
Equal probability for patients from both groups who need treatment to be correctly detected as needing additional testing, and equal probability for patients from both groups who do not need testing to be selected for unnecessary follow-ups
Where is Equality as Equalized Odds Used
In a hiring example (gender), the probability of a qualified applicant being hired should be the same for males and females & the probability of an unqualified applicant being hired should be the same for males and females. —> Equalized odds
There is a strong emphasis on predicting the positive outcome correctly (e.g.: correctly identifying who should get a loan as it drives profits for the bank) and minimizing costly False Positives (e.g.: reducing the grant of loans to people who would not be able to pay back) —> Equalized odds
One of the highest levels of algorithmic fairness (but also costly)
Advantages & Limitations of Demographic (Statistical) Parity
Advantages
Ensures equal outcome rates across groups (e.g., similar % flagged high-risk)
Simple to understand, measure, and implement
Helps detect and prevent systematic disparities or underrepresentation
Aligns with goals of equal access to opportunities/resources
Limitations
Ignores ground truth (e.g., actual disease rates), focusing only on proportions
Can lead to harmful errors: unnecessary interventions or missed true cases
Reduces overall accuracy and can increase operational costs
Struggles with intersectionality (overlapping group identities)
May require treating individuals differently, conflicting with individual fairness
Advantages & Limitations of Equality of False Negatives
Advantages
Reduces missed true cases (e.g., sick patients not flagged)
Uses ground truth, making it more aligned with real-world outcomes
Prioritizes fairness in high-stakes situations like healthcare
Ensures each group has a similar chance of receiving needed intervention
Limitations
Ignores false positives (may increase unnecessary interventions for some groups)
May require different thresholds by group, raising fairness/legal concerns
Can reduce overall model accuracy
Does not ensure equal overall outcomes or representation across groups
Advantages & Limitations of Equal Opportunity
Strengths
Ensures individuals in the positive class (e.g., truly sick patients) have the same chance of being correctly identified as high risk
Provides fair access to needed treatment or intervention, regardless of group membership
Focuses fairness on those who truly need help, rather than just overall population proportions
Limitations
Does not address false negative errors (missed cases still occur and may be unequal in other ways)
Only equalizes true positive rates, ignoring other types of errors like false positives
May still result in unequal outcomes across groups in practice
Does not ensure overall parity or eliminate all forms of bias in the model
Advantages & Limitations of Equality as Equalized Odds
Advantages
Ensures equal true positive rates and false positive rates across groups
Provides fairness for both those who need help (correctly identified) and those who do not (avoiding unnecessary selection)
Reduces systematic bias in both beneficial and harmful errors
Useful in high-stakes settings (e.g., hiring, lending, healthcare) where both types of mistakes matter
Strong, comprehensive fairness standard often considered a high level of algorithmic fairness
Limitations
Can be computationally and operationally complex to enforce
Often leads to tradeoffs with overall accuracy and efficiency
May require different decision thresholds across groups, which can raise ethical or legal concerns
Can be costly for organizations to implement and maintain
May still conflict with other fairness goals (e.g., calibration or individual fairness)
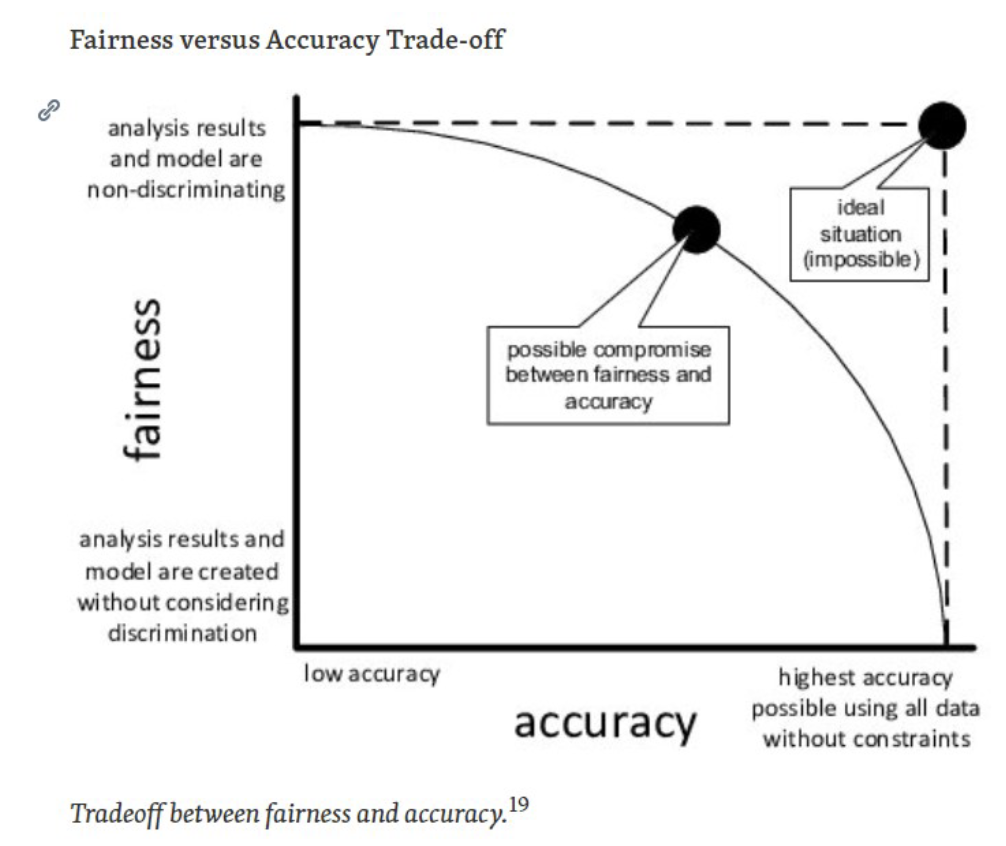
The Accuracy vs. Fairness Trade-Off
Fairness always comes at a cost: as we put an additional constraint on the
model, we introduce a trade-off with accuracyFor example, when we compare a model that maximizes total revenue, a fairness
constrained model will probably promise less profit.But sometimes, greater accuracy may lead to greater unfairness
Final Takeaways on Using Group & Individual Fairness Together
Fairness metrics usually either emphasize individual or group fairness, but fail to combine both.
Many approaches to group fairness often tackle between-group issues (e.g., between groups of different gender or race), but this can in fact increase the within-group unfairness (between members of the same group)
Reducing the between-group unfairness can exacerbate overall/individual unfairness: the overall unfairness in fact goes up.
Why is fairness complex and what can we do about it?
Fairness is highly contextual. There is no one-size-fits-all approach and it depends on the stakeholders and the application.
Finding the right metrics and risk scores for individual assessments can be very challenging and needs to be done on a case-by-case basis.
There are no set answers. A lot of times cost and benefit decisions have to be made.
There are tradeoffs
Certain fairness requirements cannot be satisfied simultaneously.
Fairness is not a “measurement” as it implies a straightforward process, but a continuous process.
The implication of “measurement” is, however, precarious as it implies a straightforward process. However, it should be seen as an investigative process that requires detection, explanation, and mitigation. There is no single fairness checkpoint; harmful properties can enter a system under biased data and/or through data science practices and decisions. This triggers the need for strong internal governance, checklists, and monitoring
What is AI Bias and why is it important?
Occurs when an algorithm produces results that are systematically prejudiced against a specific group(s).
AI algorithms are increasingly used to distribute goods and services.
information, loans, housing, jobs, interviews, diagnoses, medical treatments, punishments, etc.
Can have a significant impact on opportunities, health, and quality of life.
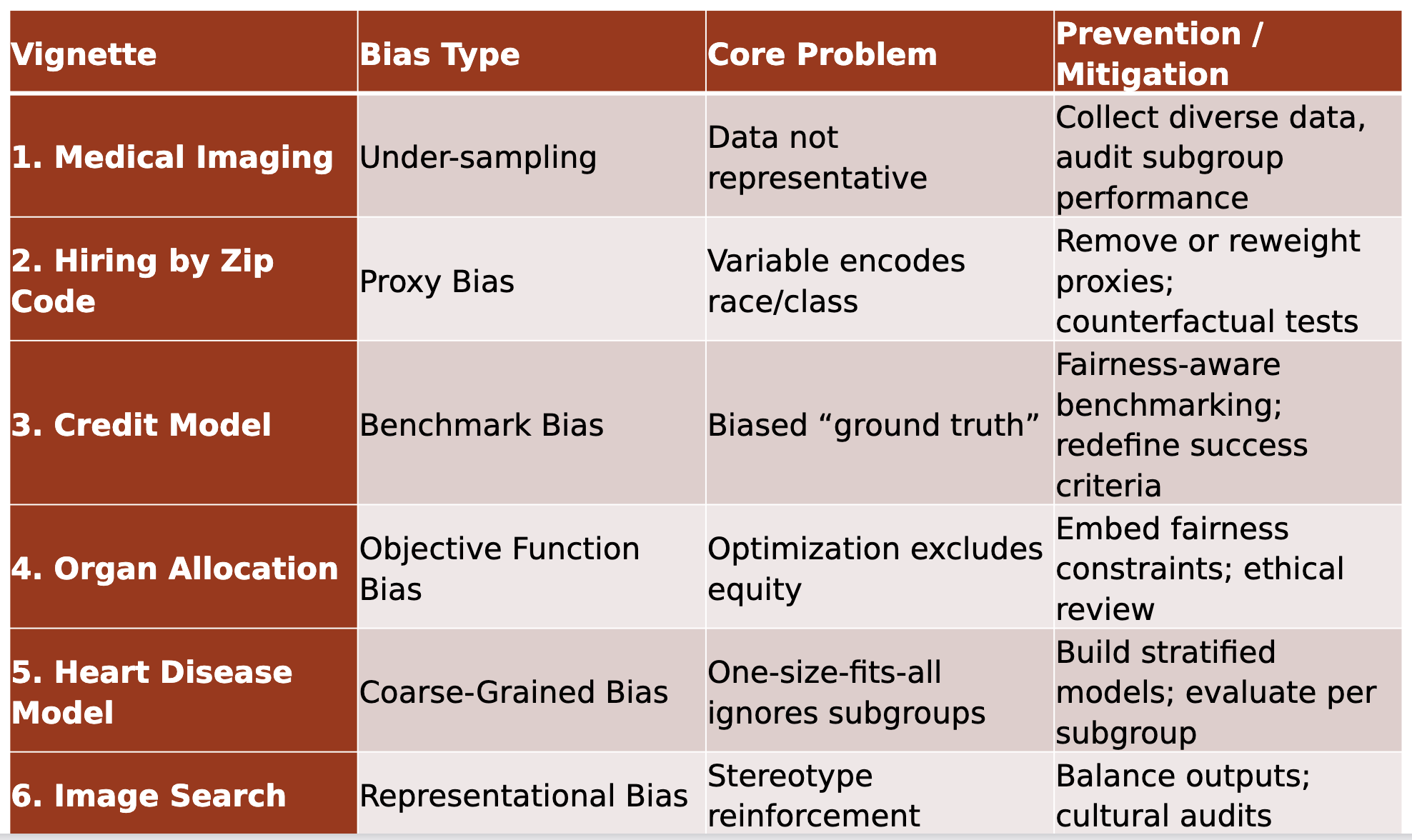
What are the sources of AI bias?
Problems with training data
Discrimination in real-world practices that are reflected in the (biased) training data
E.g., biased hiring practices, loan practices, etc.
Biased image labeling
Under-sampling/Selection bias: Data not representative of the population
Proxy Bias: using proxies for data that is difficult to access
E.g., using arrest records to proxy criminal convictions
Problems with testing and how you think about the use case
Coarse-grained model: one-size-fits all (e.g., heart disease presents differently in men vs women)
Benchmark or testing bias
Benchmarks are biased
e.g., your algorithm predicts well in terms of true positive rates against a benchmark mortgage dataset. However, the dataset under-sampled black applicants. Therefore, you have a highly accurate mortgage-worthy-white-person predictor.
Objective function bias – goals may unintentionally lead to disparate impacts
among subpopulationsE.g., lung transplant determinant that aims to maximize years out of the lungs (give it to
someone who will live the longest, all other things being equal)
How can we identify and measure bias?
Rely on definitions of fairness and related computational measures of bias based on these definitions.
E.g., equal opportunity definitions of fairness assume equal true positive rates across groups; equal odds definitions of fairness assume equal true positive and equal false positive rates across groups
What are the major challenges in measuring bias?
Metrics of fairness
Timing of Identifying Bias
Allocative AND Representational Harms
Legal Issues
Choosing Risk Mitigation Strategies
What are some suggested guidelines in terms of structure that can be helpful for bias?
Metrics of Fairness
Include individuals with relevant ethical, legal, and business expertise, who can determine which, if any, of the mathematical metrics of fairness are appropriate for a particular use case
Timing of Identifying Bias
Attempts at identifying and mitigating potential biases of your models should start before training your model and, ideally, before determining what your training data sets should look like and be sourced from
Legal Issues
Include a lawyer when determining the appropriate risk-
mitigation technique
Choosing Risk Mitigation Strategies
Include individuals with relevant expertise for choosing
appropriate risk-mitigation strategies
What are representational harms vs. allocative harms and which is easier to identify through computational AI fairness measures?
Distinction between “representational harms” (algorithmically filtered depictions that are discriminatory) vs. “allocative harms” (unfairly assigned opportunities or resources by the algorithm)
Computational measures capture “allocative harms” of unjust distribution of goods and services.
Typically humans are needed to identify many types of representational harms.
Representational Harms
Occur when systems reinforce the subordination of some groups along the line of identity
What are some bias mitigation strategies?
Input Data
Get more data in case of under-sampling
Get better proxies (to mitigate proxy bias)
Examine if one-size-fits-all model is right for your population
Alter inputs or adjust their weights: e.g., zip code proxies for race. Remove zip code from data or reduce its weight
Use bias-corrected synthetic data
Decisions/Output: Adjusting Thresholds for Outputs
Use a binary yes or no or use thresholds? What should these thresholds be? Should you use different thresholds across different populations?
Identifying bias: Lack of demographic data against which to compare outputs
Not clear how this can be addressed
Synthetic data may be an option
Bias Examples Table
What is AI explainability?
The ability to understand and explain the outputs of a machine learning (ML) model in human terms.
Enables monitoring and accountability both during production and in the “wild” to ensure fairness and debiasing and mitigate against model drift.
Lack of explanation may lead to ethical, regulatory, or legal risk.
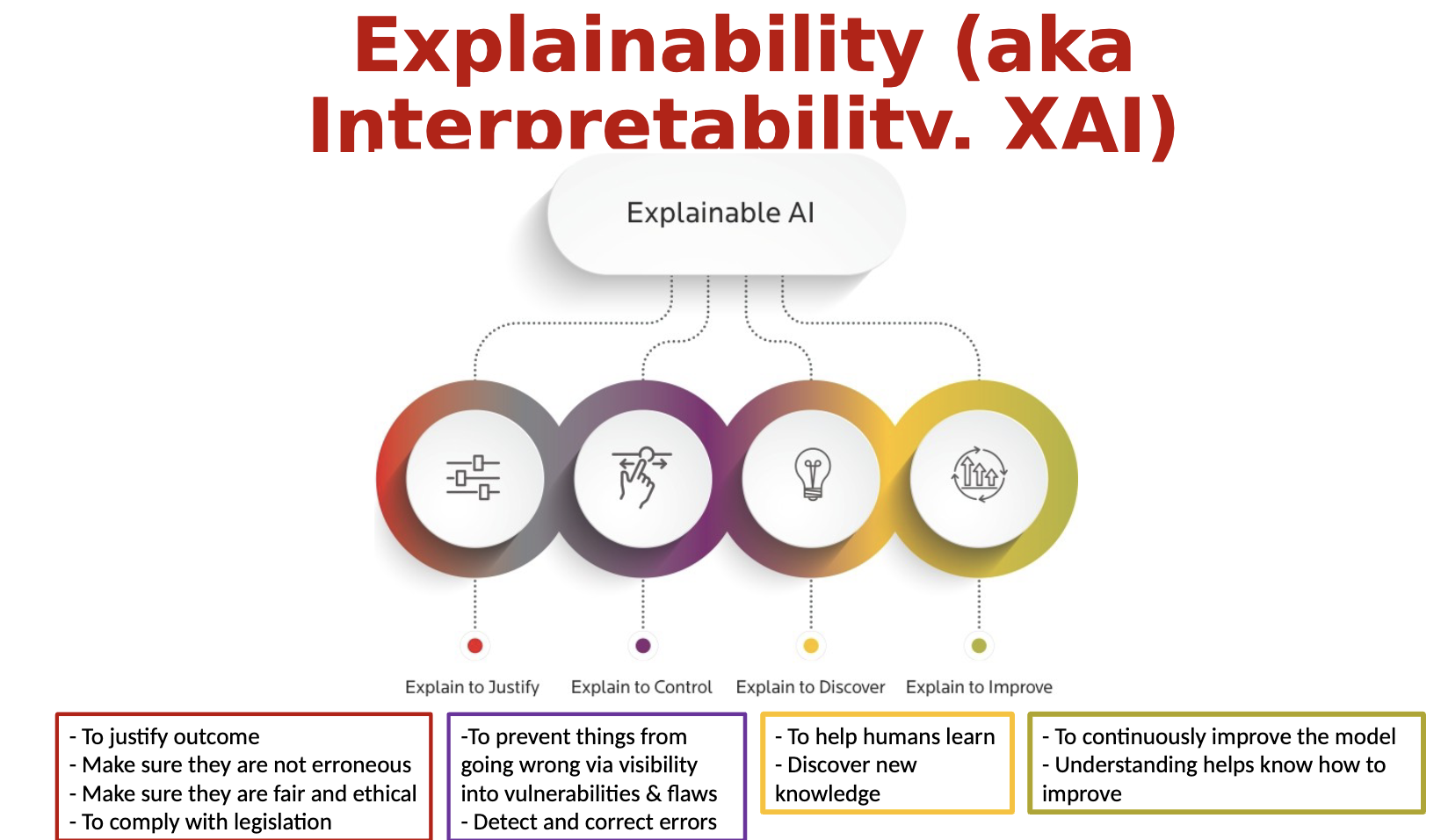
What are the objectives of AI explainability?
Explain to justify
Explain to control
Explain to Discover
Explain to Improve
Also to ensure fairness, to inform users about what they would need to change to get a favorable outcome, to show respect
Why is AI explainability important?
Lack of explanation may lead to ethical, regulatory, or legal risk
Who are the various stakeholders that need explanations?
All system builders
Who: data scientists, developers
Why: ensure/improve performance
End user decision makers
Who: physicians, judges, loan offices, recruiters
Why: trust/confidence, insights
End consumers
Who: patients, accused, loan applicants, job applicants
Why: understanding of factors
Regulatory bodies
Who: EU (GDPR), NYC Council, US Govt
Why: ensure fairness for constituents (e.g., compliance to right to explanation by GDPR)
People Explanations
Why people made the decisions they did.
E.g., we automated hiring decisions because we received more applications than we could handle; we set the threshold to 3.74 because of the way the outputs were clustered combined with knowledge of our company’s risk preference.
Machine Explanations
How the model arrived at its outputs given the inputs.
How do People v. Machine Explanations Differ?
Humans explain in terms of meaning and reasoning, while machines explain in terms of data patterns and computations
Machine explanations differ from people explanations
Machine explanations are complex
# of variables at play, # of relationships, nature of relationships
Not understandable in the same way human explanations are
What are the various types of machine explanations?
Global Explanations: What are the rules that transform inputs to outputs? What features are important to the model? How do features interact to produce the output?
Local Explanations: Why did the model yield this particular output given these particular inputs for this particular case? Why did the model come to this conclusion?
Why not ALWAYS implement Explainable AI?
Machine explanations
Require resources to develop
Tradeoff between accuracy and explainability
The more data and the more patterns your ML finds, the less likely it is to understand what’s going
Types of Machine Learning Explanations: Global v. Local
Global Explanations
Understanding the logic of the model as a whole
What are the main features that influence the predictions of the model? (e.g., feature importance)? How do these interact to produce the output?
Useful to data engineers, to managers approving use of the model, regulators
E.g., SHAP, LOFO, PDP, Permutation FI
Local Explanations
Understanding the reasons behind a specific prediction
Why did the model come to this conclusion?
Useful to decision-makers (e.g., loan officer), end-users, regulators
E.g., SHAP, LIME
Local = one decision (individual-level explanation)
Global = overall model behavior (system-level explanation)
Types of Machine Learning Explanations: Intrinsic interpretability vs. Post-hoc interpretability
Intrinsic (or Direct) Interpretability
Models are interpretable due to their simple structure (e.g., linear models, trees)
Post-hoc Interpretability
Interpreting a black-box model like a neural network by applying model interpretability methods such as LIME, SHAP, LOFO, etc. after training the model or while in production
Intrinsic = built-in transparency
Post-hoc = added explanation after the fact
Tradeoff between accuracy (and model complexity) and intrinsic interpretability
Types of Machine Learning Explanations: Model specific vs. model agnostic
Model-specific explanation methods
Limited to specific model or groups of models (e.g., feature importance assessments work for tree models)
They depend heavily on the working and capabilities of a specific model
Model-agnostic explanation methods
Work on any model
Do not look into the black box of the algorithm but work with input – output pairs (e.g., LIME, SHAP, LOFO, etc.)
Model-specific = tied to one model’s structure (more precise)
Model-agnostic = works on any model (more flexible but approximate)
Who determines what explanations are needed for a specific use case?
Explanations are not one-size-fits-all—they are defined by the context, risk level, and needs of the people affected by or responsible for the system
You need the right people to determine whether people explanations, global machine explanations, local machine explanations, or all of the above are important for a specific use case
Why don’t we provide explanations for all AI applications?
We only prioritize explanations when the stakes, risks, or legal/ethical requirements justify the added complexity.
Explanations come with costs, limitations, and tradeoffs, and they aren’t always necessary or useful
The Importance of Machine Explanations
Helps determine if the rules are fair
Helps monitor if the algorithm is functioning as intended
It informs what one can do to change the outcome
It shows respect
Need to balance the importance of explanations against accuracy and cost/resources
When Machine Explainability does not Matter
When the model does not directly deal with decisions about how anyone should be treated
No ethical risk
E.g., predicting delivery dates of inventory
When people explanations of why you want to use a black box plus informed consent justifies use
Accuracy is very important or trading off accuracy for explainability is not prudent
Stock market predictions, Identifying cancer in mammograms
Trust a black box in such cases if the algorithm performs well - reliably and robustly against benchmarks
Caveat: People explanations + informed consent not sufficient when procedural justice is required. In such cases, algorithmic inscrutability makes it impossible to assess whether someone was treated procedurally fairly or unfairly.
When Machine Explainability DOES Matter
When expressing respect is ethically required
E.g., when the person may be harmed in some way by output, “owe” them an explanation
When people need to know how to get better results
When an opportunity is denied, important to explain why so that they can make changes to improve their chances next time
When people need to know how to approach and make a decision
Human in the loop by exception: explain why a decision was flagged as an exception
When outputs are strange
Should we rely on the judgment of an algorithm or a human expert?
Correlation vs causation
When you need to justify treatment
Ethical, regulatory, legal
1. Global Explanations: Are the ML rules - what turns inputs into outputs – justifiable?
2. Local Explanations: Was this particular output about this particular person justified?
The question of whether certain rules are justified (e.g., use parents’ loan repayment history to decide whether to grant one loan) is not a question for data scientists.
What makes for good explanations?
Objective
Demonstrate respect
Help users make informed decisions
Support fairness, transparency, and trust
Truth
Accurate and faithful to the model
Use simplifications only when appropriate
Usefulness (Ease & Effectiveness)
Clear, not overly detailed or complex
Right level of detail (global vs. local as needed)
Intelligibility
Easy for the intended audience to understand
Matches users’ knowledge and context
Key idea
Good explanations are designed with end users based on their needs and goals
How can we use explanations to build the appropriate level of trust?
Avoid overreliance (too much trust) and avoid algorithmic aversion (too little trust)
Help users understand when to trust the system and when they should use their own judgment instead
How can we appropriately calibrate trust?
Explain in the moment and overall
Explain the system and the output
Both during onboarding and by tying explanations to actions
Articulate data sources
Explain what is important
Partial explanations with progressive disclosure if warranted
Account for situational stakes
Consider the risk of a user trusting a false positive, false negative, or a prediction that is off by X%
Which of these deserve an explanation so that the user can make an appropriate decision?
Decide if and how to show model confidence to manage AI influence
What are example-based explanations and how are they useful?
Explain an AI decision by showing similar past cases (examples) instead of technical model details
Help users understand “why this outcome happened” through comparison
Appropriate when it is challenging to explain the reasons behind AI predictions.
These can help users understand why the model behaved the way it did and whether to trust the recommendation.
Global: The AI shows image examples it tends to make errors on and examples it performs well on.
Local: To help the user decide whether to trust a “poison oak” classification, the AI displays most-similar images of poison oak as well as images of other leaves.
What are confidence displays?
Show how certain or uncertain an AI model is about its prediction
Usually expressed as a probability or confidence score (e.g., 92% likely, low confidence)
It can help users calibrate their trust and make better decisions
But it is not always appropriate and can be confusing and misleading
On average, the AI has 80% confidence in its categorizing of images.
It is unclear whether a certain level (e.g., 80%) reflects high or low confidence.
Numeric-Confidence level (poison oak - 80%) or categorical (high, medium, low confidence)
What is privacy?
Privacy is the claim of groups, individuals, and institutions to determine for themselves when, how, and to what extent information about them is communicated to others (Westin 1967)
Privacy is the individual’s control of information concerning their person (U.S. Dept of Justice)
What information is being collected
How that information is being used
The right to control who can collect what data about you and what they can use it for.
Extent to which people have knowledge and control over their data without undue pressure.
What are the three aspects of privacy?
Regulatory Compliance
Ethics
Cybersecurity (integrity & security of data)
The privacy act of 1974 centers around “notice and consent.” What issues around consent make this not an effective privacy protection regulation?
Impossible to enforce in many AI applications (smart driving cars)
Onerous to properly inform oneself about the privacy policies of organizations
People not only care about how their information will be used, but also about their data being collected.
Desire to change this model by shifting the burden of protecting individual privacy from consumers over to the businesses that collect data: Data Stewardship
Regulate how companies process data: what they collect and how they use it and share it
What are the privacy concern issues that are unique to AI and AI privacy issues?
AI is data hungry
Data Persistence
Data existing longer than the human subjects that created it, driven by low data storage costs.
Data Repurposing
Data being used beyond their originally imagined purpose
Data Spillovers
Data collected on people who are not the target of data collection
What are the four elements that organizations can combine to define their level of privacy?
Transparency
If you do not know what info is being collected about you, what’s been done with it, what decisions it contributes to, who it’s been shared with or sold to, then you cannot possibly exercise control
Data Control
Have the ability to collect, edit, or delete information about oneself, and be able to opt in or out of being treated in a certain way
Opt out by default
Do users automatically opt-in for collection of their information when using a site or is the default opt-out
Opt-in puts the burden on the user while Opt-out puts the burden on the organization
Full Services
Orgs may need to adjust the level of services it provides based on amount and type of data a person shares
The five levels of privacy for organizations
Blindfolded and handcuffed
People are in the dark (not knowledgeable) and passive with regard to their data and the predictions made about them
Handcuffed
People are knowledgeable about their data and predictions made about them, but they are passive with regards to what is collected and what is done with their data
Pressured
People are knowledgeable and they have some degree of control over what data is collected and how it’s used
Slightly Curtailed
People are knowledgeable and their data has not been collected and used without their consent
Grateful
Organization provides full services independent of what data the person opts in to provide and consents to be used
The five levels of privacy for organizations key points
At levels 1 (blindfolded and handcuffed) and 2 (handcuffed)
Users have no control over their data.
The judgment that we are providing valuable services and therefore we are justified in collecting and using private data is made by the organization.
At levels 3 (pressured) and 4 (slightly curtailed)
People can opt out.
Judgment of whether giving up their privacy is beneficial is made by users.
But orgs can incentivize people to make the tradeoff by curtailing services.
Tensions in Applying Existing Privacy Guidelines for AI: Three Pillars of Information Privacy (OECD Guidelines)
Collection Limitation
Collection of personal information should be limited to only what is necessary; personal information should only be collected by lawful and fair means; and where appropriate, should be collected with the knowledge and/or consent of the individual
TENSION: AI relies on large amounts of data that individuals are not aware of it being collected (IoT, smartphones, web tracking technology).
Purpose Specification
The purpose of collecting personal information should be specified to the individual at the time of collection.
TENSION: Organization may not know how the data will be used in the future by AI.
Use Limitation
Personal information should only be used or disclosed for the purpose for which it was collected, unless there is consent or legal authority to do otherwise.
TENSION: Organizations are permitted to use information for a “reasonably expected secondary purpose”. But AI can reveal patterns that are not reasonably expected
Surveillance Capitalism
Unilaterally claims human experience as free raw material for translation into behavioral data.
Although some of these data are applied to product or service improvement, the rest are declared as a proprietary behavioral surplus, fed into advanced manufacturing processes known as ‘machine intelligence,’ and fabricated into prediction products that anticipate what you will do now, soon, and later
Attention Economy
“bottleneck of human thought” that limits both what we can perceive in stimulating environments and what we can do.
“A wealth of information creates a poverty of attention,” suggesting that multitasking is a myth
Intention Economy
Born from “combining (a) hyper-personalized manipulation via LLM-based sycophancy, ingratiation, and emotional infiltration and [from] (b) increasingly detailed categorization of online activity elicited through natural language.
This new dimension of automated persuasion draws on the unique capabilities of LLMs and generative AI more broadly, which intervene not only on what users want, but also, to cite Williams, ‘what they want to want.’”
Why are surveillance capitalism, attention economy, and intention economy important with respect to AI privacy issues?
These concepts show how AI shifts from just analyzing data to tracking attention and predicting or influencing human behavior, which creates major privacy risks
How is privacy determined in organizations, and what tradeoffs does it involve?
Privacy level depends on an organization’s business model and goals
Organizations may apply different privacy levels to different products/services
There are key tradeoffs between privacy and other values:
Privacy vs. safety/security (greater good)
Privacy vs. innovation
Privacy vs. accuracy of predictions
Who should be involved in making determinations about the right level of privacy for a given product or service?
Privacy decisions should not be made by one group alone, they require a collaborative, multi-stakeholder process balancing user rights, legal constraints, and organizational goals
What are the main components of structure?
Roles and responsibilities
Policies
Processes & procedures
What is the objective of AI governance?
How to create, scale, and maintain an AI ethical risk governance structure in your organization to systematically and comprehensively identify and manage the ethical, reputational, regulatory, and legal risks of AI
What is the typical first step in creating AI governance?
Articulating ethical principles for AI development and deployment
Describe the problems with current ethics statements that prevent them from being helpful
They lump together Content and Structure
Confusing means and ends, strategies and goals, that is, governance structures and content (ethical values)
They lump together ethical and non-ethical values
Lumping together ethical, cybersecurity, and engineering (e.g., accuracy) issues into “responsible” AI obfuscates addressing the true AI ethical issues (e.g., bias, privacy violations)
They lump together instrumental and non-instrumental values
They describe overly abstract values
Values not specific enough, Don’t state “what to do”
Need AI ethical principles that guide action
What is the recommended 4-step approach to enable an organization to develop relevant and actionable ethical value statements?
Slides
State your values by thinking about your ethical nightmares
Explain why you value what you do in a way that connects to your organization’s mission or purpose
Connect your values to what you take to be ethically impermissible
Articulate how you will realize your ethical goals or avoid your ethical nightmares
Study Guide
State your ethical values by identifying the organization’s ethical nightmares
Understand why these are important by linking to the organization’s mission
Connect these values to what is ethically impermissible
Articulate how you will realize these values
What are the advantages of this approach (4-Step) to developing AI ethical values
Defined values and strategies in a way that
Enables action (helps determine KPIs)
Connects to what is ethically off-limits
Can perform gap analysis based on the values you have specified to see where your company is and where it needs to be
If you involve stakeholders across the organization, you create awareness and buy-in
By articulating what is ethically impermissible and why, you enable people to think about ethically tough cases
Explanations for why some things are impermissible and why the organization does X are helpful in discerning the right thing to do
Can be used for branding and public relations
How do we create an AI Governance Structure and what is the importance of executive leadership and ownership of this structure
Change starts from the very top. “Executives need to speak with their dollars, their time, their resources, that they’re allocating to this,” he says. Otherwise, people working on ethical AI are set up for failure.”
“Successful responsible-AI teams need enough tools, resources, and people to work on problems, but they also need agency, connections across the organization, and the power to enact the changes they're being asked to make”
Describe the 7-step approach outlined in the chapter
Articulate clear AI ethical standards.
Create broad organizational awareness of AI ethical standards and questions/risks.
Provide product development and procurement teams with the appropriate tools and processes to identify and mitigate AI ethical risk.
Include relevant experts in making these decisions (beyond data scientists).
Assign role-specific responsibilities to create accountability.
Create and track KPIs for the AI ethical risk program.
Have executive ownership of the AI ethical risk program
What is ethical case law and how do we create it? Why is this important and useful to have in deciding on AI ethical questions? Why should we create this a priori?
Like legal case precedents
Prior cases where the org faced an ethical dilemma and how it resolved it well
Prior cases from other similar organizations
Fictional cases and their resolution
One way: make statements (e.g., we never sell our data to third parties) and see how much consensus there is. Lack of consensus implies this is an area to think through what our stance should be, and under what conditions
Create these a priori (before encountering an ethical question)
Develops a skill to tackle tough ethical questions well
Resolution is not compromised because the right thing to do in the specific situation is painful (e.g., may lead to a loss of profit or loss of bonus, etc.).
Can be used by AI teams in developing products, by experts and senior execs in tackling tough cases, and in AI ethics training across the organization
Why is it critical to create AI ethical risk organizational awareness?
AI applications are procured across the organization [e.g., HR, marketing, etc.] by people who are not aware of the potential for, and are unable to assess, AI ethical risk
Two false assumptions
AI ethics are for techies to figure out in terms of technical solutions
AI ethics are for techies and product teams
AI is procured and used by many departments and units within an organization (e.g., HR, marketing).
Each needs to be aware of AI ethical risks that may be built into vendors’ solutions
Personnel in these units need to be aware of sources of AI ethical risk and be able to assess it.
Need for education and upskilling of personnel
Develop new processes to assess vendor software by appropriately trained personnel
What do product development teams need to identify and mitigate AI ethical risk?
Product development teams must understand the issues and how to address them in principle.
Product development teams must have concrete tools and processes to enable them to
Identify the ethical risks
Mitigate the ethical risks
Product development teams need to engage in “AI ethics by design”.
Why shouldn’t the identification and mitigation of AI ethical risk be solely the responsibility of data scientists and product developers?
Unwise and unfair to put the burden of identifying and mitigating AI ethical risk on data scientists, engineers, and product designers.
They lack expertise in ethics
AI ethical issues can be very complex and can result in reputational, regulatory, and legal risks
AI ethical risks scale rapidly (e.g., bias amplification)
Discuss the function, membership, and jurisdiction of an AI ethics committee (AIEC).
Function of an AI Ethics Committee
To play an oversight role in systematically and comprehensively identifying and mitigating the ethical risks of AI products that are developed in-house or that are procured from third-party vendors
What does that look like?
When teams bring a proposal for an AI solution, AIEC is responsible for
Recommending whether or not to develop or procure the solution
Confirm that there are no ethical risks pertaining to the solution that would warrant cessation
Recommend future changes to the proposed solution, that if adopted, would lead to a second review
AIEC should document all cases and record its recommendations
AIEC process should be overseen and audited
This addresses understanding risk before a product is deployed or designed.
Who is part of the AIEC?
AIEC requires diverse expertise:
Data scientist who understands the technical aspects of the product and understands what is being done and can be done from a technical perspective.
Product design expert who can shape ethical risk-mitigation strategies in ways that do not undermine the essential functions of the product.
Ethics-adjacent experts such as lawyers and privacy officers who understand current and potential regulations, anti-discrimination law, and privacy practices.
Ethicist who has training, knowledge, and experience in understanding and spotting ethical issues, familiarity with important concepts and distinctions that can aid in ethical deliberations, and skill in helping people assess ethical issues objectively
Subject-matter experts (e.g., if you are deploying an algorithm for hiring, HR)
At least one member unaffiliated with the organization
All members should have an understanding of the business goals and necessities of the organization.
When should the product teams consult with the AIEC?
Should be consulted before research or product development begins
To identify potential ethical risks
Much cheaper and efficient to make changes in products that do not yet exist
How much power should the AIEC have?
Are product development and procurement teams required to consult with AIEC or is it merely recommended
Are the decisions of the AIEC requirements that must be followed or are they merely recommendations? And if they are required, can a senior executive overrule them?
What are the risks of not having an AI ethics committee
Increased risk of not identifying AI ethical risks
Risks of identifying AI ethical risks only in deployment, when it is costly to address
legal, reputational, etc. costs have already been incurred
more difficult and costly to change the system
Inconsistencies in ethical standards across departments
More opportunities for conflict between short-term career goals, short-term profit etc. and the long-term welfare of the organization.
Discuss what is involved in creating an accountability structure in the organization
Assign role-specific responsibilities aimed at identifying and mitigating AI ethical risks.
For data collectors, data scientists and engineers, product owners, etc
There should be both incentives to fulfill responsibilities and disincentives for those who do not fulfill responsibilities.
Failure to fulfill responsibilities must be taken seriously and have consequences.
Orgs that turn a blind eye to ethical risks will realize those risks
Adhering to ethical practices should NOT put individuals at a competitive disadvantage in terms of bonuses, raises, promotions, etc. compared to those who do not
Recognize, formally and informally, those who adhere to AI ethical standards
Make this part of the annual evaluation process and incentives
What two types of KPIs are used to monitor an AI Ethics program, and what do they measure?
(1) Compliance / Adoption KPIs – Measure how well the organization is following ethical standards.
Examples:
% of product proposals approved/rejected by ethics committee
# of ethics violations or disciplinary actions
% of employees trained or aware of standards
(2) Effectiveness / Risk Mitigation KPIs – Measure whether the standards actually reduce ethical risk.
Examples:
% of products meeting privacy commitments
% of systems providing understandable explanations
Metrics related to fairness, privacy, and respect outcomes